Lista parametrów rozpoznawania
Te parametry można ustawić tylko wtedy, gdy rozpoznawanie nie jest uruchomione.
To nie jest wyczerpująca lista parametrów dostępnych w Whisper. Udostępniono tu tylko najważniejsze z nich. W razie potrzeby lista ta zostanie zaktualizowana.
Ustaw parametry rozpoznawania
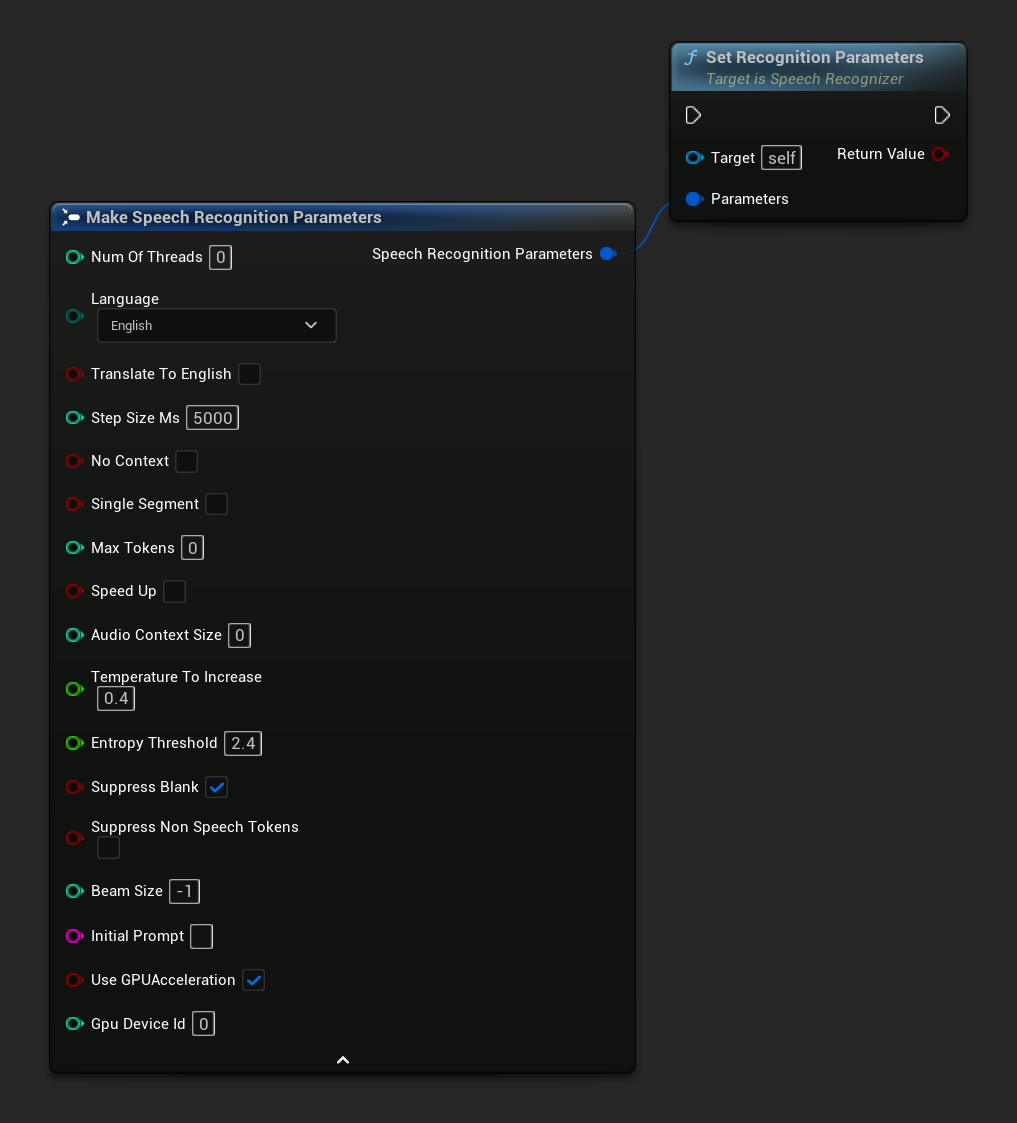
Ustawia parametry rozpoznawania mowy. Jeśli chcesz zmienić tylko określone parametry, rozważ użycie indywidualnych funkcji ustawiających.
Ustaw domyślne dla streamingu
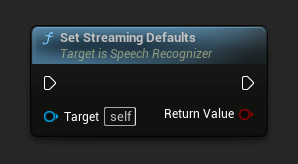
Ustawia domyślne parametry odpowiednie dla strumieniowego rozpoznawania mowy.
Ta funkcja nadpisuje wszystkie wcześniej zastosowane parametry. Upewnij się, że wywołasz ją przed ustawieniem własnych parametrów, jeśli potrzebujesz użyć domyślnych ustawień streamingu jako konfiguracji bazowej.
Ustaw domyślne dla trybu niestrumieniowego
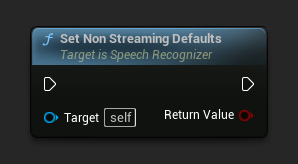
Ustawia domyślne parametry odpowiednie dla niestrumieniowego rozpoznawania mowy.
Ta funkcja nadpisuje wszystkie wcześniej zastosowane parametry. Upewnij się, że wywołasz ją przed ustawieniem własnych parametrów, jeśli potrzebujesz użyć domyślnych ustawień trybu niestrumieniowego jako konfiguracji bazowej.
Ustaw liczbę wątków
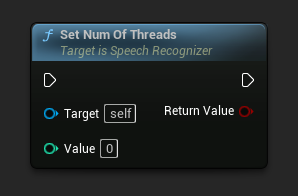
Ustawia liczbę wątków do użycia w rozpoznawaniu mowy. Ustaw tę wartość na 0, aby użyć liczby rdzeni procesora.
Ustaw język
Ustawia język do użycia w rozpoznawaniu mowy. Musi być obsługiwany przez wybrany model językowy w ustawieniach Edytora.
Ustawienie języka na Auto zmniejszy dokładność i wydajność rozpoznawania.
Pobierz wykryty język
Pobiera wykryty język z ostatniego rozpoznania. Zwraca język jako wartość wyliczeniową.
Uwaga: Ta funkcja działa tylko po wykonaniu rozpoznania. Zwraca Auto, jeśli wykrywanie języka nie powiodło się lub nie zostało wykonane. Jest to szczególnie przydatne podczas korzystania z automatycznego wykrywania języka, aby zidentyfikować, który język został faktycznie rozpoznany.
Pobierz kod języka
Konwertuje wartość wyliczeniową języka na jego kod językowy w postaci ciągu znaków (np. En -> "en", Fr -> "fr", De -> "de").
Pobierz pełną nazwę języka
Konwertuje wartość wyliczeniową języka na jego pełną nazwę (np. En -> "English", Fr -> "French", De -> "German").
Ustaw tłumaczenie na angielski
![]()
Ustawia, czy rozpoznane słowa mają być tłumaczone na język angielski. Jeśli wartość to true, model językowy musi być wielojęzyczny.
Ustaw rozmiar kroku
Ustawia rozmiar kroku w milisekundach. Określa, jak często wysyłać dane audio do rozpoznania. Wartość domyślna to 5000 ms (5 sekund).
Ustaw brak kontekstu
Ustawia, czy używać wcześniejszej transkrypcji (jeśli istnieje) jako początkowego promptu dla dekodera.
Ustaw pojedynczy segment
Ustawia, czy wymuszać wyjście w postaci pojedynczego segmentu (przydatne w streamingu).
Ustaw maksymalną liczbę tokenów
Ustawia maksymalną liczbę tokenów na segment tekstu. Użyj 0, aby nie mieć limitu.
Ustaw przyspieszenie
Ustawia, czy przyspieszyć rozpoznanie 2-krotnie za pomocą Phase Vocoder. Ustaw jako false, aby poprawić jakość wyjścia.
Ustaw rozmiar kontekstu audio
Ustawia rozmiar kontekstu audio. Ustaw jako 0, aby poprawić jakość wyjścia.
Ustaw temperaturę do zwiększenia
Ustawia temperaturę do zwiększenia podczas powrotu, gdy dekodowanie nie spełnia któregokolwiek z poniższych progów.
Ustaw próg entropii
Ustawia próg entropii. Jeśli współczynnik kompresji jest wyższy niż ta wartość, potraktuj dekodowanie jako nieudane. Podobne do "compression_ratio_threshold" od OpenAI.
Ustaw tłumienie pustych
![]()
Ustawia, czy tłumić pojawianie się pustych miejsc w wyjściach.
Ustaw tłumienie tokenów niemowy
Ustawia, czy tłumić pojawianie się tokenów niemowy w wyjściach.
Ustaw rozmiar wiązki
Ustawia liczbę wiązek w przeszukiwaniu wiązkowym. Dotyczy tylko sytuacji, gdy temperatura wynosi zero.
Ustaw początkowy prompt
Ustawia początkowy prompt dla pierwszego okna. Może to być użyte do zapewnienia kontekstu dla rozpoznania, aby zwiększyć prawdopodobieństwo poprawnego przewidzenia słów, np. niestandardowe słownictwo lub nazwy własne.
Aby uzyskać więcej szczegółów na temat skutecznych strategii promptowania, zobacz Przewodnik po promptowaniu Whisper.
Ustaw akcelerację GPU
Ustawia, czy używać akceleracji GPU do rozpoznawania mowy (dotyczy obecnie tylko systemu Windows).
Ustaw ID urządzenia GPU
Ustawia identyfikator urządzenia GPU do użycia w rozpoznawaniu mowy. Wartość domyślna to 0. Jest to przydatne w systemach z wieloma procesorami graficznymi, aby określić, który GPU powinien być używany do procesu rozpoznawania. Jeśli podany identyfikator urządzenia GPU jest nieprawidłowy, zostanie użyty pierwszy dostępny indeks urządzenia GPU.