Projekty demonstracyjne
Aby szybko rozpocząć pracę z Runtime MetaHuman Lip Sync, dostępne są dwa gotowe projekty demonstracyjne. Oba są zbudowane na Unreal Engine 5.6+, są Blueprint-only i działają na wielu platformach: Windows, Mac, Linux, iOS, Android oraz platformy oparte na Androidzie (w tym Meta Quest).
Dostępne projekty demonstracyjne
- NPC konwersacyjny AI / Interaktywny Awatar
- Podstawowe demo synchronizacji ruchu warg
Pełny przepływ pracy awatara konwersacyjnego AI łączący rozpoznawanie mowy, czatbota AI (LLM), syntezę mowy z tekstu na mowę oraz odtwarzanie dźwięku z synchronizacją ruchu warg w czasie rzeczywistym - wszystko działające razem w jednym projekcie. Nadaje się do szerokiego zakresu zastosowań — w tym interaktywnych kiosków, produkcji wirtualnej, instalacji muzealnych, cyfrowych asystentów, symulacji szkoleniowych i gier.
Przegląd potoku przetwarzania
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Filmy
Szybki podgląd (~30 sek.)
Krótki pokaz działania dema.
Pełny przewodnik
Szczegółowy przewodnik obejmujący konfigurację, ustawienia i pełny potok konwersacyjny.
Pobieranie
Wymagane i opcjonalne wtyczki
Projekt demonstracyjny jest modułowy – potrzebujesz tylko wtyczek dla dostawców, których chcesz używać.
| Wtyczka | Przeznaczenie | Wymagane? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animacja synchronizacji ruchu warg | ✅ Zawsze |
| Runtime Audio Importer | Przechwytywanie i przetwarzanie dźwięku | ✅ Zawsze |
| Runtime Speech Recognizer | Rozpoznawanie mowy offline (whisper.cpp) | ✅ Zawsze |
| Runtime AI Chatbot Integrator | Zewnętrzne LLM-y (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) i/lub zewnętrzny TTS (OpenAI, ElevenLabs) | 🔶 Opcjonalnie |
| Runtime Local LLM | Wnioskowanie lokalnego LLM za pomocą llama.cpp (Llama, Mistral, Gemma, itd., modele GGUF) | 🔶 Opcjonalnie |
| Runtime Text To Speech | Lokalny TTS przez Piper i Kokoro | 🔶 Opcjonalnie |
Choć każda z powyższych wtyczek jest indywidualnie opcjonalna, do działania dema potrzebujesz co najmniej jednego dostawcy LLM oraz co najmniej jednego dostawcy TTS. Możesz je swobodnie łączyć (np. lokalny LLM + ElevenLabs TTS lub OpenAI LLM + lokalny TTS).
Architektura modułowa
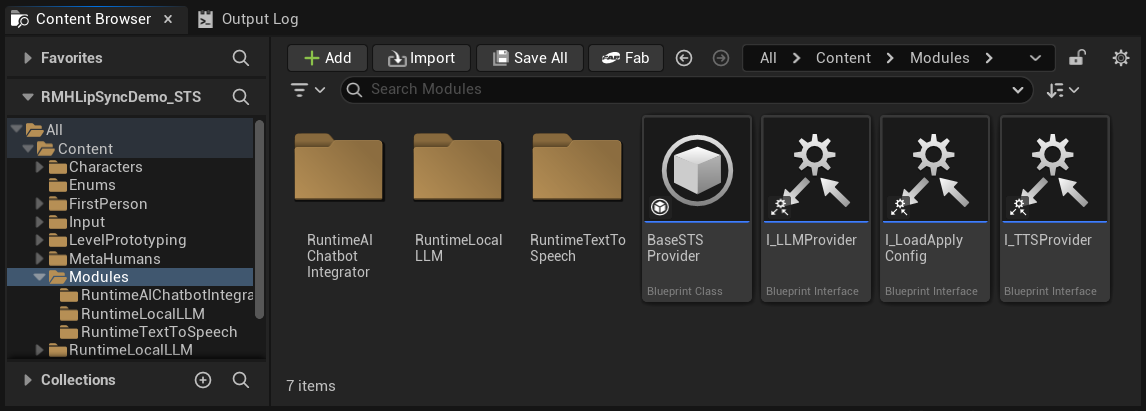
W folderze Content znajdziesz folder Modules, który zawiera trzy podfoldery:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Jeśli nie nabyłeś jednej (lub więcej) opcjonalnych wtyczek, po prostu usuń odpowiedni folder (foldery). Podstawowe zasoby projektu demonstracyjnego (instancja gry, widżety itp.) nie odwołują się bezpośrednio do tych modułów, więc ich usunięcie nie spowoduje błędów odwołań do zasobów. Interfejs konfiguracji automatycznie ukryje każdego dostawcę, którego folder jest nieobecny.
Ta modularność dotyczy tylko dostawców LLM i TTS. Rozpoznawanie mowy (Runtime Speech Recognizer) i Synchronizacja ruchu warg (Runtime MetaHuman Lip Sync) są częścią podstawowego projektu demonstracyjnego i są zawsze wymagane.
Przy pierwszym uruchomieniu Unreal może zapytać, czy wyłączyć brakujące opcjonalne wtyczki - kliknij Tak. Upewnij się, że usunąłeś także odpowiedni folder Content/Modules/ (patrz wyżej).
Układ projektu demonstracyjnego
Interfejs użytkownika pokazany poniżej jest w całości zbudowany przy użyciu UMG (Unreal Motion Graphics) i służy wyłącznie do demonstracji potoku - rozpoznawanie mowy → LLM → TTS → synchronizacja ruchu warg. Możesz go dowolnie przeprojektować lub zastąpić, aby dopasować do stylu wizualnego swojego projektu, schematu sterowania lub platformy (VR/AR, mobilne, konsola, kiosk itp.). Jeśli niektóre widżety nie są potrzebne w Twoim przypadku użycia, możesz je również po prostu ukryć (np. ustawić ich widoczność na Zwinięte lub Ukryte).

| Obszar | Co się tam znajduje |
|---|---|
| Środek | Postać MetaHuman. |
| Lewa strona | Cztery przyciski konfiguracji (Rozpoznawanie mowy, Chatbot AI, Zamiana tekstu na mowę, Animacje), szczegółowo opisane poniżej. |
| Dolny środek | Przycisk Rozpocznij nagrywanie. Kliknij go, aby rozpocząć rozmowę głosową: Twój mikrofon jest przechwytywany, transkrybowany, wysyłany do LLM, odpowiedź jest syntetyzowana za pomocą TTS i odtwarzana z synchronizacją ruchu warg, całkowicie bez użycia rąk. |
| Prawy środek | Widżet historii konwersacji pokazujący całą wymianę między Tobą a AI (wiadomości użytkownika i asystenta). Zawiera również pole wprowadzania tekstu, dzięki czemu możesz wpisywać wiadomości bezpośrednio bez korzystania z rozpoznawania mowy, co jest przydatne do testowania, dostępności lub gdy mikrofon nie jest dostępny. |
Możesz swobodnie łączyć oba tryby wprowadzania w tej samej sesji - wypowiadaj niektóre wiadomości, a inne wpisuj.
Przyciski konfiguracyjne
Cztery przyciski konfiguracyjne po lewej stronie otwierają dedykowane panele dla każdej części potoku:
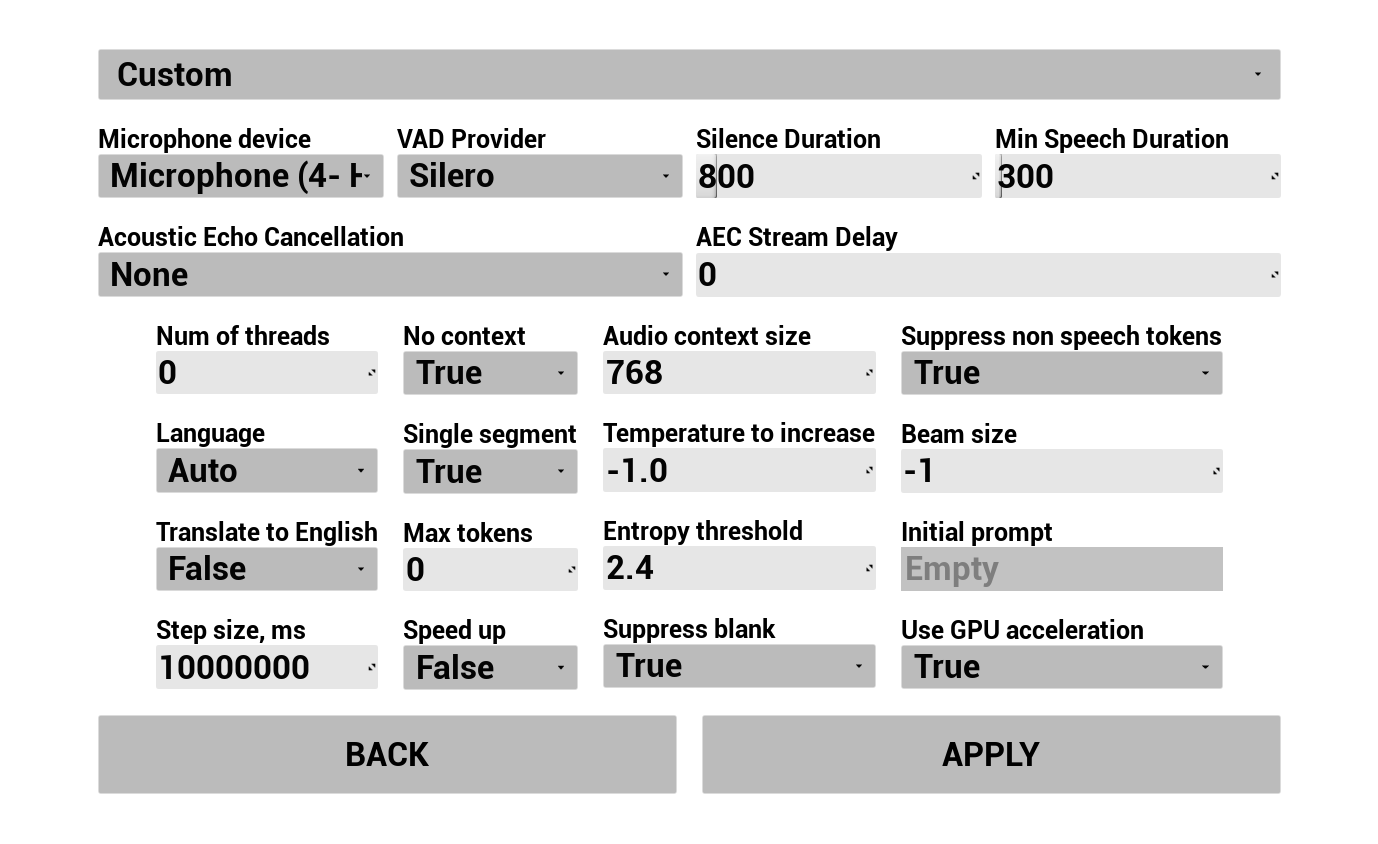
1. Konfiguracja rozpoznawania mowy
Skonfiguruj, w jaki sposób głos użytkownika jest przechwytywany i transkrybowany:
- Wybierz język
- Dostosuj parametry rozpoznawania mowy (ustawienia modelu Whisper)
- Skonfiguruj AEC (Akustyczna eliminacja echa)
- Skonfiguruj VAD (Wykrywanie aktywności głosowej)
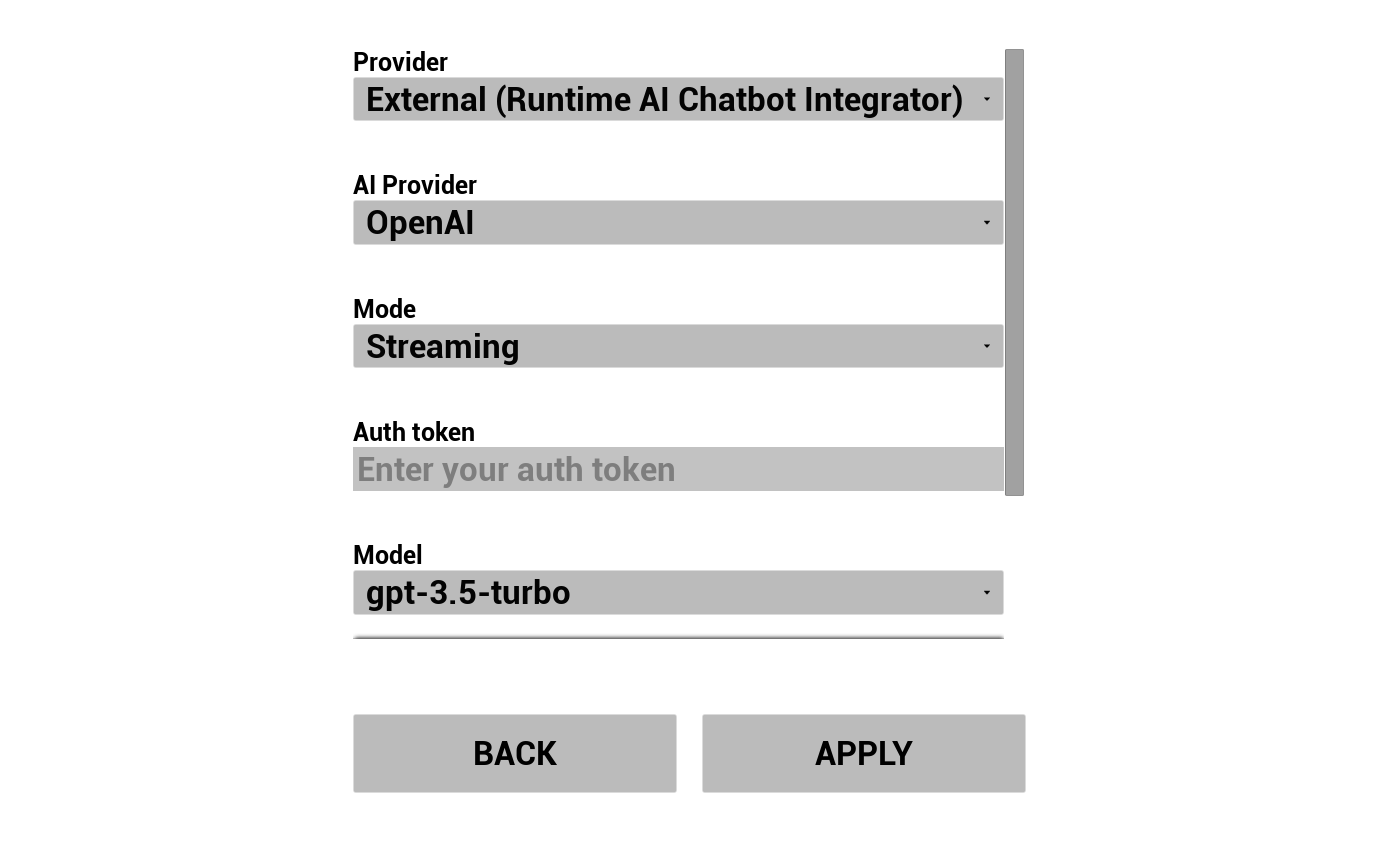
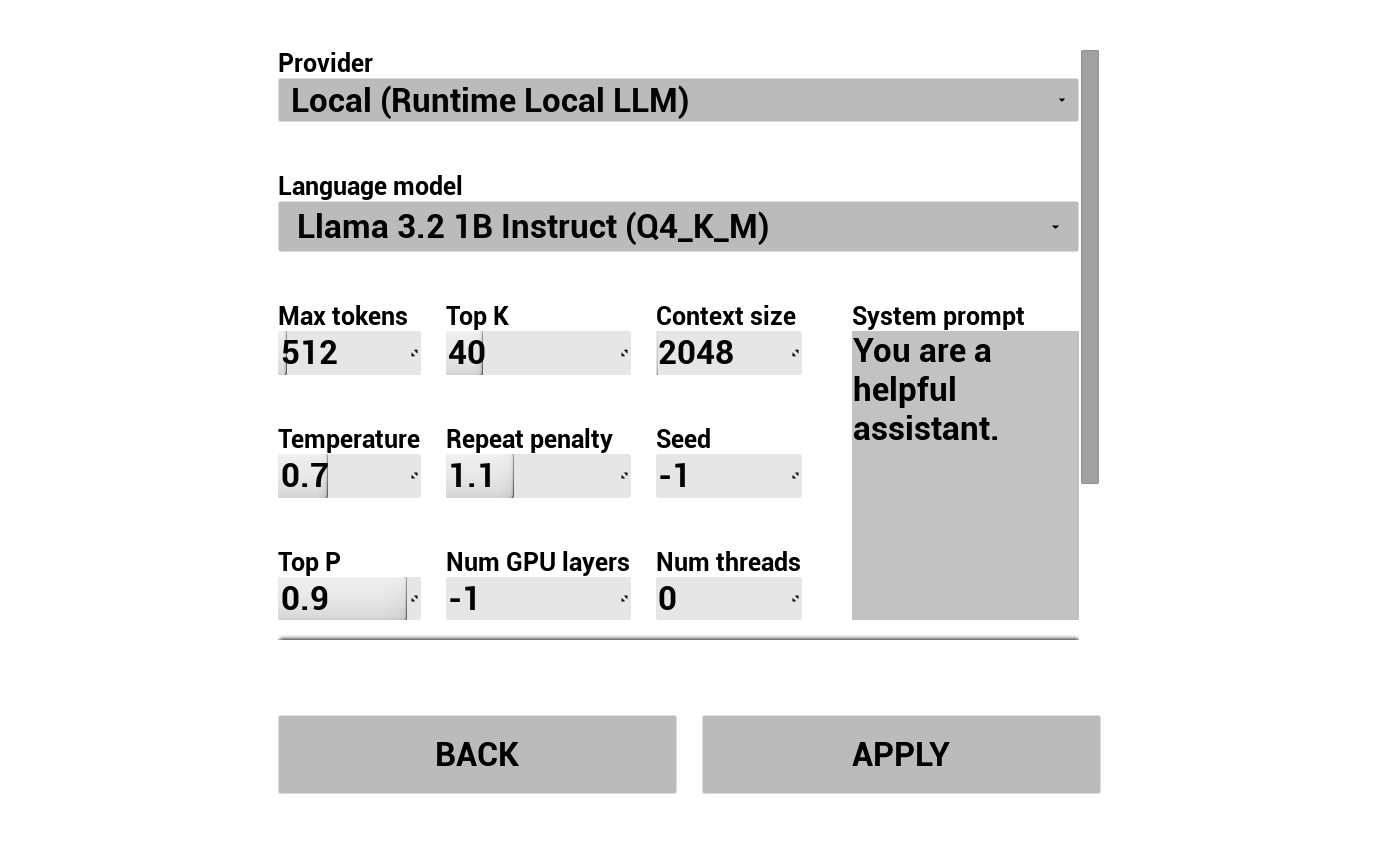
2. Konfiguracja chatbota AI
Wybierz dostawcę LLM i skonfiguruj go:
- Wybierz dostawcę (Runtime AI Chatbot Integrator lub Runtime Local LLM)
- Dla dostawców zewnętrznych: token autoryzacyjny, nazwa modelu itp.
- Dla lokalnego LLM: wybierz model GGUF, ustaw rozmiar kontekstu i inne parametry inferencji. Możesz również pobrać własny model GGUF w czasie działania bezpośrednio z demo (np. przez URL) i użyć go natychmiast bez przebudowywania projektu.
Rozwijana lista dostawców pokazuje tylko tych dostawców, których folder modułu wtyczki znajduje się w Content/Modules/.
3. Konfiguracja zamiany tekstu na mowę
Wybierz dostawcę TTS i skonfiguruj głosy/modele:
- Wybierz dostawcę (Runtime AI Chatbot Integrator dla OpenAI/ElevenLabs lub Runtime Text To Speech dla lokalnych Piper/Kokoro)
- Wybierz głos/model
- Dostosuj parametry specyficzne dla dostawcy

4. Konfiguracja animacji
Kontroluj wygląd swojego awatara AI:
- Wybierz spośród 3 wstępnie pobranych postaci MetaHuman (Aera, Ada, Orlando)
- Wybierz model synchronizacji ruchu warg (Standardowy lub Realistyczny)
- Wybierz typ modelu synchronizacji ruchu warg - Wysoce zoptymalizowany, Częściowo zoptymalizowany lub Oryginalny (zobacz Typ modelu)
- Dostosuj Processing Chunk Size - kontroluje, jak często uruchamiane jest wnioskowanie synchronizacji ruchu warg (zobacz Processing Chunk Size)
- Wybierz animację bezczynności, która będzie odtwarzana na MetaHumanie podczas rozmowy

Wstępna konfiguracja demo w edytorze
Podczas pracy z wersją źródłową możesz wstępnie wypełnić wartości domyślne bezpośrednio w edytorze, aby nie trzeba było wprowadzać ich ponownie przy każdym uruchomieniu:
| Co | Gdzie |
|---|---|
| Ustawienia ogólne (model synchronizacji ruchu warg, animacja bezczynności, klasa postaci, rozpoznawanie mowy itp.) | Content/LipSyncSTSGameInstance |
| Ustawienia zewnętrznego LLM / zewnętrznego TTS (Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Ustawienia lokalnego LLM (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Ustawienia lokalnego TTS (Runtime Text To Speech) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Uwagi dotyczące wieloplatformowości
Wszystkie wtyczki używane przez demo obsługują Windows, Mac, Linux, iOS, Android oraz platformy oparte na Androidzie (w tym Meta Quest), więc projekt demonstracyjny działa również na wszystkich tych platformach. Dzięki temu nadaje się do wdrożenia w szerokiej gamie środowisk — od kiosków stacjonarnych i przeglądarkowych doświadczeń po aplikacje mobilne, autonomiczne zestawy VR i konfiguracje wirtualnej produkcji na planie filmowym.
W przypadku słabszych urządzeń (mobilnych, autonomicznych VR) warto:
- Użyć standardowego modelu synchronizacji ruchu warg zamiast realistycznego - zobacz Porównanie modeli
- Przełączyć na typ modelu Wysoce zoptymalizowany
- Zwiększyć Processing Chunk Size, aby zmniejszyć obciążenie procesora
- Wybrać mniejsze modele LLM / TTS
Zobacz Konfiguracja specyficzna dla platformy w celu uzyskania dodatkowych kroków konfiguracji na Androidzie, iOS, Macu i Linuxie.
Wprowadzanie własnej postaci
Projekt demonstracyjny zawiera trzy przykładowe postacie MetaHuman (Aera, Ada, Orlando), ale możesz zaimportować własnego MetaHumana i użyć go w demo.
📺 Samouczek wideo: Dodawanie niestandardowej postaci MetaHuman do projektu demonstracyjnego
Samodzielnie wtyczka Runtime MetaHuman Lip Sync obsługuje wiele innych systemów postaci poza MetaHumanami (postacie oparte na ARKit, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe itp. - zobacz Przewodnik konfiguracji niestandardowych postaci). Niezależnie od tego, czy budujesz NPC do gry, wirtualnego prezentera, obsługę kiosku czy cyfrowego człowieka do produkcji wirtualnej, wtyczka dostosowuje się do Twojego potoku postaci.
Prościej projekt demonstracyjny, który skupia się wyłącznie na funkcji synchronizacji ruchu warg, bez pełnego przepływu rozmowy AI. Odpowiedni, jeśli chcesz po prostu zobaczyć synchronizację ruchu warg w działaniu z różnymi źródłami audio.
Prezentowany film
Pobrania
Co jest zawarte
To demo pokazuje podstawowe przepływy pracy synchronizacji ruchu warg:
- Wejście mikrofonu - synchronizacja ruchu warg w czasie rzeczywistym z dźwięku na żywo
- Odtwarzanie pliku audio - synchronizacja ruchu warg z zaimportowanych plików audio
- Zamiana tekstu na mowę - synchronizacja ruchu warg napędzana syntetyzowaną mową
Wymagane i opcjonalne wtyczki
| Wtyczka | Przeznaczenie | Wymagana? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animacja synchronizacji ruchu warg | ✅ Wymagana |
| Runtime Audio Importer | Import i przechwytywanie dźwięku | ✅ Wymagana |
| Runtime Text To Speech | Lokalny TTS dla sceny demonstracyjnej TTS | 🔶 Opcjonalna |
| Runtime AI Chatbot Integrator | Zewnętrzni dostawcy TTS (OpenAI, ElevenLabs) | 🔶 Opcjonalna |
Uwagi dotyczące standardowego modelu synchronizacji ruchu warg
Jeśli planujesz używać modelu standardowego (zamiast realistycznego) w którymkolwiek projekcie demonstracyjnym, musisz zainstalować wtyczkę Standard Lip Sync Extension. Zobacz Standard Model Extension, aby uzyskać instrukcje instalacji.
Potrzebujesz pomocy?
Jeśli napotkasz jakiekolwiek problemy z konfiguracją lub uruchomieniem projektów demonstracyjnych, skontaktuj się:
W przypadku próśb o niestandardowe rozwiązania programistyczne (np. rozszerzenie demonstracji o własną logikę, dostosowanie jej do konkretnej platformy lub potoku postaci), skontaktuj się z [email protected].