Параметры вывода
Структура параметров вывода LLM управляет тем, как модель загружается и генерирует текст. Вы передаёте эти параметры при загрузке модели. На этой странице описан каждый параметр и его действие.
Справочник параметров
| Параметр | Type | По умолчанию | Диапазон | Описание |
|---|---|---|---|---|
| Макс. токенов | int32 | 512 | 1–8192 | Максимальное количество токенов для генерации в одном ответе |
| Температура | плавать | 0.7 | 0.0–2.0 | Управляет случайностью. 0.0 = детерминированный результат. Более высокие значения = более творческий вывод. |
| Top P | плавать | 0.9 | 0.0–1.0 | Ядерная выборка. Рассматриваются только те токены, чья совокупная вероятность превышает это значение. |
| Top K | int32 | 40 | 0–200 | Ограничивает выбор K наиболее вероятными токенами. 0 = отключено. |
| Штраф за повторение | плавать | 1.1 | 0.0–3.0 | Штрафует токены, которые уже появились в выводе. 1.0 = без штрафа |
| Количество слоев GPU | int32 | -1 | -1–200 | Слои модели для выгрузки на GPU. -1 = авто. 0 = только CPU. |
| Размер контекста | int32 | 2048 | 128–131072 | Максимальный размер контекстного окна в токенах. Большие значения потребляют больше памяти. |
| Системный промпт | FString | «Вы — полезный помощник.» | — | Системная инструкция, определяющая поведение модели |
| Seed | int32 | -1 | -1+ | Случайное начальное значение для воспроизводимого результата. -1 = случайно. |
| Количество потоков | int32 | 0 | 0–128 | Потоки ЦП для генерации. 0 = автоматически. |
Использование
- Blueprint
- C++
Параметры инференса отображаются в виде структурного пина на узлах загрузки и асинхронных узлах. Разбейте структуру, чтобы задать отдельные значения.
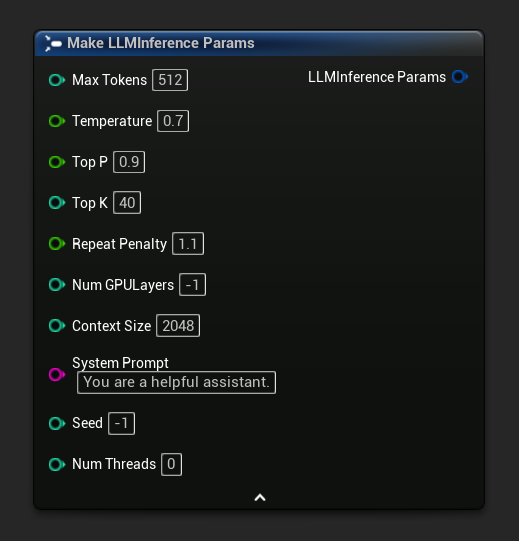
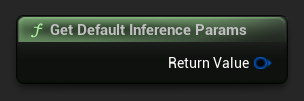
Чтобы получить стандартный набор параметров в качестве отправной точки, используйте Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Рекомендации по платформам
Мобильные устройства / VR (Android, iOS, Meta Quest)
- Размер контекста: 1024–2048
- Количество слоев GPU: 0 (только CPU), если только устройство не имеет подтвержденной поддержки GPU-вычислений
- Максимальное количество токенов: менее 256 для отзывчивого взаимодействия
- Количество потоков: 2–4 в зависимости от устройства
Настольные ПК (Windows, Mac, Linux)
- Размер контекста: 2048–8192 для большинства диалогов
- Количество слоёв GPU: -1 (авто) для использования ускорения GPU, если доступно
- Количество потоков: 0 (авто)
- Максимум токенов: 512–2048 для более длинных ответов
Длительные разговоры
Если ваше приложение поддерживает длительные диалоги (диалоги NPC, постоянные ассистенты, ролевые игры), рассмотрите возможность сочетания размера контекста с автоматическим обобщением, а не просто увеличения Context Size. Скромный Context Size в 2048–4096 с включенным автообобщением обеспечивает стабильную задержку и использование памяти, тогда как более широкие окна контекста делают каждую генерацию постепенно медленнее. См. Автоматическое обобщение контекста.