데모 프로젝트
Runtime MetaHuman Lip Sync을 빠르게 시작할 수 있도록 두 가지 즉시 사용 가능한 데모 프로젝트가 제공됩니다. 두 프로젝트 모두 **Unreal Engine 5.6+**로 제작되었으며, Blueprint 전용이고 Windows, Mac, Linux, iOS, Android 및 Android 기반 플랫폼(Meta Quest 포함)에서 크로스 플랫폼으로 실행됩니다.
사용 가능한 데모 프로젝트
- AI 대화형 NPC / 인터랙티브 아바타
- 기본 립 싱크 데모
완전한 AI 대화형 아바타 워크플로우로, 음성 인식, AI 챗봇(LLM), 텍스트 음성 변환, 오디오 재생 및 실시간 립 싱크를 하나의 프로젝트에서 모두 결합합니다. 게임, 대화형 키오스크, 가상 프로덕션, 박물관 설치물, 디지털 어시스턴트, 훈련 시뮬레이션 등 다양한 사용 사례에 적합합니다.
파이프라인 개요
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
동영상
빠른 미리보기 (~30초)
데모가 작동하는 모습을 간략히 보여줍니다.
전체 워크스루
설정, 구성 및 전체 대화 파이프라인을 다루는 상세한 안내서입니다.
다운로드
필수 및 선택 플러그인
데모 프로젝트는 모듈식으로 구성되어 있습니다. 사용하려는 제공업체의 플러그인만 있으면 됩니다.
| 플러그인 | 목적 | 필수인가요? |
|---|---|---|
| Runtime MetaHuman Lip Sync | 립싱크 애니메이션 | ✅ 항상 |
| Runtime Audio Importer | 오디오 캡처 및 처리 | ✅ 항상 |
| Runtime Speech Recognizer | 오프라인 음성 인식 (whisper.cpp) | ✅ 항상 |
| Runtime AI Chatbot Integrator | 외부 LLM(OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) 및/또는 외부 TTS(OpenAI, ElevenLabs) | 🔶 선택 사항 |
| Runtime Local LLM | llama.cpp를 통한 로컬 LLM 추론 (Llama, Mistral, Gemma 등 GGUF 모델) | 🔶 선택 사항 |
| Runtime Text To Speech | Piper 및 Kokoro를 통한 로컬 TTS | 🔶 선택 사항 |
위에 나열된 각 플러그인은 개별적으로 선택 사항이지만, 데모가 작동하려면 최소 하나의 LLM 제공자와 최소 하나의 TTS 제공자가 필요합니다. 자유롭게 조합하여 사용하세요(예: 로컬 LLM + ElevenLabs TTS, 또는 OpenAI LLM + 로컬 TTS).
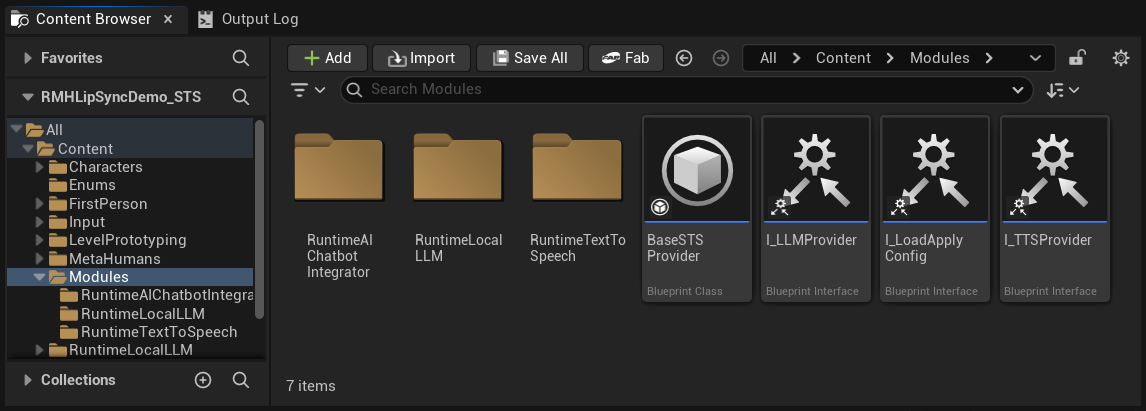
모듈형 아키텍처
Content 폴더 안에 Modules 폴더가 있으며, 이 폴더에는 세 개의 하위 폴더가 포함되어 있습니다:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
만약 선택적 플러그인 중 하나(또는 여러 개)를 획득하지 않았다면, 해당 폴더를 삭제하기만 하면 됩니다. 데모 프로젝트의 기본 에셋(게임 인스턴스, 위젯 등)은 이러한 모듈을 직접 참조하지 않으므로, 삭제해도 에셋 참조 오류가 발생하지 않습니다. 설정 UI는 폴더가 누락된 제공자를 자동으로 숨깁니다.
이러한 모듈성은 LLM 및 TTS 제공업체에만 적용됩니다. 음성 인식(Runtime Speech Recognizer)과 립 싱크(Runtime MetaHuman Lip Sync)는 기본 데모 프로젝트의 일부이며 항상 필요합니다.
최초 실행 시, 언리얼 엔진이 누락된 선택적 플러그인을 비활성화할지 묻는 메시지가 나타날 수 있습니다. 예를 클릭하세요. 또한 해당하는 Content/Modules/ 폴더를 삭제했는지 확인하세요(위 참조).
데모 프로젝트 레이아웃
아래에 표시된 사용자 인터페이스는 전적으로 UMG(Unreal Motion Graphics)로 제작되었으며, 순수하게 파이프라인(음성 인식 → LLM → TTS → 립 싱크)을 시연하기 위한 목적입니다. 프로젝트의 비주얼 디자인, 제어 방식 또는 플랫폼(VR/AR, 모바일, 콘솔, 키오스크 등)에 맞게 스타일을 변경하거나 교체하셔도 됩니다. 특정 위젯이 사용 사례에 필요하지 않은 경우, 간단히 숨길 수도 있습니다(예: 가시성을 Collapsed 또는 Hidden으로 설정).

| Area | 무엇이 있나요? |
|---|---|
| 가운데 | 메타휴먼 캐릭터. |
| 왼쪽 | 네 가지 설정 버튼(음성 인식, AI 챗봇, 텍스트 음성 변환, 애니메이션)에 대한 자세한 설명은 아래와 같습니다. |
| 중앙 하단 | 녹음 시작 버튼. 클릭하면 음성 대화가 시작됩니다. 마이크가 입력을 받아 텍스트로 변환되고, LLM으로 전송되며, 응답이 TTS를 통해 합성되어 립 싱크와 함께 재생됩니다. 완전히 핸즈프리로 작동합니다. |
| 오른쪽 중앙 | 대화 기록 위젯은 사용자와 AI 간의 전체 주고받음(사용자 및 어시스턴트 메시지 모두)을 표시합니다. 또한 텍스트 입력 필드가 포함되어 있어 음성 인식을 사용하지 않고도 직접 메시지를 입력할 수 있으며, 이는 테스트, 접근성 향상, 또는 마이크를 사용할 수 없는 상황에서 유용합니다. |
동일한 세션에서 두 입력 모드를 자유롭게 혼합할 수 있습니다. 일부 메시지는 말하고, 다른 메시지는 입력하세요.
설정 버튼
왼쪽에 있는 네 개의 구성 버튼은 파이프라인의 각 부분에 대한 전용 패널을 엽니다.
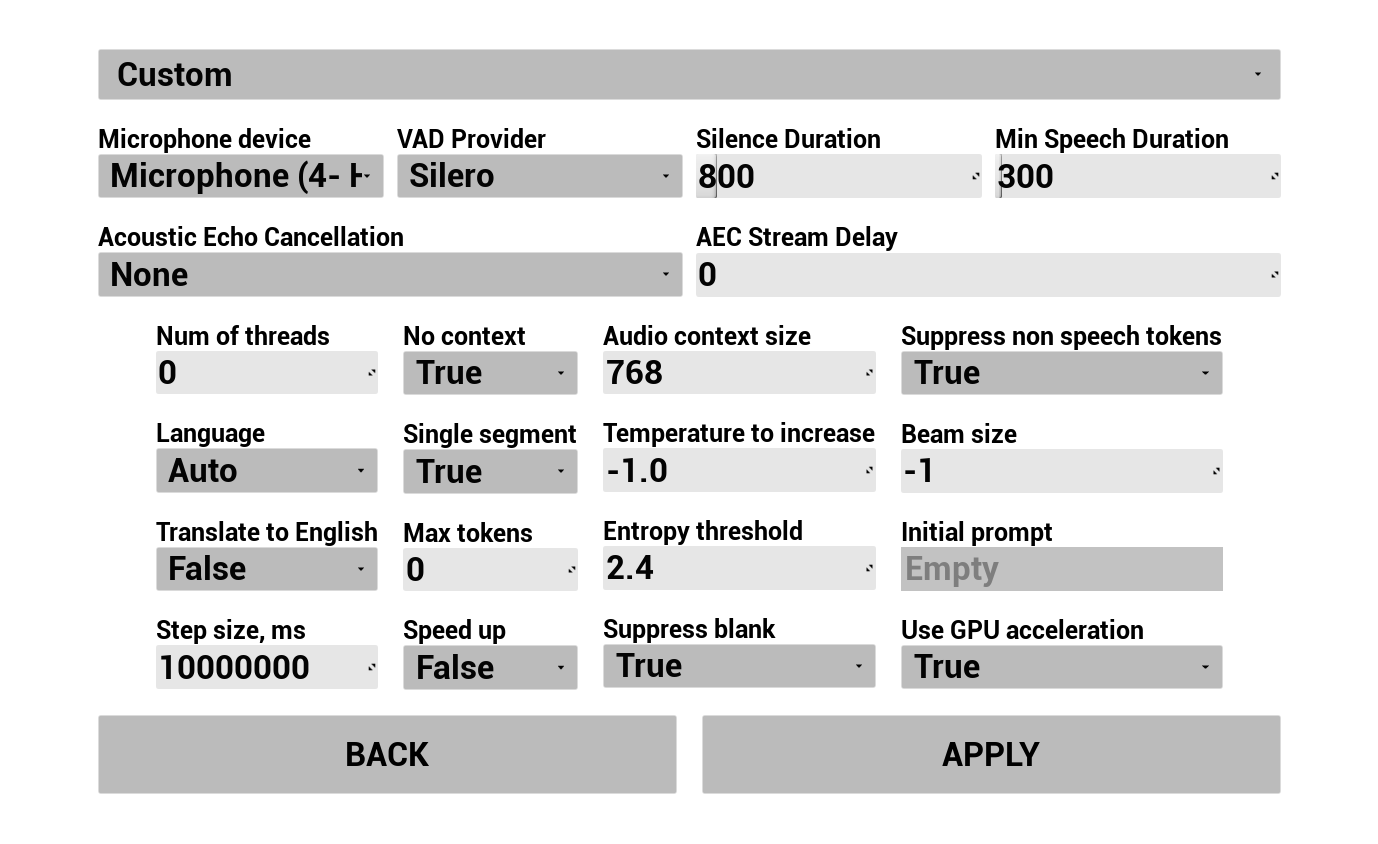
1. 음성 인식 구성
사용자의 음성이 캡처되고 텍스트로 변환되는 방식을 구성합니다:
- 언어 선택
- 음성 인식 매개변수 조정 (Whisper 모델 설정)
- AEC(음향 반향 제거) 구성
- VAD(음성 활동 감지) 구성
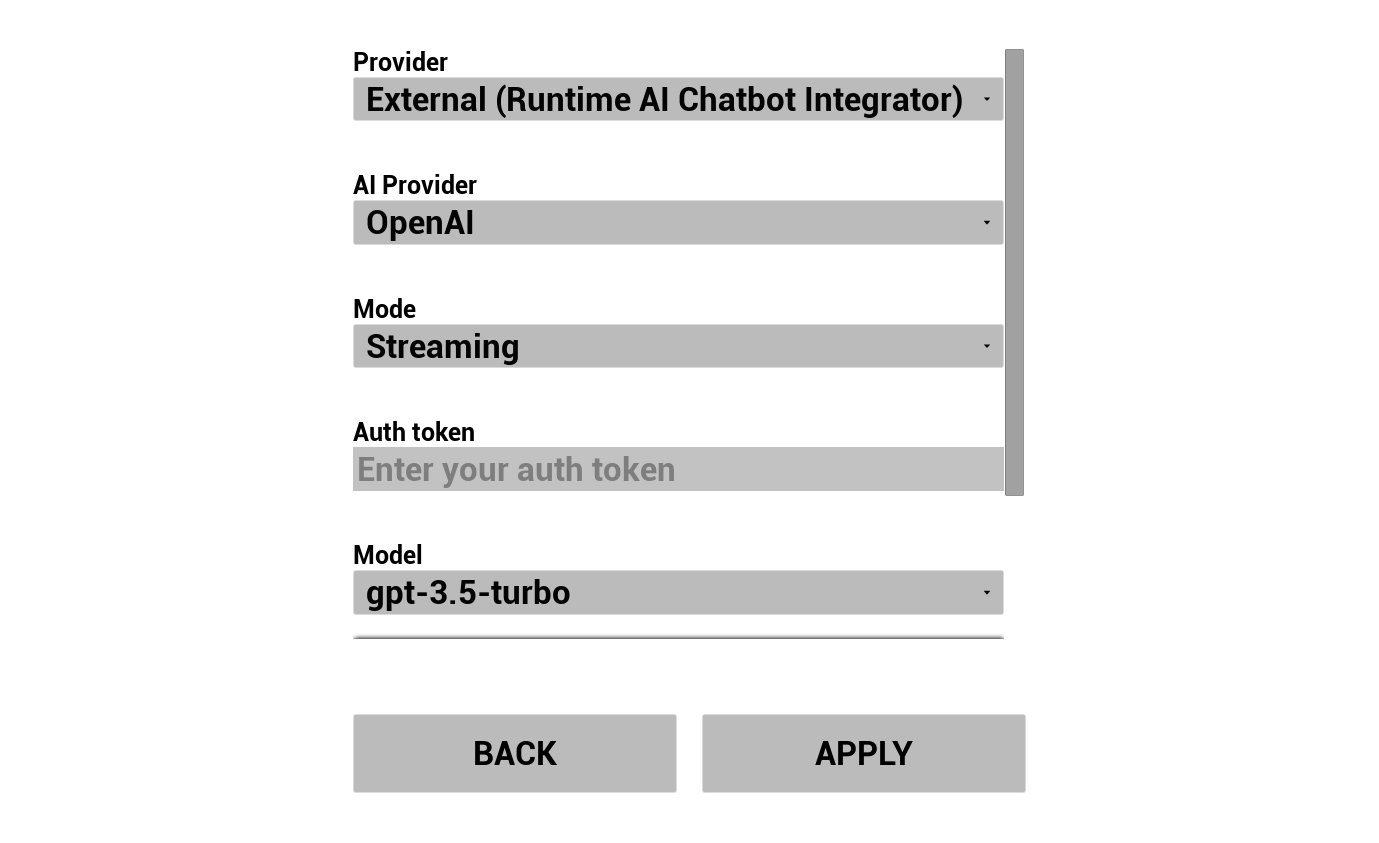
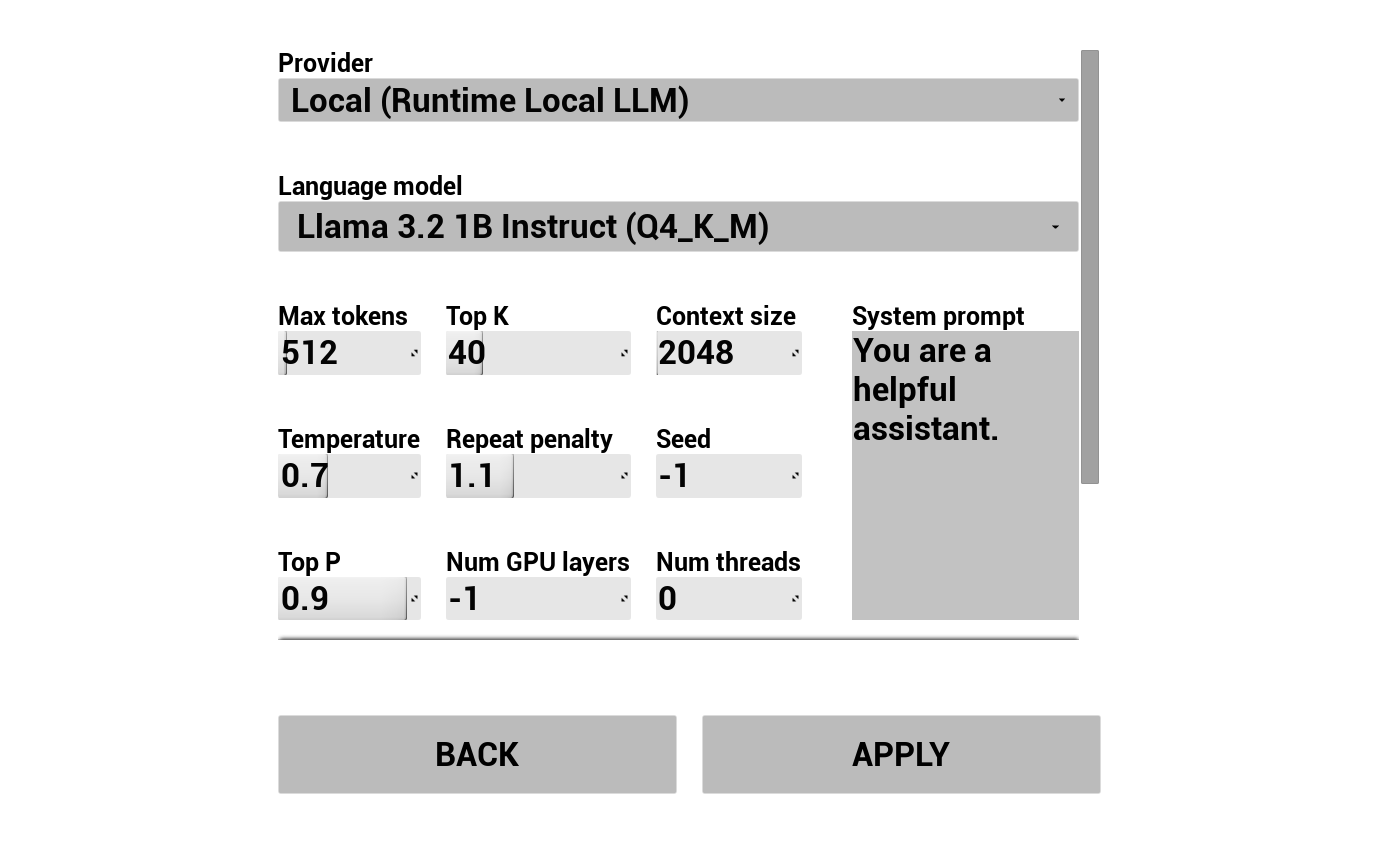
2. AI 챗봇 구성
LLM 제공자를 선택하고 구성하세요:
- 제공자 선택 (Runtime AI Chatbot Integrator 또는 Runtime Local LLM)
- 외부 제공자의 경우: 인증 토큰, 모델 이름 등
- 로컬 LLM의 경우: GGUF 모델 선택, 컨텍스트 크기 및 기타 추론 매개변수 설정. 또한 데모에서 직접 런타임에 자신의 GGUF 모델을 다운로드(예: URL로)하여 프로젝트를 다시 빌드하지 않고 즉시 사용할 수 있습니다.
공급자 콤보박스는 Content/Modules/에 플러그인 모듈 폴더가 있는 공급자만 표시합니다.
3. 텍스트 음성 변환 구성
TTS 제공업체를 선택하고 음성/모델을 구성하세요:
- 제공자 선택 (OpenAI/ElevenLabs용 Runtime AI Chatbot Integrator 또는 로컬 Piper/Kokoro용 Runtime Text To Speech)
- 음성/모델 선택
- 제공자별 매개변수 조정

4. 애니메이션 구성
AI 아바타의 시각적 요소를 제어하세요:
- 사전 다운로드된 3개의 메타휴먼 캐릭터(Aera, Ada, Orlando) 중에서 선택하세요
- 립 싱크 모델(표준 또는 현실적)을 선택하세요
- 립 싱크 모델 유형을 선택하세요 - 고도로 최적화, 반 최적화 또는 원본 (모델 유형 참조)
- 처리 청크 크기를 조정하세요 - 립 싱크 추론이 실행되는 빈도를 제어합니다 (처리 청크 크기 참조)
- 대화 중 메타휴먼이 재생할 대기 애니메이션을 선택하세요

편집기에서 데모 사전 구성하기
소스 버전으로 작업할 때, 편집기에서 기본값을 미리 채워넣어 매번 실행할 때마다 값을 다시 입력할 필요가 없습니다:
| What | 어디 |
|---|---|
| 일반 설정 (립 싱크 모델, 대기 애니메이션, 캐릭터 클래스, 음성 인식 등) | Content/LipSyncSTSGameInstance |
| 외부 LLM / 외부 TTS 설정 (Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| 로컬 LLM 설정 (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| 로컬 TTS 설정 (런타임 텍스트 음성 변환) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
크로스 플랫폼 참고 사항
데모에서 사용된 모든 플러그인은 Windows, Mac, Linux, iOS, Android 및 Android 기반 플랫폼(Meta Quest 포함)을 지원하므로, 데모 프로젝트도 이 모든 환경에서 작동합니다. 따라서 게임, 데스크톱 키오스크, 모바일 앱, 독립형 VR 헤드셋, 현장 가상 프로덕션 설정 등 다양한 환경에 배포하기 적합합니다.
약한 기기(모바일, 독립형 VR)의 경우 다음을 고려할 수 있습니다:
- 표준 립싱크 모델을 사실적인 모델 대신 사용하세요 - 모델 비교를 참조하세요.
- 고도로 최적화된 모델 유형으로 전환하세요.
- CPU 부하를 줄이기 위해 처리 청크 크기를 늘리세요.
- 더 작은 LLM / TTS 모델을 선택하세요.
플랫폼별 구성을 참조하여 Android, iOS, Mac 및 Linux에서 추가 설정 단계를 확인하세요.
픽셀 스트리밍 지원
Pixel Streaming에 데모 배포하기 (클릭하여 펼치기)
AI 대화형 데모 프로젝트는 Pixel Streaming 환경에서도 작동하여, MetaHuman 아바타를 원격 클라이언트(예: 웹 브라우저)로 스트리밍하면서 클라이언트 측에서 사용자의 마이크 오디오를 캡처할 수 있습니다. 데모에는 단 한 가지 변경만 필요합니다.
1. Runtime Audio Importer용 Pixel Streaming 확장 프로그램을 설치하세요.
Runtime Audio Importer 플러그인은 Pixel Streaming 클라이언트에서 오디오를 캡처할 수 있는 무료 확장 플러그인을 제공합니다. 사용 중인 Pixel Streaming 인프라 버전에 따라 다음 중 하나를 설치하세요:
- Pixel Streaming 확장 (원본 Pixel Streaming 플러그인) 또는
- Pixel Streaming 2 확장 (최신 Pixel Streaming 2 플러그인)
다운로드 링크 및 설치 단계는 여기에서 확인할 수 있습니다: Pixel Streaming Audio Capture - 확장 플러그인 설치.
2. LipSyncSTSGameInstance에서 캡처 가능한 사운드 웨이브 노드를 교체하세요.
확장 플러그인이 설치된 후:
- 콘텐츠 브라우저에서
/All/Game으로 이동한 후LipSyncSTSGameInstance에셋을 엽니다. - 이벤트 그래프로 전환합니다.
- Event Init을 찾아 실행 흐름을 따라가다 보면
Create Capturable Sound Wave→Set Capturable Sound Wave노드 쌍을 발견할 수 있습니다. Create Capturable Sound Wave호출을 대상으로 하는 Pixel Streaming 인프라 버전에 따라Create Pixel Streaming Capturable Sound Wave또는Create Pixel Streaming 2 Capturable Sound Wave로 교체합니다.- 해당 출력을 동일한
Set Capturable Sound Wave노드에 연결합니다.
이후, 프로젝트는 Pixel Streaming에 배포할 준비가 완료됩니다. 음성 인식, LLM, TTS 및 립 싱크는 모두 이전과 동일하게 작동하지만, 로컬 마이크 대신 원격 클라이언트에서 오디오를 캡처합니다.
자체 캐릭터 가져오기
데모 프로젝트에는 세 개의 샘플 메타휴먼 캐릭터(Aera, Ada, Orlando)가 포함되어 있지만, 자신의 메타휴먼을 가져와 데모에서 사용할 수도 있습니다.
📺 동영상 튜토리얼: 데모 프로젝트에 커스텀 메타휴먼 캐릭터 추가하기
Runtime MetaHuman Lip Sync 플러그인 자체는 메타휴먼 외에도 많은 다른 캐릭터 시스템(ARKit 기반 캐릭터, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe 등 - 커스텀 캐릭터 설정 가이드 참조)을 지원합니다. 게임 NPC, 가상 프레젠터, 키오스크 안내원, 또는 가상 프로덕션용 디지털 휴먼을 제작하든, 이 플러그인은 사용자의 캐릭터 파이프라인에 맞게 조정됩니다.
AI 대화 워크플로우 없이 립 싱크 기능 자체에만 집중한 더 간단한 데모 프로젝트입니다. 다양한 오디오 소스로 립 싱크가 어떻게 작동하는지 확인하고 싶다면 적합합니다.
추천 동영상
다운로드
포함된 내용
이 데모는 기본적인 립 싱크 워크플로우를 보여줍니다:
- 마이크 입력 - 실시간 오디오에서 립 싱크
- 오디오 파일 재생 - 가져온 오디오 파일에서 립 싱크
- 텍스트 음성 변환 - 합성된 음성으로 구동되는 립 싱크
필수 및 선택 플러그인
| 플러그인 | 목적 | 필수인가요? |
|---|---|---|
| Runtime MetaHuman Lip Sync | 립 싱크 애니메이션 | ✅ 필수 |
| Runtime Audio Importer | 오디오 가져오기 및 캡처 | ✅ 필수 |
| Runtime Text To Speech | TTS 데모 씬을 위한 로컬 TTS | 🔶 선택 사항 |
| Runtime AI Chatbot Integrator | 외부 TTS 제공업체 (OpenAI, ElevenLabs) | 🔶 선택 사항 |
표준 립 싱크 모델에 대한 참고 사항
데모 프로젝트에서 리얼리스틱 대신 표준 모델을 사용하려면 표준 립 싱크 확장 플러그인을 설치해야 합니다. 설치 방법은 표준 모델 확장을 참조하세요.
도움이 필요하신가요?
데모 프로젝트 설정이나 실행 중 문제가 발생하면 언제든지 문의해 주세요.
맞춤 개발 요청(예: 데모에 자체 로직 추가, 특정 플랫폼 또는 캐릭터 파이프라인에 맞게 조정)이 있는 경우 [email protected]로 문의하세요.