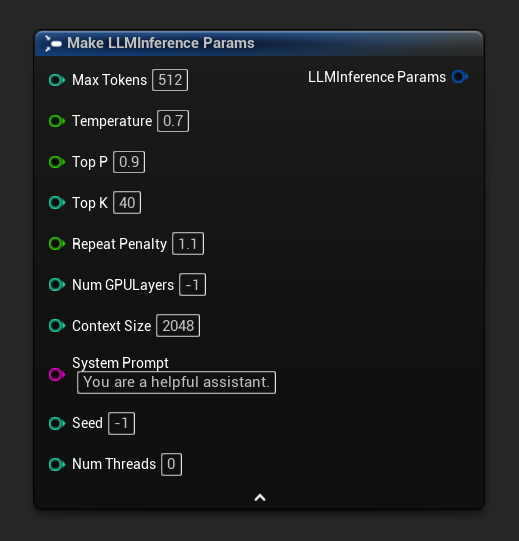
Parâmetros de inferência
A estrutura de Parâmetros de Inferência do LLM controla como o modelo carrega e gera texto. Você passa esses parâmetros ao carregar um modelo. Esta página descreve cada parâmetro e seu efeito.
Referência de Parâmetros
| Parâmetro | Type | Padrão | Alcance | Descrição |
|---|---|---|---|---|
| Máximo de Tokens | int32 | 512 | 1–8192 | Número máximo de tokens a serem gerados em uma única resposta |
| Temperatura | float | 0.7 | 0.0–2.0 | Controla a aleatoriedade. 0.0 = determinístico. Valores mais altos = saída mais criativa. |
| Top P | float | 0.9 | 0,0–1,0 | Amostragem por núcleo. Apenas tokens cuja probabilidade cumulativa exceda este valor são considerados. |
| Top K | int32 | 40 | 0–200 | Limita a seleção aos K tokens mais prováveis. 0 = desativado. |
| Penalidade de Repetição | float | 1.1 | 0.0–3.0 | Penaliza tokens que já aparecem na saída. 1.0 = sem penalidade |
| Camadas de GPU | int32 | -1 | -1–200 | Camadas do modelo para descarregar na GPU. -1 = automático. 0 = apenas CPU. |
| Tamanho do Contexto | int32 | 2048 | 128–131072 | Janela de contexto máxima em tokens. Valores maiores usam mais memória. |
| Prompt do Sistema | FString | "Você é um assistente útil." | — | Instrução do sistema que molda o comportamento do modelo |
| Semente | int32 | -1 | -1+ | Semente aleatória para saída reproduzível. -1 = aleatório |
| Número de Threads | int32 | 0 | 0–128 | Threads da CPU para geração. 0 = automático |
Uso
- Blueprint
- C++
Os parâmetros de inferência aparecem como um pino de struct nos nós de carregamento e assíncronos. Desmembre a struct para definir valores individuais:
Para obter um conjunto padrão de parâmetros como ponto de partida, use Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Recomendações de Plataforma
Dispositivo Móvel / RV (Android, iOS, Meta Quest)
- Tamanho do Contexto: 1024–2048
- Camadas de GPU: 0 (apenas CPU) a menos que o dispositivo tenha suporte confirmado para computação em GPU
- Máximo de Tokens: Abaixo de 256 para interações responsivas
- Número de Threads: 2–4 dependendo do dispositivo
Desktop (Windows, Mac, Linux)
- Tamanho do Contexto: 2048–8192 para a maioria das conversas
- Camadas de GPU: -1 (automático) para aproveitar a aceleração da GPU quando disponível
- Número de Threads: 0 (automático)
- Tokens Máximos: 512–2048 para respostas mais longas
Conversas Longas
Se sua aplicação mantém conversas ao longo de sessões longas (diálogo de NPCs, assistentes persistentes, roleplay), considere combinar o tamanho do contexto com sumarização automática em vez de apenas aumentar o Context Size. Um Context Size modesto de 2048–4096 com sumarização automática ativada mantém a latência e o uso de memória estáveis, enquanto janelas de contexto maiores tornam cada geração progressivamente mais lenta. Veja Sumarização Automática de Contexto.