Как использовать плагин
Это руководство охватывает полный API времени выполнения: создание экземпляра LLM, загрузка моделей, отправка сообщений, загрузка моделей во время выполнения, управление состоянием и вспомогательные функции.
Создайте экземпляр LLM
Начните с создания объекта Runtime Local LLM. Сохраните ссылку на него (например, как переменную в Blueprints или UPROPERTY в C++), чтобы предотвратить преждевременную сборку мусора.
- Blueprint
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
Загрузить модель
Вы должны загрузить модель перед отправкой сообщений. Плагин предоставляет несколько методов загрузки в зависимости от вашего рабочего процесса.
Загрузка по имени
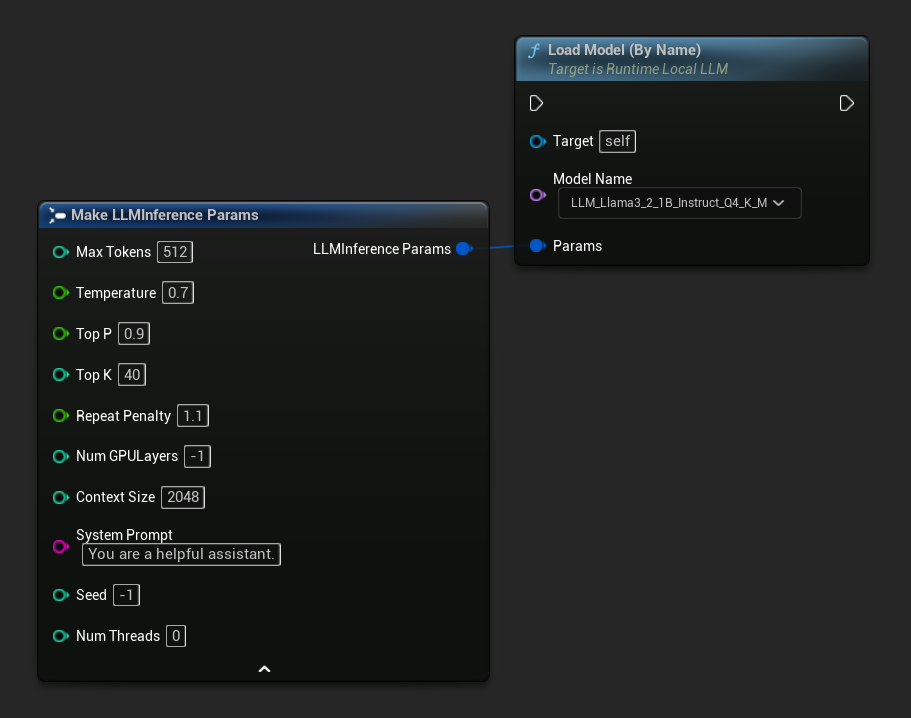
Если вы управляете моделями через панель настроек редактора, используйте Load Model (By Name).
- Blueprint
- C++
- UE 5.3 и более ранние версии
- UE 5.4+
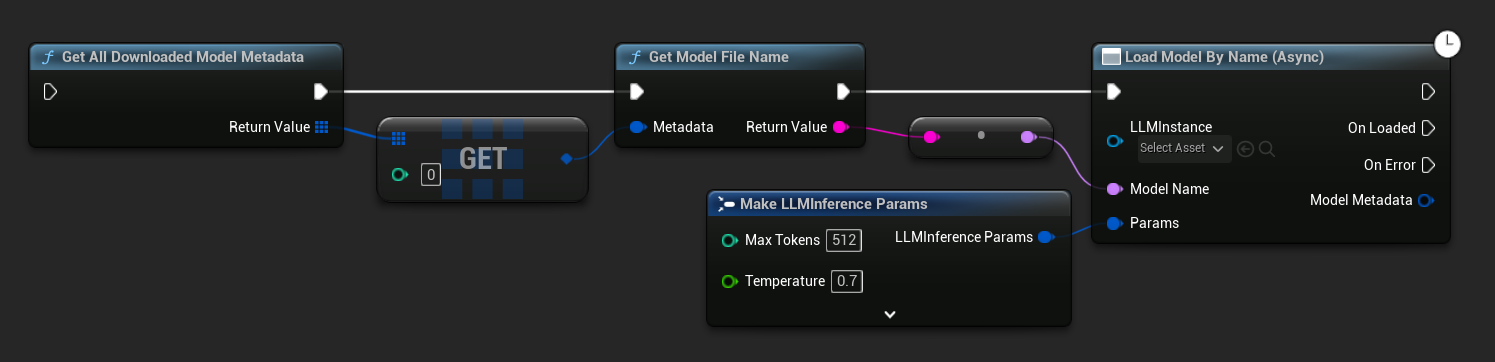
В UE 5.3 и более ранних версиях выпадающий список не отображается, поэтому вам нужно получить доступные модели вручную. Используйте Get All Downloaded Model Metadata, возьмите элемент с индексом 0 (или любую нужную модель), передайте его в Get Model File Name, чтобы получить строку имени, затем передайте её в Load Model (By Name).
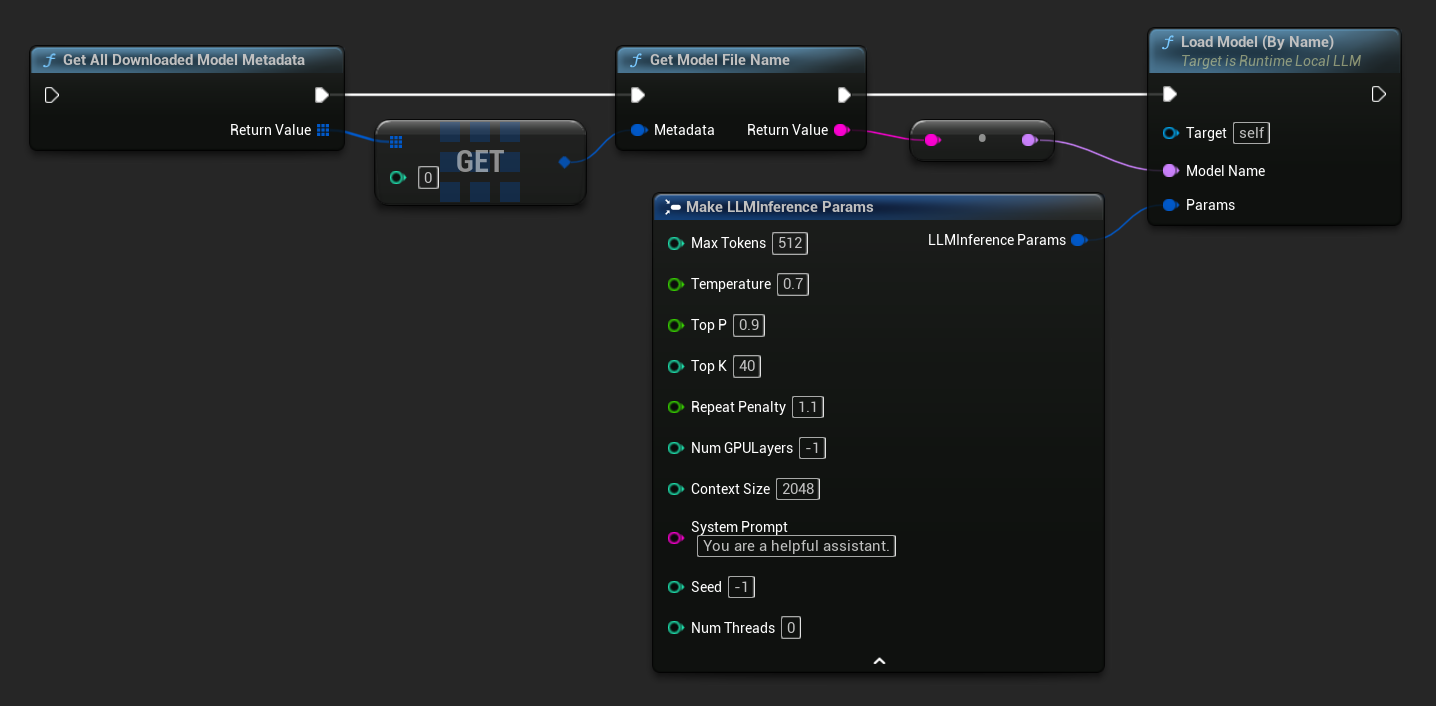
В UE 5.4 и более поздних версиях Load Model (By Name) отображает выпадающий список всех моделей на диске — просто выберите модель, которую хотите загрузить.
В C++ используйте GetAllDownloadedModelMetadata для получения доступных моделей и GetModelFileName для получения имени, которое нужно передать в LoadModelByName.
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
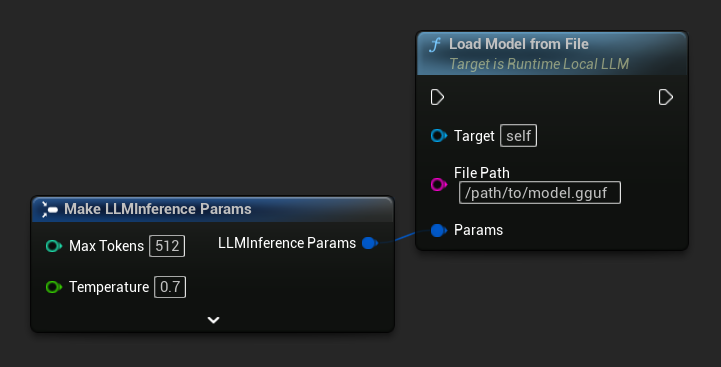
Загрузить из пути к файлу
Загрузите модель напрямую по абсолютному пути к файлу .gguf:
- Blueprint
- C++
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
Загрузить из URL (Скачать и загрузить)
Скачать модель по URL (если её ещё нет на диске) и загрузить автоматически. Если файл уже существует локально, загрузка пропускается.
- Blueprint
- C++
Самый простой вариант принимает только URL — метаданные извлекаются из имени файла:
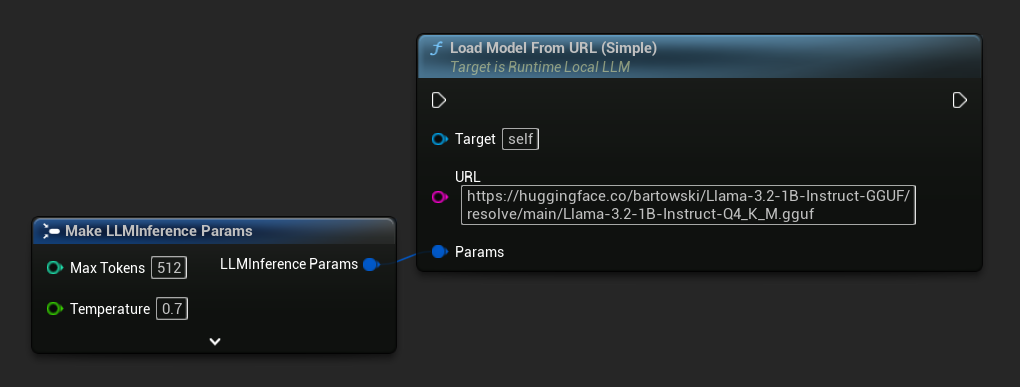
Вы также можете использовать Load Model From URL с полными метаданными модели для получения более подробной информации о модели:
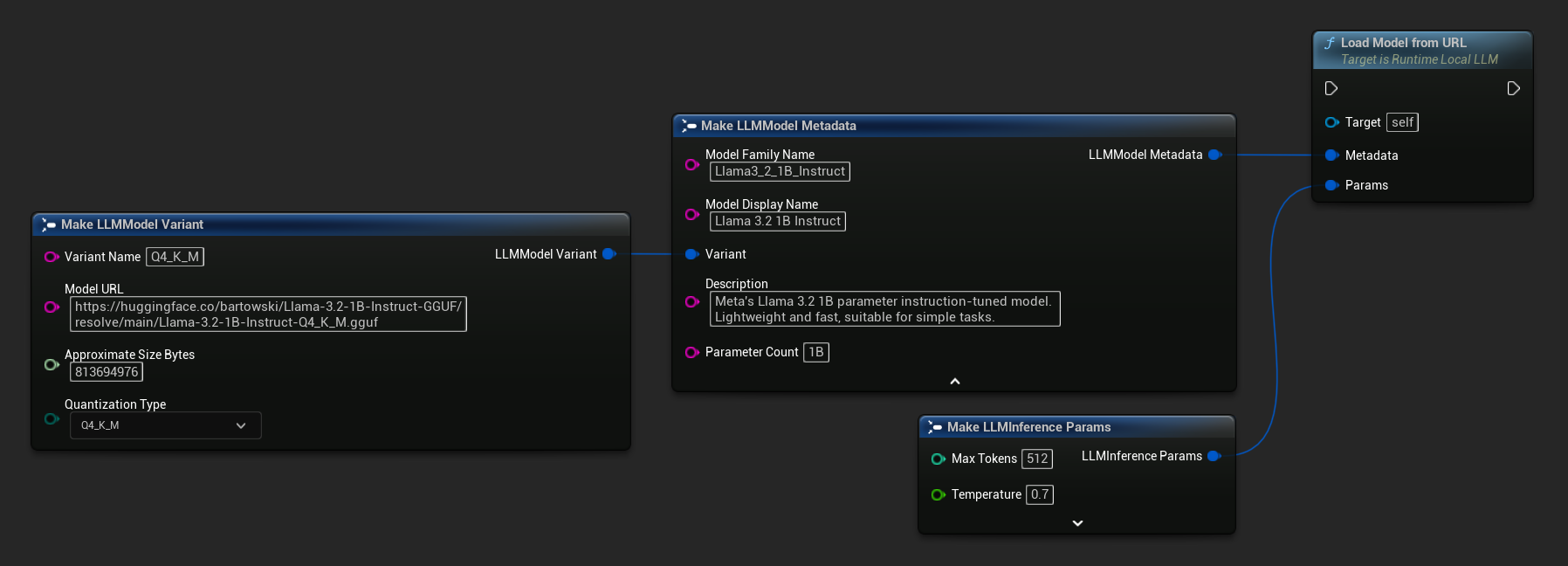
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
Асинхронная загрузка (Blueprint)
Для обработки завершения загрузки и ошибок через выходные пины вместо ручного привязывания делегатов доступны два асинхронных узла.
Load Model By Name (Async) повторяет Load Model (By Name) — в UE 5.4+ он отображает выпадающий список всех моделей на диске.
- UE 5.4+
- UE 5.3 и более ранние версии
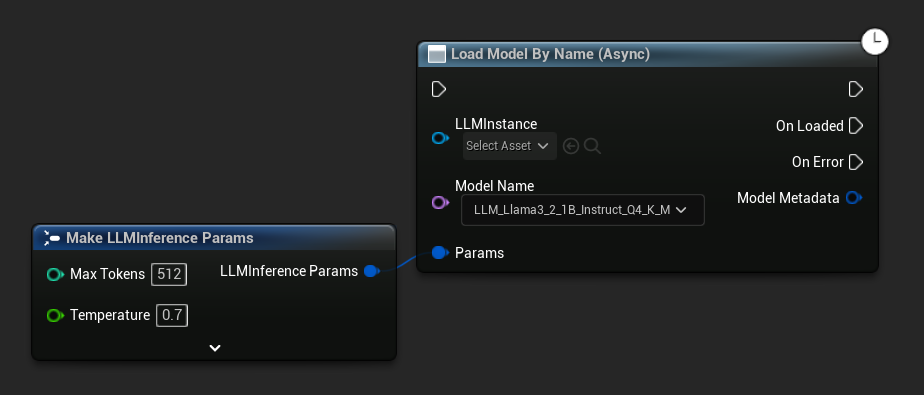
В UE 5.3 и более ранних версиях выпадающий список не отображается. Используйте Get All Downloaded Model Metadata, получите элемент с индексом 0 (или нужную вам модель), передайте его в Get Model File Name, а затем передайте результат в Load Model By Name (Async).
Load Model From File (Async) принимает абсолютный путь к файлу:
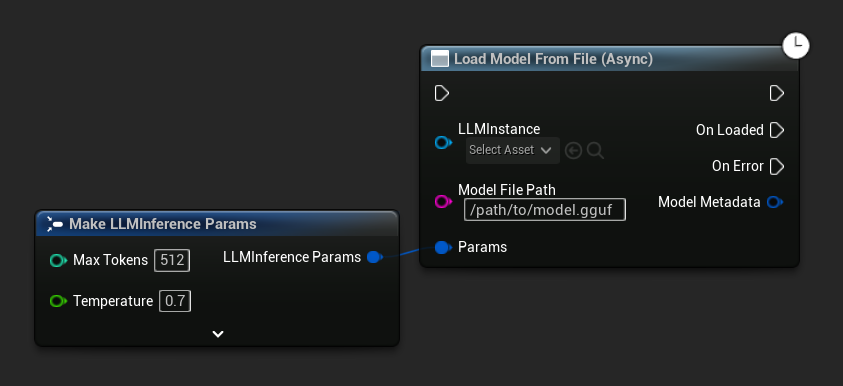
Привязать события
Привяжитесь к делегатам экземпляра LLM, чтобы получать обратные вызовы. Все обратные вызовы срабатывают в игровом потоке.
- Blueprint
- C++
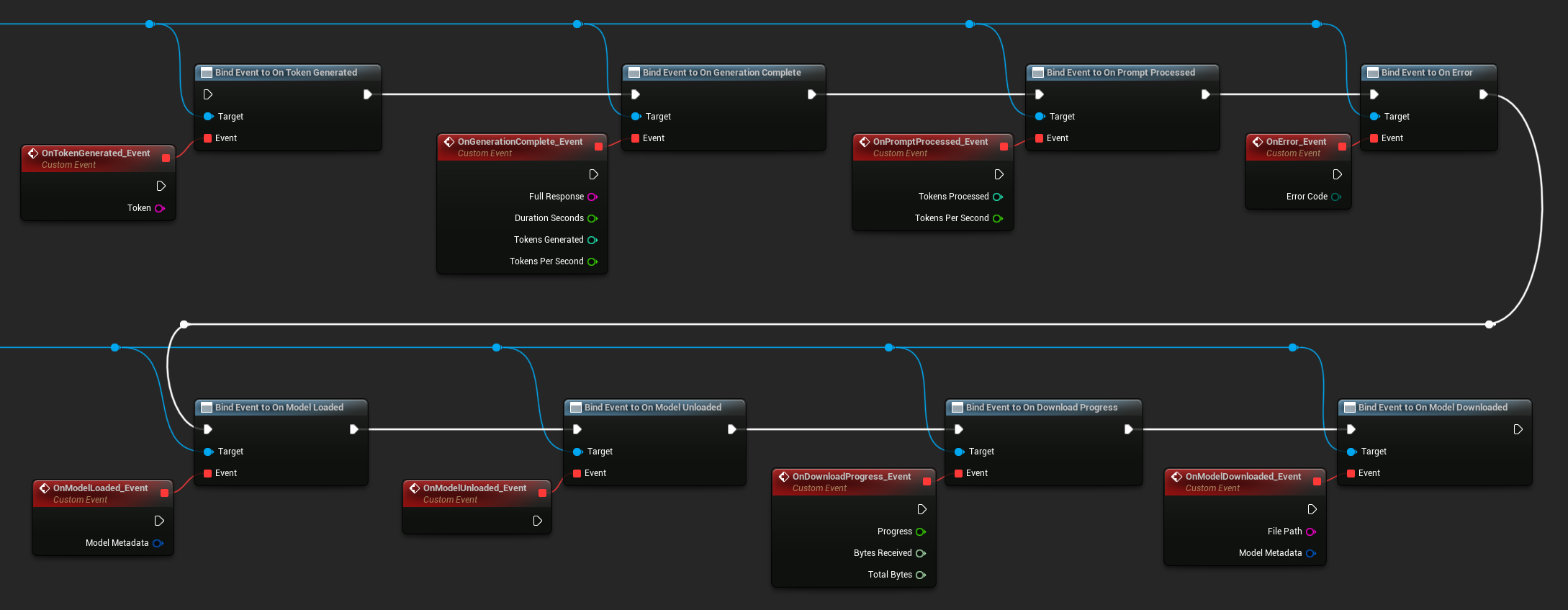
Доступные делегаты:
- При генерации токена: Срабатывает для каждого выходного токена
- При завершении генерации: Срабатывает, когда полный ответ готов, с указанием длительности, количества токенов и токенов в секунду
- При обработке подсказки: Срабатывает после обработки входной подсказки, до начала генерации
- При ошибке: Срабатывает, если во время любой операции произошла ошибка
- При загрузке модели: Срабатывает, когда модель завершает загрузку
- При выгрузке модели: Срабатывает, когда модель выгружается
- О прогрессе загрузки: Срабатывает периодически во время загрузки модели (доля прогресса, полученные байты, общее количество байт)
- При загрузке модели: Срабатывает, когда завершается операция только загрузки
- При сохранении разговора: Срабатывает, когда разговор был записан в JSON-файл
- При загрузке разговора: Срабатывает, когда разговор был загружен из файла или снимка памяти
- При суммировании истории: Срабатывает, когда автосуммирование сжимает старые сообщения (сообщает количество сообщений, сохранённые токены и сводку)
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda(
[](const FString& FullResponse, float DurationSeconds, int32 TokensGenerated, float TokensPerSecond)
{
});
LLM->OnPromptProcessedNative.AddLambda([](int32 TokensProcessed, float TokensPerSecond)
{
});
LLM->OnErrorNative.AddLambda([](ELLMErrorCode ErrorCode)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnModelUnloadedNative.AddLambda([]()
{
});
LLM->OnDownloadProgressNative.AddLambda([](float Progress, int64 BytesReceived, int64 TotalBytes)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& FilePath, const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnConversationSavedNative.AddLambda([](const FString& FilePath)
{
});
LLM->OnConversationLoadedNative.AddLambda([](const FLLMConversationSnapshot& Snapshot)
{
});
LLM->OnHistorySummarizedNative.AddLambda([](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
});
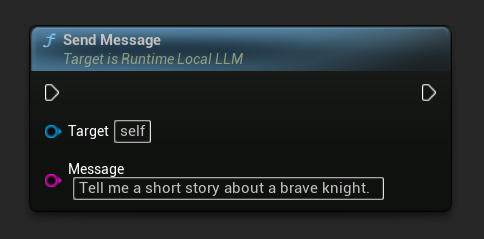
Отправить сообщения
После загрузки модели отправьте сообщение пользователя для генерации ответа:
- Blueprint
- C++
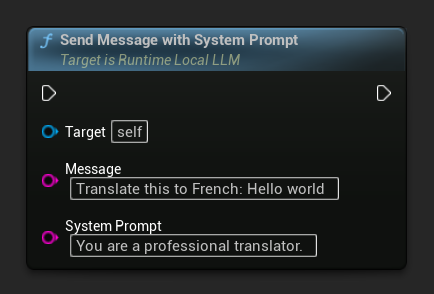
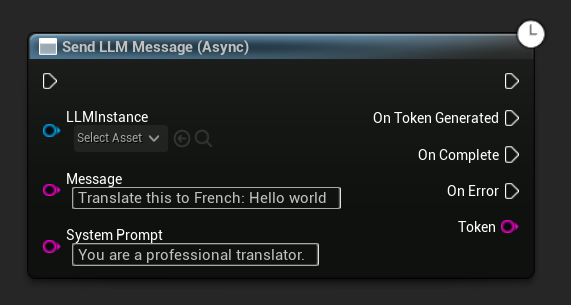
Чтобы переопределить системный промпт для конкретного сообщения, используйте Send Message With System Prompt:
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
Токены передаются через OnTokenGenerated по мере их генерации. Когда генерация завершается, срабатывает OnGenerationComplete, предоставляя полный ответ, длительность, количество токенов и токенов в секунду.
Асинхронная отправка сообщения (Blueprint)
Узел Send LLM Message (Async) предоставляет выделенные выходные контакты для токенов, завершения и ошибок:
Загрузка моделей во время выполнения
Помимо описанного выше потока загрузки и выгрузки, вы можете скачать модель на диск без её загрузки. Это полезно для предварительного кэширования моделей на экране загрузки или в меню настроек.
- Blueprint
- C++
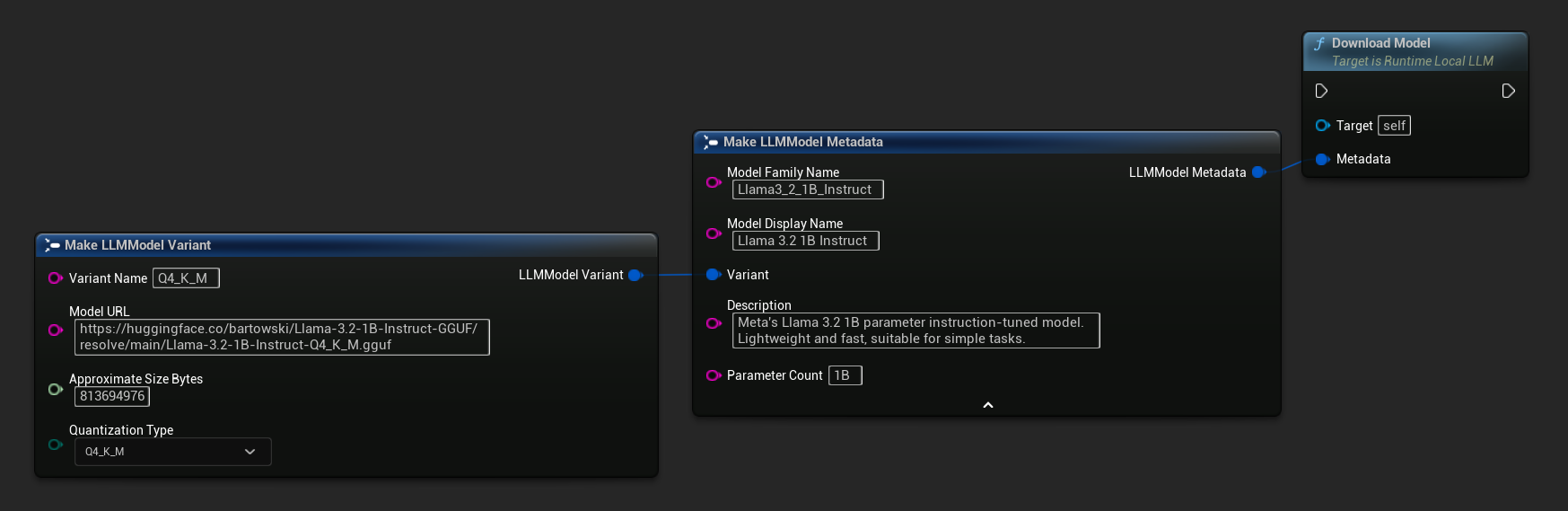
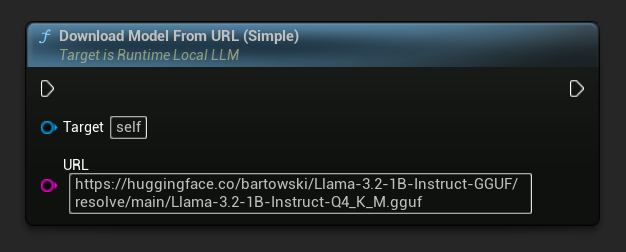
Доступен также вариант только с URL-адресом:
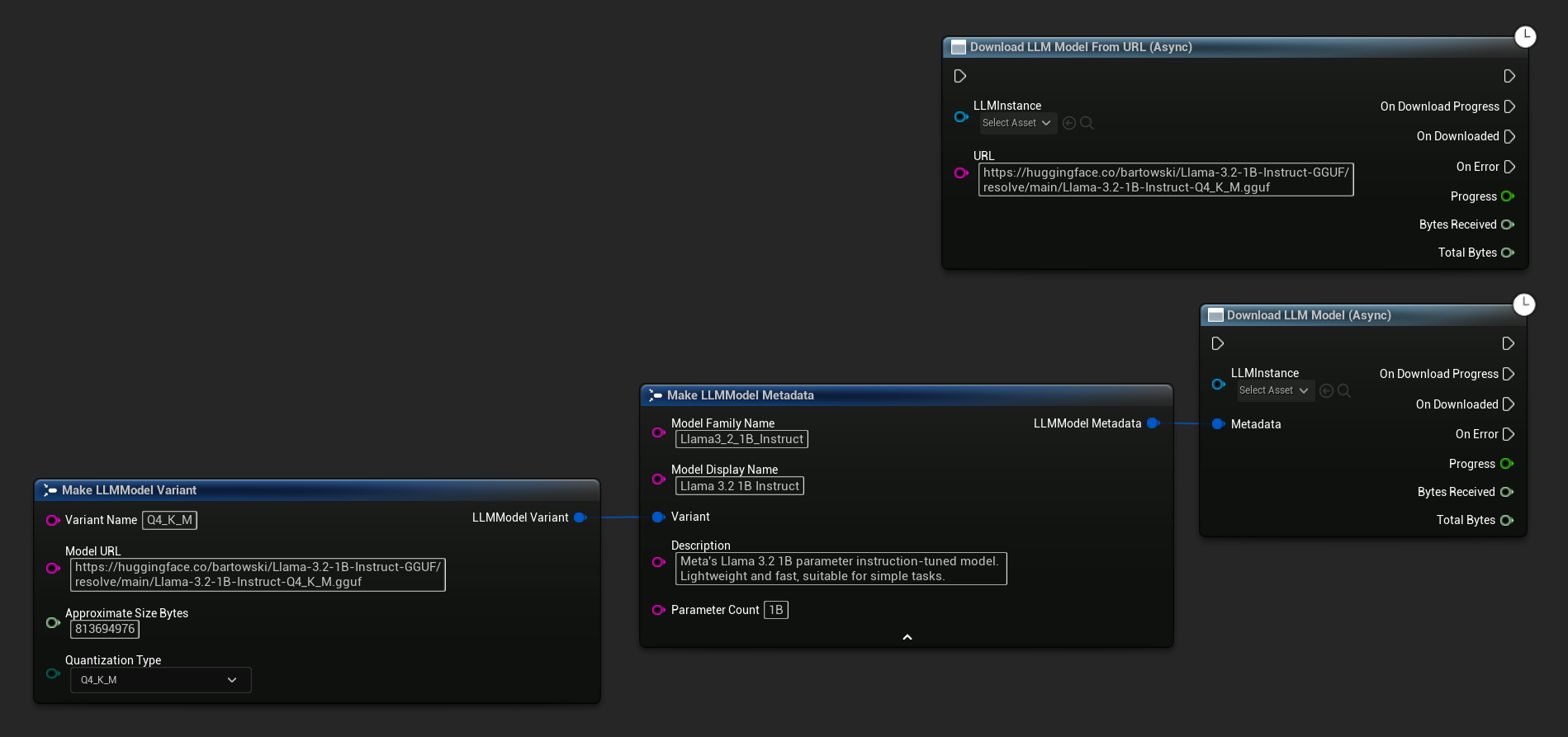
Узел Download LLM Model (Async) и Download LLM Model From URL (Async) предоставляют выходные контакты для отслеживания прогресса, завершения и ошибок:
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
Делегат OnDownloadProgress сообщает о ходе загрузки. OnModelDownloaded срабатывает, когда файл сохранен на диск.
Чтобы отменить текущую загрузку:
- Blueprint
- C++
LLM->CancelDownload();
Плагин автоматически предотвращает повторные загрузки: если загрузка одной и той же модели уже выполняется, последующие вызовы игнорируются.
Остановить генерацию
Чтобы прервать текущую генерацию:
- Blueprint
- C++
LLM->StopGeneration();
Сбросить контекст разговора
Очистите историю разговора, чтобы начать новый диалог:
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
Сохранение и загрузка разговоров
Плагин может сохранять историю разговора на диск в формате JSON или хранить её в памяти в виде снимка. По умолчанию системный промпт исключается из сохранений, поэтому одну и ту же историю разговора можно загружать в разные экземпляры LLM с различными системными правилами. Это полезно для сценариев с несколькими NPC, где каждый персонаж имеет свою собственную память, но может иметь общие или отличающиеся системные инструкции.
Сохранить в файл
Сохранить текущий разговор в JSON-файл на диск:
- Blueprint
- C++
Параметр Include System Prompt управляет тем, будет ли системное сообщение (если оно присутствует) записано в файл. По умолчанию установлено значение false для обеспечения переносимости между NPC.
On Conversation Saved срабатывает при записи файла.
// Excludes system prompt by default
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"));
// Include the system prompt in the file
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"), /*bIncludeSystemPrompt=*/ true);
Загрузить из файла
Загрузить разговор обратно из JSON-файла:
- Blueprint
- C++
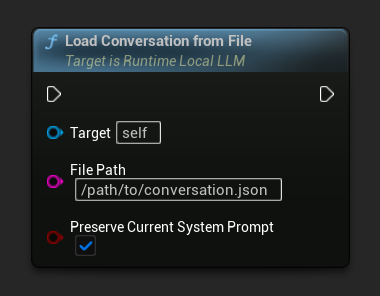
Параметр Preserve Current System Prompt (по умолчанию true) сохраняет текущий системный промпт без изменений при замене на сохранённую историю диалога. Это рекомендуемая настройка для замены памяти NPC.
On Conversation Loaded срабатывает с загруженным снимком.
// Keep current system prompt, swap in the saved history
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"));
// Replace the system prompt with whatever's in the file
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"), /*bPreserveCurrentSystemPrompt=*/ false);
In-Memory Snapshots (Multi-NPC Workflow)
Для быстрой смены NPC во время игры сохраняйте текущий разговор в памяти, а не записывайте на диск. Этот подход является рекомендуемым способом управления множеством NPC, использующих одну загруженную модель:
- Blueprint
- C++
Типичный шаблон для нескольких NPC использует Карту Имя → Снимок LLM-диалога в вашем менеджере NPC или состоянии игры:
- При переключении с NPC: вызовите
Save Conversation To Memory, затем вOn Conversation Loaded(который также срабатывает при доставке снимка) сохраните снимок в вашей карте, используя имя NPC в качестве ключа. - При переключении на другого NPC: прочитайте снимок из вашей карты и вызовите
Load Conversation From Memoryс включенной опциейPreserve Current System Prompt.

Поскольку системный промпт остается загруженным при переключении, «личность» каждого NPC может быть либо закодирована в индивидуальном системном промпте (вызовите Send Message With System Prompt один раз после переключения, чтобы обновить его), либо быть общей для всех NPC.
// Maintain per-NPC snapshots
UPROPERTY()
TMap<FName, FLLMConversationSnapshot> NPCMemories;
// Save the currently active NPC's memory before switching
LLM->OnConversationLoadedNative.AddLambda([this](const FLLMConversationSnapshot& Snapshot)
{
NPCMemories.Add(CurrentNPC, Snapshot);
});
LLM->SaveConversationToMemory();
// Activate another NPC's memory
if (const FLLMConversationSnapshot* Found = NPCMemories.Find(NextNPC))
{
LLM->LoadConversationFromMemory(*Found, /*bPreserveCurrentSystemPrompt=*/ true);
CurrentNPC = NextNPC;
}
Снимки не зависят от модели — они хранят сообщения, а не состояние KV-кэша. Один и тот же снимок можно загрузить в другую модель (хотя стиль разговора может измениться). Поле OriginModelFamilyName в снимке позволяет проверить, какая модель его создала, если вы хотите обеспечить совместимость.
Автоматическое обобщение контекста
Длинные разговоры со временем превышают окно контекста модели, что обычно приводит либо к усечению истории, либо к ошибкам. Функция автоматического суммаризирования плагина отслеживает использование контекста и, когда превышается заданный порог, обобщает старые сообщения в одно «памятное» сообщение перед генерацией следующего ответа. Это позволяет поддерживать стабильные затраты токенов и задержку в разговорах любой продолжительности.
Суммирование выполняется той же загруженной моделью, поэтому второй модели или вызова API не требуется.
Включить авто-суммирование
- Blueprint
- C++
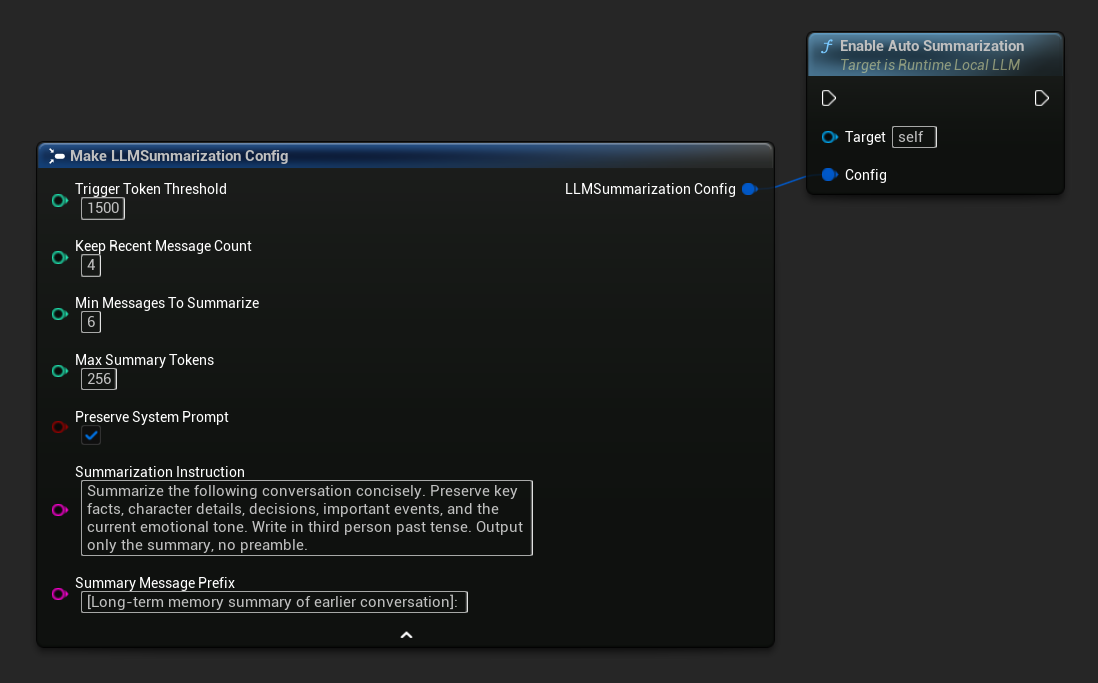
Используйте Get Default Summarization Config для разумных начальных значений по умолчанию, затем настройте по необходимости:
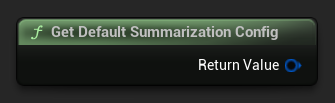
FLLMSummarizationConfig Config = URuntimeLocalLLM::GetDefaultSummarizationConfig();
Config.TriggerTokenThreshold = 1500;
Config.KeepRecentMessageCount = 4;
Config.MinMessagesToSummarize = 6;
LLM->EnableAutoSummarization(Config);
После включения суммаризация запускается автоматически перед каждым вызовом SendMessage при необходимости, никаких дополнительных действий не требуется.
По умолчанию автосуммирование выполняется перед обработкой нового сообщения, так как ему необходимо перестроить контекст, что нельзя безопасно делать одновременно с генерацией ответа. Если вы предпочитаете, чтобы оно выполнялось после ответа, пока игрок читает и печатает, отключите автосуммирование и управляйте им вручную: привяжитесь к On Generation Complete, проверьте Get Used Context Length на соответствие вашему порогу и вызовите Summarize Now, если он превышен. Поскольку Summarize Now ставится в очередь в том же фоновом потоке задач, он выполнится сразу после завершения ответа и до обработки следующего сообщения.
Справочник по конфигурации
| Параметр | Type | По умолчанию | Описание |
|---|---|---|---|
| Порог триггерного токена | int32 | 1500 | Суммирование запускается, когда количество используемых токенов контекста превышает это значение. Установите его относительно вашего Context Size; хорошим эмпирическим правилом является значение около 60–75%. |
| Количество последних сообщений для сохранения | int32 | 4 | Последние N сообщений никогда не суммируются, сохраняя непосредственную связность диалога. |
| Минимальное количество сообщений для суммаризации | int32 | 6 | Пропускать суммаризацию, если доступно меньше этого количества старых сообщений (чтобы избежать бессмысленных крошечных суммаризаций). |
| Максимальное количество токенов в сводке | int32 | 256 | Максимальная длина сгенерированного резюме в токенах |
| Сохранить системную подсказку | bool | true | Всегда сохраняйте системное сообщение (индекс 0) без изменений |
| Инструкция по суммаризации | FString | (see default) | Инструкция, отправленная модели для создания сводки |
| Префикс сообщения сводки | FString | "[Краткое содержание долговременной памяти предыдущего разговора]: " | Добавляется к сгенерированной сводке при её вставке в диалог в качестве сообщения памяти с ролью ассистента. |
Ручной триггер и прослушивание для получения сводок
Вы можете вручную запустить суммаризацию в любой момент, независимо от порога.
- Blueprint
- C++
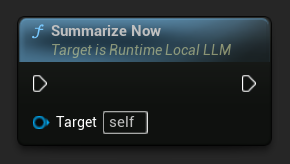
Привяжитесь к On History Summarized, чтобы получать уведомление о завершении прохода суммаризации. Событие сообщает, сколько сообщений было удалено, сколько токенов сохранено и сгенерированный текст сводки, что полезно для отображения ненавязчивого индикатора в интерфейсе чата.
LLM->SummarizeNow();
LLM->OnHistorySummarizedNative.AddLambda(
[](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
UE_LOG(LogTemp, Log, TEXT("Summarized %d messages, saved %d tokens"), MessagesRemoved, TokensSaved);
});
Запрос используемой длины контекста
Используйте Get Used Context Length, чтобы проверить, сколько токенов в данный момент занято в контекстном окне модели. Это то же значение, с которым сверяется встроенный триггер автоматического суммаризирования по параметру Trigger Token Threshold.
- Blueprint
- C++
LLM->GetUsedContextLengthNative([](int32 UsedTokens)
{
UE_LOG(LogTemp, Log, TEXT("Used context: %d tokens"), UsedTokens);
});
Отключить автоматическое обобщение
- Blueprint
- C++
LLM->DisableAutoSummarization();
Отключение не отменяет уже примененные к беседе сводки.
Суммирование выполняется в фоновом потоке (модель генерирует краткое содержание). Обратные вызовы токенового потока подавляются во время этой внутренней генерации, поэтому они не будут отображаться в вашем интерфейсе чата. On History Summarized срабатывает после завершения сращивания.
Выгрузить модель
Освобождение ресурсов, когда модель больше не нужна:
- Blueprint
- C++
LLM->UnloadModel();
Состояние запроса
Проверьте текущее состояние экземпляра LLM:
- Blueprint
- C++
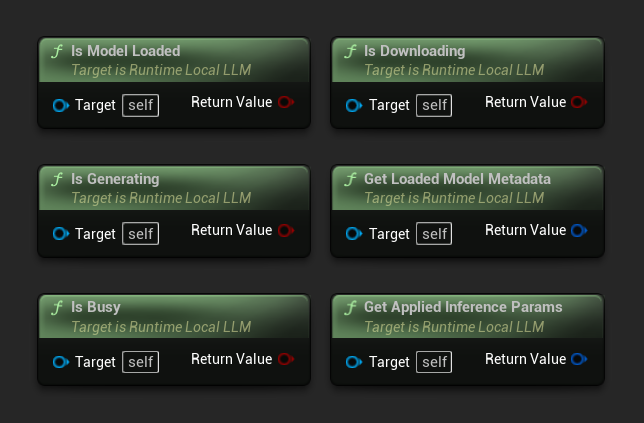
- Модель загружена: True, если модель готова к инференсу
- Идет генерация: True, если генерация выполняется
- Занято: True, если выполняется любая операция (загрузка, генерация, скачивание)
- Идет скачивание: True, если выполняется скачивание модели
- Получить метаданные загруженной модели: Возвращает метаданные текущей модели
- Получить примененные параметры инференса: Возвращает параметры, примененные при загрузке
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
Функции библиотеки моделей
Предоставляется набор статических служебных функций для управления файлами моделей на диске. Они полезны для создания пользовательского интерфейса выбора модели или проверки доступности модели во время выполнения.
Получить названия загруженных моделей / метаданные
- Blueprint
- C++
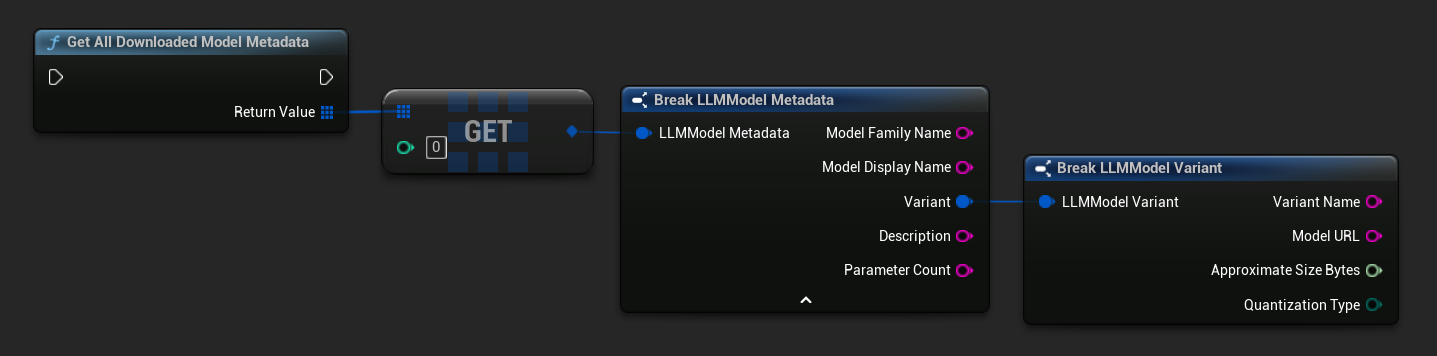
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
Проверить, есть ли модель на диске
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
Получить путь к файлу модели
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
Удалить файлы модели
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
Получить предопределенные и доступные модели
- Blueprint
- C++
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
Создание метаданных из URL
Создать метаданные модели из необработанного URL (поля извлекаются из имени файла):
- Blueprint
- C++
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
Вспомогательные функции
Предоставляется набор вспомогательных функций для форматирования и отображения ошибок.
Байты в читаемую строку
Преобразует количество байт в удобочитаемую строку (например, "4.07 ГБ"). Полезно для отображения размеров моделей в интерфейсе.
Формат загрузки прогресса
Форматирует строку прогресса загрузки, например "1.23 ГБ / 4.07 ГБ (30.2%)". Если общий размер неизвестен, возвращает только полученный объём.
Получить описание ошибки / строку кода ошибки
Get LLM Error Description возвращает читаемое текстовое описание для кода ошибки. Get LLM Error Code String возвращает имя значения перечисления в виде строки (полезно для логирования).
Справочник кодов ошибок
| Code | Ценность | Описание |
|---|---|---|
| Неизвестно | 0 | Неопределенная ошибка |
| ModelLoadFailed | 10 | Файл GGUF не удалось загрузить (повреждённый файл, несовместимый формат и т. д.). |
| ContextCreateFailed | 11 | Не удалось создать контекст вывода |
| ModelNotLoaded | 20 | Попытка вывода была предпринята без загруженной модели. |
| ChatTemplateFailed | 21 | Не удалось применить шаблон чата модели. |
| TokenizationFailed | 22 | Текст не удалось токенизировать. |
| ContextOverflow | 23 | Подсказка + контекст превышает настроенный размер контекста. |
| PromptDecodeFailed | 24 | Не удалось декодировать токены подсказки. |
| ContextTooFullToGenerate | 25 | Недостаточно оставшегося контекстного пространства для генерации вывода |
| GenerationDecodeFailed | 30 | Во время генерации не удалось декодировать токен |
| GenerationTruncated | 31 | Генерация остановлена, так как был достигнут лимит максимального количества токенов. |
| LLMInstanceNull | 40 | Экземпляр LLM равен null или недействителен. |
| ModelNotFoundOnDisk | 41 | Модельный файл не существует по ожидаемому пути |
| ModelURLEmpty | 42 | Был запрошен загрузка с пустым URL. |
| ModelDownloadCancelled | 43 | Загрузка была отменена. |
| ModelDownloadEmptyData | 44 | Загрузка завершена, но тело ответа было пустым. |
| ModelDownloadSaveFailed | 45 | Загрузка завершена, но файл не удалось сохранить на диск. |