Jak korzystać z wtyczki
Wtyczka Runtime Speech Recognizer została zaprojektowana do rozpoznawania słów z przychodzących danych audio. Wykorzystuje nieco zmodyfikowaną wersję whisper.cpp do pracy z silnikiem. Aby użyć wtyczki, wykonaj następujące kroki:
Strona edytora
- Wybierz odpowiednie modele językowe dla swojego projektu, jak opisano tutaj.
Strona uruchomieniowa
- Utwórz Speech Recognizer i ustaw niezbędne parametry (CreateSpeechRecognizer, parametry znajdziesz tutaj).
- Podłącz się do potrzebnych delegatów (OnRecognitionFinished, OnRecognizedTextSegment i OnRecognitionError).
- Rozpocznij rozpoznawanie mowy (StartSpeechRecognition).
- Przetwarzaj dane audio i oczekuj na wyniki z delegatów (ProcessAudioData).
- Zatrzymaj rozpoznawanie mowy, gdy jest to potrzebne (np. po emisji OnRecognitionFinished).
Wtyczka obsługuje przychodzące dane audio w formacie floating point 32-bit interleaved PCM. Chociaż dobrze współpracuje z Runtime Audio Importer, nie zależy od niego bezpośrednio.
Parametry rozpoznawania
Wtyczka obsługuje rozpoznawanie danych audio zarówno w trybie strumieniowym, jak i niestrumieniowym. Aby dostosować parametry rozpoznawania do swojego konkretnego przypadku użycia, wywołaj SetStreamingDefaults lub SetNonStreamingDefaults. Dodatkowo masz elastyczność, aby ręcznie ustawić indywidualne parametry, takie jak liczba wątków, rozmiar kroku, czy tłumaczyć przychodzący język na angielski oraz czy korzystać z wcześniejszej transkrypcji. Zapoznaj się z Listą Parametrów Rozpoznawania, aby uzyskać pełną listę dostępnych parametrów.
Poprawa wydajności
Zapoznaj się z sekcją Jak poprawić wydajność, aby uzyskać wskazówki, jak zoptymalizować działanie wtyczki.
Wykrywanie aktywności głosowej (VAD)
Podczas przetwarzania danych wejściowych audio, szczególnie w scenariuszach strumieniowych, zaleca się użycie Wykrywania Aktywności Głosowej (VAD) w celu odfiltrowania pustych lub zawierających tylko szum segmentów audio, zanim dotrą one do rozpoznawacza. To filtrowanie można włączyć po stronie capturable sound wave przy użyciu wtyczki Runtime Audio Importer, co pomaga zapobiec halucynacjom modeli językowych – próbom znalezienia wzorców w szumie i generowaniu błędnych transkrypcji.
Dla optymalnych wyników rozpoznawania mowy zalecamy użycie dostawcy Silero VAD, który oferuje lepszą tolerancję szumów i dokładniejsze wykrywanie mowy. Silero VAD jest dostępny jako rozszerzenie wtyczki Runtime Audio Importer. Szczegółowe instrukcje konfiguracji VAD znajdują się w dokumentacji Wykrywania Aktywności Głosowej.
Węzły do skopiowania w poniższych przykładach używają domyślnego dostawcy VAD ze względu na kompatybilność. Aby zwiększyć dokładność rozpoznawania, możesz łatwo przełączyć się na Silero VAD, wykonując następujące kroki:
- Zainstaluj rozszerzenie Silero VAD zgodnie z opisem w sekcji Rozszerzenie Silero VAD
- Po włączeniu VAD za pomocą węzła Toggle VAD, dodaj węzeł Set VAD Provider i wybierz "Silero" z listy rozwijanej
W projekcie demonstracyjnym dołączonym do wtyczki, VAD jest domyślnie włączony. Więcej informacji na temat implementacji demo można znaleźć w Projekcie demonstracyjnym.
Przykłady
Te przykłady ilustrują, jak używać wtyczki Runtime Speech Recognizer zarówno ze strumieniowym, jak i niestrumieniowym wejściem audio, używając Runtime Audio Importer do uzyskania danych audio jako przykładu. Należy pamiętać, że oddzielne pobranie RuntimeAudioImporter jest wymagane, aby uzyskać dostęp do tego samego zestawu funkcji importowania audio przedstawionych w przykładach (np. capturable sound wave i ImportAudioFromFile). Te przykłady mają wyłącznie na celu zilustrowanie podstawowej koncepcji i nie zawierają obsługi błędów.
Przykłady strumieniowego wejścia audio
Uwaga: W UE 5.3 i innych wersjach możesz napotkać brakujące węzły po skopiowaniu Blueprints. Może to wystąpić z powodu różnic w serializacji węzłów między wersjami silnika. Zawsze sprawdzaj, czy wszystkie węzły są prawidłowo połączone w twojej implementacji.
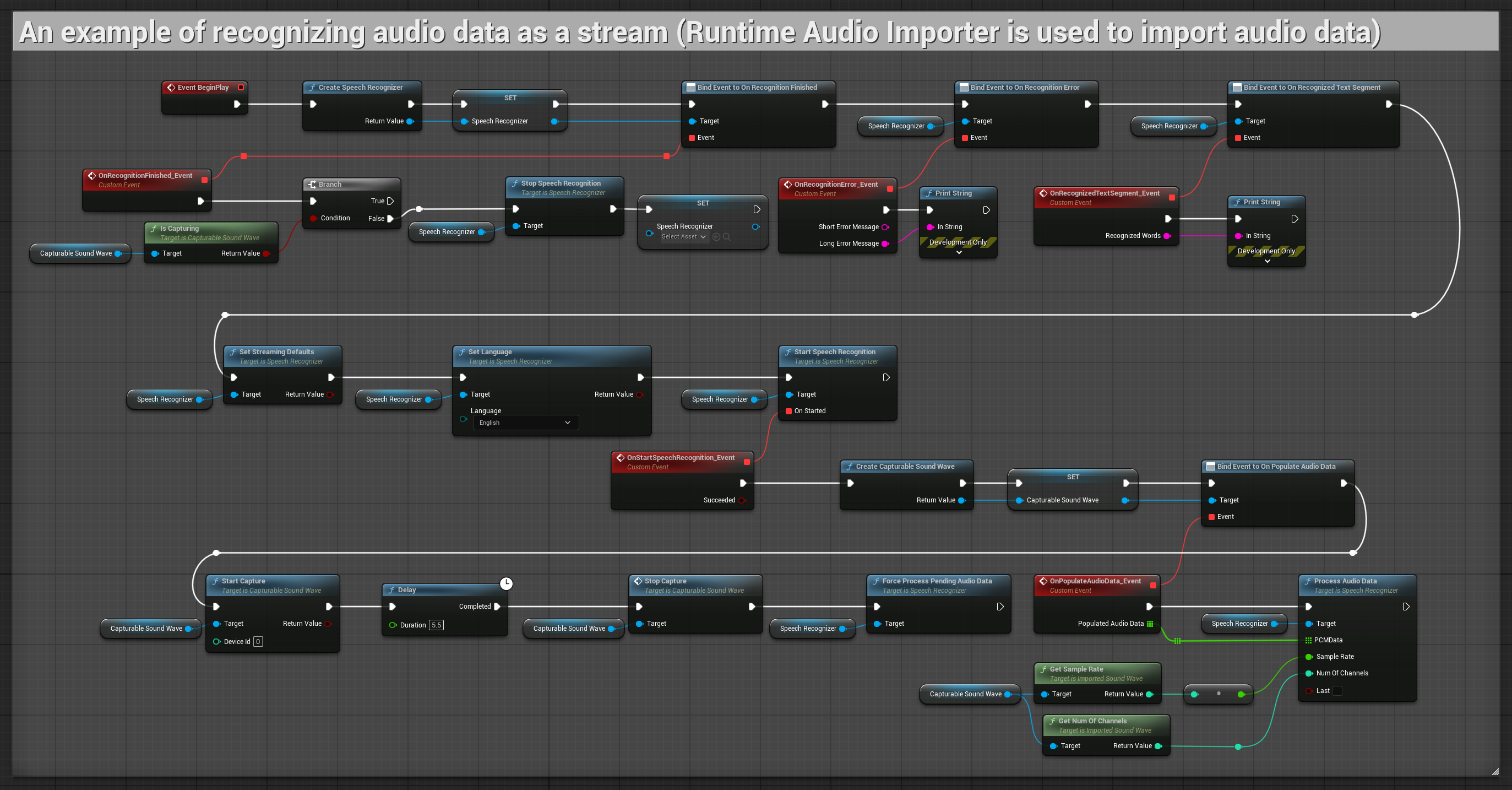
1. Podstawowe rozpoznawanie strumieniowe
Ten przykład demonstruje podstawową konfigurację do przechwytywania danych audio z mikrofonu jako strumienia przy użyciu Capturable sound wave i przekazywania ich do rozpoznawania mowy. Nagrywa mowę przez około 5 sekund, a następnie przetwarza rozpoznanie, co czyni go odpowiednim do szybkich testów i prostych implementacji. Węzły do skopiowania.
Kluczowe cechy tej konfiguracji:
- Stały czas nagrywania wynoszący 5 sekund
- Proste rozpoznanie jednorazowe
- Minimalne wymagania konfiguracyjne
- Idealne do testowania i prototypowania
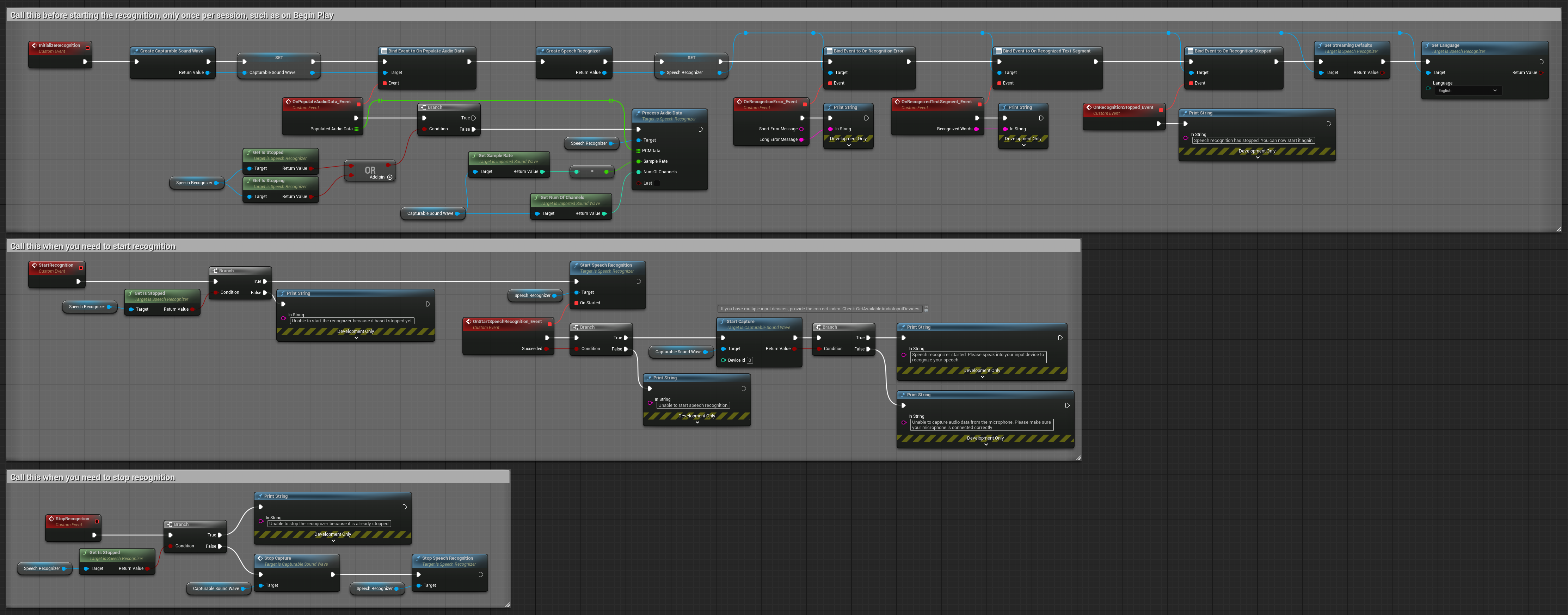
2. Kontrolowane rozpoznawanie strumieniowe
Ten przykład rozszerza podstawową konfigurację strumieniową poprzez dodanie ręcznej kontroli nad procesem rozpoznawania. Pozwala na uruchamianie i zatrzymywanie rozpoznawania według własnego uznania, co czyni go odpowiednim dla scenariuszy, w których potrzebna jest precyzyjna kontrola nad momentem rozpoznawania. Węzły do skopiowania.
Kluczowe cechy tej konfiguracji:
- Ręczne sterowanie startem/stopem
- Możliwość ciągłego rozpoznawania
- Elastyczny czas nagrywania
- Odpowiednie dla aplikacji interaktywnych
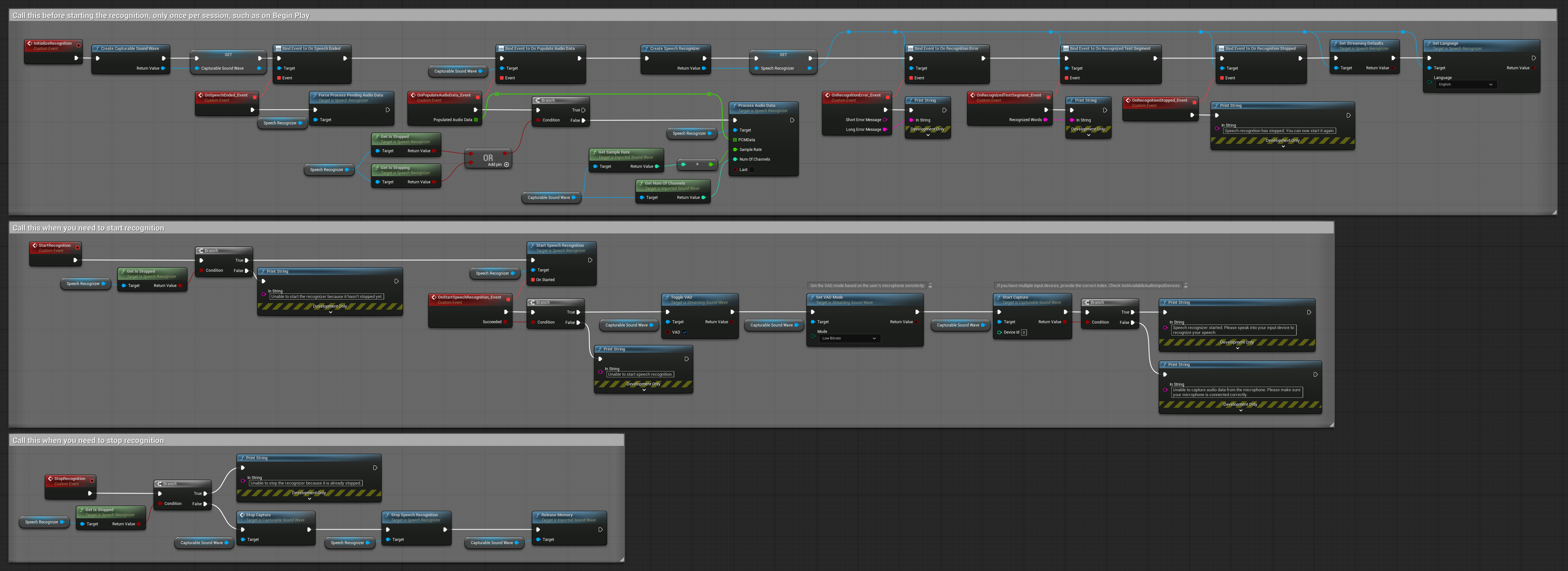
3. Rozpoznawanie komend aktywowanych głosem
Ten przykład jest zoptymalizowany dla scenariuszy rozpoznawania komend. Łączy rozpoznawanie strumieniowe z Wykrywaniem Aktywności Głosowej (VAD), aby automatycznie przetwarzać mowę, gdy użytkownik przestanie mówić. Rozpoznawanie rozpoczyna przetwarzanie nagromadzonej mowy tylko wtedy, gdy wykryta jest cisza, co czyni je idealnym dla interfejsów opartych na komendach. Kopiowalne węzły.
Kluczowe cechy tego ustawienia:
- Ręczne sterowanie startem/stopem
- Wykrywanie Aktywności Głosowej (VAD) włączone do wykrywania segmentów mowy
- Automatyczne uruchamianie rozpoznawania po wykryciu ciszy
- Optymalne dla rozpoznawania krótkich komend
- Zmniejszone obciążenie przetwarzania dzięki rozpoznawaniu tylko rzeczywistej mowy
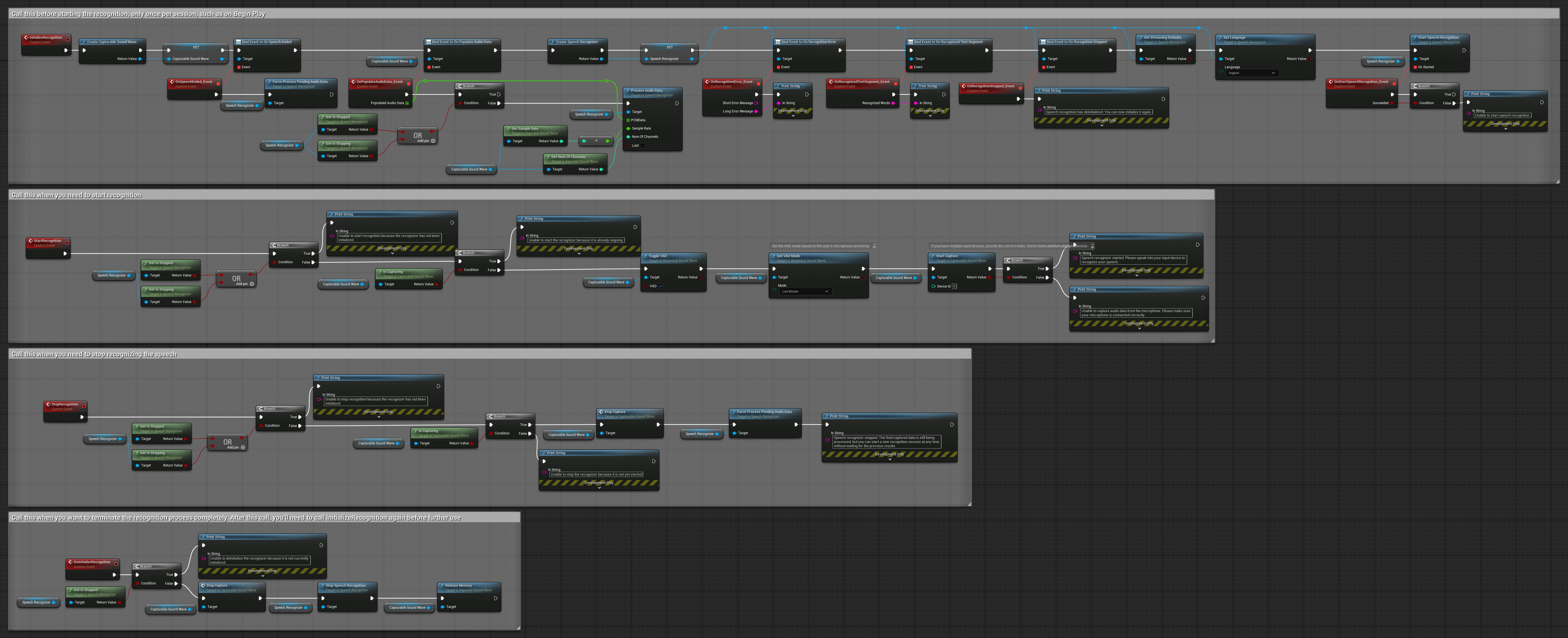
4. Automatycznie inicjujące rozpoznawanie głosu z przetwarzaniem końcowego bufora
Ten przykład to kolejna odmiana podejścia do rozpoznawania aktywowanego głosem z innym zarządzaniem cyklem życia. Automatycznie uruchamia rozpoznawanie podczas inicjalizacji i zatrzymuje je podczas deinicjalizacji. Kluczową cechą jest to, że przetwarza ostatni zgromadzony bufor audio przed zatrzymaniem rozpoznawania, zapewniając, że żadne dane mowy nie zostaną utracone, gdy użytkownik chce zakończyć proces rozpoznawania. To ustawienie jest szczególnie przydatne dla aplikacji, w których trzeba przechwytywać pełne wypowiedzi użytkownika, nawet podczas zatrzymywania w trakcie mówienia. Kopiowalne węzły.
Kluczowe cechy tego ustawienia:
- Automatycznie uruchamia rozpoznawanie przy inicjalizacji
- Automatycznie zatrzymuje rozpoznawanie przy deinicjalizacji
- Przetwarza końcowy bufor audio przed całkowitym zatrzymaniem
- Używa Wykrywania Aktywności Głosowej (VAD) do efektywnego rozpoznawania
- Zapewnia, że żadne dane mowy nie zostaną utracone przy zatrzymywaniu
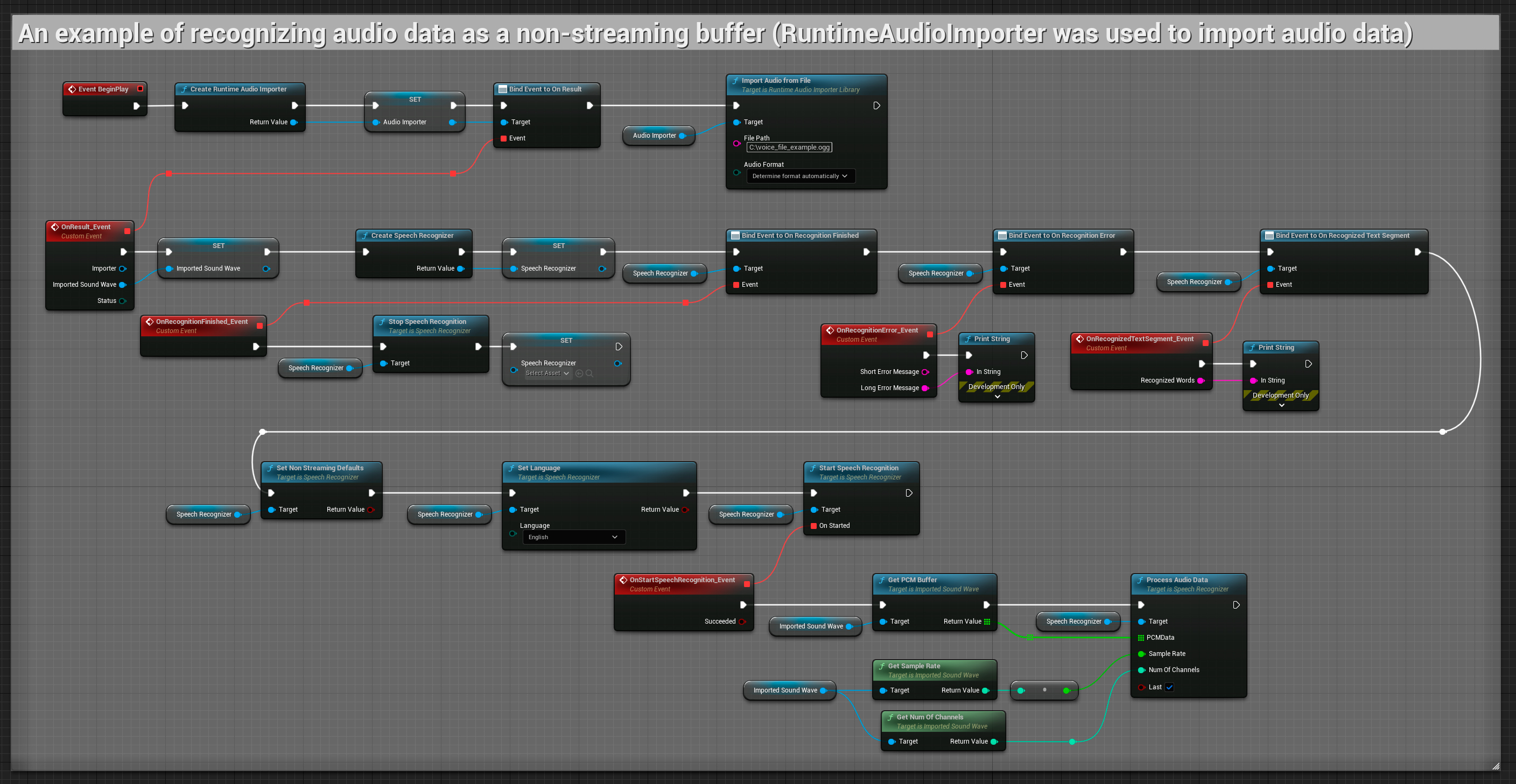
Niestrumieniowe wejście audio
Ten przykład importuje dane audio do Imported sound wave i rozpoznaje pełne dane audio po ich zaimportowaniu. Kopiowalne węzły.