Como usar o plugin
O plugin Runtime Speech Recognizer é projetado para reconhecer palavras a partir de dados de áudio recebidos. Ele usa uma versão ligeiramente modificada do whisper.cpp para funcionar com o motor. Para usar o plugin, siga estes passos:
Lado do Editor
- Selecione os modelos de linguagem apropriados para o seu projeto conforme descrito aqui.
Lado do Runtime
- Crie um Speech Recognizer e defina os parâmetros necessários (CreateSpeechRecognizer, para parâmetros veja aqui).
- Vincule aos delegados necessários (OnRecognitionFinished, OnRecognizedTextSegment e OnRecognitionError).
- Inicie o reconhecimento de fala (StartSpeechRecognition).
- Processe os dados de áudio e aguarde os resultados dos delegados (ProcessAudioData).
- Pare o reconhecedor de fala quando necessário (por exemplo, após a transmissão do OnRecognitionFinished).
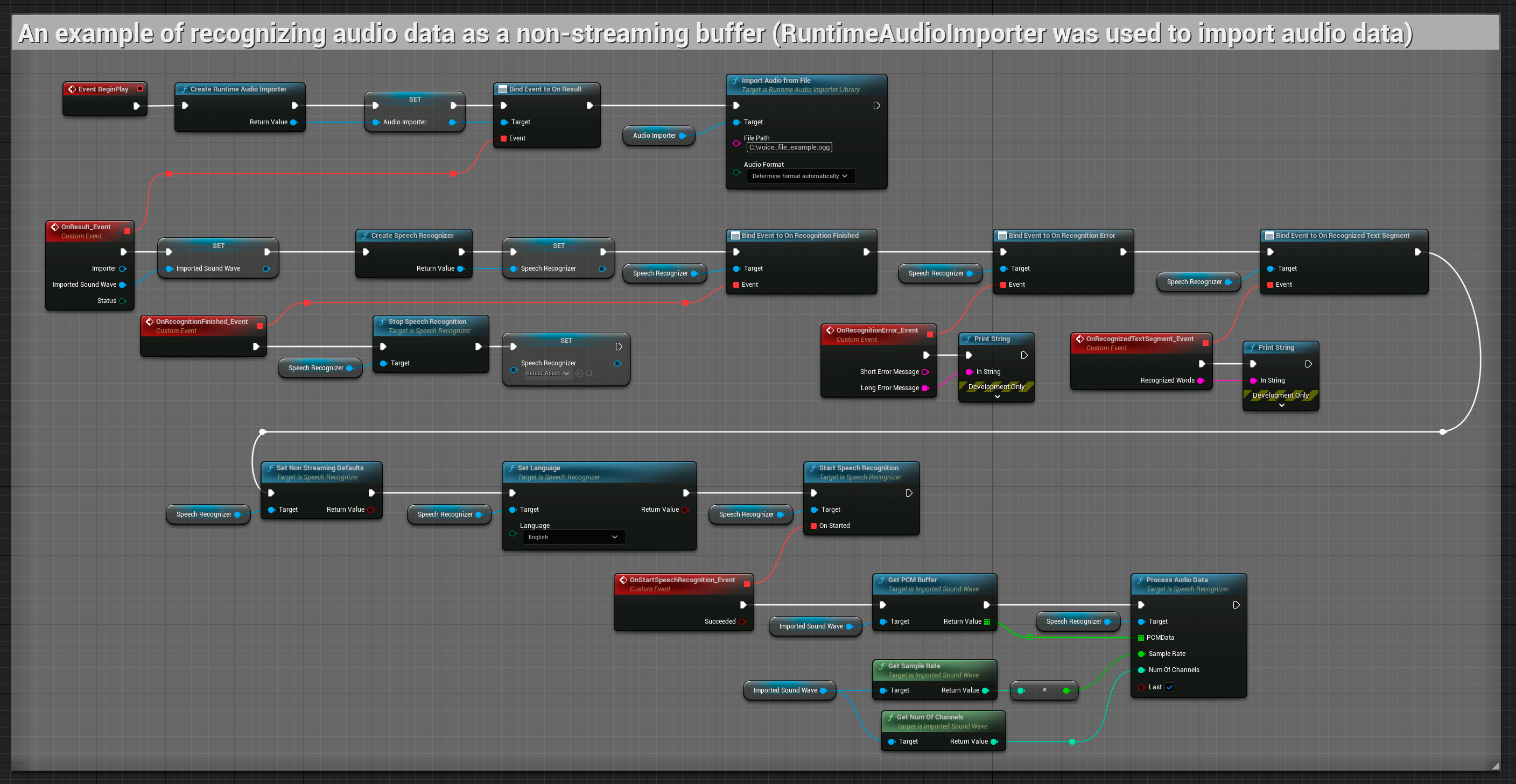
O plugin suporta áudio recebido no formato PCM intercalado de 32 bits em ponto flutuante. Embora funcione bem com o Runtime Audio Importer, ele não depende diretamente dele.
Parâmetros de reconhecimento
O plugin suporta reconhecimento de dados de áudio em streaming e não streaming. Para ajustar os parâmetros de reconhecimento para o seu caso de uso específico, chame SetStreamingDefaults ou SetNonStreamingDefaults. Além disso, você tem a flexibilidade de definir manualmente parâmetros individuais, como o número de threads, o tamanho do passo, se deve traduzir o idioma de entrada para inglês e se deve usar transcrição passada. Consulte a Lista de Parâmetros de Reconhecimento para uma lista completa dos parâmetros disponíveis.
Melhorando o desempenho
Consulte a seção Como melhorar o desempenho para dicas sobre como otimizar o desempenho do plugin.
Detecção de Atividade de Voz (VAD)
Ao processar a entrada de áudio, especialmente em cenários de streaming, é recomendado usar Detecção de Atividade de Voz (VAD) para filtrar segmentos de áudio vazios ou apenas com ruído antes que eles cheguem ao reconhecedor. Essa filtragem pode ser habilitada no lado da onda sonora capturável usando o plugin Runtime Audio Importer, o que ajuda a evitar que os modelos de linguagem alucinem - tentando encontrar padrões no ruído e gerando transcrições incorretas.
Para resultados ótimos de reconhecimento de fala, recomendamos usar o provedor Silero VAD que oferece tolerância superior a ruídos e detecção de fala mais precisa. O Silero VAD está disponível como uma extensão do plugin Runtime Audio Importer. Para instruções detalhadas sobre configuração de VAD, consulte a documentação de Detecção de Atividade de Voz.
Os nós copiáveis nos exemplos abaixo usam o provedor VAD padrão por questões de compatibilidade. Para melhorar a precisão do reconhecimento, você pode facilmente mudar para o Silero VAD fazendo:
- Instalando a extensão Silero VAD conforme descrito na seção Extensão Silero VAD
- Após ativar o VAD com o nó Toggle VAD, adicione um nó Set VAD Provider e selecione "Silero" no dropdown
No projeto de demonstração incluído com o plugin, o VAD está ativado por padrão. Você pode encontrar mais informações sobre a implementação da demo em Projeto de Demonstração.
Exemplos
Estes exemplos ilustram como usar o plugin Runtime Speech Recognizer com entrada de áudio streaming e não-streaming, usando o Runtime Audio Importer para obter dados de áudio como exemplo. Observe que o download separado do RuntimeAudioImporter é necessário para acessar o mesmo conjunto de recursos de importação de áudio mostrados nos exemplos (ex: capturable sound wave e ImportAudioFromFile). Estes exemplos são destinados apenas a ilustrar o conceito central e não incluem tratamento de erros.
Exemplos de entrada de áudio streaming
Nota: No UE 5.3 e outras versões, você pode encontrar nós ausentes após copiar Blueprints. Isso pode ocorrer devido a diferenças na serialização de nós entre versões do engine. Sempre verifique se todos os nós estão devidamente conectados em sua implementação.
1. Reconhecimento streaming básico
Este exemplo demonstra a configuração básica para capturar dados de áudio do microfone como um stream usando o Capturable sound wave e passá-lo para o reconhecedor de fala. Ele grava a fala por cerca de 5 segundos e então processa o reconhecimento, tornando-o adequado para testes rápidos e implementações simples. Nós copiáveis.
Características principais desta configuração:
- Duração de gravação fixa de 5 segundos
- Reconhecimento one-shot simples
- Requisitos mínimos de configuração
- Perfeito para testes e prototipagem
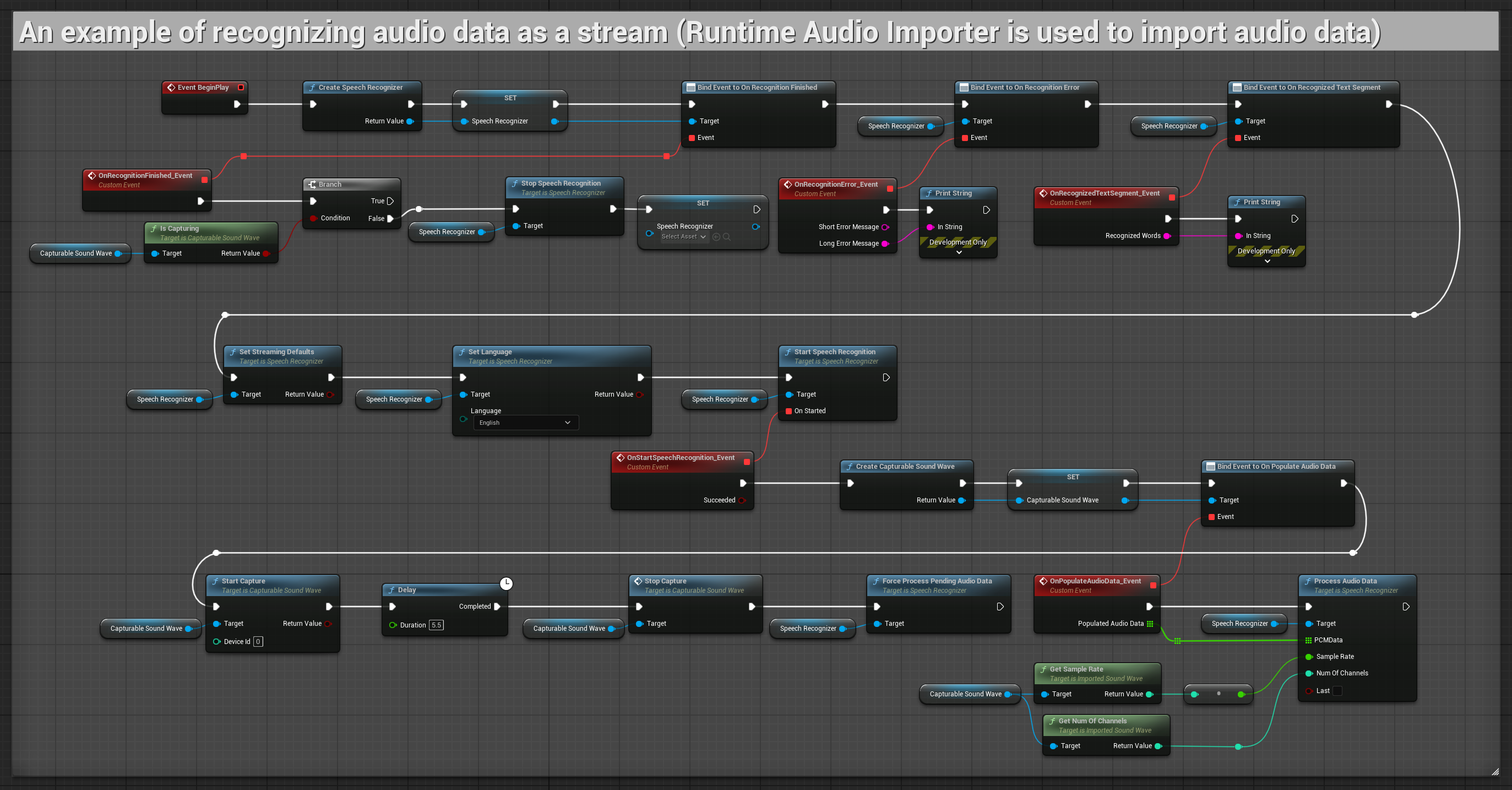
2. Reconhecimento streaming controlado
Este exemplo estende a configuração streaming básica adicionando controle manual sobre o processo de reconhecimento. Ele permite que você inicie e pare o reconhecimento à vontade, tornando-o adequado para cenários onde você precisa de controle preciso sobre quando o reconhecimento ocorre. Nós copiáveis.
Características principais desta configuração:
- Controle manual de início/parada
- Capacidade de reconhecimento contínuo
- Duração de gravação flexível
- Adequado para aplicações interativas
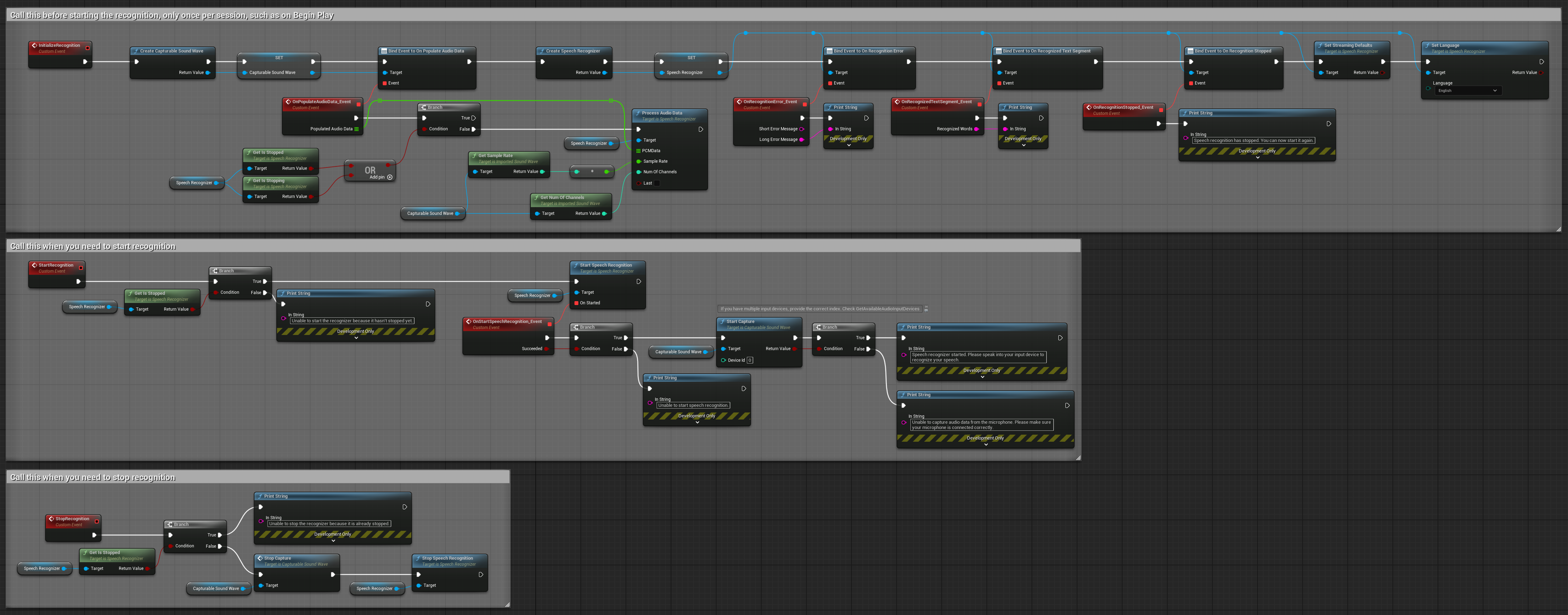
3. Reconhecimento de comando por voz ativado
Este exemplo é otimizado para cenários de reconhecimento de comandos. Ele combina reconhecimento em streaming com Detecção de Atividade Vocal (VAD) para processar automaticamente a fala quando o usuário para de falar. O reconhecedor inicia o processamento da fala acumulada apenas quando o silêncio é detectado, tornando-o ideal para interfaces baseadas em comandos. Nós copiáveis.
Características principais desta configuração:
- Controle manual de início/parada
- Detecção de Atividade Vocal (VAD) ativada para detectar segmentos de fala
- Disparo automático de reconhecimento quando o silêncio é detectado
- Otimizado para reconhecimento de comandos curtos
- Redução de sobrecarga de processamento ao reconhecer apenas fala real
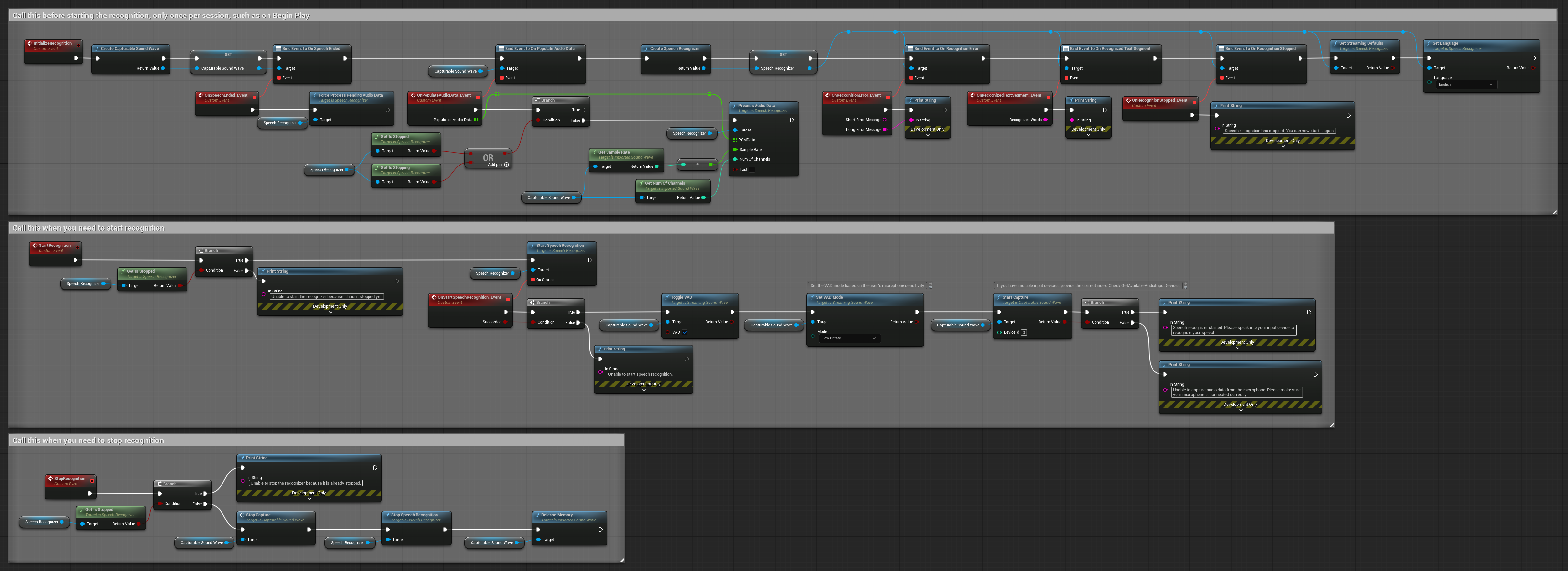
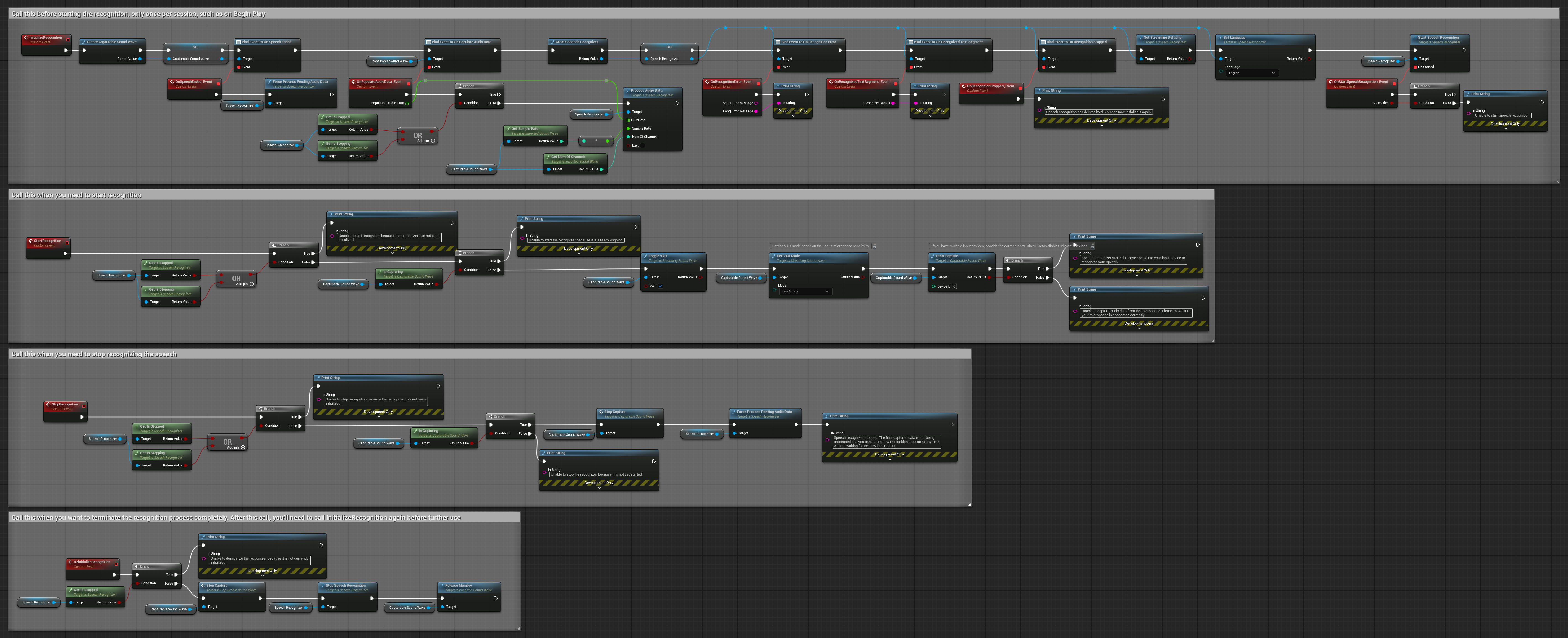
4. Reconhecimento de voz com autoinicialização e processamento de buffer final
Este exemplo é outra variação da abordagem de reconhecimento ativado por voz com tratamento de ciclo de vida diferente. Ele inicia automaticamente o reconhecedor durante a inicialização e o para durante a desinicialização. Uma característica fundamental é que ele processa o último buffer de áudio acumulado antes de parar o reconhecedor, garantindo que nenhum dado de fala seja perdido quando o usuário deseja encerrar o processo de reconhecimento. Esta configuração é particularmente útil para aplicações onde você precisa capturar enunciados completos do usuário, mesmo ao parar no meio da fala. Nós copiáveis.
Características principais desta configuração:
- Auto-inicia o reconhecedor na inicialização
- Auto-pára o reconhecedor na desinicialização
- Processa o buffer de áudio final antes de parar completamente
- Usa Detecção de Atividade Vocal (VAD) para reconhecimento eficiente
- Garante que nenhum dado de fala seja perdido ao parar
Entrada de áudio não streaming
Este exemplo importa dados de áudio para a Onda sonora importada e reconhece os dados de áudio completos uma vez que tenham sido importados. Nós copiáveis.