Przewodnik przetwarzania audio
Ten przewodnik obejmuje konfigurację różnych metod wprowadzania danych audio, które będą zasilać generatory synchronizacji ust. Upewnij się, że ukończyłeś Przewodnik konfiguracji przed kontynuacją.
Przetwarzanie wejścia audio
Musisz skonfigurować metodę przetwarzania wejścia audio. Istnieje kilka sposobów, w zależności od źródła dźwięku.
- Mikrofon (w czasie rzeczywistym)
- Mikrofon (odtwarzanie)
- Zamiana tekstu na mowę (lokalna)
- Zamiana tekstu na mowę (zewnętrzne API)
- Z pliku/bufora audio
- Strumieniowy bufor audio
To podejście wykonuje synchronizację ust w czasie rzeczywistym podczas mówienia do mikrofonu:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Utwórz Capturable Sound Wave za pomocą Runtime Audio Importer
- Dla systemu Linux z Pixel Streaming, użyj zamiast tego Pixel Streaming Capturable Sound Wave
- Przed rozpoczęciem przechwytywania dźwięku, podłącz się do delegata
OnPopulateAudioData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator - Rozpocznij przechwytywanie dźwięku z mikrofonu
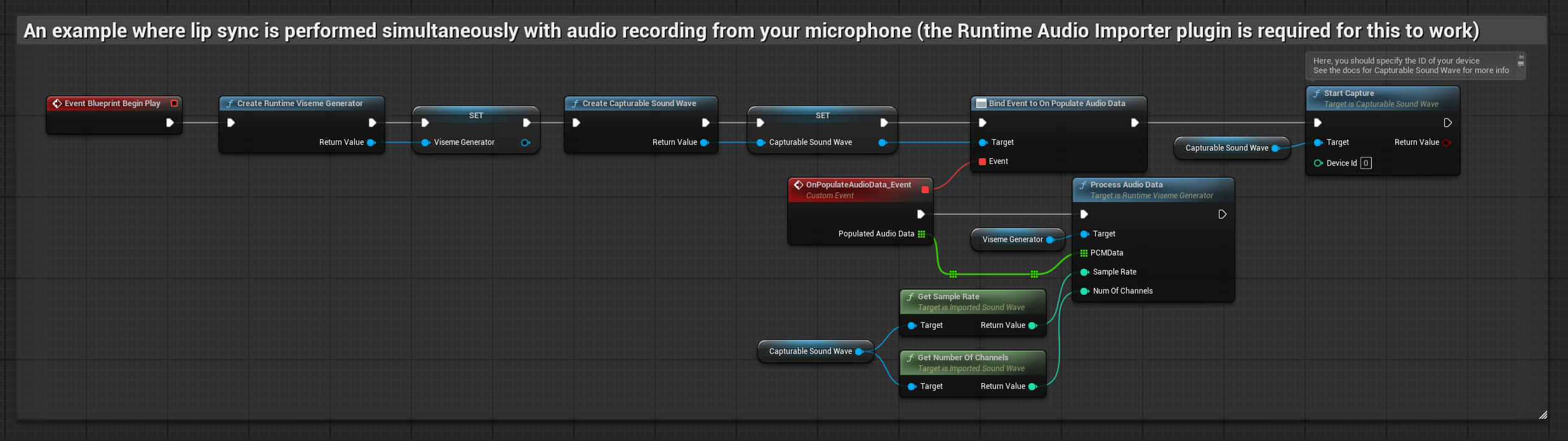
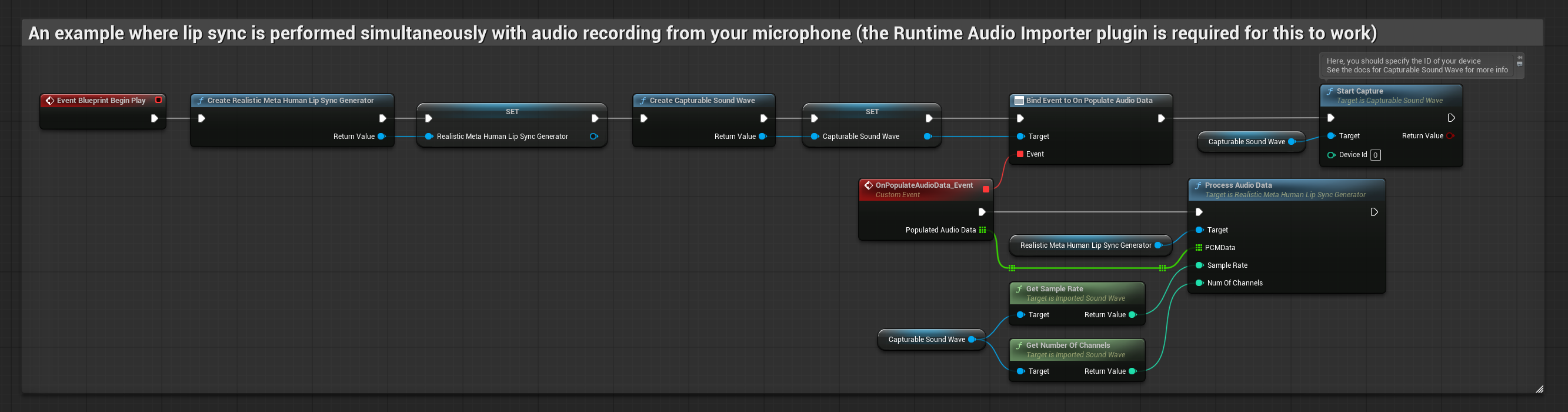
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
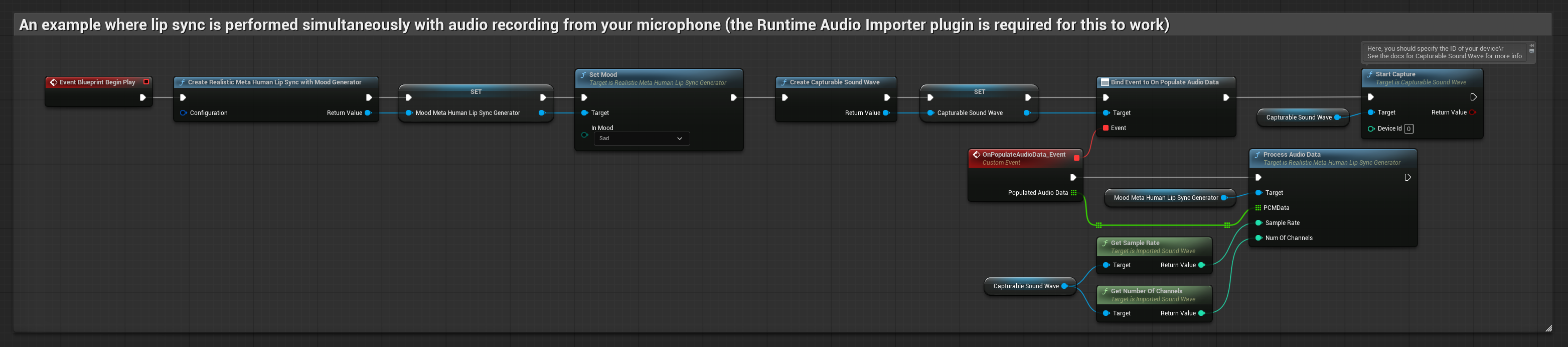
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
To podejście przechwytuje dźwięk z mikrofonu, a następnie odtwarza go z synchronizacją ust:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Utwórz Capturable Sound Wave za pomocą Runtime Audio Importer
- Dla systemu Linux z Pixel Streaming, użyj zamiast tego Pixel Streaming Capturable Sound Wave
- Rozpocznij przechwytywanie dźwięku z mikrofonu
- Przed odtworzeniem przechwytywalnej fali dźwiękowej, podłącz się do jej delegata
OnGeneratePCMData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator
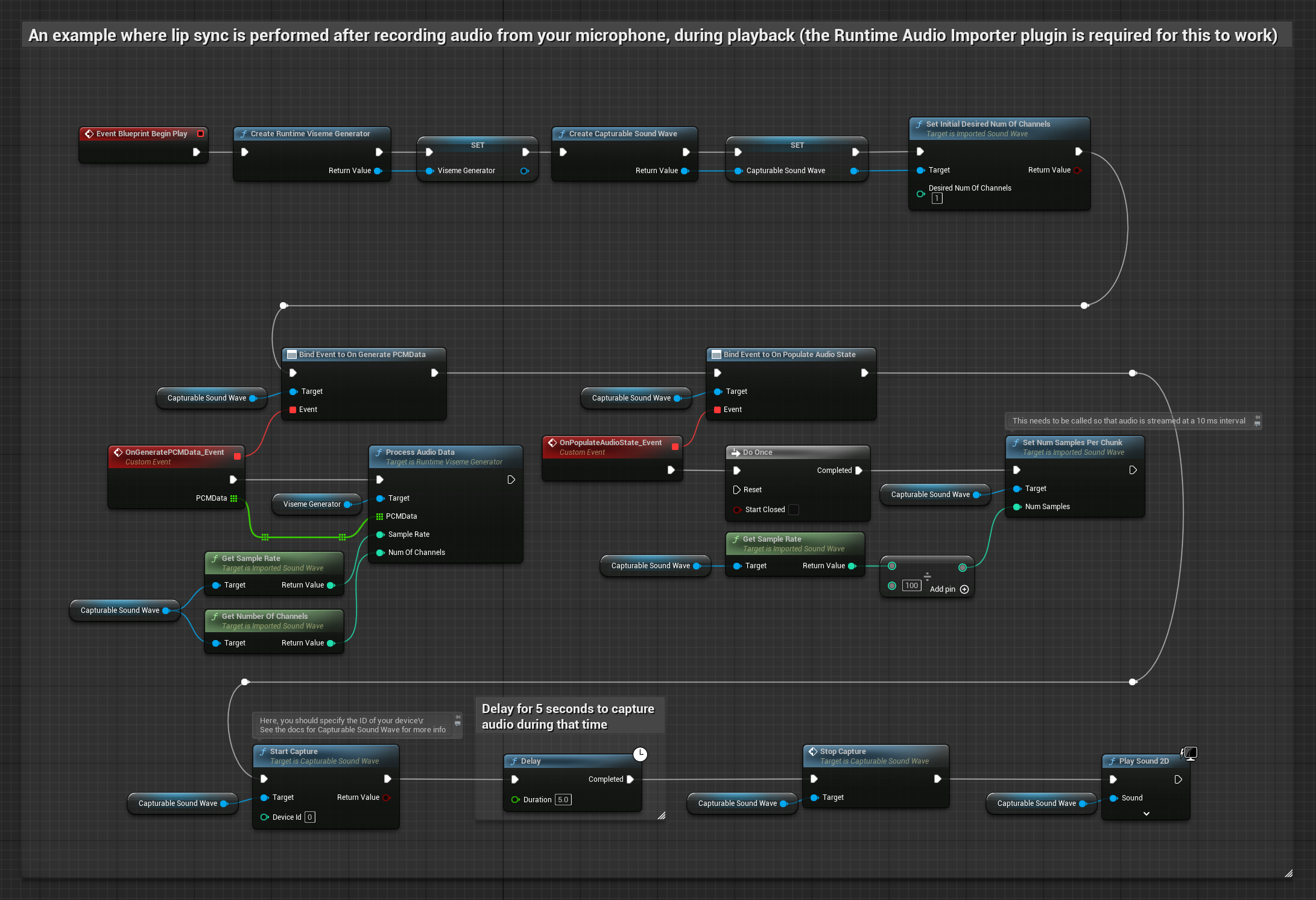
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
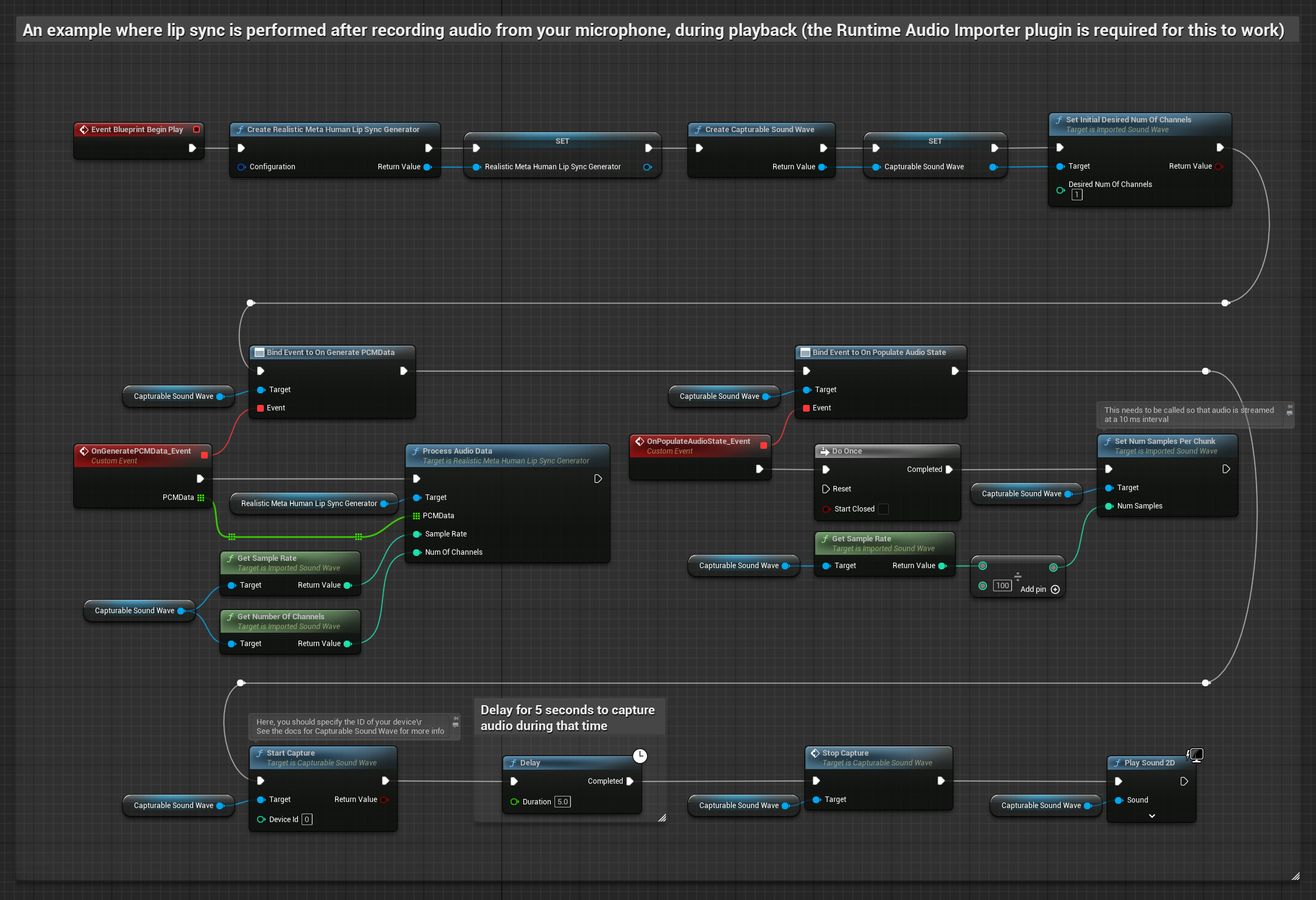
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
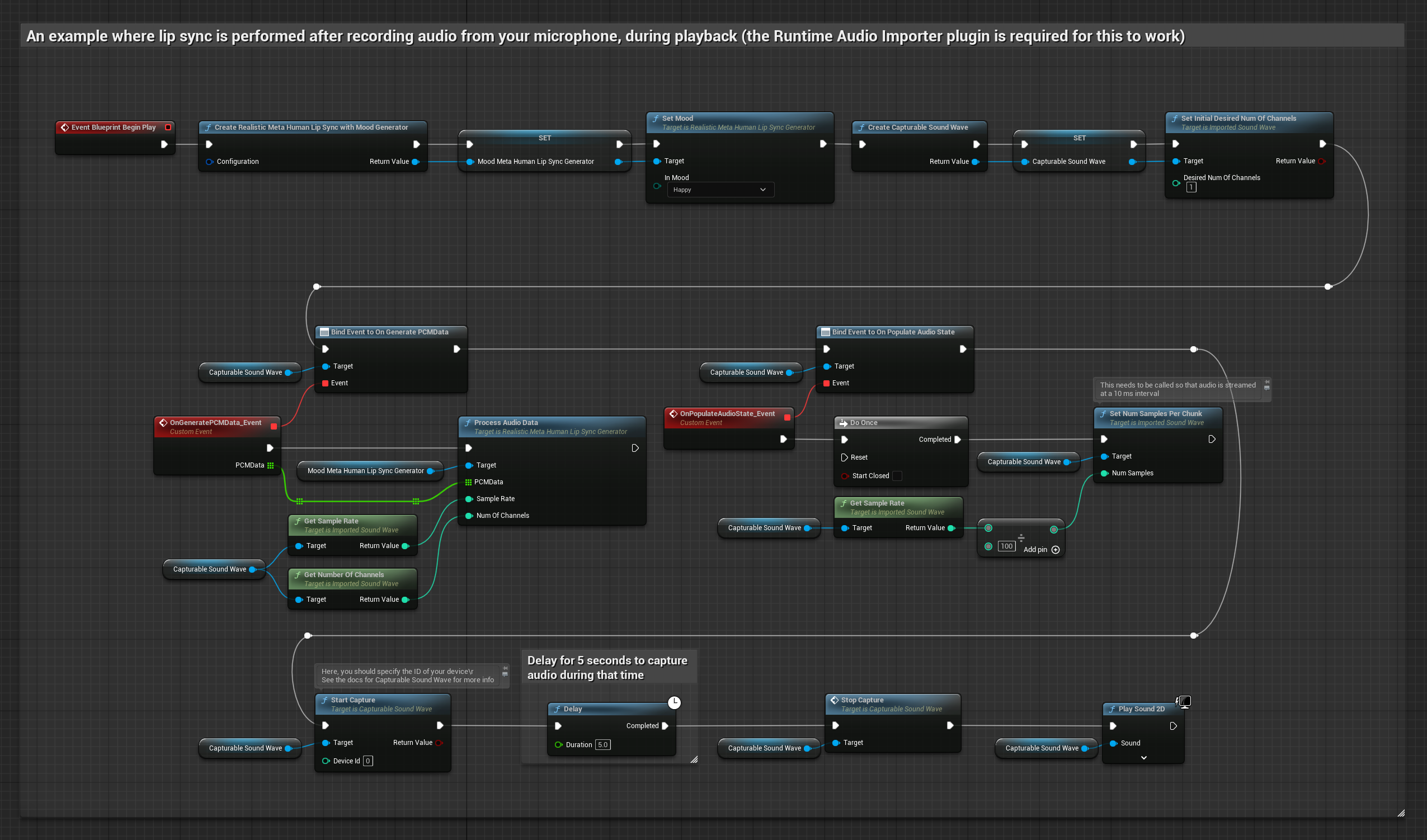
- Zwykła
- Streaming
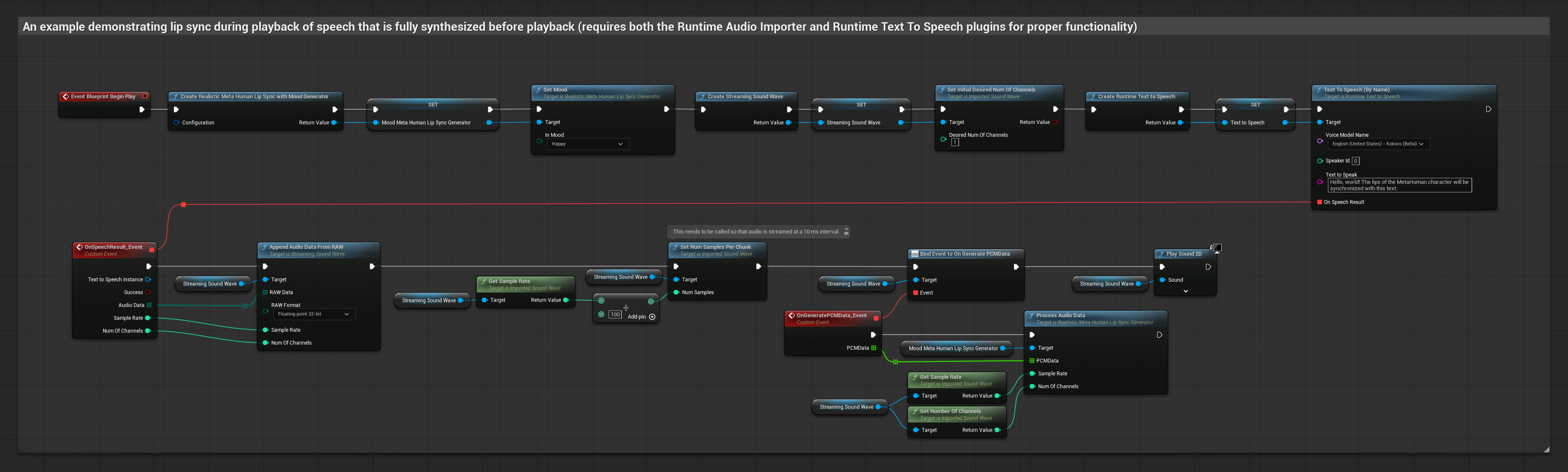
To podejście syntetyzuje mowę z tekstu przy użyciu lokalnego TTS i wykonuje synchronizację ust:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Użyj Runtime Text To Speech do wygenerowania mowy z tekstu
- Użyj Runtime Audio Importer do zaimportowania zsyntetyzowanego dźwięku
- Przed odtworzeniem zaimportowanej fali dźwiękowej, podłącz się do jej delegata
OnGeneratePCMData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator
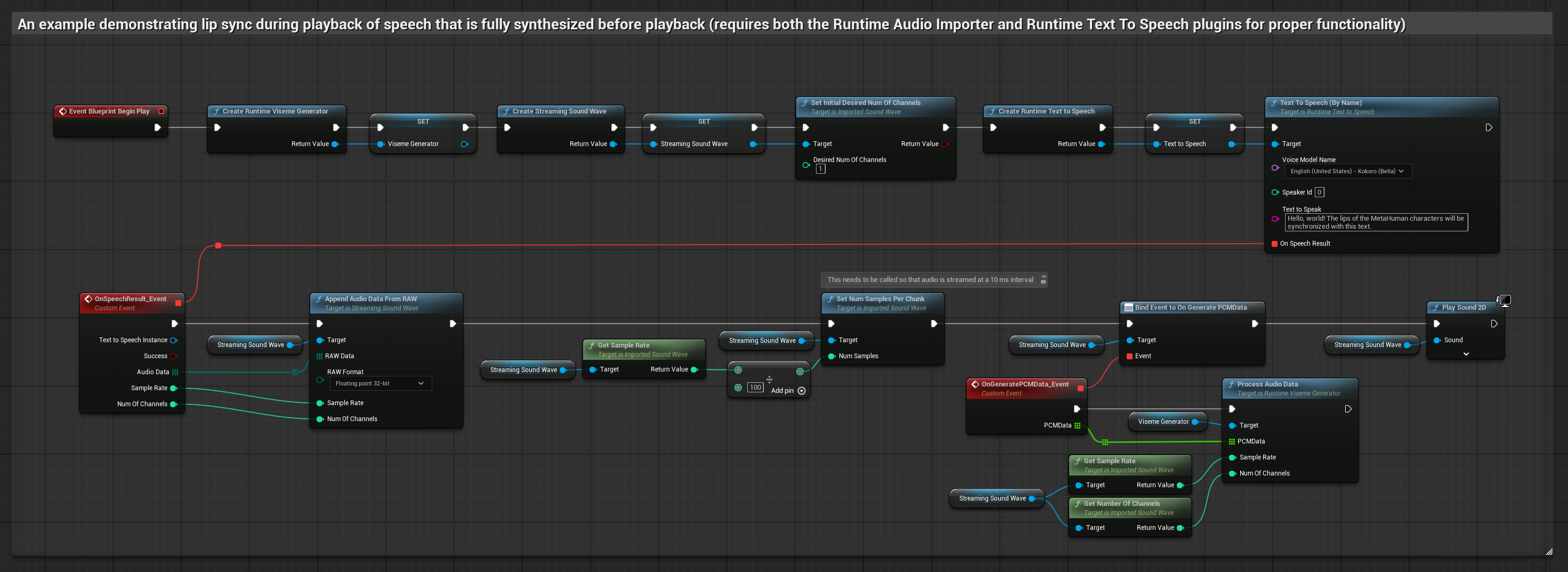
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
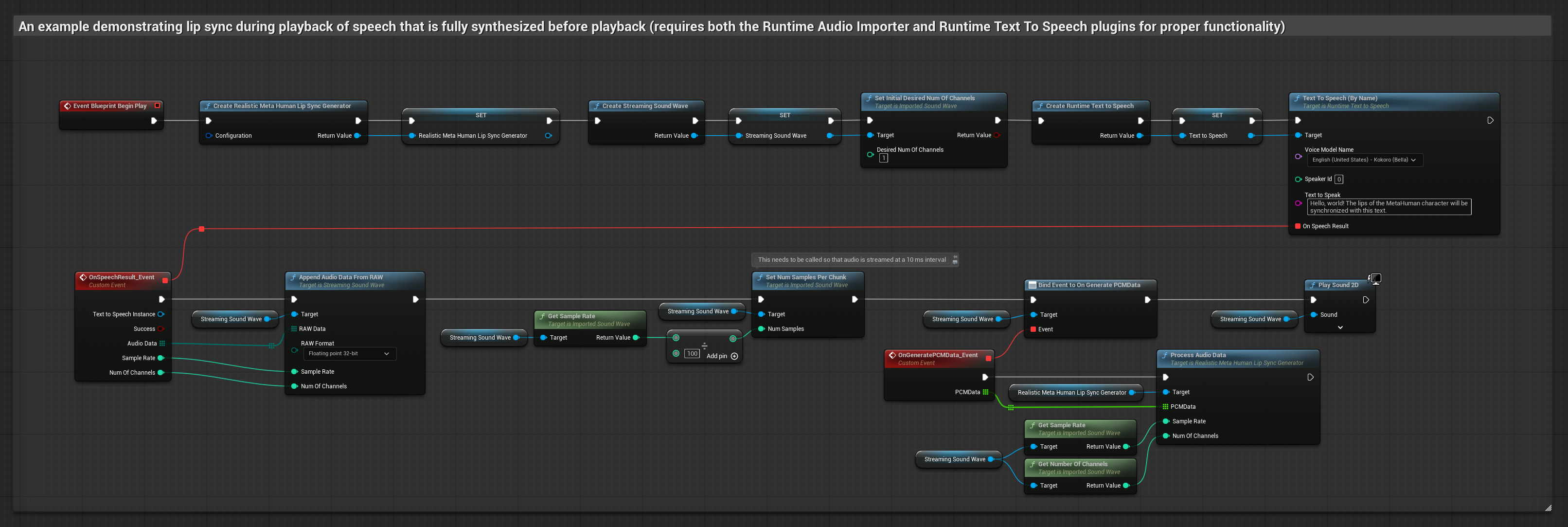
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
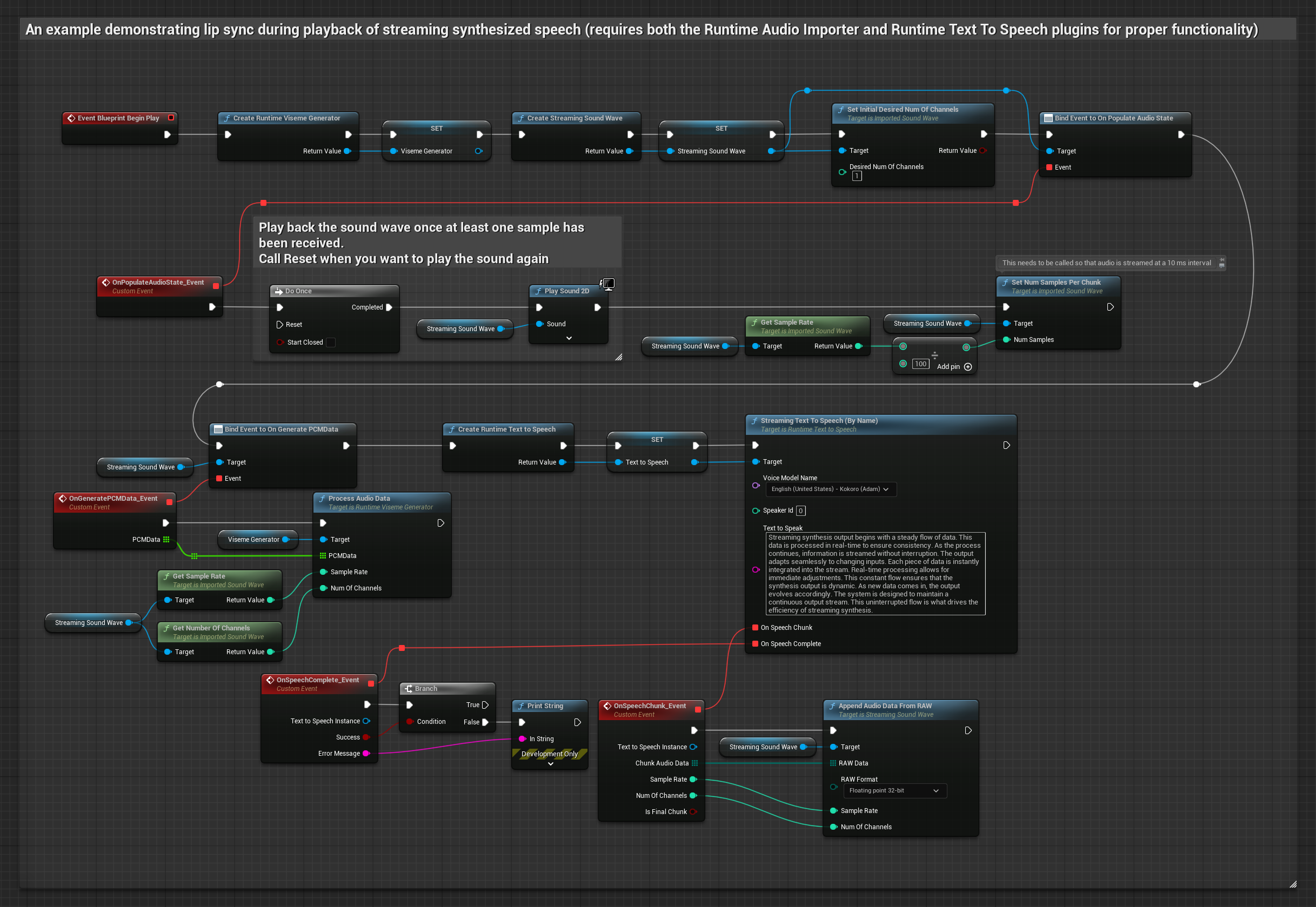
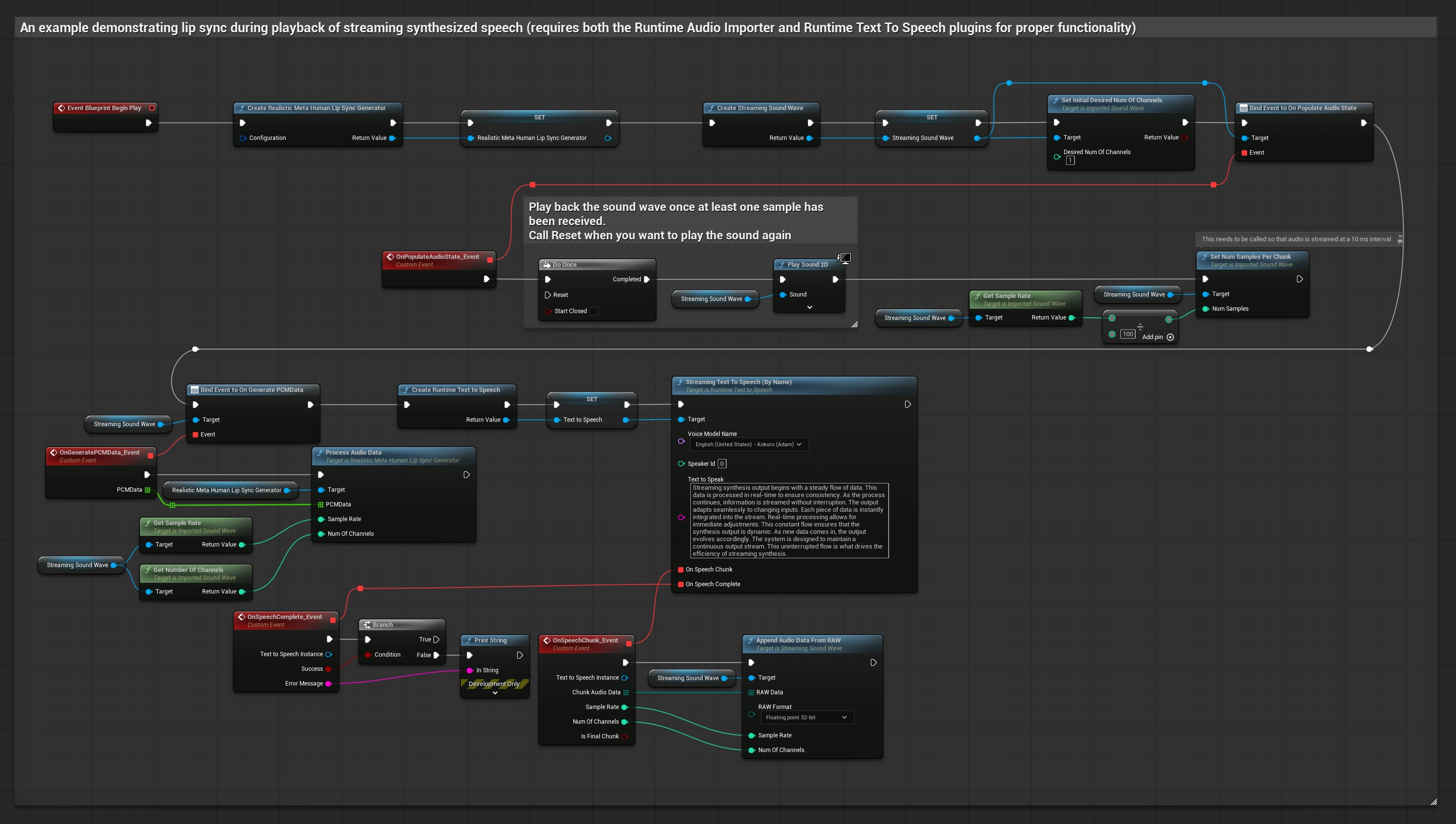
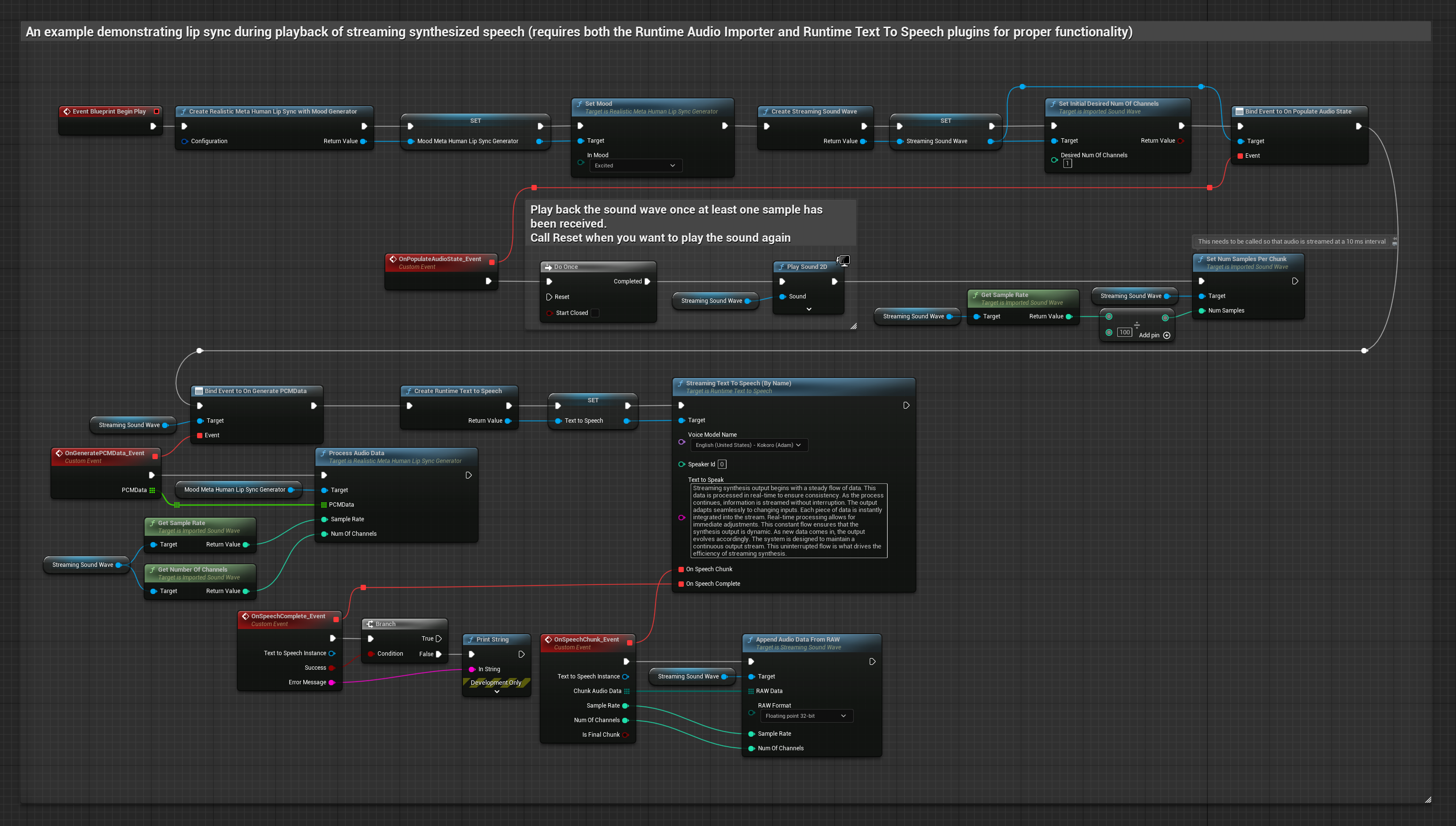
To podejście używa strumieniowej syntezy mowy z tekstu z synchronizacją ust w czasie rzeczywistym:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Użyj Runtime Text To Speech do wygenerowania strumieniowej mowy z tekstu
- Użyj Runtime Audio Importer do zaimportowania zsyntetyzowanego dźwięku
- Przed odtworzeniem strumieniowej fali dźwiękowej, podłącz się do jej delegata
OnGeneratePCMData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
- Zwykła
- Streaming
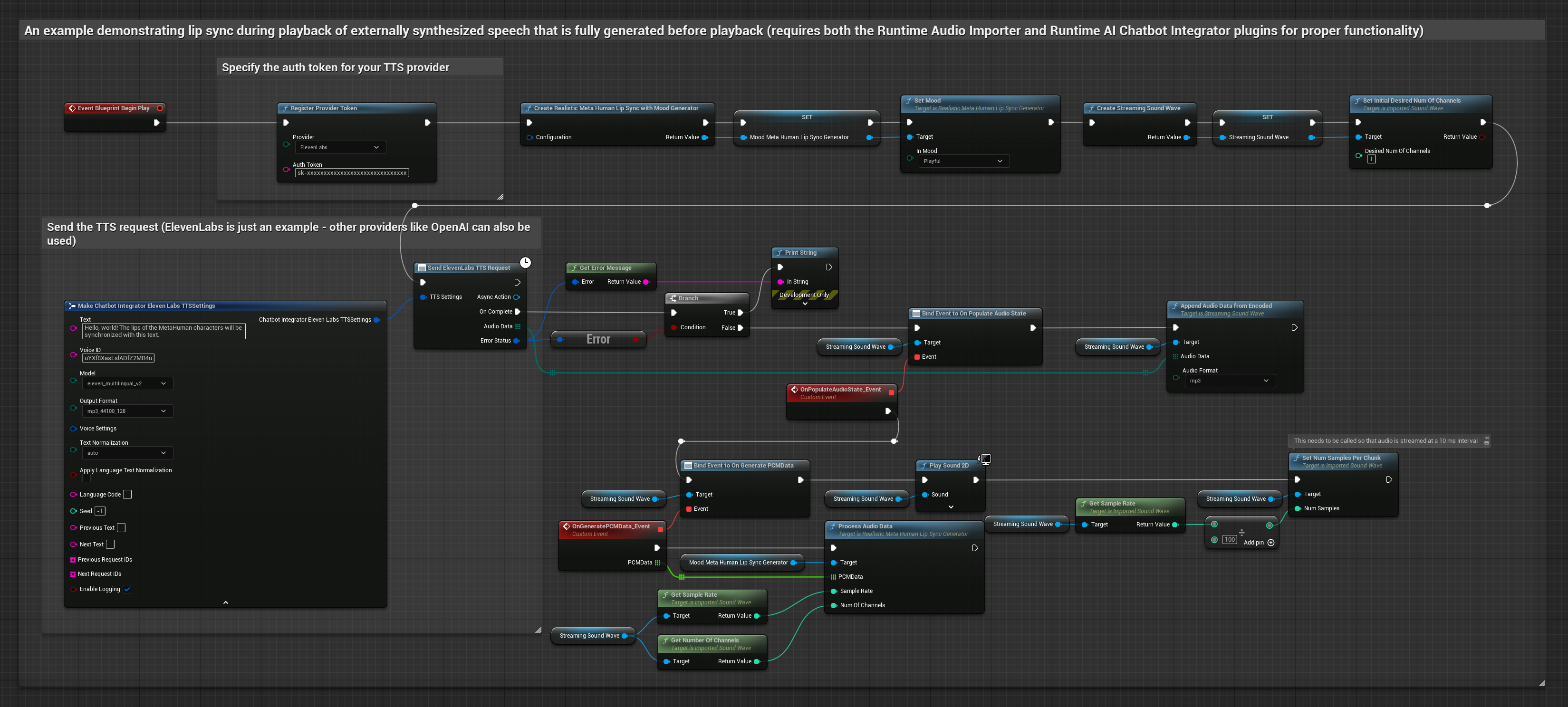
To podejście używa wtyczki Runtime AI Chatbot Integrator do generowania zsyntetyzowanej mowy z usług AI (OpenAI lub ElevenLabs) i wykonania synchronizacji ust:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Użyj Runtime AI Chatbot Integrator do wygenerowania mowy z tekstu przy użyciu zewnętrznych API (OpenAI, ElevenLabs, itp.)
- Użyj Runtime Audio Importer do zaimportowania zsyntetyzowanych danych audio
- Przed odtworzeniem zaimportowanej fali dźwiękowej, podłącz się do jej delegata
OnGeneratePCMData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator
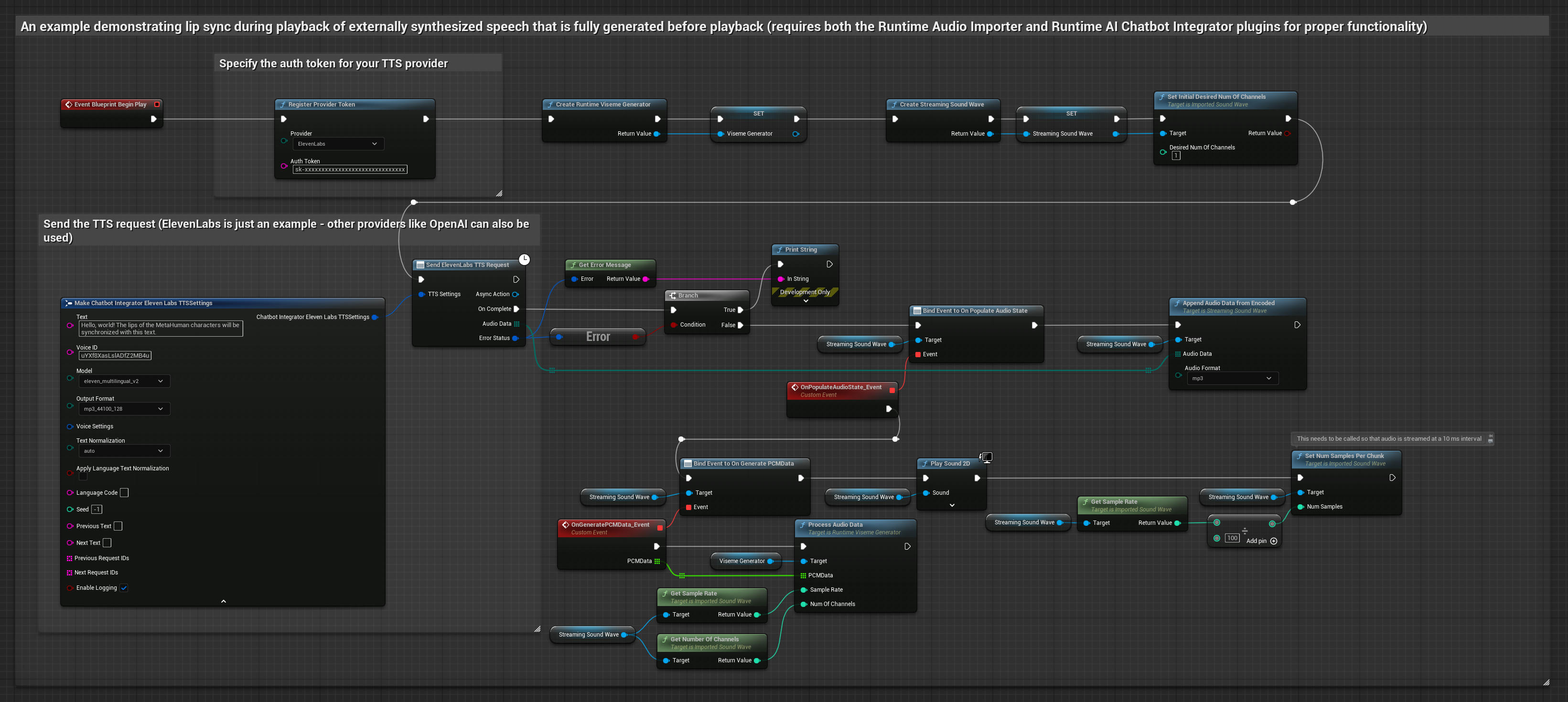
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
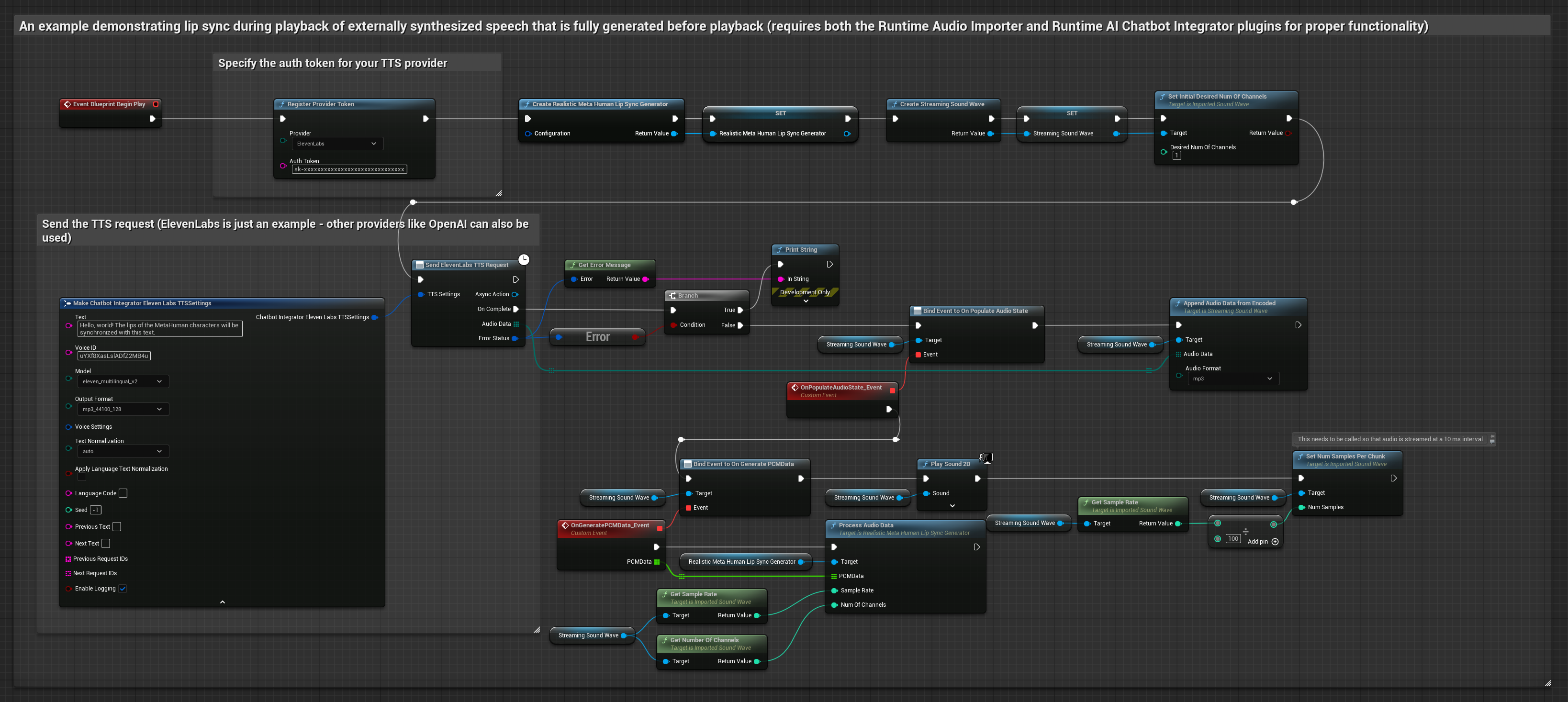
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
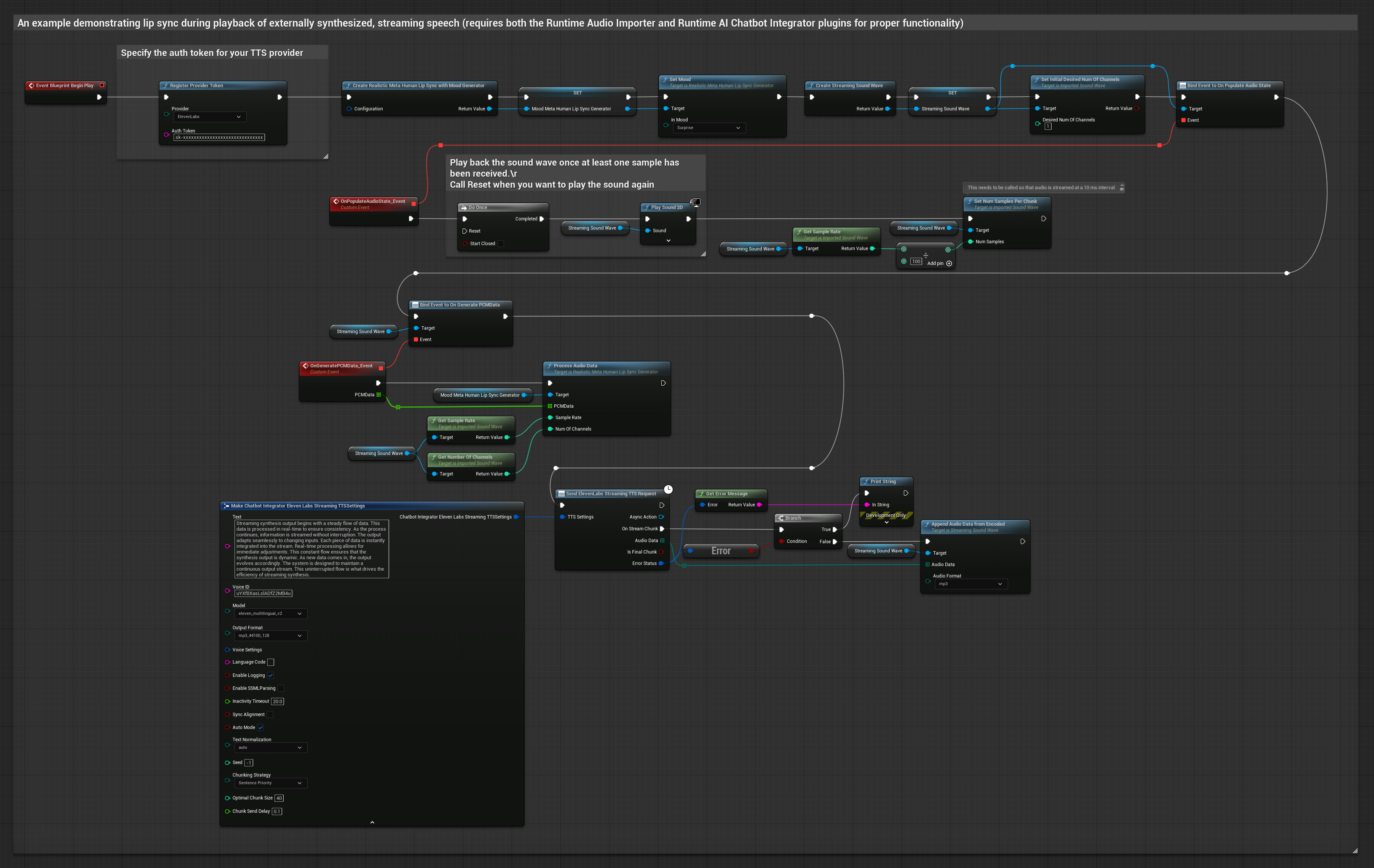
To podejście używa wtyczki Runtime AI Chatbot Integrator do generowania strumieniowej zsyntetyzowanej mowy z usług AI (OpenAI lub ElevenLabs) i wykonania synchronizacji ust:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Użyj Runtime AI Chatbot Integrator do połączenia ze strumieniowymi API TTS (jak ElevenLabs Streaming API)
- Użyj Runtime Audio Importer do zaimportowania zsyntetyzowanych danych audio
- Przed odtworzeniem strumieniowej fali dźwiękowej, podłącz się do jej delegata
OnGeneratePCMData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator
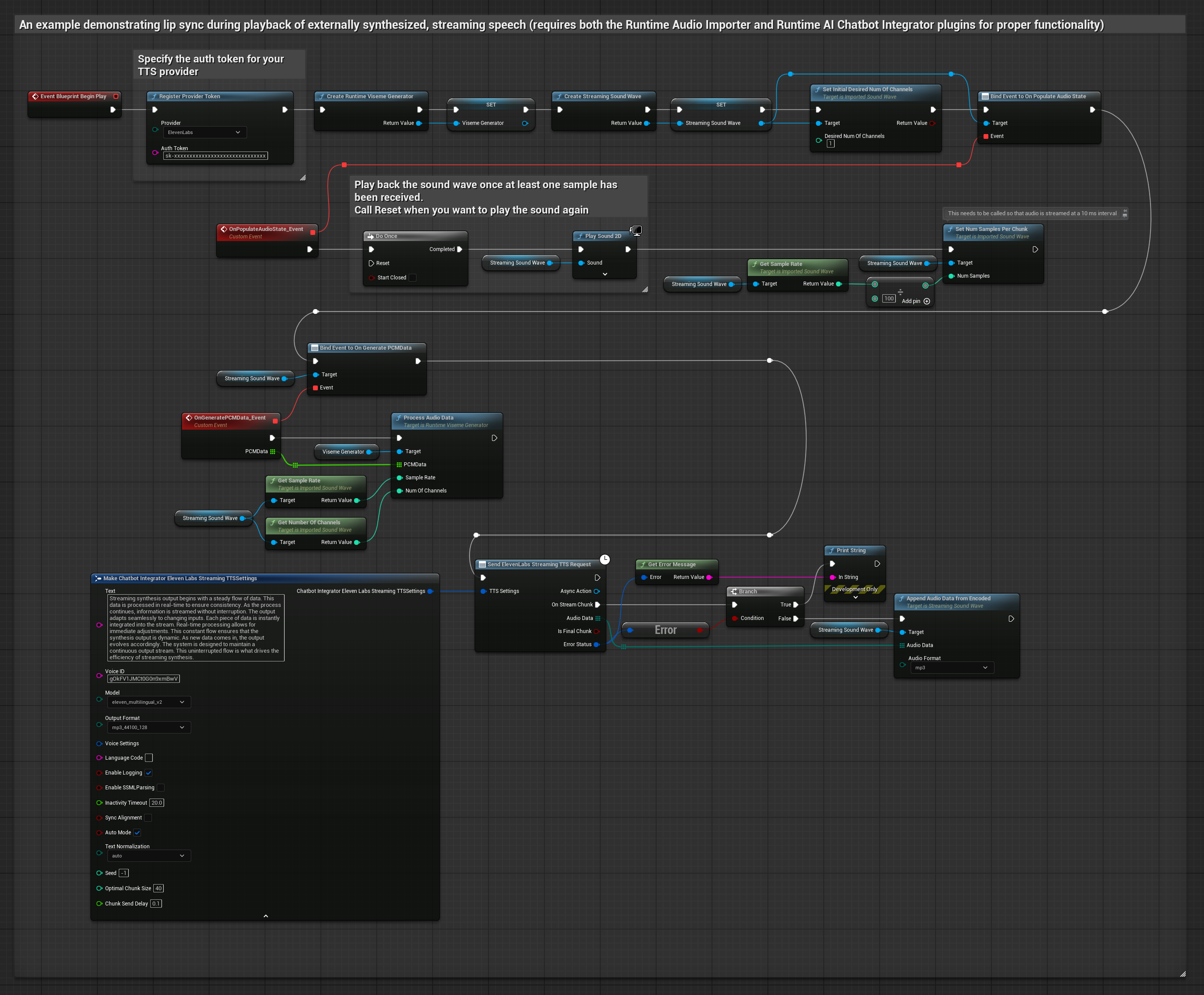
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
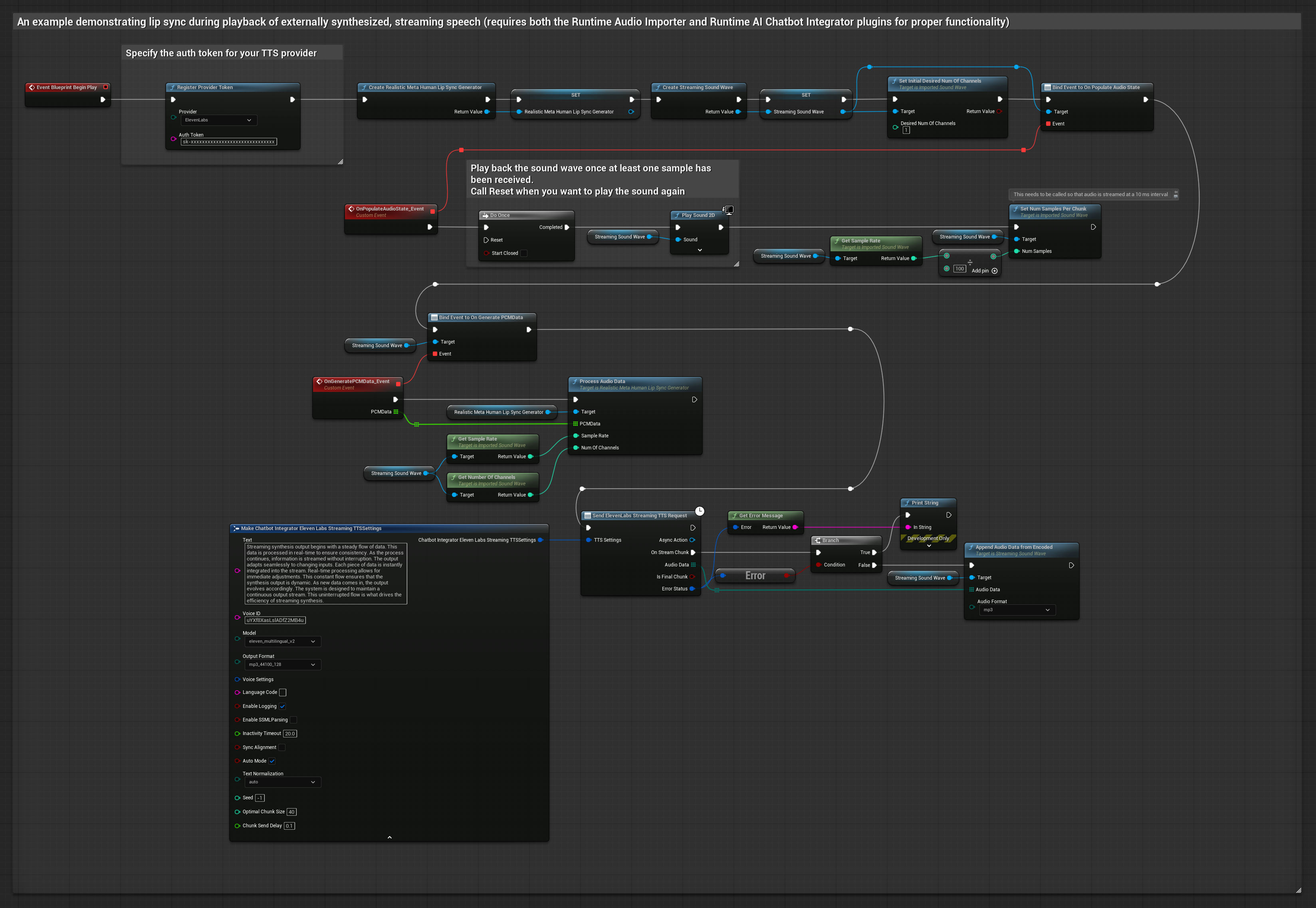
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
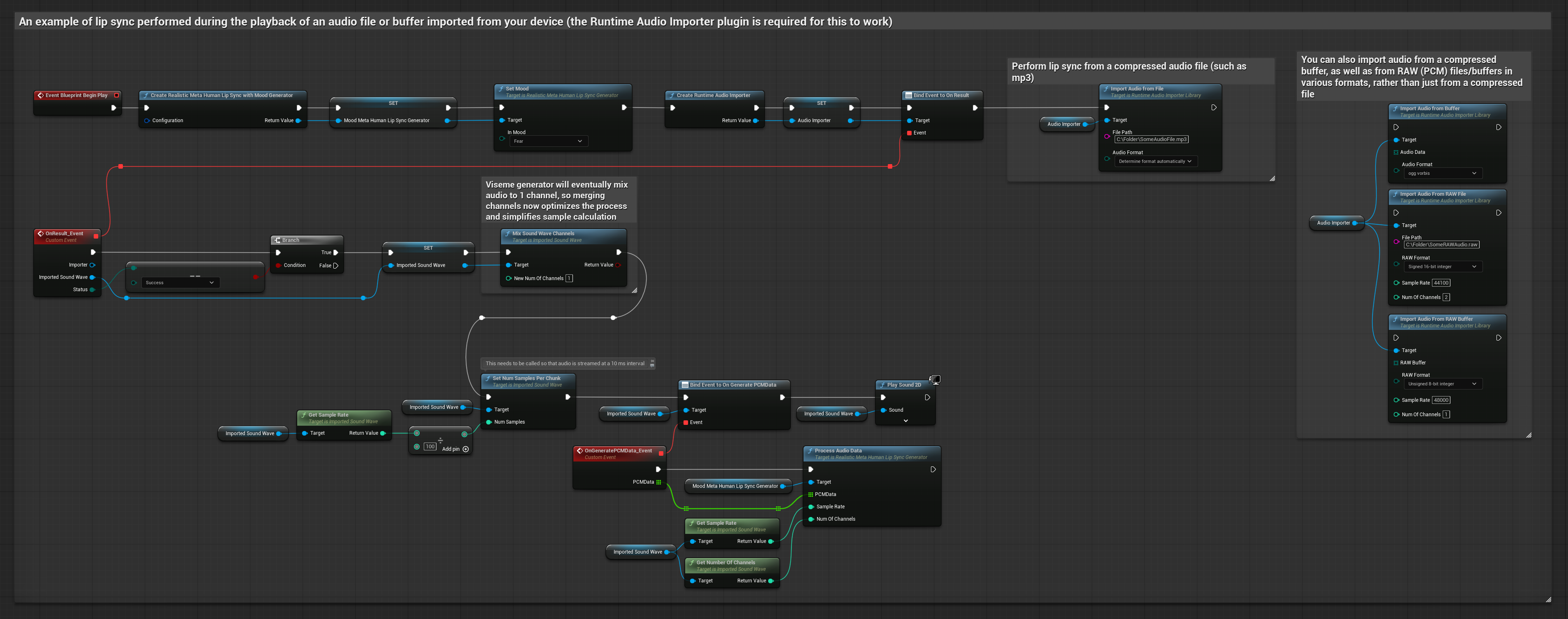
To podejście używa wcześniej nagranych plików audio lub buforów audio do synchronizacji ust:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Użyj Runtime Audio Importer do zaimportowania pliku audio z dysku lub pamięci
- Przed odtworzeniem zaimportowanej fali dźwiękowej, podłącz się do jej delegata
OnGeneratePCMData - W powiązanej funkcji, wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator - Odtwórz zaimportowaną falę dźwiękową i obserwuj animację synchronizacji ust
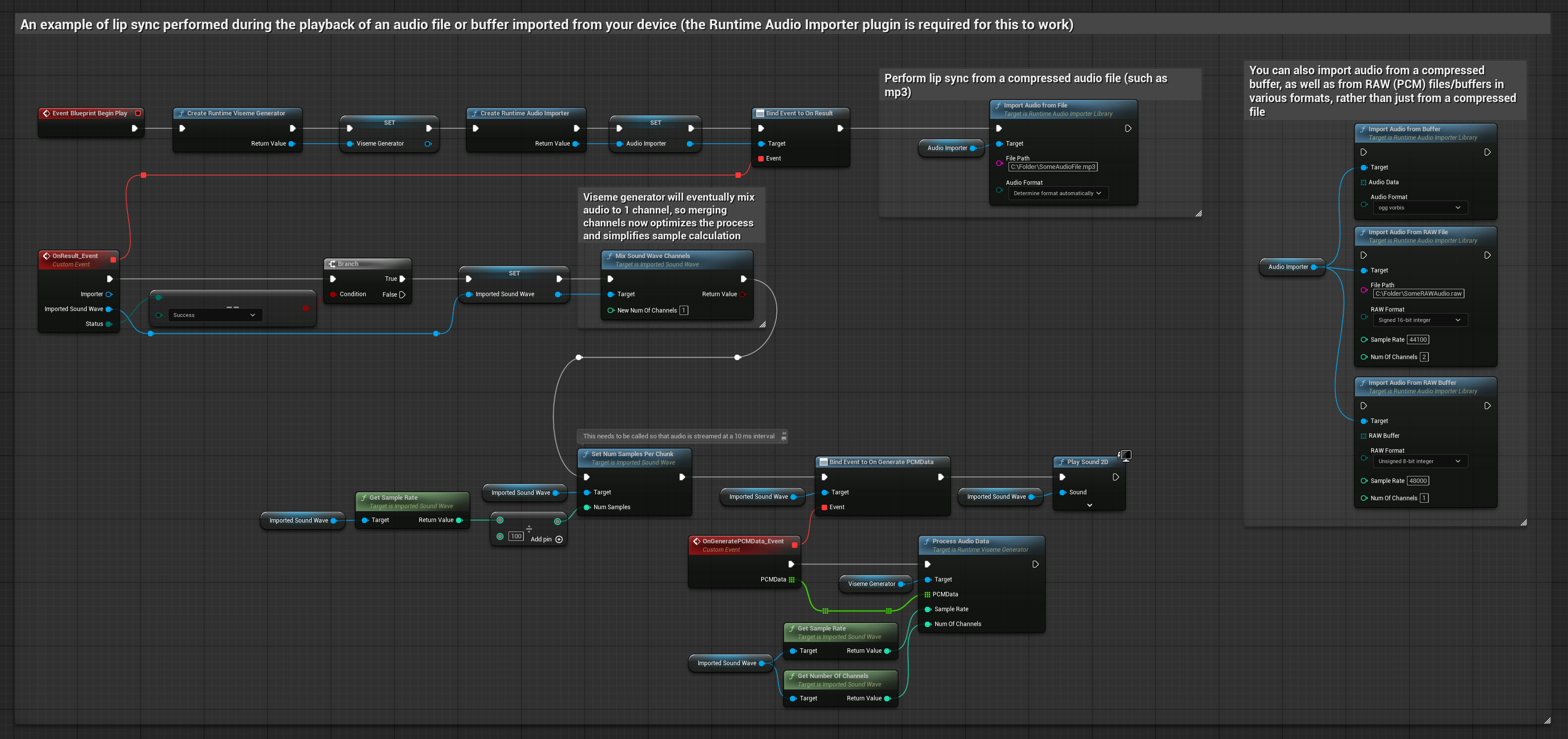
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
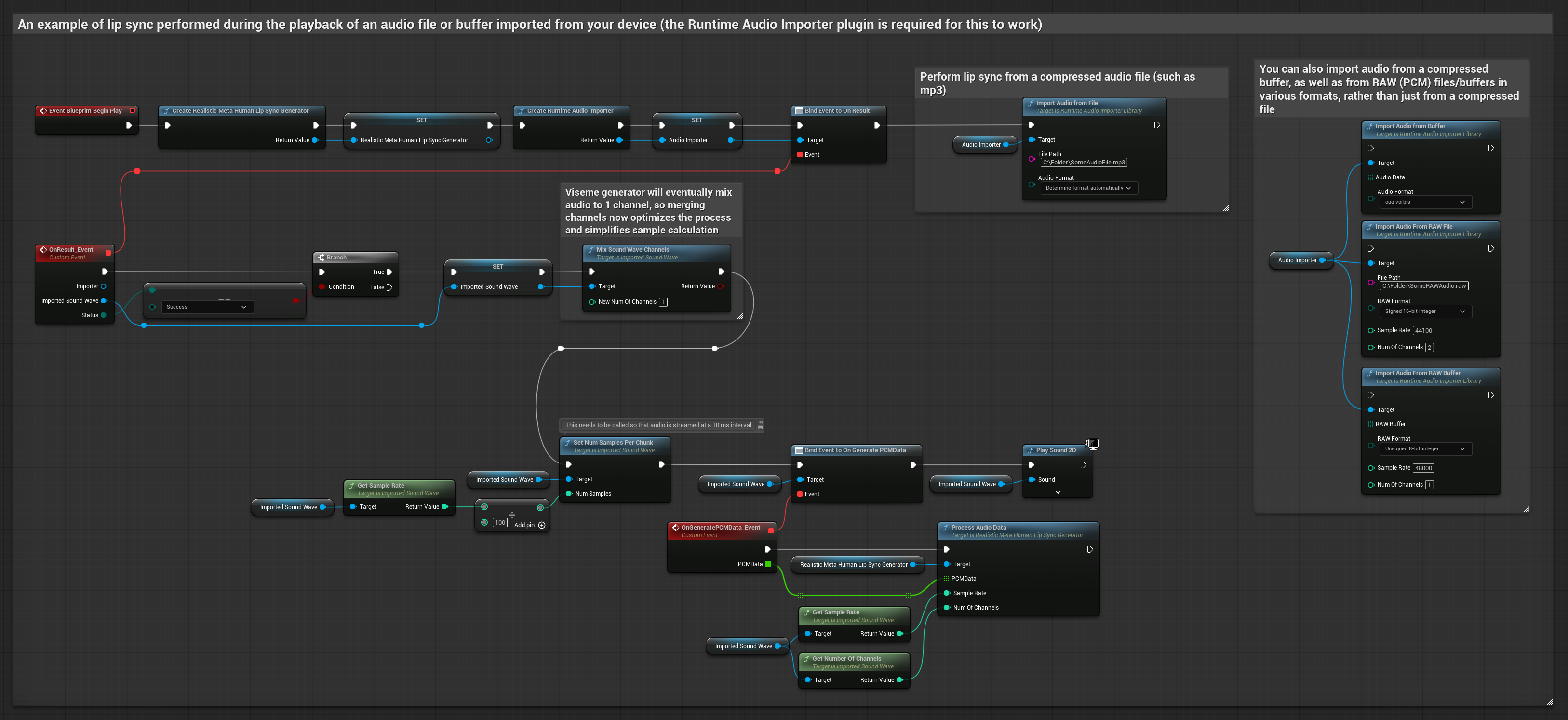
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.
Dla strumieniowych danych audio z bufora, potrzebujesz:
- Model standardowy
- Model realistyczny
- Model realistyczny z nastrojem
- Dane audio w formacie PCM float (tablica próbek zmiennoprzecinkowych) dostępne ze źródła strumieniowego (lub użyj Runtime Audio Importer do obsługi większej liczby formatów)
- Częstotliwość próbkowania i liczbę kanałów
- Wywołaj
ProcessAudioDataz twojego Runtime Viseme Generator z tymi parametrami, gdy fragmenty audio staną się dostępne
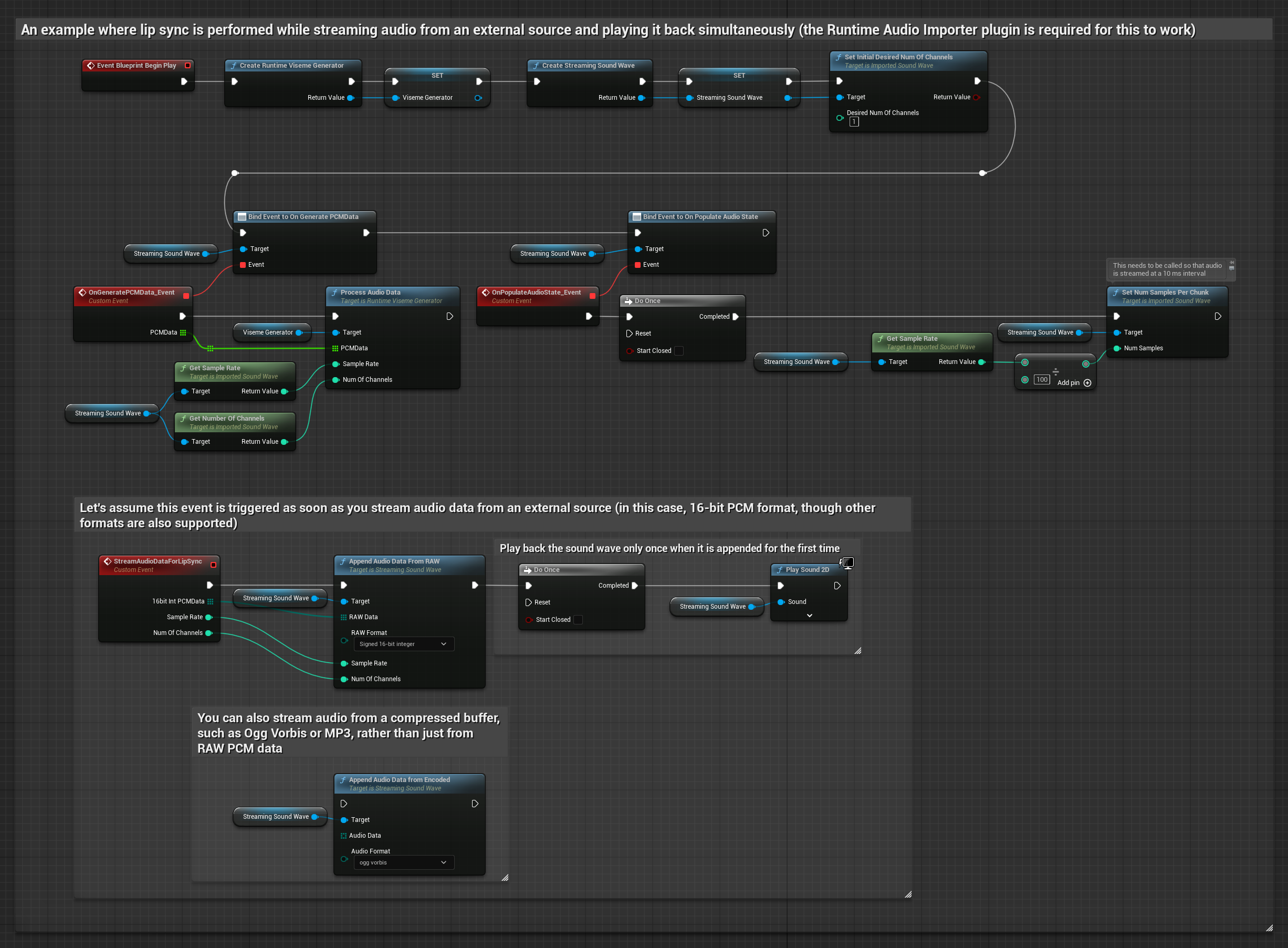
Model Realistyczny używa tego samego przepływu pracy przetwarzania audio co Model Standardowy, ale ze zmienną RealisticLipSyncGenerator zamiast VisemeGenerator.
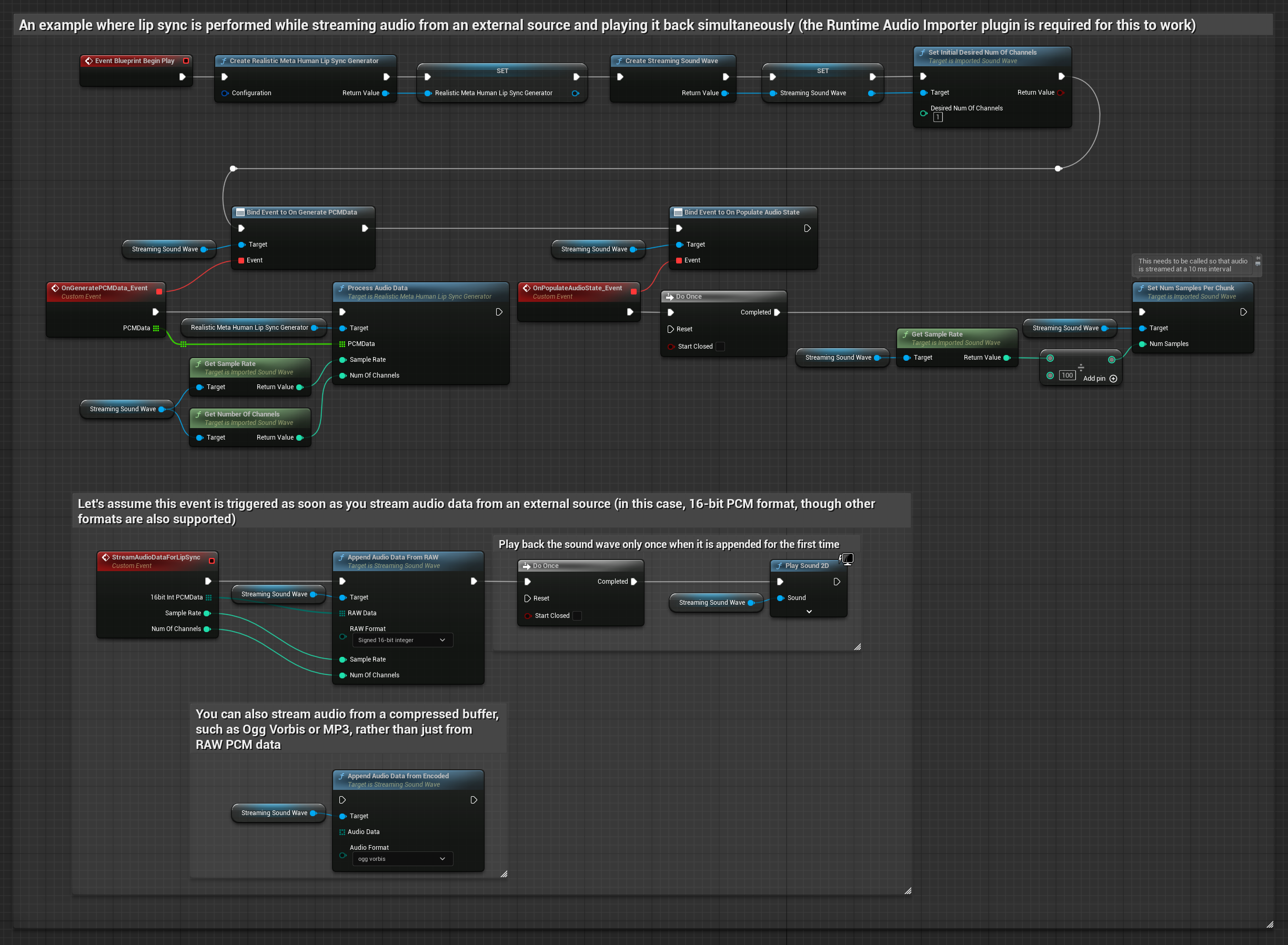
Model z obsługą nastroju używa tego samego przepływu pracy przetwarzania audio, ale ze zmienną MoodMetaHumanLipSyncGenerator i dodatkowymi możliwościami konfiguracji nastroju.

Uwaga: Podczas korzystania ze strumieniowych źródeł audio, upewnij się, że odpowiednio zarządzasz czasowaniem odtwarzania dźwięku, aby uniknąć zniekształconego odtwarzania. Zobacz dokumentację Streaming Sound Wave po więcej informacji.
Wskazówki dotyczące wydajności przetwarzania
-
Rozmiar fragmentu: Zwiększenie opcji konfiguracyjnej
ProcessingChunkSizeconfiguration option (np. do 320, 480 lub 640 próbek) może zauważalnie poprawić opóźnienie przy minimalnym wpływie na jakość lub responsywność. -
Typ modelu: Podczas używania modeli Realistycznych, przełączenie na typ modelu Highly Optimized (wybrany domyślnie) może poprawić wydajność. Należy pamiętać, że oryginalny model może dawać nieco lepszą jakość, szczególnie przy hałaśliwym dźwięku.
-
Zarządzanie buforem: Model z obsługą nastroju przetwarza dźwięk w klatkach 320-próbkowych (20ms przy 16kHz). Upewnij się, że czasowanie twojego wejścia audio jest z tym zsynchronizowane dla optymalnej wydajności.
-
Ponowne tworzenie generatora: Dla niezawodnej pracy z modelami Realistycznymi, odtwórz generator za każdym razem, gdy chcesz podać nowe dane audio po okresie bezczynności.
Następne kroki
Po skonfigurowaniu przetwarzania audio, możesz chcieć:
- Dowiedzieć się o opcjach konfiguracji, aby dostroić zachowanie synchronizacji ust
- Dodać animację śmiechu dla zwiększonej ekspresyjności
- Połączyć synchronizację ust z istniejącymi animacjami twarzy przy użyciu technik warstwowania opisanych w przewodniku konfiguracji