Руководство по обработке аудио
Это руководство описывает, как настроить различные методы ввода аудио для передачи аудиоданных вашим генераторам синхронизации губ. Убедитесь, что вы завершили Руководство по настройке перед продолжением.
Обработка аудиовхода
Вам необходимо настроить метод обработки аудиовхода. Существует несколько способов сделать это в зависимости от вашего источника аудио.
- Микрофон (в реальном времени)
- Микрофон (воспроизведение)
- Текст-в-речь (локальный)
- Текст-в-речь (внешние API)
- Из аудиофайла/буфера
- Буфер потокового аудио
Этот подход выполняет синхронизацию губ в реальном времени во время разговора в микрофон:
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Создайте Capturable Sound Wave с помощью Runtime Audio Importer
- Для Linux с Pixel Streaming используйте Pixel Streaming Capturable Sound Wave вместо
- Перед началом захвата аудио привяжитесь к делегату
OnPopulateAudioData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator - Начните захват аудио с микрофона
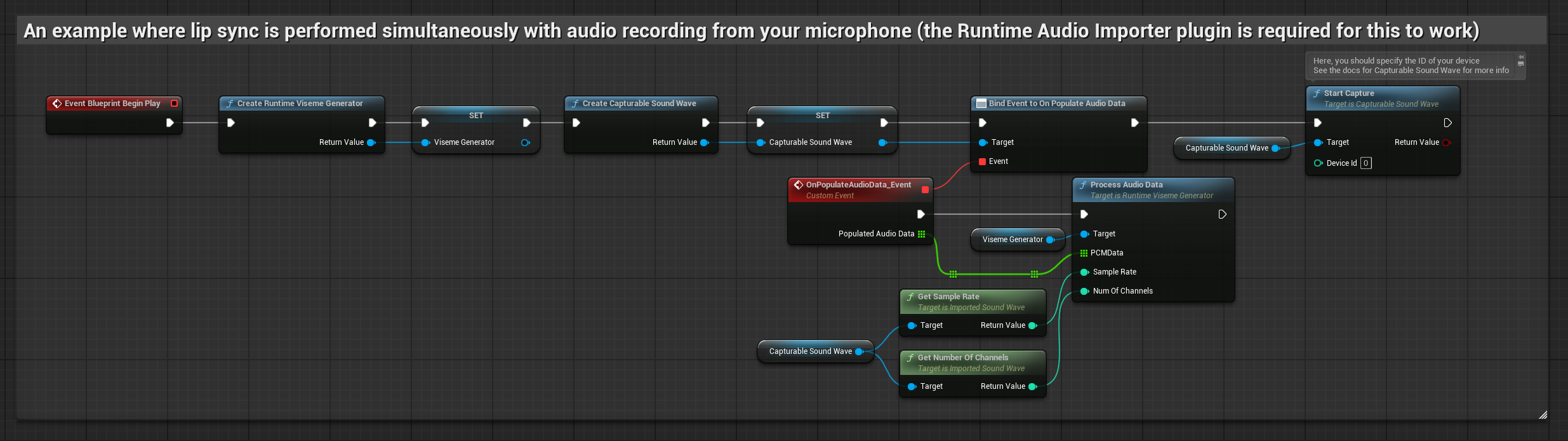
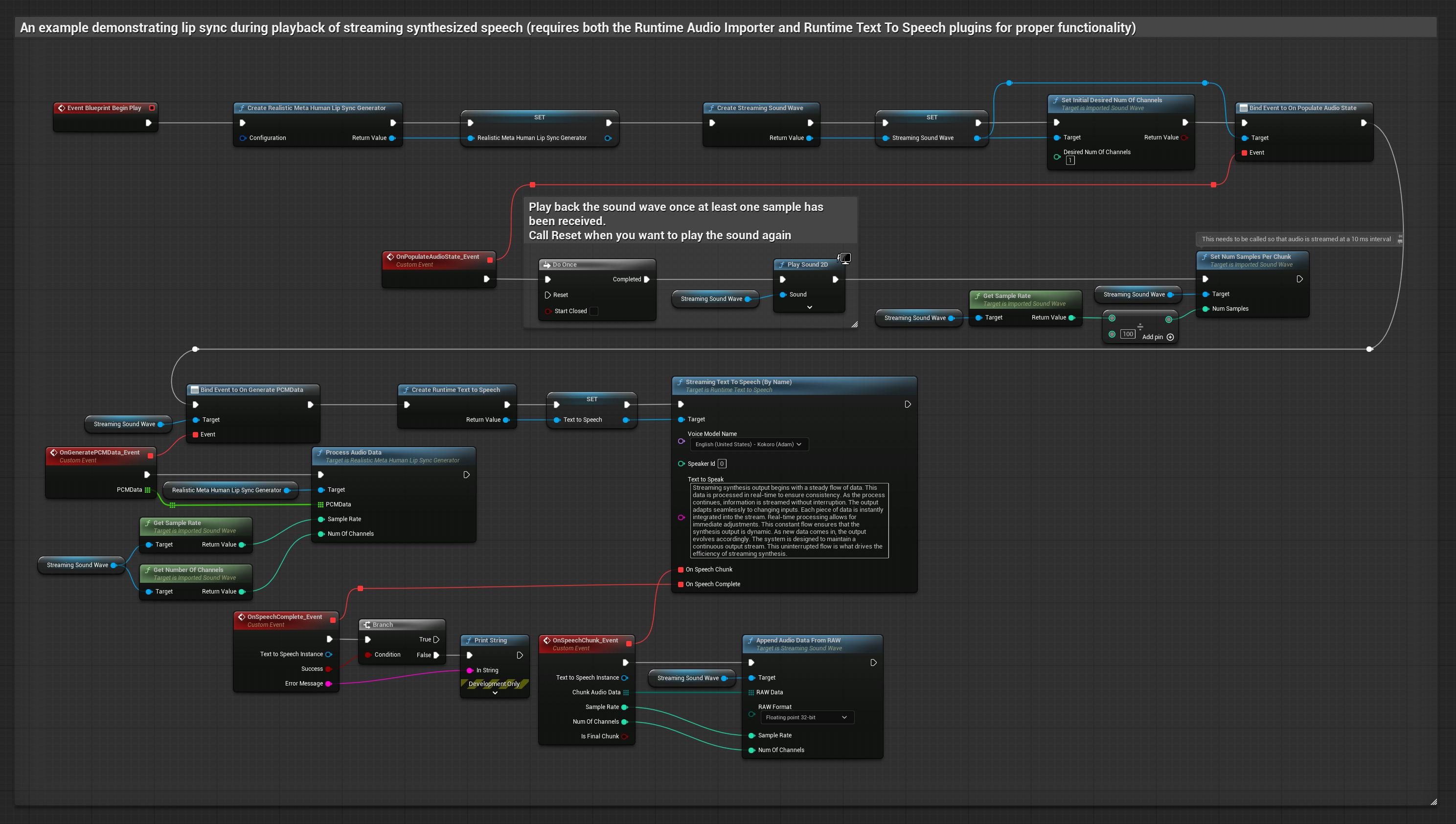
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
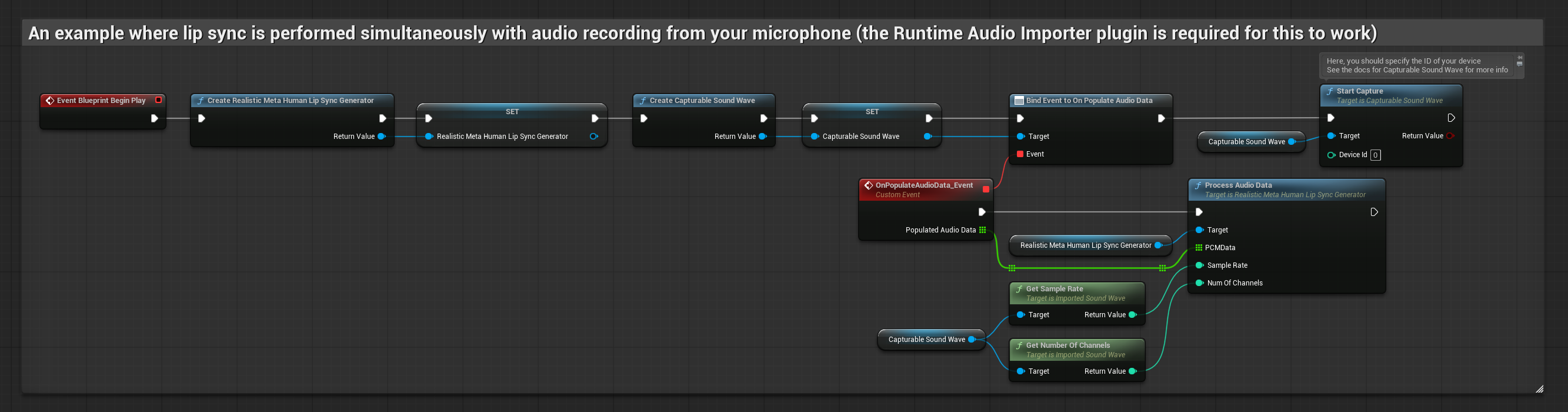
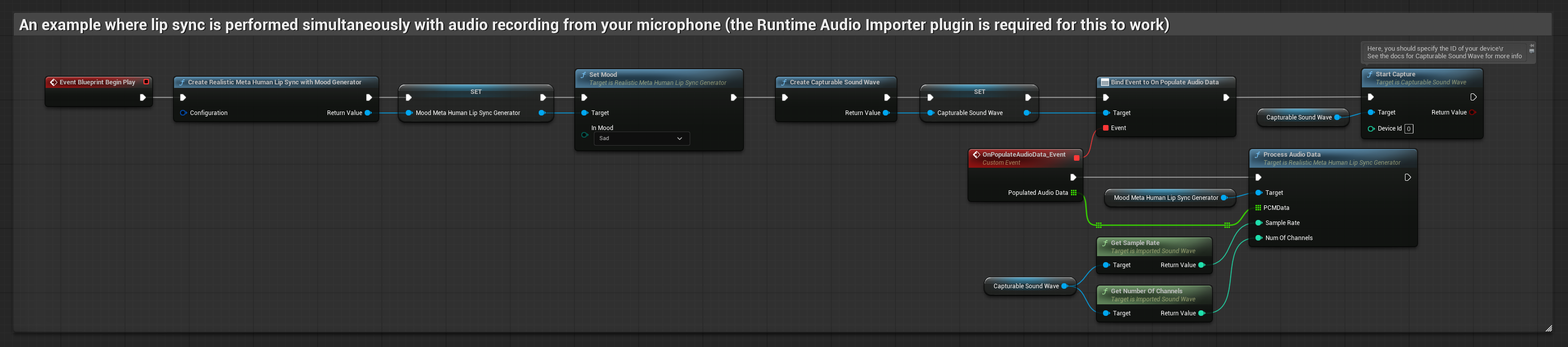
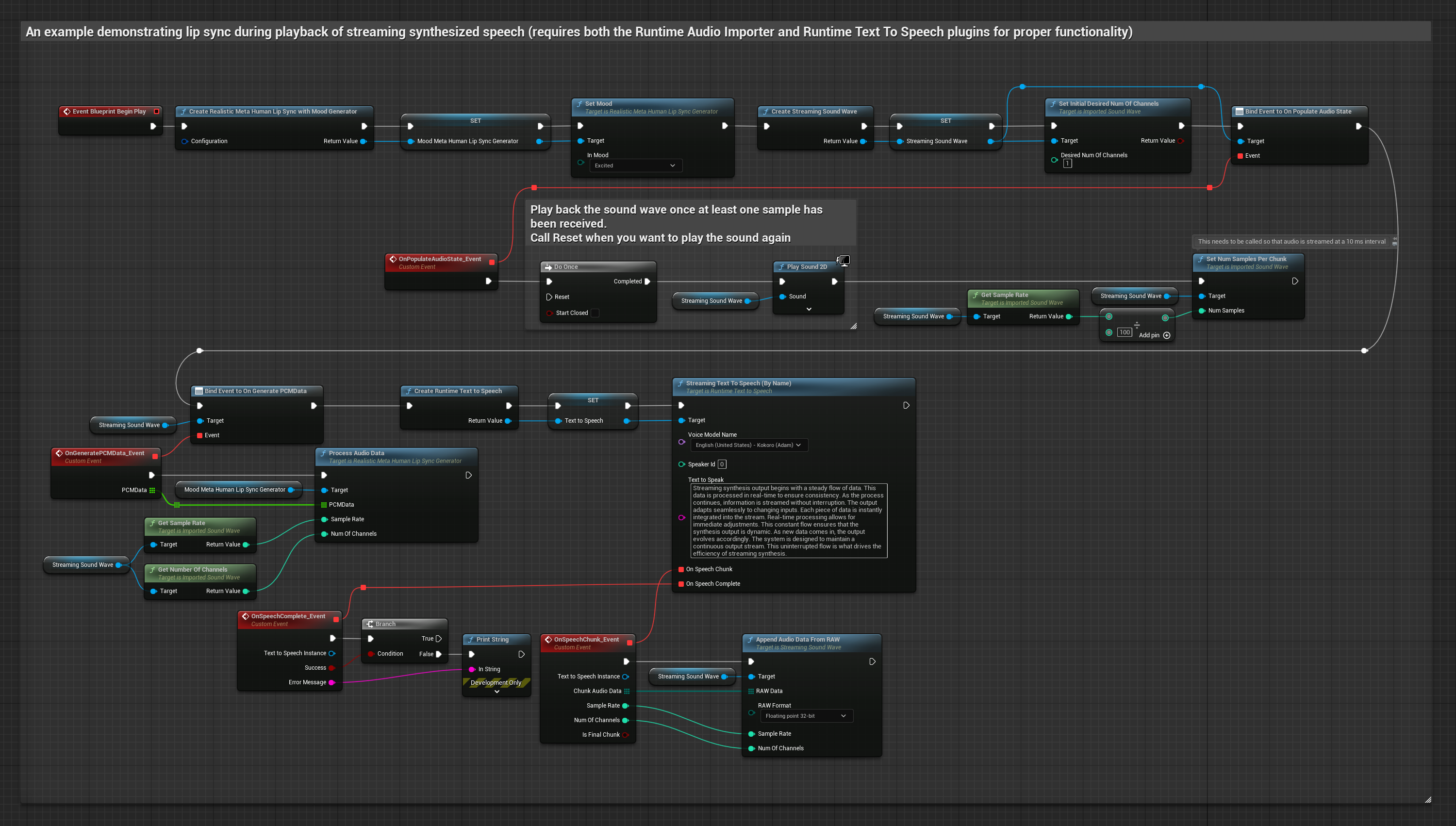
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
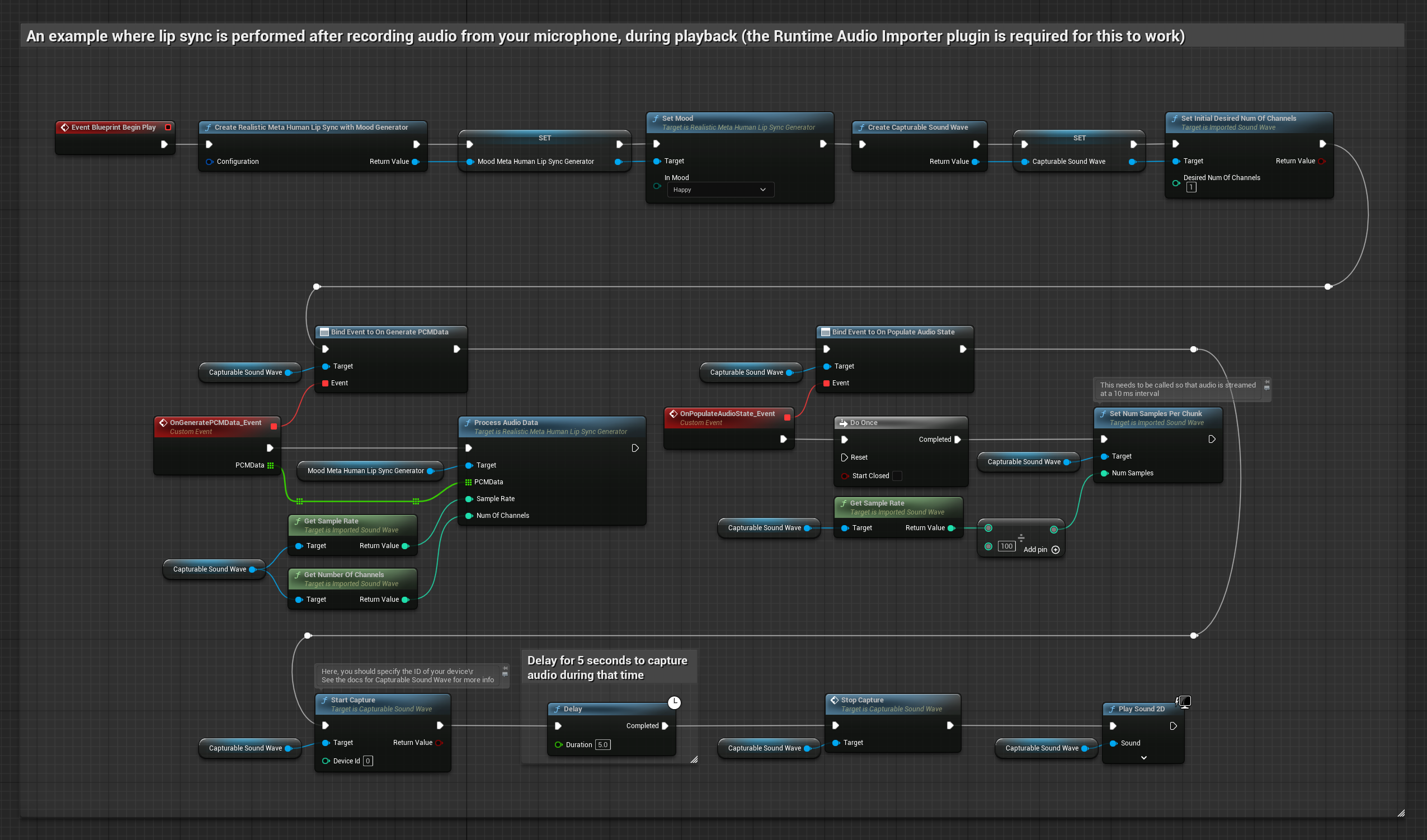
Этот подход захватывает аудио с микрофона, а затем воспроизводит его с синхронизацией губ:
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Создайте Capturable Sound Wave с помощью Runtime Audio Importer
- Для Linux с Pixel Streaming используйте Pixel Streaming Capturable Sound Wave вместо
- Начать захват аудио с микрофона
- Перед воспроизведением захватываемой звуковой волны привяжитесь к её делегату
OnGeneratePCMData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator
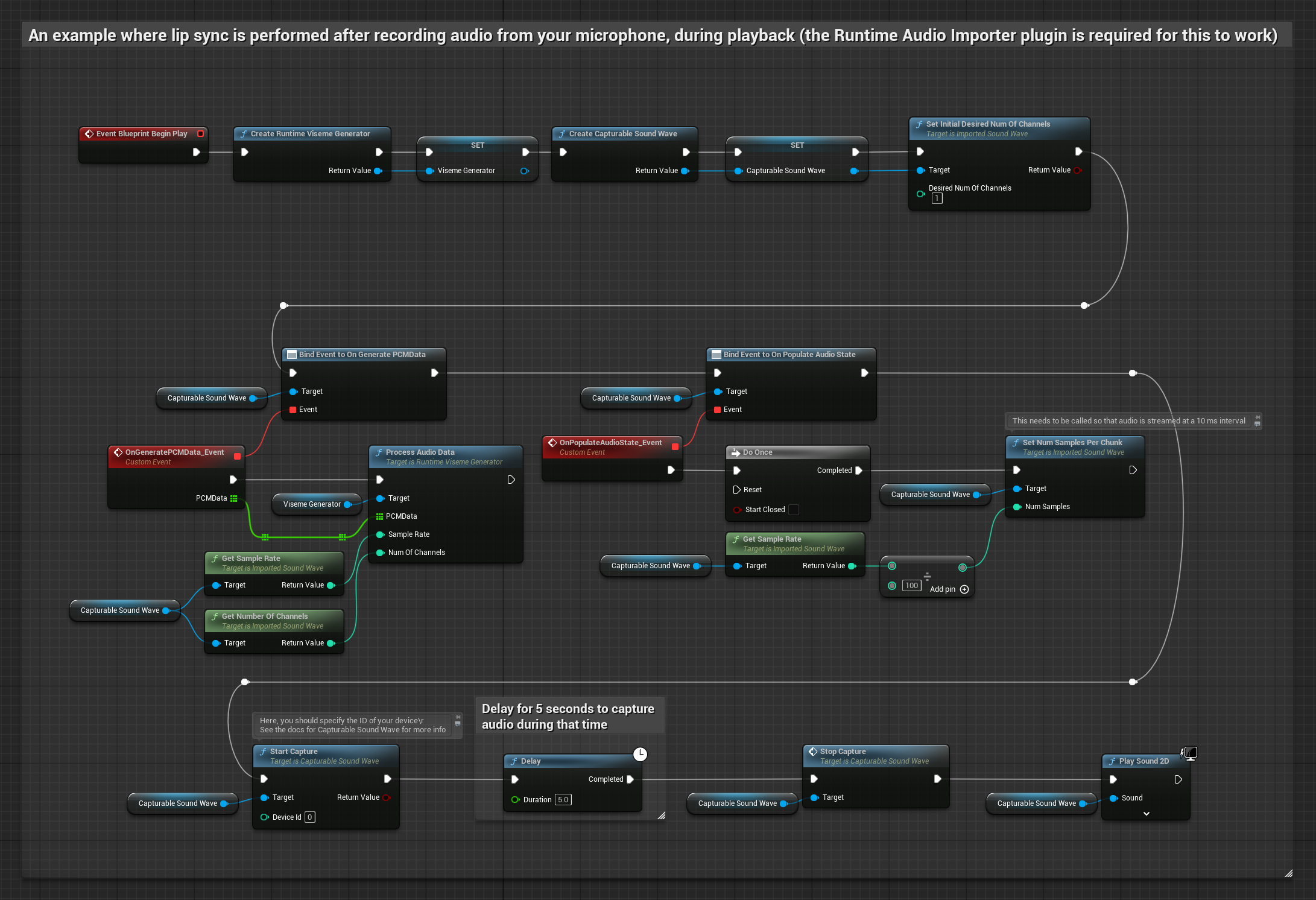
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
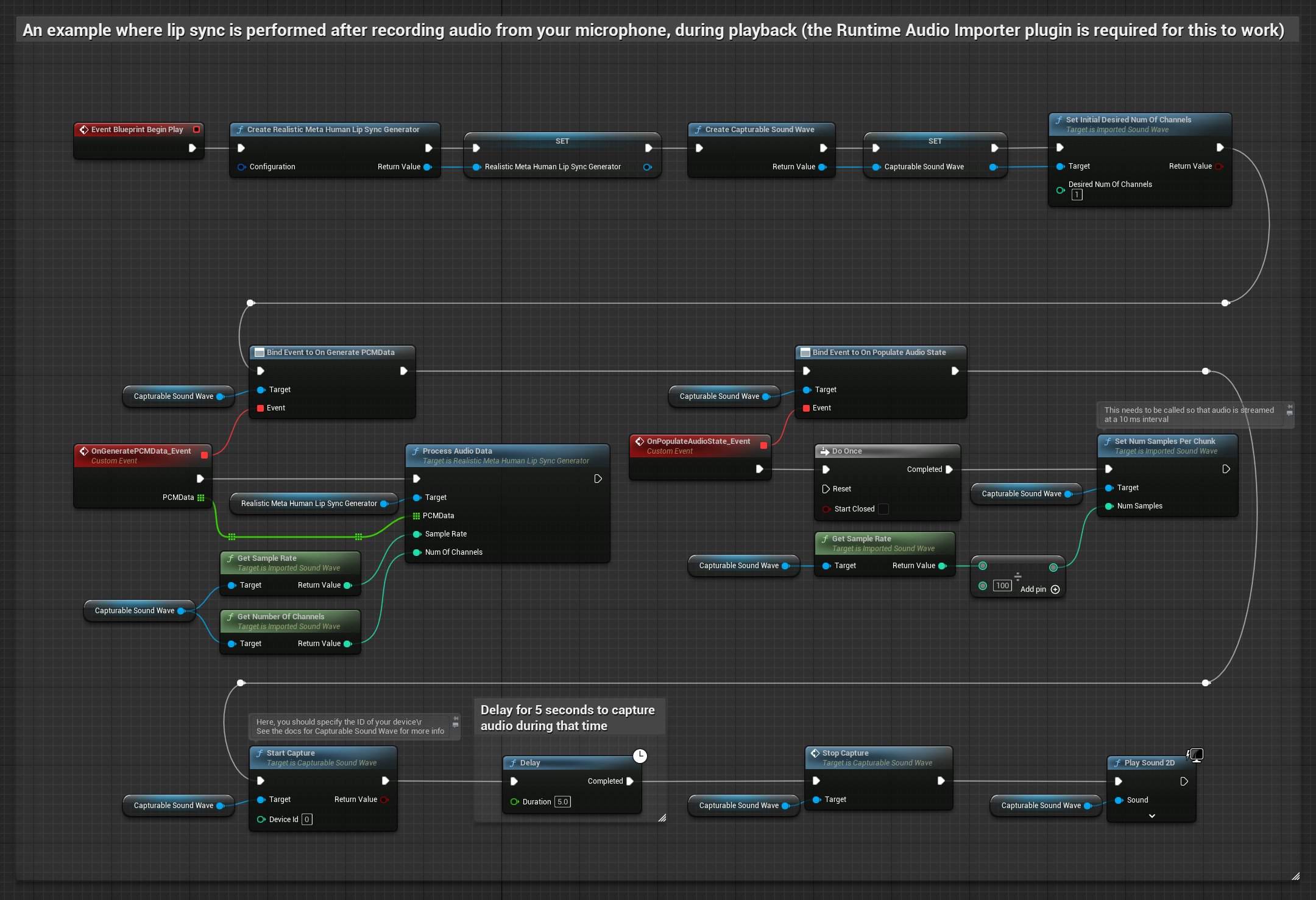
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
- Обычный
- Стриминг
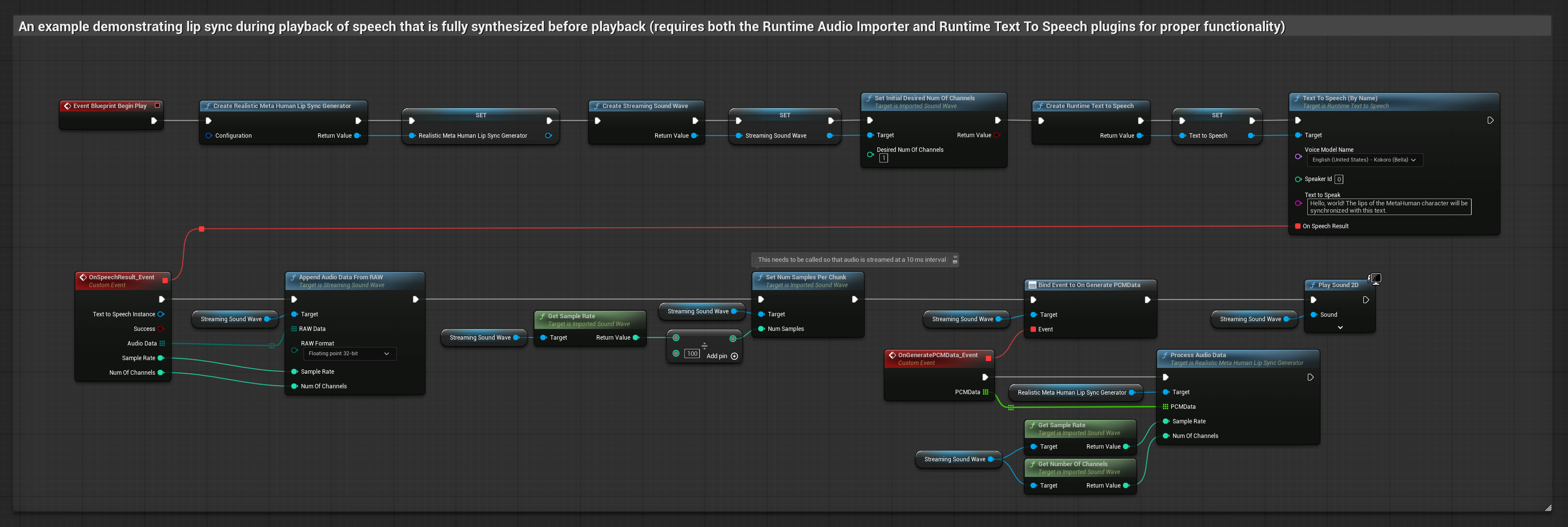
Этот подход синтезирует речь из текста с помощью локального TTS и выполняет синхронизацию губ.
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Используйте Runtime Text To Speech для генерации речи из текста
- Используйте Runtime Audio Importer для импорта синтезированного аудио
- Перед воспроизведением импортированной звуковой волны привяжитесь к её делегату
OnGeneratePCMData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator
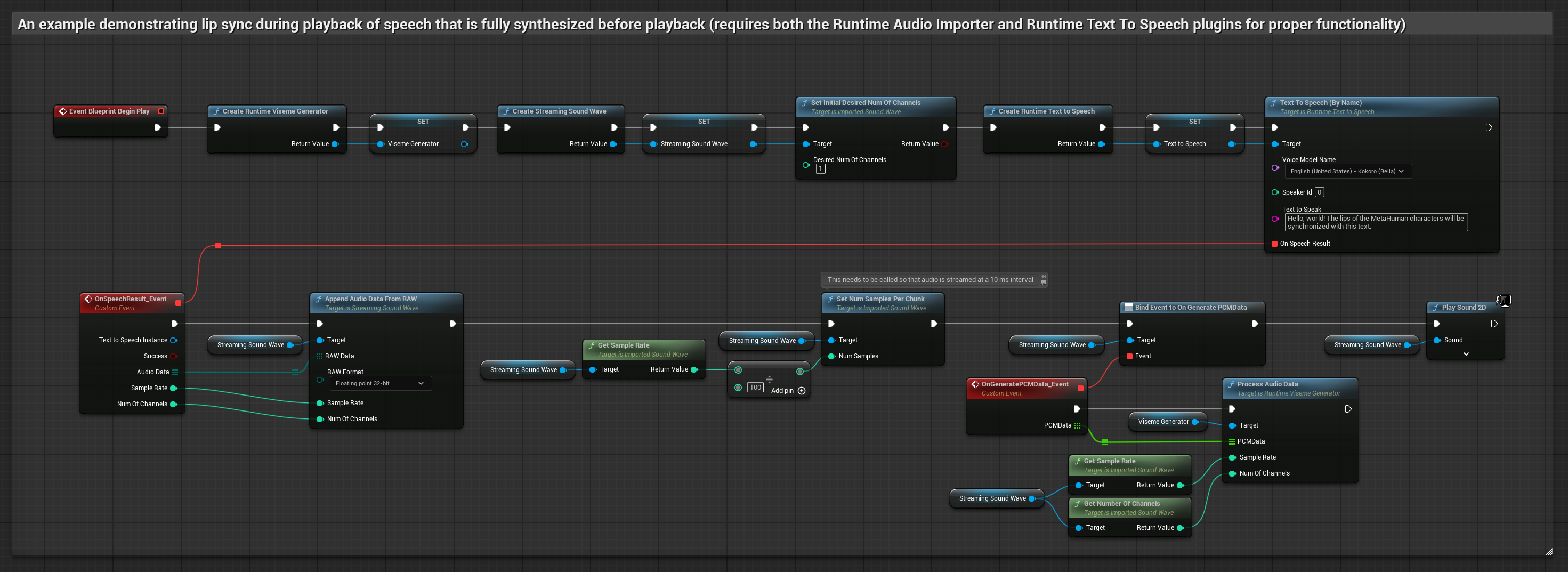
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
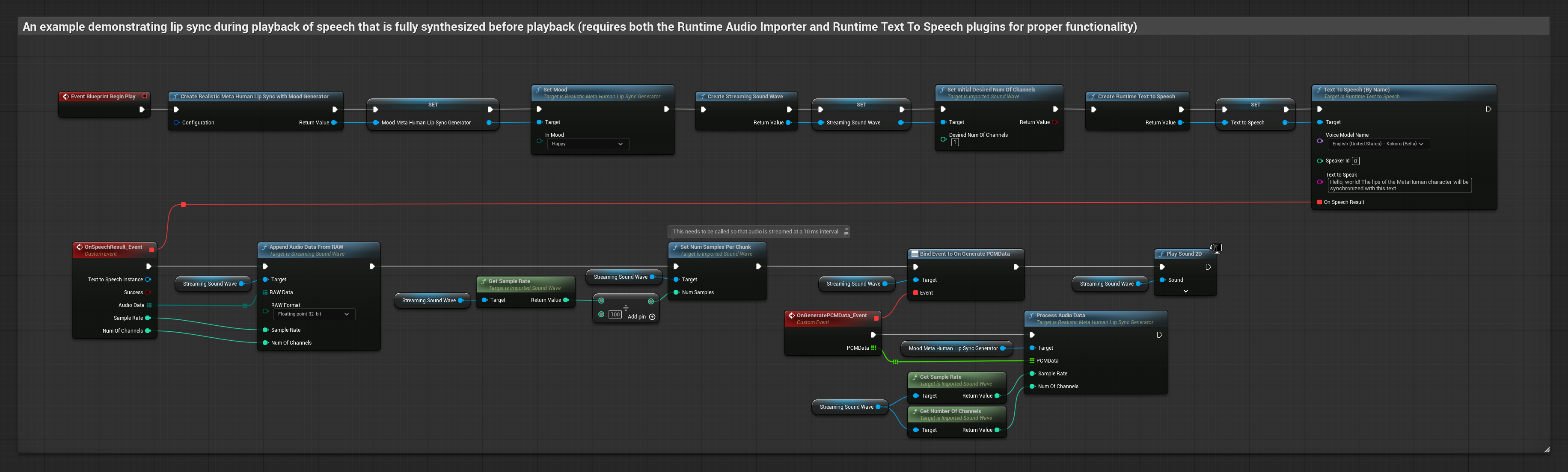
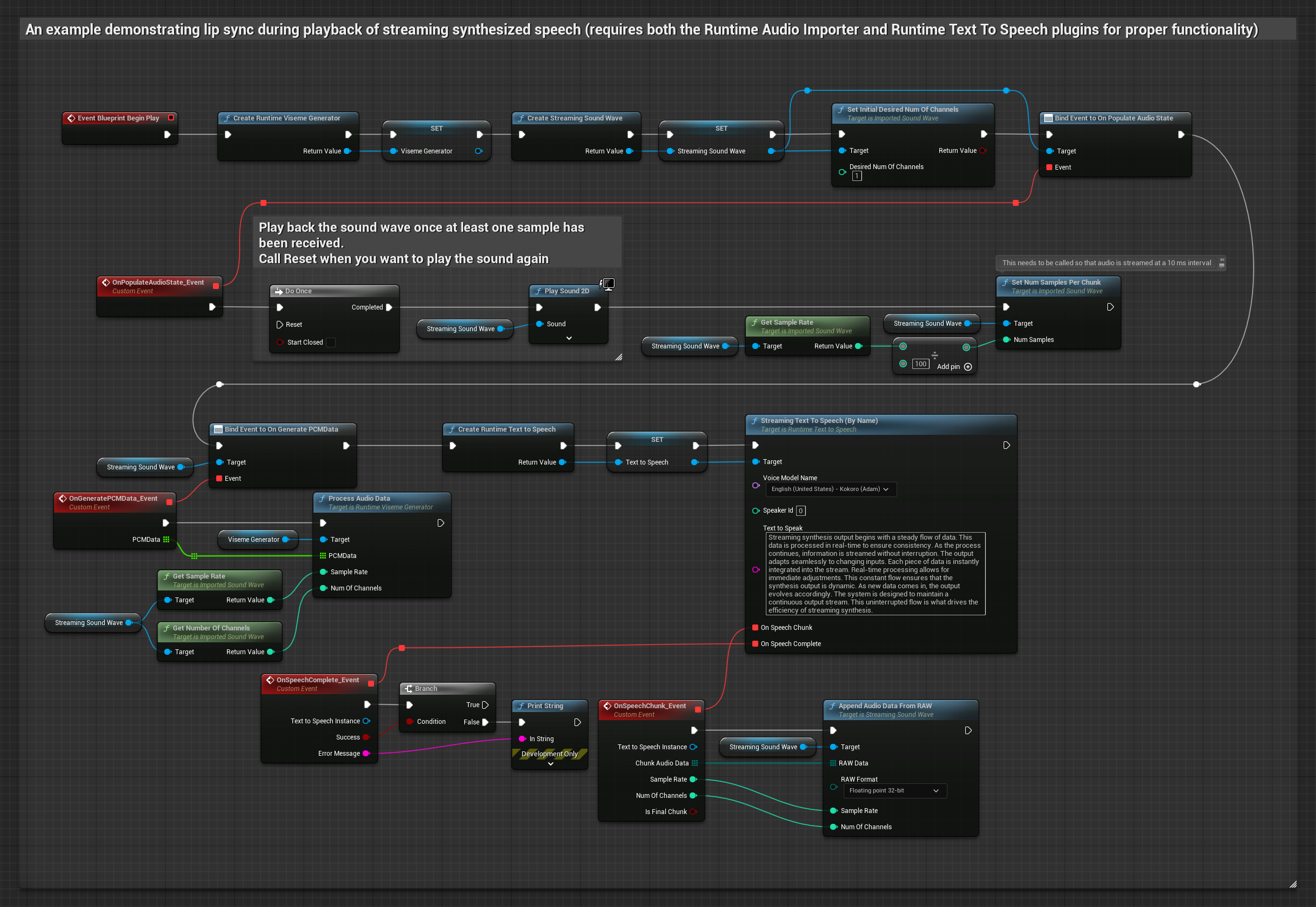
Этот подход использует потоковый синтез речи в текст с синхронизацией губ в реальном времени.
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Используйте Runtime Text To Speech для генерации потоковой речи из текста
- Используйте Runtime Audio Importer для импорта синтезированного аудио
- Перед воспроизведением потоковой звуковой волны привяжитесь к её делегату
OnGeneratePCMData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
- Обычный
- Стриминг
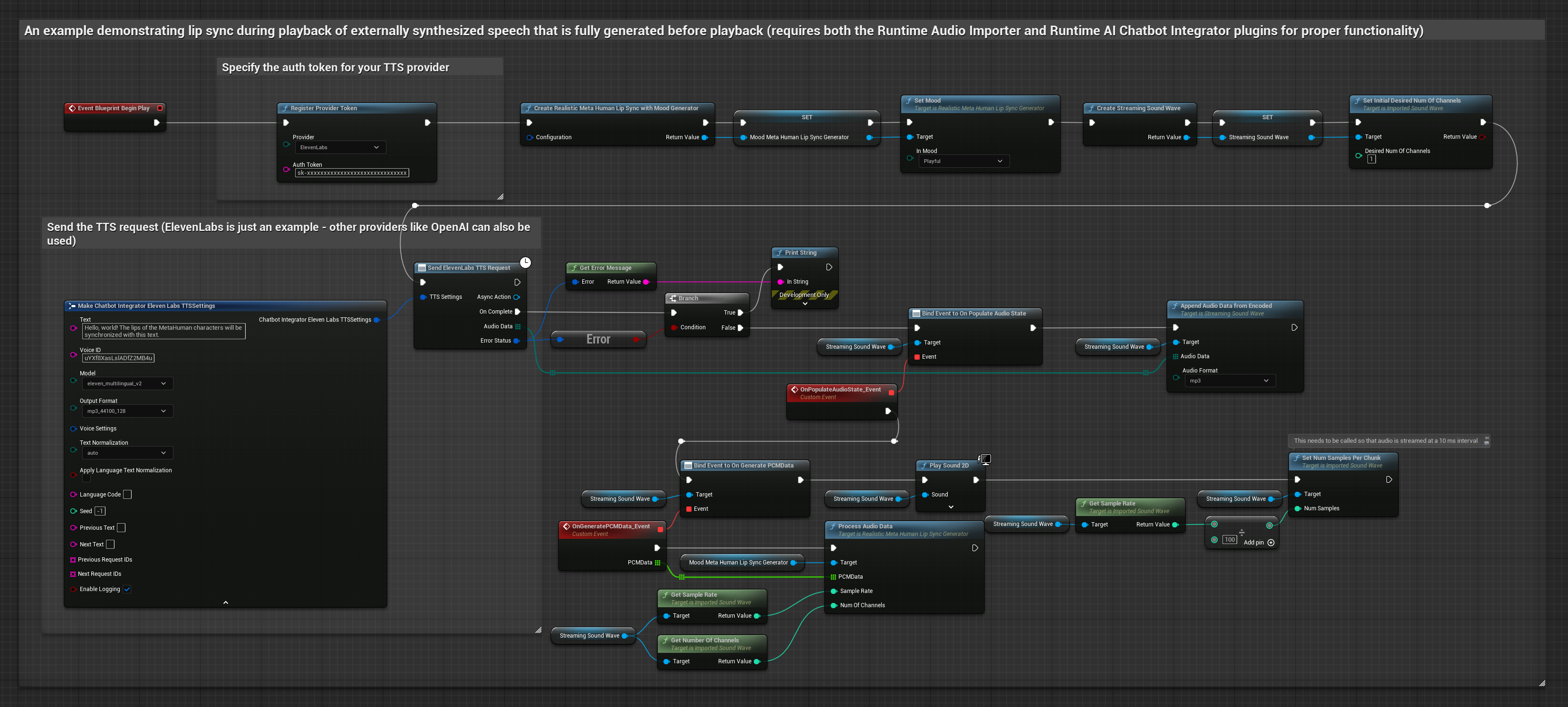
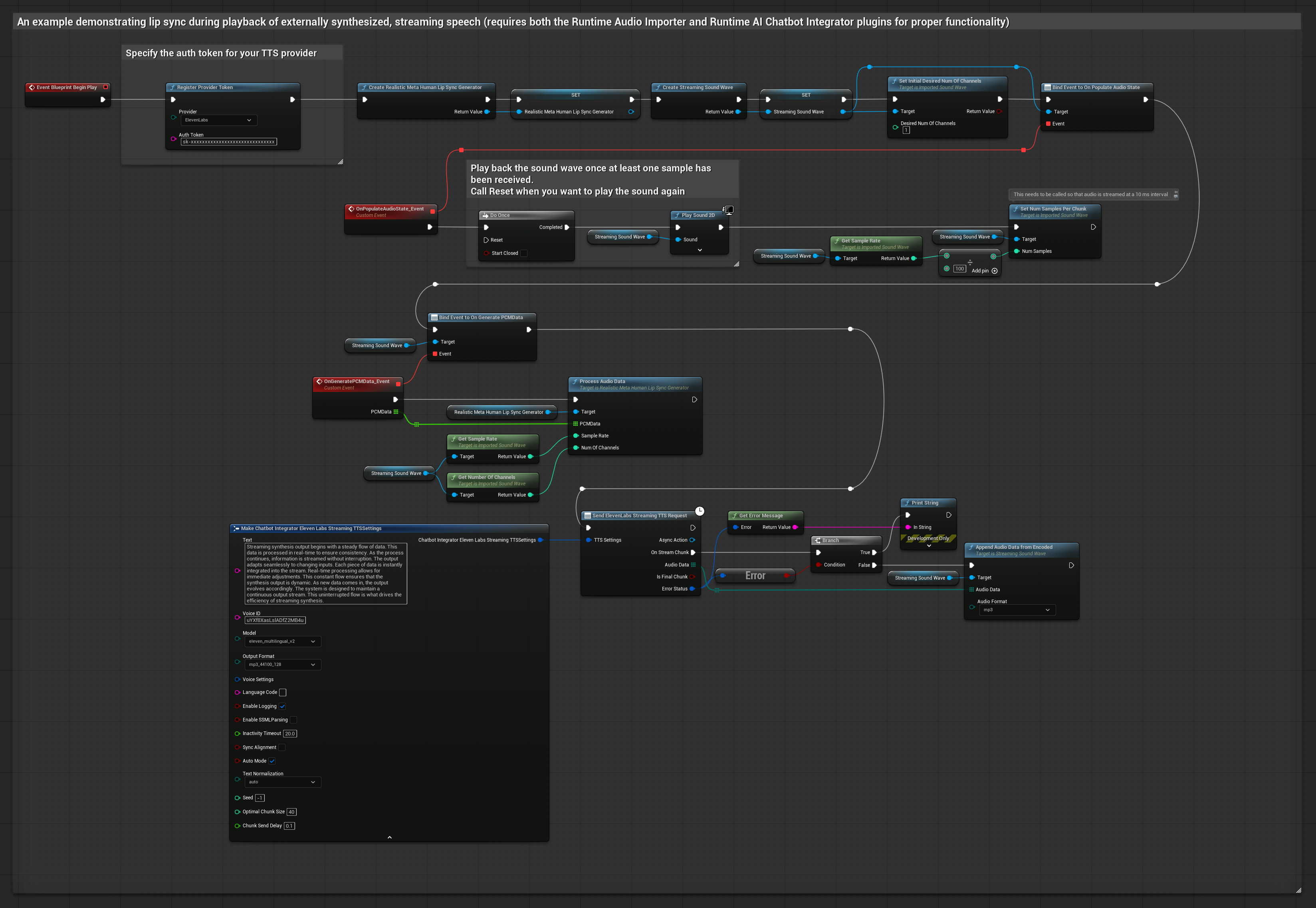
Этот подход использует плагин Runtime AI Chatbot Integrator для генерации синтезированной речи из AI-сервисов (OpenAI или ElevenLabs) и выполнения синхронизации губ:
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Используйте Runtime AI Chatbot Integrator для генерации речи из текста с помощью внешних API (OpenAI, ElevenLabs и т.д.)
- Используйте Runtime Audio Importer для импорта синтезированных аудиоданных
- Перед воспроизведением импортированной звуковой волны привяжитесь к её делегату
OnGeneratePCMData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator
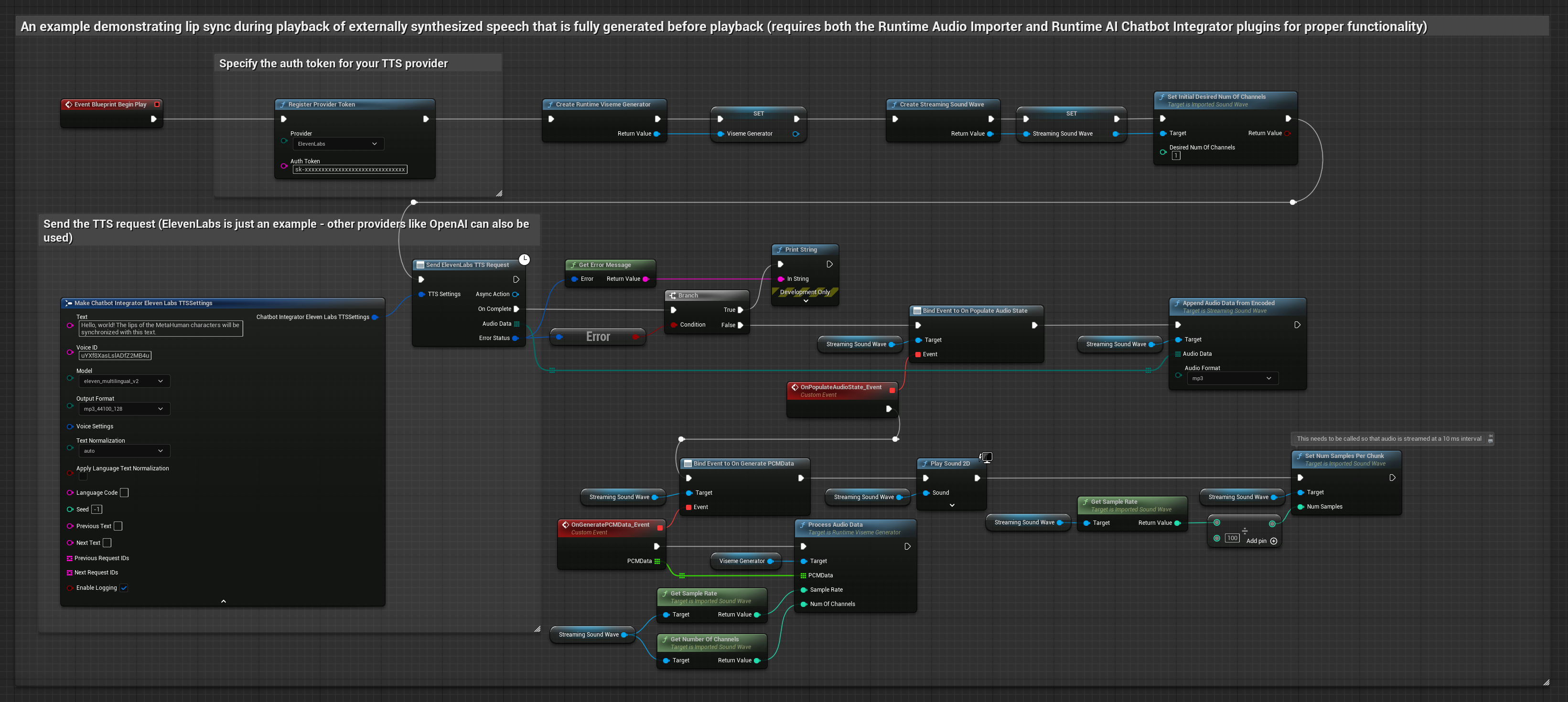
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
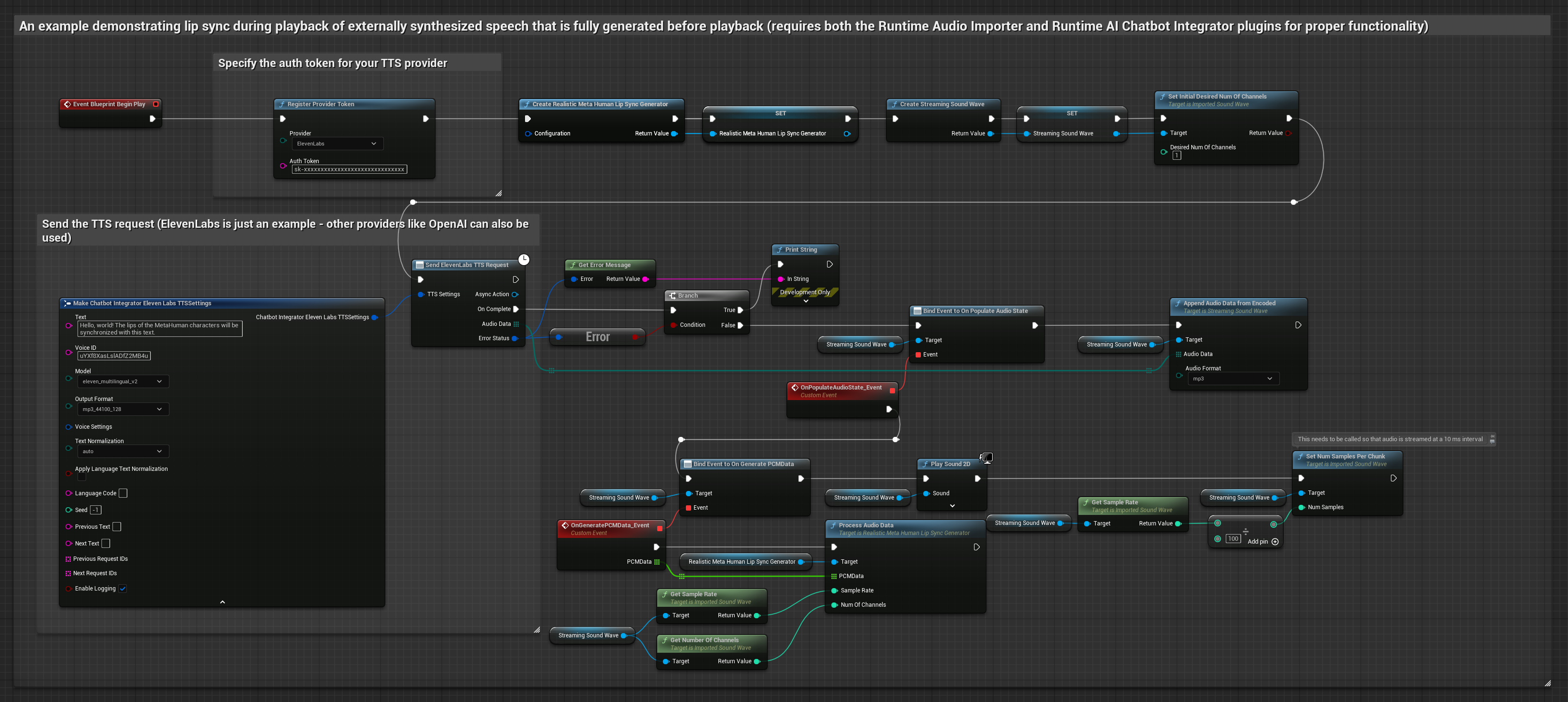
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
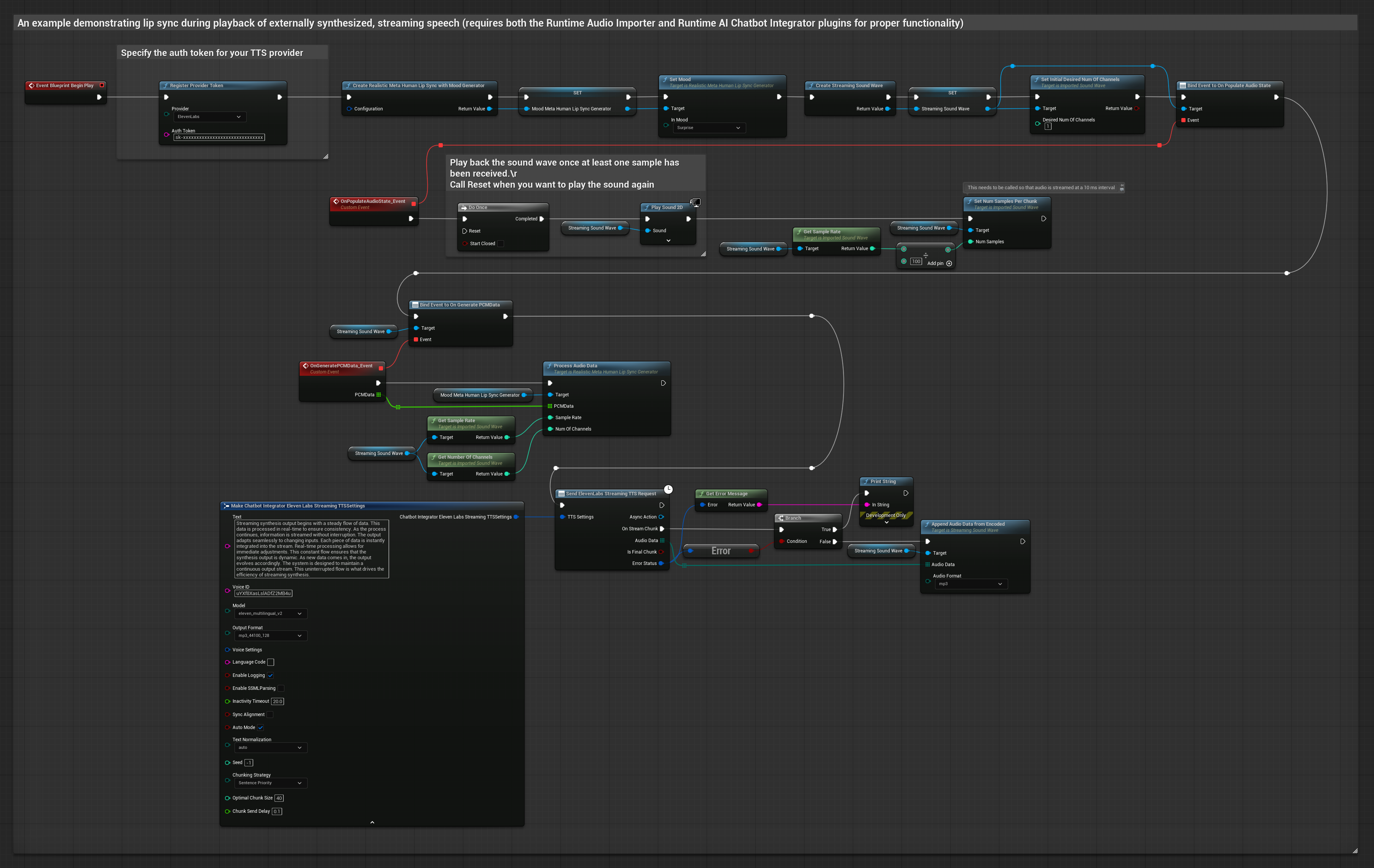
Этот подход использует плагин Runtime AI Chatbot Integrator для генерации синтезированной потоковой речи из AI-сервисов (OpenAI или ElevenLabs) и выполнения синхронизации губ:
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Используйте Runtime AI Chatbot Integrator для подключения к потоковым TTS API (например, ElevenLabs Streaming API)
- Используйте Runtime Audio Importer для импорта синтезированных аудиоданных
- Перед воспроизведением потоковой звуковой волны привяжитесь к её делегату
OnGeneratePCMData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator
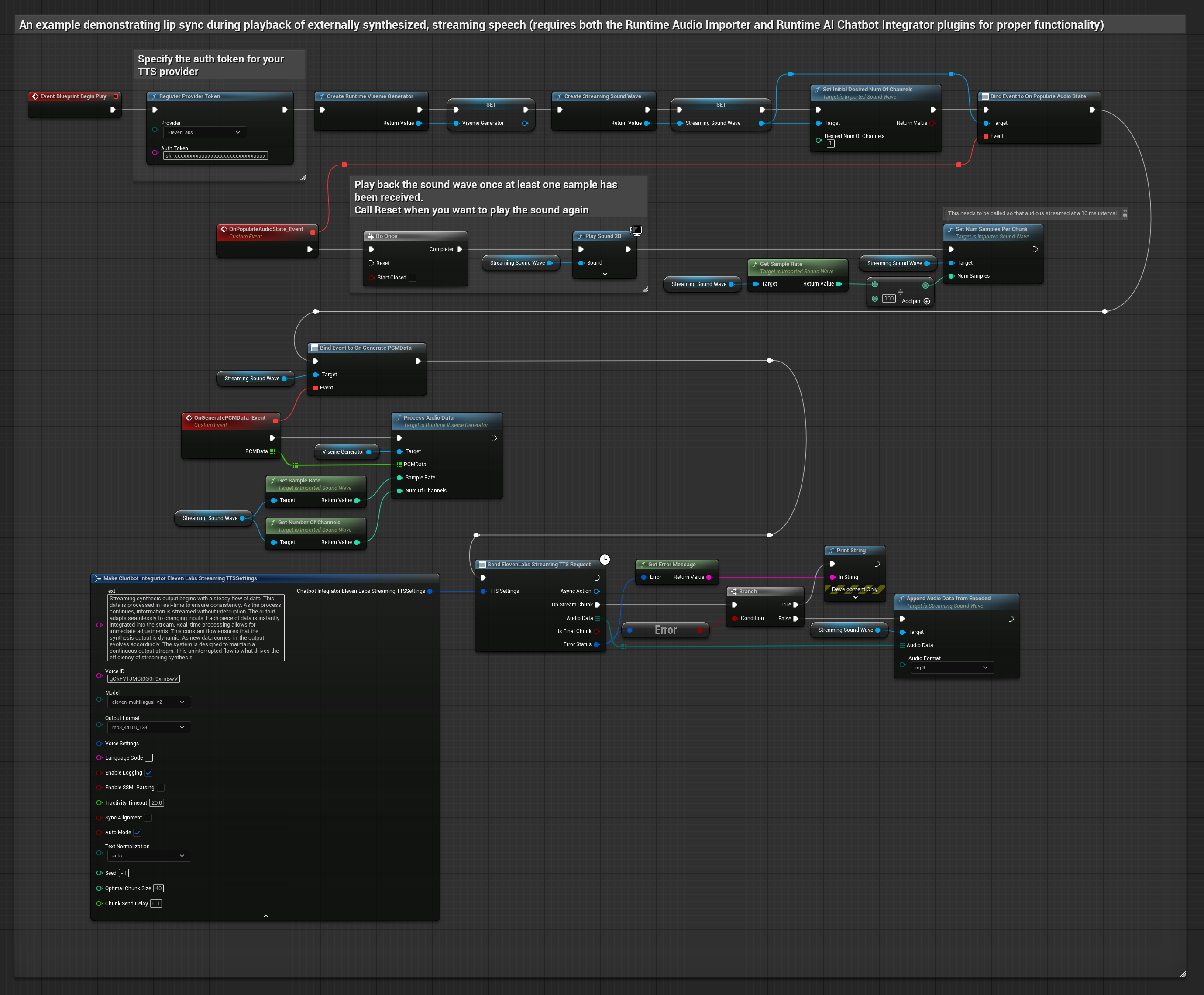
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и Стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
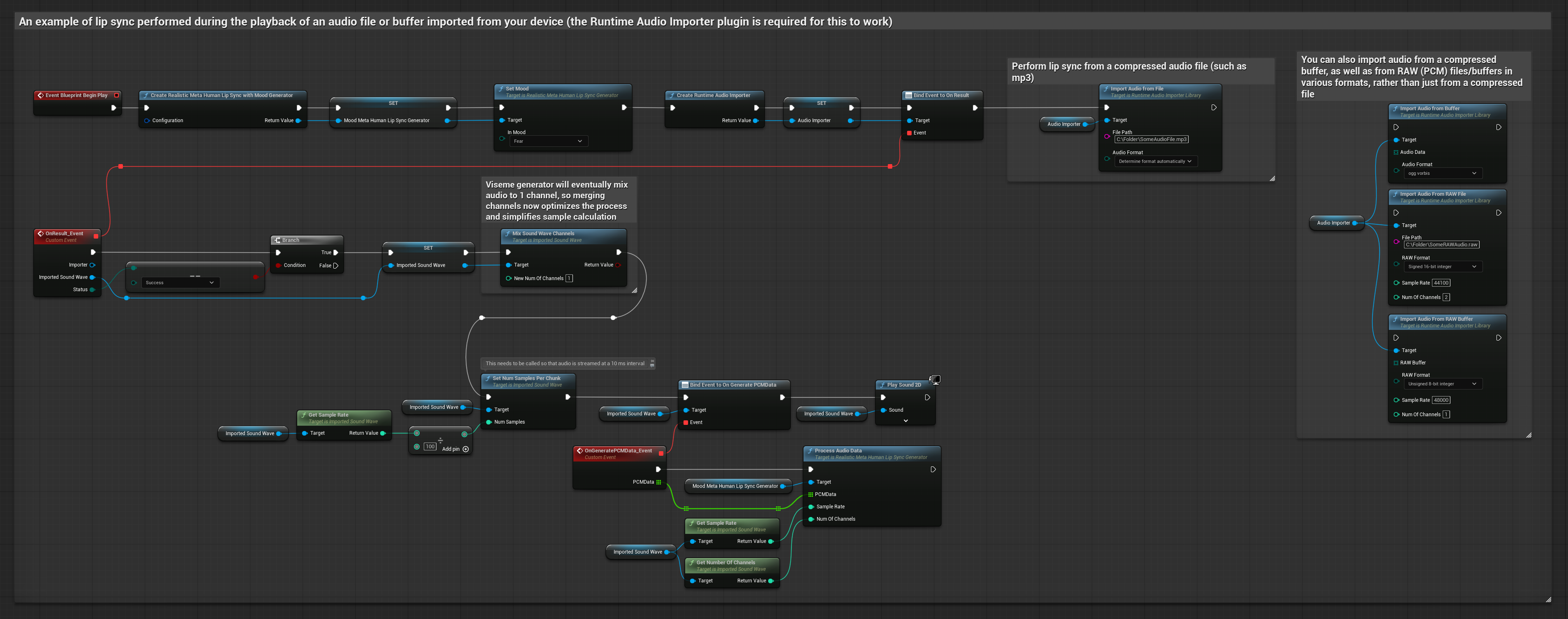
Этот подход использует предварительно записанные аудиофайлы или аудиобуферы для синхронизации губ.
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Используйте Runtime Audio Importer для импорта аудиофайла с диска или из памяти
- Перед воспроизведением импортированной звуковой волны привяжитесь к её делегату
OnGeneratePCMData - В привязанной функции вызовите
ProcessAudioDataиз вашего Runtime Viseme Generator - Воспроизведите импортированную звуковую волну и наблюдайте за анимацией синхронизации губ
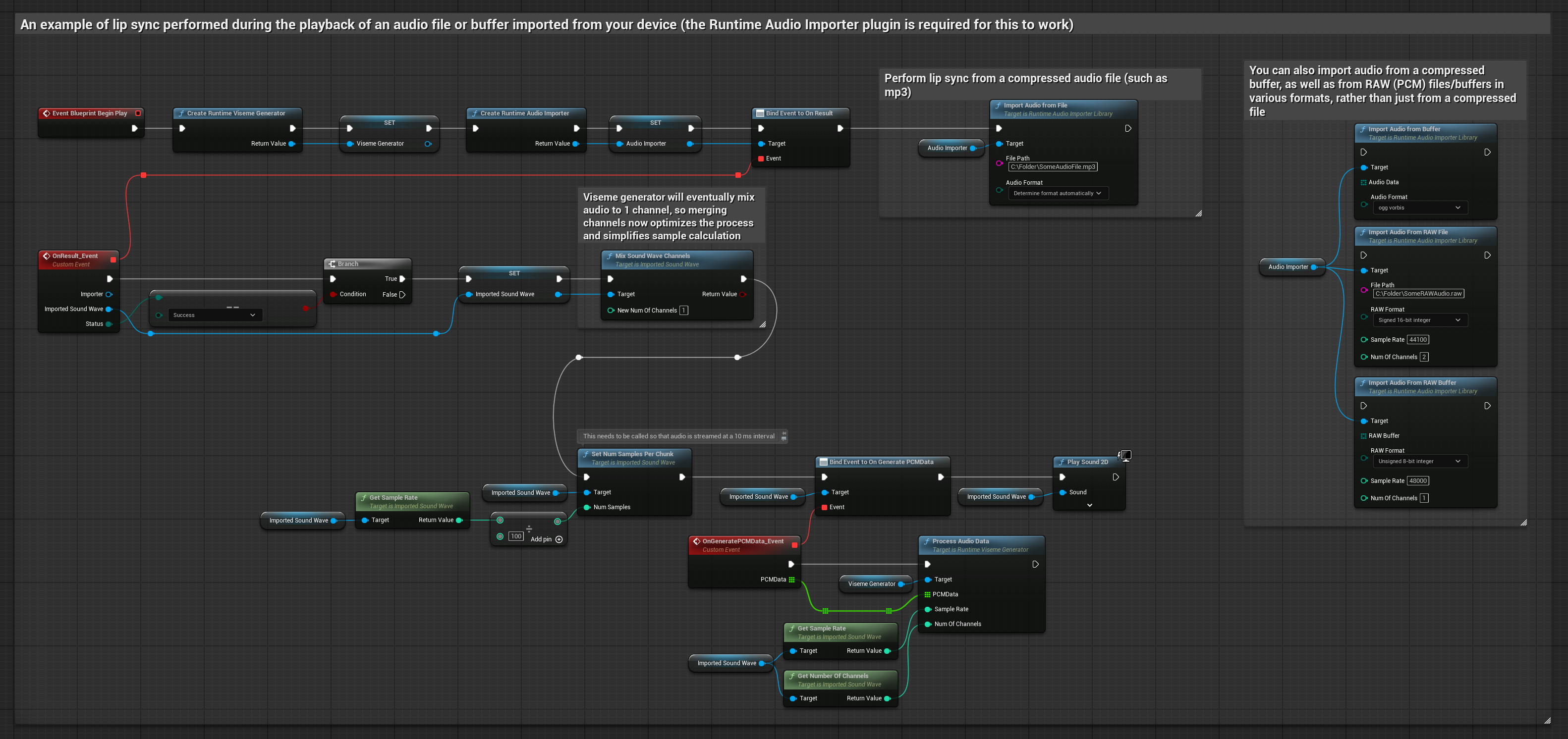
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
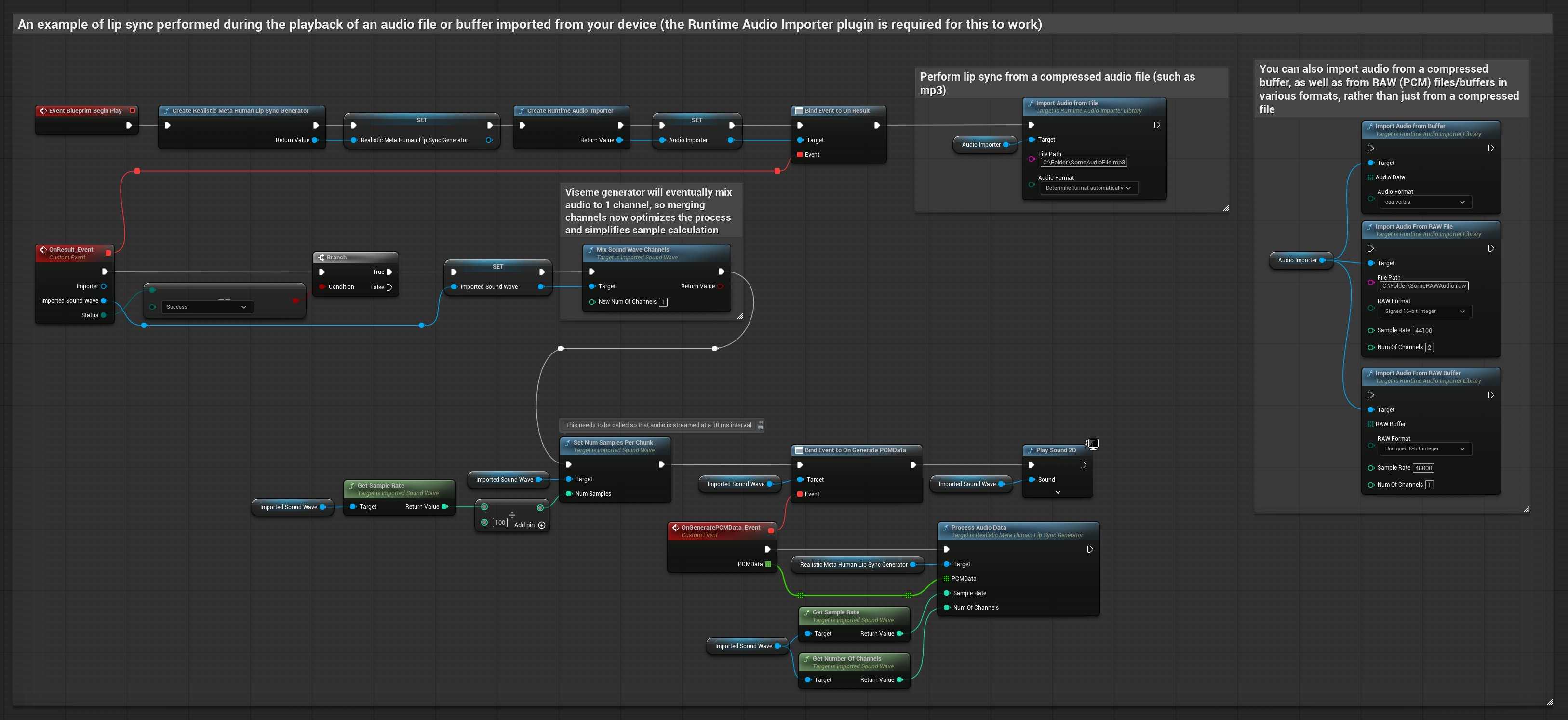
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
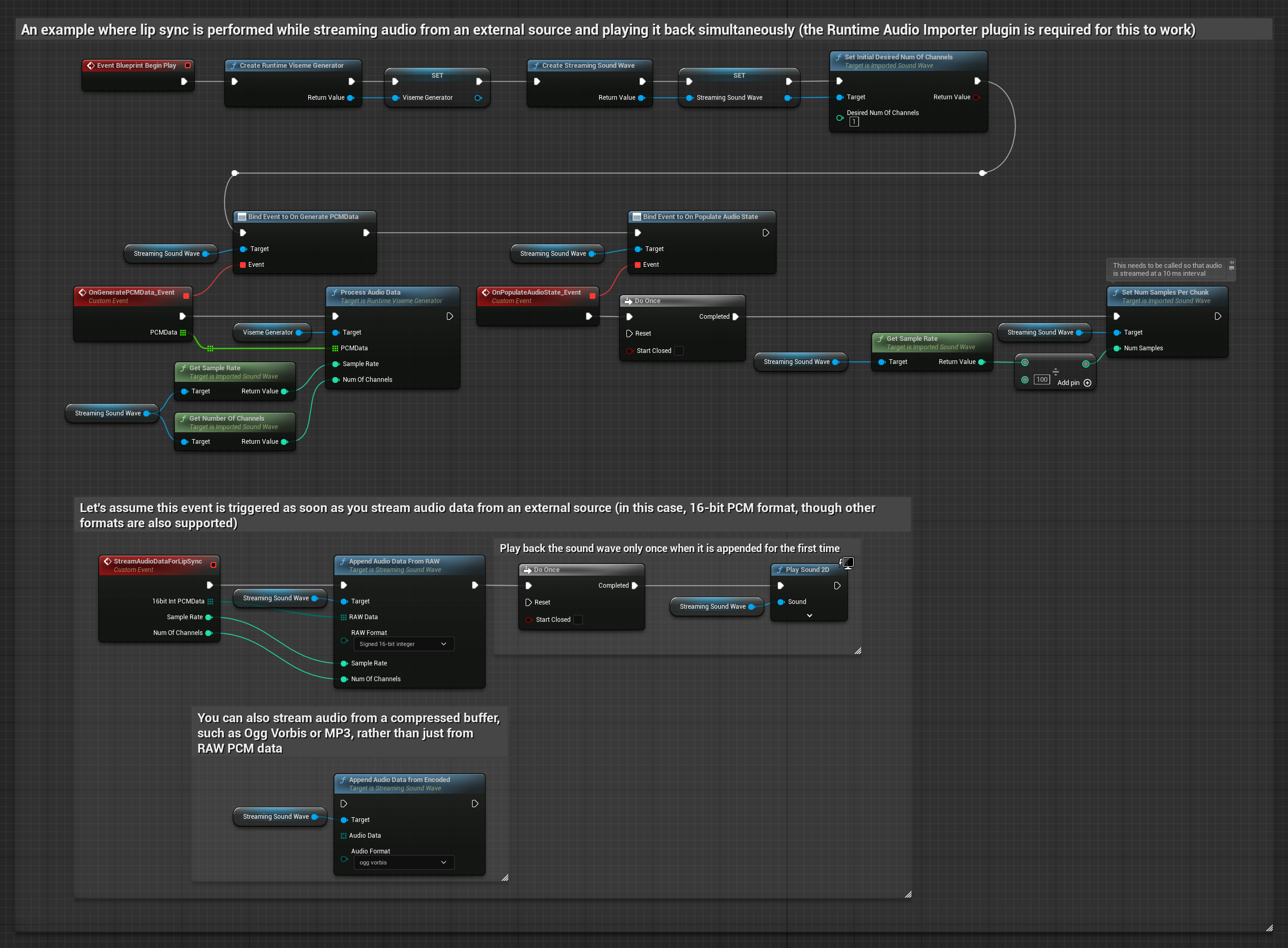
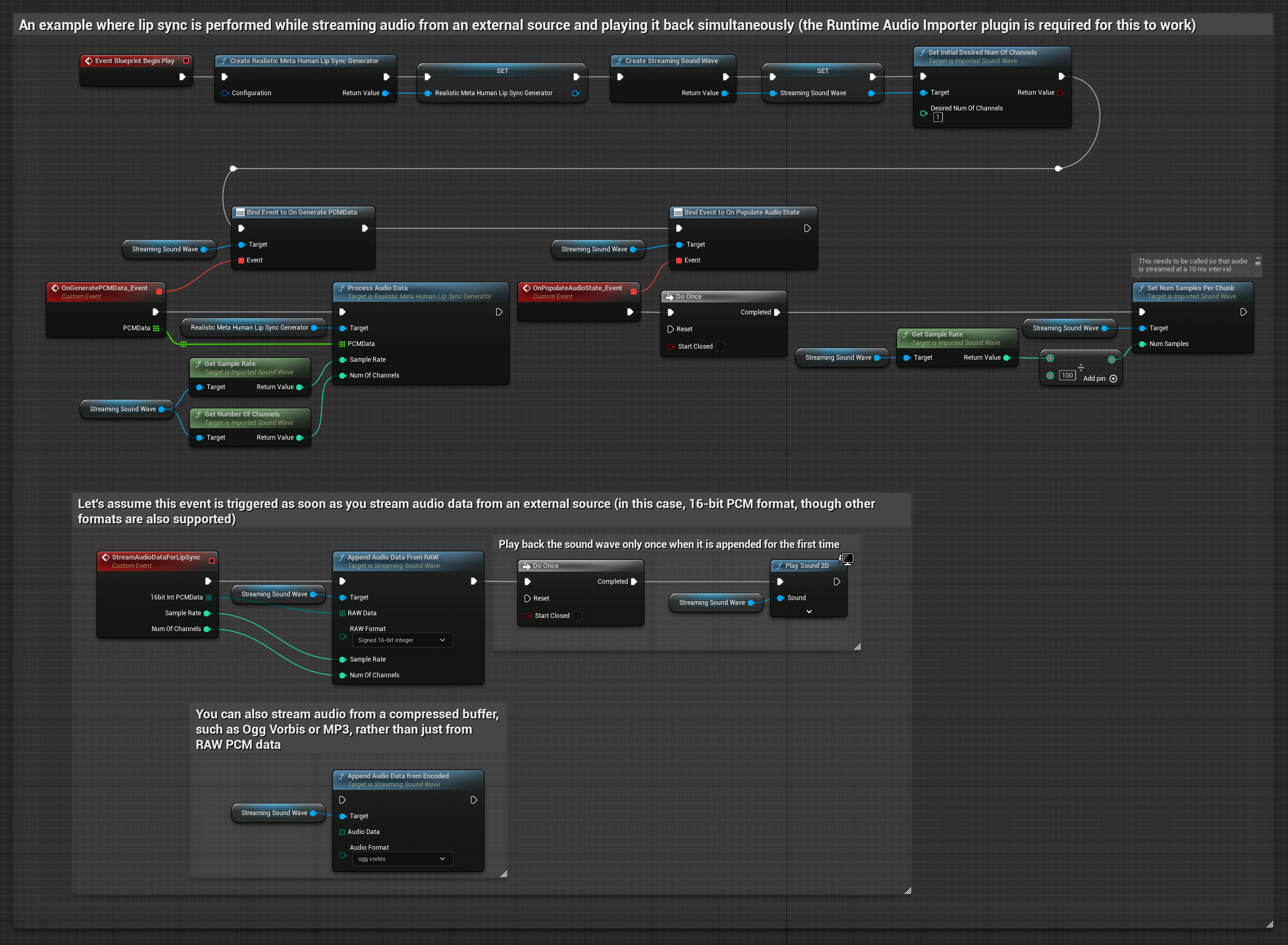
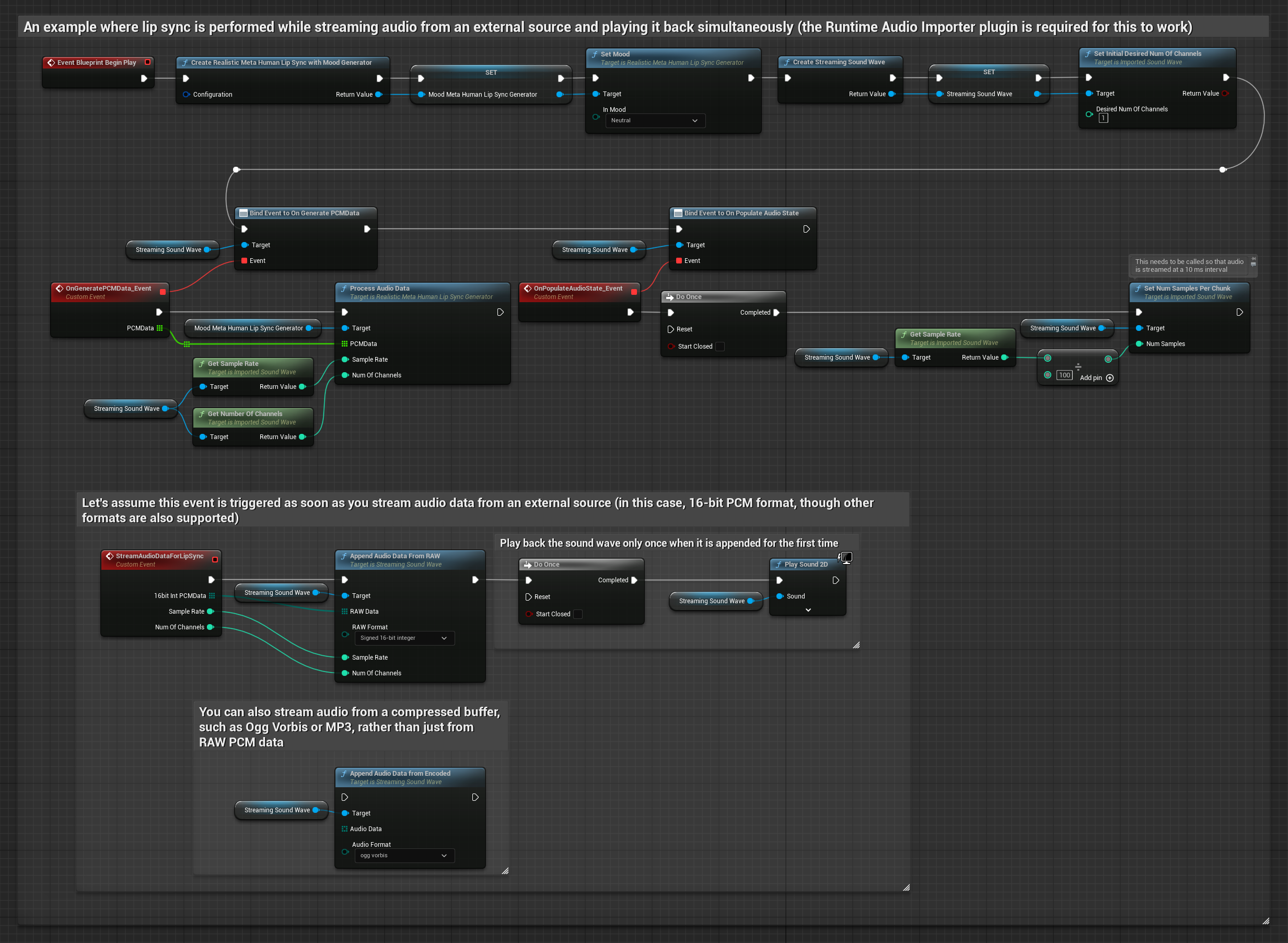
Для потоковой передачи аудиоданных из буфера вам потребуется:
- Стандартная модель
- Реалистичная модель
- Модель с поддержкой настроения и реалистичной анимацией
- Аудиоданные в формате float PCM (массив семплов с плавающей точкой), доступные из вашего потокового источника (или используйте Runtime Audio Importer для поддержки дополнительных форматов)
- Частота дискретизации и количество каналов
- Вызывайте
ProcessAudioDataиз вашего Runtime Viseme Generator с этими параметрами по мере поступления аудиочанков
Реалистичная модель использует тот же рабочий процесс обработки аудио, что и стандартная модель, но с переменной RealisticLipSyncGenerator вместо VisemeGenerator.
Модель с поддержкой настроения использует тот же рабочий процесс обработки аудио, но с переменной MoodMetaHumanLipSyncGenerator и дополнительными возможностями настройки настроения.
Примечание: При использовании потоковых аудиоисточников убедитесь, что вы правильно управляете временем воспроизведения аудио, чтобы избежать искажений. Дополнительную информацию см. в документации по потоковым звуковым волнам.
Советы по производительности обработки
-
Размер чанка: Увеличение
ProcessingChunkSizeпараметра конфигурации (например, до 320, 480 или 640 сэмплов) может заметно улучшить задержку с минимальным влиянием на качество или отзывчивость. -
Тип модели: При использовании реалистичных моделей переключение на высокооптимизированный тип модели (выбран по умолчанию) может повысить производительность. Обратите внимание, что оригинальная модель может обеспечивать немного лучшее качество, особенно при работе с зашумленным аудио.
-
Управление буфером: Модель с поддержкой настроения обрабатывает аудио фрагментами по 320 сэмплов (20 мс при частоте 16 кГц). Убедитесь, что временные параметры вашего аудиовхода соответствуют этому для достижения оптимальной производительности.
-
Пересоздание генератора: Для надежной работы с реалистичными моделями пересоздавайте генератор каждый раз, когда хотите подать новые аудиоданные после периода бездействия. См. раздел Пересоздание генератора в разделе «Устранение неполадок» для объяснения.
Следующие шаги
После того как вы настроили обработку аудио, вы можете:
- Узнайте о параметрах конфигурации для точной настройки поведения синхронизации губ
- Добавьте анимацию смеха для усиления выразительности
- Объедините синхронизацию губ с существующей лицевой анимацией, используя методы наложения, описанные в руководстве по конфигурации