Parametry inferencji
Referencja parametrów
| Parametr | Typ | Domyślnie | Zakres | Opis |
|---|---|---|---|---|
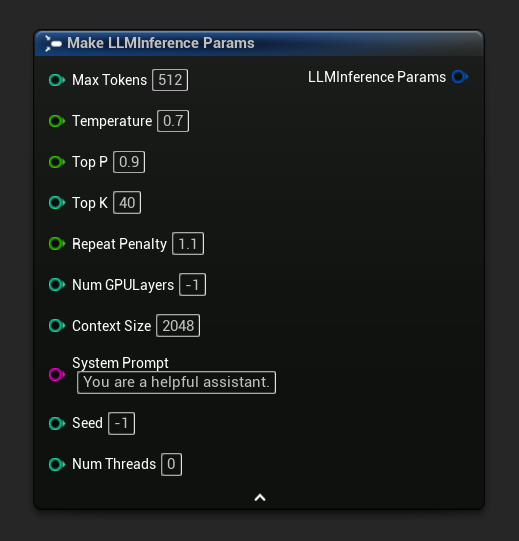
| Max Tokens | int32 | 512 | 1–8192 | Maksymalna liczba tokenów do wygenerowania w pojedynczej odpowiedzi |
| Temperature | float | 0.7 | 0.0–2.0 | Kontroluje losowość. 0.0 = deterministycznie. Wyższe wartości = bardziej kreatywne wyjście |
| Top P | float | 0.9 | 0.0–1.0 | Próbkowanie jądra. Uwzględniane są tylko tokeny, których skumulowane prawdopodobieństwo przekracza tę wartość |
| Top K | int32 | 40 | 0–200 | Ogranicza wybór do K najbardziej prawdopodobnych tokenów. 0 = wyłączone |
| Repeat Penalty | float | 1.1 | 0.0–3.0 | Karze tokeny, które już wystąpiły w wyjściu. 1.0 = brak kary |
| Num GPU Layers | int32 | -1 | -1–200 | Liczba warstw modelu do przeniesienia na GPU. -1 = auto. 0 = tylko CPU |
| Context Size | int32 | 2048 | 128–131072 | Maksymalne okno kontekstu w tokenach. Większe wartości zużywają więcej pamięci |
| System Prompt | FString | "Jesteś pomocnym asystentem." | — | Instrukcja systemowa kształtująca zachowanie modelu |
| Seed | int32 | -1 | -1+ | Ziarno losowe do odtwarzalnych wyników. -1 = losowe |
| Num Threads | int32 | 0 | 0–128 | Wątki CPU do generowania. 0 = automatyczne |
Użycie
- Blueprint
- C++
Parametry inferencji pojawiają się jako pin struktury na węzłach ładowania i asynchronicznych. Rozbij strukturę, aby ustawić poszczególne wartości:
Aby uzyskać domyślny zestaw parametrów jako punkt wyjścia, użyj Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Zalecenia dotyczące platformy
Mobilne / VR (Android, iOS, Meta Quest)
- Rozmiar kontekstu: 1024–2048
- Num GPU Layers: 0 (tylko CPU), chyba że urządzenie ma potwierdzoną obsługę obliczeń GPU
- Max Tokens: Poniżej 256 dla responsywnych interakcji
- Num Threads: 2–4 w zależności od urządzenia
Desktop (Windows, Mac, Linux)
- Rozmiar kontekstu: 2048–8192 dla większości rozmów
- Num GPU Layers: -1 (auto) w celu wykorzystania akceleracji GPU, gdy jest dostępna
- Num Threads: 0 (auto)
- Max Tokens: 512–2048 dla dłuższych odpowiedzi