인식 매개변수 목록
이 매개변수들은 인식기가 실행 중이지 않을 때만 설정할 수 있습니다.
이것은 Whisper에서 사용 가능한 모든 매개변수의 완전한 목록이 아닙니다. 가장 중요한 매개변수들만 여기에 노출되어 있습니다. 필요하다면 이 목록은 업데이트될 것입니다.
인식 매개변수 설정
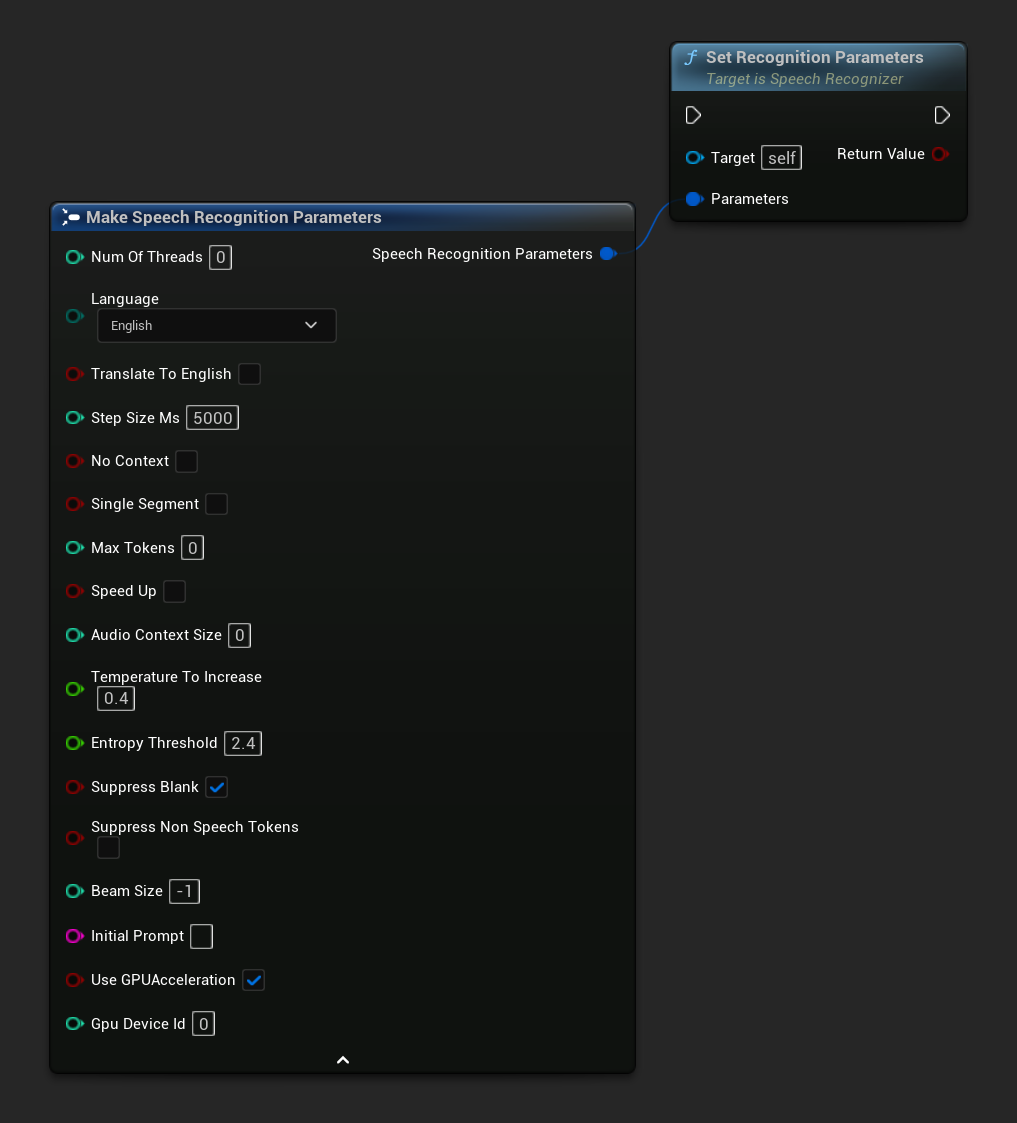
음성 인식을 위한 매개변수를 설정합니다. 특정 매개변수만 변경하려면 개별 설정 함수를 사용하는 것을 고려하세요.
스트리밍 기본값 설정
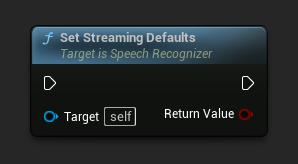
스트리밍 음성 인식에 적합한 기본 매개변수를 설정합니다.
이 함수는 이전에 적용된 모든 매개변수를 덮어씁니다. 스트리밍 기본값을 기본 구성으로 사용해야 하는 경우, 사용자 정의 매개변수를 설정하기 전에 이 함수를 호출해야 합니다.
비스트리밍 기본값 설정
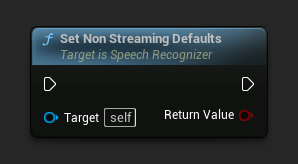
비스트리밍 음성 인식에 적합한 기본 매개변수를 설정합니다.
이 함수는 이전에 적용된 모든 매개변수를 덮어씁니다. 비스트리밍 기본값을 기본 구성으로 사용해야 하는 경우, 사용자 정의 매개변수를 설정하기 전에 이 함수를 호출해야 합니다.
스레드 수 설정
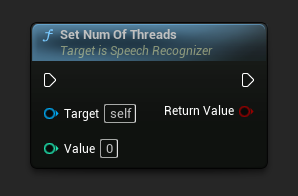
음성 인식에 사용할 스레드 수를 설정합니다. 이 값을 0으로 설정하면 코어 수를 사용합니다.
언어 설정
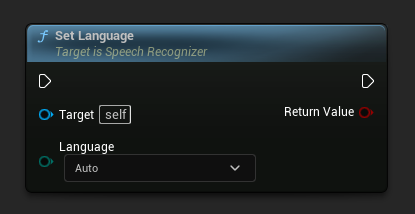
음성 인식에 사용할 언어를 설정합니다. 에디터 설정에서 선택한 언어 모델이 지원해야 합니다.
언어를 Auto로 설정하면 인식 정확도와 성능이 저하됩니다.
감지된 언어 가져오기

마지막 인식에서 감지된 언어를 가져옵니다. 언어를 열거형 값으로 반환합니다.
참고: 이 함수는 인식이 수행된 후에만 작동합니다. 언어 감지가 실패하거나 수행되지 않은 경우 Auto를 반환합니다. 이는 Auto 언어 감지를 사용할 때 실제로 어떤 언어가 인식되었는지 식별하는 데 특히 유용합니다.
언어 코드 가져오기
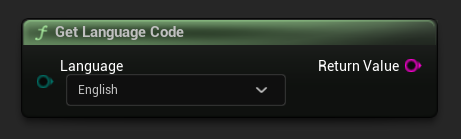
언어 열거형 값을 언어 코드 문자열로 변환합니다 (예: En -> "en", Fr -> "fr", De -> "de").
언어 전체 이름 가져오기
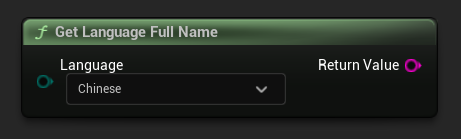
언어 열거형 값을 전체 언어 이름으로 변환합니다 (예: En -> "English", Fr -> "French", De -> "German").
영어로 번역 설정
![]()
인식된 단어를 영어로 번역할지 여부를 설정합니다. true인 경우, 언어 모델은 다국어를 지원해야 합니다.
스텝 크기 설정
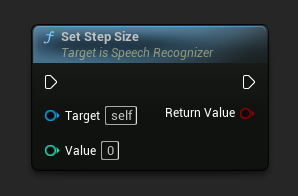
밀리초 단위의 스텝 크기를 설정합니다. 인식을 위해 오디오 데이터를 얼마나 자주 전송할지 결정합니다. 기본값은 5000ms(5초)입니다.
컨텍스트 없음 설정
이전 전사(있는 경우)를 디코더의 초기 프롬프트로 사용할지 여부를 설정합니다.
단일 세그먼트 설정
단일 세그먼트 출력을 강제할지 여부를 설정합니다(스트리밍에 유용함).
최대 토큰 수 설정
텍스트 세그먼트당 최대 토큰 수를 설정합니다. 제한 없음을 위해 0을 사용하세요.
속도 향상 설정
Phase Vocoder를 사용하여 인식 속도를 2배로 높일지 여부를 설정합니다. 출력 품질을 향상시키려면 false로 설정하세요.
오디오 컨텍스트 크기 설정
오디오 컨텍스트의 크기를 설정합니다. 출력 품질을 향상시키려면 0으로 설정하세요.
증가시킬 온도 설정
아래 임계값 중 하나를 충족하지 못하여 디코딩이 실패할 때 폴백할 때 증가시킬 온도를 설정합니다.
엔트로피 임계값 설정
엔트로피 임계값을 설정합니다. 압축률이 이 값보다 높으면 디코딩을 실패한 것으로 처리합니다. OpenAI의 "compression_ratio_threshold"과 유사합니다.
공백 억제 설정
![]()
출력에 나타나는 공백을 억제할지 여부를 설정합니다.
비음성 토큰 억제 설정
출력에 나타나는 비음성 토큰을 억제할지 여부를 설정합니다.
빔 크기 설정
빔 검색에서 사용할 빔의 수를 설정합니다. 온도가 0일 때만 적용 가능합니다.
초기 프롬프트 설정
첫 번째 창에 대한 초기 프롬프트를 설정합니다. 이는 인식에 컨텍스트를 제공하여 단어를 올바르게 예측할 가능성을 높이는 데 사용할 수 있습니다. 예를 들어 사용자 정의 어휘나 고유 명사 등에 사용됩니다.
효과적인 프롬프팅 전략에 대한 자세한 내용은 Whisper 프롬프팅 가이드를 참조하세요.
GPU 가속 설정
음성 인식에 GPU 가속을 사용할지 여부를 설정합니다(현재 Windows에서만 적용 가능).
GPU 장치 ID 설정
음성 인식에 사용할 GPU 장치 ID를 설정합니다. 기본값은 0입니다. 이는 여러 GPU가 있는 시스템에서 어떤 GPU를 인식 프로세스에 사용할지 지정하는 데 유용합니다. 지정된 GPU 장치 ID가 유효하지 않으면 사용 가능한 첫 번째 GPU 장치 인덱스가 대신 사용됩니다.