Guia de Processamento de Áudio
Este guia aborda como configurar diferentes métodos de entrada de áudio para alimentar dados de áudio aos seus geradores de sincronia labial. Certifique-se de ter concluído o Guia de Configuração antes de prosseguir.
Processamento de Entrada de Áudio
Você precisa configurar um método para processar entrada de áudio. Existem várias formas de fazer isso, dependendo da sua fonte de áudio.
- Microfone (Tempo real)
- Microfone (Reprodução)
- Texto-para-Fala (Local)
- Texto-para-Fala (APIs Externas)
- A partir de Arquivo de Áudio/Buffer
- Buffer de Áudio em Streaming
Esta abordagem realiza a sincronização labial em tempo real enquanto fala no microfone:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Crie uma Onda Sonora Capturável usando o Runtime Audio Importer
- Para Linux com Pixel Streaming, use Pixel Streaming Capturable Sound Wave
- Antes de começar a capturar áudio, vincule-se ao delegado
OnPopulateAudioData - Na função vinculada, chame
ProcessAudioDatado seu Gerador de Visemas em Tempo de Execução - Comece a capturar áudio do microfone
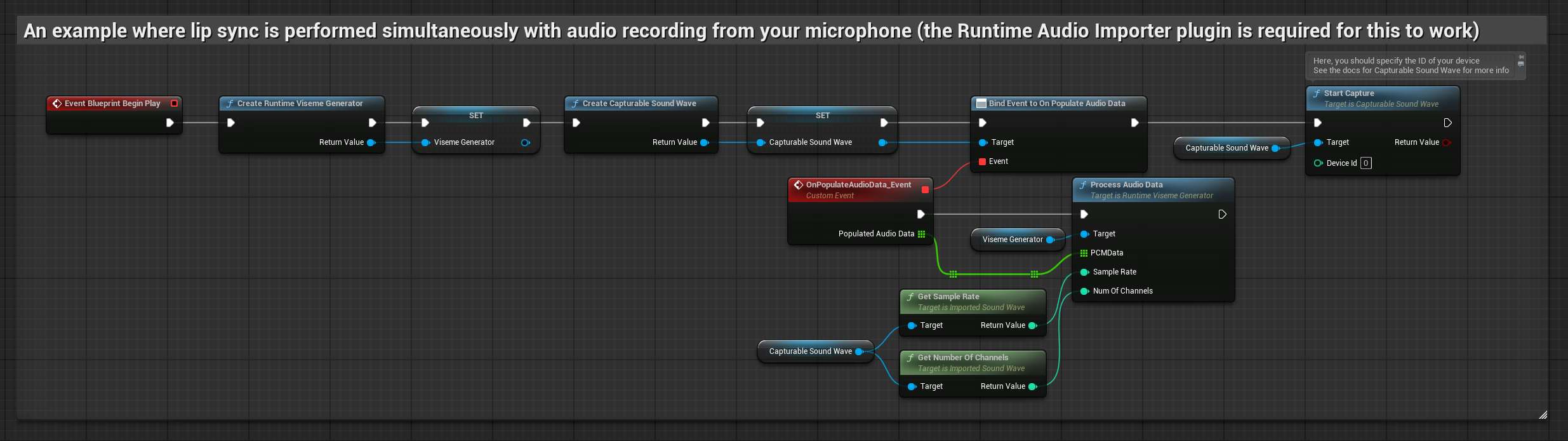
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
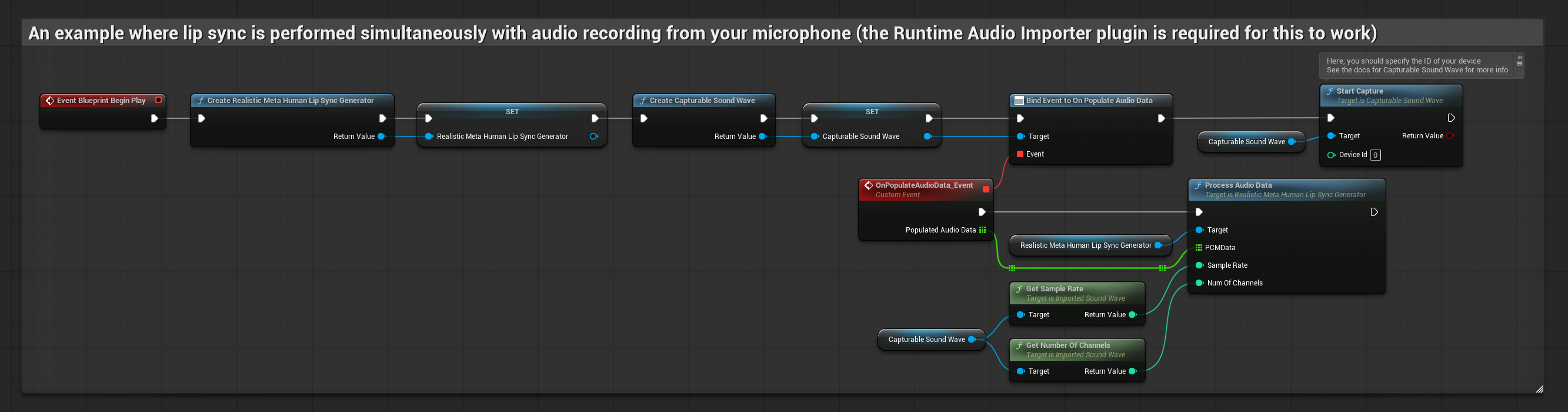
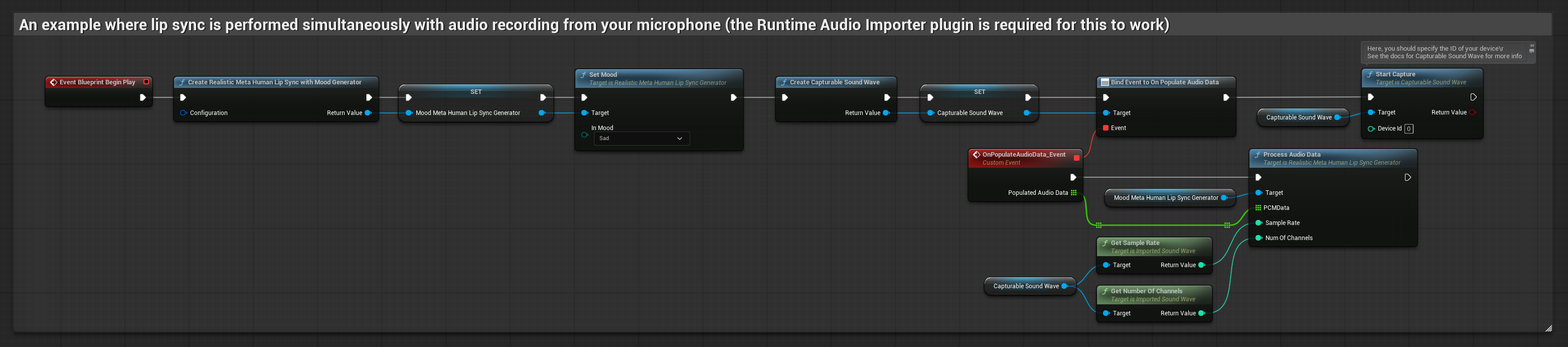
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
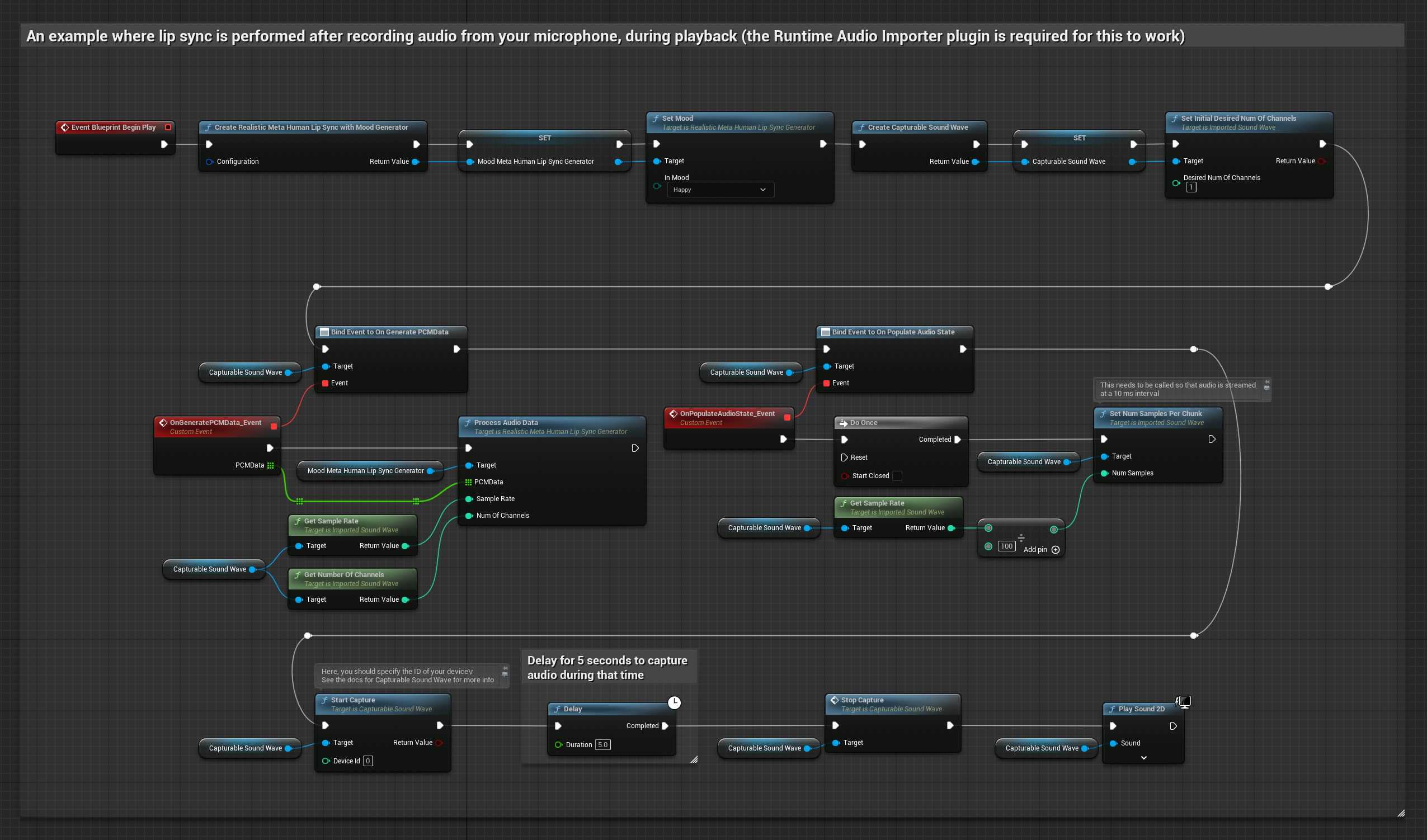
Esta abordagem captura o áudio de um microfone e o reproduz com sincronização labial:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Crie uma Onda Sonora Capturável usando o Runtime Audio Importer
- Para Linux com Pixel Streaming, use Pixel Streaming Capturable Sound Wave
- Iniciar captura de áudio do microfone
- Antes de reproduzir a onda sonora capturável, vincule-se ao seu delegado
OnGeneratePCMData - Na função vinculada, chame
ProcessAudioDatado seu Gerador de Visemas em Tempo de Execução
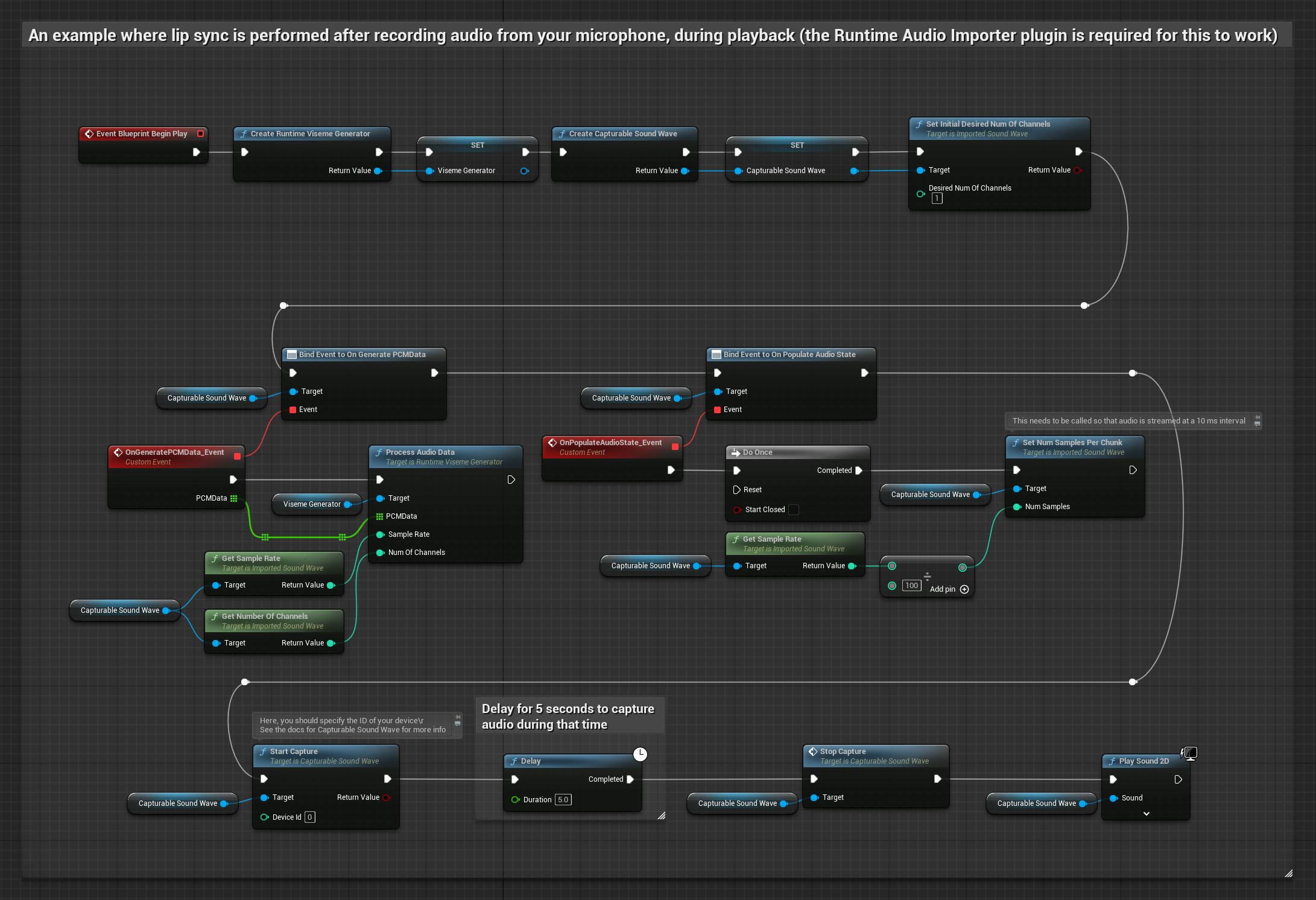
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
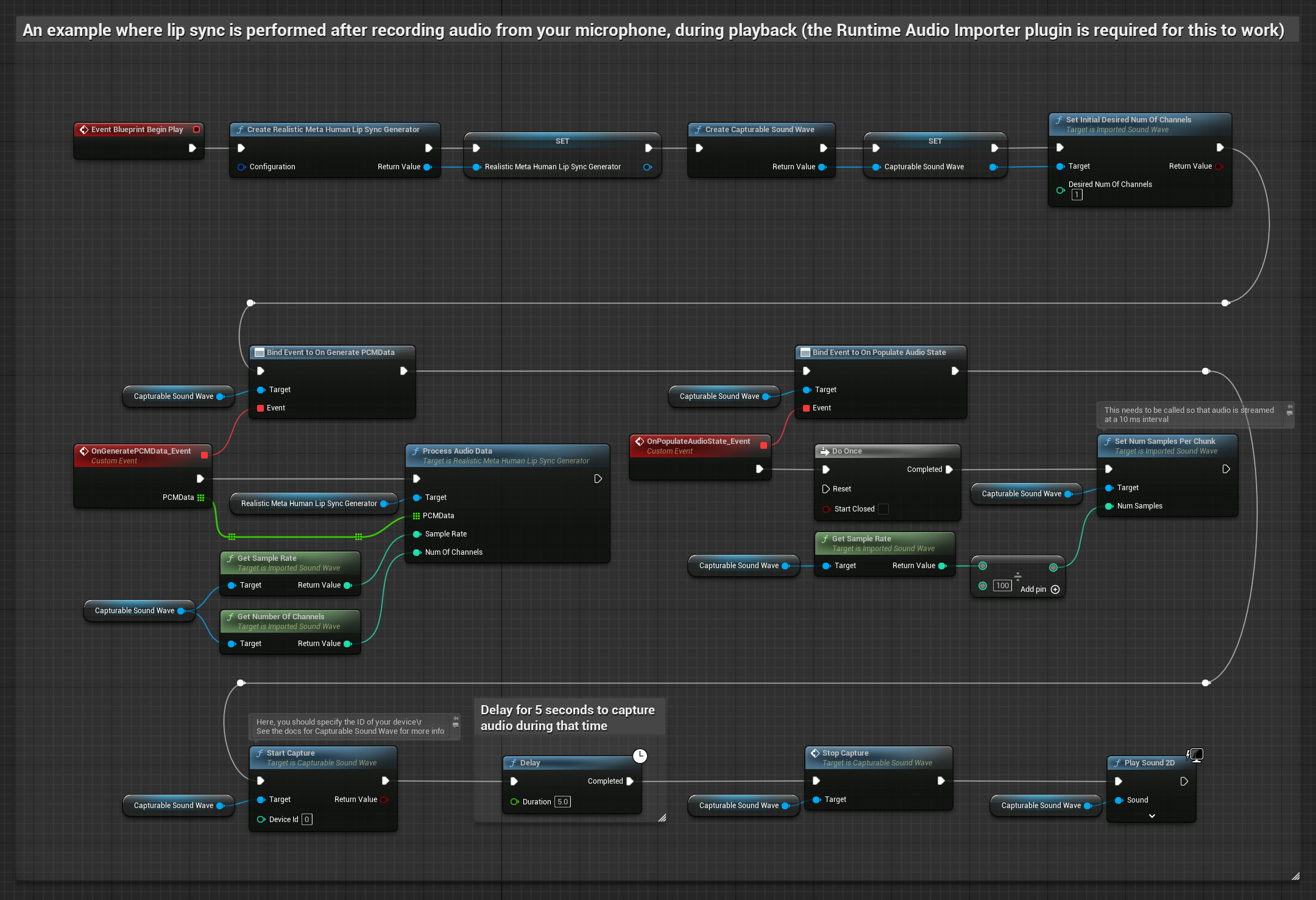
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
- Regular
- Streaming
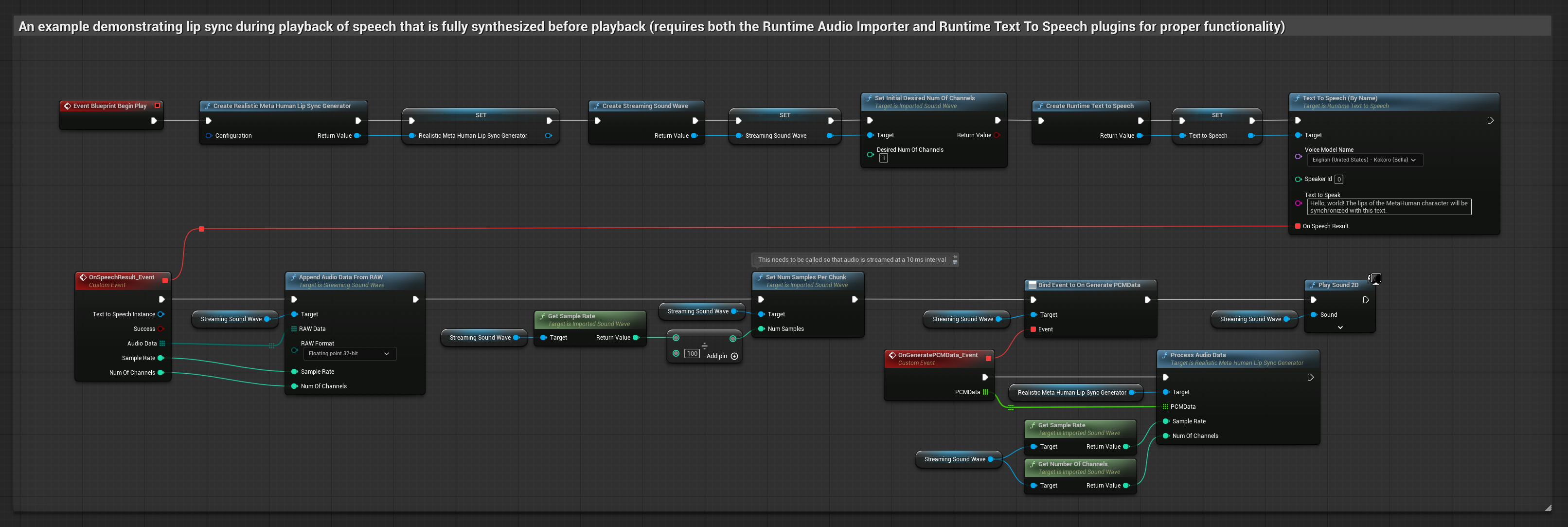
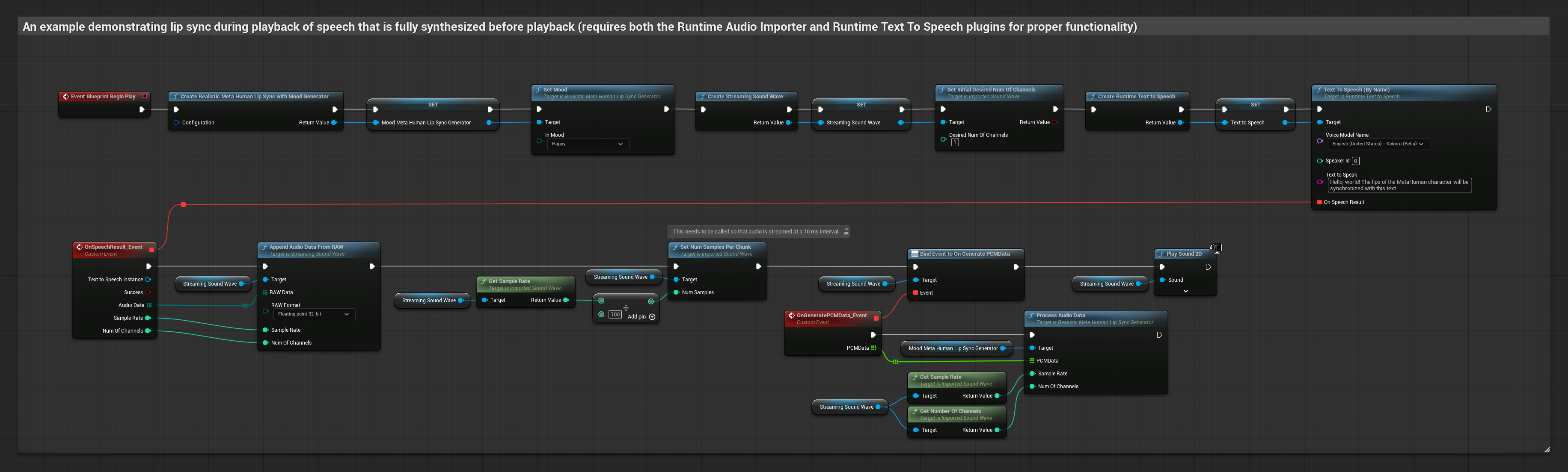
Esta abordagem sintetiza fala a partir de texto usando TTS local e realiza sincronização labial:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Use Runtime Text To Speech para gerar fala a partir de texto
- Use Runtime Audio Importer para importar o áudio sintetizado
- Antes de reproduzir a onda sonora importada, vincule-se ao seu delegado
OnGeneratePCMData - Na função vinculada, chame
ProcessAudioDatado seu Gerador de Visemas Runtime
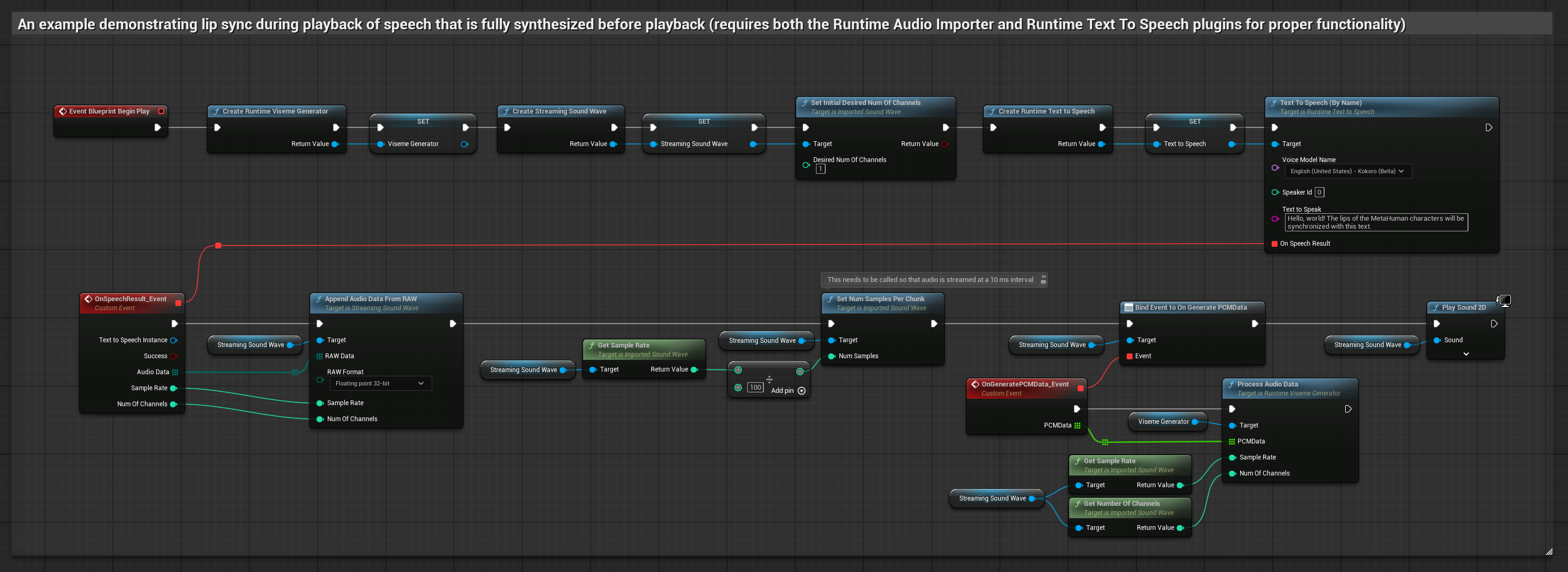
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
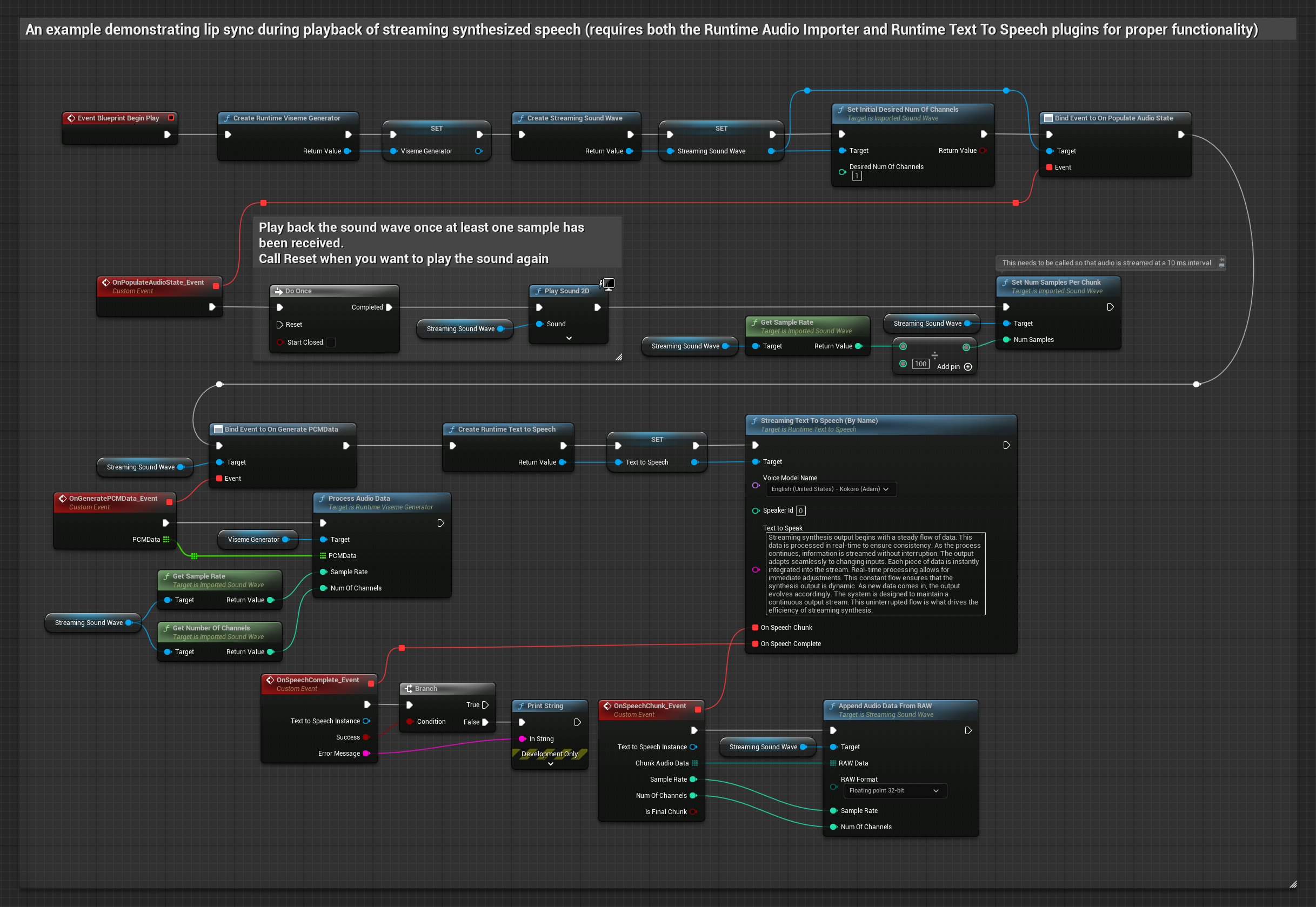
Esta abordagem utiliza síntese de fala por streaming com sincronização labial em tempo real.
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Use Runtime Text To Speech para gerar fala em streaming a partir de texto
- Use Runtime Audio Importer para importar o áudio sintetizado
- Antes de reproduzir a onda sonora em streaming, vincule-se ao seu delegado
OnGeneratePCMData - Na função vinculada, chame
ProcessAudioDatado seu Runtime Viseme Generator
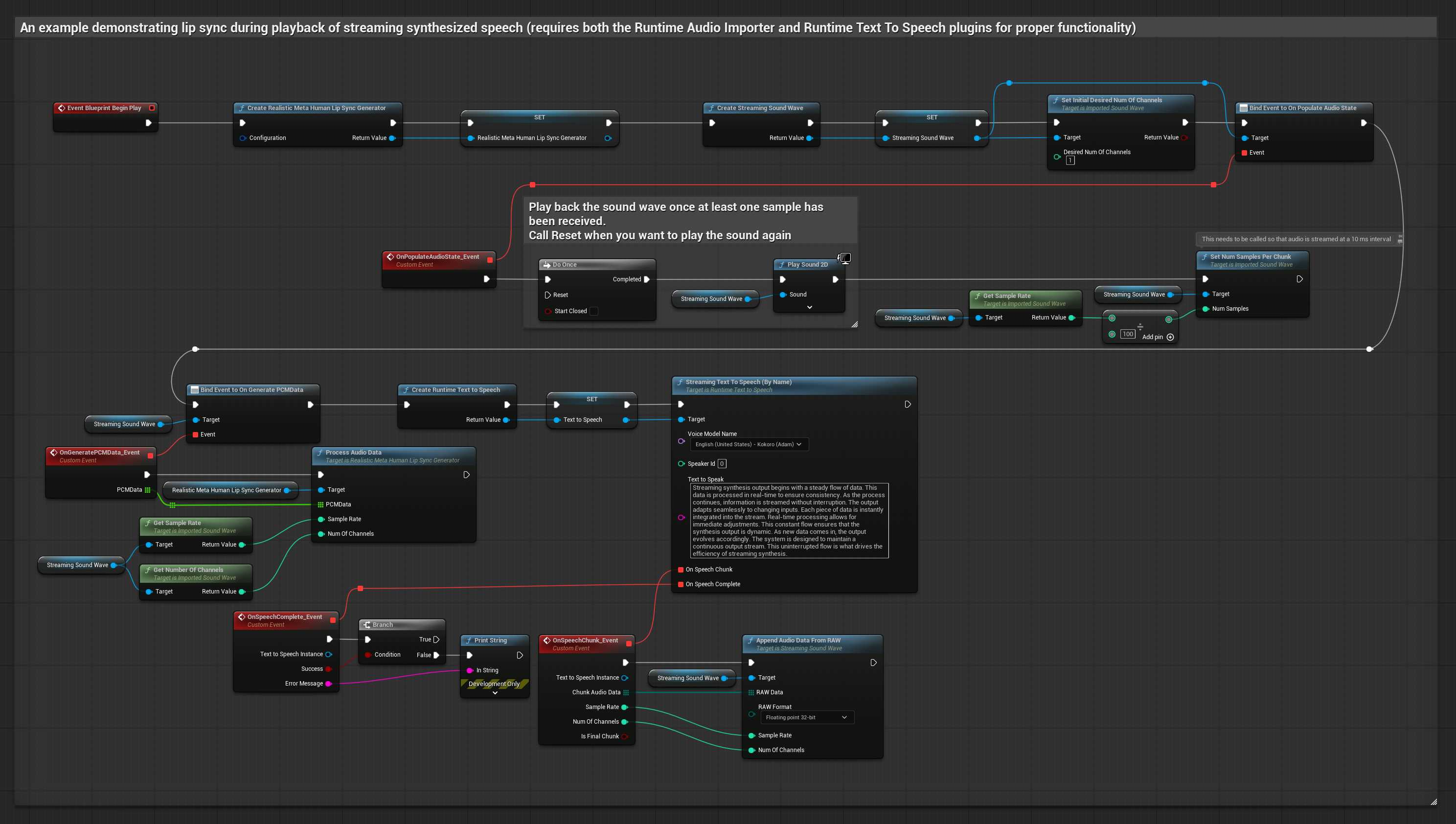
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
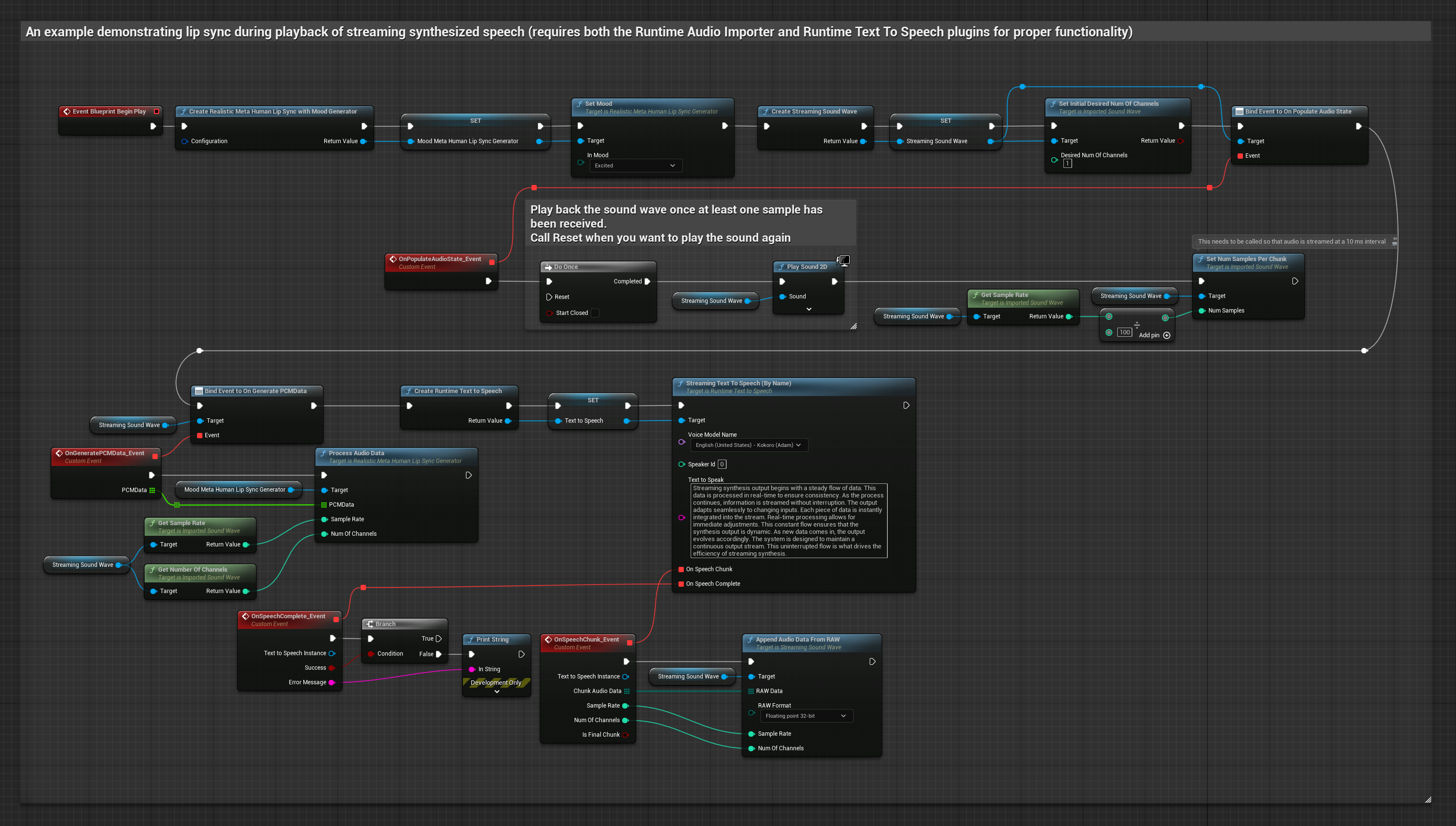
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
- Regular
- Streaming
Esta abordagem utiliza o plugin Runtime AI Chatbot Integrator para gerar fala sintetizada a partir de serviços de IA (OpenAI ou ElevenLabs) e realizar a sincronização labial:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Use o Runtime AI Chatbot Integrator para gerar fala a partir de texto usando APIs externas (OpenAI, ElevenLabs, etc.)
- Use o Runtime Audio Importer para importar os dados de áudio sintetizados
- Antes de reproduzir a onda sonora importada, vincule-se ao seu delegado
OnGeneratePCMData - Na função vinculada, chame
ProcessAudioDatado seu Runtime Viseme Generator
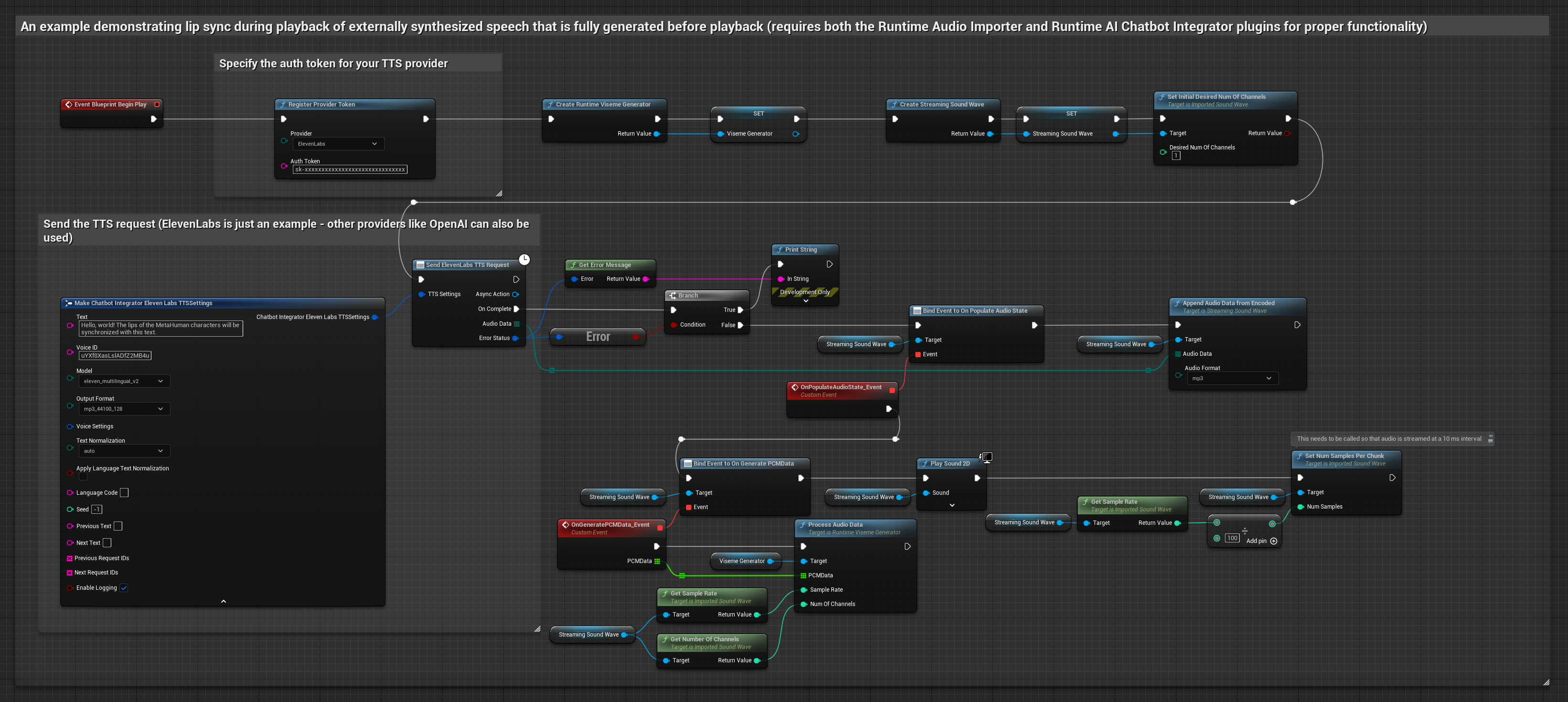
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
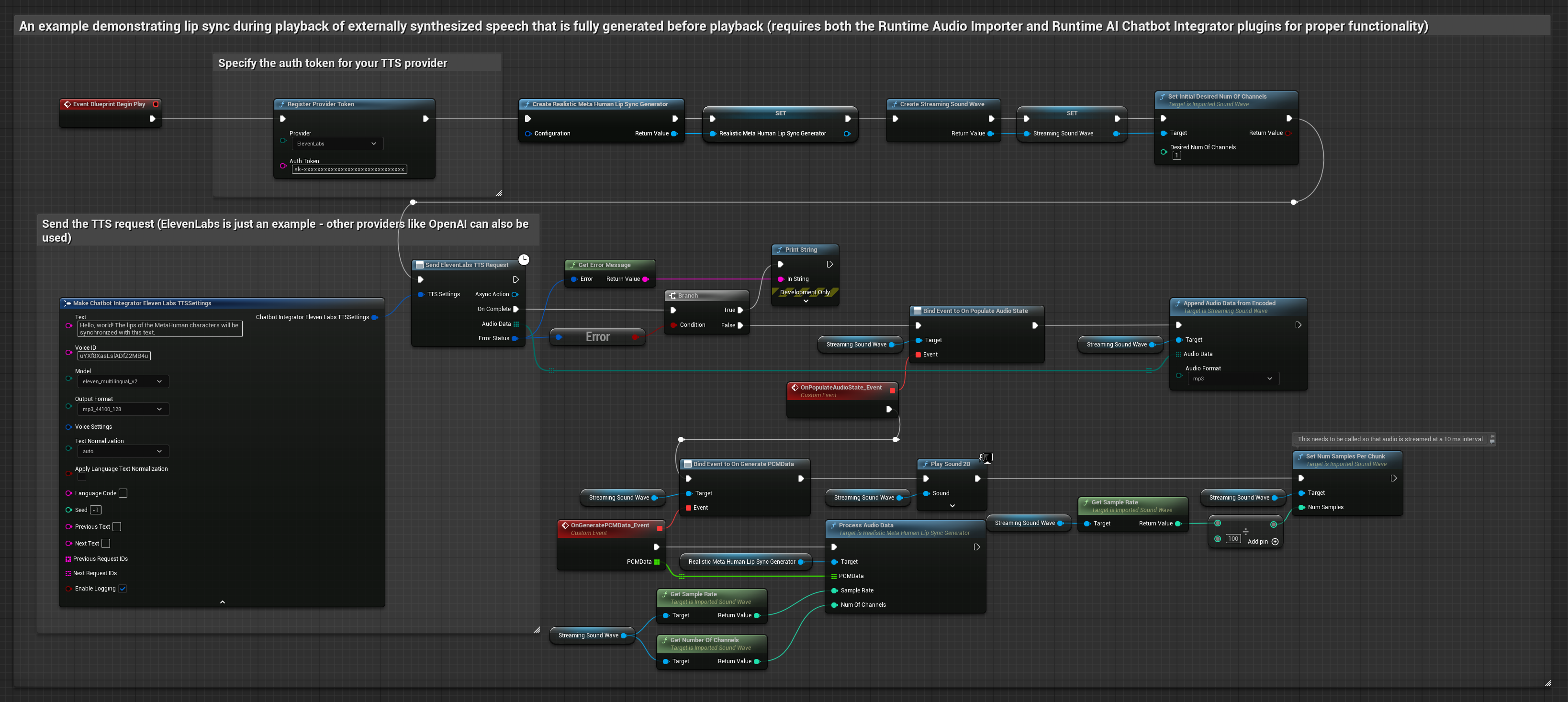
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
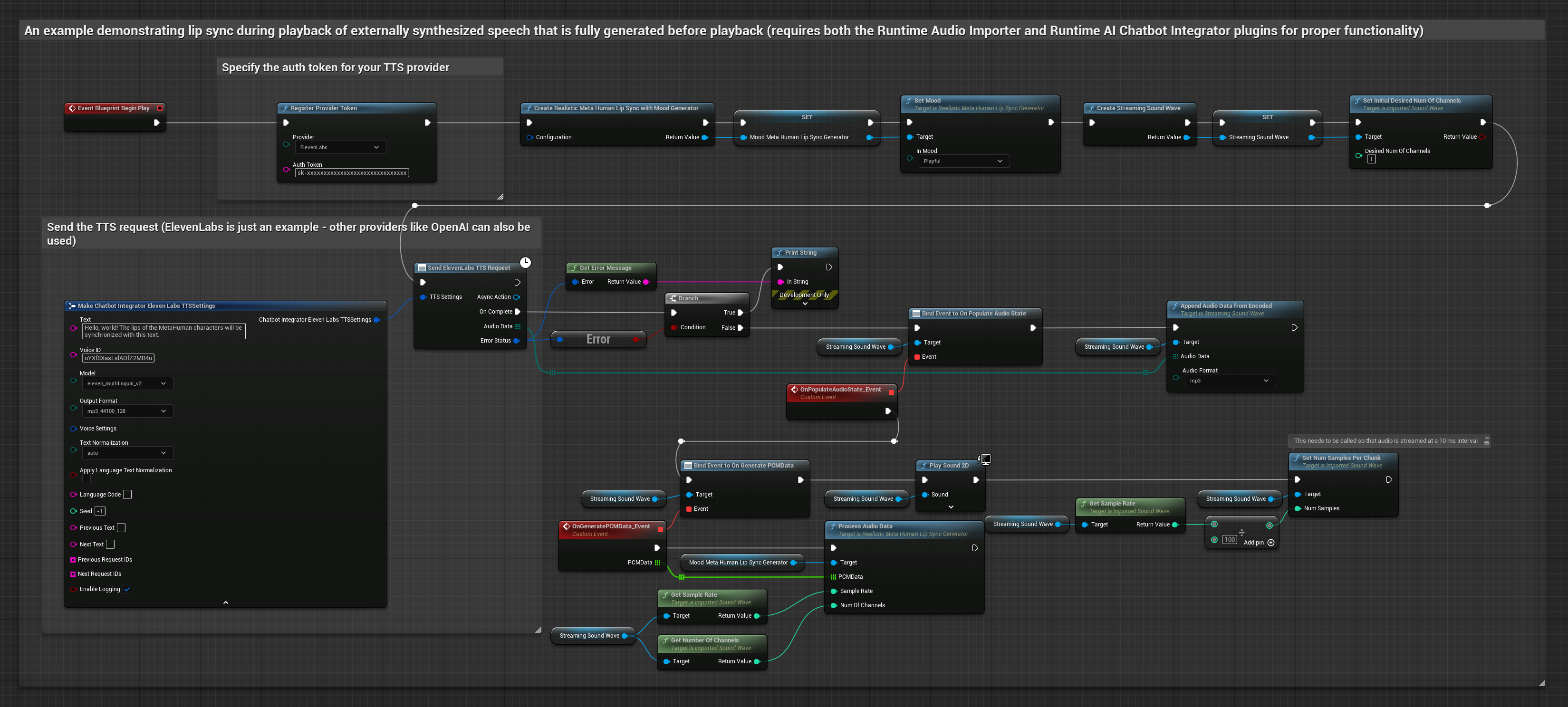
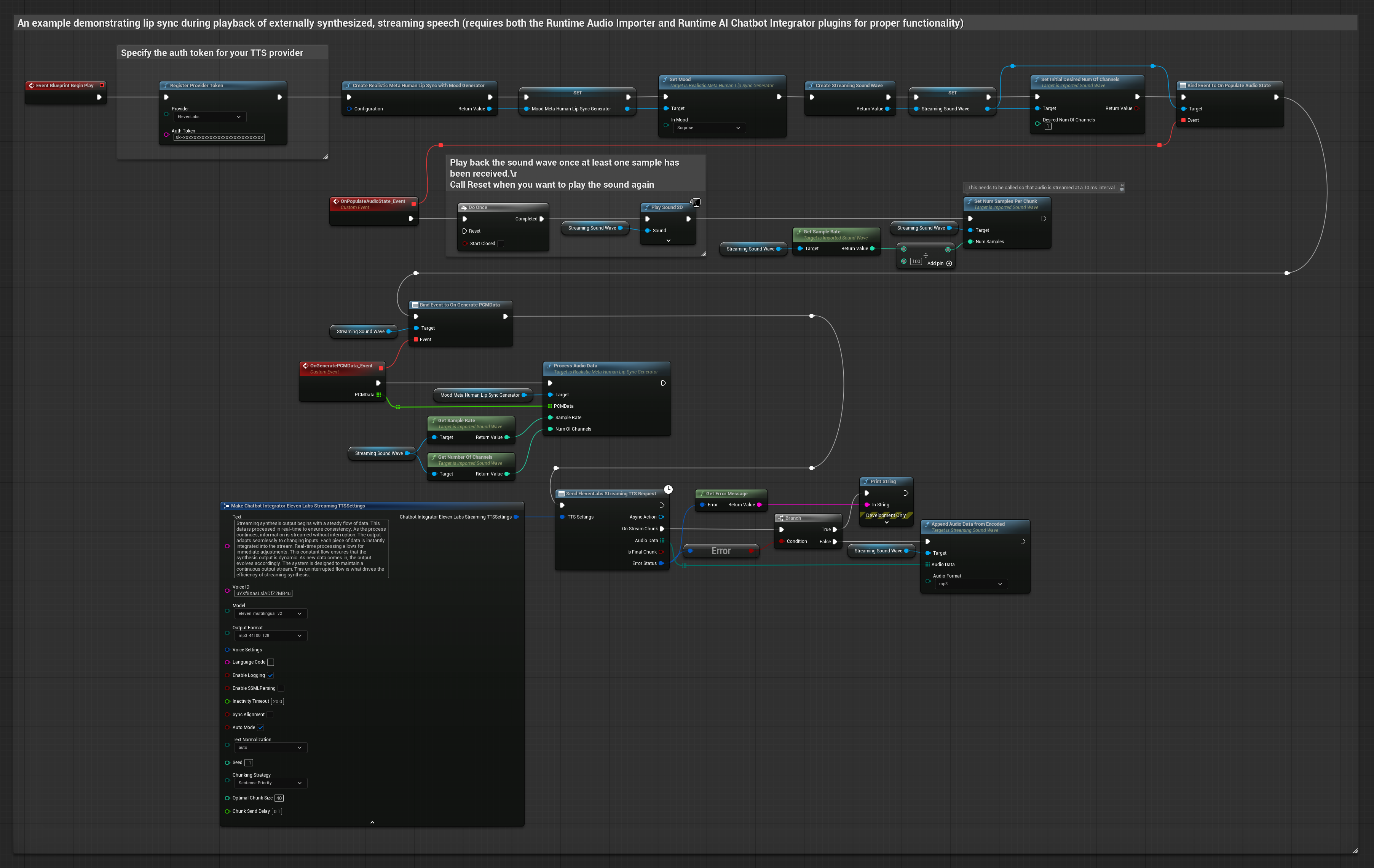
Esta abordagem utiliza o plugin Runtime AI Chatbot Integrator para gerar fala sintetizada em streaming a partir de serviços de IA (OpenAI ou ElevenLabs) e realizar lip sync:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Use o Runtime AI Chatbot Integrator para conectar-se a APIs de TTS em streaming (como a ElevenLabs Streaming API)
- Use o Runtime Audio Importer para importar os dados de áudio sintetizados
- Antes de reproduzir a onda sonora em streaming, vincule-se ao seu delegate
OnGeneratePCMData - Na função vinculada, chame
ProcessAudioDatado seu Runtime Viseme Generator
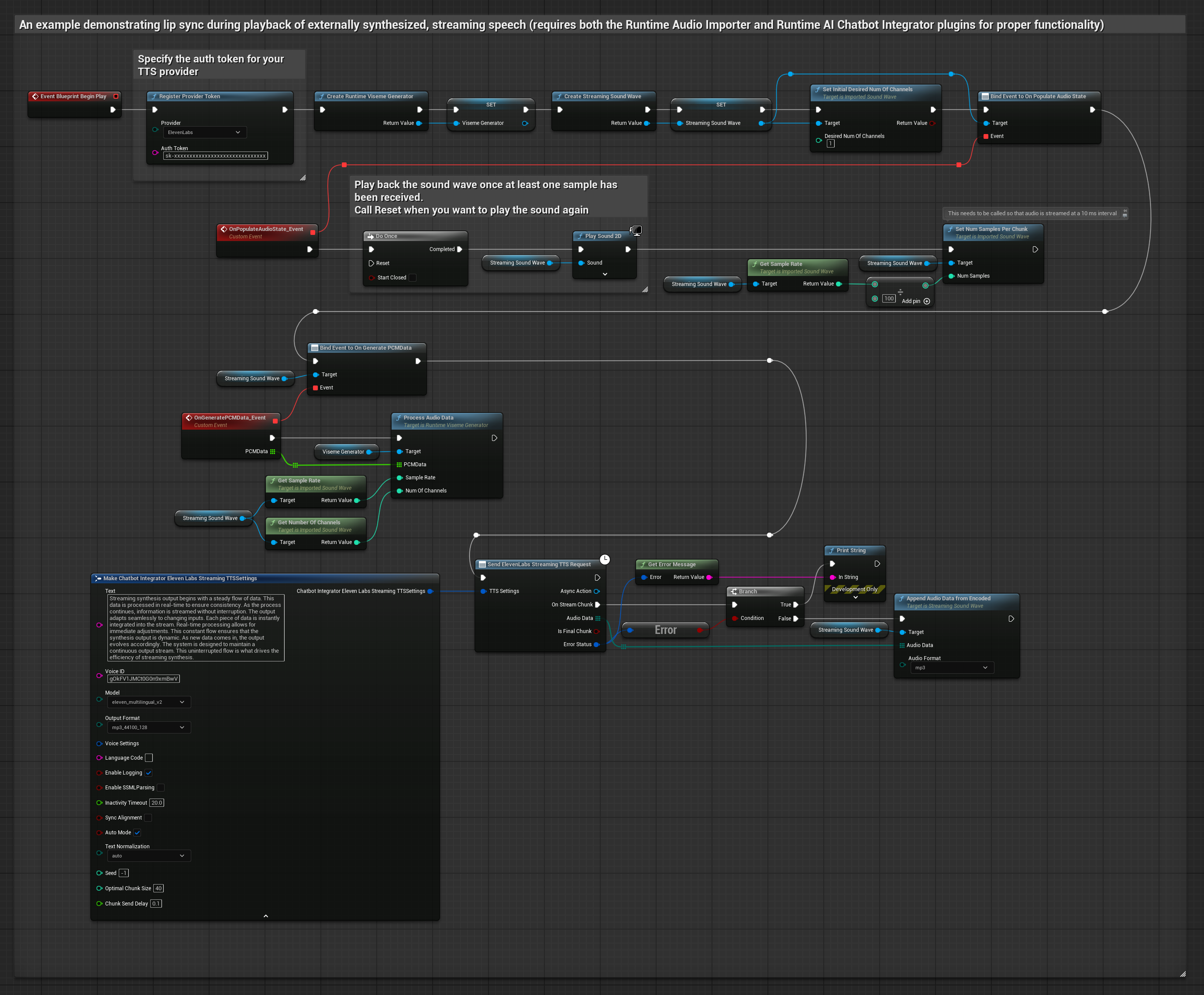
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
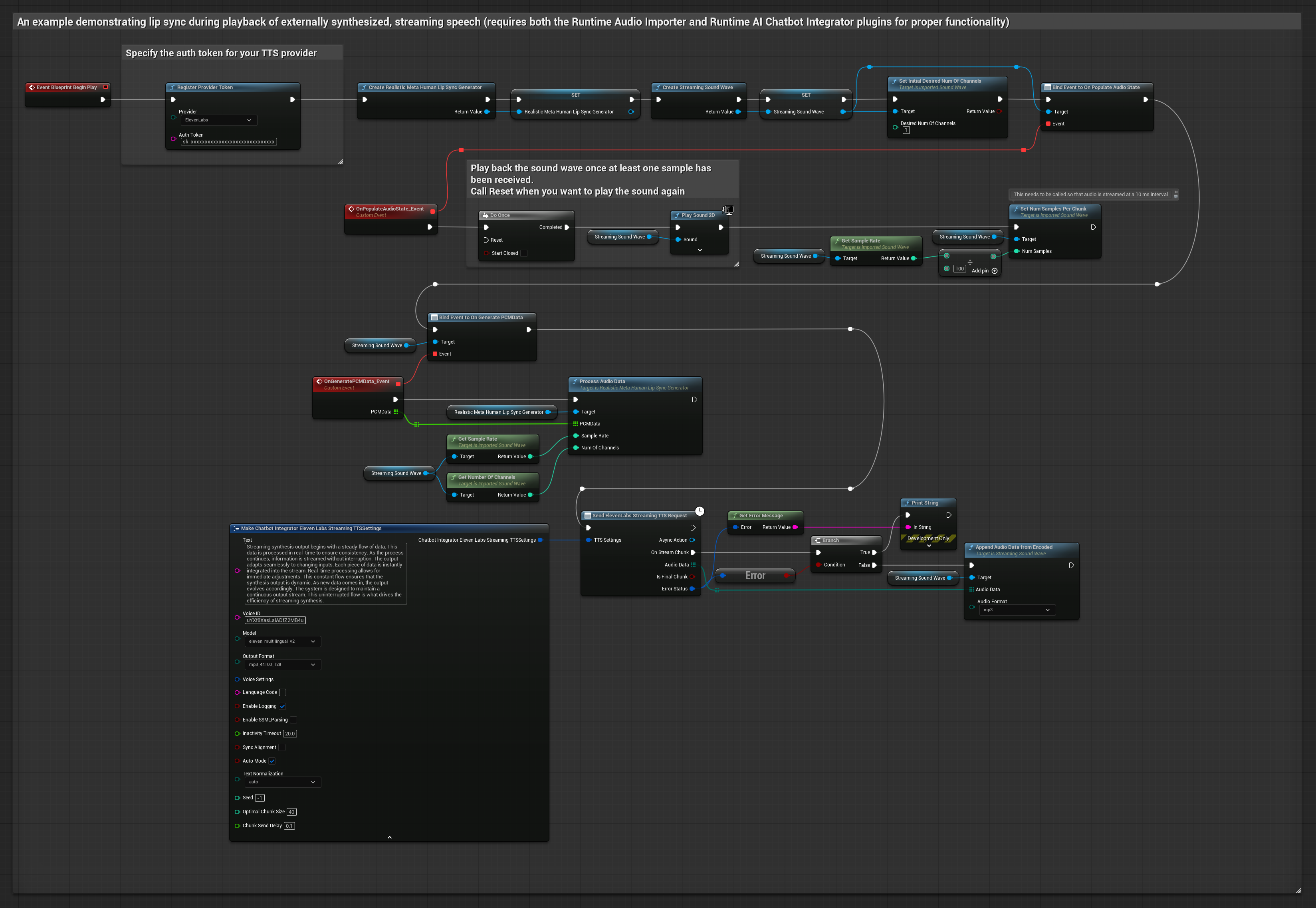
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
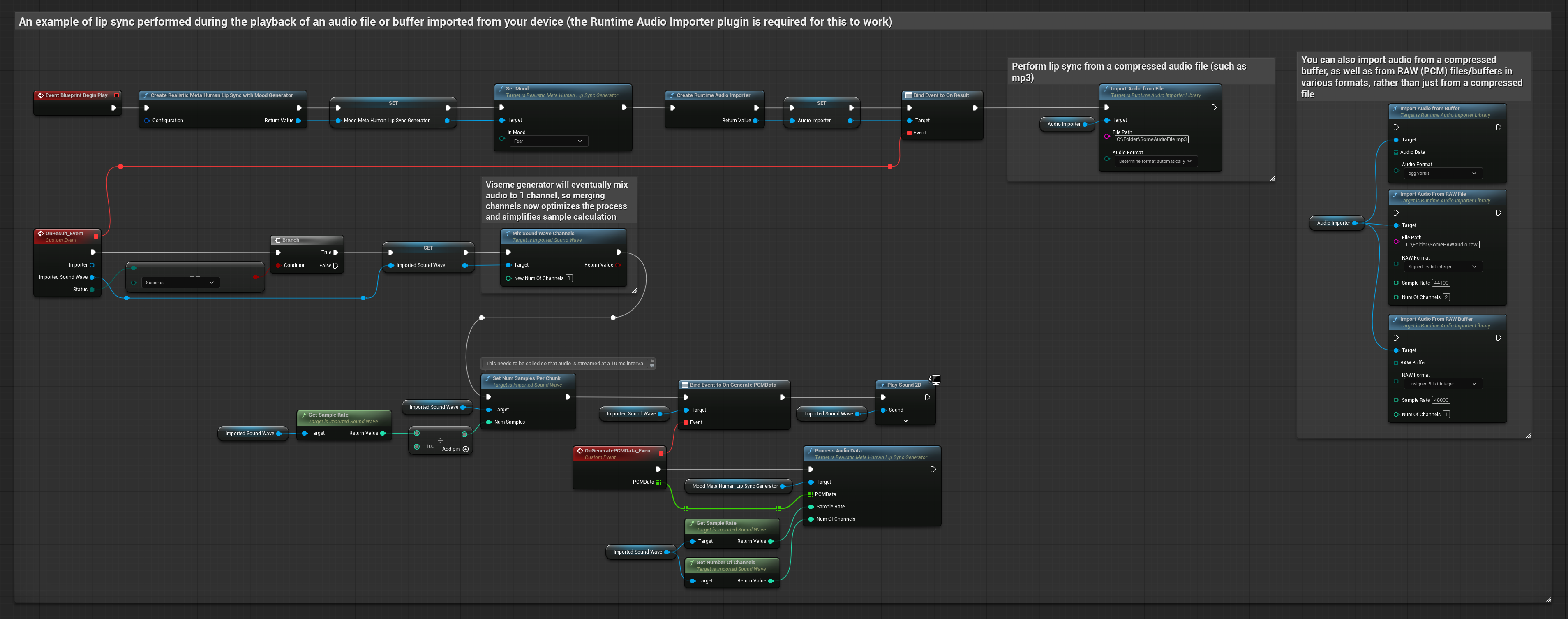
Esta abordagem utiliza arquivos de áudio pré-gravados ou buffers de áudio para sincronização labial:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Controle de Humor
- Use o Runtime Audio Importer para importar um arquivo de áudio do disco ou da memória
- Antes de reproduzir a onda sonora importada, vincule-se ao seu delegado
OnGeneratePCMData - Na função vinculada, chame
ProcessAudioDatado seu Runtime Viseme Generator - Reproduza a onda sonora importada e observe a animação de sincronização labial
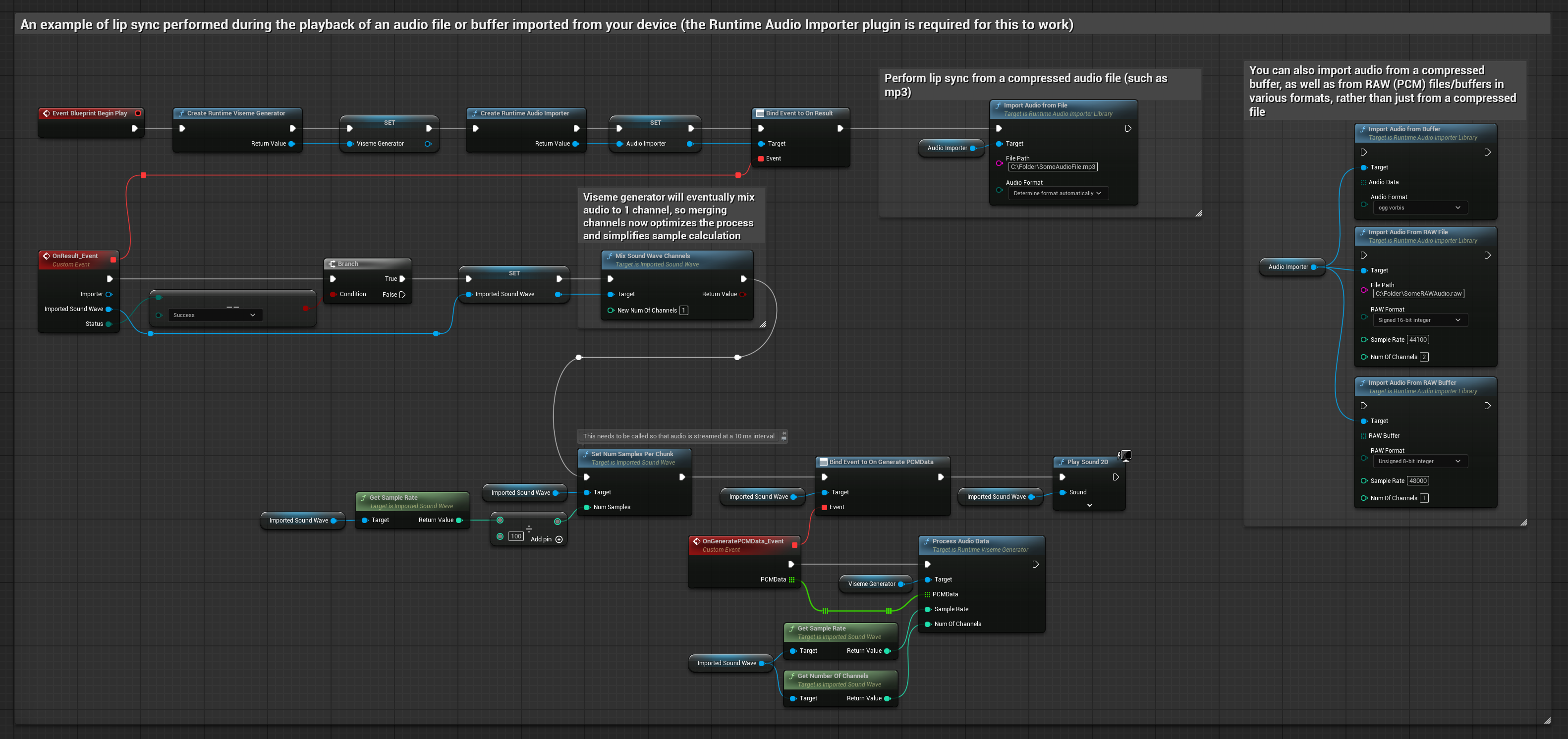
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
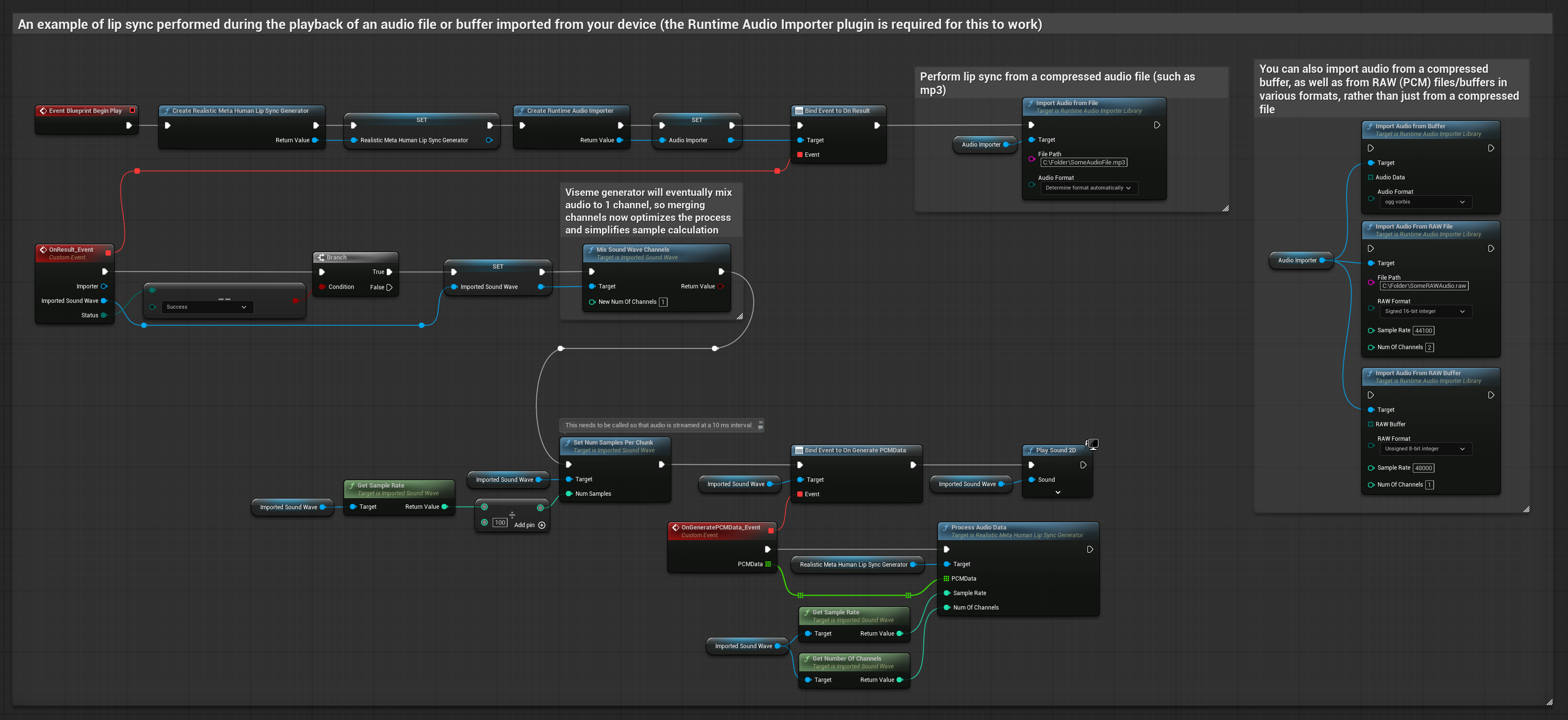
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.
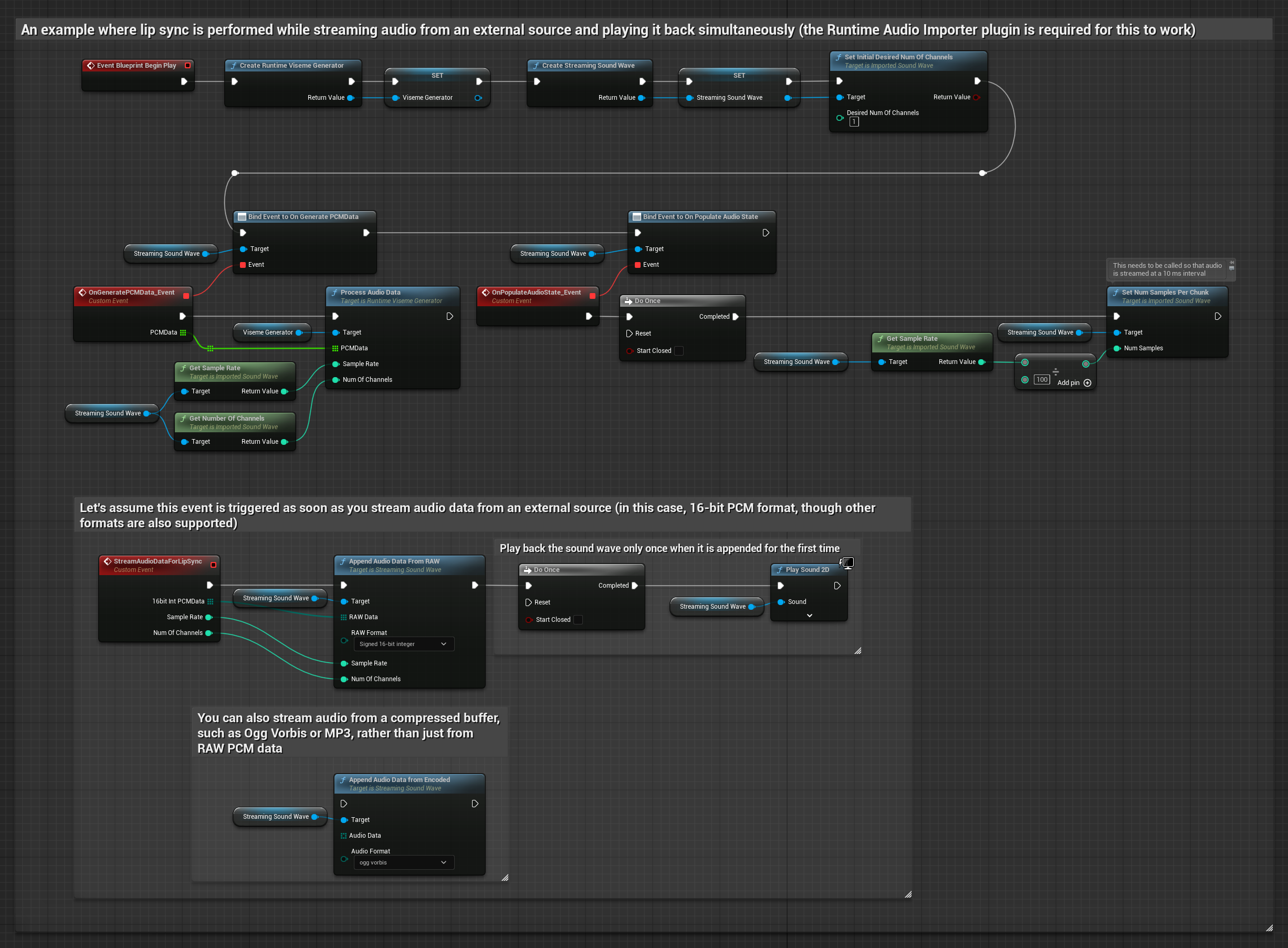
Para transmitir dados de áudio de um buffer, você precisa:
- Modelo Padrão
- Modelo Realista
- Modelo Realista com Suporte a Humor
- Dados de áudio no formato PCM float (um array de amostras de ponto flutuante) disponíveis em sua fonte de streaming (ou use Runtime Audio Importer para suportar mais formatos)
- A taxa de amostragem e o número de canais
- Chame
ProcessAudioDatado seu Runtime Viseme Generator com esses parâmetros conforme os chunks de áudio ficam disponíveis
O Modelo Realista utiliza o mesmo fluxo de trabalho de processamento de áudio que o Modelo Padrão, mas com a variável RealisticLipSyncGenerator em vez de VisemeGenerator.
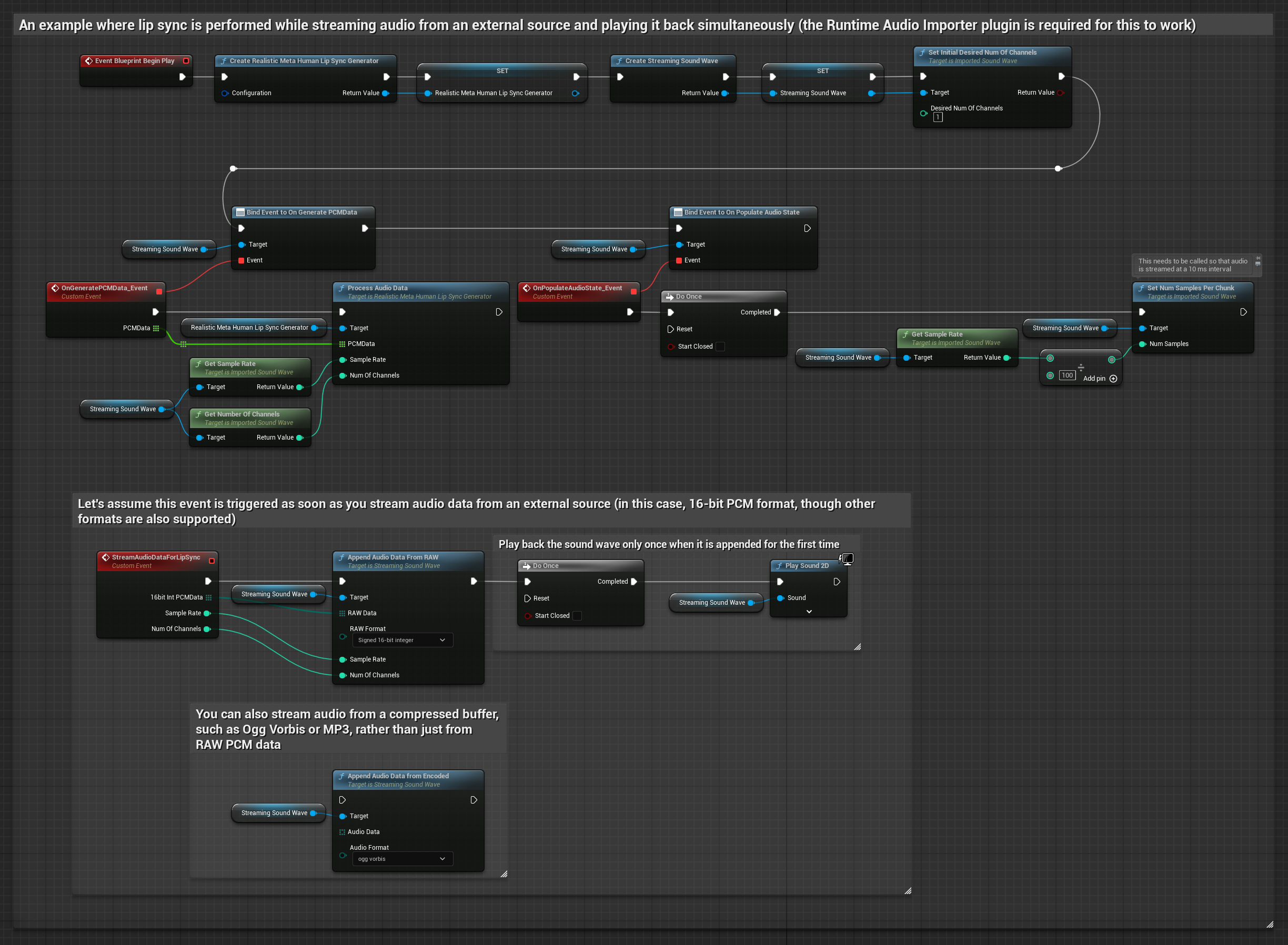
O modelo habilitado para humor utiliza o mesmo fluxo de trabalho de processamento de áudio, mas com a variável MoodMetaHumanLipSyncGenerator e capacidades adicionais de configuração de humor.

Nota: Ao usar fontes de áudio em streaming, certifique-se de gerenciar o tempo de reprodução de áudio adequadamente para evitar reprodução distorcida. Consulte a documentação do Streaming Sound Wave para mais informações.
Dicas de Desempenho de Processamento
-
Tamanho do Chunk: Aumentar a opção de configuração
ProcessingChunkSize(por exemplo, para 320, 480 ou 640 amostras) pode melhorar visivelmente a latência com impacto mínimo na qualidade ou na capacidade de resposta. -
Tipo de Modelo: Ao usar modelos realistas, mudar para o tipo de modelo Altamente Otimizado (selecionado por padrão) pode melhorar o desempenho. Observe que o modelo original pode produzir uma qualidade ligeiramente melhor, especialmente com áudio ruidoso.
-
Gerenciamento de Buffer: O modelo habilitado para emoção processa áudio em quadros de 320 amostras (20ms a 16kHz). Certifique-se de que o tempo da sua entrada de áudio esteja alinhado com isso para obter desempenho ideal.
-
Recriação do Gerador: Para uma operação confiável com modelos Realistas, recrie o gerador sempre que desejar fornecer novos dados de áudio após um período de inatividade. Consulte Recriação do Gerador na seção de Solução de Problemas para obter a explicação.
Próximos Passos
Depois de configurar o processamento de áudio, você pode querer:
- Saiba mais sobre Opções de configuração para ajustar o comportamento da sincronização labial
- Adicione animação de risada para maior expressividade
- Combine a sincronização labial com animações faciais existentes usando as técnicas de camadas descritas no guia de Configuração