Jak używać wtyczki
Runtime AI Chatbot Integrator oferuje dwie główne funkcjonalności: czat Tekst-do-Tekstu oraz Tekst-na-Mowę (TTS). Obie funkcje działają według podobnego schematu:
- Zarejestruj swój token dostawcy API
- Skonfiguruj ustawienia specyficzne dla danej funkcji
- Wyślij żądania i przetwarzaj odpowiedzi
Zarejestruj Token Dostawcy
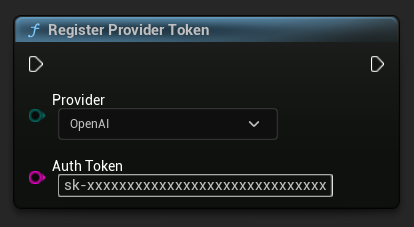
Przed wysłaniem jakichkolwiek żądań, zarejestruj swój token dostawcy API za pomocą funkcji RegisterProviderToken.
Ollama działa lokalnie i nie wymaga tokena API. Możesz pominąć ten krok dla Ollama.
- Blueprint
- C++
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
// Register other providers as needed
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::Anthropic,
TEXT("sk-ant-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::DeepSeek,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
etc
Funkcjonalność Czatu Tekst-do-Tekst
Wtyczka obsługuje dwa tryby żądań czatu dla każdego dostawcy:
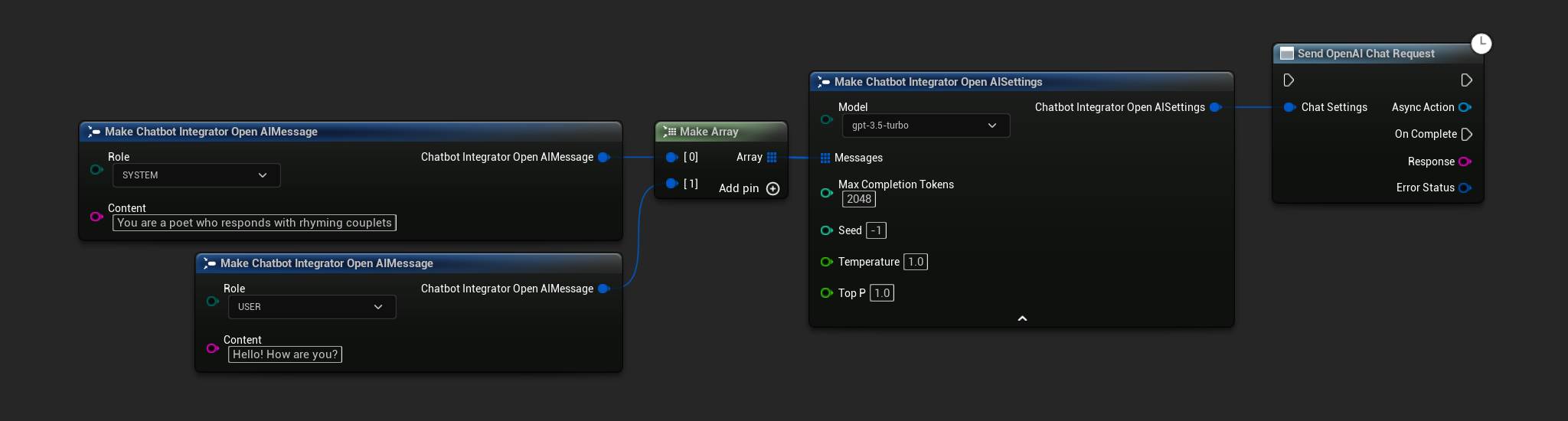
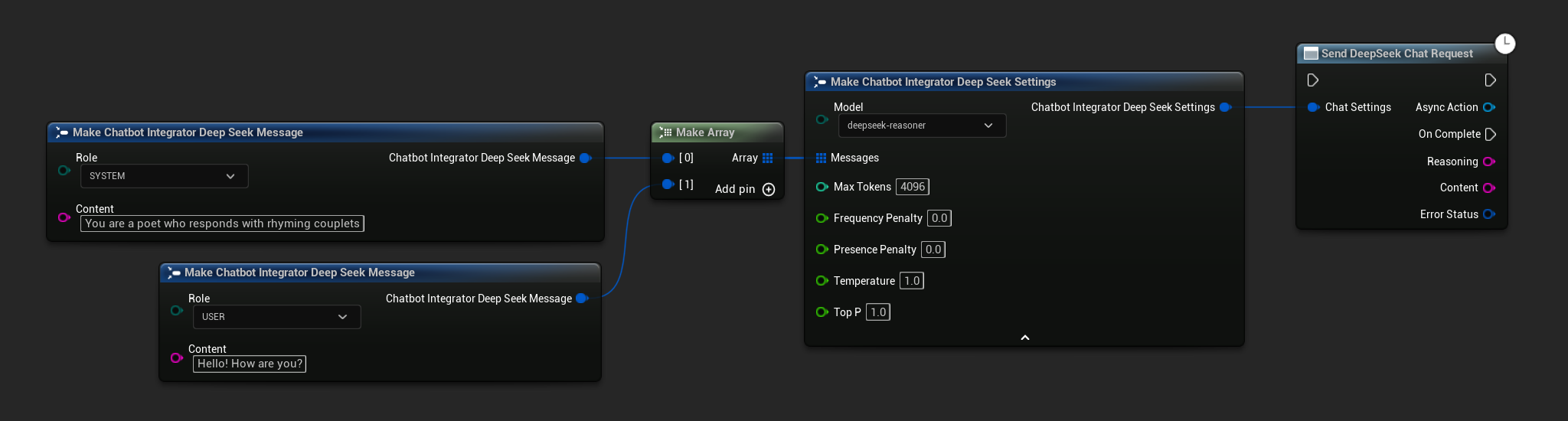
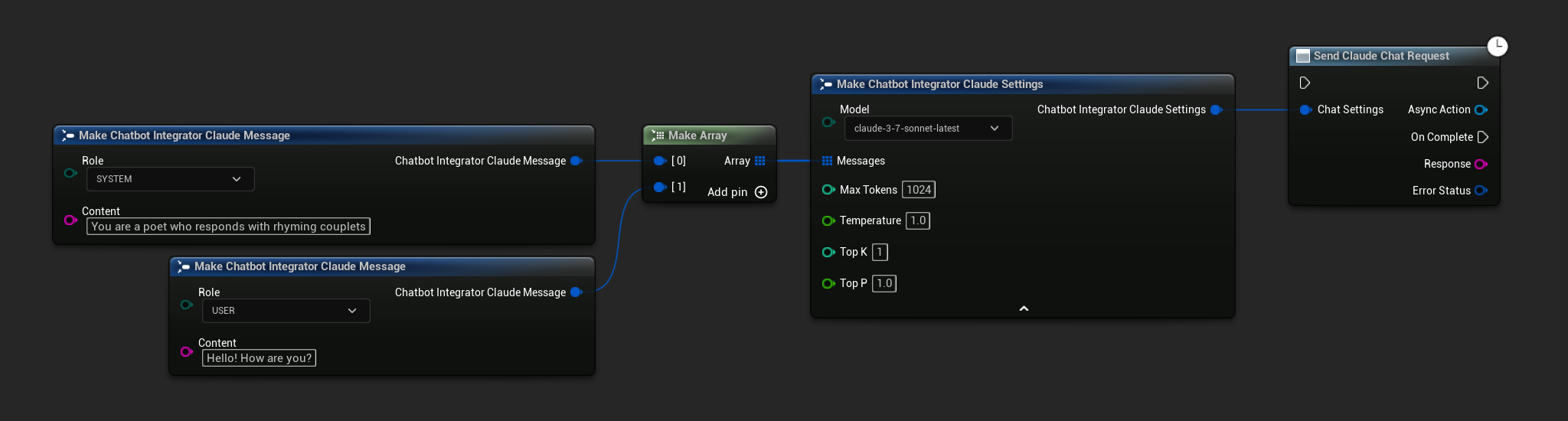
Niestrumieniowe Żądania Czatu
Pobierz pełną odpowiedź w jednym wywołaniu.
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaude::SendChatRequestNative(
Settings,
FOnClaudeChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
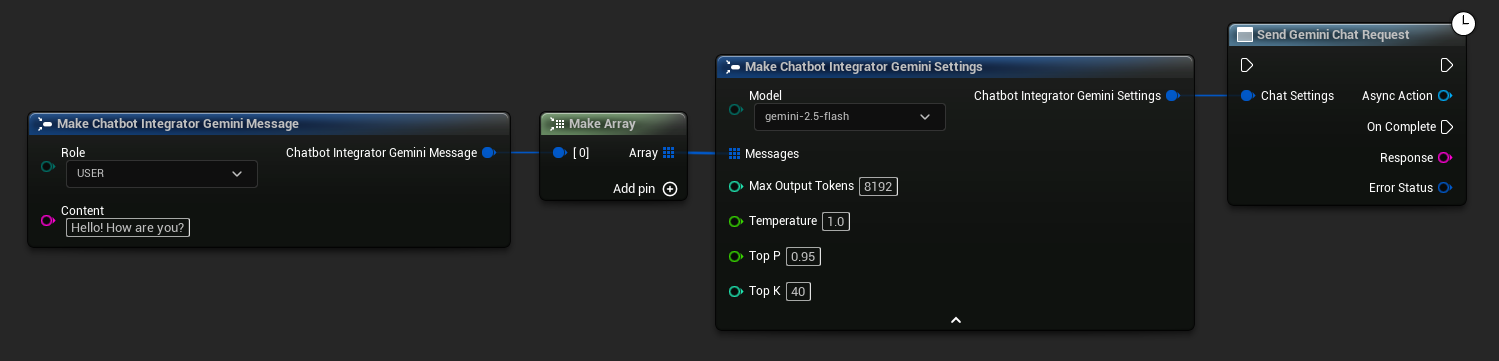
// Example of sending a non-streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGemini::SendChatRequestNative(
Settings,
FOnGeminiChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++

// Example of sending a non-streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrok::SendChatRequestNative(
Settings,
FOnGrokChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Response: %s, Error: %d: %s"),
*Reasoning, *Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
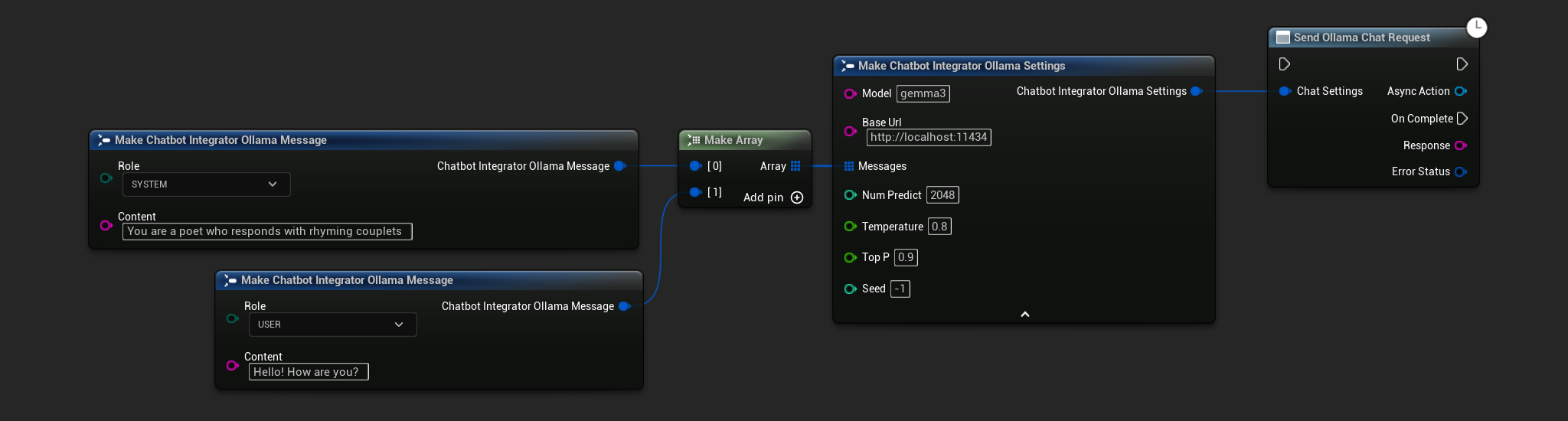
// Example of sending a non-streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllama::SendChatRequestNative(
Settings,
FOnOllamaChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
Przesyłanie strumieniowe żądań czatu
Otrzymuj fragmenty odpowiedzi w czasie rzeczywistym, aby zapewnić bardziej dynamiczną interakcję.
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
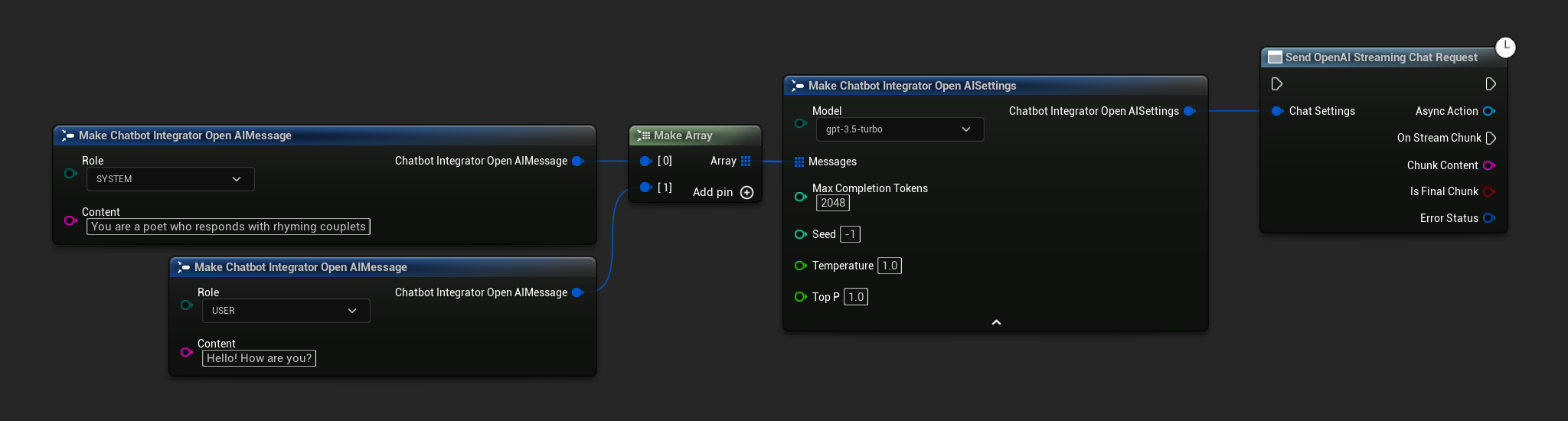
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAIStreamingSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
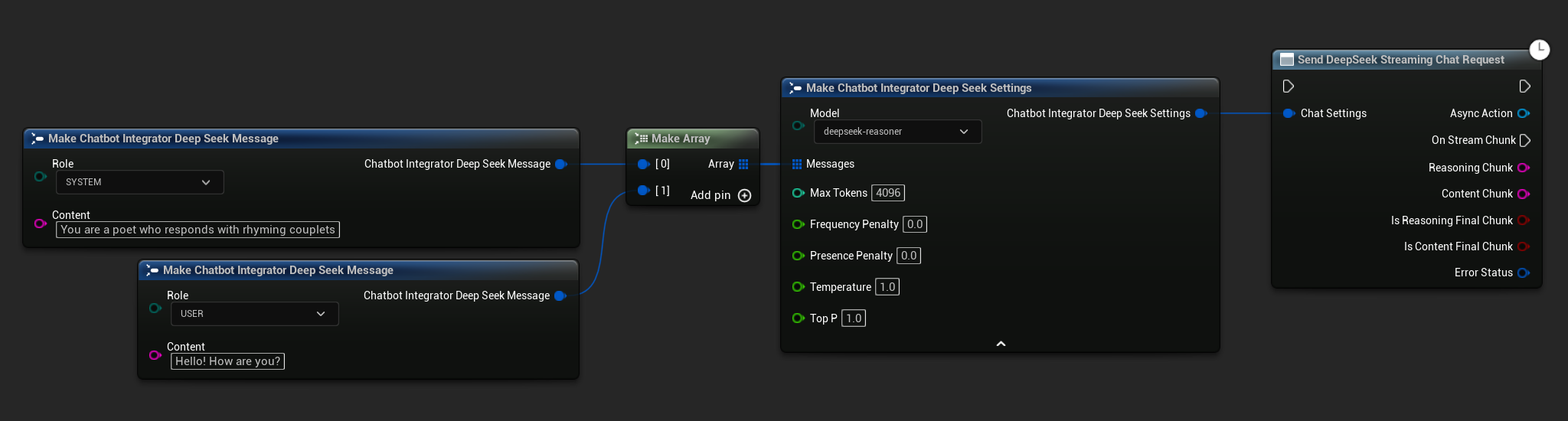
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
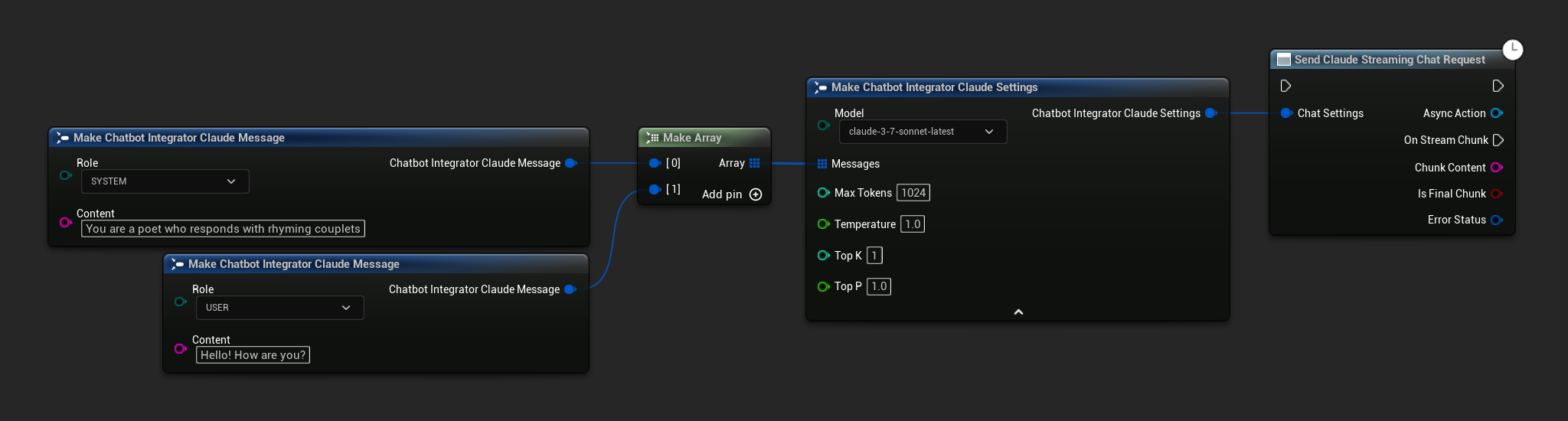
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
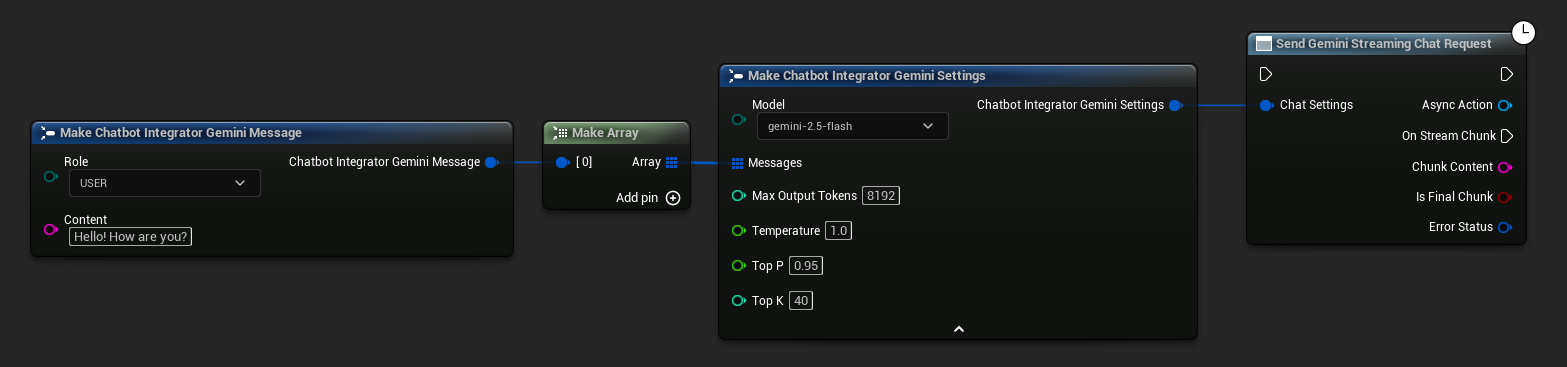
// Example of sending a streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGeminiStream::SendStreamingChatRequestNative(
Settings,
FOnGeminiChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
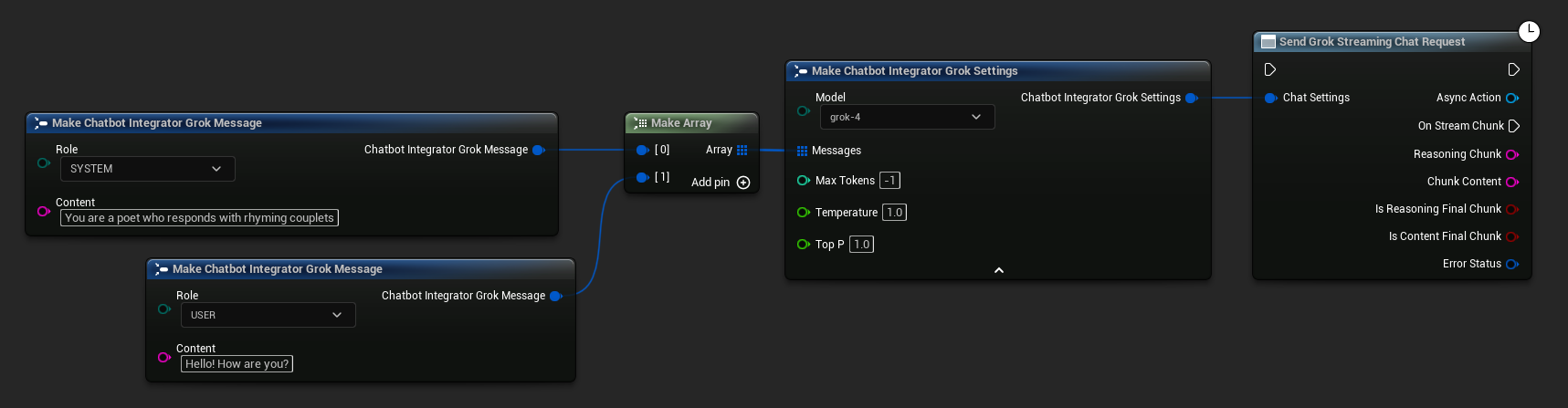
// Example of sending a streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrokStream::SendStreamingChatRequestNative(
Settings,
FOnGrokChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
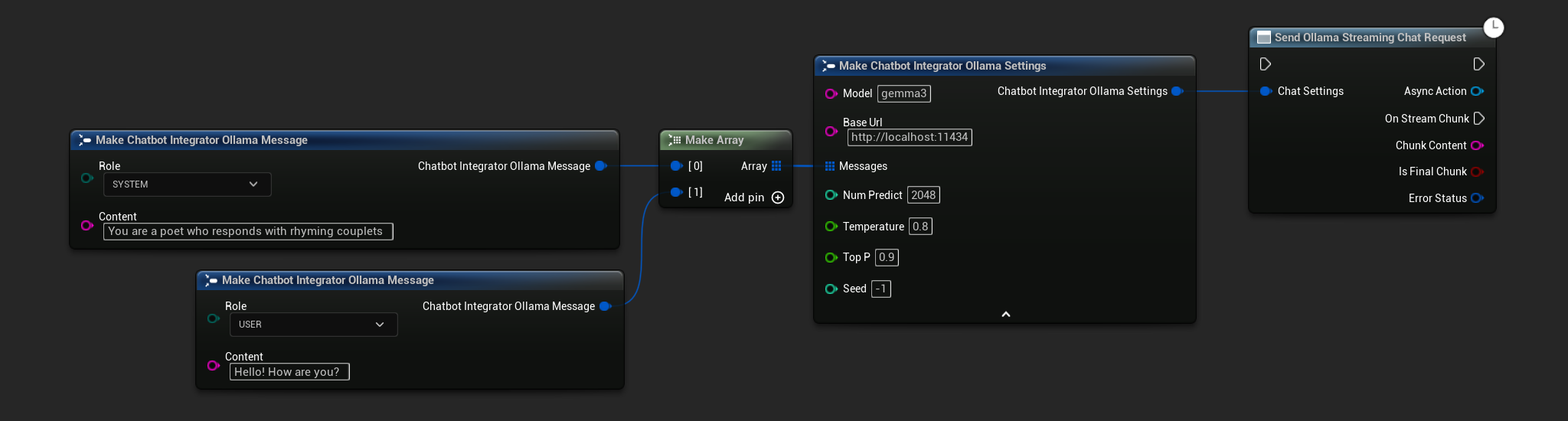
// Example of sending a streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllamaStream::SendStreamingChatRequestNative(
Settings,
FOnOllamaChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
Funkcjonalność Zamiany Tekstu na Mowę (TTS)
Konwertuj tekst na wysokiej jakości dźwięk mowy przy użyciu wiodących dostawców TTS. Wtyczka zwraca surowe dane audio (TArray<uint8>), które możesz przetworzyć zgodnie z potrzebami swojego projektu.
Podczas gdy poniższe przykłady demonstrują przetwarzanie audio do odtwarzania przy użyciu wtyczki Runtime Audio Importer (zobacz dokumentację importowania audio), Runtime AI Chatbot Integrator jest zaprojektowany tak, aby być elastyczny. Wtyczka po prostu zwraca surowe dane audio, dając Ci pełną swobodę w sposobie ich przetwarzania dla konkretnego przypadku użycia, co może obejmować odtwarzanie audio, zapis do pliku, dalsze przetwarzanie audio, przesyłanie do innych systemów, niestandardowe wizualizacje i więcej.
Niestrumieniowe Żądania TTS
Niestrumieniowe żądania TTS zwracają kompletne dane audio w jednej odpowiedzi po całkowitym przetworzeniu tekstu. To podejście jest odpowiednie dla krótszych tekstów, gdzie oczekiwanie na kompletne audio nie stanowi problemu.
- OpenAI TTS
- ElevenLabs TTS
- Google Cloud TTS
- Azure TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnOpenAITTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
}
)
);
- Blueprint
- C++
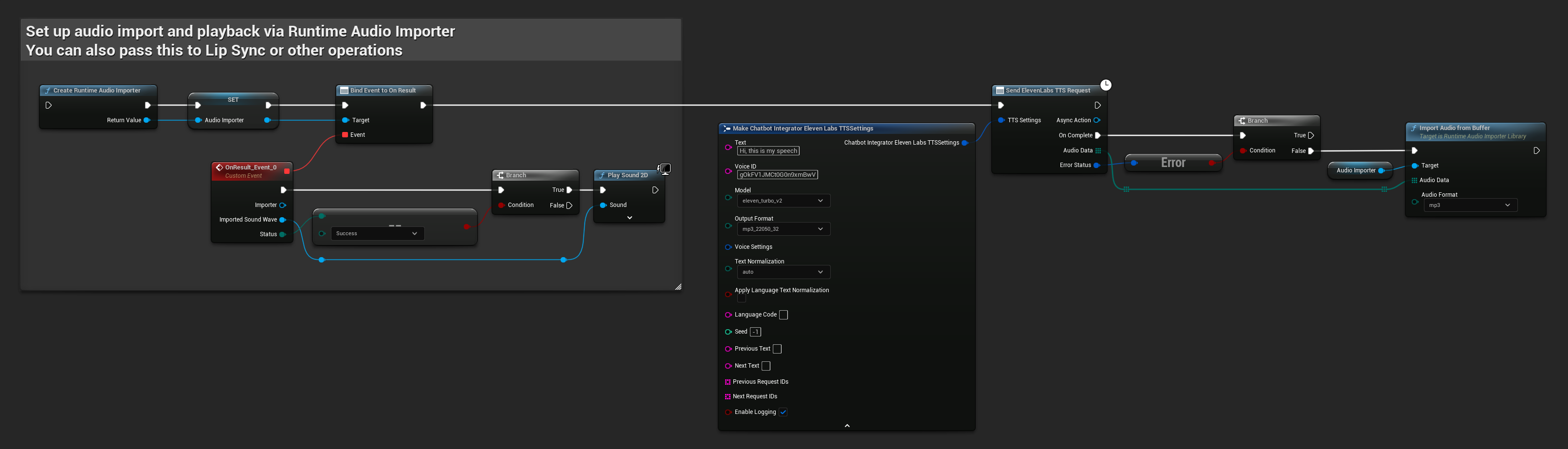
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process audio data as needed
}
}
)
);
- Blueprint
- C++
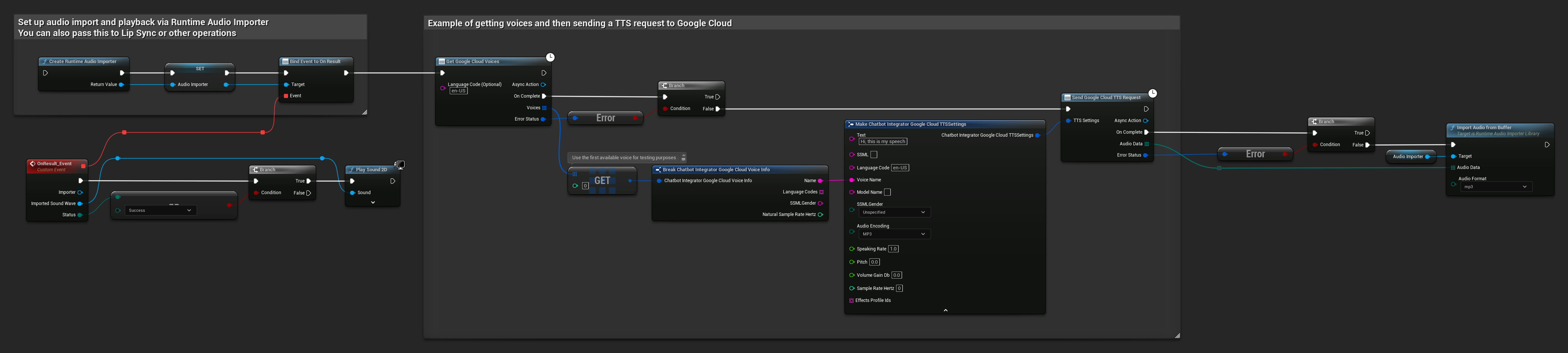
// Example of getting voices and then sending a TTS request to Google Cloud
// First, get available voices
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_GoogleCloudVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s"), *FirstVoice.Name);
// Now send TTS request with the selected voice
FChatbotIntegrator_GoogleCloudTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.LanguageCode = FirstVoice.LanguageCodes.Num() > 0 ? FirstVoice.LanguageCodes[0] : TEXT("en-US");
TTSSettings.VoiceName = FirstVoice.Name;
TTSSettings.AudioEncoding = EChatbotIntegrator_GoogleCloudAudioEncoding::MP3;
UAIChatbotIntegratorGoogleCloudTTS::SendTTSRequestNative(
TTSSettings,
FOnGoogleCloudTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
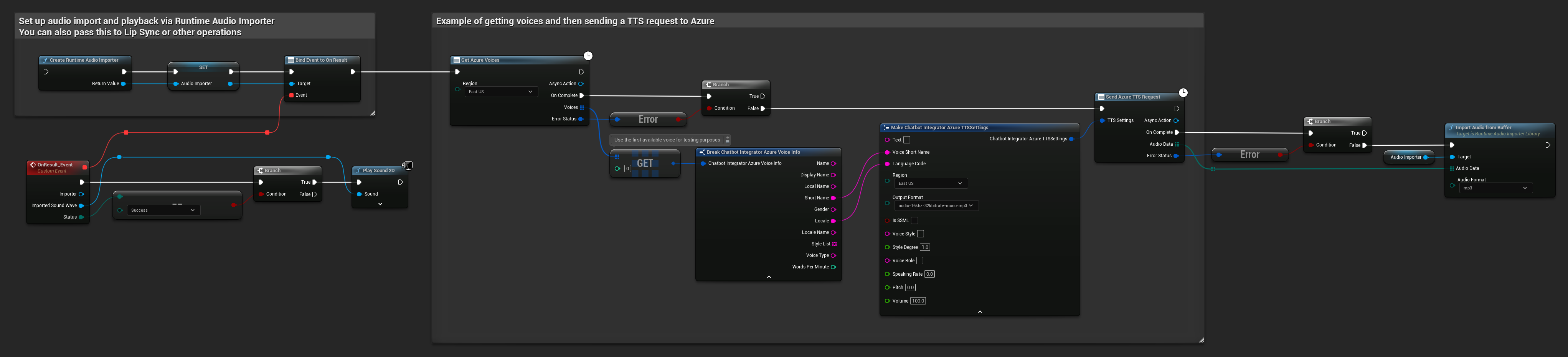
// Example of getting voices and then sending a TTS request to Azure
// First, get available voices
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_AzureVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s (%s)"), *FirstVoice.DisplayName, *FirstVoice.ShortName);
// Now send TTS request with the selected voice
FChatbotIntegrator_AzureTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceShortName = FirstVoice.ShortName;
TTSSettings.LanguageCode = FirstVoice.Locale;
TTSSettings.Region = EChatbotIntegrator_AzureRegion::EAST_US;
TTSSettings.OutputFormat = EChatbotIntegrator_AzureTTSFormat::AUDIO_16KHZ_32KBITRATE_MONO_MP3;
UAIChatbotIntegratorAzureTTS::SendTTSRequestNative(
TTSSettings,
FOnAzureTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
Przesyłanie strumieniowe żądań TTS
Przesyłanie strumieniowe TTS dostarcza fragmenty audio w miarę ich generowania, umożliwiając przetwarzanie danych przyrostowo, zamiast czekać na syntezę całego nagrania. Znacząco to redukuje postrzegane opóźnienie dla dłuższych tekstów i umożliwia aplikacje działające w czasie rzeczywistym. Przesyłanie strumieniowe TTS ElevenLabs obsługuje również zaawansowane funkcje przesyłania strumieniowego z podziałem na fragmenty dla scenariuszy dynamicznego generowania tekstu.
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
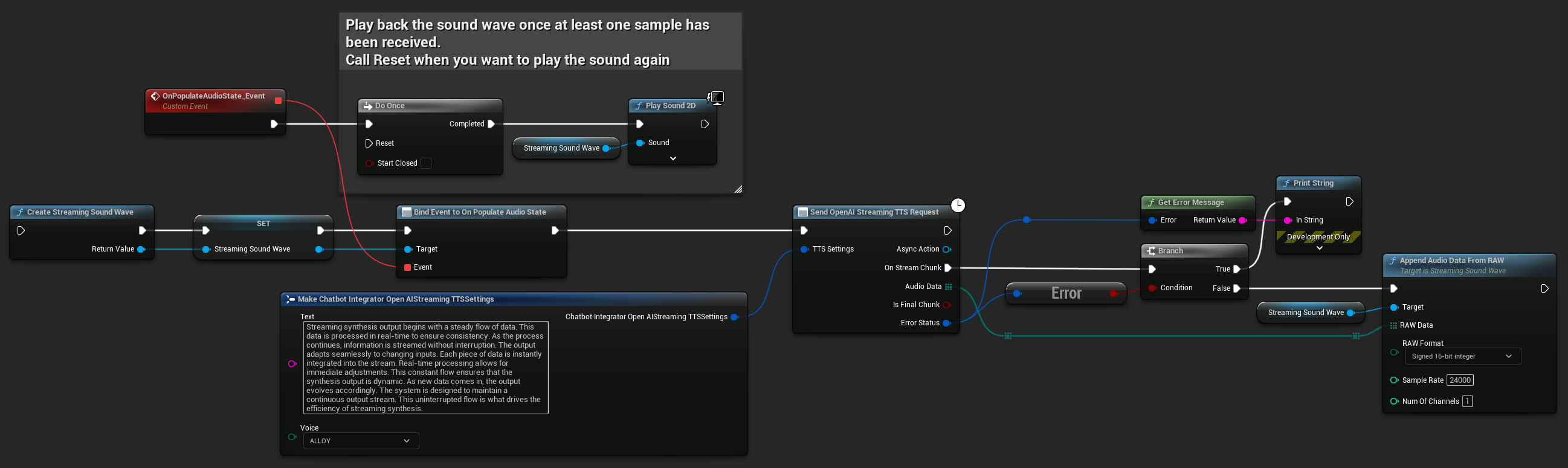
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
}));
}
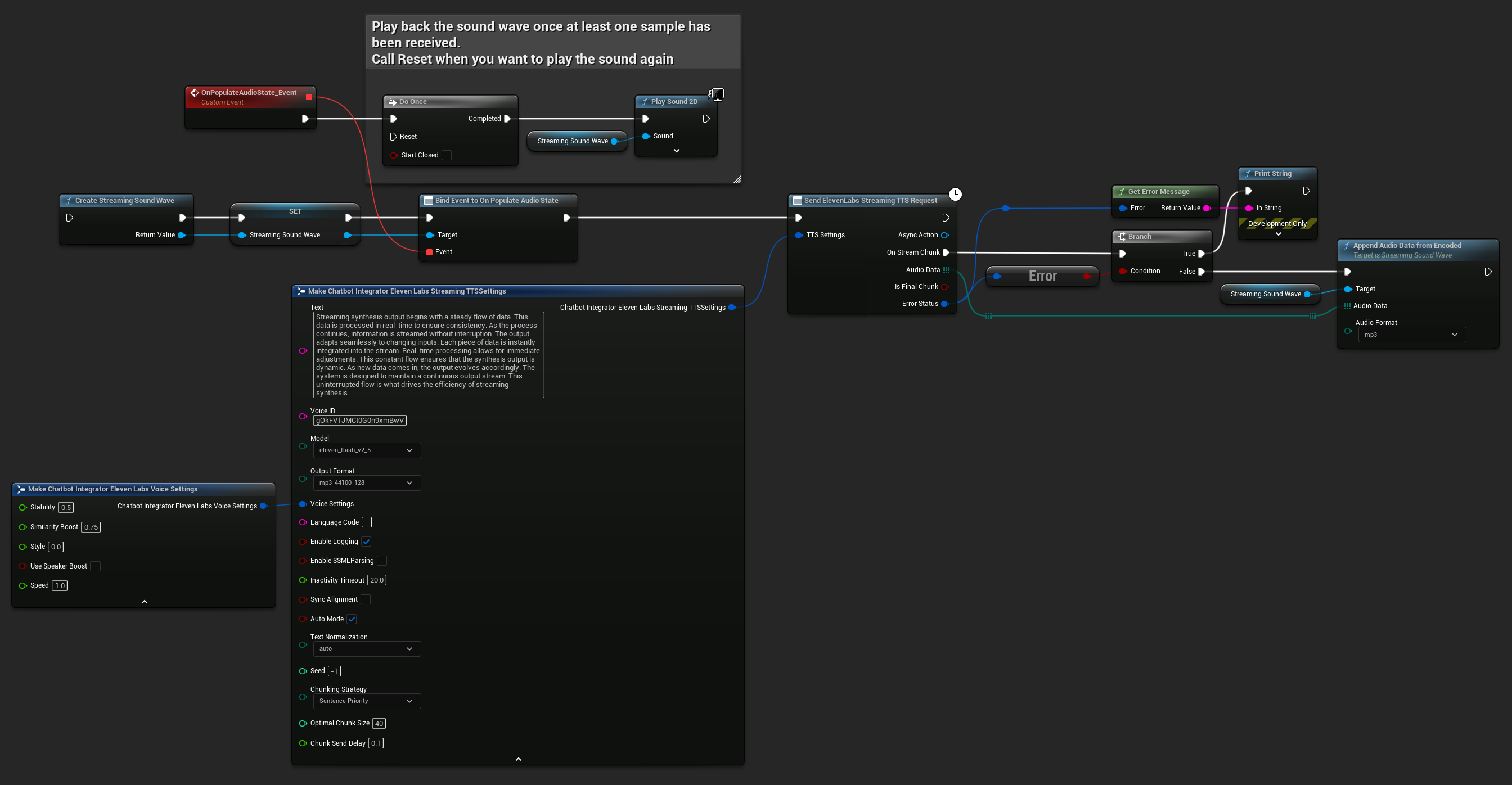
ElevenLabs Streaming TTS obsługuje zarówno standardowy tryb przesyłania strumieniowego, jak i zaawansowany tryb przesyłania strumieniowego z podziałem na fragmenty, co zapewnia elastyczność dla różnych przypadków użycia.
Standardowy Tryb Przesyłania Strumieniowego
Standardowy tryb przesyłania strumieniowego przetwarza zdefiniowany tekst i dostarcza fragmenty audio w miarę ich generowania.
- Blueprint
- C++
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = false; // Standard streaming mode
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
}));
}
Tryb Przesyłania Strumieniowego z Podziałem na Fragmenty
Tryb przesyłania strumieniowego z podziałem na fragmenty pozwala na dynamiczne dołączanie tekstu podczas syntezy, idealny dla aplikacji działających w czasie rzeczywistym, gdzie tekst jest generowany przyrostowo (np. odpowiedzi czatu AI syntezowane w miarę ich generowania). Aby włączyć ten tryb, ustaw bEnableChunkedStreaming na true w ustawieniach TTS.
- Blueprint
- C++
Konfiguracja początkowa: Skonfiguruj przesyłanie strumieniowe z podziałem na fragmenty, włączając ten tryb w ustawieniach TTS i tworząc początkową prośbę. Funkcja żądania zwraca obiekt akcji asynchronicznej, który dostarcza metod do zarządzania sesją przesyłania strumieniowego z podziałem na fragmenty:
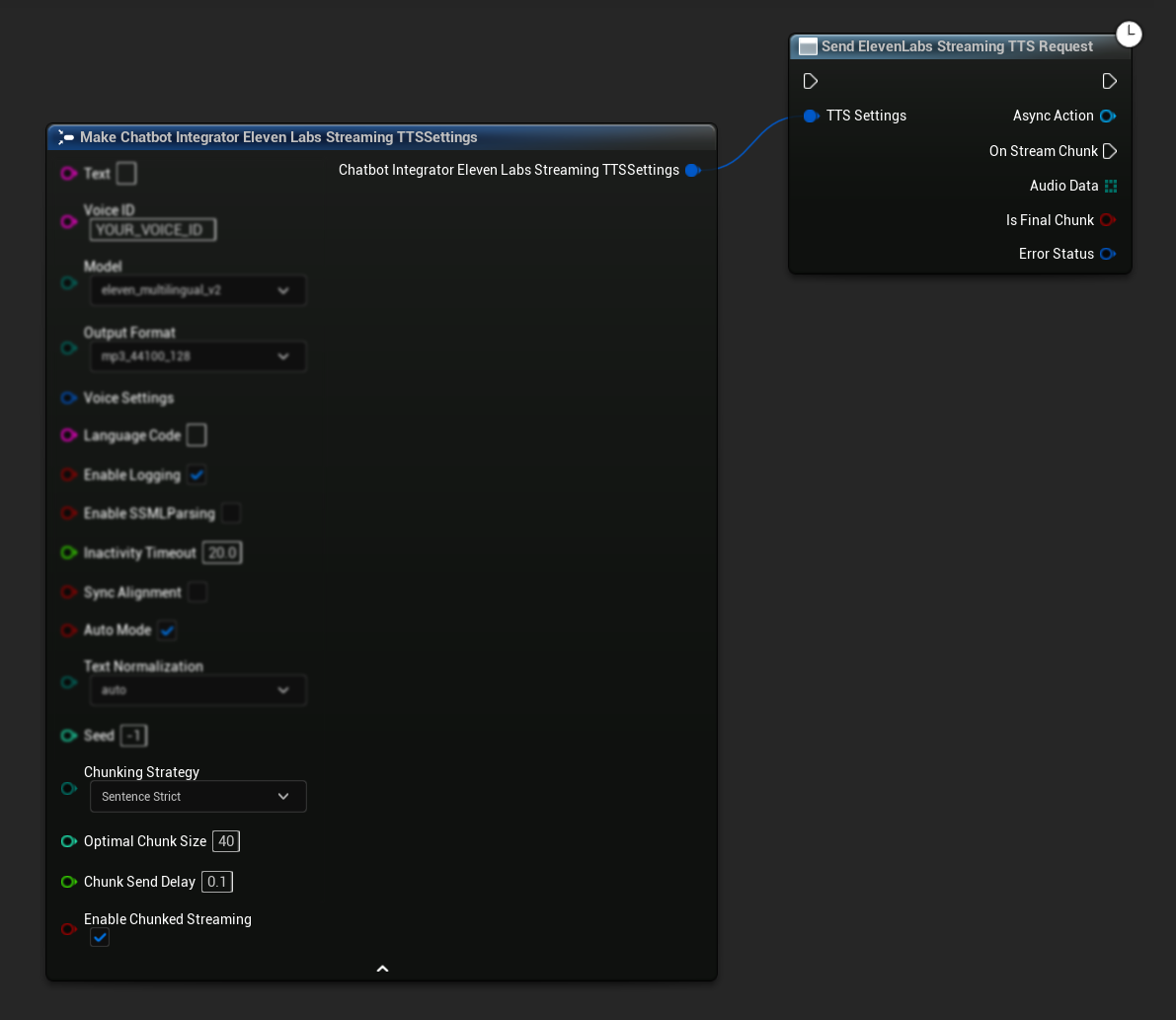
Dołącz tekst do syntezy:
Użyj tej funkcji na zwróconym obiekcie akcji asynchronicznej, aby dynamicznie dodawać tekst podczas aktywnej sesji przesyłania strumieniowego z podziałem na fragmenty. Parametr bContinuousMode kontroluje sposób przetwarzania tekstu:

- Gdy
bContinuousModejesttrue: Tekst jest buforowany wewnętrznie do momentu wykrycia pełnych granic zdań (kropki, wykrzykniki, znaki zapytania). System automatycznie wyodrębnia kompletne zdania do syntezy, zachowując niekompletny tekst w buforze. Używaj tego, gdy tekst dociera w fragmentach lub częściowych słowach, gdzie ukończenie zdania jest niepewne. - Gdy
bContinuousModejestfalse: Tekst jest przetwarzany natychmiast bez buforowania lub analizy granic zdań. Każde wywołanie skutkuje natychmiastowym przetworzeniem fragmentu i syntezą. Używaj tego, gdy masz wcześniej uformowane kompletne zdania lub frazy, które nie wymagają wykrywania granic.
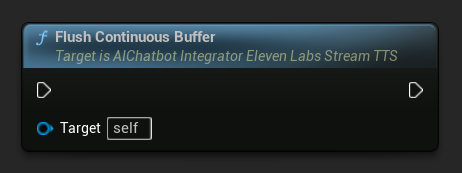
Opróżnij bufor ciągły: Wymusza przetworzenie dowolnego buforowanego tekstu ciągłego na obiekcie akcji asynchronicznej, nawet jeśli nie wykryto granicy zdania. Przydatne, gdy wiesz, że przez jakiś czas nie będzie już nowego tekstu:
Ustaw limit czasu opróżniania ciągłego: Konfiguruje automatyczne opróżnianie bufora ciągłego na obiekcie akcji asynchronicznej, gdy żaden nowy tekst nie pojawi się w określonym limicie czasu:
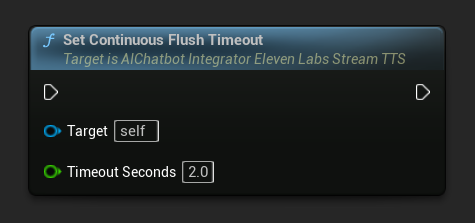
Ustaw na 0, aby wyłączyć automatyczne opróżnianie. Zalecane wartości to 1-3 sekundy dla aplikacji działających w czasie rzeczywistym.
Zakończ przesyłanie strumieniowe z podziałem na fragmenty: Zamyka sesję przesyłania strumieniowego z podziałem na fragmenty na obiekcie akcji asynchronicznej i oznacza bieżącą syntezę jako ostateczną. Zawsze wywołuj tę funkcję, gdy skończysz dodawać tekst:
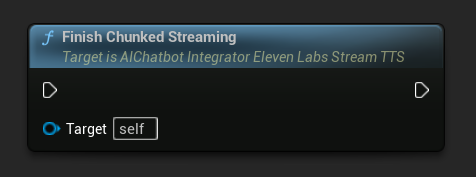
UPROPERTY()
UAIChatbotIntegratorElevenLabsStreamTTS* ChunkedTTSRequest;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartChunkedStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT(""); // Start with empty text in chunked mode
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = true; // Enable chunked streaming mode
// Store the returned async action object to call chunked streaming functions on it
ChunkedTTSRequest = UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(
GetWorld(),
TTSSettings,
FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && AudioData.Num() > 0)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
if (IsFinalChunk)
{
UE_LOG(LogTemp, Log, TEXT("Chunked streaming session completed"));
ChunkedTTSRequest = nullptr;
}
})
);
// Now you can append text dynamically as it becomes available
// For example, from an AI chat response stream:
AppendTextToTTS(TEXT("Hello, this is the first part of the message. "));
}
UFUNCTION(BlueprintCallable)
void AppendTextToTTS(const FString& AdditionalText)
{
// Call AppendTextForSynthesis on the returned async action object
if (ChunkedTTSRequest)
{
// Use continuous mode (true) when text is being generated word-by-word
// and you want to wait for complete sentences before processing
bool bContinuousMode = true;
bool bSuccess = ChunkedTTSRequest->AppendTextForSynthesis(AdditionalText, bContinuousMode);
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Successfully appended text: %s"), *AdditionalText);
}
}
}
// Configure continuous text buffering with custom timeout
UFUNCTION(BlueprintCallable)
void SetupAdvancedChunkedStreaming()
{
// Call SetContinuousFlushTimeout on the async action object
if (ChunkedTTSRequest)
{
// Set automatic flush timeout to 1.5 seconds
// Text will be automatically processed if no new text arrives within this timeframe
ChunkedTTSRequest->SetContinuousFlushTimeout(1.5f);
}
}
// Example of handling real-time AI chat response synthesis
UFUNCTION(BlueprintCallable)
void HandleAIChatResponseForTTS(const FString& ChatChunk, bool IsStreamFinalChunk)
{
if (ChunkedTTSRequest)
{
if (!IsStreamFinalChunk)
{
// Append each chat chunk in continuous mode
// The system will automatically extract complete sentences for synthesis
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
}
else
{
// Add the final chunk
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
// Flush any remaining buffered text and finish the session
ChunkedTTSRequest->FlushContinuousBuffer();
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
}
// Example of immediate chunk processing (bypassing sentence boundary detection)
UFUNCTION(BlueprintCallable)
void AppendImmediateText(const FString& Text)
{
// Call AppendTextForSynthesis with continuous mode = false on the async action object
if (ChunkedTTSRequest)
{
// Use continuous mode = false for immediate processing
// Useful when you have complete sentences or phrases ready
ChunkedTTSRequest->AppendTextForSynthesis(Text, false);
}
}
UFUNCTION(BlueprintCallable)
void FinishChunkedTTS()
{
// Call FlushContinuousBuffer and FinishChunkedStreaming on the async action object
if (ChunkedTTSRequest)
{
// Flush any remaining buffered text
ChunkedTTSRequest->FlushContinuousBuffer();
// Mark the session as finished
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
Kluczowe funkcje ElevenLabs Chunked Streaming:
- Tryb ciągły: Gdy
bContinuousModejest ustawione natrue, tekst jest buforowany do momentu wykrycia granic pełnych zdań, a następnie przetwarzany do syntezy - Tryb natychmiastowy: Gdy
bContinuousModejest ustawione nafalse, tekst jest przetwarzany natychmiast jako oddzielne fragmenty bez buforowania - Automatyczne opróżnianie: Konfigurowalny limit czasu przetwarza buforowany tekst, gdy w określonym czasie nie pojawi się nowe wejście
- Wykrywanie granic zdań: Wykrywa zakończenia zdań (., !, ?) i wyodrębnia pełne zdania z buforowanego tekstu
- Integracja w czasie rzeczywistym: Obsługuje przyrostowe wprowadzanie tekstu, gdzie treść dociera w fragmentach w czasie
- Elastyczne dzielenie tekstu na fragmenty: Dostępne są różne strategie (Priorytet zdań, Ścisłe zdania, Na podstawie rozmiaru) do optymalizacji przetwarzania syntezy
Pobieranie dostępnych głosów
Niektórzy dostawcy TTS oferują API do listowania głosów, umożliwiające programowe odkrywanie dostępnych głosów.
- Google Cloud Voices
- Azure Voices
- Blueprint
- C++
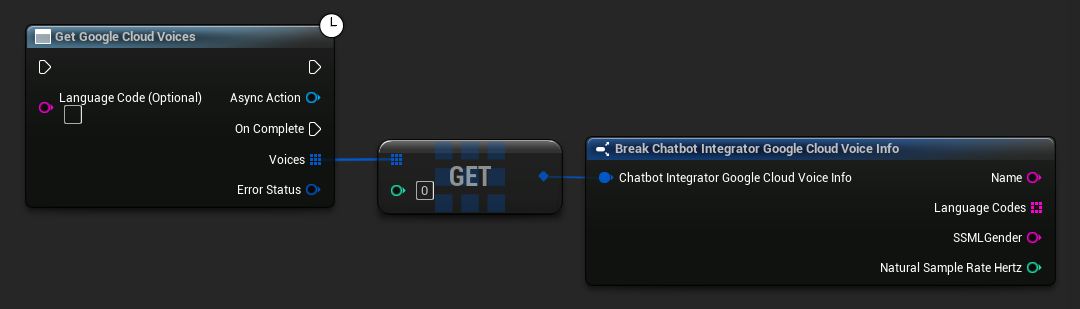
// Example of getting available voices from Google Cloud
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.Name, *Voice.SSMLGender);
}
}
}
)
);
- Blueprint
- C++
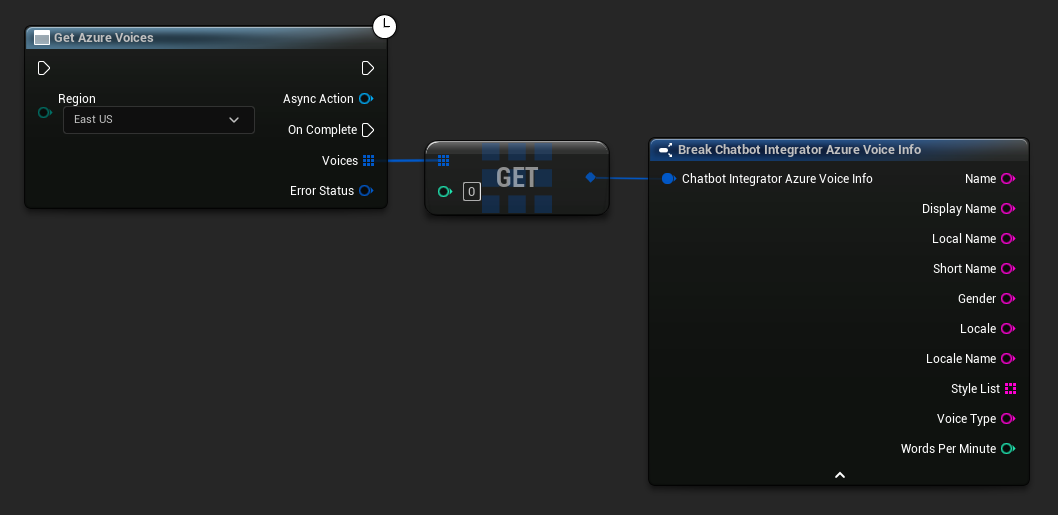
// Example of getting available voices from Azure
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.DisplayName, *Voice.Gender);
}
}
}
)
);
Listowanie modeli Ollama
Możesz zapytać swoją lokalną instancję Ollama o wszystkie dostępne modele za pomocą funkcji ListOllamaModels. Może to być przydatne, na przykład do dynamicznego wypełniania selektora modeli w interfejsie użytkownika. Pomocnicza funkcja GetModelNames wyodrębnia dla wygody tylko ciągi znaków z nazwami z wyniku.
- Blueprint
- C++
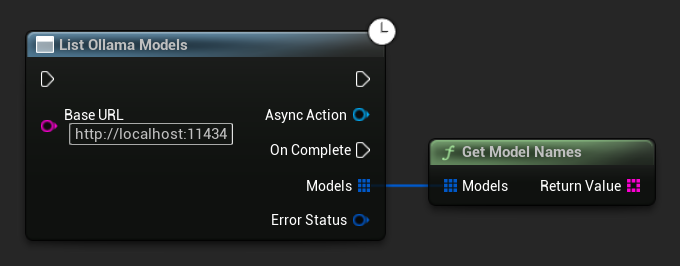
// Example of listing locally available Ollama models
UAIChatbotIntegratorOllamaModelList::ListModelsNative(
TEXT("http://localhost:11434"),
FOnOllamaListModelsResponseNative::CreateWeakLambda(
this,
[this](const TArray<FOllamaModelInfo>& Models, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const FOllamaModelInfo& Model : Models)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s | Family: %s | Parameters: %s | Quantization: %s | Size: %lld bytes"),
*Model.Name, *Model.Family, *Model.ParameterSize, *Model.QuantizationLevel, Model.Size);
}
// Convenience helper to get just the name strings, e.g. for a UI dropdown
TArray<FString> ModelNames = UAIChatbotIntegratorOllamaModelList::GetModelNames(Models);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to list Ollama models: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
Obsługa Błędów
Podczas wysyłania jakichkolwiek żądań, kluczowe jest obsłużenie potencjalnych błędów poprzez sprawdzenie ErrorStatus w swoim wywołaniu zwrotnym. ErrorStatus dostarcza informacji o wszelkich problemach, które mogą wystąpić podczas żądania.
- Blueprint
- C++
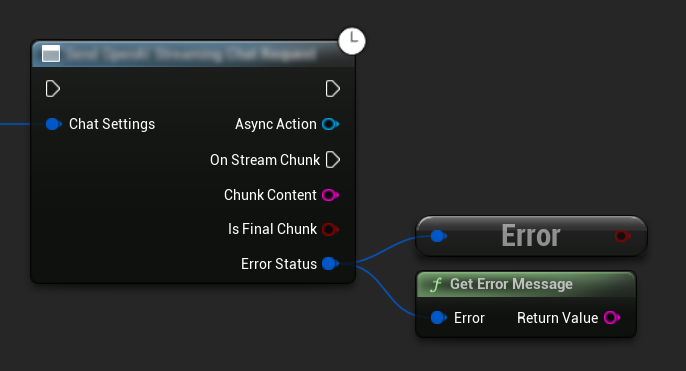
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
Anulowanie Żądań
Wtyczka umożliwia anulowanie zarówno żądań tekst-na-tekst, jak i TTS, gdy są one w trakcie przetwarzania. Może to być przydatne, gdy chcesz przerwać długotrwałe żądanie lub dynamicznie zmienić przebieg konwersacji.
- Blueprint
- C++
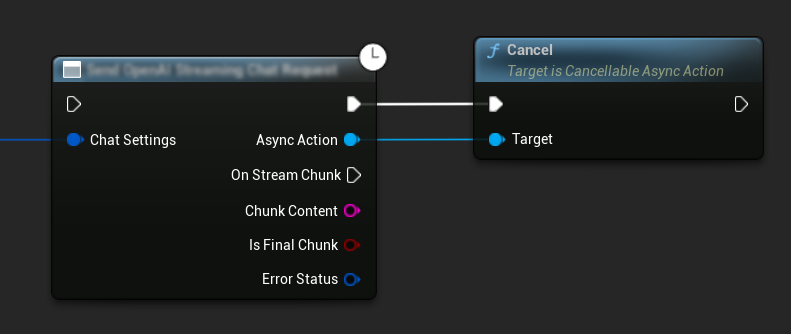
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
Najlepsze Praktyki
- Zawsze obsługuj potencjalne błędy, sprawdzając
ErrorStatusw swoim wywołaniu zwrotnym - Zwracaj uwagę na limity szybkości API i koszty dla każdego dostawcy
- Używaj trybu strumieniowania dla długich lub interaktywnych konwersacji
- Rozważ anulowanie żądań, które nie są już potrzebne, aby efektywnie zarządzać zasobami
- Używaj strumieniowego TTS dla dłuższych tekstów, aby zmniejszyć postrzegane opóźnienie
- Do przetwarzania dźwięku, wtyczka Runtime Audio Importer oferuje wygodne rozwiązanie, ale możesz zaimplementować własne przetwarzanie w oparciu o potrzeby swojego projektu
- Używając modeli wnioskujących (DeepSeek Reasoner, Grok), odpowiednio obsługuj zarówno wyjścia z rozumowania, jak i treści
- Odkrywaj dostępne głosy za pomocą API listowania głosów przed implementacją funkcji TTS
- Dla strumieniowania ElevenLabs z podziałem na fragmenty: Używaj trybu ciągłego, gdy tekst jest generowany przyrostowo (jak odpowiedzi AI) i trybu natychmiastowego dla wcześniej utworzonych fragmentów tekstu
- Konfiguruj odpowiednie limity czasu opróżniania dla trybu ciągłego, aby zrównoważyć responsywność z naturalnym przepływem mowy
- Wybieraj optymalne rozmiary fragmentów i opóźnienia wysyłki w oparciu o wymagania czasu rzeczywistego Twojej aplikacji
- Dla Ollama: Używaj
ListOllamaModels, aby dynamicznie odkrywać dostępne modele, zamiast na stałe wpisywać ich nazwy
Rozwiązywanie Problemów
- Sprawdź, czy Twoje dane uwierzytelniające API są poprawne dla każdego dostawcy
- Sprawdź swoje połączenie internetowe
- Upewnij się, że wszelkie używane biblioteki do przetwarzania dźwięku (takie jak Runtime Audio Importer) są poprawnie zainstalowane podczas pracy z funkcjami TTS
- Sprawdź, czy używasz poprawnego formatu audio podczas przetwarzania danych odpowiedzi TTS
- Dla strumieniowego TTS, upewnij się, że poprawnie obsługujesz fragmenty audio
- Dla modeli wnioskujących, upewnij się, że przetwarzasz zarówno wyjścia z rozumowania, jak i treści
- Sprawdź dokumentację specyficzną dla dostawcy pod kątem dostępności i możliwości modeli
- Dla strumieniowania ElevenLabs z podziałem na fragmenty: Upewnij się, że wywołujesz
FinishChunkedStreamingpo zakończeniu, aby poprawnie zamknąć sesję - W przypadku problemów z trybem ciągłym: Sprawdź, czy granice zdań są poprawnie wykrywane w Twoim tekście
- Dla aplikacji czasu rzeczywistego: Dostosuj opóźnienia wysyłki fragmentów i limity czasu opróżniania w oparciu o swoje wymagania dotyczące opóźnienia
- Dla Ollama: Upewnij się, że serwer Ollama jest uruchomiony i dostępny pod skonfigurowanym
BaseUrlprzed wysłaniem żądań