Lista de parâmetros de reconhecimento
Estes parâmetros só podem ser definidos enquanto o reconhecedor não está em execução.
Esta não é uma lista exaustiva dos parâmetros disponíveis no Whisper. Apenas os mais importantes são expostos aqui. Se necessário, esta lista será atualizada.
Definir Parâmetros de Reconhecimento
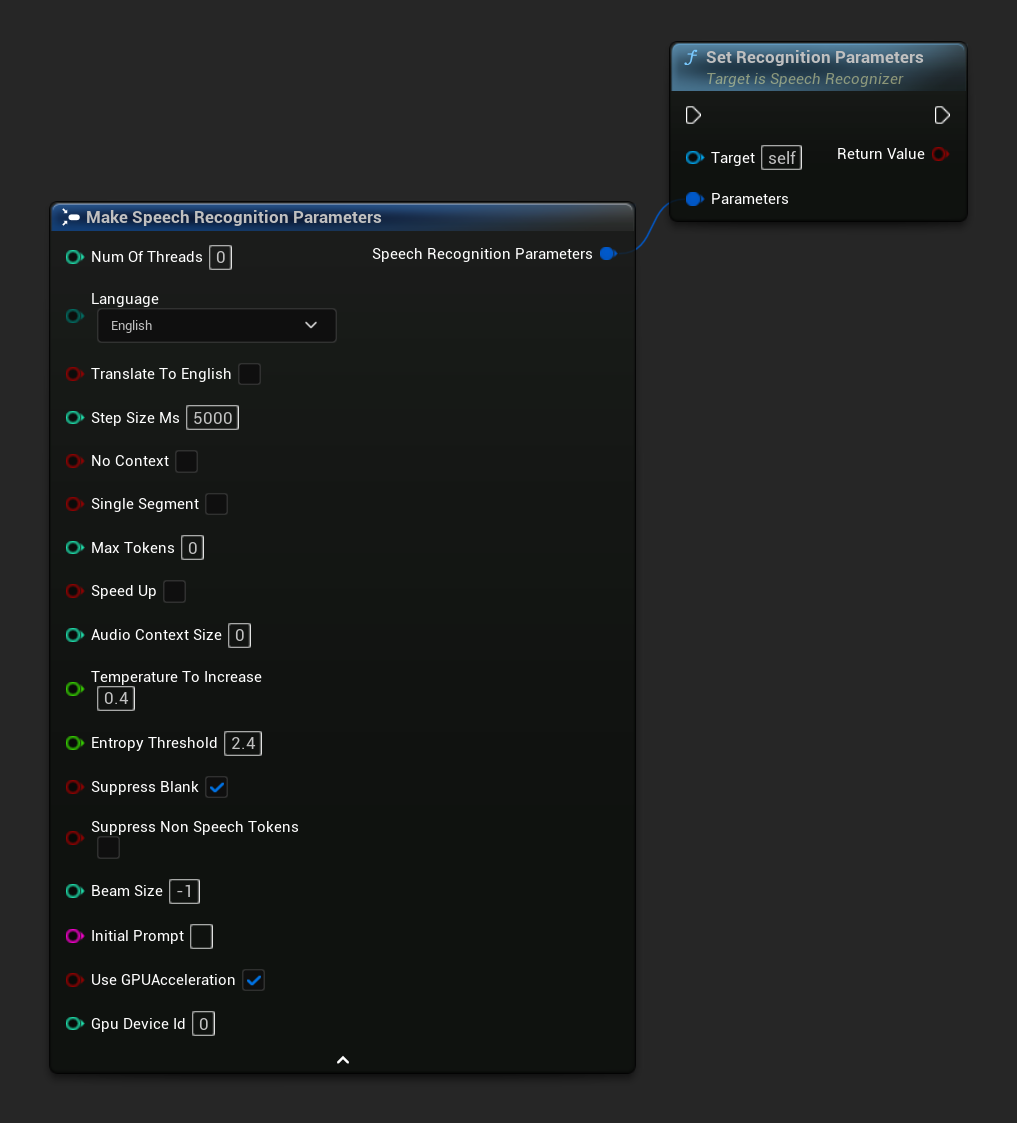
Define os parâmetros para o reconhecimento de fala. Se você quiser alterar apenas parâmetros específicos, considere usar as funções setter individuais.
Definir Padrões de Streaming
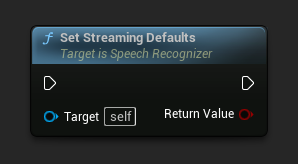
Define os parâmetros padrão adequados para reconhecimento de fala em streaming.
Esta função sobrescreve todos os parâmetros aplicados anteriormente. Certifique-se de chamá-la antes de definir seus parâmetros personalizados se precisar usar os padrões de streaming como uma configuração base.
Definir Padrões Sem Streaming
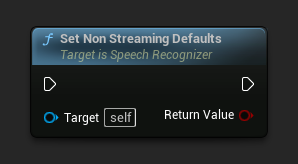
Define os parâmetros padrão adequados para reconhecimento de fala sem streaming.
Esta função sobrescreve todos os parâmetros aplicados anteriormente. Certifique-se de chamá-la antes de definir seus parâmetros personalizados se precisar usar os padrões sem streaming como uma configuração base.
Definir Número de Threads
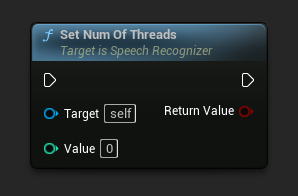
Define o número de threads a serem usadas para o reconhecimento de fala. Defina este valor como 0 para usar o número de núcleos.
Definir Idioma
Define o idioma a ser usado para o reconhecimento de fala. Deve ser suportado pelo modelo de linguagem selecionado nas configurações do Editor.
Definir o idioma como Auto diminuirá a precisão e o desempenho do reconhecimento.
Obter Idioma Detectado
Obtém o idioma detectado do último reconhecimento. Retorna o idioma como um valor de enumeração.
Nota: Esta função só funciona após o reconhecimento ter sido realizado. Ela retorna Auto se a detecção de idioma falhou ou não foi realizada. Isto é particularmente útil ao usar a detecção automática de idioma para identificar qual idioma foi realmente reconhecido.
Obter Código do Idioma
Converte um valor de enumeração de idioma para sua string de código de idioma (ex.: En -> "en", Fr -> "fr", De -> "de").
Obter Nome Completo do Idioma
Converte um valor de enumeração de idioma para seu nome completo de idioma (ex.: En -> "English", Fr -> "French", De -> "German").
Definir Traduzir para Inglês
![]()
Define se as palavras reconhecidas devem ser traduzidas para o inglês. Se verdadeiro, o modelo de linguagem deve ser multilíngue.
Definir Tamanho do Passo
Define o tamanho do passo em milissegundos. Determina com que frequência enviar dados de áudio para reconhecimento. O valor padrão é 5000 ms (5 segundos).
Definir Sem Contexto
Define se deve usar a transcrição anterior (se houver) como prompt inicial para o decodificador.
Definir Segmento Único
Define se deve forçar a saída de segmento único (útil para streaming).
Definir Máximo de Tokens
Define o número máximo de tokens por segmento de texto. Use 0 para sem limite.
Definir Acelerar
Define se deve acelerar o reconhecimento em 2x usando Phase Vocoder. Defina como false para melhorar a qualidade da saída.
Definir Tamanho do Contexto de Áudio
Define o tamanho do contexto de áudio. Defina como 0 para melhorar a qualidade da saída.
Definir Temperatura para Aumentar
Define a temperatura para aumentar ao recuar quando a decodificação falha em atender a qualquer um dos limites abaixo.
Definir Limite de Entropia
Define o limite de entropia. Se a taxa de compressão for maior que este valor, trate a decodificação como falha. Semelhante ao "compression_ratio_threshold" da OpenAI
Definir Suprimir Espaços em Branco
![]()
Define se deve suprimir espaços em branco aparecendo nas saídas.
Definir Suprir Tokens Não de Fala
Define se deve suprimir tokens não de fala aparecendo nas saídas.
Definir Tamanho do Feixe
Define o número de feixes na busca por feixe. Aplicável apenas quando a temperatura é zero.
Definir Prompt Inicial
Define o prompt inicial para a primeira janela. Isto pode ser usado para fornecer contexto para o reconhecimento, tornando-o mais propenso a prever as palavras corretamente, ex.: vocabulários personalizados ou nomes próprios.
Para mais detalhes sobre estratégias eficazes de prompting, consulte o Guia de Prompting do Whisper.
Definir Aceleração por GPU
Define se deve usar aceleração por GPU para reconhecimento de fala (aplicável apenas no Windows no momento).
Definir ID do Dispositivo GPU
Define o ID do dispositivo GPU a ser usado para reconhecimento de fala. O valor padrão é 0. Isto é útil para sistemas com múltiplas GPUs para especificar qual GPU deve ser usada para o processo de reconhecimento. Se o ID do dispositivo GPU especificado for inválido, o primeiro índice de dispositivo GPU disponível será usado.