Демонстрационные проекты
Чтобы помочь вам быстро начать работу с Runtime MetaHuman Lip Sync, доступны два готовых демонстрационных проекта. Оба созданы на Unreal Engine 5.6+, являются Blueprint-only и работают кроссплатформенно на Windows, Mac, Linux, iOS, Android и платформах на базе Android (включая Meta Quest).
Доступные демонстрационные проекты
- AI-диалоговый NPC / Интерактивный аватар
- Базовая демонстрация синхронизации губ
Полный рабочий процесс создания разговорного аватара с ИИ, объединяющий распознавание речи, ИИ-чат-бота (LLM), синтез речи и воспроизведение аудио с синхронизацией губ в реальном времени — всё это работает вместе в одном проекте. Подходит для широкого круга сценариев использования, включая игры, интерактивные киоски, виртуальное производство, музейные инсталляции, цифровых ассистентов и тренировочные симуляции.
Обзор конвейера
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Когда LLM работает в потоковом режиме, его вывод разбивается на предложения и отправляется в TTS по мере завершения каждого предложения, а не после получения полного ответа, чтобы минимизировать задержку.
Видео
Быстрый предпросмотр (~30 сек)
Краткая демонстрация работы демо-проекта.
Полное прохождение
Подробное руководство, охватывающее настройку, конфигурацию и полный конвейер диалогов.
Загрузки
Обязательные и опциональные плагины
Демонстрационный проект является модульным — вам понадобятся только плагины для тех провайдеров, которые вы хотите использовать.
| Плагин | Цель | Обязательно? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Анимация синхронизации губ | ✅ Всегда |
| Runtime Audio Importer | Захват и обработка аудио | ✅ Всегда |
| Runtime Speech Recognizer | Офлайн-распознавание речи (whisper.cpp) | ✅ Всегда |
| Runtime AI Chatbot Integrator | Внешние LLM (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) и/или внешние TTS (OpenAI, ElevenLabs) | 🔶 Необязательно |
| Runtime Local LLM | Локальный вывод LLM через llama.cpp (модели Llama, Mistral, Gemma и др. в формате GGUF) | 🔶 Необязательно |
| Runtime Text To Speech | Локальный TTS через Piper и Kokoro | 🔶 Необязательно |
Хотя каждый из перечисленных плагинов является опциональным, для работы демо вам понадобится как минимум один LLM-провайдер и как минимум один TTS-провайдер. Комбинируйте их свободно (например, локальный LLM + ElevenLabs TTS, или OpenAI LLM + локальный TTS).
Модульная архитектура
В папке Content вы найдете папку Modules, которая содержит три подпапки:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Если вы не приобрели один (или несколько) дополнительных плагинов, просто удалите соответствующие папки. Базовые ассеты демо-проекта (экземпляр игры, виджеты и т.д.) не ссылаются напрямую на эти модули, поэтому их удаление не вызовет ошибок ссылок на ассеты. Интерфейс конфигурации автоматически скроет любого провайдера, чья папка отсутствует.
Эта модульность применима только к провайдерам LLM и TTS. Распознавание речи (Runtime Speech Recognizer) и Синхронизация губ (Runtime MetaHuman Lip Sync) являются частью базового демонстрационного проекта и всегда обязательны.
При первом запуске Unreal может спросить, нужно ли отключить отсутствующие опциональные плагины — нажмите Да. Убедитесь, что вы также удалили соответствующую папку Content/Modules/ (см. выше).
Структура демонстрационного проекта
Пользовательский интерфейс, показанный ниже, полностью создан с помощью UMG (Unreal Motion Graphics) и предназначен исключительно для демонстрации конвейера: распознавание речи → LLM → TTS → синхронизация губ. Вы можете свободно изменить его стиль или заменить, чтобы он соответствовал визуальному дизайну вашего проекта, схеме управления или платформе (VR/AR, мобильные устройства, консоли, киоски и т. д.). Если некоторые виджеты не нужны в вашем сценарии использования, вы также можете просто скрыть их (например, установить для них видимость Collapsed или Hidden).

| Area | Что там есть |
|---|---|
| По центру | Персонаж MetaHuman. |
| Левая сторона | Четыре кнопки конфигурации (Распознавание речи, ИИ-чатбот, Синтез речи, Анимации), подробно описанные ниже. |
| По центру внизу | Кнопка «Начать запись». Нажмите её, чтобы начать голосовой разговор: ваш микрофон захватывается, речь распознаётся, отправляется в LLM, ответ синтезируется через TTS и воспроизводится с синхронизацией губ — полностью без помощи рук. |
| Правый центр | Виджет истории разговора, отображающий полный диалог между вами и ИИ (сообщения как пользователя, так и ассистента). Он также включает поле ввода текста, позволяющее вводить сообщения напрямую без использования распознавания речи — полезно для тестирования, обеспечения доступности или при отсутствии микрофона. |
В одном сеансе можно свободно смешивать оба режима ввода — произносить одни сообщения, вводить другие.
Если синхронизация губ со временем всё сильнее отстаёт от аудио (а не просто имеет фиксированную задержку), см. раздел Размер обрабатываемого фрагмента в Настройка анимаций ниже.
Кнопки конфигурации
Четыре кнопки конфигурации слева открывают специальные панели для каждой части конвейера:
1. Настройка распознавания речи
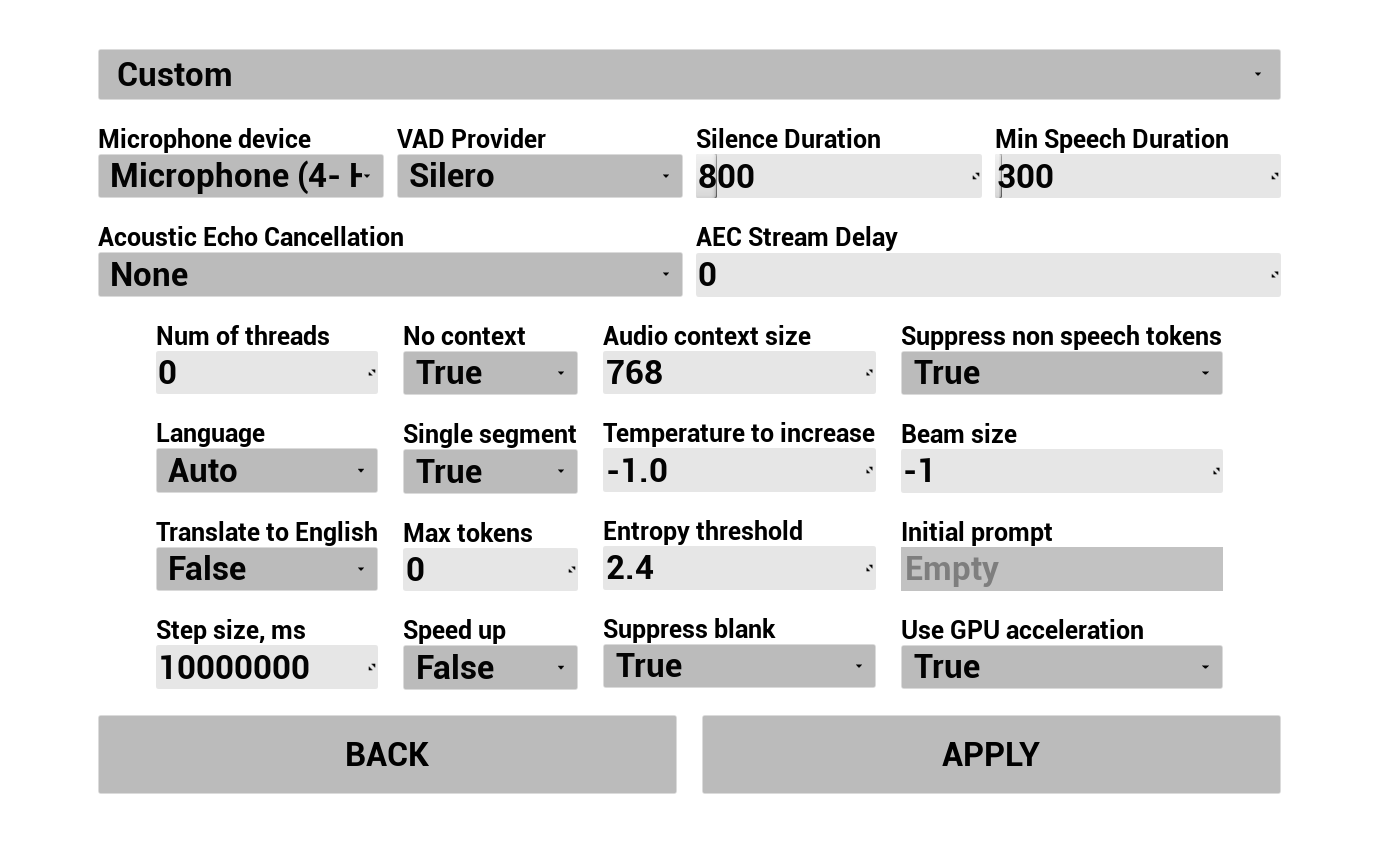
Настройте, как захватывается и транскрибируется голос пользователя:
- Выберите язык
- Настройте параметры распознавания речи (настройки модели Whisper)
- Настройте AEC (подавление акустического эха)
- Настройте VAD (детектор голосовой активности)
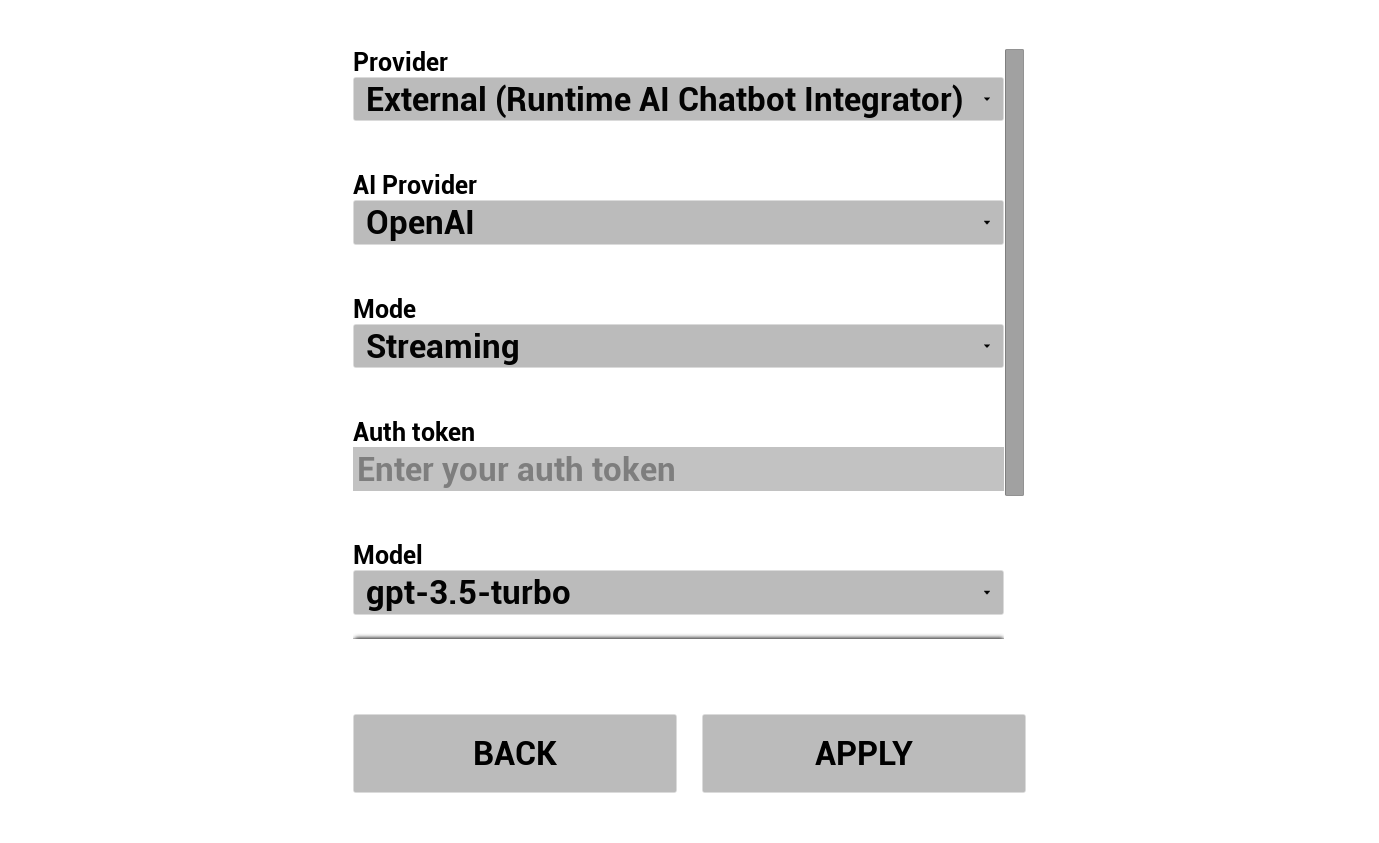
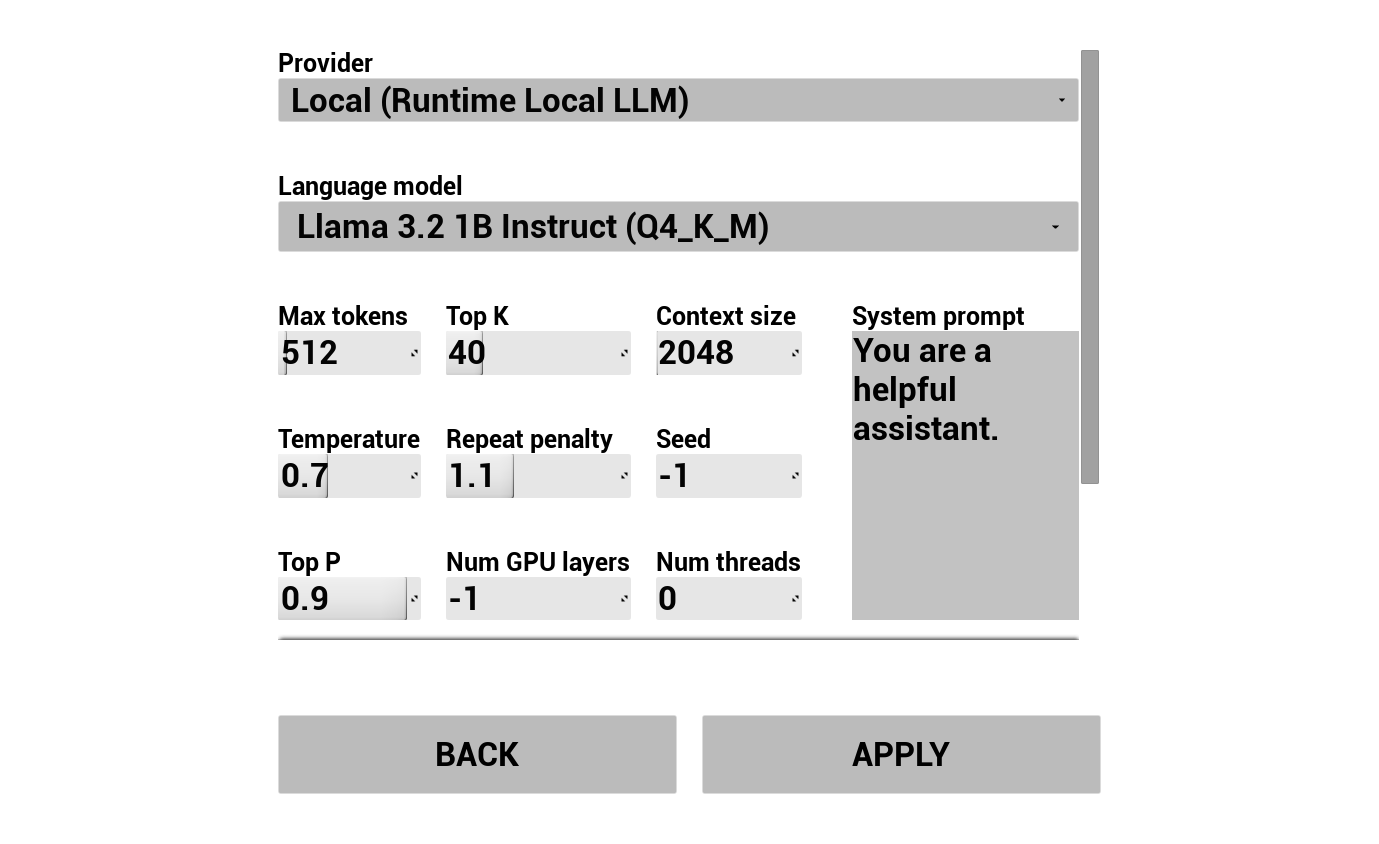
2. Настройка AI-чатбота
Выберите провайдера LLM и настройте его:
- Выберите провайдера (Runtime AI Chatbot Integrator или Runtime Local LLM)
- Выберите режим: Обычный или Потоковый (зависит от провайдера, Потоковый режим включает передачу TTS по предложениям, см. Обзор конвейера)
- Для внешних провайдеров: токен аутентификации, название модели и т.д.
- Для локальной LLM: выберите модель GGUF, задайте размер контекста и другие параметры вывода. Вы также можете загрузить свою собственную модель GGUF во время выполнения прямо из демо (например, по URL) и использовать её немедленно без пересборки проекта.
Комбобокс провайдера отображает только тех провайдеров, чья папка модуля плагина присутствует в Content/Modules/.
3. Настройте преобразование текста в речь
Выберите вашего TTS-провайдера и настройте голоса/модели:
- Выберите провайдера (Runtime AI Chatbot Integrator для OpenAI/ElevenLabs или Runtime Text To Speech для локального Piper/Kokoro)
- Выберите режим: Обычный или Потоковый (определяет, возвращается ли аудио целиком или по мере синтеза)
- Выберите голос/модель
- Настройте параметры, специфичные для провайдера

4. Настройка анимаций
Управляйте визуальным отображением вашего AI-аватара:
- Выберите одного из 3 предварительно загруженных персонажей MetaHuman (Aera, Ada, Orlando)
- Выберите модель синхронизации губ (Standard или Realistic)
- Выберите тип модели синхронизации губ — Highly Optimized, Semi-Optimized или Original (см. Тип модели)
- Настройте Размер блока обработки — определяет, как часто выполняется вывод синхронизации губ (см. Размер блока обработки)
- Если синхронизация губ со временем всё больше отстаёт от аудио из-за нагрузки на процессор, увеличьте это значение до 480 или 640.
- Выберите анимацию бездействия для воспроизведения на MetaHuman во время разговора

Предварительная настройка демо-версии в редакторе
При работе с исходной версией вы можете предварительно заполнить значения по умолчанию прямо в редакторе, чтобы не вводить их заново при каждом запуске:
| What | Где |
|---|---|
| Общие настройки (модель синхронизации губ, анимация бездействия, класс персонажа, распознавание речи и т.д.) | Content/LipSyncSTSGameInstance |
| Настройки внешней LLM / внешней TTS (Интегратор чат-ботов с ИИ во время выполнения) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Настройки Local LLM (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Локальный TTS (синтез речи в реальном времени) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Кроссплатформенные заметки
Все плагины, используемые демо, поддерживают Windows, Mac, Linux, iOS, Android и платформы на базе Android (включая Meta Quest), поэтому демо-проект также работает на всех них. Это делает его пригодным для развертывания в самых разных средах — от игр и настольных киосков до мобильных приложений, автономных VR-гарнитур и систем виртуального производства на съемочной площадке.
Для слабых устройств (мобильных, автономных VR) вы можете:
- Используйте стандартную модель синхронизации губ вместо реалистичной — см. сравнение моделей
- Переключитесь на высокооптимизированный тип модели
- Увеличьте размер обрабатываемого фрагмента, чтобы снизить нагрузку на ЦП
- Выбирайте более компактные модели LLM / TTS
См. Конфигурация для конкретных платформ для дополнительных шагов настройки на Android, iOS, Mac и Linux.
Поддержка Pixel Streaming
Развертывание демо на Pixel Streaming (нажмите, чтобы развернуть)
Демонстрационный проект AI-диалогов также работает в среде Pixel Streaming, позволяя транслировать аватар MetaHuman на удаленный клиент (например, веб-браузер) с захватом аудио с микрофона пользователя на стороне клиента. Для этого требуется лишь одно изменение в демо-проекте.
1. Установите расширение Pixel Streaming для Runtime Audio Importer
Плагин Runtime Audio Importer предоставляет бесплатный плагин-расширение, который позволяет захватывать аудио с клиента Pixel Streaming. В зависимости от версии инфраструктуры Pixel Streaming, которую вы используете, установите один из следующих вариантов:
- Pixel Streaming расширение (для оригинального плагина Pixel Streaming), или
- Pixel Streaming 2 расширение (для более нового плагина Pixel Streaming 2)
Ссылки для скачивания и инструкции по установке доступны здесь: Установка плагина расширения Pixel Streaming Audio Capture.
2. Замените узел захватываемой звуковой волны в LipSyncSTSGameInstance
После установки плагина расширения:
- В Content Browser перейдите в
/All/Gameи откройте ассетLipSyncSTSGameInstance. - Переключитесь на Event Graph.
- Найдите Event Init и проследите поток выполнения, пока не найдете пару узлов:
Create Capturable Sound Wave→Set Capturable Sound Wave. - Замените вызов
Create Capturable Sound WaveнаCreate Pixel Streaming Capturable Sound WaveилиCreate Pixel Streaming 2 Capturable Sound Waveв зависимости от версии инфраструктуры Pixel Streaming, на которую вы ориентируетесь. - Подключите его выход к тому же узлу
Set Capturable Sound Wave.
После этого проект готов к развертыванию на Pixel Streaming — распознавание речи, LLM, TTS и синхронизация губ будут работать как и прежде, но с аудио, захваченным с удаленного клиента вместо локального микрофона.
Импорт собственного персонажа
Демонстрационный проект поставляется с тремя образцами персонажей MetaHuman (Aera, Ada, Orlando), но вы можете импортировать собственного MetaHuman и использовать его в демо.
📺 Видеоурок: Добавление пользовательского персонажа MetaHuman в демонстрационный проект
Плагин Runtime MetaHuman Lip Sync сам по себе поддерживает множество других систем персонажей помимо MetaHumans (персонажи на основе ARKit, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe и т. д. — см. Руководство по настройке пользовательских персонажей). Создаете ли вы игрового NPC, виртуального ведущего, киоскового ассистента или цифрового человека для виртуального производства — плагин адаптируется к вашему пайплайну персонажей.
Более простой демонстрационный проект, который фокусируется исключительно на функции синхронизации губ, без полного рабочего процесса ИИ-диалогов. Подходит, если вы просто хотите увидеть синхронизацию губ в действии с различными аудиоисточниками.
Рекомендуемое видео
Загрузки
Что входит
Эта демонстрация показывает основные рабочие процессы синхронизации губ:
- Ввод с микрофона — синхронизация губ в реальном времени с живого аудио
- Воспроизведение аудиофайлов — синхронизация губ из импортированных аудиофайлов
- Преобразование текста в речь — синхронизация губ, управляемая синтезированной речью
Обязательные и опциональные плагины
| Плагин | Цель | Обязательно? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Анимация синхронизации губ | ✅ Требуется |
| Runtime Audio Importer | Импорт и захват аудио | ✅ Требуется |
| Runtime Text To Speech | Локальный TTS для демонстрационной сцены TTS | 🔶 Необязательно |
| Runtime AI Chatbot Integrator | Внешние провайдеры TTS (OpenAI, ElevenLabs) | 🔶 Необязательно |
Примечания к стандартной модели синхронизации губ
Если вы планируете использовать Стандартную модель (вместо Реалистичной) в любом из демонстрационных проектов, вам потребуется установить плагин расширения Standard Lip Sync. Инструкции по установке см. в разделе Расширение для стандартной модели.
Нужна помощь?
Если у вас возникнут проблемы с настройкой или запуском демонстрационных проектов, не стесняйтесь обращаться:
Для запросов на индивидуальную разработку (например, расширение демо-версии собственной логикой, адаптация под конкретную платформу или пайплайн персонажей) обращайтесь по адресу [email protected].