Jak korzystać z wtyczki
Wtyczka Runtime Text To Speech syntezuje tekst na mowę przy użyciu modeli głosowych do pobrania. Modele te są zarządzane w ustawieniach wtyczki w edytorze, pobierane i pakowane do użycia w czasie rzeczywistym. Wykonaj poniższe kroki, aby rozpocząć.
Strona edytora
Pobierz odpowiednie modele głosowe dla swojego projektu, jak opisano tutaj. Możesz pobrać wiele modeli głosowych jednocześnie.
Strona runtime
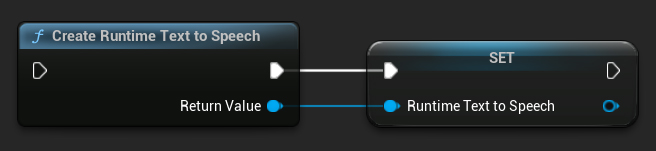
Utwórz syntezator za pomocą funkcji CreateRuntimeTextToSpeech. Upewnij się, że zachowujesz do niego referencję (np. jako oddzielną zmienną w Blueprints lub UPROPERTY w C++), aby zapobiec jego usunięciu przez garbage collector.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Syntetyzowanie Mowy
Wtyczka oferuje dwa tryby syntezy tekstu na mowę:
- Standardowa synteza tekstu na mowę: Syntetyzuje cały tekst i zwraca kompletny dźwięk po zakończeniu
- Strumieniowa synteza tekstu na mowę: Dostarcza fragmenty dźwięku w miarę ich generowania, umożliwiając przetwarzanie w czasie rzeczywistym
Każdy tryb obsługuje dwie metody wyboru modeli głosowych:
- Po nazwie: Wybierz model głosowy po jego nazwie (zalecane dla UE 5.4+)
- Po obiekcie: Wybierz model głosowy przez bezpośrednie odwołanie (zalecane dla UE 5.3 i wcześniejszych)
Standardowa synteza tekstu na mowę
Po nazwie
- Blueprint
- C++
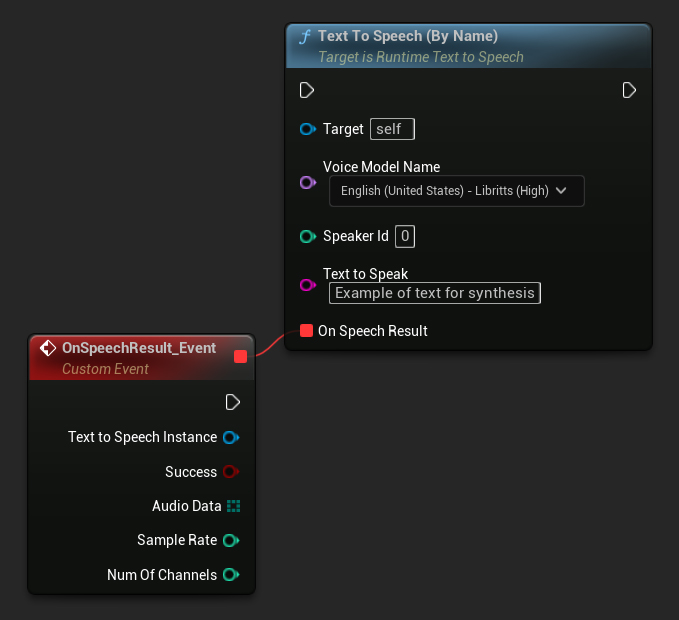
Funkcja Text To Speech (By Name) jest wygodniejsza w Blueprints od wersji UE 5.4. Pozwala wybierać modele głosowe z listy rozwijanej pobranych modeli. W wersjach UE poniżej 5.3 ta lista rozwijana się nie pojawia, więc jeśli używasz starszej wersji, musisz ręcznie iterować po tablicy modeli głosowych zwróconej przez GetDownloadedVoiceModels, aby wybrać potrzebny model.
W C++ wybór modeli głosowych może być nieco bardziej złożony z powodu braku listy rozwijanej. Możesz użyć funkcji GetDownloadedVoiceModelNames, aby pobrać nazwy pobranych modeli głosowych i wybrać potrzebną. Następnie możesz wywołać funkcję TextToSpeechByName, aby zsyntetyzować tekst przy użyciu wybranej nazwy modelu głosowego.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Według Obiektu
- Blueprint
- C++
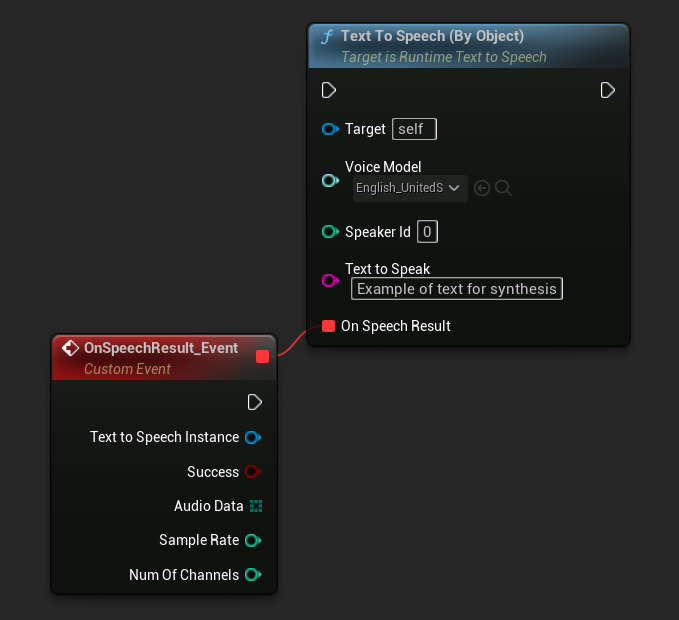
Funkcja Text To Speech (By Object) działa we wszystkich wersjach Unreal Engine, ale przedstawia modele głosowe jako listę rozwijaną referencji do assetów, co jest mniej intuicyjne. Ta metoda jest odpowiednia dla UE 5.3 i wcześniejszych, lub jeśli twój projekt wymaga bezpośredniej referencji do asseta modelu głosowego z jakiegokolwiek powodu.
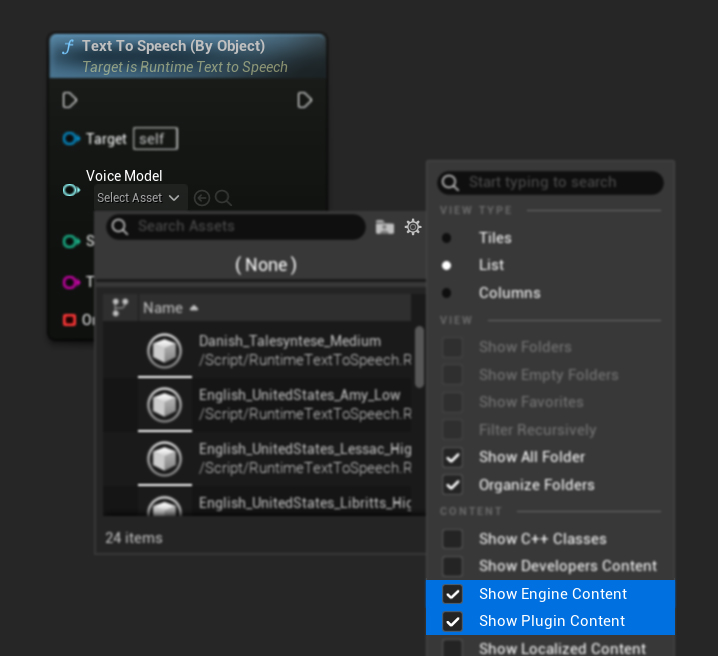
Jeśli pobrałeś modele, ale ich nie widzisz, otwórz listę rozwijaną Voice Model, kliknij ustawienia (ikona koła zębatego) i włącz zarówno Show Plugin Content, jak i Show Engine Content, aby modele stały się widoczne.
W C++, wybór modeli głosowych może być nieco bardziej złożony z powodu braku listy rozwijanej. Możesz użyć funkcji GetDownloadedVoiceModelNames, aby pobrać nazwy pobranych modeli głosowych i wybrać ten, którego potrzebujesz. Następnie, możesz wywołać funkcję GetVoiceModelFromName, aby uzyskać obiekt modelu głosowego i przekazać go do funkcji TextToSpeechByObject, aby zsyntetyzować tekst.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Streaming Text-to-Speech
Dla dłuższych tekstów lub gdy chcesz przetwarzać dane audio w czasie rzeczywistym, w miarę ich generowania, możesz użyć wersji streamingowych funkcji Text-to-Speech:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNamew C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjectw C++)
Te funkcje dostarczają dane audio w porcjach (chunkach) w miarę ich generowania, umożliwiając natychmiastowe przetwarzanie bez oczekiwania na zakończenie całej syntezy. Jest to przydatne w różnych zastosowaniach, takich jak odtwarzanie audio w czasie rzeczywistym, wizualizacja na żywo lub w każdym scenariuszu, w którym potrzebujesz przetwarzać dane mowy przyrostowo.
Streaming By Name
- Blueprint
- C++
Funkcja Streaming Text To Speech (By Name) działa podobnie do zwykłej wersji, ale dostarcza audio w porcjach poprzez delegata On Speech Chunk.
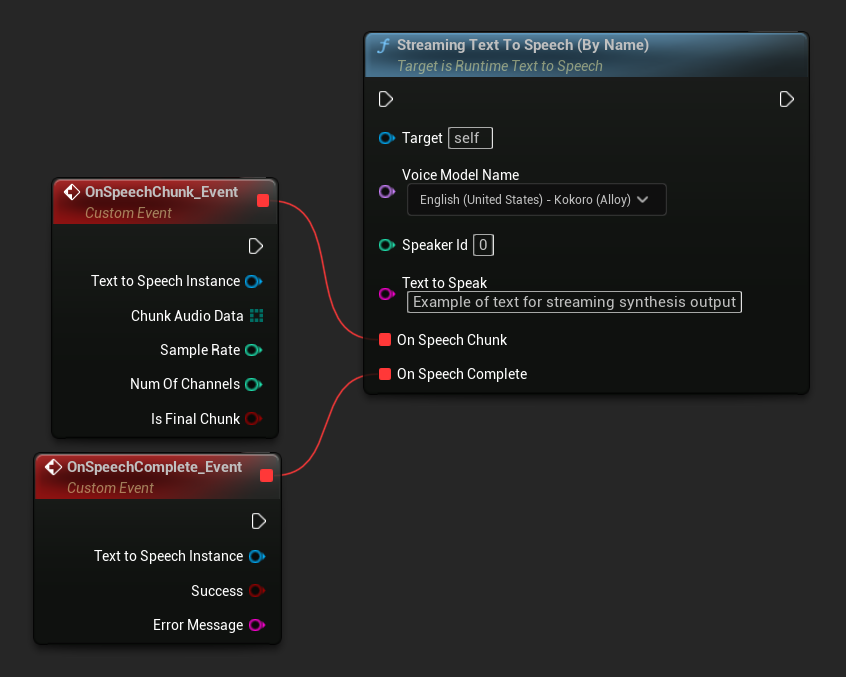
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Streaming Według Obiektu
- Blueprint
- C++
Funkcja Streaming Text To Speech (By Object) zapewnia tę samą funkcjonalność strumieniowania, ale przyjmuje referencję do obiektu modelu głosu.
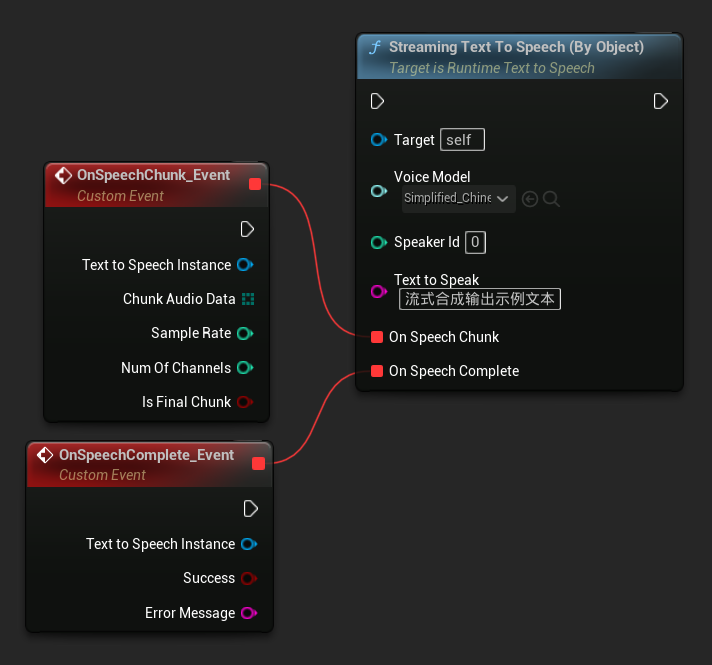
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Odtwarzanie dźwięku
- Regularne odtwarzanie
- Streaming Playback
Dla standardowego (niestrumieniowego) zamiany tekstu na mowę, delegat On Speech Result dostarcza zsyntetyzowany dźwięk jako dane PCM w formacie float (jako tablicę bajtów w Blueprints lub TArray<uint8> w C++), wraz z Sample Rate i Num Of Channels.
Do odtwarzania zaleca się użycie wtyczki Runtime Audio Importer do konwersji surowych danych audio na odtwarzalną falę dźwiękową.
- Blueprint
- C++
Oto przykład, jak mogą wyglądać węzły Blueprint do syntezy tekstu i odtwarzania dźwięku (Kopiowalne węzły):
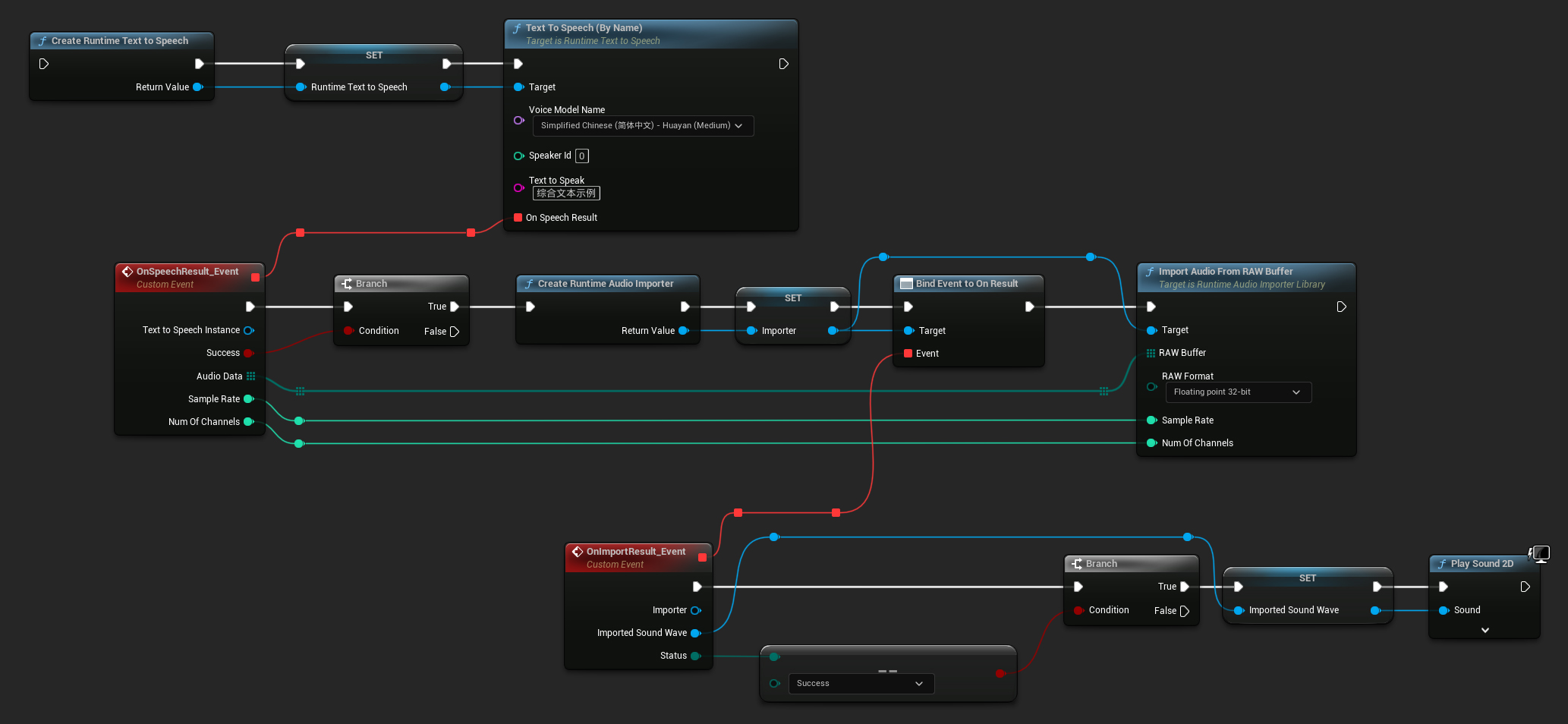
Oto przykład, jak zsyntetyzować tekst i odtworzyć dźwięk w C++:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Dla streamingu tekstu na mowę, będziesz otrzymywać dane audio w porcjach jako dane PCM w formacie float (jako tablica bajtów w Blueprints lub TArray<uint8> w C++), wraz z Sample Rate i Num Of Channels. Każdą porcję można przetwarzać natychmiast, gdy stanie się dostępna.
Do odtwarzania w czasie rzeczywistym zaleca się użycie wtyczki Runtime Audio Importer Streaming Sound Wave, która jest specjalnie zaprojektowana do streamingu audio lub przetwarzania w czasie rzeczywistym.
- Blueprint
- C++
Oto przykład, jak mogą wyglądać węzły Blueprint dla streamingu tekstu na mowę i odtwarzania dźwięku (Kopiowalne węzły):
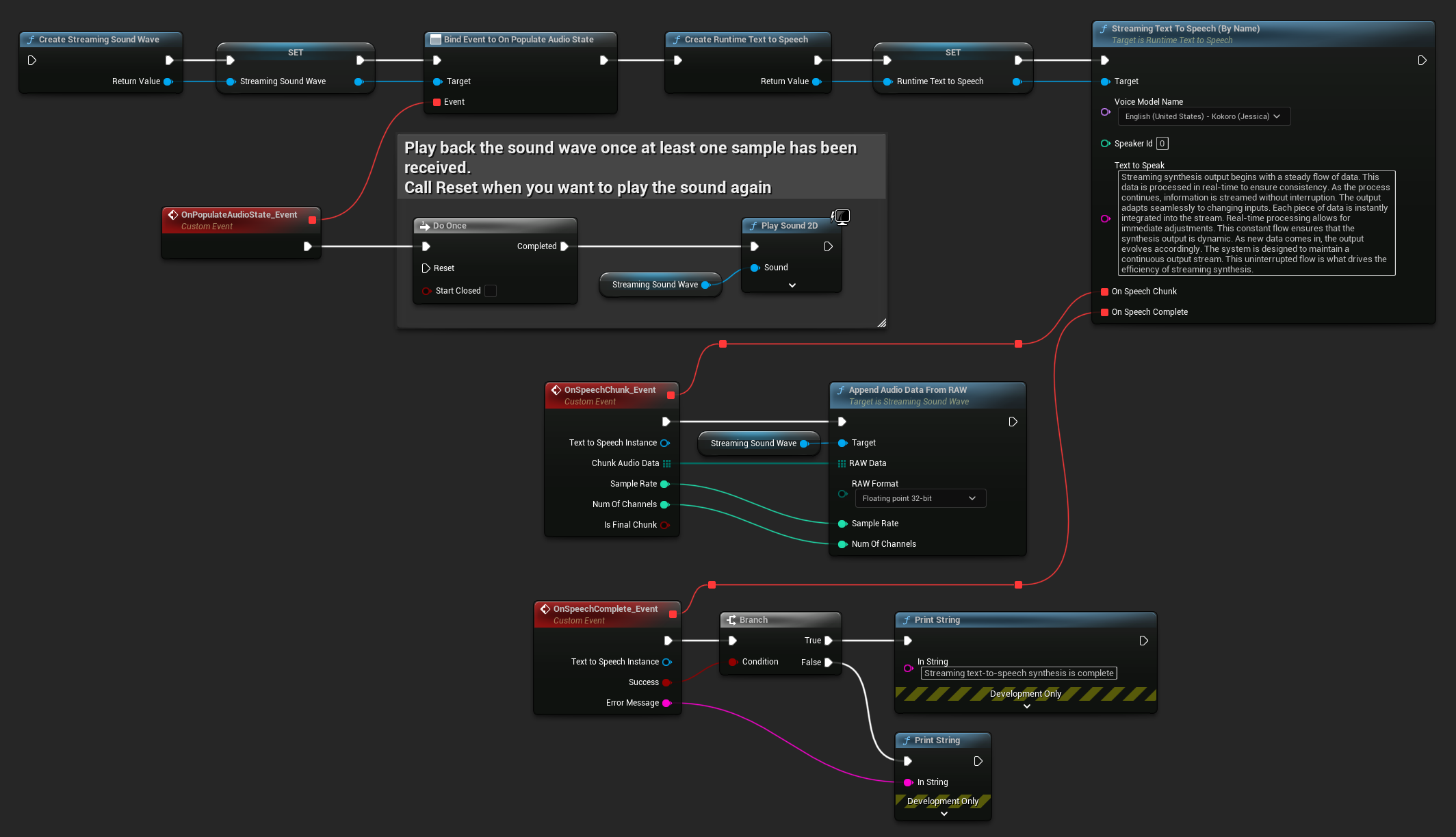
Oto przykład, jak zaimplementować streaming tekstu na mowę z odtwarzaniem w czasie rzeczywistym w C++:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Anulowanie zamiany tekstu na mowę
Możesz anulować trwającą operację syntezy mowy w dowolnym momencie, wywołując funkcję CancelSpeechSynthesis na swojej instancji syntezatora:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Gdy synteza zostanie anulowana:
- Proces syntezy zatrzyma się tak szybko, jak to możliwe
- Wszelkie trwające wywołania zwrotne zostaną zakończone
- Delegat ukończenia zostanie wywołany z
bSuccess = falsei komunikatem błędu wskazującym, że synteza została anulowana - Wszelkie zasoby przydzielone do syntezy zostaną właściwie zwolnione
Jest to szczególnie przydatne w przypadku długich tekstów lub gdy trzeba przerwać odtwarzanie, aby rozpocząć nową syntezę.
Wybór mówcy
Obie funkcje Text To Speech akceptują opcjonalny parametr ID mówcy, który jest przydatny podczas pracy z modelami głosowymi obsługującymi wielu mówców. Możesz użyć funkcji GetSpeakerCountFromVoiceModel lub GetSpeakerCountFromModelName, aby sprawdzić, czy wybrany model głosowy obsługuje wielu mówców. Jeśli dostępnych jest wielu mówców, po prostu określ żądane ID mówcy podczas wywoływania funkcji Text To Speech. Niektóre modele głosowe oferują szeroką różnorodność - na przykład English LibriTTS zawiera ponad 900 różnych mówców do wyboru.
Wtyczka Runtime Audio Importer zapewnia również dodatkowe funkcje, takie jak eksportowanie danych audio do pliku, przekazywanie ich do SoundCue, MetaSound i nie tylko. Aby uzyskać więcej szczegółów, zapoznaj się z dokumentacją Runtime Audio Importer.