Como usar o plugin
Este guia cobre a API completa de tempo de execução: criar uma instância de LLM, carregar modelos, enviar mensagens, baixar modelos em tempo de execução, gerenciar estado e funções utilitárias.
Crie uma instância de LLM
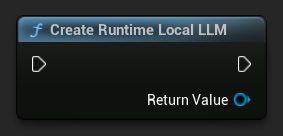
Comece criando um objeto Runtime Local LLM. Mantenha uma referência a ele (por exemplo, como uma variável em Blueprints ou uma UPROPERTY em C++) para evitar coleta de lixo prematura.
- Blueprint
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
Carregar um Modelo
Você deve carregar um modelo antes de enviar mensagens. O plugin oferece vários métodos de carregamento, dependendo do seu fluxo de trabalho.
Carregar por Nome
Se você gerenciar modelos através do painel de configurações do editor, use Load Model (By Name).
- Blueprint
- C++
- UE 5.3 e anteriores
- UE 5.4+
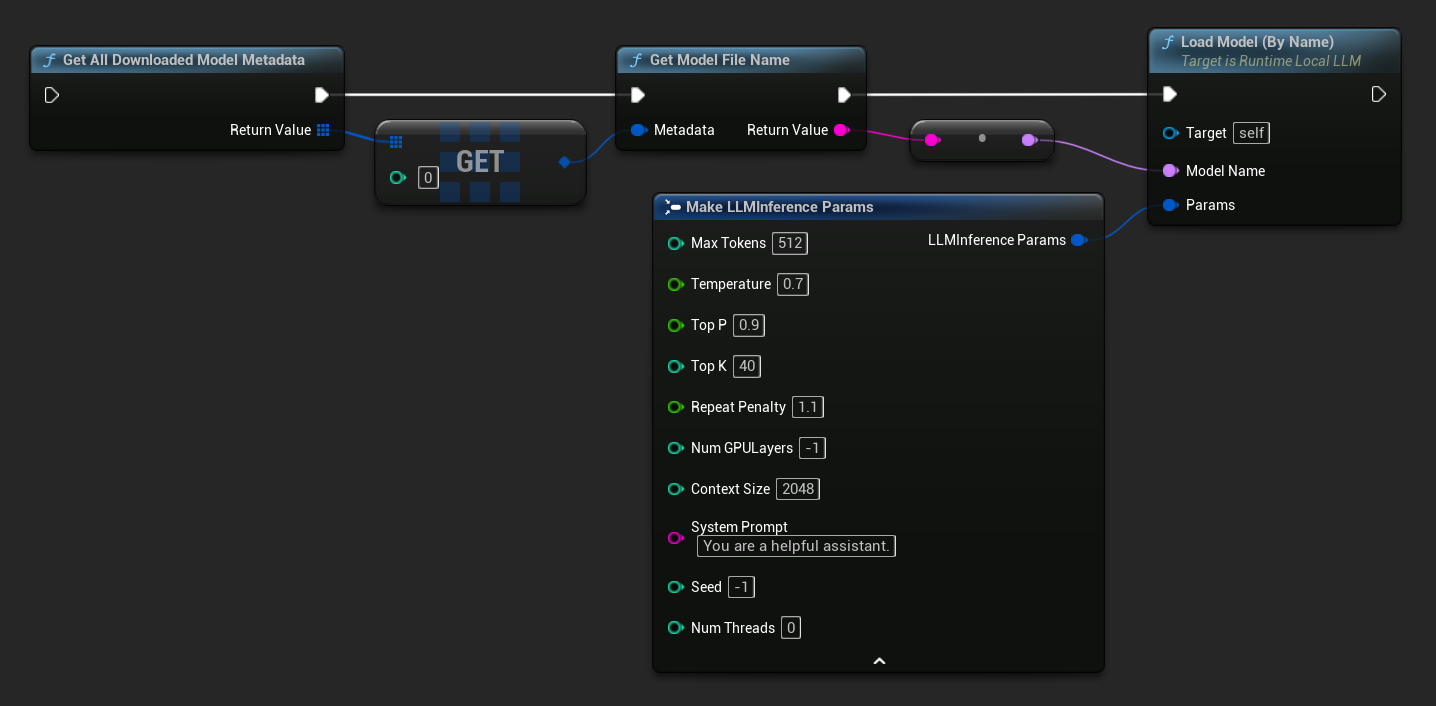
Em UE 5.3 e versões anteriores, o menu suspenso não aparece, então você precisa recuperar os modelos disponíveis manualmente. Use Get All Downloaded Model Metadata, obtenha o elemento no índice 0 (ou qualquer modelo que precisar), passe-o para Get Model File Name para recuperar a string do nome e, em seguida, passe-o para Load Model (By Name).
No UE 5.4 e versões posteriores, o Load Model (By Name) apresenta um menu suspenso com todos os modelos no disco — basta selecionar o modelo que deseja carregar.
Em C++, use GetAllDownloadedModelMetadata para recuperar os modelos disponíveis e GetModelFileName para obter o nome a ser passado para LoadModelByName.
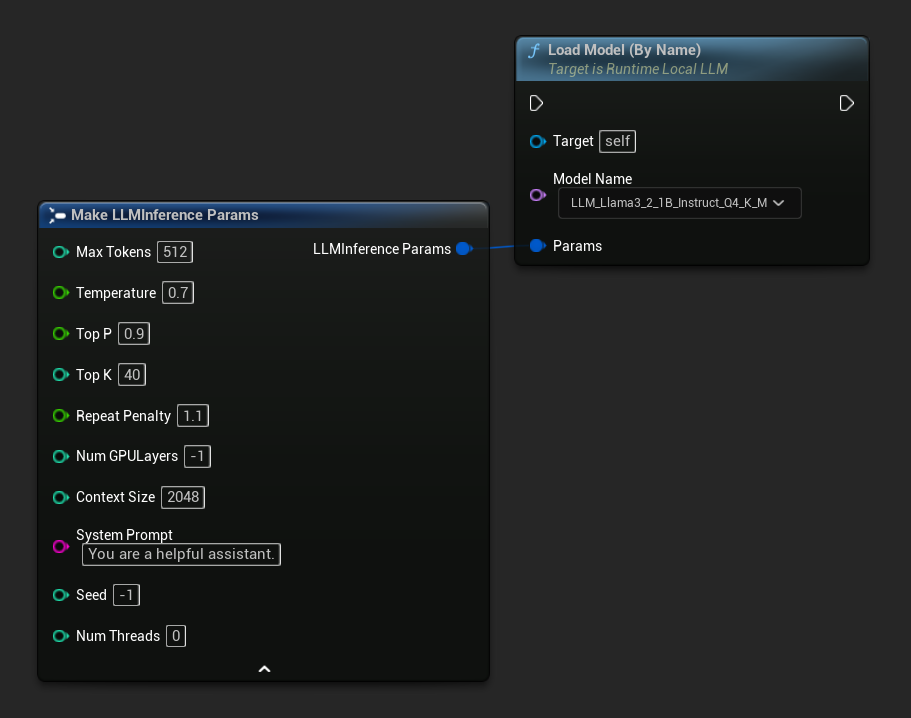
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
Carregar do Caminho do Arquivo
Carregue um modelo diretamente de um caminho de arquivo absoluto para um arquivo .gguf:
- Blueprint
- C++
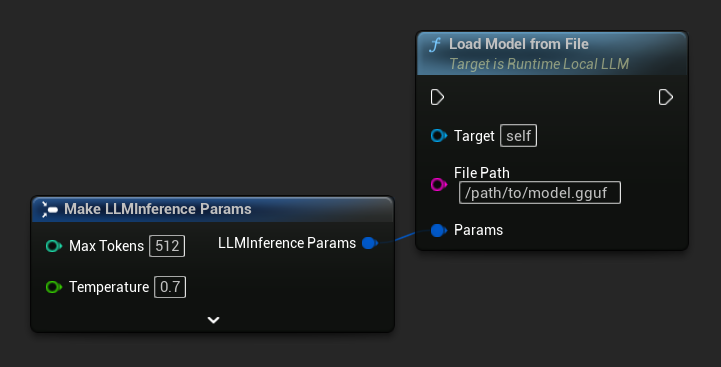
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
Carregar da URL (Baixar e Carregar)
Baixe um modelo de uma URL (se ainda não estiver no disco) e carregue-o automaticamente. Se o arquivo já existir localmente, o download é ignorado.
- Blueprint
- C++
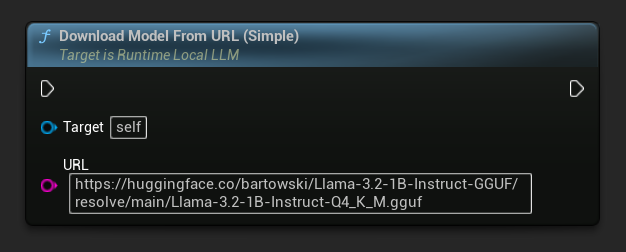
A variante mais simples aceita apenas uma URL - os metadados são derivados do nome do arquivo:
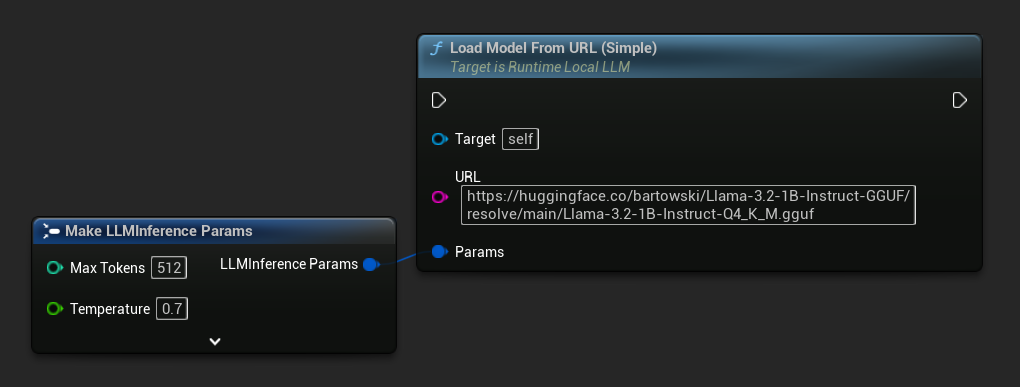
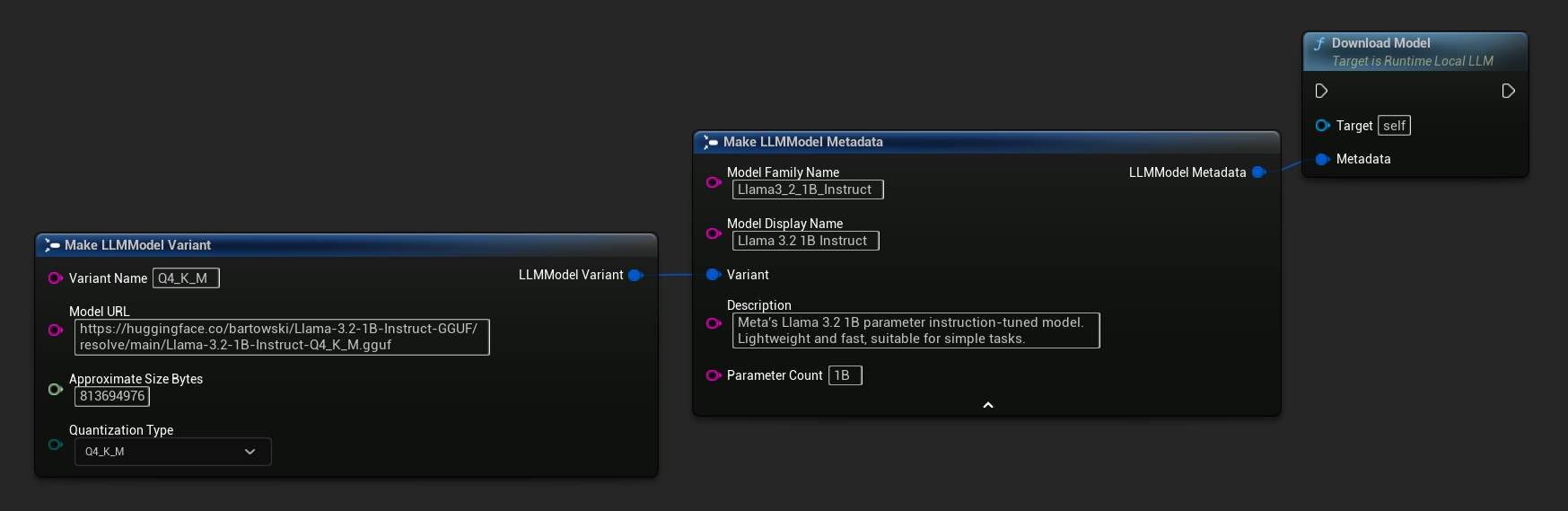
Você também pode usar Load Model From URL com metadados completos do modelo para obter informações mais detalhadas:
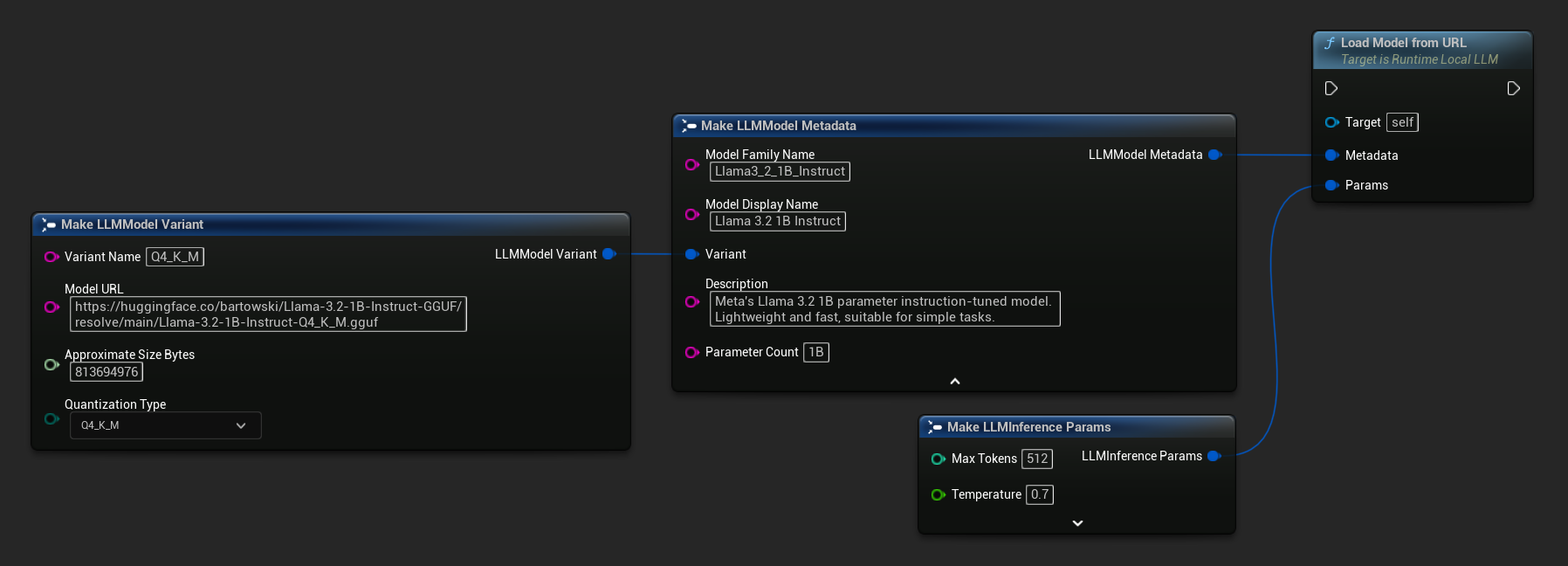
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
Carregamento Assíncrono (Blueprint)
Para lidar com a conclusão do carregamento e erros por meio de pinos de saída, em vez de vincular delegados manualmente, dois nós assíncronos estão disponíveis.
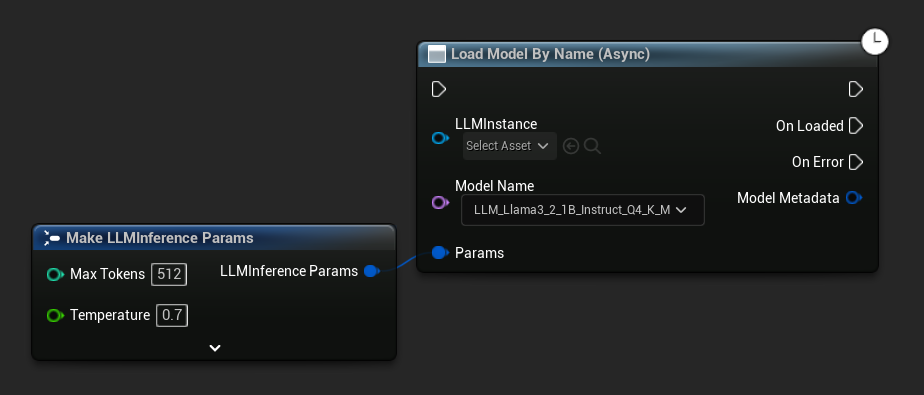
Load Model By Name (Async) espelha Load Model (By Name) - na UE 5.4+ ele apresenta um menu suspenso com todos os modelos no disco:
- UE 5.4+
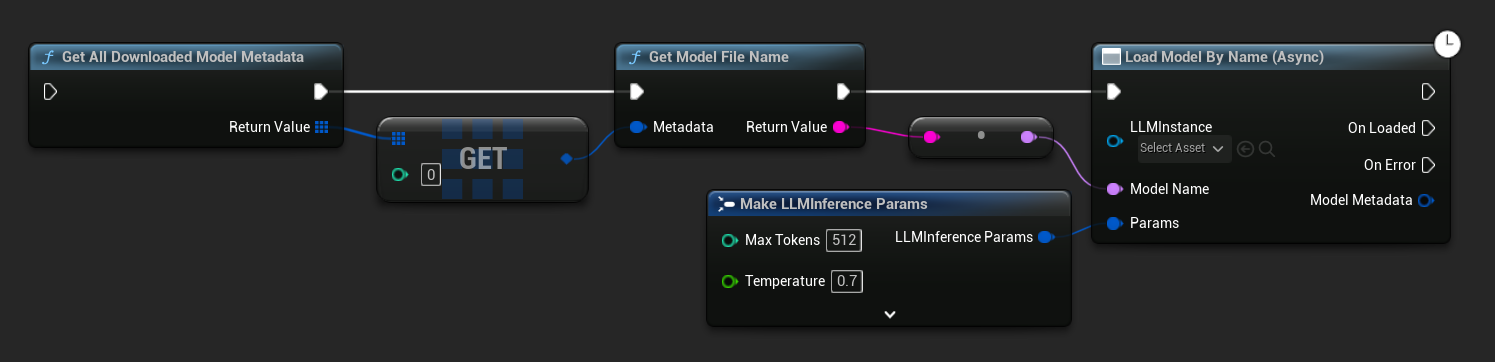
- UE 5.3 e anteriores
No UE 5.3 e versões anteriores, o menu suspenso não aparece. Use Get All Downloaded Model Metadata, obtenha o elemento no índice 0 (ou o modelo que você precisar), passe-o para Get Model File Name, e então passe o resultado para Load Model By Name (Async).
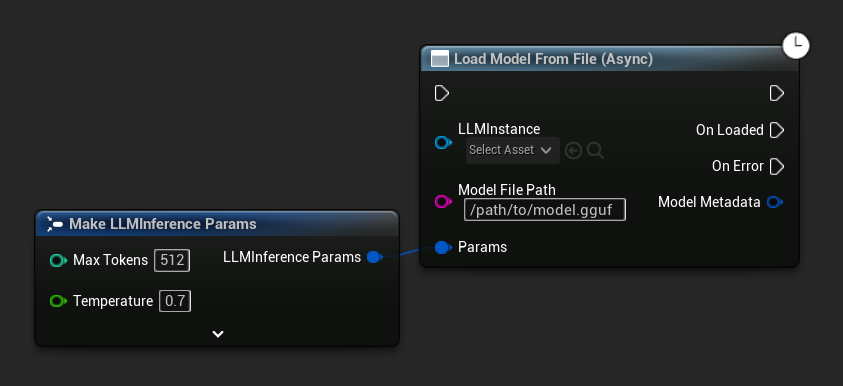
Load Model From File (Async) recebe um caminho de arquivo absoluto:
Vincular Eventos
Vincule-se aos delegates da instância do LLM para receber callbacks. Todos os callbacks são acionados na thread do jogo.
- Blueprint
- C++
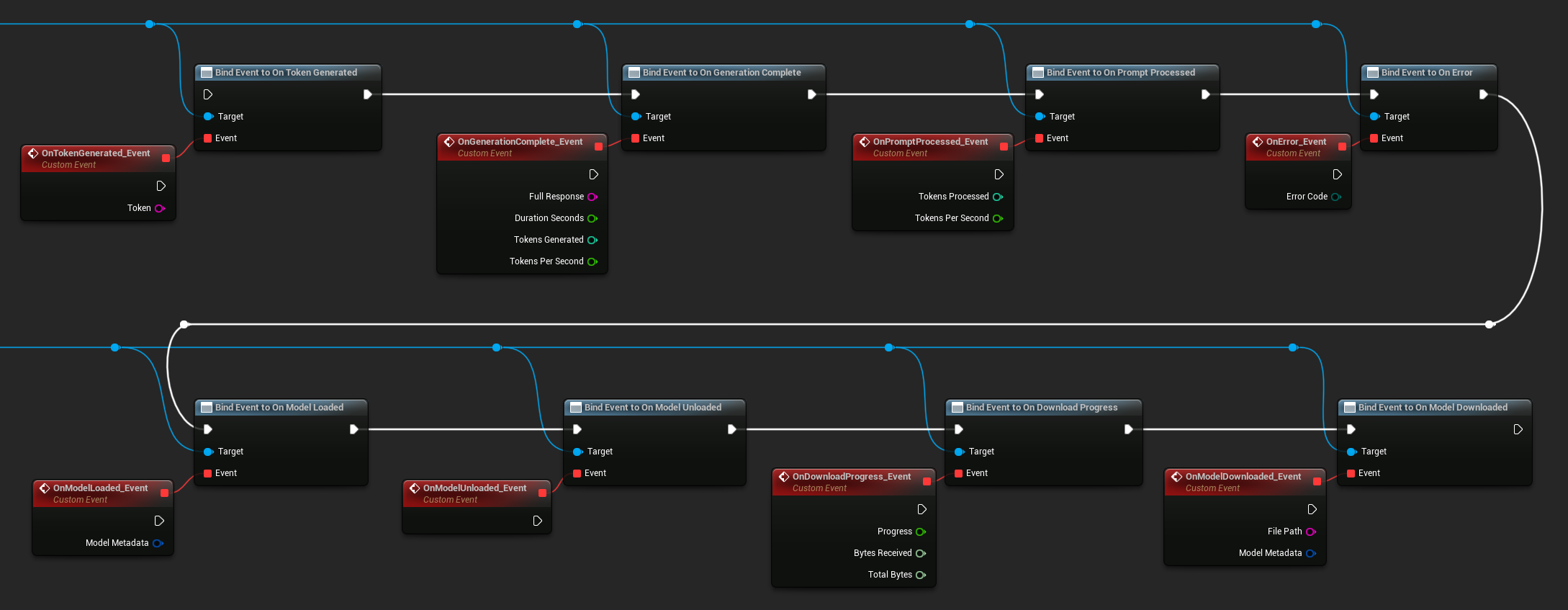
Delegados disponíveis:
- Ao Token Gerado: Dispara para cada token de saída
- Ao Finalizar Geração: Dispara quando a resposta completa está pronta, com duração, contagem de tokens e tokens por segundo
- Ao Processar Prompt: Dispara após o prompt de entrada ser processado, antes do início da geração
- Ao Ocorrer Erro: Dispara se um erro ocorrer durante qualquer operação
- Ao Modelo Carregado: Dispara quando um modelo termina de carregar
- Ao Modelo Descarregado: Dispara quando o modelo é descarregado
- Ao Progresso do Download: Dispara periodicamente durante o download de um modelo (fração de progresso, bytes recebidos, bytes totais)
- Ao Modelo Baixado: Dispara quando uma operação apenas de download é concluída
- Ao Conversa Salva: Dispara quando uma conversa foi gravada em um arquivo JSON
- Ao Conversa Carregada: Dispara quando uma conversa foi carregada de um arquivo ou instantâneo de memória
- Ao Histórico Resumido: Dispara quando a auto-sumarização comprime mensagens mais antigas (relata contagem de mensagens, tokens economizados e o resumo)
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda(
[](const FString& FullResponse, float DurationSeconds, int32 TokensGenerated, float TokensPerSecond)
{
});
LLM->OnPromptProcessedNative.AddLambda([](int32 TokensProcessed, float TokensPerSecond)
{
});
LLM->OnErrorNative.AddLambda([](ELLMErrorCode ErrorCode)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnModelUnloadedNative.AddLambda([]()
{
});
LLM->OnDownloadProgressNative.AddLambda([](float Progress, int64 BytesReceived, int64 TotalBytes)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& FilePath, const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnConversationSavedNative.AddLambda([](const FString& FilePath)
{
});
LLM->OnConversationLoadedNative.AddLambda([](const FLLMConversationSnapshot& Snapshot)
{
});
LLM->OnHistorySummarizedNative.AddLambda([](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
});
Enviar Mensagens
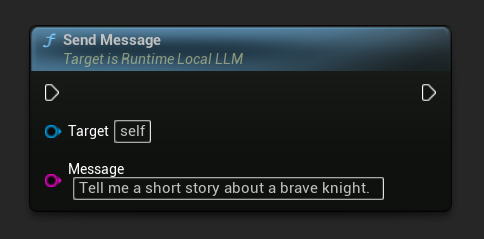
Depois que um modelo for carregado, envie uma mensagem do usuário para gerar uma resposta:
- Blueprint
- C++
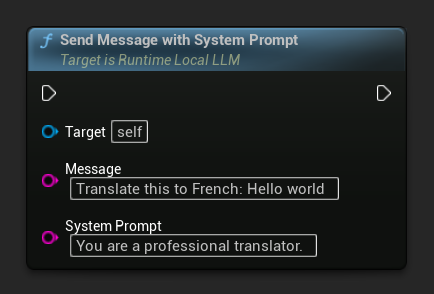
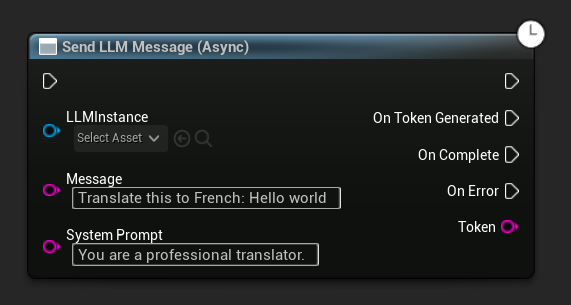
Para substituir o prompt do sistema para uma mensagem específica, use Send Message With System Prompt:
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
Tokens fluem através de OnTokenGenerated conforme são produzidos. Quando a geração termina, OnGenerationComplete é acionado com a resposta completa, duração, contagem de tokens e tokens por segundo.
Enviar Mensagem Assíncrona (Blueprint)
O nó Send LLM Message (Async) fornece pinos de saída dedicados para tokens, conclusão e erros:
Baixar Modelos em Tempo de Execução
Além do fluxo de download e carregamento descrito acima, você pode baixar um modelo para o disco sem carregá-lo. Isso é útil para pré-carregar modelos em uma tela de carregamento ou menu de configurações.
- Blueprint
- C++
Uma variante apenas com URL também está disponível:
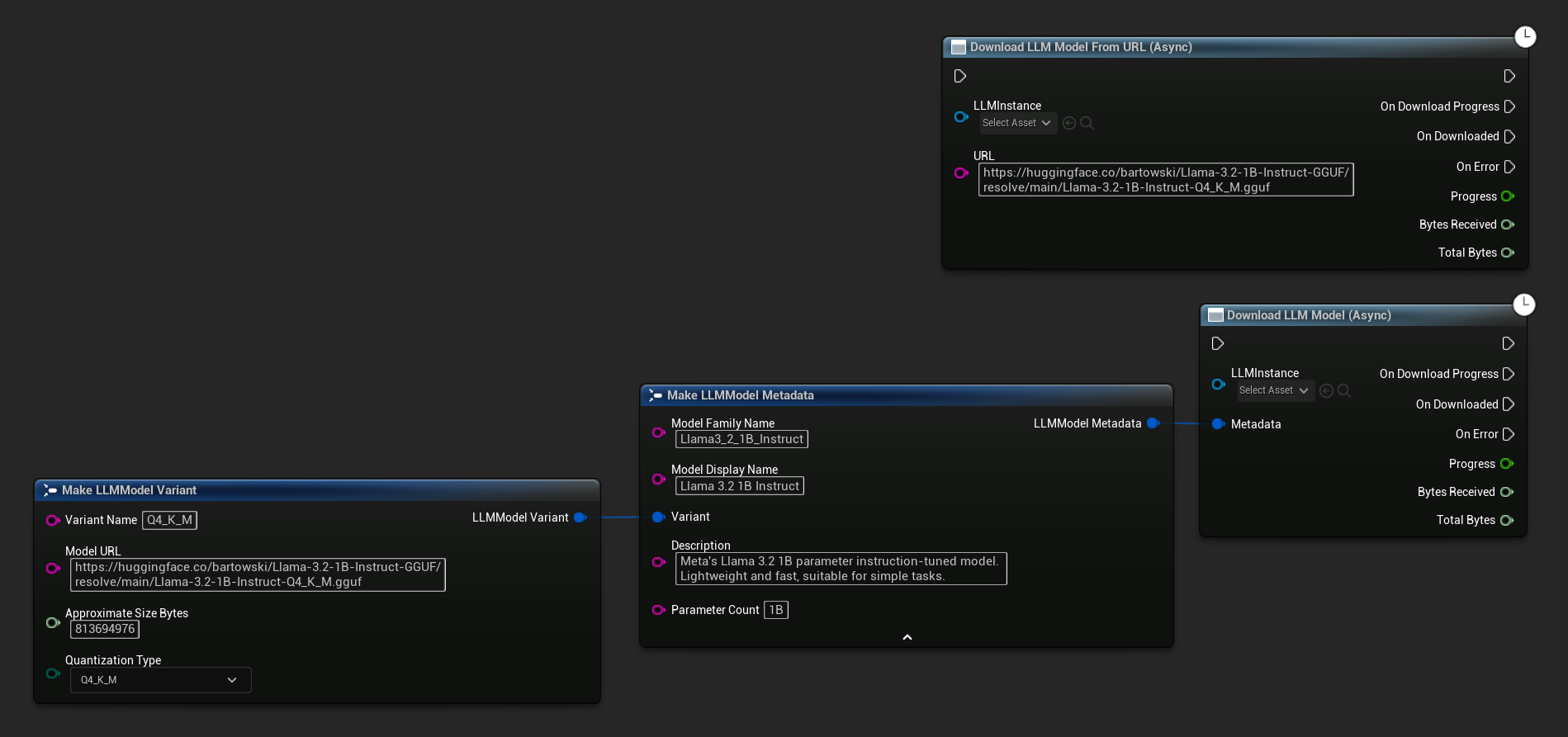
Os nós Download LLM Model (Async) e Download LLM Model From URL (Async) fornecem pinos de saída para progresso, conclusão e erros:
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
O delegado OnDownloadProgress relata o progresso durante o download. OnModelDownloaded é acionado quando o arquivo é salvo no disco.
Para cancelar um download em andamento:
- Blueprint
- C++
LLM->CancelDownload();
O plugin impede downloads duplicados automaticamente - se um download já estiver em andamento para o mesmo modelo, chamadas subsequentes são ignoradas.
Parar Geração
Para interromper uma geração em andamento:
- Blueprint
- C++
LLM->StopGeneration();
Redefinir Contexto da Conversa
Limpe o histórico da conversa para iniciar uma nova conversa:
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
Salvar e Carregar Conversas
O plugin pode persistir o histórico de conversas em disco como JSON ou mantê-lo na memória como um snapshot. Por padrão, o prompt do sistema é excluído dos salvamentos, para que o mesmo histórico de conversas possa ser carregado em diferentes instâncias de LLM com regras de sistema distintas. Isso é útil para cenários com múltiplos NPCs, onde cada personagem tem sua própria memória, mas pode compartilhar ou diferir em suas instruções de sistema.
Salvar em Arquivo
Salve a conversa atual em um arquivo JSON no disco:
- Blueprint
- C++
O parâmetro Include System Prompt controla se a mensagem do sistema (se presente) é gravada no arquivo. O padrão é false para portabilidade entre NPCs.
Ao Salvar Conversa é acionado quando o arquivo é escrito.
// Excludes system prompt by default
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"));
// Include the system prompt in the file
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"), /*bIncludeSystemPrompt=*/ true);
Carregar do Arquivo
Carregar uma conversa de volta de um arquivo JSON:
- Blueprint
- C++
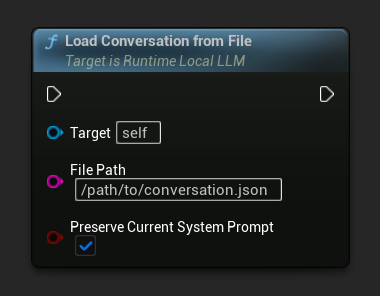
O parâmetro Preserve Current System Prompt (padrão true) mantém o prompt de sistema atualmente carregado intacto enquanto troca o histórico de conversação salvo. Esta é a configuração recomendada para a troca de memória de NPCs.
Ao Carregar a Conversa é acionado com o snapshot carregado.
// Keep current system prompt, swap in the saved history
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"));
// Replace the system prompt with whatever's in the file
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"), /*bPreserveCurrentSystemPrompt=*/ false);
Instantâneos em Memória (Fluxo de Trabalho com Múltiplos NPCs)
Para troca rápida de NPCs durante o jogo, armazene a conversa atual em memória em vez de gravá-la em disco. Esse padrão é a maneira recomendada de gerenciar vários NPCs compartilhando um único modelo carregado:
- Blueprint
- C++
O padrão típico de múltiplos NPCs usa um Mapa de Nome → Instantâneo de Conversa do LLM no seu gerenciador de NPCs ou estado do jogo:
- Ao alternar para outro NPC: leia o snapshot do seu mapa e chame
Load Conversation From MemorycomPreserve Current System Promptativado. - Ao alternar para outro NPC: leia o snapshot do seu mapa e chame
Load Conversation From MemorycomPreserve Current System Promptativado.

Como o prompt do sistema permanece carregado entre as trocas, a "personalidade" de cada NPC pode ser codificada em um prompt do sistema por NPC (chame Send Message With System Prompt uma vez após uma troca para atualizá-lo) ou compartilhada entre todos os NPCs.
// Maintain per-NPC snapshots
UPROPERTY()
TMap<FName, FLLMConversationSnapshot> NPCMemories;
// Save the currently active NPC's memory before switching
LLM->OnConversationLoadedNative.AddLambda([this](const FLLMConversationSnapshot& Snapshot)
{
NPCMemories.Add(CurrentNPC, Snapshot);
});
LLM->SaveConversationToMemory();
// Activate another NPC's memory
if (const FLLMConversationSnapshot* Found = NPCMemories.Find(NextNPC))
{
LLM->LoadConversationFromMemory(*Found, /*bPreserveCurrentSystemPrompt=*/ true);
CurrentNPC = NextNPC;
}
Snapshots são independentes de modelo — eles armazenam mensagens, não o estado do cache KV. O mesmo snapshot pode ser carregado em um modelo diferente (embora o estilo conversacional possa mudar). O campo OriginModelFamilyName no snapshot permite verificar qual modelo o produziu, caso queira impor compatibilidade.
Resumo Automático de Contexto
Conversas longas eventualmente excedem a janela de contexto do modelo, o que normalmente truncaria o histórico ou causaria erros. O recurso de sumarização automática do plugin monitora o uso do contexto e, quando um limite configurado é excedido, resume mensagens mais antigas em uma única mensagem de "memória" antes da próxima resposta ser gerada. Isso mantém os custos de tokens e a latência estáveis em conversas indefinidamente longas.
A sumarização é realizada pelo mesmo modelo carregado, portanto, não é necessário um segundo modelo ou chamada de API.
Ativar Auto-Resumo
- Blueprint
- C++
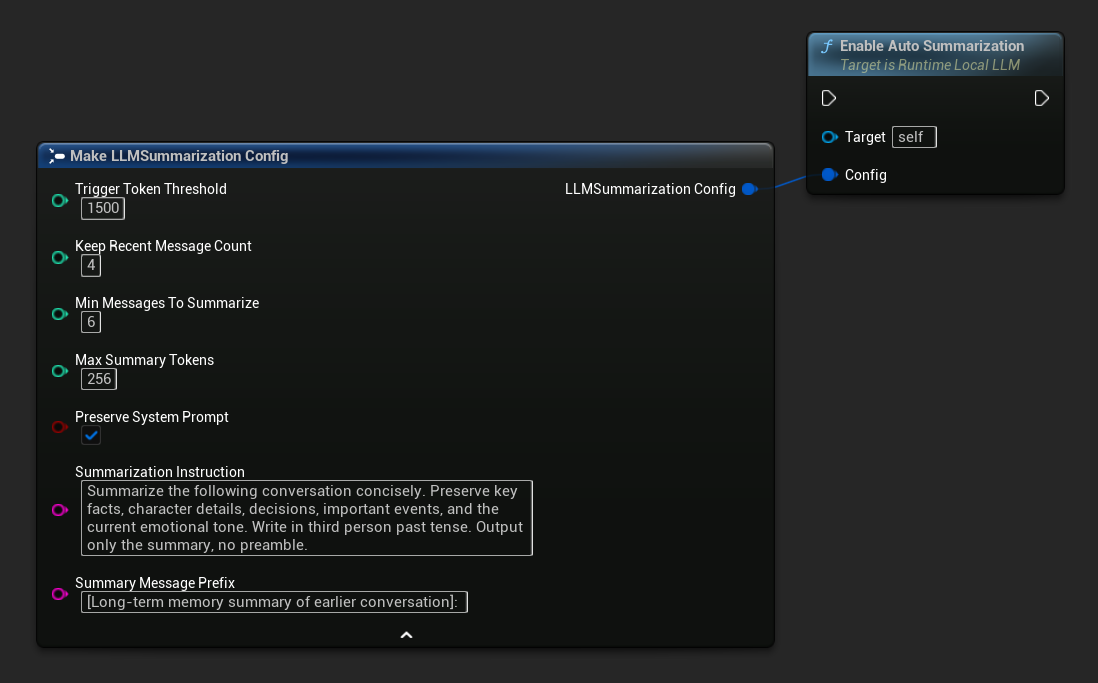
Use Get Default Summarization Config para obter padrões iniciais sensatos e, em seguida, ajuste conforme necessário:
FLLMSummarizationConfig Config = URuntimeLocalLLM::GetDefaultSummarizationConfig();
Config.TriggerTokenThreshold = 1500;
Config.KeepRecentMessageCount = 4;
Config.MinMessagesToSummarize = 6;
LLM->EnableAutoSummarization(Config);
Uma vez ativado, o resumo é executado automaticamente antes de cada chamada SendMessage quando necessário, sem exigir nenhuma ação adicional.
Por padrão, o resumo automático é executado antes do processamento de uma nova mensagem, pois precisa reconstruir o contexto, o que não pode ocorrer com segurança junto com a geração de uma resposta. Se preferir que ele seja executado após a resposta, enquanto o jogador está lendo e digitando, desative o resumo automático e acione-o manualmente: vincule a On Generation Complete, verifique Get Used Context Length em relação ao seu limite e chame Summarize Now se o limite for excedido. Como Summarize Now é enfileirado na mesma fila de tarefas em segundo plano, ele será executado logo após a resposta terminar e antes do processamento da próxima mensagem.
Referência de Configuração
| Parâmetro | Type | Padrão | Descrição |
|---|---|---|---|
| Limiar do Token de Gatilho | int32 | 1500 | O resumo é executado quando os tokens de contexto usados excedem este valor. Defina este valor em relação ao seu Tamanho do Contexto. Cerca de 60-75% é uma boa regra geral. |
| Manter Contagem de Mensagens Recentes | int32 | 4 | As mensagens N mais recentes nunca são resumidas, preservando a coerência imediata da conversa. |
| Mensagens Mínimas para Resumir | int32 | 6 | Pular sumarização se houver menos que este número de mensagens antigas elegíveis (evita sumários pequenos e sem propósito) |
| Máximo de Tokens de Resumo | int32 | 256 | Comprimento máximo do resumo gerado em tokens |
| Preservar o Prompt do Sistema | bool | true | Sempre mantenha a mensagem do sistema (índice 0) intacta. |
| Instrução de Resumo | FString | (see default) | A instrução enviada ao modelo para produzir o resumo |
| Prefixo da Mensagem de Resumo | FString | "[Resumo de memória de longo prazo da conversa anterior]:" | Prependido ao resumo gerado quando ele é inserido na conversa como uma mensagem de memória no papel de assistente. |
Gatilho Manual e Escuta para Resumos
Você pode acionar a sumarização manualmente a qualquer momento, independentemente do limite.
- Blueprint
- C++
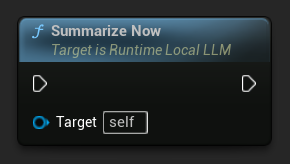
Vincule-se a On History Summarized para ser notificado quando uma passagem de sumarização for concluída. O evento informa quantas mensagens foram removidas, quantos tokens foram economizados e o texto do resumo gerado, útil para exibir um indicador sutil na interface de chat:
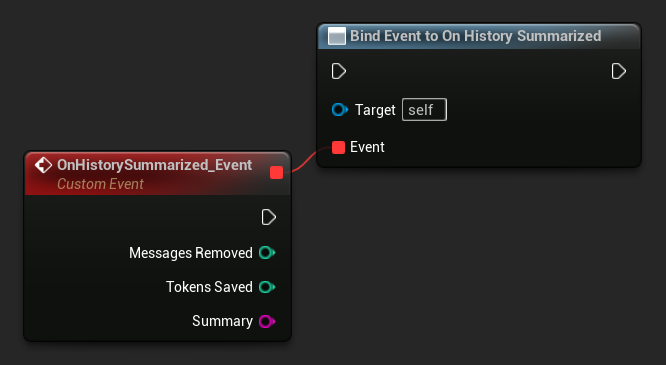
LLM->SummarizeNow();
LLM->OnHistorySummarizedNative.AddLambda(
[](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
UE_LOG(LogTemp, Log, TEXT("Summarized %d messages, saved %d tokens"), MessagesRemoved, TokensSaved);
});
Consultando o Comprimento de Contexto Utilizado
Use Get Used Context Length para verificar quantos tokens estão atualmente ocupados na janela de contexto do modelo. Este é o mesmo valor que o gatilho de sumarização automática integrado verifica em relação ao Trigger Token Threshold.
- Blueprint
- C++
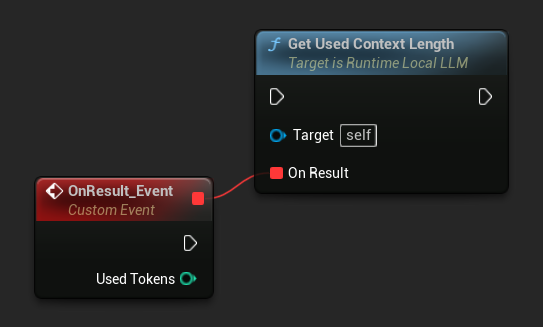
LLM->GetUsedContextLengthNative([](int32 UsedTokens)
{
UE_LOG(LogTemp, Log, TEXT("Used context: %d tokens"), UsedTokens);
});
Desativar a Sumarização Automática
- Blueprint
- C++
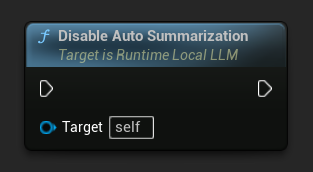
LLM->DisableAutoSummarization();
A desativação não desfaz os resumos já aplicados à conversa.
O resumo leva um momento para ser executado na thread de fundo (o modelo está gerando o resumo). Os callbacks de fluxo de tokens são suprimidos durante essa geração interna para que não apareçam na sua interface de chat. On History Summarized é acionado assim que a mesclagem é concluída.
Descarregar um Modelo
Recursos liberados quando um modelo não é mais necessário:
- Blueprint
- C++
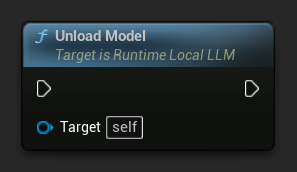
LLM->UnloadModel();
Estado da Consulta
Verifique o estado atual da instância do LLM:
- Blueprint
- C++
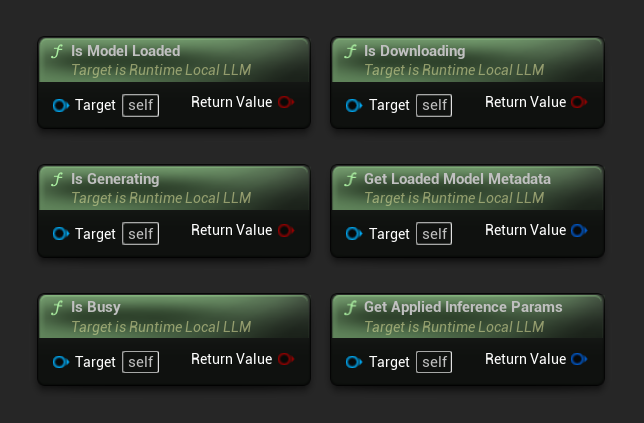
- Modelo Carregado: Verdadeiro se um modelo estiver pronto para inferência
- Gerando: Verdadeiro se a geração estiver em andamento
- Ocupado: Verdadeiro se alguma operação (carregamento, geração, download) estiver ativa
- Baixando: Verdadeiro se um download de modelo estiver em andamento
- Obter Metadados do Modelo Carregado: Retorna os metadados do modelo atual
- Obter Parâmetros de Inferência Aplicados: Retorna os parâmetros aplicados ao carregar
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
Funções da Biblioteca de Modelos
Um conjunto de funções utilitárias estáticas é fornecido para gerenciar arquivos de modelo no disco. Elas são úteis para criar uma interface de seleção de modelo ou verificar a disponibilidade do modelo em tempo de execução.
Obter Nomes de Modelos Baixados / Metadados
- Blueprint
- C++
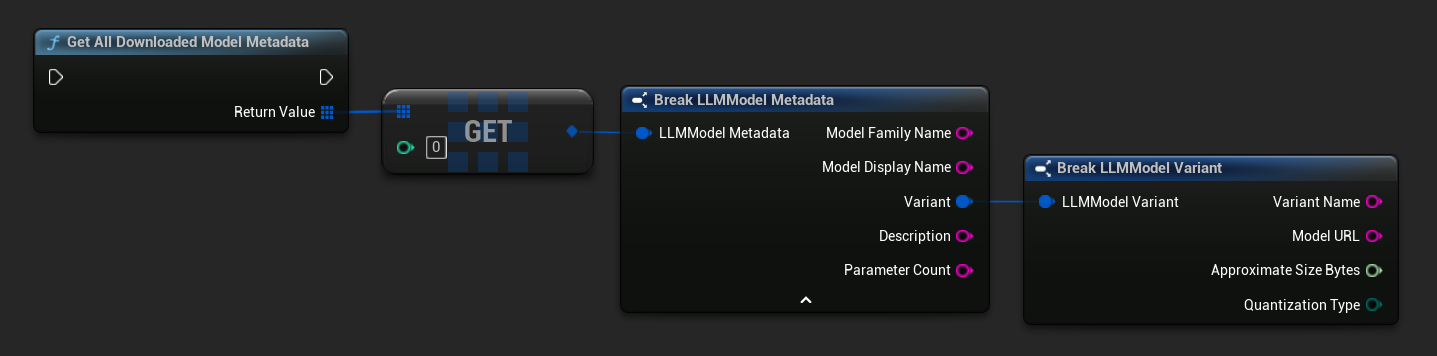
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
Verifique se um modelo está no disco
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
Obter o Caminho do Arquivo do Modelo
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
Excluir Arquivos do Modelo
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
Obter Modelos Pré-definidos e Disponíveis
- Blueprint
- C++
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
Gerar Metadados a partir de uma URL
Construa metadados de modelo a partir de uma URL bruta (os campos são derivados do nome do arquivo):
- Blueprint
- C++
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
Funções Utilitárias
Um conjunto de funções auxiliares é fornecido para formatação e exibição de erros.
Bytes para String Legível
Converte uma contagem de bytes para uma string legível (ex.: "4,07 GB"). Útil para exibir tamanhos de modelo na interface do usuário.
Progresso do Download do Formato
Formata uma string de progresso de download como "1,23 GB / 4,07 GB (30,2%)". Se o tamanho total for desconhecido, retorna apenas o valor recebido.
Obter Descrição do Erro / String do Código de Erro
Get LLM Error Description retorna uma descrição textual legível para um código de erro. Get LLM Error Code String retorna o nome do valor do enum como uma string (útil para registro/log).
Referência de Códigos de Erro
| Code | Valor | Descrição |
|---|---|---|
| Desconhecido | 0 | Um erro não especificado |
| FalhaAoCarregarModelo | 10 | O arquivo GGUF falhou ao carregar (arquivo corrompido, formato incompatível, etc.) |
| FalhaNaCriaçãoDoContexto | 11 | Falha ao criar o contexto de inferência |
| ModeloNãoCarregado | 20 | Foi feita uma tentativa de inferência sem nenhum modelo carregado. |
| Falha no Modelo de Chat | 21 | O modelo de template de chat falhou ao aplicar |
| Falha na Tokenização | 22 | O texto de entrada não pôde ser tokenizado. |
| ContextOverflow | 23 | O prompt + contexto excede o tamanho de contexto configurado. |
| PromptDecodeFailed | 24 | Os tokens do prompt falharam na decodificação. |
| ContextTooFullToGenerate | 25 | Espaço de contexto insuficiente restante para gerar a saída. |
| Falha na Decodificação da Geração | 30 | Um token falhou ao decodificar durante a geração. |
| GeraçãoTruncada | 31 | Geração interrompida porque o limite máximo de tokens foi atingido. |
| LLMInstanceNull | 40 | A instância do LLM é nula ou inválida. |
| ModelNotFoundOnDisk | 41 | O arquivo do modelo não existe no caminho esperado. |
| ModelURLEmpty | 42 | Foi solicitado um download com uma URL vazia. |
| ModeloDownloadCancelado | 43 | O download foi cancelado. |
| ModeloDownloadDadosVazios | 44 | O download foi concluído, mas o corpo da resposta estava vazio. |
| FalhaAoSalvarDownloadDoModelo | 45 | O download foi concluído, mas o arquivo não pôde ser salvo no disco. |