오디오 처리 가이드
이 가이드는 립 싱크 생성기에 오디오 데이터를 공급하기 위해 다양한 오디오 입력 방식을 설정하는 방법을 다룹니다. 진행하기 전에 설정 가이드를 완료했는지 확인하세요.
오디오 입력 처리
오디오 입력을 처리하는 방법을 설정해야 합니다. 오디오 소스에 따라 이를 수행하는 여러 가지 방법이 있습니다.
- 마이크 (실시간)
- 마이크 (재생)
- 텍스트 음성 변환 (로컬)
- 텍스트 음성 변환 (외부 API)
- 오디오 파일/버퍼에서
- 스트리밍 오디오 버퍼
이 접근 방식은 마이크에 말하는 동안 실시간으로 립 싱크를 수행합니다:
- 표준 모델
- 현실적인 모델
- 감정 반영 현실적 모델
- Runtime Audio Importer를 사용하여 캡처 가능한 사운드 웨이브를 생성합니다.
- Linux 및 Pixel Streaming의 경우, Pixel Streaming Capturable Sound Wave를 대신 사용하세요.
- 오디오 캡처를 시작하기 전에
OnPopulateAudioData델리게이트에 바인딩하세요 - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData를 호출하세요 - 마이크에서 오디오 캡처를 시작하세요
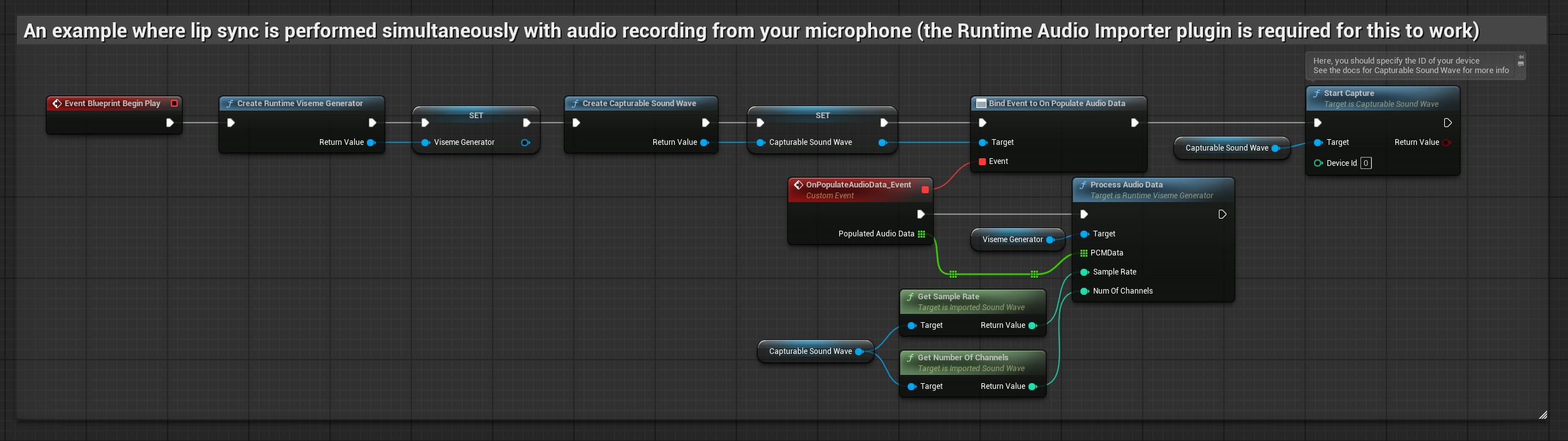
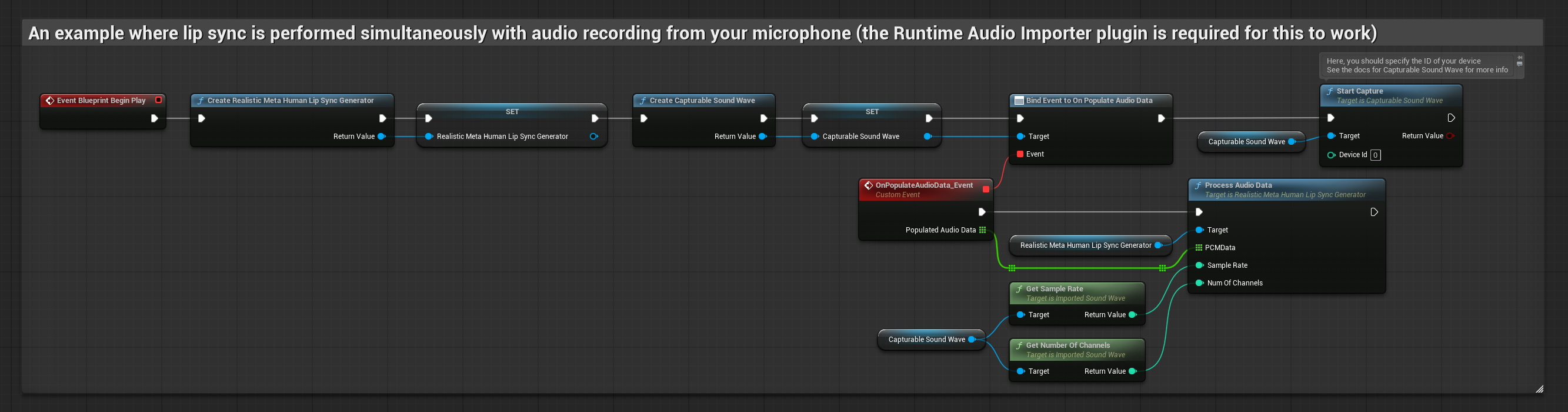
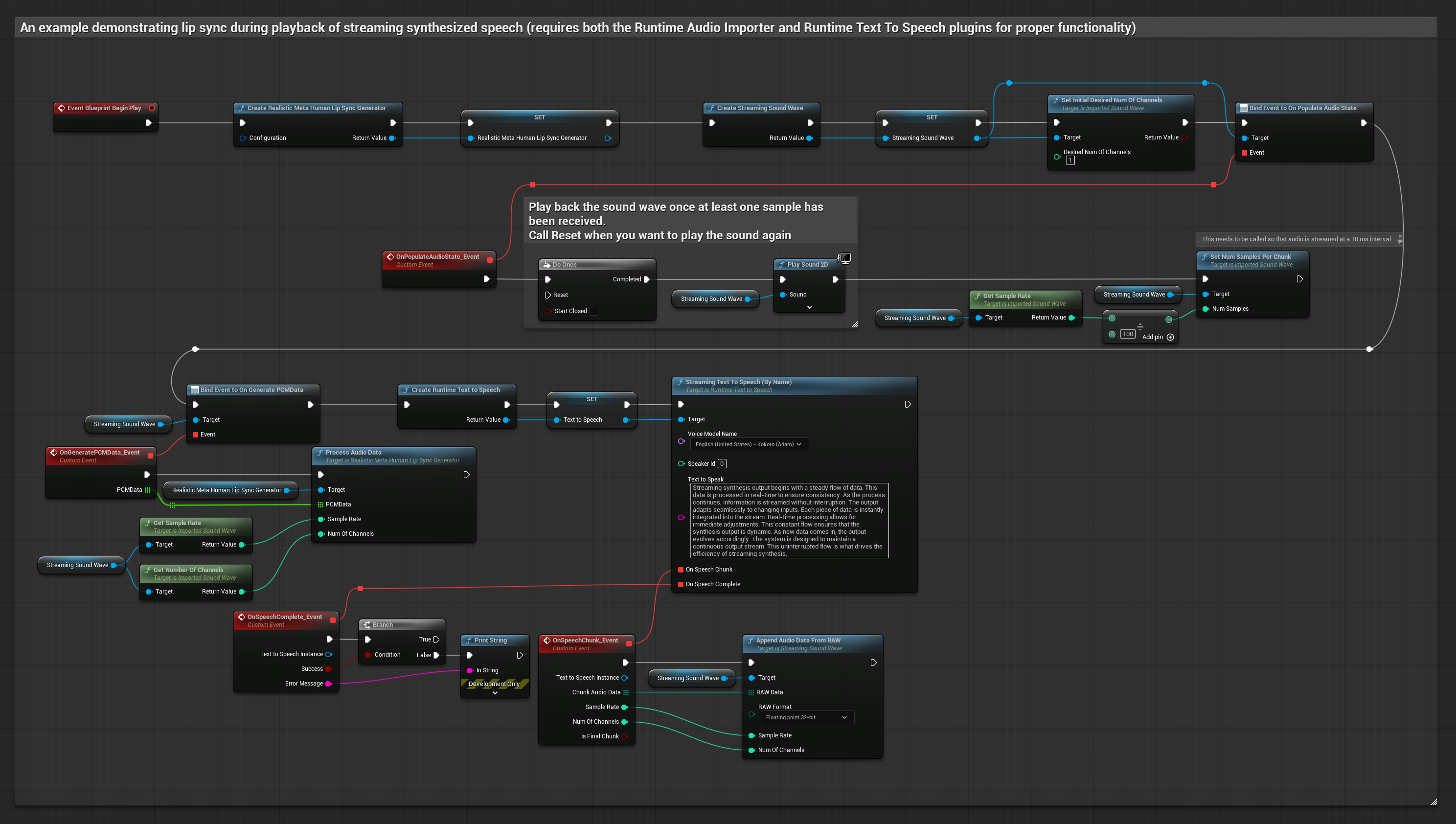
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
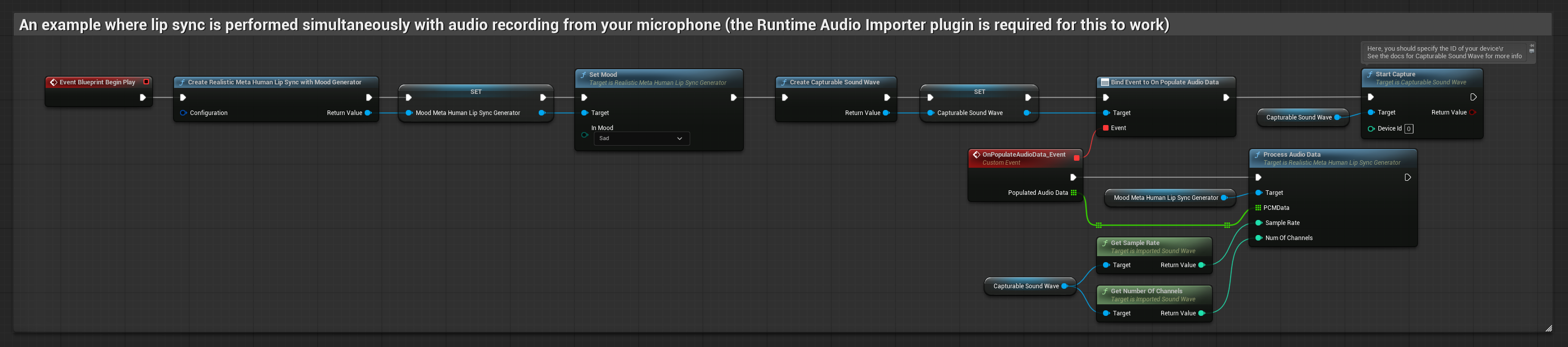
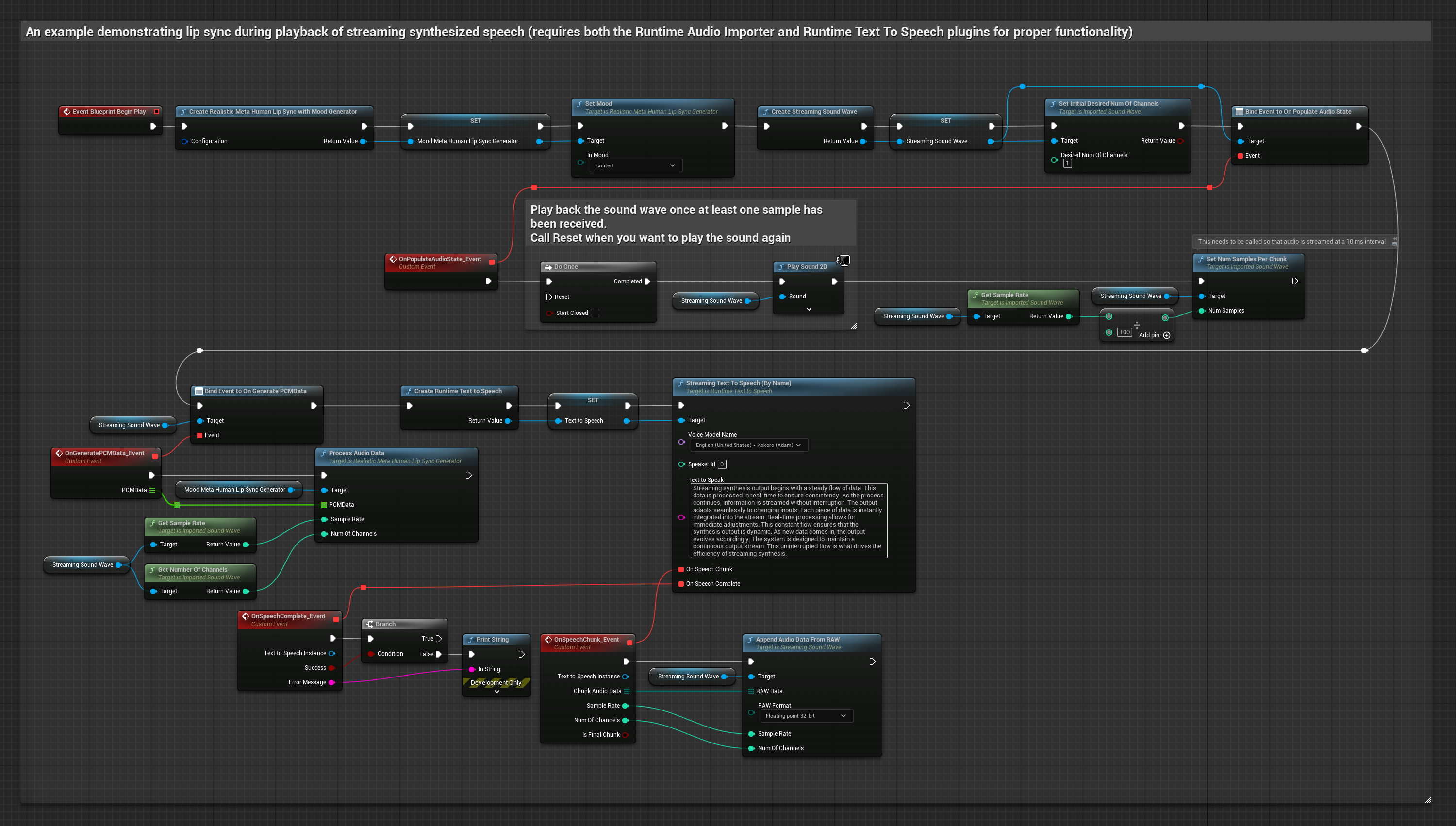
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
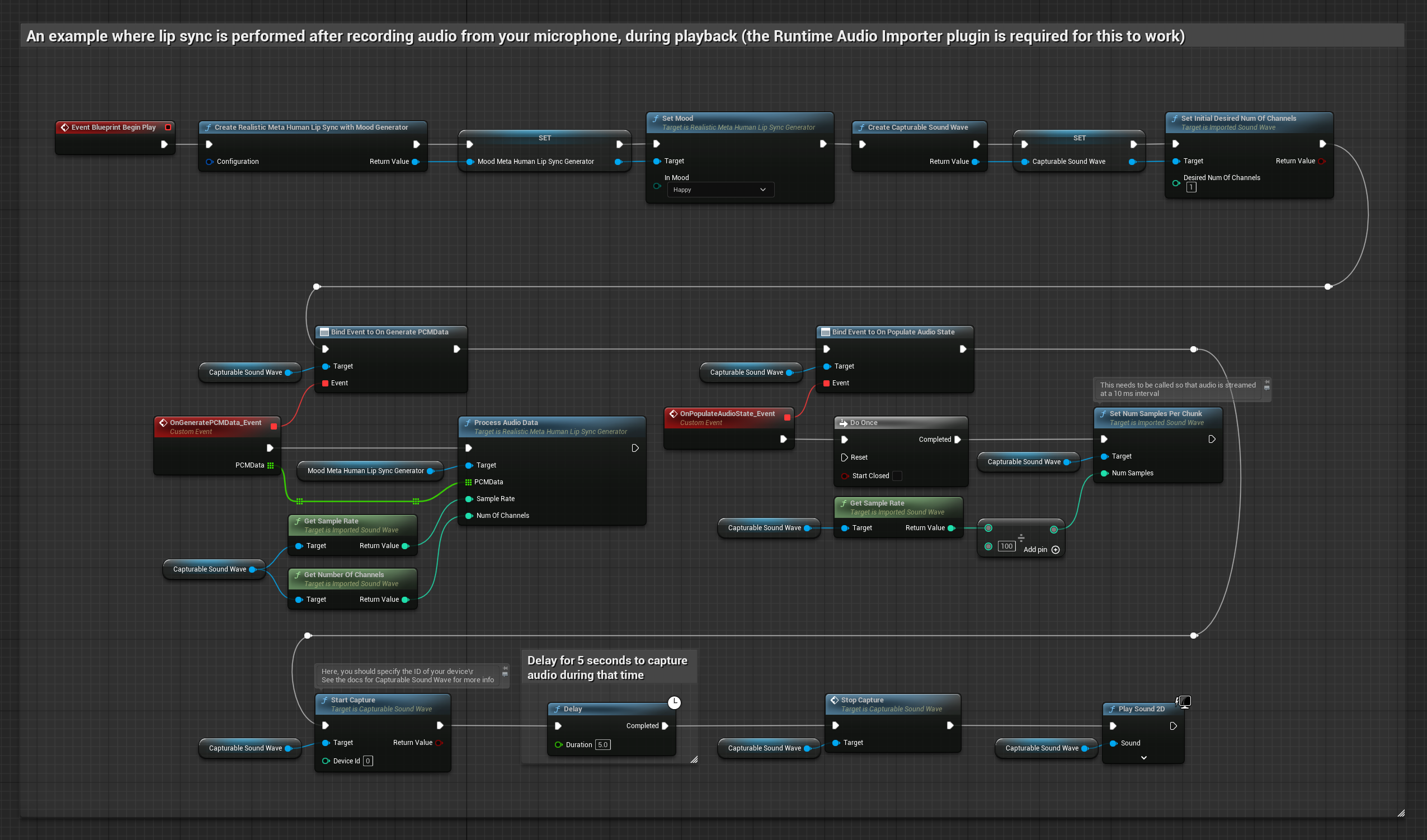
이 접근 방식은 마이크에서 오디오를 캡처한 후 립 싱크와 함께 재생합니다.
- 표준 모델
- 현실적인 모델
- 감정 반영 사실적 모델
- Runtime Audio Importer를 사용하여 캡처 가능한 사운드 웨이브를 생성합니다.
- Linux 및 Pixel Streaming의 경우, Pixel Streaming Capturable Sound Wave를 대신 사용하세요.
- 마이크에서 오디오 캡처 시작
- 캡처 가능한 사운드 웨이브를 재생하기 전에 해당
OnGeneratePCMData델리게이트에 바인딩 - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData호출
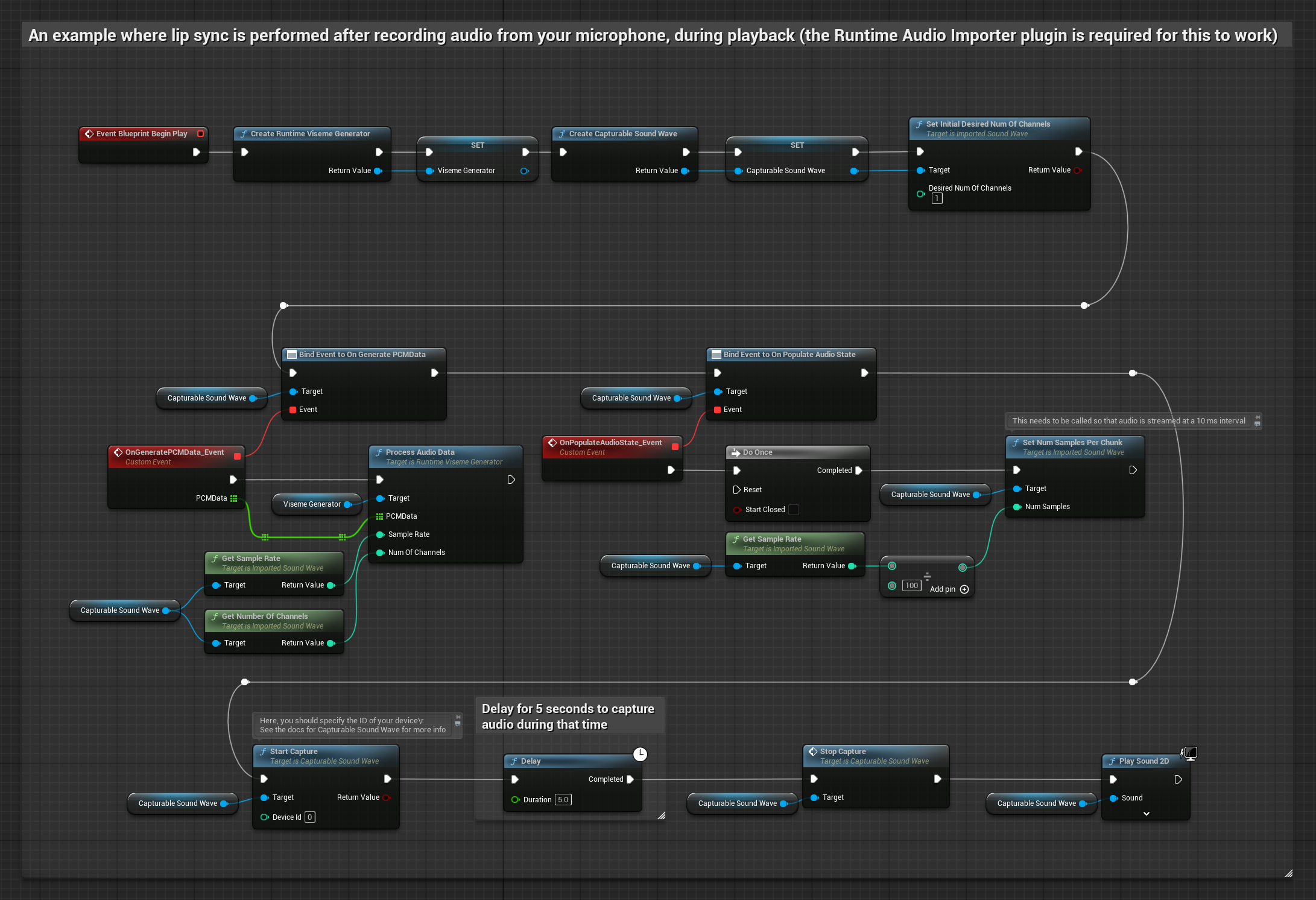
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
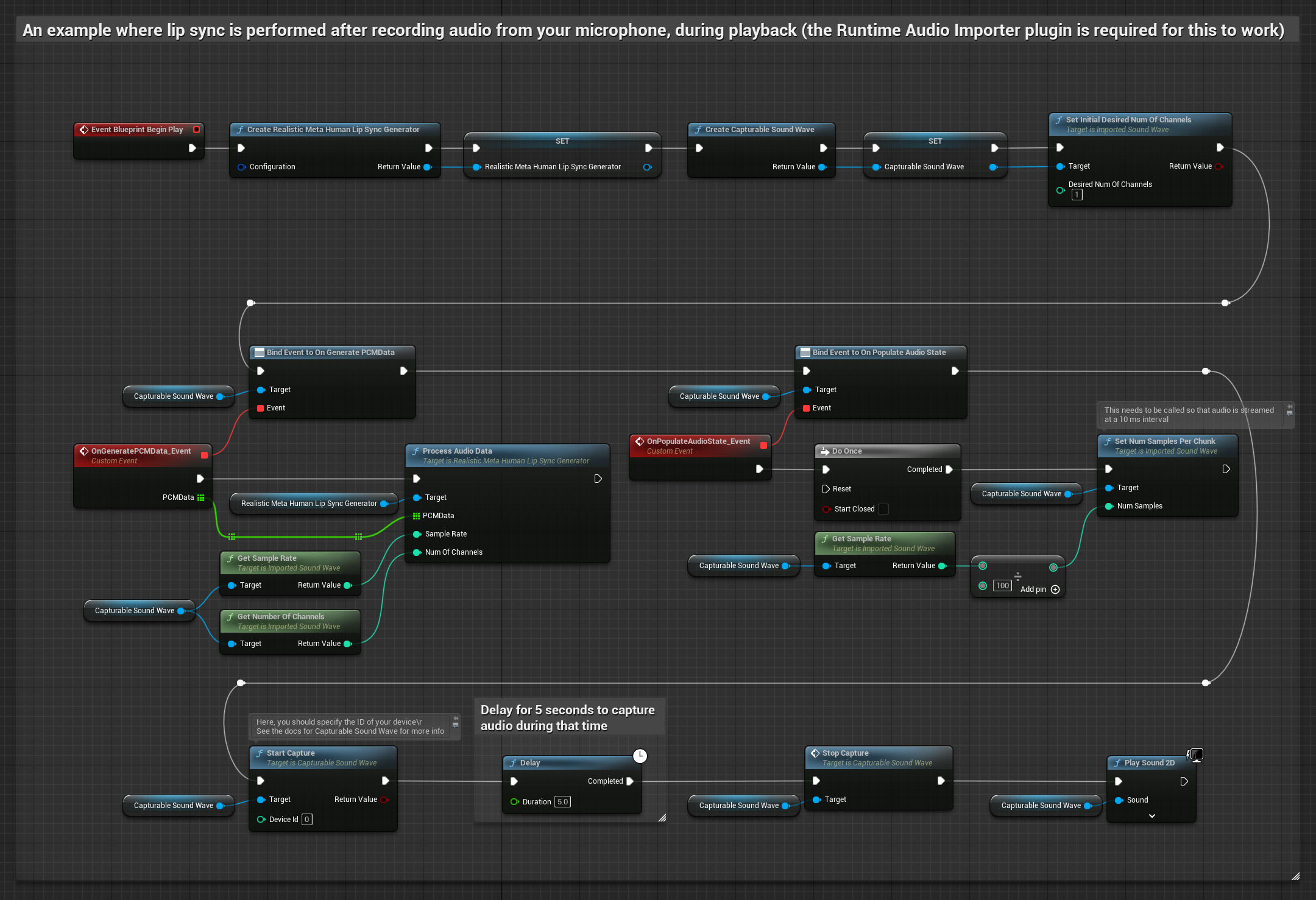
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
- 정기적인
- 스트리밍
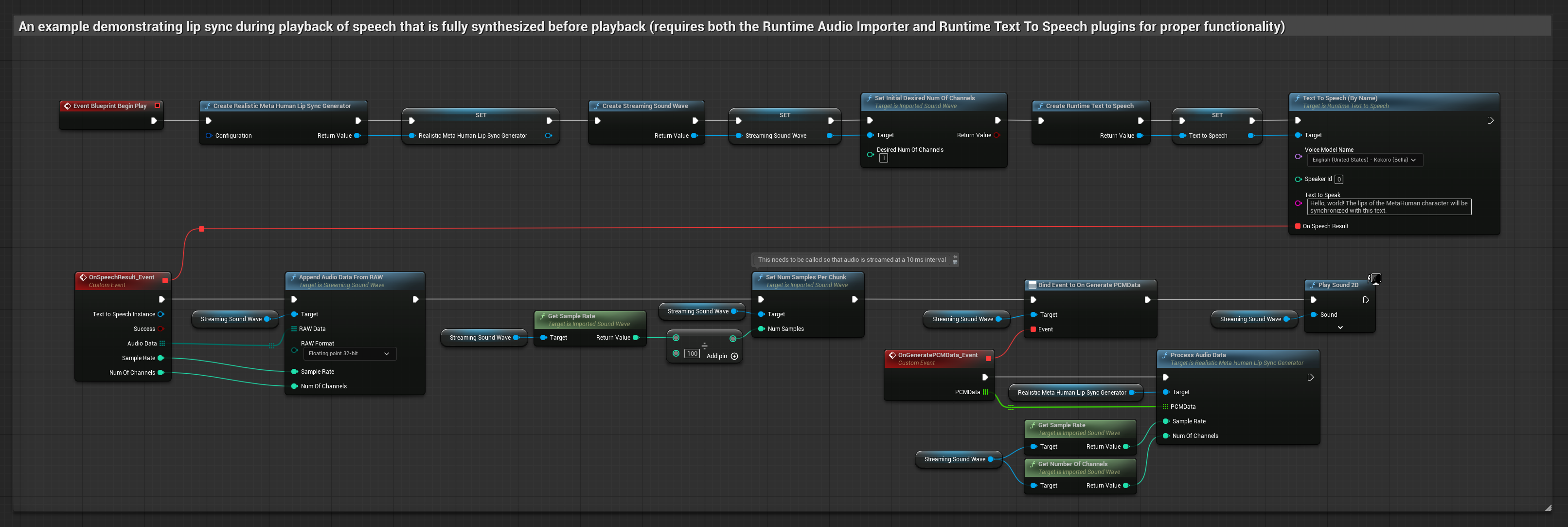
이 접근 방식은 로컬 TTS를 사용하여 텍스트에서 음성을 합성하고 립 싱크를 수행합니다.
- 표준 모델
- 현실적인 모델
- 감정 반영 현실적 모델
- Runtime Text To Speech를 사용하여 텍스트에서 음성을 생성합니다
- Runtime Audio Importer를 사용하여 합성된 오디오를 가져옵니다
- 가져온 사운드 웨이브를 재생하기 전에 해당
OnGeneratePCMData델리게이트에 바인딩합니다 - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData를 호출합니다
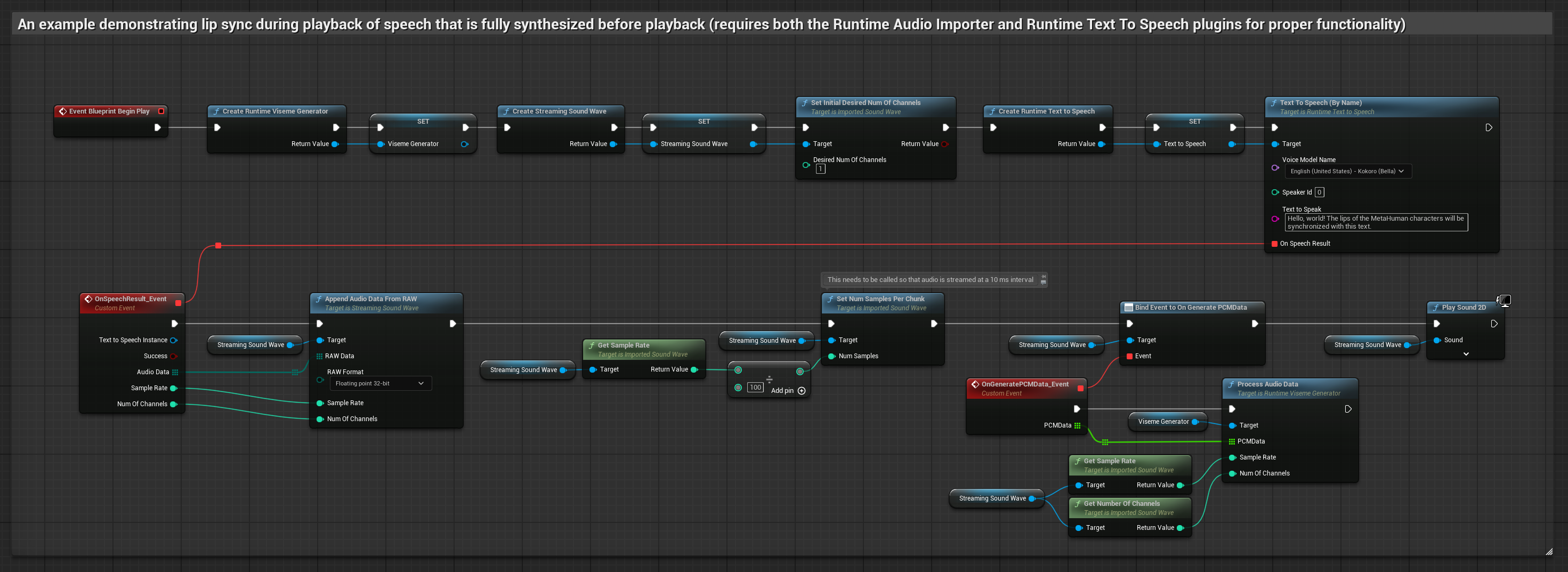
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
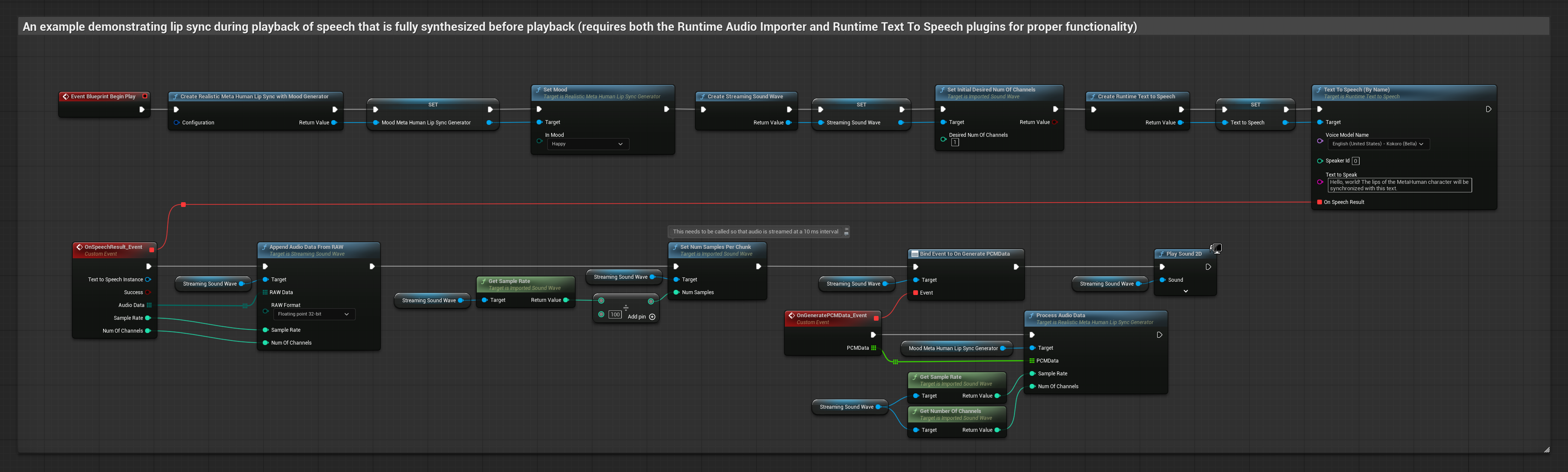
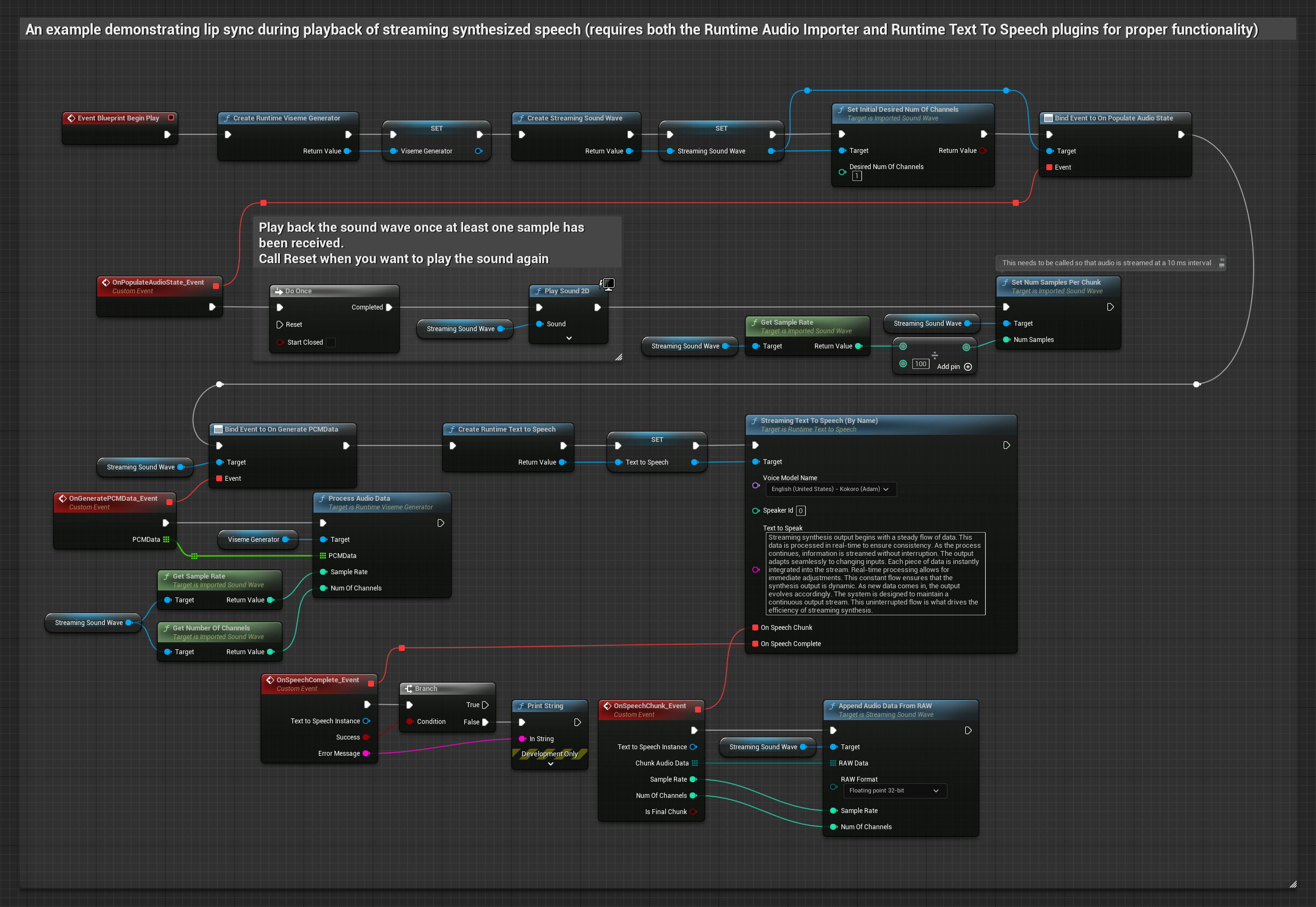
이 접근 방식은 실시간 립싱크와 함께 스트리밍 텍스트 음성 합성을 사용합니다.
- 표준 모델
- 현실적인 모델
- 감정 반영 사실적 모델
- Runtime Text To Speech를 사용하여 텍스트에서 스트리밍 음성을 생성합니다
- Runtime Audio Importer를 사용하여 합성된 오디오를 가져옵니다
- 스트리밍 사운드 웨이브를 재생하기 전에 해당
OnGeneratePCMData델리게이트에 바인딩합니다 - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData를 호출합니다
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
- 정기적인
- 스트리밍
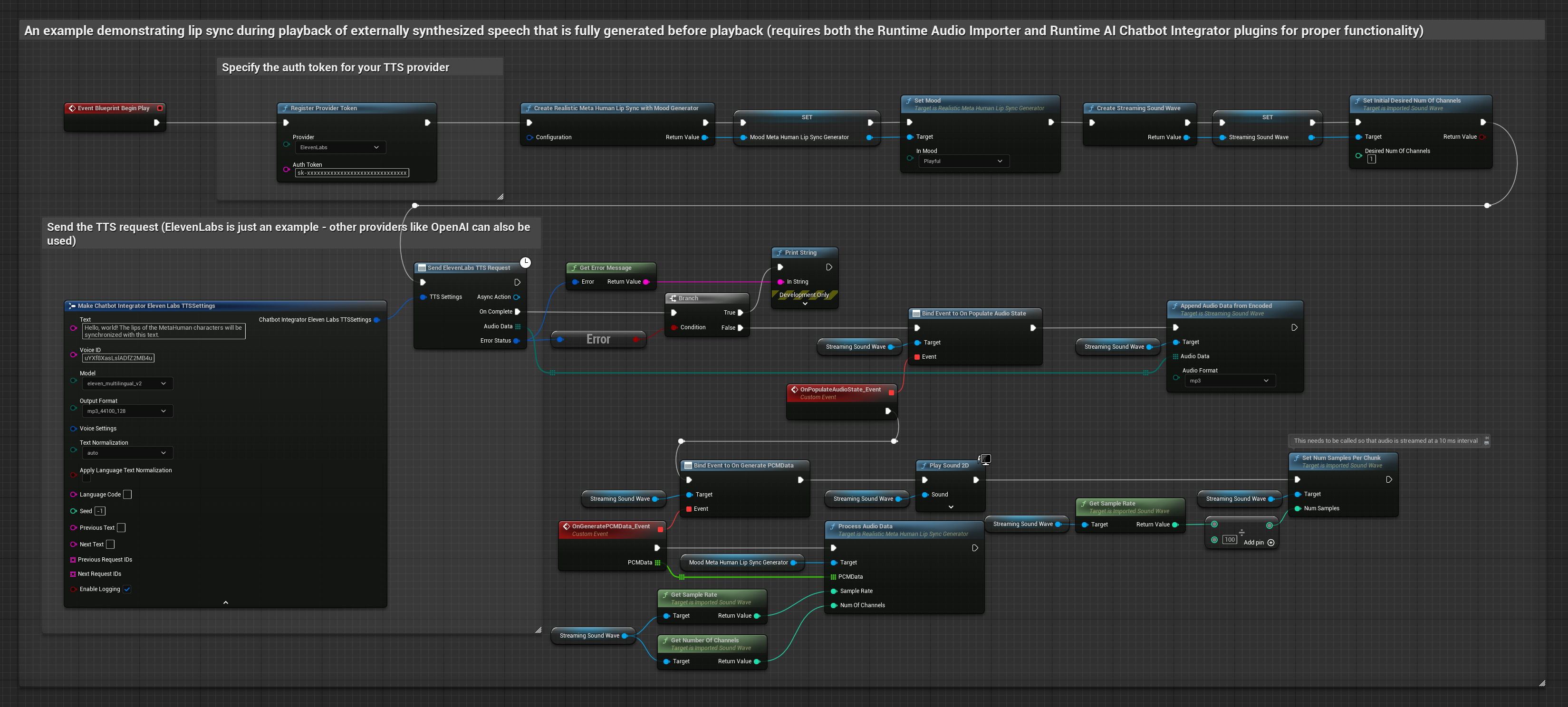
이 접근 방식은 Runtime AI Chatbot Integrator 플러그인을 사용하여 AI 서비스(OpenAI 또는 ElevenLabs)에서 합성된 음성을 생성하고 립 싱크를 수행합니다.
- 표준 모델
- 현실적인 모델
- 감정 반영 사실적 모델
- Runtime AI Chatbot Integrator를 사용하여 외부 API(OpenAI, ElevenLabs 등)를 통해 텍스트에서 음성을 생성합니다.
- Runtime Audio Importer를 사용하여 합성된 오디오 데이터를 가져옵니다.
- 가져온 사운드 웨이브를 재생하기 전에
OnGeneratePCMData델리게이트에 바인딩합니다. - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData를 호출합니다.
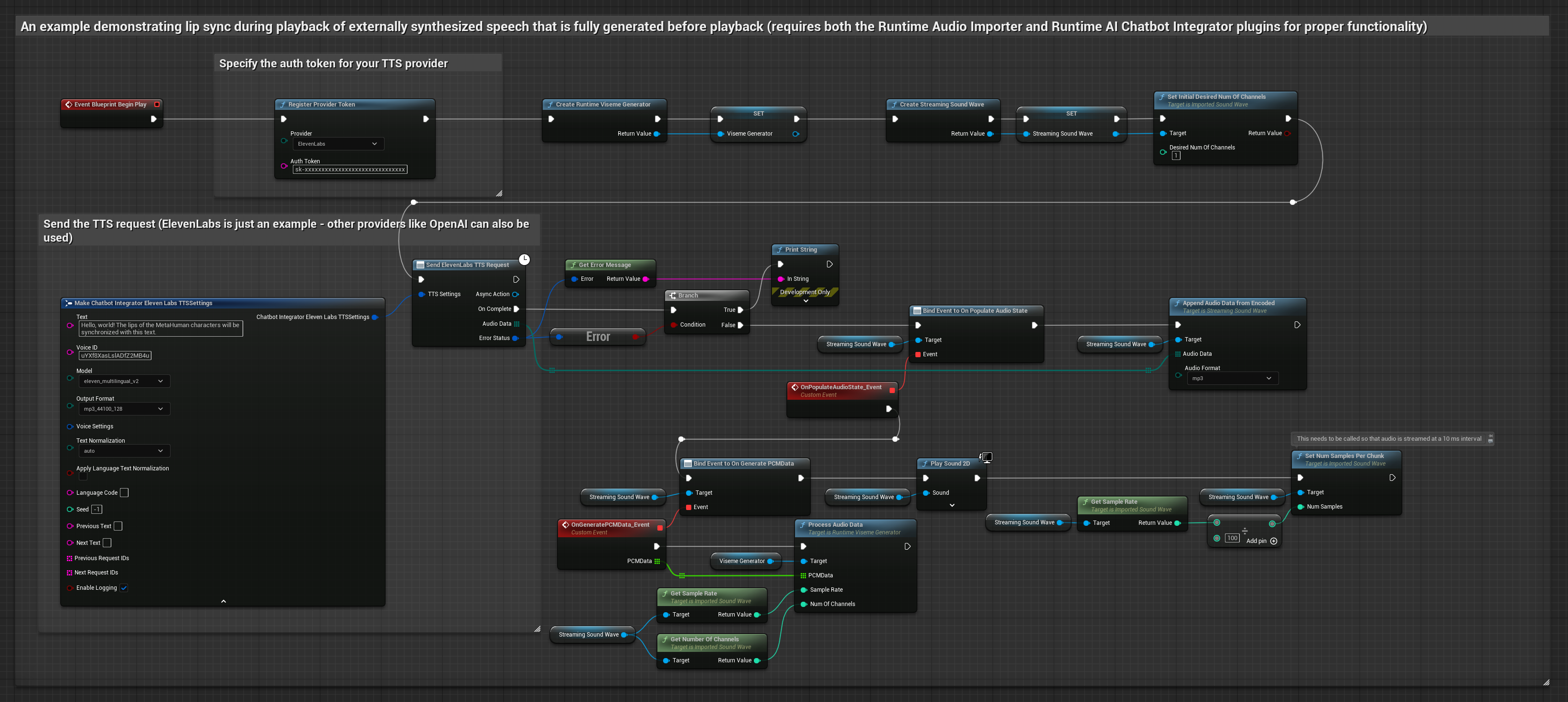
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
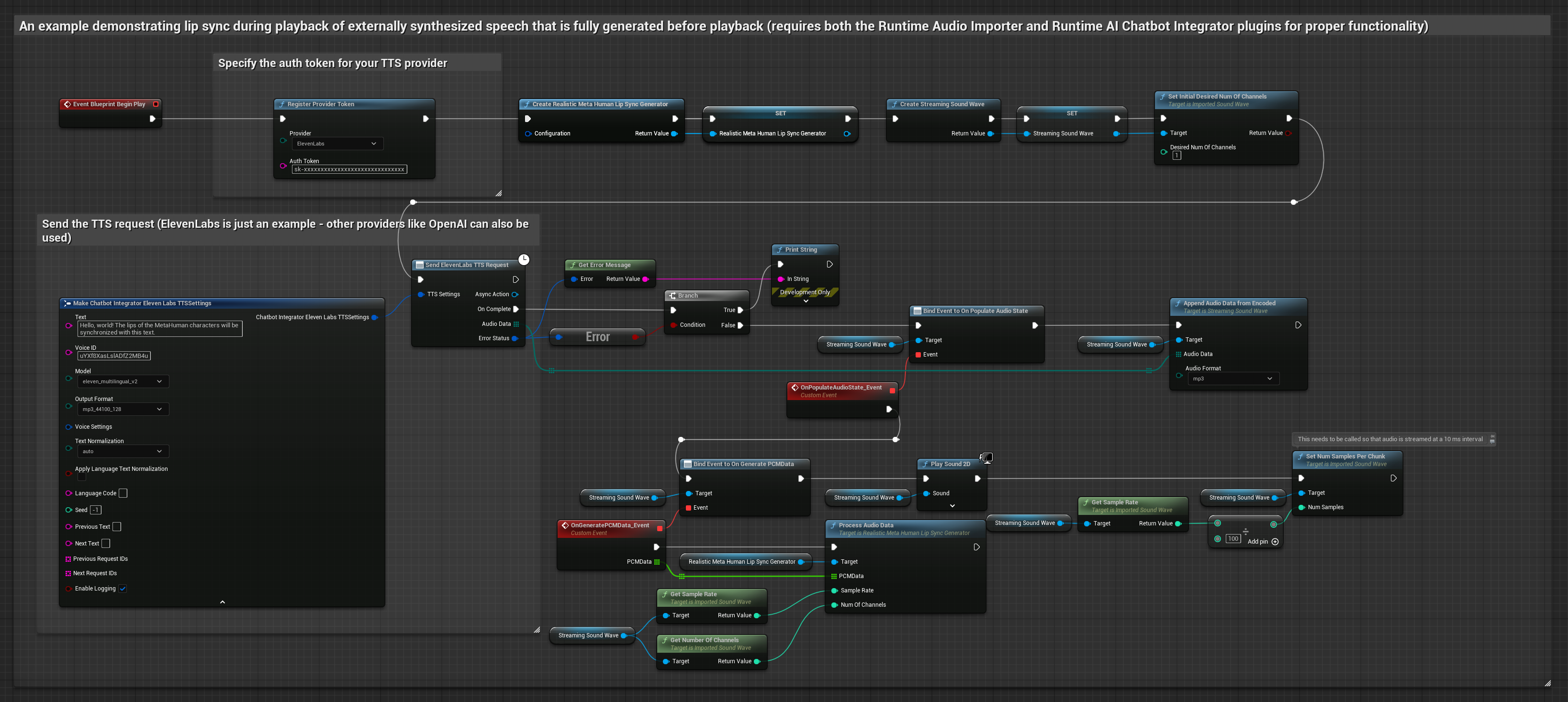
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
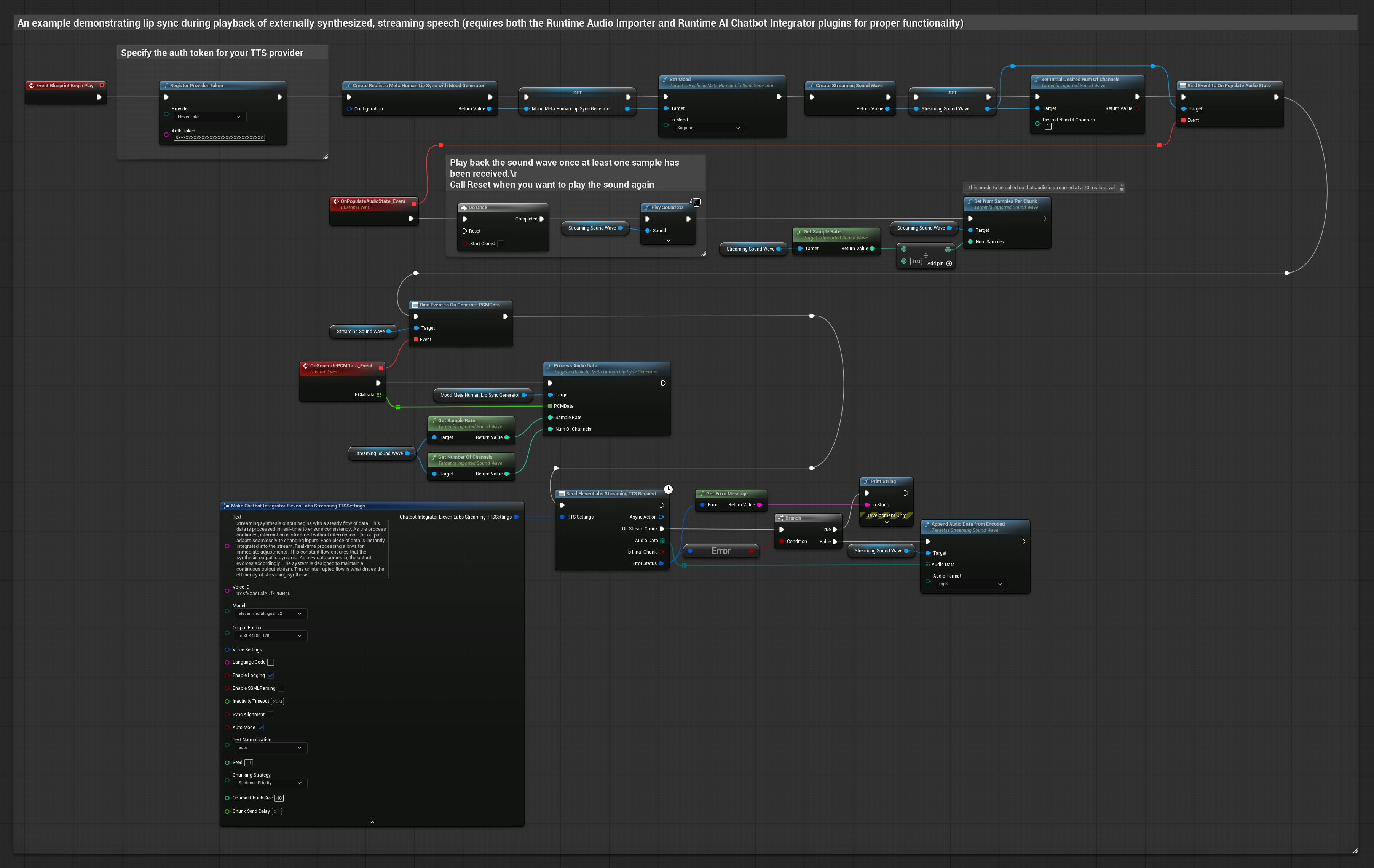
이 접근 방식은 Runtime AI Chatbot Integrator 플러그인을 사용하여 AI 서비스(OpenAI 또는 ElevenLabs)에서 합성된 스트리밍 음성을 생성하고 립 싱크를 수행합니다.
- 표준 모델
- 현실적인 모델
- 감정 반영 현실적 모델
- Runtime AI Chatbot Integrator를 사용하여 스트리밍 TTS API(예: ElevenLabs Streaming API)에 연결합니다.
- Runtime Audio Importer를 사용하여 합성된 오디오 데이터를 가져옵니다.
- 스트리밍 사운드 웨이브를 재생하기 전에
OnGeneratePCMData델리게이트에 바인딩합니다. - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData를 호출합니다.
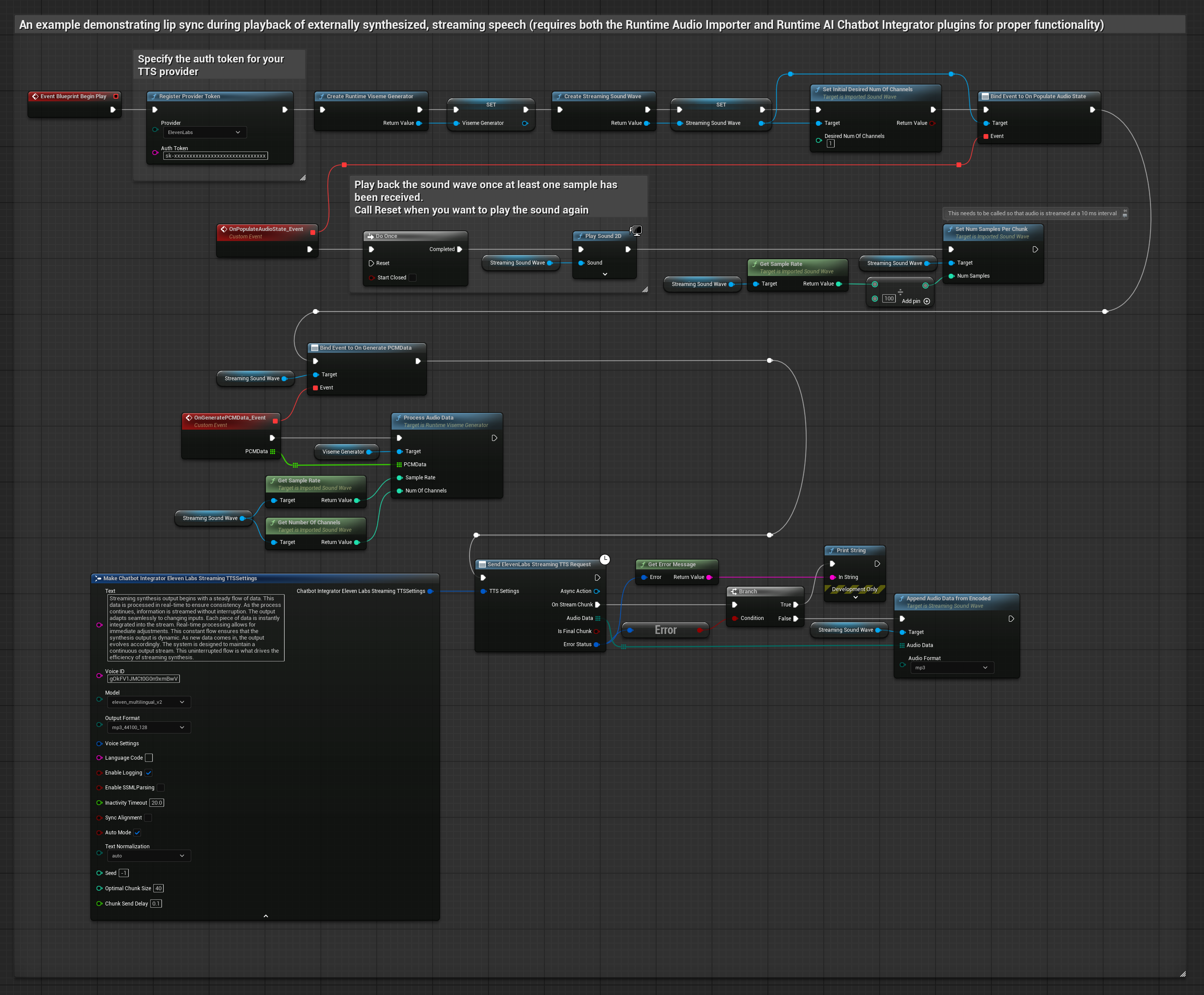
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
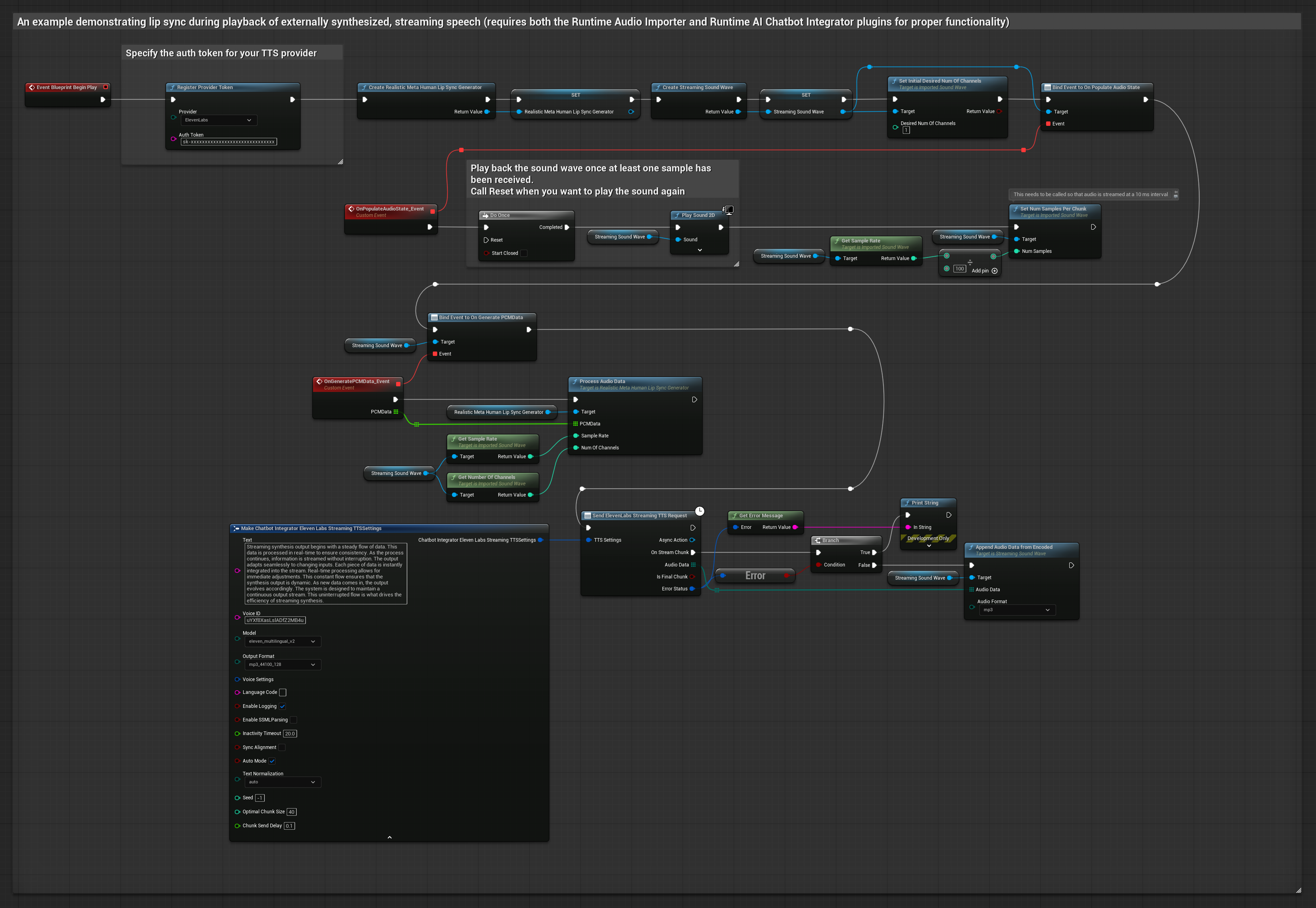
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
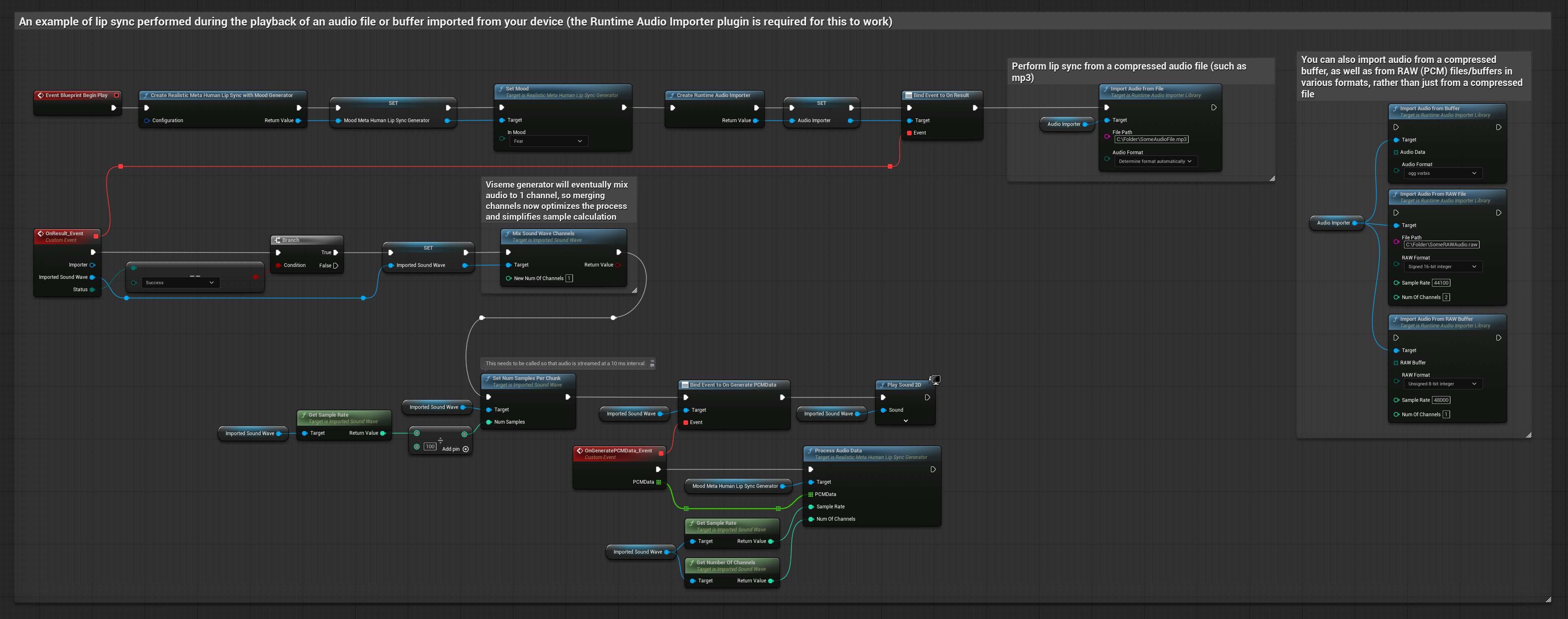
이 접근 방식은 립 싱크를 위해 사전 녹음된 오디오 파일이나 오디오 버퍼를 사용합니다.
- 표준 모델
- 현실적인 모델
- 감정 반영 사실적 모델
- Runtime Audio Importer를 사용하여 디스크나 메모리에서 오디오 파일을 가져옵니다
- 가져온 사운드 웨이브를 재생하기 전에 해당
OnGeneratePCMData델리게이트에 바인딩합니다 - 바인딩된 함수에서 Runtime Viseme Generator의
ProcessAudioData를 호출합니다 - 가져온 사운드 웨이브를 재생하고 립 싱크 애니메이션을 관찰합니다
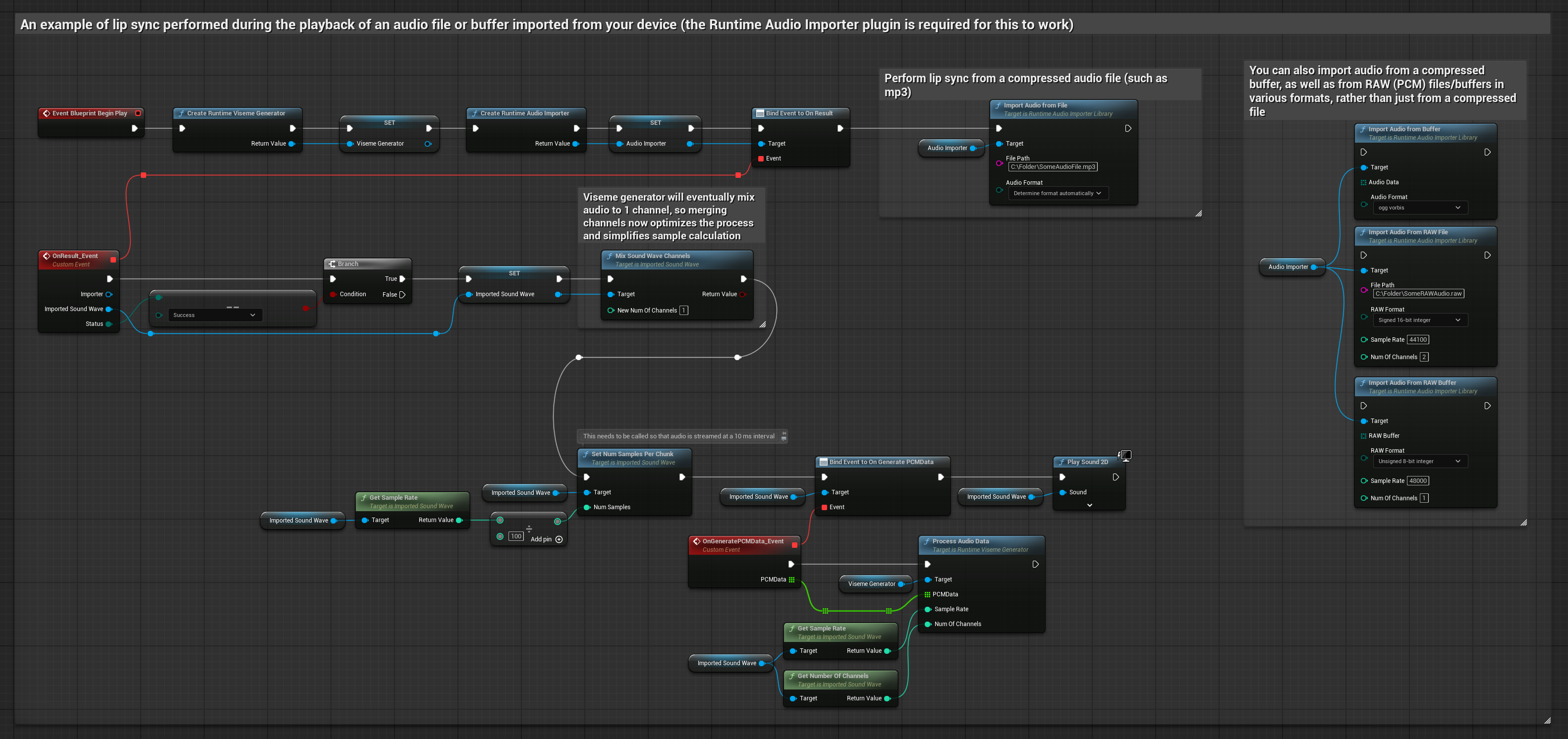
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.

분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
버퍼에서 오디오 데이터를 스트리밍하려면 다음이 필요합니다:
- 표준 모델
- 현실적인 모델
- 감정 반영 현실적 모델
- 스트리밍 소스에서 제공되는 float PCM 형식의 오디오 데이터(부동 소수점 샘플 배열) (또는 Runtime Audio Importer를 사용하여 더 많은 형식 지원)
- 샘플 레이트와 채널 수
- 오디오 청크가 준비될 때마다 이러한 매개변수를 사용하여 Runtime Viseme Generator에서
ProcessAudioData호출
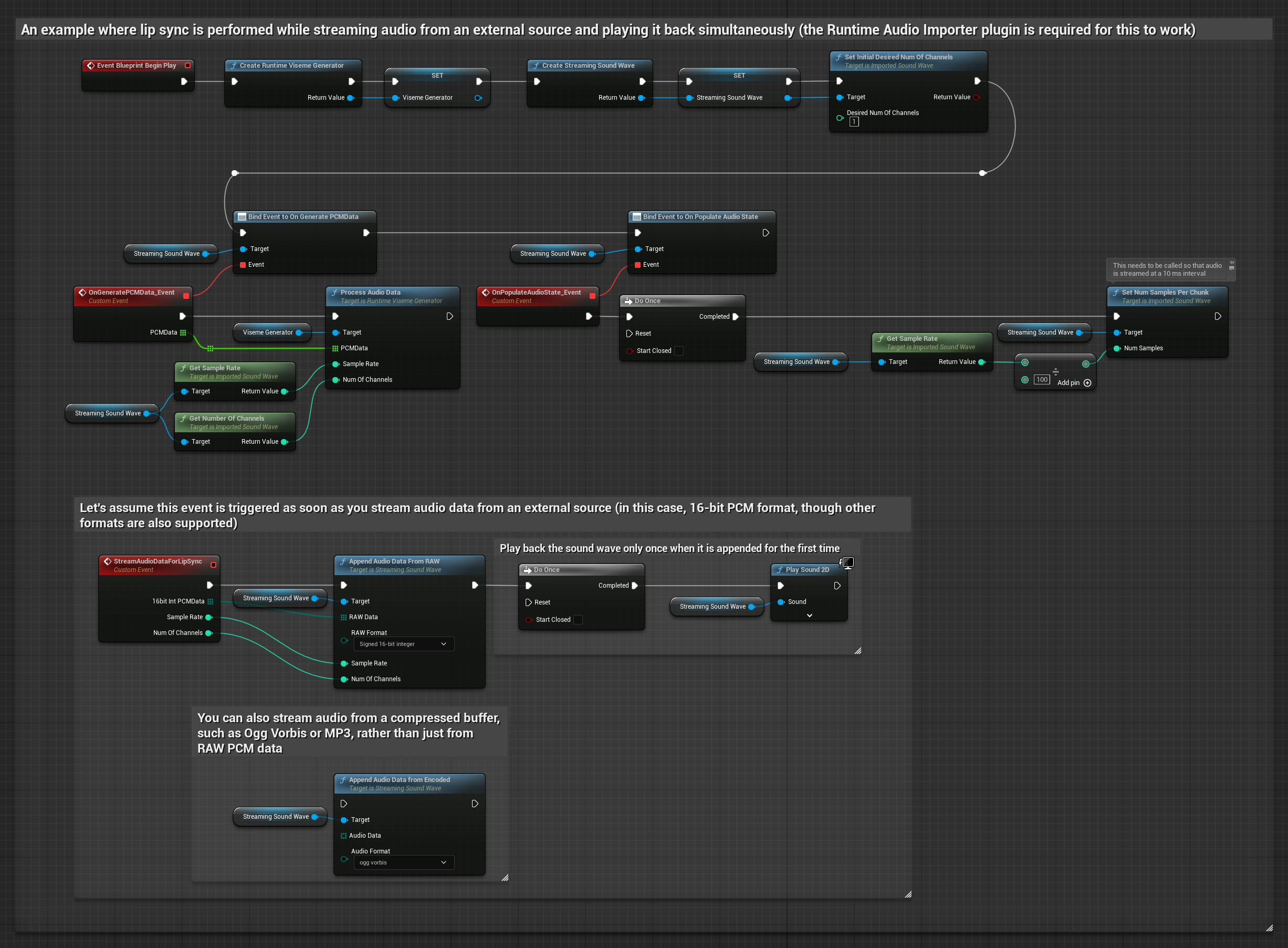
현실적인 모델은 표준 모델과 동일한 오디오 처리 워크플로우를 사용하지만, VisemeGenerator 대신 RealisticLipSyncGenerator 변수를 사용합니다.
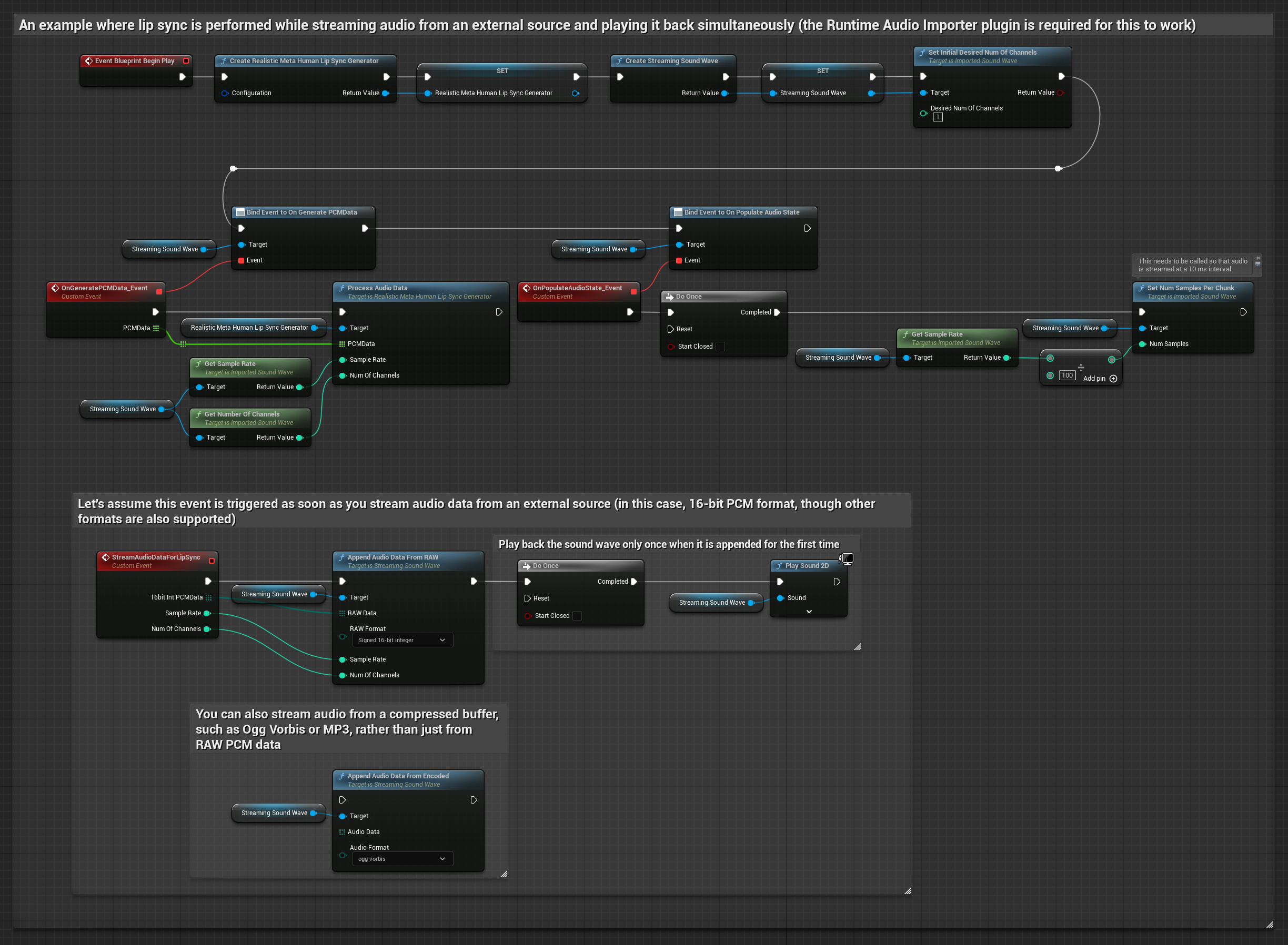
분위기 지원 모델은 동일한 오디오 처리 워크플로우를 사용하지만, MoodMetaHumanLipSyncGenerator 변수와 추가적인 분위기 설정 기능을 제공합니다.
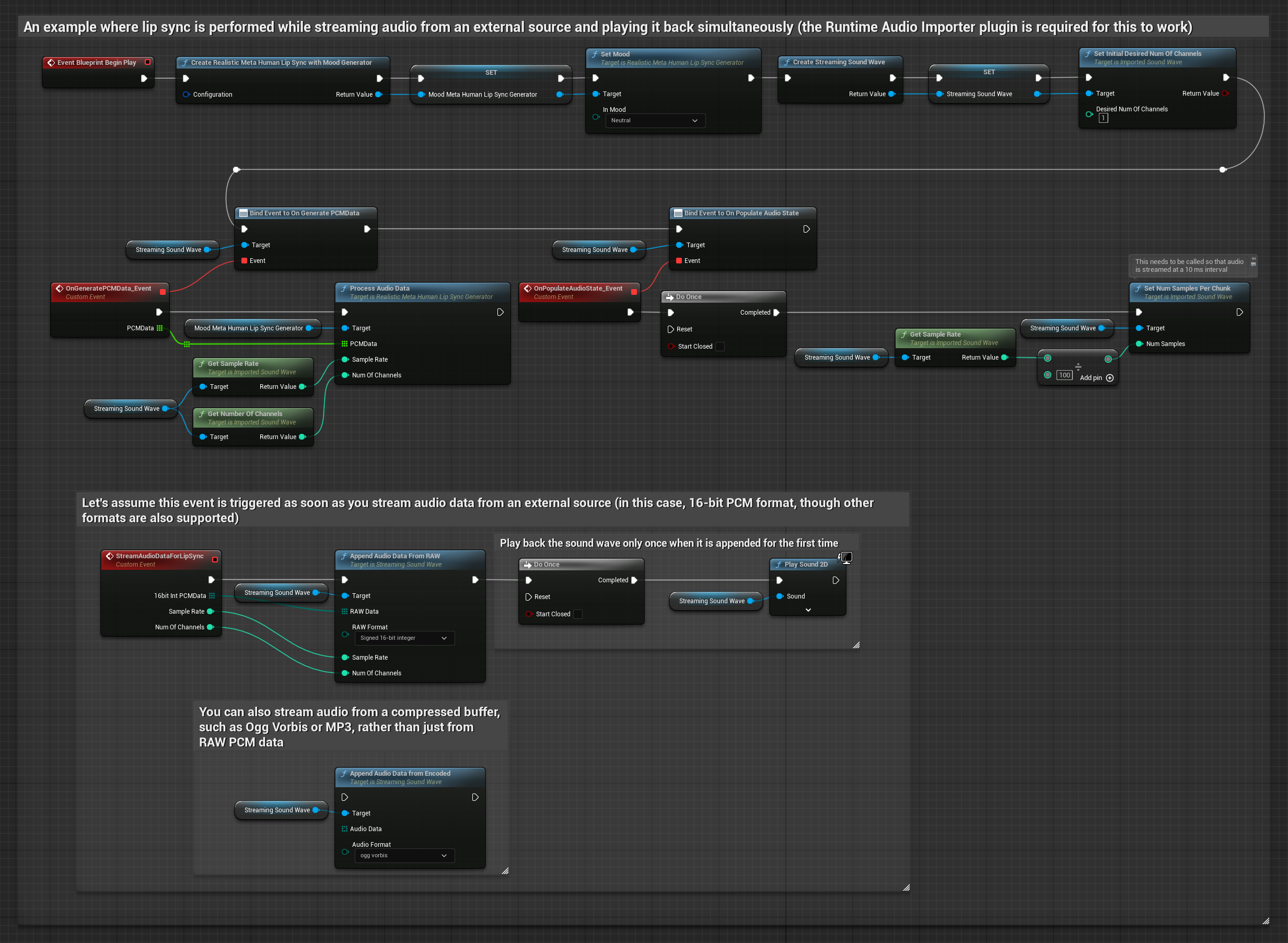
참고: 스트리밍 오디오 소스를 사용할 때는 왜곡된 재생을 방지하기 위해 오디오 재생 타이밍을 적절히 관리해야 합니다. 자세한 내용은 스트리밍 사운드 웨이브 문서를 참조하세요.
처리 성능 팁
-
청크 크기:
ProcessingChunkSize구성 옵션을 (예: 320, 480, 640 샘플로) 늘리면 품질이나 응답성에 미치는 영향은 최소화하면서 지연 시간을 눈에 띄게 개선할 수 있습니다. -
모델 유형: 리얼리스틱 모델을 사용할 때 고도로 최적화된 모델 유형(기본 선택)으로 전환하면 성능이 향상될 수 있습니다. 원본 모델이 특히 노이즈가 있는 오디오에서 약간 더 나은 품질을 제공할 수 있다는 점에 유의하세요.
-
버퍼 관리: 감정 지원 모델은 320-샘플 프레임(16kHz에서 20ms) 단위로 오디오를 처리합니다. 최적의 성능을 위해 오디오 입력 타이밍이 이에 맞춰져 있는지 확인하세요.
-
제너레이터 재생성: Realistic 모델에서 안정적인 작동을 위해, 비활성 기간 후 새로운 오디오 데이터를 입력하려면 매번 제너레이터를 재생성하세요. 설명은 문제 해결의 제너레이터 재생성을 참조하십시오.
다음 단계
오디오 처리를 설정한 후에는 다음을 수행할 수 있습니다: