Provedores de Tradução
O AI Localization Automator suporta cinco diferentes provedores de IA, cada um com pontos fortes e opções de configuração únicos. Escolha o provedor que melhor se adequa às necessidades, orçamento e requisitos de qualidade do seu projeto.
Ollama (IA Local)
Melhor para: Projetos sensíveis à privacidade, tradução offline, uso ilimitado
O Ollama executa modelos de IA localmente na sua máquina, fornecendo privacidade e controle completos sem custos de API ou requisitos de internet.
Modelos Populares
- translategemma:12b (Modelo de tradução especializado baseado no Gemma 3)
- llama3.2 (Propósito geral recomendado)
- mistral (Alternativa eficiente)
- codellama (Traduções com consciência de código)
- E muitos outros modelos da comunidade
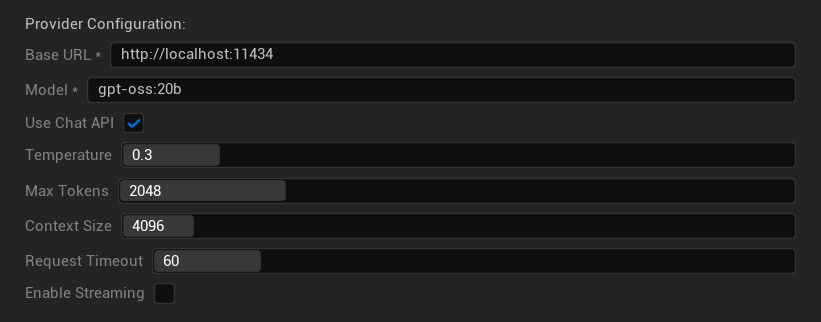
Opções de Configuração
- URL Base: Servidor Ollama local (padrão:
http://localhost:11434) - Modelo: Nome do modelo instalado localmente (obrigatório)
- Usar API de Chat: Habilitar para melhor manipulação de conversas
- Temperatura: 0.0-2.0 (0.3 recomendado)
- Tokens Máximos: 1-8.192 tokens
- Tamanho do Contexto: 512-32.768 tokens
- Tempo Limite da Requisição: 10-300 segundos (modelos locais podem ser mais lentos)
- Habilitar Streaming: Para processamento de resposta em tempo real
Pontos Fortes
- ✅ Privacidade completa (nenhum dado sai da sua máquina)
- ✅ Sem custos de API ou limites de uso
- ✅ Funciona offline
- ✅ Controle total sobre os parâmetros do modelo
- ✅ Grande variedade de modelos da comunidade
- ✅ Sem dependência de fornecedor
Considerações
- 💻 Requer configuração local e hardware capaz
- ⚡ Geralmente mais lento que provedores em nuvem
- 🔧 Configuração mais técnica necessária
- 📊 A qualidade da tradução varia significativamente conforme o modelo (alguns podem superar provedores em nuvem)
- 💾 Grandes requisitos de armazenamento para modelos
Configurando o Ollama
- Instale o Ollama: Baixe em ollama.ai e instale no seu sistema
- Baixe Modelos: Use
ollama pull translategemma:12bpara baixar o modelo escolhido - Inicie o Servidor: O Ollama é executado automaticamente, ou inicie com
ollama serve - Configure o Plugin: Defina a URL base e o nome do modelo nas configurações do plugin
- Teste a Conexão: O plugin verificará a conectividade quando você aplicar a configuração
OpenAI
Melhor para: Maior qualidade geral de tradução, ampla seleção de modelos
A OpenAI fornece modelos de linguagem líderes do setor através de sua API Chat Completions, incluindo os modelos GPT mais recentes, modelos de raciocínio e modelos habilitados para busca na web.
Modelos Disponíveis
Família GPT-5 (Modelos principais)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
Família GPT-4.1 (Alto desempenho)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
Família GPT-4o (Multimodal)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
Série O (Modelos de raciocínio — temperatura/top_p não suportados)
- o1, o1-pro, o3, o3-mini, o4-mini
Modelos de Busca na Web (Temperatura/top_p não suportados)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
Legado / Visualização
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
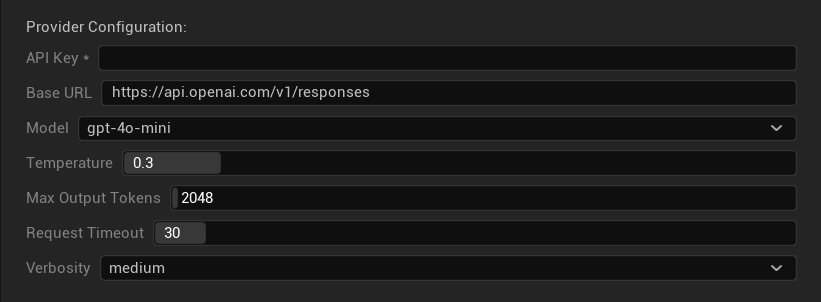
Opções de Configuração
- Chave da API: Sua chave de API da OpenAI (obrigatória)
- URL Base: Endpoint da API (padrão:
https://api.openai.com/v1/chat/completions) - Modelo: Escolha entre os modelos disponíveis listados acima
- Usar Temperatura: Alternar parâmetro de temperatura ligado/desligado (ignorado automaticamente para modelos de raciocínio da série o e modelos de busca na web)
- Temperatura: 0.0–2.0 (0.3 recomendado para consistência de tradução)
- Top P: Parâmetro de amostragem de núcleo 0.0–1.0 (ignorado para modelos de raciocínio da série o e modelos de busca na web)
- Tokens de Conclusão Máximos: 1–128.000 tokens (inclui tokens de saída e de raciocínio)
- Tempo Limite da Requisição: 5–300 segundos
Pontos Fortes
- ✅ Traduções consistentemente de alta qualidade
- ✅ Excelente compreensão de contexto
- ✅ Forte preservação de formato
- ✅ Amplo suporte a idiomas
- ✅ Tempo de atividade da API confiável
Considerações
- 💰 Custo mais alto por requisição
- 🌐 Requer conexão com a internet
- ⏱️ Limites de uso baseados no nível
Anthropic Claude
Melhor para: Traduções com nuances, conteúdo criativo, aplicações focadas em segurança
Os modelos Claude se destacam em entender contexto e nuance, tornando-os ideais para jogos com muita narrativa e cenários de localização complexos.
Modelos Disponíveis
Família Claude 4.6 (Mais recente)
- claude-opus-4-6, claude-sonnet-4-6
Família Claude 4.5
- claude-haiku-4-5 (Rápido e eficiente)
- claude-sonnet-4-5, claude-opus-4-5
Família Claude 4.x
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Família Claude 3.x (Legado)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
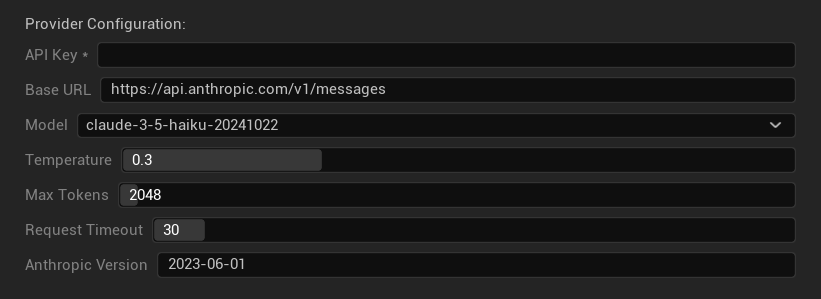
Opções de Configuração
- Chave da API: Sua chave de API da Anthropic (obrigatória)
- URL Base: Endpoint da API Claude
- Modelo: Selecione da família de modelos Claude
- Temperatura: 0.0–1.0 (0.3 recomendado)
- Top K: Parâmetro de amostragem Top-K (0 = não definido)
- Tokens Máximos: 1–64.000 tokens
- Tempo Limite da Requisição: 5–300 segundos
- Versão Anthropic: Cabeçalho da versão da API
Pontos Fortes
- ✅ Consciência de contexto excepcional
- ✅ Ótimo para conteúdo criativo/narrativo
- ✅ Recursos de segurança robustos
- ✅ Capacidades de raciocínio detalhadas (pensamento estendido em modelos 3.7+)
- ✅ Excelente seguimento de instruções
Considerações
- 💰 Modelo de preços premium
- 🌐 Conexão com a internet necessária
- 📏 Limites de tokens variam conforme o modelo
DeepSeek
Melhor para: Tradução econômica, alta taxa de transferência, projetos com orçamento limitado
O DeepSeek oferece qualidade de tradução competitiva a uma fração do custo de outros provedores, tornando-o ideal para projetos de localização em grande escala.
Modelos Disponíveis
- deepseek-chat (Propósito geral, recomendado)
- deepseek-reasoner (Capacidades de raciocínio aprimoradas)
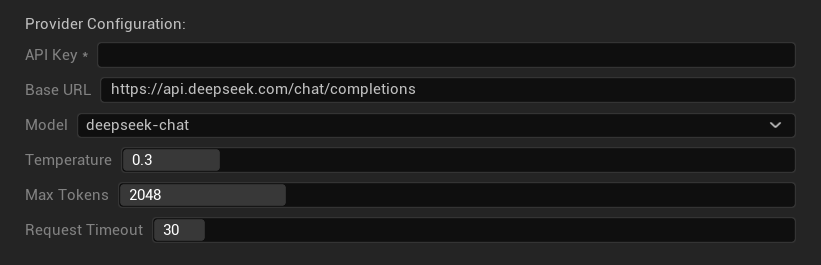
Opções de Configuração
- Chave da API: Sua chave de API do DeepSeek (obrigatória)
- URL Base: Endpoint da API DeepSeek
- Modelo: Escolha entre modelos de chat e de raciocínio
- Temperatura: 0.0-2.0 (0.3 recomendado)
- Tokens Máximos: 1-8.192 tokens
- Tempo Limite da Requisição: 5-300 segundos
Pontos Fortes
- ✅ Muito econômico
- ✅ Boa qualidade de tradução
- ✅ Tempos de resposta rápidos
- ✅ Configuração simples
- ✅ Limites de taxa altos
Considerações
- 📏 Limites de tokens mais baixos
- 🆕 Provedor mais novo (menor histórico)
- 🌐 Requer conexão com a internet
Google Gemini
Melhor para: Projetos multilíngues, tradução econômica, integração com ecossistema Google
Os modelos Gemini oferecem fortes capacidades multilíngues com preços competitivos e recursos únicos como modo de pensamento para raciocínio aprimorado.
Modelos Disponíveis
Família Gemini 3.x (Visualização)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Família Gemini 2.5 (Com suporte a pensamento)
- gemini-2.5-pro (Principal com pensamento)
- gemini-2.5-flash (Rápido, com suporte a pensamento)
- gemini-2.5-flash-lite (Variante leve)
Família Gemini 2.0
- gemini-2.0-flash, gemini-2.0-flash-lite
Apelidos Mais Recentes
- gemini-flash-latest, gemini-flash-lite-latest
Opções de Configuração
- Chave da API: Sua chave de API do Google AI (obrigatória)
- URL Base: Endpoint da API Gemini
- Modelo: Selecione da família de modelos Gemini
- Temperatura: 0.0–2.0 (0.3 recomendado)
- Tokens de Saída Máximos: 1–8.192 tokens
- Tempo Limite da Requisição: 5–300 segundos
- Habilitar Pensamento: Ativar raciocínio aprimorado para modelos 2.5+
- Orçamento de Pensamento: Controlar alocação de tokens de pensamento (0 = sem pensamento)
Pontos Fortes
- ✅ Forte suporte multilíngue
- ✅ Preços competitivos
- ✅ Raciocínio avançado (modo de pensamento)
- ✅ Integração com ecossistema Google
- ✅ Atualizações regulares de modelos com acesso de visualização aos modelos mais novos
Considerações
- 🧠 O modo de pensamento aumenta o uso de tokens
- 📏 Limites de tokens variáveis por modelo
- 🌐 Conexão com a internet necessária
Escolhendo o Provedor Certo
| Provedor | Melhor Para | Qualidade | Custo | Configuração | Privacidade |
|---|---|---|---|---|---|
| Ollama | Privacidade/offline | Variável* | Grátis | Avançada | Local |
| OpenAI | Maior qualidade | ⭐⭐⭐⭐⭐ | 💰💰💰 | Fácil | Nuvem |
| Claude | Conteúdo criativo | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Fácil | Nuvem |
| DeepSeek | Projetos com orçamento | ⭐⭐⭐⭐ | 💰 | Fácil | Nuvem |
| Gemini | Multilíngue | ⭐⭐⭐⭐ | 💰 | Fácil | Nuvem |
*A qualidade para o Ollama varia significativamente com base no modelo local usado - alguns modelos locais modernos podem igualar ou superar provedores em nuvem.
Dicas de Configuração do Provedor
Para Todos os Provedores em Nuvem:
- Armazene as chaves de API com segurança e não as envie para o controle de versão
- Comece com configurações de temperatura conservadoras (0.3) para traduções consistentes
- Monitore seu uso e custos da API
- Teste com lotes pequenos antes de execuções de tradução grandes
Para o Ollama:
- Garanta RAM adequada (8GB+ recomendado para modelos maiores)
- Use armazenamento SSD para melhor desempenho de carregamento de modelos
- Considere aceleração por GPU para inferência mais rápida
- Teste localmente antes de confiar nele para traduções de produção