Провайдеры перевода
AI Localization Automator поддерживает пять различных AI-провайдеров, каждый со своими уникальными преимуществами и настройками. Выберите провайдера, который лучше всего соответствует потребностям вашего проекта, бюджету и требованиям к качеству.
Ollama (Локальный AI)
Лучше всего подходит для: Проектов, чувствительных к конфиденциальности, офлайн-перевода, неограниченного использования
Ollama запускает AI-модели локально на вашем компьютере, обеспечивая полную конфиденциальность и контроль без затрат на API и необходимости подключения к интернету.
Популярные модели
- translategemma:12b (Специализированная модель перевода на основе Gemma 3)
- llama3.2 (Рекомендуемая модель общего назначения)
- mistral (Эффективная альтернатива)
- codellama (Перевод с учетом кода)
- И многие другие модели сообщества
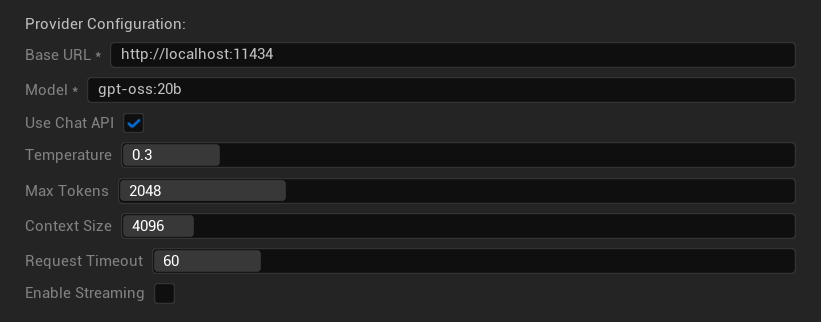
Параметры конфигурации
- Базовый URL: Локальный сервер Ollama (по умолчанию:
http://localhost:11434) - Модель: Имя локально установленной модели (обязательно)
- Использовать Chat API: Включить для лучшей обработки диалогов
- Температура: 0.0-2.0 (рекомендуется 0.3)
- Максимум токенов: 1-8,192 токена
- Размер контекста: 512-32,768 токенов
- Таймаут запроса: 10-300 секунд (локальные модели могут быть медленнее)
- Включить потоковую передачу: Для обработки ответов в реальном времени
Преимущества
- ✅ Полная конфиденциальность (данные не покидают ваш компьютер)
- ✅ Нет затрат на API или ограничений по использованию
- ✅ Работает офлайн
- ✅ Полный контроль над параметрами модели
- ✅ Широкий выбор моделей сообщества
- ✅ Нет привязки к поставщику
Особенности
- 💻 Требует локальной настройки и производительного оборудования
- ⚡ Как правило, медленнее, чем облачные провайдеры
- 🔧 Требуется более техническая настройка
- 📊 Качество перевода значительно варьируется в зависимости от модели (некоторые могут превосходить облачных провайдеров)
- 💾 Большие требования к объему памяти для моделей
Настройка Ollama
- Установите Ollama: Скачайте с ollama.ai и установите на вашу систему
- Загрузите модели: Используйте
ollama pull translategemma:12bдля загрузки выбранной модели - Запустите сервер: Ollama запускается автоматически, или запустите с помощью
ollama serve - Настройте плагин: Установите базовый URL и имя модели в настройках плагина
- Проверьте соединение: Плагин проверит подключение при применении конфигурации
OpenAI
Лучше всего подходит для: Самого высокого общего качества перевода, обширного выбора моделей
OpenAI предоставляет передовые языковые модели через свой Chat Completions API, включая последние модели GPT, модели с рассуждениями и модели с поддержкой веб-поиска.
Доступные модели
Семейство GPT-5 (Флагманские модели)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
Семейство GPT-4.1 (Высокопроизводительные)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
Семейство GPT-4o (Мультимодальные)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O-Series (Модели с рассуждениями — температура/top_p не поддерживаются)
- o1, o1-pro, o3, o3-mini, o4-mini
Модели с веб-поиском (Температура/top_p не поддерживаются)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
Устаревшие / Предварительные версии
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
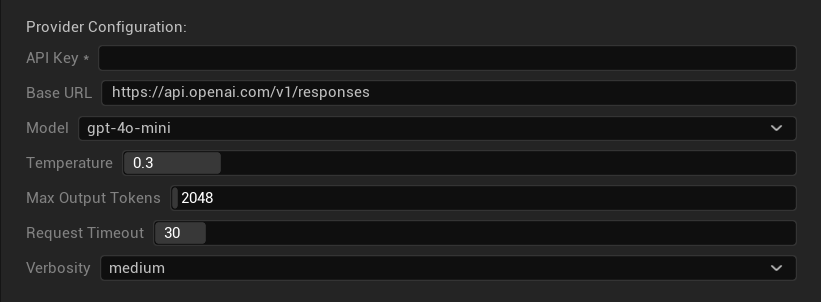
Параметры конфигурации
- API-ключ: Ваш API-ключ OpenAI (обязательно)
- Базовый URL: Конечная точка API (по умолчанию:
https://api.openai.com/v1/chat/completions) - Модель: Выберите из доступных моделей, перечисленных выше
- Использовать температуру: Переключить параметр температуры вкл/выкл (автоматически игнорируется для O-Series моделей с рассуждениями и моделей с веб-поиском)
- Температура: 0.0–2.0 (рекомендуется 0.3 для согласованности перевода)
- Top P: 0.0–1.0 параметр ядерной выборки (игнорируется для O-Series моделей с рассуждениями и моделей с веб-поиском)
- Максимум токенов завершения: 1–128,000 токенов (включает как выходные, так и токены рассуждений)
- Таймаут запроса: 5–300 секунд
Преимущества
- ✅ Стабильно высокое качество переводов
- ✅ Отличное понимание контекста
- ✅ Хорошее сохранение формата
- ✅ Поддержка широкого спектра языков
- ✅ Надежная доступность API
Особенности
- 💰 Высокая стоимость за запрос
- 🌐 Требуется подключение к интернету
- ⏱️ Ограничения использования в зависимости от тарифа
Anthropic Claude
Лучше всего подходит для: Нюансированных переводов, творческого контента, приложений, ориентированных на безопасность
Модели Claude отлично справляются с пониманием контекста и нюансов, что делает их идеальными для игр с насыщенным повествованием и сложных сценариев локализации.
Доступные модели
Семейство Claude 4.6 (Последние)
- claude-opus-4-6, claude-sonnet-4-6
Семейство Claude 4.5
- claude-haiku-4-5 (Быстрая и эффективная)
- claude-sonnet-4-5, claude-opus-4-5
Семейство Claude 4.x
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Семейство Claude 3.x (Устаревшие)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
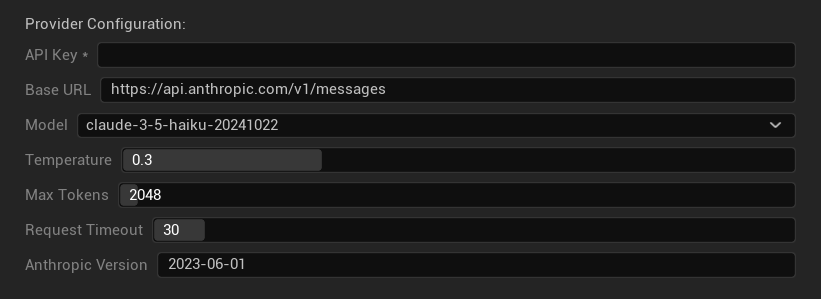
Параметры конфигурации
- API-ключ: Ваш API-ключ Anthropic (обязательно)
- Базовый URL: Конечная точка API Claude
- Модель: Выберите из семейства моделей Claude
- Температура: 0.0–1.0 (рекомендуется 0.3)
- Top K: Параметр выборки Top-K (0 = не установлен)
- Максимум токенов: 1–64,000 токенов
- Таймаут запроса: 5–300 секунд
- Версия Anthropic: Заголовок версии API
Преимущества
- ✅ Исключительная осведомленность о контексте
- ✅ Отлично подходит для творческого/повествовательного контента
- ✅ Сильные функции безопасности
- ✅ Подробные возможности рассуждений (расширенное мышление на моделях 3.7+)
- ✅ Отличное следование инструкциям
Особенности
- 💰 Премиальная модель ценообразования
- 🌐 Требуется подключение к интернету
- 📏 Лимиты токенов варьируются в зависимости от модели
DeepSeek
Лучше всего подходит для: Экономичного перевода, высокой пропускной способности, проектов с ограниченным бюджетом
DeepSeek предлагает конкурентоспособное качество перевода за долю стоимости других провайдеров, что делает его идеальным для крупномасштабных проектов локализации.
Доступные модели
- deepseek-chat (Общего назначения, рекомендуется)
- deepseek-reasoner (Расширенные возможности рассуждений)
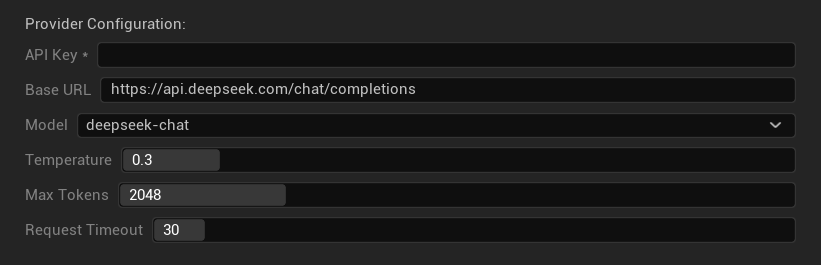
Параметры конфигурации
- API-ключ: Ваш API-ключ DeepSeek (обязательно)
- Базовый URL: Конечная точка API DeepSeek
- Модель: Выберите между чат-моделями и моделями с рассуждениями
- Температура: 0.0-2.0 (рекомендуется 0.3)
- Максимум токенов: 1-8,192 токена
- Таймаут запроса: 5-300 секунд
Преимущества
- ✅ Очень экономически эффективный
- ✅ Хорошее качество перевода
- ✅ Быстрое время отклика
- ✅ Простая конфигурация
- ✅ Высокие лимиты скорости
Особенности
- 📏 Более низкие лимиты токенов
- 🆕 Более новый провайдер (меньше опыта работы)
- 🌐 Требуется подключение к интернету
Google Gemini
Лучше всего подходит для: Многоязычных проектов, экономичного перевода, интеграции с экосистемой Google
Модели Gemini предлагают сильные многоязычные возможности с конкурентоспособным ценообразованием и уникальными функциями, такими как режим мышления для улучшенных рассуждений.
Доступные модели
Семейство Gemini 3.x (Предварительная версия)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Семейство Gemini 2.5 (С поддержкой мышления)
- gemini-2.5-pro (Флагманская с мышлением)
- gemini-2.5-flash (Быстрая, с поддержкой мышления)
- gemini-2.5-flash-lite (Облегченный вариант)
Семейство Gemini 2.0
- gemini-2.0-flash, gemini-2.0-flash-lite
Последние псевдонимы
- gemini-flash-latest, gemini-flash-lite-latest
Параметры конфигурации
- API-ключ: Ваш API-ключ Google AI (обязательно)
- Базовый URL: Конечная точка API Gemini
- Модель: Выберите из семейства моделей Gemini
- Температура: 0.0–2.0 (рекомендуется 0.3)
- Максимум выходных токенов: 1–8,192 токена
- Таймаут запроса: 5–300 секунд
- Включить мышление: Активировать улучшенные рассуждения для моделей 2.5+
- Бюджет мышления: Контролировать распределение токенов мышления (0 = без мышления)
Преимущества
- ✅ Сильная поддержка многоязычности
- ✅ Конкурентоспособное ценообразование
- ✅ Продвинутые рассуждения (режим мышления)
- ✅ Интеграция с экосистемой Google
- ✅ Регулярные обновления моделей с предварительным доступом к новейшим моделям
Особенности
- 🧠 Режим мышления увеличивает использование токенов
- 📏 Переменные лимиты токенов в зависимости от модели
- 🌐 Требуется подключение к интернету
Выбор подходящего провайдера
| Провайдер | Лучше всего подходит для | Качество | Стоимость | Настройка | Конфиденциальность |
|---|---|---|---|---|---|
| Ollama | Конфиденциальность/офлайн | Переменное* | Бесплатно | Продвинутая | Локальная |
| OpenAI | Высшее качество | ⭐⭐⭐⭐⭐ | 💰💰💰 | Легкая | Облачная |
| Claude | Творческий контент | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Легкая | Облачная |
| DeepSeek | Бюджетные проекты | ⭐⭐⭐⭐ | 💰 | Легкая | Облачная |
| Gemini | Многоязычность | ⭐⭐⭐⭐ | 💰 | Легкая | Облачная |
*Качество для Ollama значительно варьируется в зависимости от используемой локальной модели — некоторые современные локальные модели могут соответствовать или превосходить облачных провайдеров.
Советы по настройке провайдеров
Для всех облачных провайдеров:
- Храните API-ключи безопасно и не добавляйте их в систему контроля версий
- Начните с консервативных настроек температуры (0.3) для согласованных переводов
- Следите за использованием вашего API и затратами
- Тестируйте на небольших пакетах перед запуском крупных переводов
Для Ollama:
- Убедитесь в достаточном объеме ОЗУ (рекомендуется 8 ГБ+ для больших моделей)
- Используйте SSD-накопитель для лучшей производительности загрузки моделей
- Рассмотрите возможность ускорения на GPU для более быстрого вывода
- Тестируйте локально, прежде чем полагаться на него для производственных переводов