Jak używać wtyczki
Ten przewodnik obejmuje pełne API środowiska uruchomieniowego: tworzenie instancji LLM, ładowanie modeli, wysyłanie wiadomości, pobieranie modeli w czasie działania, zarządzanie stanem i funkcje narzędziowe.
Utwórz instancję LLM
Zacznij od utworzenia obiektu Runtime Local LLM. Utrzymuj do niego referencję (np. jako zmienną w Blueprints lub UPROPERTY w C++), aby zapobiec przedwczesnemu odśmiecaniu.
- Blueprint
- C++
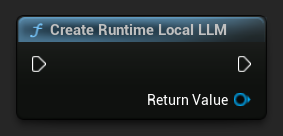
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
Ładowanie modelu
Musisz załadować model przed wysłaniem wiadomości. Wtyczka oferuje kilka metod ładowania w zależności od Twojego przepływu pracy.
Ładowanie po nazwie
Jeśli zarządzasz modelami za pomocą panelu ustawień edytora, użyj Load Model (By Name).
- Blueprint
- C++
- UE 5.3 i wcześniejsze
- UE 5.4 i nowsze
W UE 5.3 i wcześniejszych wersjach menu rozwijane nie jest wyświetlane, więc musisz ręcznie pobrać dostępne modele. Użyj Get All Downloaded Model Metadata, pobierz element o indeksie 0 (lub dowolny potrzebny model), przekaż go do Get Model File Name, aby uzyskać ciąg znaków z nazwą, a następnie przekaż tę nazwę do Load Model (By Name).
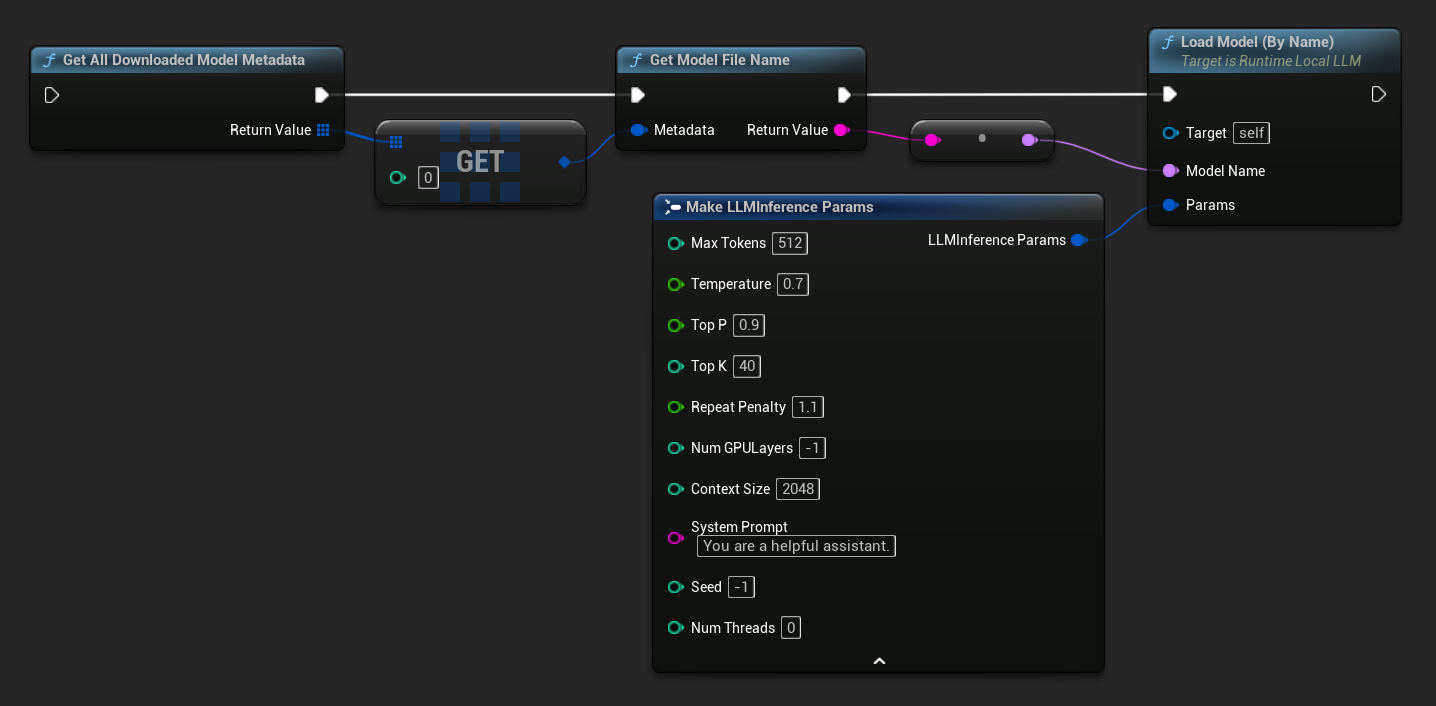
W UE 5.4 i nowszych wersjach Load Model (By Name) wyświetla menu rozwijane ze wszystkimi modelami na dysku – po prostu wybierz model, który chcesz załadować.
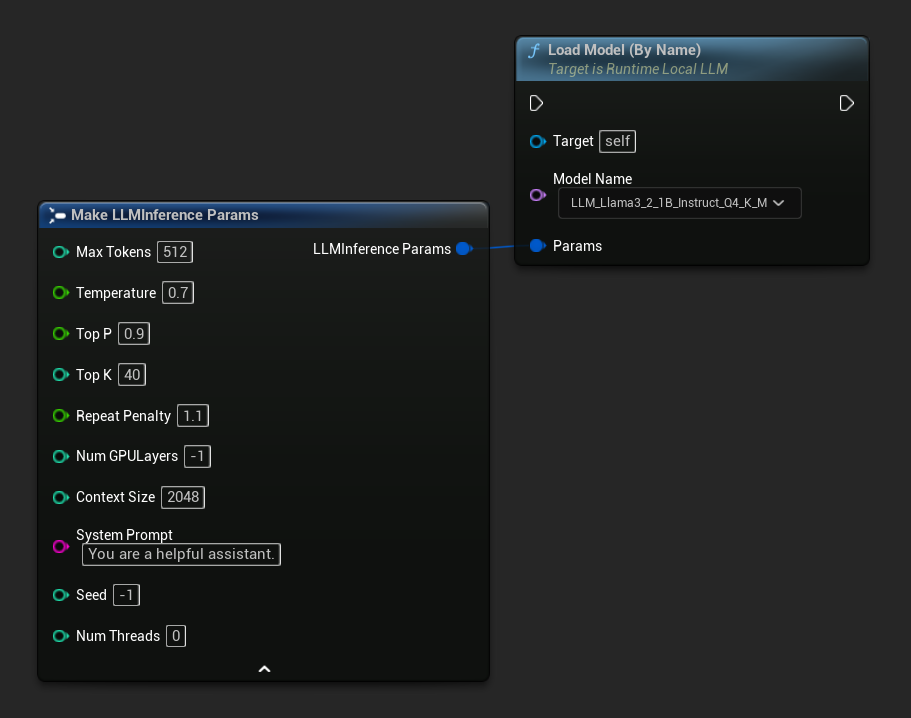
W C++ użyj GetAllDownloadedModelMetadata, aby pobrać dostępne modele, oraz GetModelFileName, aby uzyskać nazwę do przekazania do LoadModelByName:
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
Ładowanie z ścieżki pliku
Wczytaj model bezpośrednio z bezwzględnej ścieżki pliku do pliku .gguf:
- Blueprint
- C++
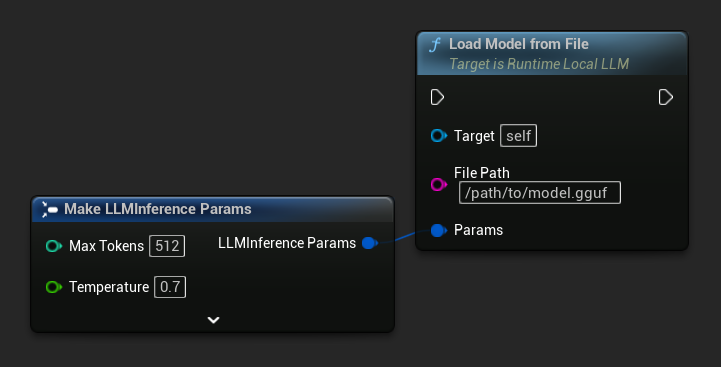
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
Ładowanie z adresu URL (Pobieranie i ładowanie)
Pobiera model z adresu URL (jeśli nie znajduje się już na dysku) i automatycznie go ładuje. Jeśli plik istnieje lokalnie, pobieranie jest pomijane.
- Blueprint
- C++
Najprostszy wariant przyjmuje tylko adres URL – metadane są wyodrębniane z nazwy pliku:
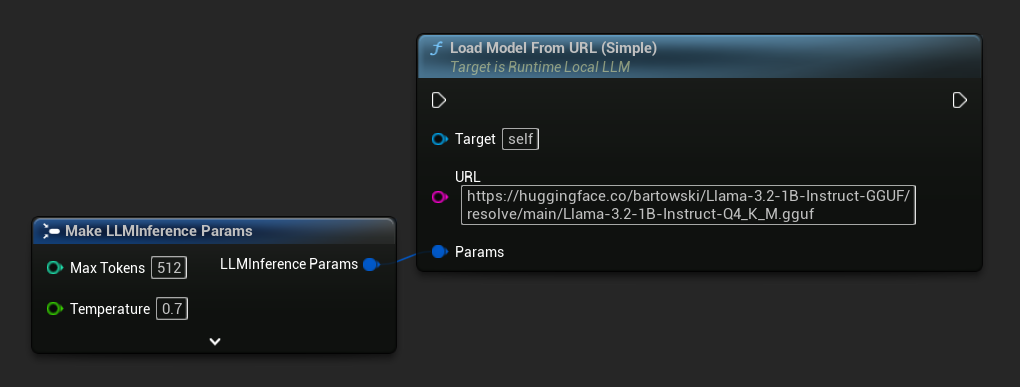
Możesz również użyć Load Model From URL z pełnymi metadanymi modelu, aby uzyskać bogatsze informacje o modelu:
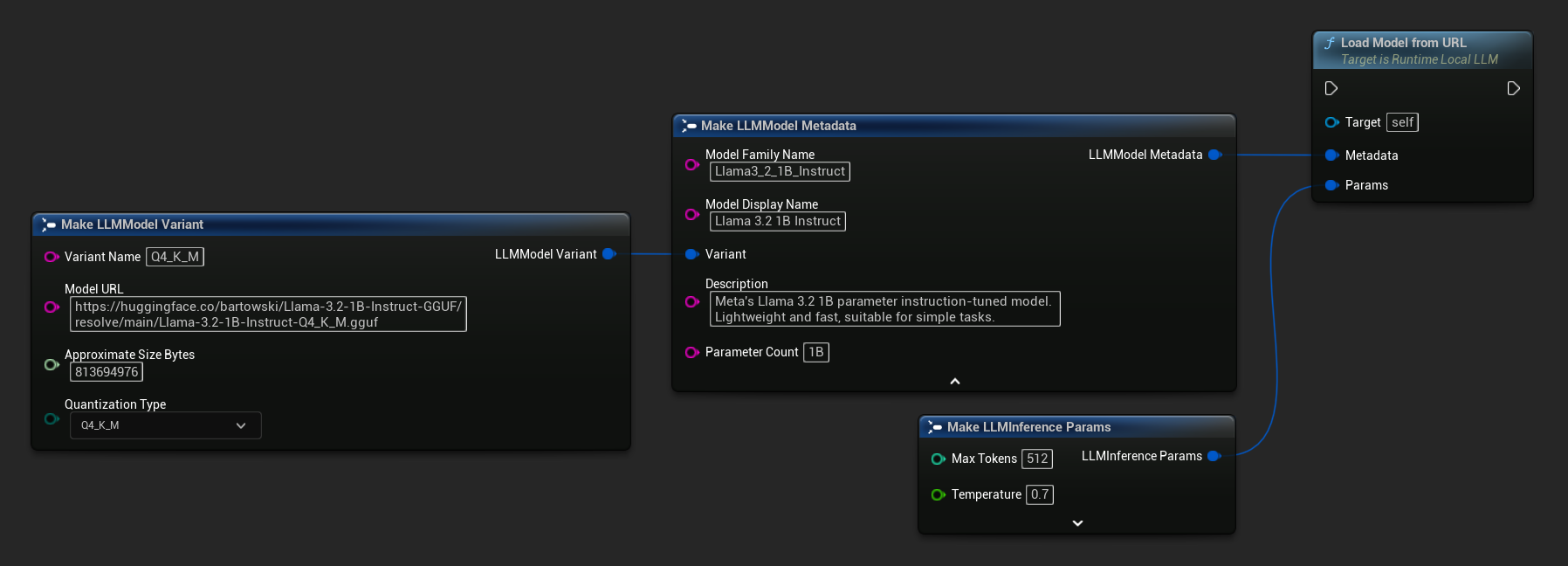
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
Ładowanie asynchroniczne (Blueprint)
Aby obsłużyć zakończenie ładowania i błędy poprzez piny wyjściowe zamiast ręcznego podpinania delegatów, dostępne są dwa węzły asynchroniczne.
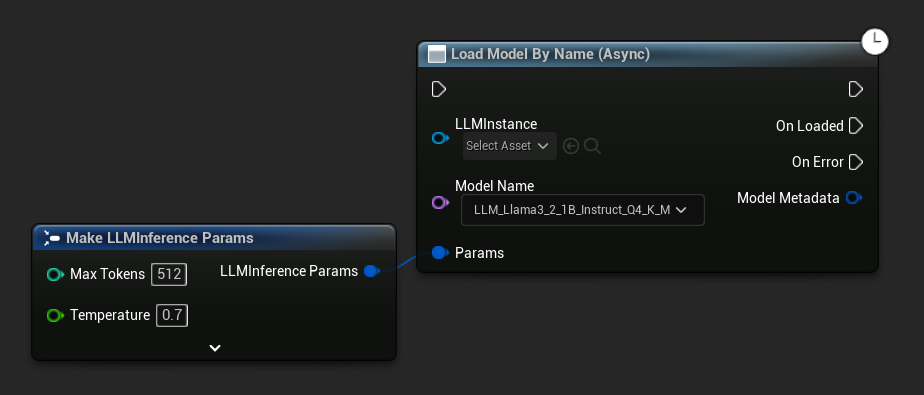
Load Model By Name (Async) odwzorowuje Load Model (By Name) – w UE 5.4+ wyświetla listę rozwijaną wszystkich modeli na dysku:
- UE 5.4+
- UE 5.3 and earlier
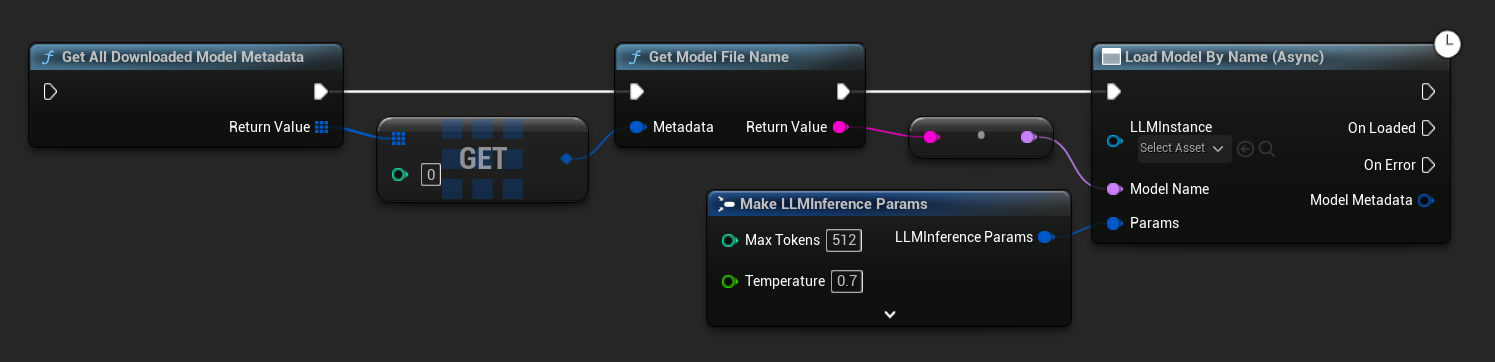
W UE 5.3 i wcześniejszych lista rozwijana nie jest widoczna. Użyj Get All Downloaded Model Metadata, pobierz element o indeksie 0 (lub dowolny model, którego potrzebujesz), przekaż go do Get Model File Name, a następnie przekaż to do Load Model By Name (Async).
Load Model From File (Async) przyjmuje zamiast tego ścieżkę bezwzględną do pliku:
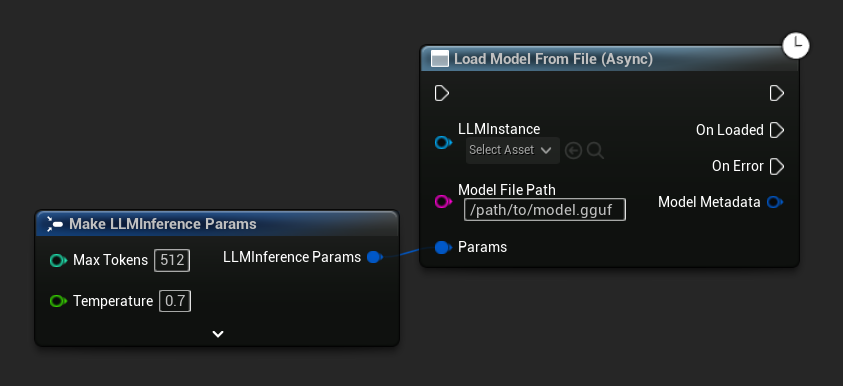
Podpinanie zdarzeń
Podepnij się do delegatów instancji LLM, aby otrzymywać wywołania zwrotne. Wszystkie wywołania zwrotne są wyzwalane na wątku gry.
- Blueprint
- C++
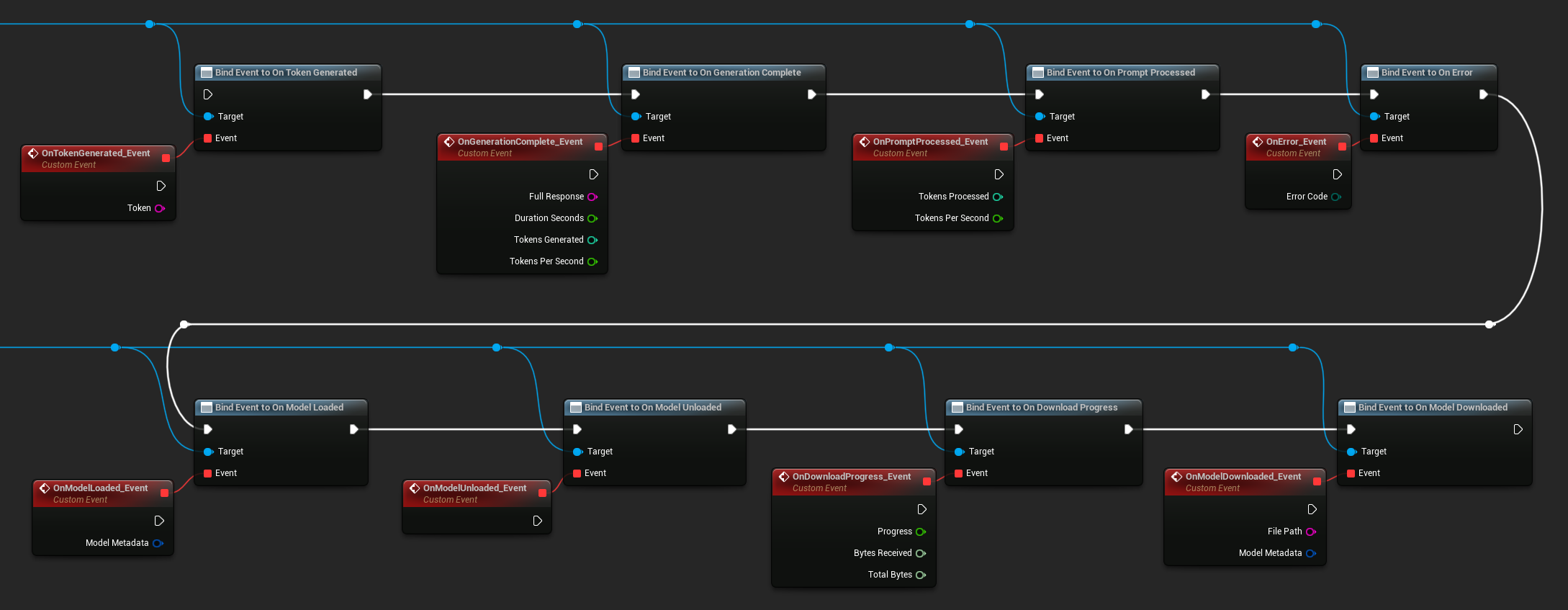
Dostępne delegaty:
- On Token Generated: wyzwala się dla każdego tokena wyjściowego
- On Generation Complete: wyzwala się, gdy pełna odpowiedź jest gotowa, wraz z czasem trwania, liczbą tokenów i tokenów na sekundę
- On Prompt Processed: wyzwala się po przetworzeniu zapytania wejściowego, przed rozpoczęciem generowania
- On Error: wyzwala się, jeśli wystąpi błąd podczas dowolnej operacji
- On Model Loaded: wyzwala się, gdy model zakończy ładowanie
- On Model Unloaded: wyzwala się, gdy model zostanie wyładowany
- On Download Progress: wyzwala się okresowo podczas pobierania modelu (postęp w formie ułamka, odebrane bajty, całkowita liczba bajtów)
- On Model Downloaded: wyzwala się, gdy operacja pobierania zakończy się
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda([](const FString& FullResponse)
{
});
LLM->OnPromptProcessedNative.AddLambda([]()
{
});
LLM->OnErrorNative.AddLambda([](const FString& ErrorMessage)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FString& ModelName)
{
});
LLM->OnModelUnloadedNative.AddLambda([](const FString& ModelName)
{
});
LLM->OnDownloadProgressNative.AddLambda([](const FString& ModelName, float Progress)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& ModelName)
{
});
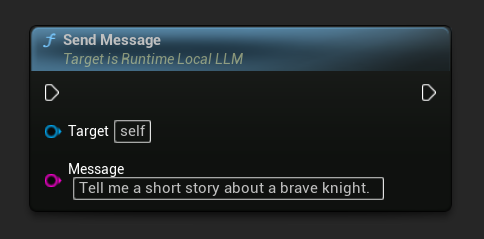
Wysyłanie wiadomości
Po załadowaniu modelu, wyślij wiadomość użytkownika, aby wygenerować odpowiedź:
- Blueprint
- C++
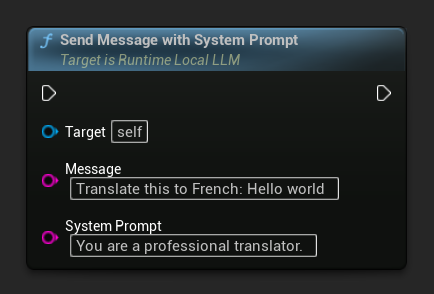
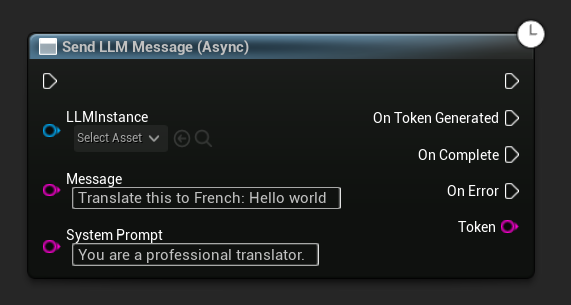
Aby zastąpić zachętę systemową dla konkretnej wiadomości, użyj Send Message With System Prompt:
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
Tokeny przepływają przez OnTokenGenerated w miarę jak są generowane. Gdy generowanie się zakończy, OnGenerationComplete wywoływane jest z pełną odpowiedzią, czasem trwania, liczbą tokenów i tokenami na sekundę.
Asynchroniczne wysyłanie wiadomości (Blueprint)
Węzeł Send LLM Message (Async) zapewnia dedykowane piny wyjściowe dla tokenów, zakończenia i błędów:
Pobieranie modeli w czasie wykonywania
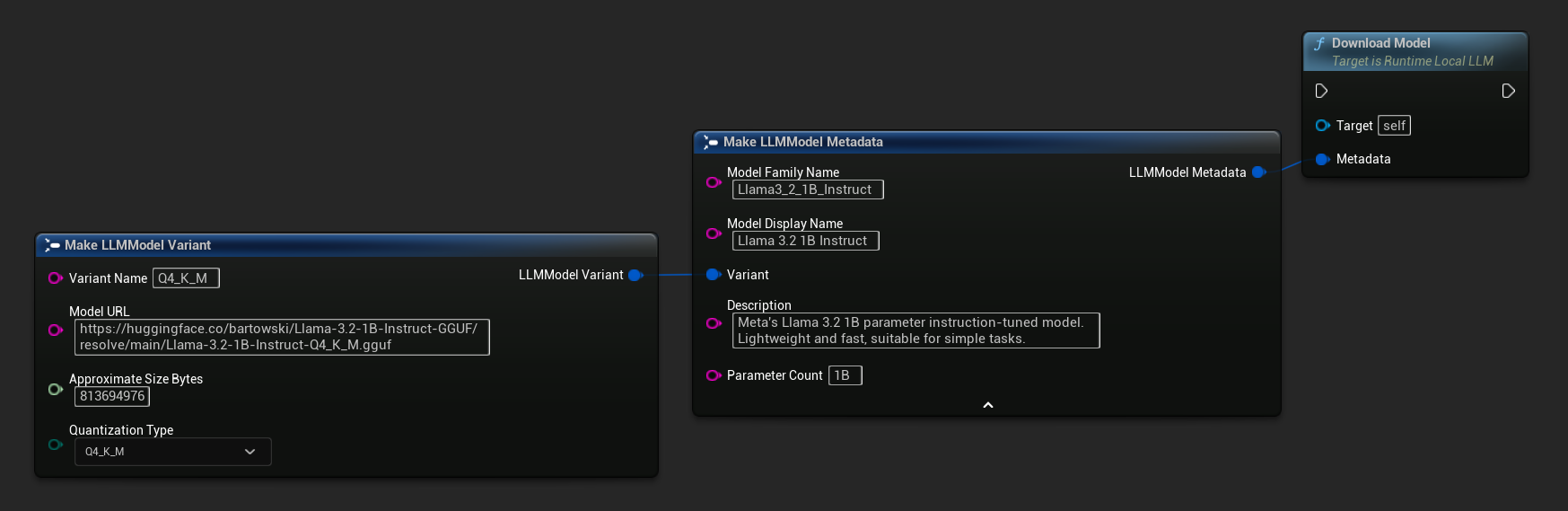
Oprócz opisanego powyżej przepływu pobierz-i-załaduj, możesz pobrać model na dysk bez jego ładowania. Jest to przydatne do wstępnego buforowania modeli na ekranie ładowania lub w menu ustawień.
- Blueprint
- C++
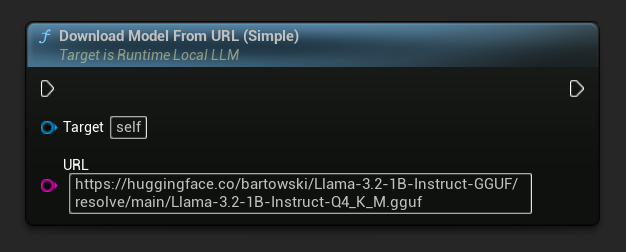
Dostępny jest również wariant tylko z adresem URL:
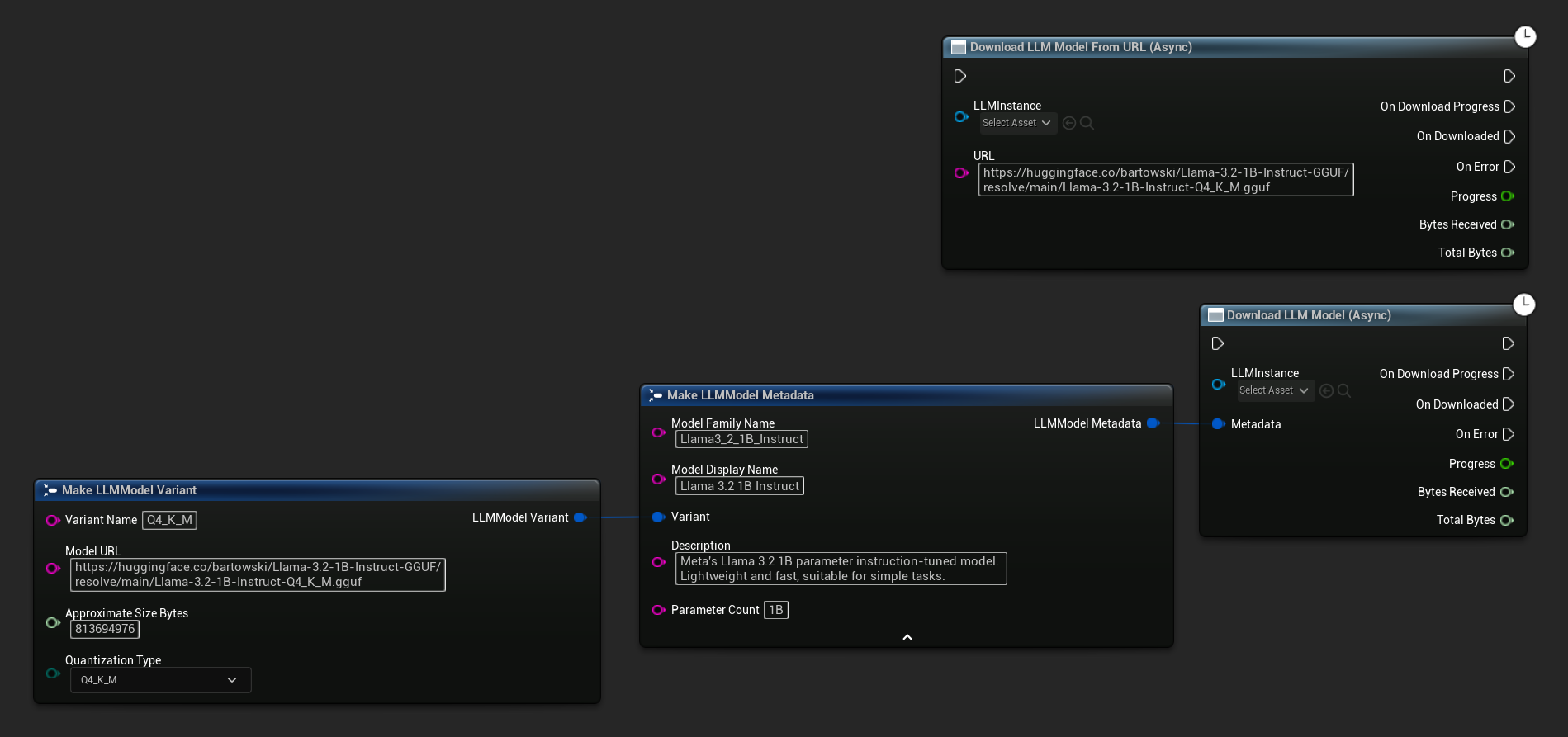
Węzeł Download LLM Model (Async) i Download LLM Model From URL (Async) zapewnia piny wyjściowe dla postępu, zakończenia i błędów:
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
Delegat OnDownloadProgress raportuje postęp podczas pobierania. OnModelDownloaded jest wywoływany, gdy plik zostanie zapisany na dysku.
Aby anulować trwające pobieranie:
- Blueprint
- C++
LLM->CancelDownload();
Wtyczka automatycznie zapobiega duplikowaniu pobrań — jeśli pobieranie dla tego samego modelu jest już w toku, kolejne wywołania są ignorowane.
Zatrzymanie generowania
Aby przerwać trwającą generację:
- Blueprint
- C++
LLM->StopGeneration();
Resetuj kontekst rozmowy
Wyczyść historię rozmowy, aby rozpocząć nową rozmowę:
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
Wyładuj model
Zwolnij zasoby, gdy model nie jest już potrzebny:
- Blueprint
- C++
LLM->UnloadModel();
Query State
Sprawdź bieżący stan instancji LLM:
- Blueprint
- C++
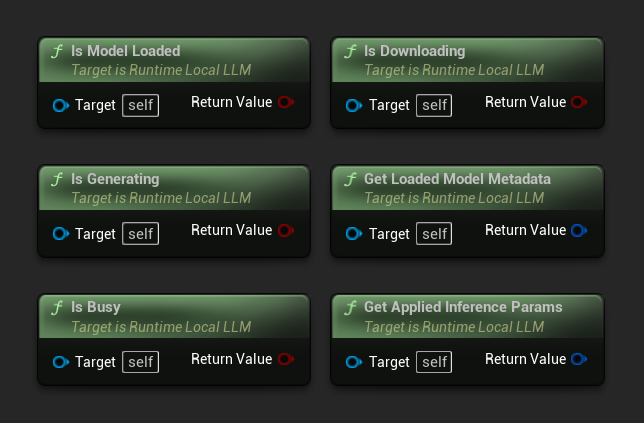
- Is Model Loaded: Prawda, jeśli model jest gotowy do wnioskowania
- Is Generating: Prawda, jeśli generowanie jest w toku
- Is Busy: Prawda, jeśli trwa jakakolwiek operacja (ładowanie, generowanie, pobieranie)
- Is Downloading: Prawda, jeśli trwa pobieranie modelu
- Get Loaded Model Metadata: Zwraca metadane bieżącego modelu
- Get Applied Inference Params: Zwraca parametry zastosowane przy ładowaniu
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
Funkcje biblioteki modeli
Udostępniony jest zestaw statycznych funkcji narzędziowych do zarządzania plikami modeli na dysku. Są one przydatne przy tworzeniu interfejsu wyboru modelu lub sprawdzaniu dostępności modelu w czasie działania.
Pobieranie nazw pobranych modeli / metadanych
- Blueprint
- C++
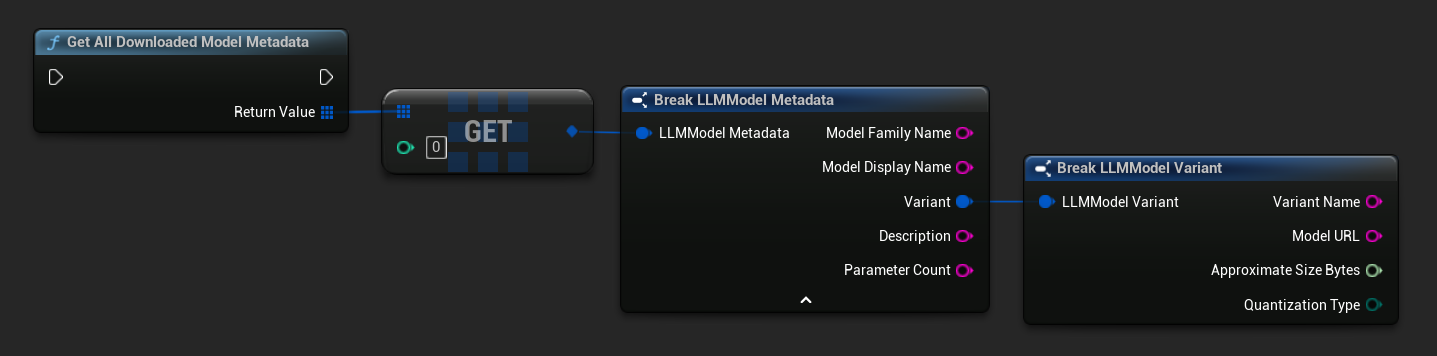
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
Sprawdź, czy model znajduje się na dysku
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
Pobierz ścieżkę pliku modelu
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
Usuń pliki modelu
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
Uzyskiwanie predefiniowanych i dostępnych modeli
- Blueprint
- C++
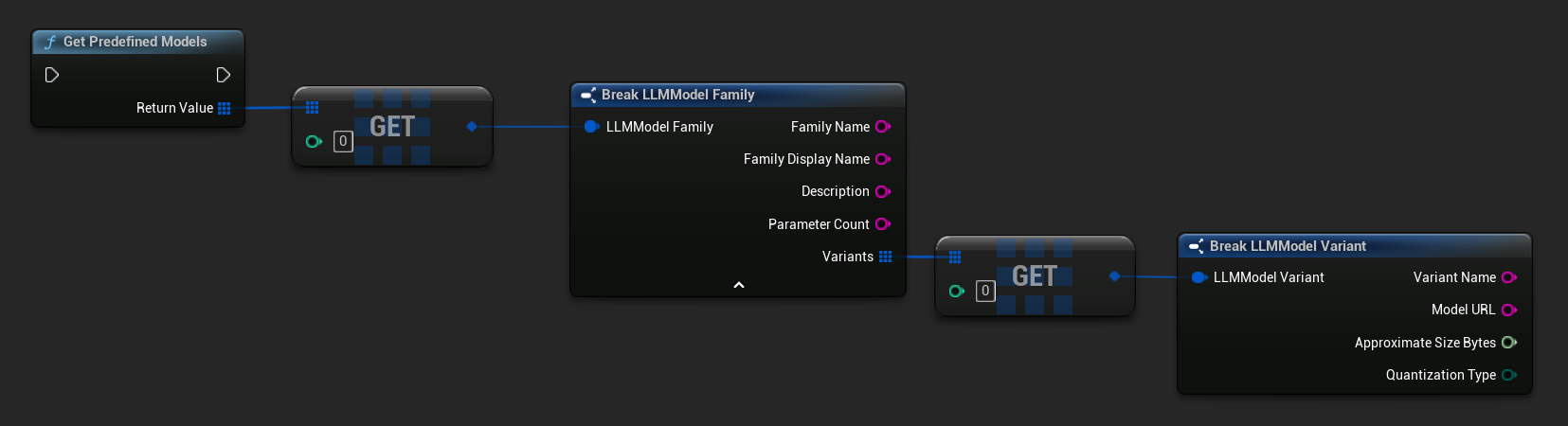
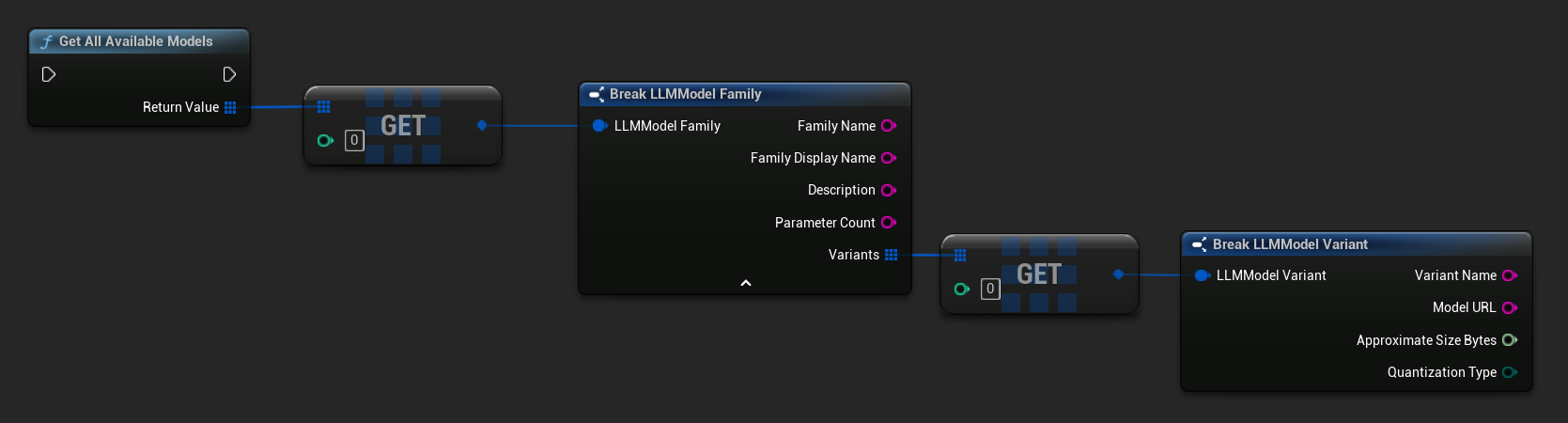
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
</TabItem>
</Tabs>
### Budowanie metadanych z adresu URL {/* #build-metadata-from-url */}
Tworzenie metadanych modelu z surowego adresu URL (pola pochodzą z nazwy pliku):
<Tabs groupId="languages">
<TabItem value="blueprint" label="Blueprint">
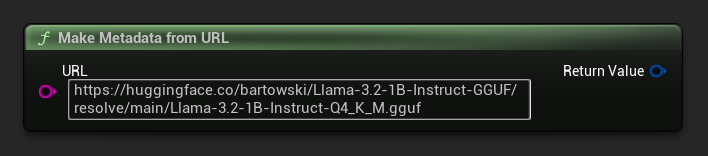
</TabItem>
<TabItem value="c++" label="C++">
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
Funkcje narzędziowe
Dostarczono zestaw funkcji pomocniczych do formatowania i wyświetlania błędów.
Konwersja bajtów na czytelny ciąg znaków
Konwertuje liczbę bajtów na czytelny dla człowieka ciąg znaków (np. „4,07 GB”). Przydatne do wyświetlania rozmiarów modeli w interfejsie.
Formatowanie postępu pobierania
Formatuje ciąg postępu pobierania w formie „1,23 GB / 4,07 GB (30,2%)”. Jeśli całkowity rozmiar jest nieznany, zwraca tylko odebraną ilość.
Pobierz opis błędu / ciąg kodu błędu
Get LLM Error Description zwraca czytelny dla człowieka opis tekstowy dla kodu błędu. Get LLM Error Code String zwraca nazwę wartości enum jako ciąg znaków (przydatne do logowania).
Referencja kodów błędów
| Kod | Wartość | Opis |
|---|---|---|
| Unknown | 0 | Nieokreślony błąd |
| ModelLoadFailed | 10 | Plik GGUF nie mógł zostać załadowany (uszkodzony plik, niekompatybilny format itp.) |
| ContextCreateFailed | 11 | Nie udało się utworzyć kontekstu wnioskowania |
| ModelNotLoaded | 20 | Próbowano przeprowadzić wnioskowanie bez załadowanego modelu |
| ChatTemplateFailed | 21 | Nie udało się zastosować szablonu czatu modelu |
| TokenizationFailed | 22 | Nie udało się tokenizować tekstu wejściowego |
| ContextOverflow | 23 | Prompt + kontekst przekracza skonfigurowany rozmiar kontekstu |
| PromptDecodeFailed | 24 | Nie udało się zdekodować tokenów promptu |
| ContextTooFullToGenerate | 25 | Niewystarczająca ilość wolnego miejsca w kontekście, aby wygenerować wyjście |
| GenerationDecodeFailed | 30 | Nie udało się zdekodować tokenu podczas generowania |
| GenerationTruncated | 31 | Generowanie zostało zatrzymane, ponieważ osiągnięto maksymalny limit tokenów |
| LLMInstanceNull | 40 | Instancja LLM ma wartość null lub jest nieprawidłowa |
| ModelNotFoundOnDisk | 41 | Plik modelu nie istnieje w oczekiwanej ścieżce |
| ModelURLEmpty | 42 | Zażądano pobrania z pustym adresem URL |
| ModelDownloadCancelled | 43 | Pobieranie zostało anulowane |
| ModelDownloadEmptyData | 44 | Pobieranie zakończone, ale treść odpowiedzi była pusta |
| ModelDownloadSaveFailed | 45 | Pobieranie zakończone, ale plik nie mógł zostać zapisany na dysku |