플러그인 설정
모델 구성
안정적인 작동을 위해 사실적 및 감정 지원 사실적 모델을 사용할 때는 긴 침묵 동안 하나의 생성기를 재사용하지 말고, 각 새로운 오디오 재생 전에 생성기를 다시 생성하세요. 자세한 내용은 문제 해결의 생성기 재생성을 참조하십시오.
표준 모델 구성
Create Runtime Viseme Generator 노드는 대부분의 시나리오에서 잘 작동하는 기본 설정을 사용합니다. 구성은 애니메이션 블루프린트 블렌딩 노드 속성을 통해 처리됩니다.
애니메이션 블루프린트 구성 옵션에 대한 자세한 내용은 아래 립 싱크 구성 섹션을 참조하세요.
현실적인 모델 구성
Create Realistic MetaHuman Lip Sync Generator 노드는 생성기의 동작을 사용자 정의할 수 있는 선택적 Configuration 매개변수를 허용합니다:
모델 유형
모델 유형 설정은 사용할 사실적인 모델의 버전을 결정합니다.
| 모델 유형 | 성능 | 시각적 품질 | 잡음 처리 | 권장 사용 사례 |
|---|---|---|---|---|
| 고도로 최적화됨 (기본값) | 최고 성능, 최저 CPU 사용량 | 좋은 품질 | 배경 소음이나 비음성 사운드가 있을 때 눈에 띄는 입 움직임이 나타날 수 있습니다. | 깨끗한 오디오 환경, 성능이 중요한 시나리오 |
| 반 최적화 | 좋은 성능, 적당한 CPU 사용량 | 고품질 | 잡음이 있는 오디오에서 더 나은 안정성 | 성능과 품질의 균형, 혼합된 오디오 조건 |
| 원본 | 최신 CPU에서 실시간 사용에 적합합니다. | 최고 품질 | 배경 소음과 비음성 사운드에서 가장 안정적입니다 | 고품질 제작, 소음이 많은 오디오 환경, 최대 정확도가 필요할 때 |
성능 설정
Intra Op 스레드: 내부 모델 처리 작업에 사용되는 스레드 수를 제어합니다.
- 0 (기본/자동): 자동 감지 사용 (일반적으로 사용 가능한 CPU 코어의 1/4, 최대 4개)
- 1-16: 스레드 수를 수동으로 지정합니다. 값이 높을수록 멀티코어 시스템에서 성능이 향상될 수 있지만 CPU 사용량이 증가합니다.
Inter Op 스레드: 서로 다른 모델 연산의 병렬 실행에 사용되는 스레드 수를 제어합니다.
- 0 (기본/자동): 자동 감지 사용 (일반적으로 사용 가능한 CPU 코어의 1/8, 최대 2개)
- 1-8: 스레드 수를 수동으로 지정합니다. 일반적으로 실시간 처리를 위해 낮게 유지됩니다.
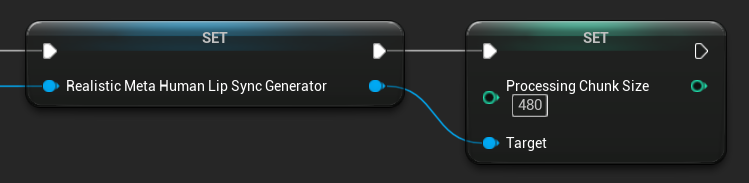
청크 처리 크기
처리 청크 크기는 각 추론 단계에서 처리되는 샘플 수를 결정합니다. 기본값은 160개 샘플(16kHz에서 10ms 오디오)입니다.
- 값이 작을수록 업데이트가 더 자주 이루어지지만 CPU 사용량이 증가합니다
- 값이 클수록 CPU 부하는 줄어들지만 립 싱크 반응성이 저하될 수 있습니다
- 최적의 정렬을 위해 160의 배수를 사용하는 것이 좋습니다
감정 지원 모델 구성
Create Realistic MetaHuman Lip Sync With Mood Generator 노드는 기본 사실적인 모델 외에 추가 구성 옵션을 제공합니다:
기본 구성
Lookahead Ms: 립 싱크 정확도 향상을 위한 선행 시간(밀리초)입니다.
- 기본값: 80ms
- 범위: 20ms ~ 200ms (20으로 나누어 떨어져야 함)
- 값이 높을수록 동기화는 더 좋아지지만 지연 시간이 증가합니다
출력 유형: 생성될 얼굴 컨트롤을 제어합니다.
- 전체 얼굴: 눈썹, 눈, 코, 입, 턱, 혀를 포함한 81개의 모든 얼굴 컨트롤
- 입만: 입, 턱, 혀와 관련된 컨트롤만
성능 설정: 일반 리얼리스틱 모델과 동일한 Intra Op Threads 및 Inter Op Threads 설정을 사용합니다.
분위기 설정
사용 가능한 감정 상태:
- 중립, 행복, 슬픔, 혐오, 분노, 놀람, 두려움
- 자신감, 신남, 지루함, 장난기, 혼란
감정 강도: 감정이 애니메이션에 얼마나 강하게 영향을 미치는지 제어합니다 (0.0 ~ 1.0)
런타임 무드 컨트롤
런타임 중에 다음 함수들을 사용하여 분위기 설정을 조정할 수 있습니다:
- 분위기 설정: 현재 분위기 유형 변경
- 분위기 강도 설정: 분위기가 애니메이션에 영향을 미치는 강도 조정 (0.0 ~ 1.0)
- 미리보기 시간(ms) 설정: 동기화를 위한 미리보기 타이밍 수정
- 출력 유형 설정: 전체 얼굴과 입 전용 컨트롤 간 전환

분위기 선택 가이드
콘텐츠에 따라 적절한 분위기를 선택하세요.
| Mood | 가장 적합한 | 일반적인 강도 범위 |
|---|---|---|
| 중립 | 일반 대화, 내레이션, 기본 상태 | 0.5 - 1.0 |
| 행복한 | 긍정적인 내용, 즐거운 대화, 축하 | 0.6 - 1.0 |
| 슬픔 | 우울한 콘텐츠, 감정적인 장면, 엄숙한 순간 | 0.5 - 0.9 |
| 혐오 | 부정적인 반응, 불쾌한 콘텐츠, 거절 | 0.4 - 0.8 |
| 분노 | 공격적인 대화, 대립적인 장면, 좌절감 | 0.6 - 1.0 |
| 놀람 | 예상치 못한 사건들, 폭로, 충격적인 반응 | 0.7 - 1.0 |
| 두려움 | 위협적인 상황, 불안, 긴장된 대화 | 0.5 - 0.9 |
| 자신감 있는 | 전문적인 프레젠테이션, 리더십 대화, 단호한 연설 | 0.7 - 1.0 |
| 신난 | 활기찬 콘텐츠, 공지사항, 열정적인 대화 | 0.8 - 1.0 |
| 지루한 | 단조로운 내용, 무관심한 대화, 지친 말투 | 0.3 - 0.7 |
| 장난기 가득한 | 캐주얼한 대화, 유머, 가벼운 상호작용 | 0.6 - 0.9 |
| 혼란스러운 | 질문이 많은 대화, 불확실함, 당혹감 | 0.4 - 0.8 |
애니메이션 블루프린트 구성
립 싱크 설정
- 표준 모델
- 현실적인 모델
Blend Runtime MetaHuman Lip Sync 노드의 속성 패널에는 구성 옵션이 있습니다:
| 속성 | 기본값 | 설명 |
|---|---|---|
| 보간 속도 | 25 | 립 움직임이 비지엠(viseme) 간에 전환되는 속도를 제어합니다. 값이 높을수록 더 빠르고 급격한 전환이 이루어집니다. |
| 시간 초기화 | 0.2 | 립 싱크가 리셋되는 시간(초)입니다. 오디오가 중지된 후에도 립 싱크가 계속되는 것을 방지하는 데 유용합니다. |
웃음 애니메이션
오디오에서 웃음이 감지되면 동적으로 반응하는 웃음 애니메이션을 추가할 수도 있습니다.
Blend Runtime MetaHuman Laughter노드를 추가하세요RuntimeVisemeGenerator변수를Viseme Generator핀에 연결하세요- 이미 립 싱크를 사용 중인 경우:
Blend Runtime MetaHuman Lip Sync노드의 출력을Blend Runtime MetaHuman Laughter노드의Source Pose에 연결합니다.Blend Runtime MetaHuman Laughter노드의 출력을Output Pose의Result핀에 연결합니다.
- 립싱크 없이 웃음만 사용하는 경우:
- 소스 포즈를
Blend Runtime MetaHuman Laughter노드의Source Pose에 직접 연결하세요 - 출력을
Result핀에 연결하세요
- 소스 포즈를
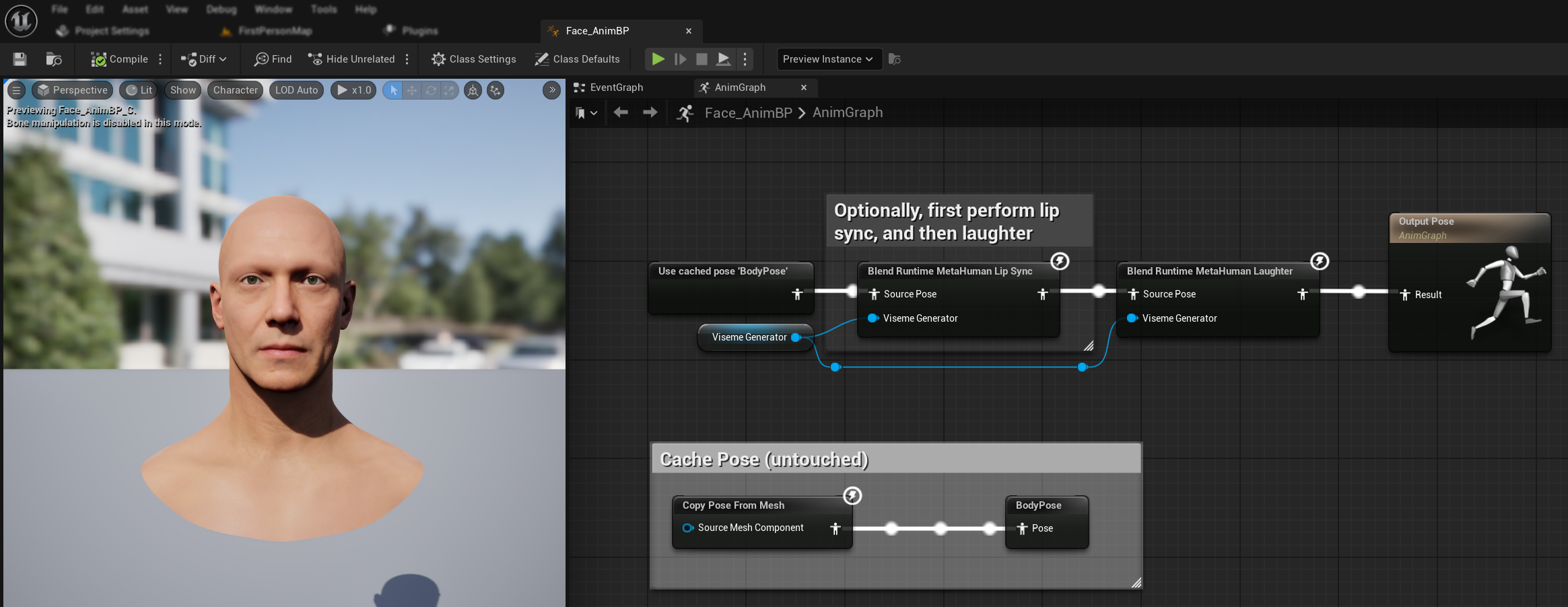
오디오에서 웃음이 감지되면 캐릭터가 이에 맞춰 동적으로 애니메이션을 수행합니다:
웃음 설정
Blend Runtime MetaHuman Laughter 노드에는 자체 구성 옵션이 있습니다:
| 속성 | 기본값 | 설명 |
|---|---|---|
| 보간 속도 | 25 | 웃음 애니메이션 간 입술 움직임 전환 속도를 제어합니다. 값이 높을수록 더 빠르고 급격한 전환이 발생합니다. |
| 시간 초기화 | 0.2 | 웃음이 초기화되는 시간(초)입니다. 오디오가 중지된 후에도 웃음이 계속되는 것을 방지하는 데 유용합니다. |
| 최대 웃음 가중치 | 0.7 | 웃음 애니메이션의 최대 강도를 조정합니다 (0.0 - 1.0). |
참고: 웃음 감지는 현재 Standard Model에서만 사용할 수 있습니다.
Blend Realistic MetaHuman Lip Sync 노드에는 속성 패널에 구성 옵션이 있습니다:
| 속성 | 기본값 | 설명 |
|---|---|---|
| 보간 속도 | 30 | 말하는 동안 표정이 전환되는 속도를 제어합니다. 값이 높을수록 더 빠르고 급격한 전환이 발생합니다. |
| 대기 중 보간 속도 | 15 | 표정이 중립 상태로 돌아가는 속도를 제어합니다. 값이 낮을수록 더 부드럽고 점진적으로 기본 포즈로 복귀합니다. |
| 시간 초기화 | 0.2 | 립 싱크가 유휴 상태로 재설정되기까지의 시간(초)입니다. 오디오가 중지된 후에도 표정이 계속되는 것을 방지하는 데 유용합니다. |
| 유휴 상태 유지 | 거짓 | 활성화되면 대기 중에 중립 상태로 초기화되지 않고 마지막 감정 상태를 유지합니다. |
| 눈 표정 유지 | true | 아이들 상태에서 눈 관련 얼굴 컨트롤을 유지할지 여부를 제어합니다. 아이들 상태 유지가 활성화된 경우에만 적용됩니다. |
| 눈썹 표정 유지 | true | 유휴 상태 동안 눈썹 관련 얼굴 컨트롤을 유지할지 여부를 제어합니다. 유휴 상태 유지가 활성화된 경우에만 적용됩니다. |
| 입 모양 유지 | 거짓 | 입 상태 컨트롤(혀와 턱 같은 발음 관련 움직임 제외)이 유휴 상태에서 유지되는지 여부를 제어합니다. 유휴 상태 유지가 활성화된 경우에만 적용됩니다. |
대기 상태 유지
Preserve Idle State 기능은 Realistic 모델이 무음 구간을 처리하는 방식을 다룹니다. 개별 비짐(viseme)을 사용하고 무음 중에 일관되게 0 값으로 돌아가는 Standard 모델과 달리, Realistic 모델의 신경망은 MetaHuman의 기본 휴식 포즈와 다른 미묘한 얼굴 위치를 유지할 수 있습니다.
활성화 시점:
- 말하는 구간 사이에서 감정 표현 유지하기
- 캐릭터 성격 특성 유지하기
- 시네마틱 시퀀스에서 시각적 연속성 보장하기
지역 제어 옵션:
- 눈 표정: 눈을 가늘게 뜨거나 크게 뜨는 동작과 눈꺼풀 위치를 유지합니다
- 눈썹 표정: 눈썹과 이마의 위치를 유지합니다
- 입 모양: 말하는 동작(혀, 턱)이 초기화되는 동안 입의 전체적인 곡률을 유지합니다
기존 애니메이션과 결합하기
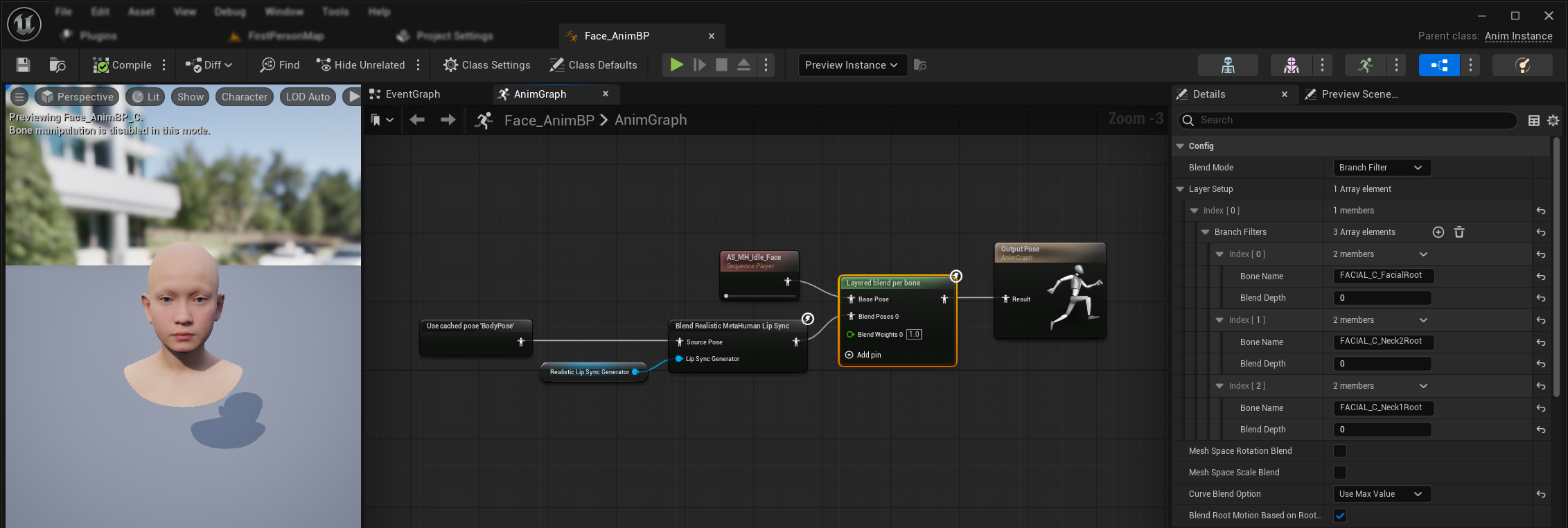
립 싱크와 웃음을 기존의 신체 애니메이션 및 사용자 정의 얼굴 애니메이션을 덮어쓰지 않고 적용하려면:
이 설정은 얼굴 애니메이션 블루프린트에 적용됩니다. 립 싱크는 바디 애니메이션 블루프린트의 일부가 아니기 때문입니다. 사용자 정의 바디 애니메이션(예: 상체, 팔 및 기타 신체 움직임)의 경우, Sequence Player를 통해 애니메이션 시퀀스를 바디 애니메이션 블루프린트의 출력 포즈에 직접 연결하기만 하면 됩니다. 추가 설정은 필요하지 않습니다.
- 바디 애니메이션과 최종 출력 사이에
Layered blend per bone노드를 추가합니다.Use Attached Parent가 true인지 확인하세요. - 레이어 설정을 구성합니다:
- 레이어 설정 배열에 1개 항목 추가
- 레이어에 3개 항목을 분기 필터에 추가하고, 다음 뼈 이름을 사용합니다:
FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- 사용자 정의 얼굴 애니메이션에 중요:
Curve Blend Option에서 **"Use Max Value"**를 선택하세요. 이렇게 하면 사용자 정의 얼굴 애니메이션(표정, 감정 등)이 립 싱크 위에 적절하게 레이어링될 수 있습니다. - 연결을 만드세요:
- 사용자 정의 애니메이션(일반적으로 원하는 애니메이션 시퀀스 에셋이 포함된
Sequence Player) →Base Pose입력 - 얼굴 애니메이션 출력(립 싱크 및/또는 웃음 노드에서) →
Blend Poses 0입력 - 레이어드 블렌드 노드 → 최종
Result포즈
- 사용자 정의 애니메이션(일반적으로 원하는 애니메이션 시퀀스 에셋이 포함된
형태 타겟 세트 선택
- 표준 모델
- 현실적인 모델
표준 모델은 사용자 정의 포즈 애셋 설정을 통해 모든 모프 타겟 명명 규칙을 기본적으로 지원하는 포즈 애셋을 사용합니다. 추가 구성이 필요하지 않습니다.
Blend Realistic MetaHuman Lip Sync 노드에는 얼굴 애니메이션에 사용할 모프 타겟 명명 규칙을 결정하는 Morph Target Set 속성이 포함되어 있습니다.
| 형태 타겟 세트 | 설명 | 사용 사례 |
|---|---|---|
| 메타휴먼 (기본값) | 표준 메타휴먼 모프 타겟 이름 (예: CTRL_expressions_jawOpen) | 메타휴먼 캐릭터 |
| ARKit | Apple ARKit 호환 이름 (예: JawOpen, MouthSmileLeft) | ARKit 기반 캐릭터 |
립싱크 동작 미세 조정
특정 립 싱크 커브 조정
Modify Curve 노드를 사용하여 립 싱크로 생성된 개별 얼굴 움직임을 감쇠(또는 증폭)할 수 있습니다. 이는 특정 커브가 오디오 콘텐츠나 캐릭터에 비해 너무 두드러져 보일 때 유용합니다.
설정:
- 립 싱크 블렌드 노드 뒤에
Modify Curve노드를 추가하세요 - 노드를 우클릭하고 Add Curve Pin을 선택한 다음, 스케일을 조정할 커브 이름을 입력하세요
- 노드의 Apply Mode 속성을 Scale로 설정하세요
- Value 매개변수를 설정하세요: 1.0 미만의 값은 움직임을 감소시키고, 1.0 초과의 값은 증폭시킵니다 (예: 0.8 = 20% 감소)
일반적으로 스케일링되는 커브:
| 곡선 이름 | 목적 | 적용 대상 | 일반적인 조정 |
|---|---|---|---|
CTRL_expressions_tongueOut | 특정 음소 발음 시 혀가 앞으로 내밀어짐 | 표준 모델 | 0.8로 돌출을 줄입니다 |
CTRL_expressions_jawOpen | 턱 열림 범위 | 현실적인 모델 | 0.9로 설정하여 턱 움직임을 줄입니다. |
동일한 Modify Curve 노드에 여러 개의 커브 핀을 추가하여 여러 커브를 한 번에 스케일할 수 있습니다.
분위기별 미세 조정
감정 지원 모델의 경우 특정 감정 표현을 미세 조정할 수 있습니다:
눈썹 제어:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- 눈썹 안쪽 올리기CTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- 눈썹 바깥쪽 올리기CTRL_expressions_browDownL/CTRL_expressions_browDownR- 눈썹 내리기
눈 표정 제어:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- 눈을 가늘게 뜨기CTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- 볼 올리기
모델 비교 및 선택
모델 선택하기
프로젝트에 사용할 립 싱크 모델을 결정할 때는 다음 요소를 고려하세요:
| 고려 사항 | 표준 모델 | 현실적인 모델 | 감정 반영 현실적 모델 |
|---|---|---|---|
| 캐릭터 호환성 | 메타휴먼 및 모든 사용자 정의 캐릭터 유형 | 메타휴먼(및 ARKit) 캐릭터 | 메타휴먼(및 ARKit) 캐릭터 |
| 시각적 품질 | 효율적인 성능을 갖춘 우수한 립싱크 | 입술 움직임이 더 자연스러워져 현실감 향상 | 감정 표현을 통한 향상된 사실감 |
| 성능 | 모바일/VR을 포함한 모든 플랫폼에 최적화됨 | 더 높은 리소스 요구 사항 | 더 높은 리소스 요구 사항 |
| 기능 | 14개의 비제임(visemes), 웃음 감지 | 81개의 얼굴 컨트롤, 3가지 최적화 수준 | 81개의 얼굴 컨트롤, 12가지 무드, 설정 가능한 출력 |
| 플랫폼 지원 | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| 사용 사례 | 일반 애플리케이션, 게임, VR/AR, 모바일 | 시네마틱 경험, 클로즈업 상호작용 | 감정적인 스토리텔링, 고급 캐릭터 상호작용 |
엔진 버전 호환성
Unreal Engine 5.2를 사용하는 경우, UE의 리샘플링 라이브러리 버그로 인해 Realistic Models가 올바르게 작동하지 않을 수 있습니다. 안정적인 립 싱크 기능이 필요한 UE 5.2 사용자는 Standard Model을 대신 사용해 주세요.
이 문제는 UE 5.2에만 해당되며 다른 엔진 버전에는 영향을 미치지 않습니다.
성능 권장 사항
- 대부분의 프로젝트에서 표준 모델은 품질과 성능의 훌륭한 균형을 제공합니다
- MetaHuman 캐릭터에 가장 높은 시각적 충실도가 필요할 때 리얼리스틱 모델을 사용하세요
- 애플리케이션에서 감정 표현 제어가 중요할 때 감정 지원 리얼리스틱 모델을 사용하세요
- 모델을 선택할 때 대상 플랫폼의 성능 능력을 고려하세요
- 특정 사용 사례에 가장 적합한 균형을 찾기 위해 다양한 최적화 수준을 테스트하세요
문제 해결
일반적인 문제
리얼리스틱 모델을 위한 생성기 재생성: 리얼리스틱 모델에서 안정적이고 일관된 작동을 보장하려면, 비활성 기간 후에 새로운 오디오 데이터를 입력할 때마다 생성기를 다시 생성하는 것이 좋습니다. 이는 ONNX 런타임 동작으로 인해 침묵 기간 후 생성기를 재사용할 때 립 싱크가 작동을 멈출 수 있기 때문입니다.
예를 들어, 재생이 시작될 때마다 립 싱크 생성기를 다시 생성할 수 있습니다. 예를 들어, Play Sound 2D를 호출하거나 다른 방법을 사용하여 사운드 웨이브 재생 및 립 싱크를 시작할 때마다 그렇게 할 수 있습니다.
Runtime Text To Speech 통합을 위한 플러그인 위치: Runtime MetaHuman Lip Sync와 Runtime Text To Speech를 함께 사용하는 경우(두 플러그인 모두 ONNX Runtime 사용), 플러그인이 엔진의 Marketplace 폴더에 설치되어 있으면 패키징된 빌드에서 문제가 발생할 수 있습니다. 이를 해결하려면:
- 두 플러그인을 UE 설치 폴더의
\Engine\Plugins\Marketplace경로에서 찾으세요 (예:C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) RuntimeMetaHumanLipSync및RuntimeTextToSpeech폴더를 모두 프로젝트의Plugins폴더로 이동하세요- 프로젝트에
Plugins폴더가 없는 경우,.uproject파일과 동일한 디렉터리에 새로 만드세요 - 언리얼 에디터를 다시 시작하세요
이는 엔진의 마켓플레이스 디렉토리에서 여러 ONNX Runtime 기반 플러그인이 로드될 때 발생할 수 있는 호환성 문제를 해결합니다.
패키징 구성 (Windows): Windows에서 패키징된 프로젝트의 립 싱크가 제대로 작동하지 않는 경우, Development 대신 Shipping 빌드 구성을 사용하고 있는지 확인하세요. Development 구성은 패키징된 빌드에서 리얼리스틱 모델 ONNX 런타임에 문제를 일으킬 수 있습니다.
이 문제를 해결하려면:
- 프로젝트 설정 → 패키징에서 빌드 구성을 배포로 설정하세요
- 프로젝트를 다시 패키징하세요
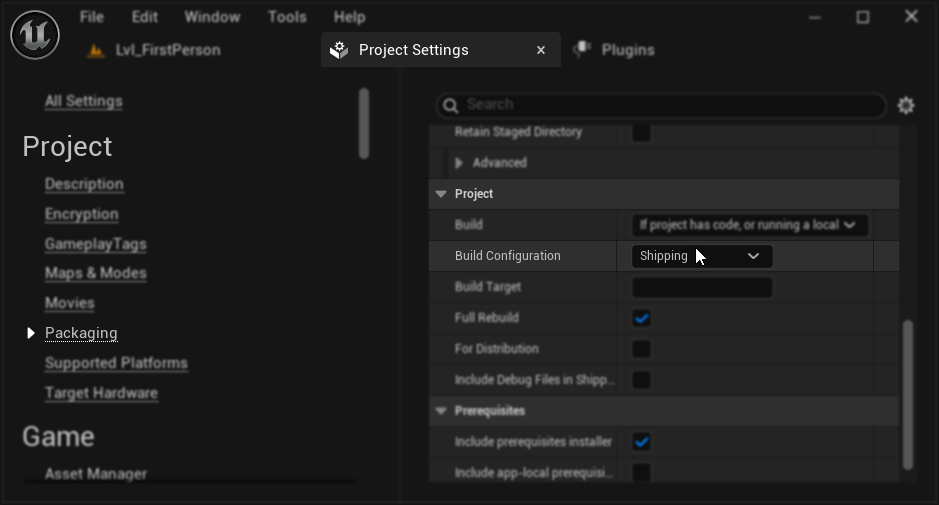
일부 블루프린트 전용 프로젝트에서 언리얼 엔진이 Shipping을 선택했음에도 Development 구성으로 빌드되는 경우가 있습니다. 이 문제가 발생하면 C++ 클래스를 하나 이상 추가하여(비어 있어도 됩니다) 프로젝트를 C++ 프로젝트로 변환하세요. 이렇게 하려면 UE 에디터 메뉴에서 Tools → New C++ Class로 이동하여 빈 클래스를 생성하십시오. 그러면 프로젝트가 Shipping 구성에서 올바르게 빌드되도록 강제됩니다. 프로젝트의 기능은 블루프린트 전용으로 유지될 수 있으며, C++ 클래스는 올바른 빌드 구성을 위해 필요할 뿐입니다.
저하된 립 싱크 응답성: 스트리밍 사운드 웨이브 또는 캡처 가능 사운드 웨이브를 사용할 때 시간이 지남에 따라 립 싱크 응답성이 저하되는 경우, 이는 메모리 누적 때문일 수 있습니다. 기본적으로 새 오디오가 추가될 때마다 메모리가 재할당됩니다. 이 문제를 방지하려면 ReleaseMemory 함수를 주기적으로 호출하여 누적된 메모리를 해제하세요(예: 30초마다).
성능 최적화:
- 성능 요구 사항에 따라 현실적인 모델의 처리 청크 크기를 조정하세요
- 대상 하드웨어에 적합한 스레드 수를 사용하세요
- 전체 얼굴 애니메이션이 필요하지 않은 경우, 감정 지원 모델에는 입 전용 출력 유형을 사용하는 것을 고려하세요