Projetos de Demonstração
Para ajudar você a começar rapidamente com o Runtime MetaHuman Lip Sync, dois projetos de demonstração prontos para uso estão disponíveis. Ambos são construídos com Unreal Engine 5.6+, são apenas Blueprint e funcionam em várias plataformas, incluindo Windows, Mac, Linux, iOS, Android e plataformas baseadas em Android (incluindo Meta Quest).
Projetos de Demonstração Disponíveis
- NPC Conversacional com IA / Avatar Interativo
- Demonstração Básica de Sincronização Labial
Um fluxo de trabalho completo de avatar conversacional com IA combinando reconhecimento de fala, um chatbot de IA (LLM), conversão de texto em fala e reprodução de áudio com sincronização labial em tempo real – tudo rodando junto em um único projeto. Adequado para uma ampla gama de casos de uso – incluindo jogos, quiosques interativos, produção virtual, instalações em museus, assistentes digitais e simulações de treinamento.
Visão Geral do Pipeline
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Quando o LLM está configurado para o modo Streaming, sua saída é dividida frase por frase e enviada ao TTS à medida que cada frase é concluída, em vez de aguardar a resposta completa, para minimizar a latência.
Vídeos
Prévia Rápida (~30 segundos)
Uma breve demonstração do demo em ação.
Passo a Passo Completo
Um passo a passo detalhado cobrindo a configuração, a parametrização e o pipeline completo de conversação.
Downloads
Plugins Obrigatórios e Opcionais
O projeto de demonstração é modular — você só precisa dos plugins dos provedores que deseja utilizar.
| Plugin | Propósito | Obrigatório? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animação de sincronização labial | ✅ Sempre |
| Runtime Audio Importer | Captura e processamento de áudio | ✅ Sempre |
| Runtime Speech Recognizer | Reconhecimento de fala offline (whisper.cpp) | ✅ Sempre |
| Runtime AI Chatbot Integrator | LLMs externos (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) e/ou TTS externo (OpenAI, ElevenLabs) | 🔶 Opcional |
| Runtime Local LLM | Inferência de LLM local via llama.cpp (modelos GGUF como Llama, Mistral, Gemma, etc.) | 🔶 Opcional |
| Runtime Text To Speech | TTS local via Piper e Kokoro | 🔶 Opcional |
Embora cada plugin acima seja opcional individualmente, você precisa de pelo menos um provedor de LLM e pelo menos um provedor de TTS para que a demonstração funcione. Misture e combine livremente (ex.: LLM local + TTS ElevenLabs, ou LLM OpenAI + TTS local).
Arquitetura Modular
Na pasta Content você encontrará uma pasta Modules que contém três subpastas:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Se você não adquiriu um (ou mais) dos plugins opcionais, basta excluir a(s) pasta(s) correspondente(s). Os assets base do projeto de demonstração (instância do jogo, widgets, etc.) não fazem referência direta a esses módulos, portanto, excluí-los não causará erros de referência de assets. A interface de configuração ocultará automaticamente qualquer provedor cuja pasta esteja ausente.
Essa modularidade se aplica apenas aos provedores de LLM e TTS. O Reconhecimento de Fala (Runtime Speech Recognizer) e a Sincronização Labial (Runtime MetaHuman Lip Sync) fazem parte do projeto de demonstração base e são sempre necessários.
Na primeira inicialização, o Unreal pode perguntar se deseja desabilitar plugins opcionais ausentes — clique em Sim. Certifique-se de também ter excluído a pasta Content/Modules/ correspondente (veja acima).
Layout do Projeto de Demonstração
A interface do usuário mostrada abaixo é construída inteiramente com UMG (Unreal Motion Graphics) e tem o objetivo puramente de demonstrar o pipeline - reconhecimento de fala → LLM → TTS → sincronização labial. Você pode remodelá-la ou substituí-la livremente para se adequar ao design visual, esquema de controle ou plataforma do seu projeto (VR/AR, mobile, console, quiosque, etc.). Se alguns widgets não forem necessários no seu caso de uso, você também pode simplesmente ocultá-los (por exemplo, definir a visibilidade deles como Collapsed ou Hidden).

| Area | O que há |
|---|---|
| Centralizar | O personagem MetaHuman. |
| Lado esquerdo | Quatro botões de configuração (Reconhecimento de Fala, Chatbot de IA, Conversão de Texto em Fala, Animações), descritos em detalhes abaixo. |
| Centro inferior | Um botão Iniciar Gravação. Clique nele para começar uma conversa por voz: seu microfone é capturado, transcrito, enviado ao LLM, a resposta é sintetizada via TTS e reproduzida com sincronia labial, totalmente sem usar as mãos. |
| Centro direito | Um widget de histórico de conversa exibindo toda a troca de mensagens entre você e a IA (mensagens do usuário e do assistente). Ele também inclui um campo de entrada de texto, para que você possa digitar mensagens diretamente sem usar reconhecimento de fala, útil para testes, acessibilidade ou quando um microfone não estiver disponível. |
Você pode misturar livremente ambos os modos de entrada na mesma sessão — falar algumas mensagens, digitar outras.
Se o sync labial continuar ficando cada vez mais atrás do áudio quanto mais você testar (não apenas um atraso fixo), veja Tamanho do Chunk de Processamento em Configurar Animações abaixo.
Botões de Configuração
Os quatro botões de configuração à esquerda abrem painéis dedicados para cada parte do pipeline:
1. Configure o Reconhecimento de Fala
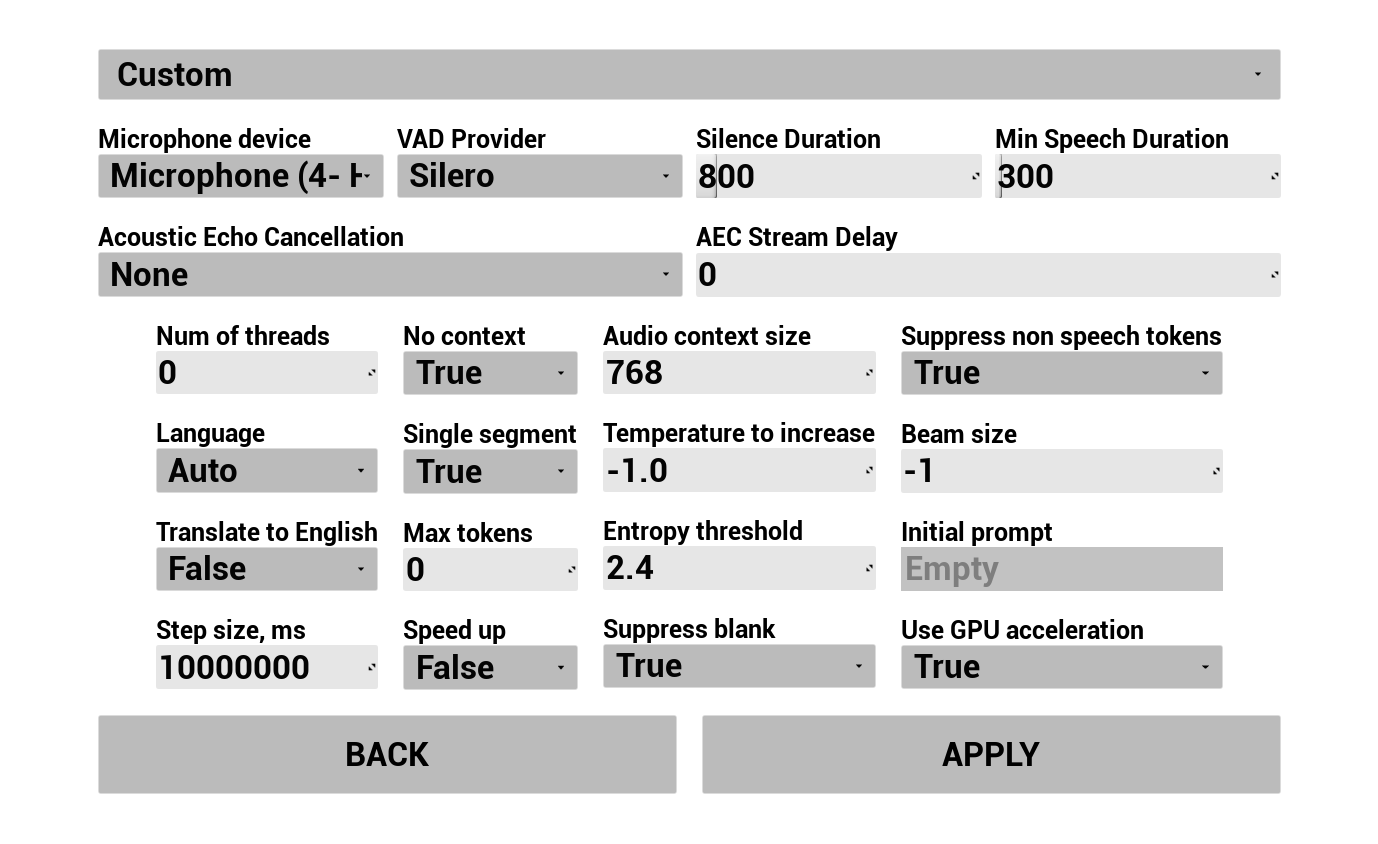
Configure como a voz do usuário é capturada e transcrita:
- Selecione idioma
- Ajuste os parâmetros de reconhecimento de fala (configurações do modelo Whisper)
- Configure o AEC (Cancelamento de Eco Acústico)
- Configure o VAD (Detecção de Atividade de Voz)
2. Configure o Chatbot de IA
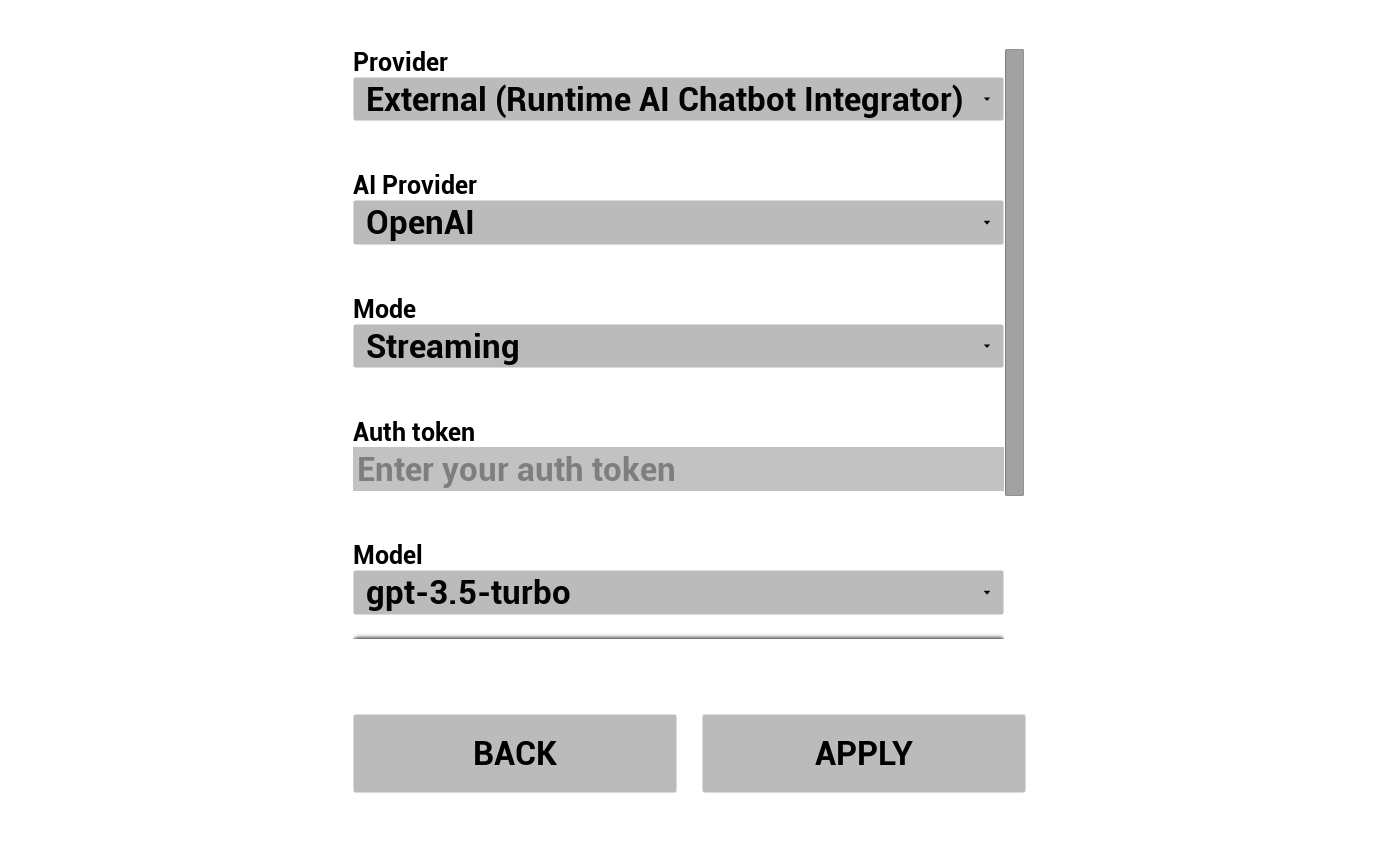
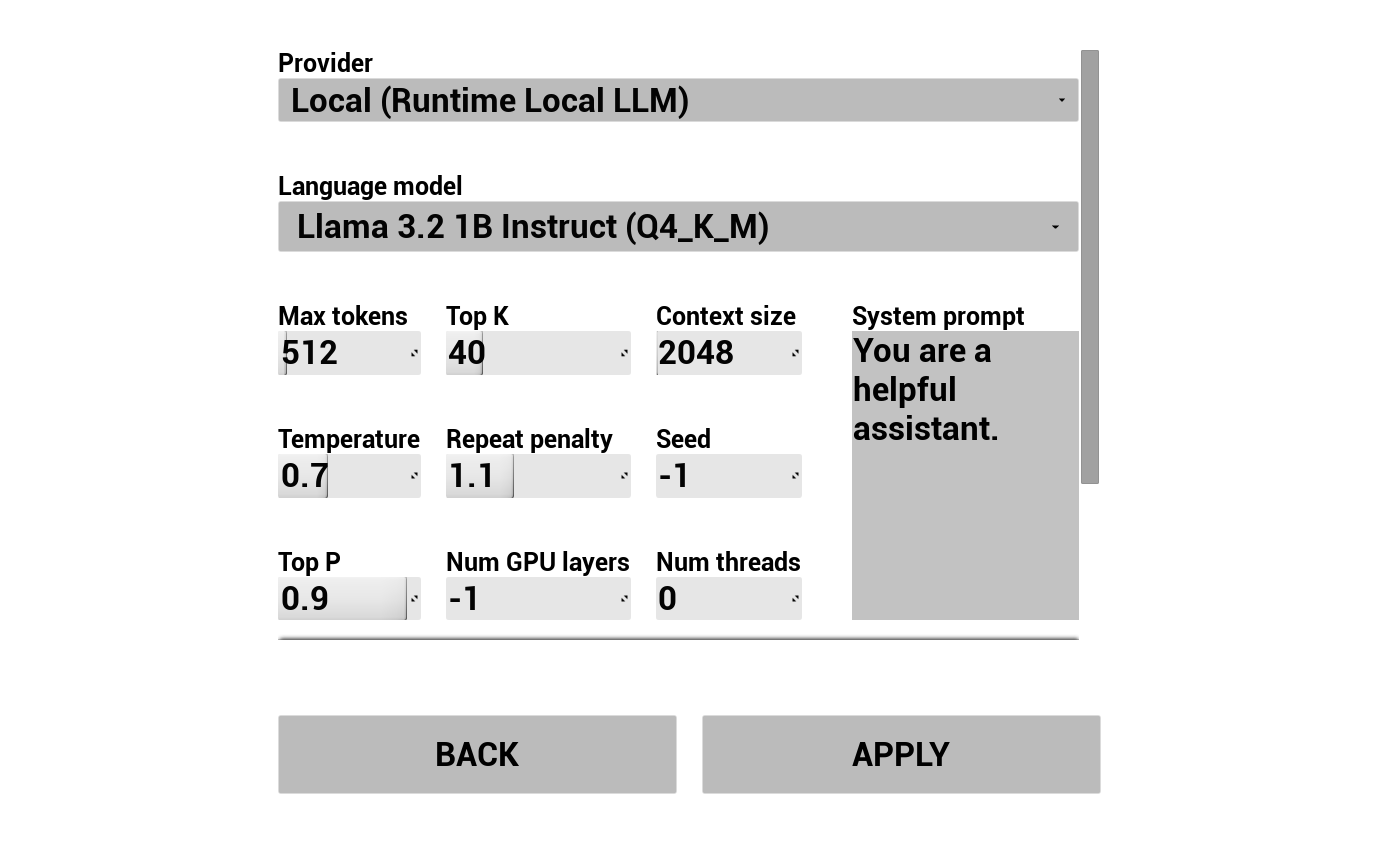
Escolha seu provedor de LLM e configure-o:
- Selecione o provedor (Runtime AI Chatbot Integrator ou Runtime Local LLM)
- Selecione o modo: Regular ou Streaming (depende do provedor; Streaming permite a transferência de TTS frase por frase, consulte Visão Geral do Pipeline)
- Para provedores externos: token de autenticação, nome do modelo, etc.
- Para LLM local: selecione um modelo GGUF, defina o tamanho do contexto e outros parâmetros de inferência. Você também pode baixar seu próprio modelo GGUF em tempo de execução diretamente da demonstração (por exemplo, por URL) e usá-lo imediatamente sem precisar reconstruir o projeto.
O combobox de provedores exibe apenas provedores cuja pasta de módulo do plugin está presente em Content/Modules/.
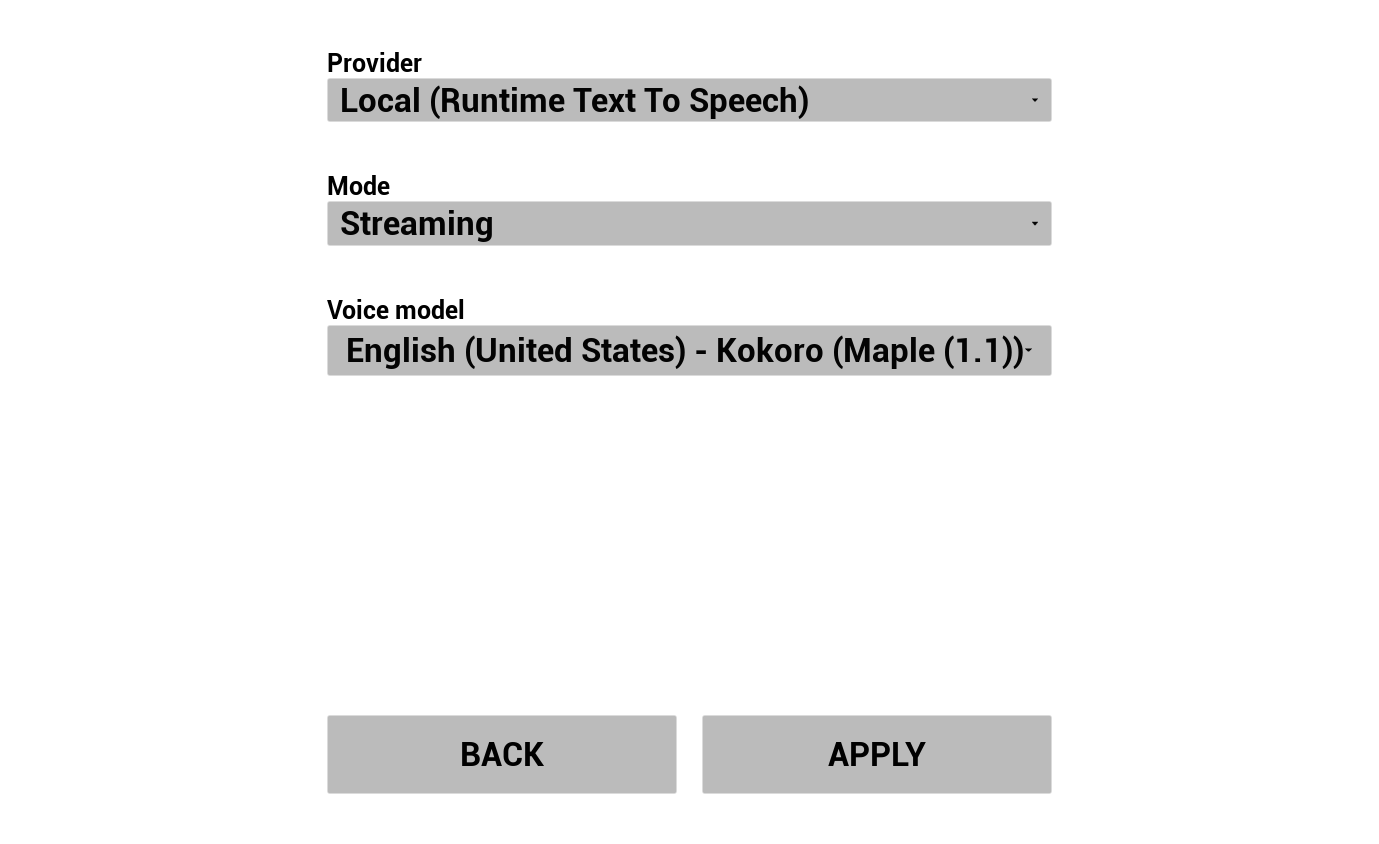
3. Configure Text To Speech
Escolha seu provedor de TTS e configure vozes/modelos:
- Selecione o provedor (Integrador de Chatbot de IA em Tempo de Execução para OpenAI/ElevenLabs, ou Conversão de Texto em Fala em Tempo de Execução para Piper/Kokoro local)
- Selecione o modo: Regular ou Streaming (controla se o áudio é retornado de uma só vez ou conforme é sintetizado)
- Selecione voz/modelo
- Ajuste os parâmetros específicos do provedor

4. Configurar Animações
Controle os visuais do seu avatar de IA:
- Escolha entre 3 personagens MetaHuman pré-baixados (Aera, Ada, Orlando)
- Selecione o modelo de sincronização labial (Padrão ou Realista)
- Selecione o tipo de modelo de sincronização labial - Altamente Otimizado, Semi-Otimizado ou Original (consulte Tipo de Modelo)
- Ajuste o Tamanho do Bloco de Processamento - controla a frequência com que a inferência de sincronização labial é executada (consulte Tamanho do Bloco de Processamento)
- Se a sincronização labial ficar cada vez mais atrasada em relação ao áudio sob carga da CPU, aumente isso para 480 ou 640
- Selecione uma animação de idle para reproduzir no MetaHuman durante a conversa.

Pré-configurando a Demonstração no Editor
Ao trabalhar com a versão fonte, você pode pré-preenche os padrões diretamente no editor para que os valores não precisem ser reinseridos a cada execução:
| What | Onde |
|---|---|
| Configurações gerais (modelo de sincronia labial, animação ociosa, classe do personagem, reconhecimento de fala, etc.) | Content/LipSyncSTSGameInstance |
| Configurações de LLM Externo / TTS Externo (Integrador de Chatbot de IA em Tempo Real) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Configurações do Local LLM (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Configurações de TTS Local (Conversão de Texto em Fala em Tempo Real) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Notas Multiplataforma
Todos os plugins usados pelo demo são compatíveis com Windows, Mac, Linux, iOS, Android e plataformas baseadas em Android (incluindo Meta Quest), portanto, o projeto demo também funciona em todas elas. Isso o torna adequado para implantação em uma ampla variedade de ambientes — desde jogos e quiosques desktop até aplicativos móveis, headsets VR autônomos e configurações de produção virtual em estúdio.
Para dispositivos mais fracos (dispositivos móveis, RV autônoma), você pode querer:
- Use o modelo de sincronização labial padrão em vez do Realista - veja a Comparação de modelos
- Mude para o tipo de modelo Altamente Otimizado
- Aumente o Tamanho do Bloco de Processamento para reduzir a carga da CPU
- Escolha modelos LLM / TTS menores
Consulte a Configuração Específica da Plataforma para etapas adicionais de configuração no Android, iOS, Mac e Linux.
Suporte ao Pixel Streaming
Implantando a demonstração no Pixel Streaming (clique para expandir)
O projeto de demonstração de Conversação com IA também funciona em um ambiente de Pixel Streaming, permitindo que você transmita o avatar MetaHuman para um cliente remoto (ex.: um navegador web) enquanto captura o áudio do microfone do usuário do lado do cliente. Apenas uma única alteração na demonstração é necessária.
1. Instale a extensão Pixel Streaming para o Runtime Audio Importer
O plugin Runtime Audio Importer fornece um plugin de extensão gratuito que permite capturar áudio de um cliente Pixel Streaming. Dependendo da versão da infraestrutura Pixel Streaming que você está usando, instale um dos seguintes:
- Extensão Pixel Streaming (para o plugin original Pixel Streaming), ou
- Extensão Pixel Streaming 2 (para o plugin mais recente Pixel Streaming 2)
Os links de download e as etapas de instalação estão disponíveis aqui: Captura de Áudio para Pixel Streaming - Instalação do Plugin de Extensão.
2. Substitua o nó de onda sonora capturável em LipSyncSTSGameInstance
Após a instalação do plugin de extensão:
- No Navegador de Conteúdo, navegue até
/All/Gamee abra o ativoLipSyncSTSGameInstance. - Mude para o Event Graph.
- Localize o Event Init e siga o fluxo de execução até encontrar o par de nós:
Create Capturable Sound Wave→Set Capturable Sound Wave. - Substitua a chamada
Create Capturable Sound WaveporCreate Pixel Streaming Capturable Sound WaveouCreate Pixel Streaming 2 Capturable Sound Wave, dependendo da versão da infraestrutura do Pixel Streaming que você está utilizando. - Conecte sua saída ao mesmo nó
Set Capturable Sound Wave.
Após isso, o projeto está pronto para ser implantado no Pixel Streaming - reconhecimento de fala, LLM, TTS e sincronização labial funcionarão como antes, mas com áudio capturado do cliente remoto em vez de um microfone local.
Trazendo Seu Próprio Personagem
O projeto de demonstração vem com três personagens MetaHuman de exemplo (Aera, Ada, Orlando), mas você pode importar seu próprio MetaHuman e usá-lo na demonstração.
📺 Tutorial em vídeo: Adicionando um Personagem MetaHuman Personalizado ao Projeto de Demonstração
O plugin Runtime MetaHuman Lip Sync em si suporta muitos outros sistemas de personagens além dos MetaHumans (personagens baseados em ARKit, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe, etc - veja o Guia de Configuração de Personagens Personalizados). Seja criando um NPC de jogo, um apresentador virtual, um atendente de quiosque ou um humano digital para produção virtual, o plugin se adapta ao seu pipeline de personagens.
Um projeto de demonstração mais simples que foca puramente no recurso de sincronização labial em si, sem o fluxo completo de conversação com IA. Adequado se você quiser apenas ver a sincronização labial em ação com várias fontes de áudio.
Vídeo em Destaque
Downloads
O que está incluído
Esta demonstração apresenta os fluxos de trabalho básicos de sincronização labial:
- Entrada de microfone - sincronização labial em tempo real a partir de áudio ao vivo
- Reprodução de arquivo de áudio - sincronização labial a partir de arquivos de áudio importados
- Texto para Fala - sincronização labial impulsionada por fala sintetizada
Plugins Obrigatórios e Opcionais
| Plugin | Propósito | Obrigatório? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animação de sincronização labial | ✅ Obrigatório |
| Runtime Audio Importer | Importação e captura de áudio | ✅ Obrigatório |
| Runtime Text To Speech | TTS local para a cena de demonstração do TTS | 🔶 Opcional |
| Runtime AI Chatbot Integrator | Provedores de TTS externos (OpenAI, ElevenLabs) | 🔶 Opcional |
Notas para o Modelo Padrão de Sincronização Labial
Se você planeja usar o Modelo Padrão (em vez do Realista) em qualquer um dos projetos de demonstração, precisará instalar o plugin de Extensão de Sincronização Labial Padrão. Consulte Extensão do Modelo Padrão para obter instruções de instalação.
Precisa de Ajuda?
Se você encontrar qualquer problema ao configurar ou executar os projetos de demonstração, fique à vontade para entrar em contato:
Para solicitações de desenvolvimento personalizado (ex.: estender o demo com sua própria lógica, adaptá-lo para uma plataforma específica ou pipeline de personagens), entre em contato com [email protected].