Конфигурация плагина
Конфигурация модели
Для надежной работы с моделями Realistic и Mood-Enabled Realistic пересоздавайте генератор перед каждым новым воспроизведением аудио, а не используйте один и тот же во время длительных пауз. Подробнее см. Пересоздание генератора в разделе «Устранение неполадок».
Стандартная конфигурация модели
Узел Create Runtime Viseme Generator использует настройки по умолчанию, которые хорошо подходят для большинства сценариев. Конфигурация осуществляется через свойства узла смешивания в Animation Blueprint.
Для параметров конфигурации Animation Blueprint см. раздел Конфигурация синхронизации губ ниже.
Конфигурация реалистичной модели
Узел Create Realistic MetaHuman Lip Sync Generator принимает необязательный параметр Configuration, который позволяет настроить поведение генератора:
Тип модели
Настройка Model Type определяет, какую версию реалистичной модели использовать:
| Тип модели | Производительность | Визуальное качество | Обработка шума | Рекомендуемые сценарии использования |
|---|---|---|---|---|
| Высоко оптимизированный (по умолчанию) | Максимальная производительность, минимальная загрузка ЦП | Хорошее качество | Может наблюдаться заметное движение рта при фоновом шуме или неречевых звуках. | Чистые аудиосреды, сценарии, критичные к производительности |
| Полуоптимизированный | Хорошая производительность, умеренное использование ЦП. | Высокое качество | Повышенная стабильность при работе с зашумленным аудио | Сбалансированная производительность и качество, смешанные аудиоусловия |
| Оригинал | Подходит для использования в реальном времени на современных процессорах | Высочайшее качество | Наиболее стабилен при фоновом шуме и неречевых звуках | Высококачественные постановки, шумные аудиосреды, когда требуется максимальная точность |
Настройки производительности
Внутренние потоки операций: Управляет количеством потоков, используемых для внутренних операций обработки модели.
- 0 (По умолчанию/Автоматически): Использует автоматическое определение (обычно 1/4 доступных ядер ЦП, максимум 4)
- 1–16: Укажите количество потоков вручную. Более высокие значения могут повысить производительность на многоядерных системах, но увеличивают нагрузку на ЦП.
Потоки межоперационного взаимодействия: Управляет количеством потоков, используемых для параллельного выполнения различных операций модели.
- 0 (По умолчанию/Автоматически): Использует автоматическое определение (обычно 1/8 от доступных ядер ЦП, максимум 2)
- 1-8: Укажите количество потоков вручную. Обычно устанавливается низким для обработки в реальном времени.
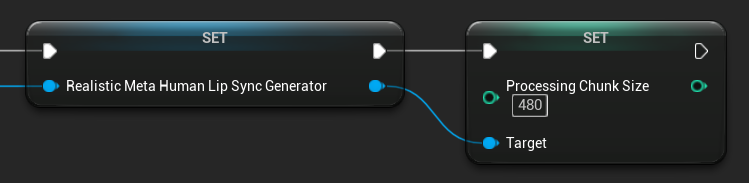
Размер обрабатываемого фрагмента
Размер обрабатываемого блока определяет, сколько сэмплов обрабатывается на каждом этапе вывода. Значение по умолчанию — 160 сэмплов (10 мс аудио при частоте 16 кГц).
- Меньшие значения обеспечивают более частые обновления, но увеличивают нагрузку на процессор
- Большие значения снижают нагрузку на процессор, но могут уменьшить отзывчивость синхронизации губ
- Рекомендуется использовать значения, кратные 160, для оптимального выравнивания
Конфигурация модели с поддержкой настроения
Узел Create Realistic MetaHuman Lip Sync With Mood Generator предоставляет дополнительные параметры конфигурации помимо базовой реалистичной модели:
Базовая конфигурация
Lookahead Ms: Время упреждения в миллисекундах для повышения точности синхронизации губ.
- По умолчанию: 80 мс
- Диапазон: от 20 мс до 200 мс (должно быть кратно 20)
- Более высокие значения обеспечивают лучшую синхронизацию, но увеличивают задержку
Тип вывода: Определяет, какие лицевые контроллеры будут сгенерированы.
- Полное лицо: Все 81 элемент управления мимикой (брови, глаза, нос, рот, челюсть, язык)
- Только рот: Только элементы управления, связанные с ртом, челюстью и языком
Настройки производительности: Использует те же параметры Intra Op Threads и Inter Op Threads, что и обычная реалистичная модель.
Настройки настроения
Доступные настроения:
- Нейтральное, Счастливое, Грустное, Отвращение, Гнев, Удивление, Страх
- Уверенное, Взволнованное, Скучающее, Игривое, Растерянное
Интенсивность настроения: Управляет тем, насколько сильно настроение влияет на анимацию (от 0.0 до 1.0)
Управление настроением в реальном времени
Вы можете настраивать параметры настроения во время выполнения с помощью следующих функций:
- Установить настроение: Изменить текущий тип настроения
- Установить интенсивность настроения: Настроить силу влияния настроения на анимацию (от 0.0 до 1.0)
- Установить время упреждения (мс): Изменить время упреждения для синхронизации
- Установить тип вывода: Переключение между режимами «Полное лицо» и «Только рот»

Руководство по выбору настроения
Выберите подходящие настроения в зависимости от вашего контента:
| Mood | Лучше всего подходит для | Типичный диапазон интенсивности |
|---|---|---|
| Нейтральный | Общий разговор, повествование, состояние по умолчанию | 0.5 - 1.0 |
| Счастливый | Позитивный контент, жизнерадостные диалоги, празднования | 0.6 - 1.0 |
| Грустный | Меланхоличное содержание, эмоциональные сцены, мрачные моменты | 0.5 - 0.9 |
| Отвращение | Негативные реакции, неприемлемый контент, отторжение | 0.4 - 0.8 |
| Гнев | Агрессивный диалог, конфликтные сцены, разочарование | 0.6 - 1.0 |
| Удивление | Неожиданные события, откровения, шоковые реакции | 0.7 - 1.0 |
| Страх | Угрожающие ситуации, тревога, нервный диалог | 0.5 - 0.9 |
| Уверенный | Профессиональные презентации, лидерский диалог, уверенная речь | 0.7 - 1.0 |
| Взволнован | Энергичный контент, анонсы, восторженный диалог | 0.8 - 1.0 |
| Скучающий | Однообразный контент, безучастный диалог, усталая речь | 0.3 - 0.7 |
| Игривый | Непринуждённая беседа, юмор, лёгкое общение | 0.6 - 0.9 |
| Смущенный | Диалог, полный вопросов, неуверенность, замешательство | 0.4 - 0.8 |
Конфигурация Animation Blueprint
Конфигурация синхронизации губ
- Стандартная модель
- Реалистичные модели
Узел Blend Runtime MetaHuman Lip Sync имеет параметры конфигурации на панели свойств:
| Свойство | По умолчанию | Описание |
|---|---|---|
| Скорость интерполяции | 25 | Управляет скоростью перехода движений губ между виземами. Более высокие значения приводят к более быстрым и резким переходам. |
| Сброс времени | 0.2 | Продолжительность в секундах, после которой синхронизация губ сбрасывается. Это полезно для предотвращения продолжения синхронизации губ после остановки аудио. |
Анимация смеха
Вы также можете добавить анимации смеха, которые будут динамически реагировать на смех, обнаруженный в аудио:
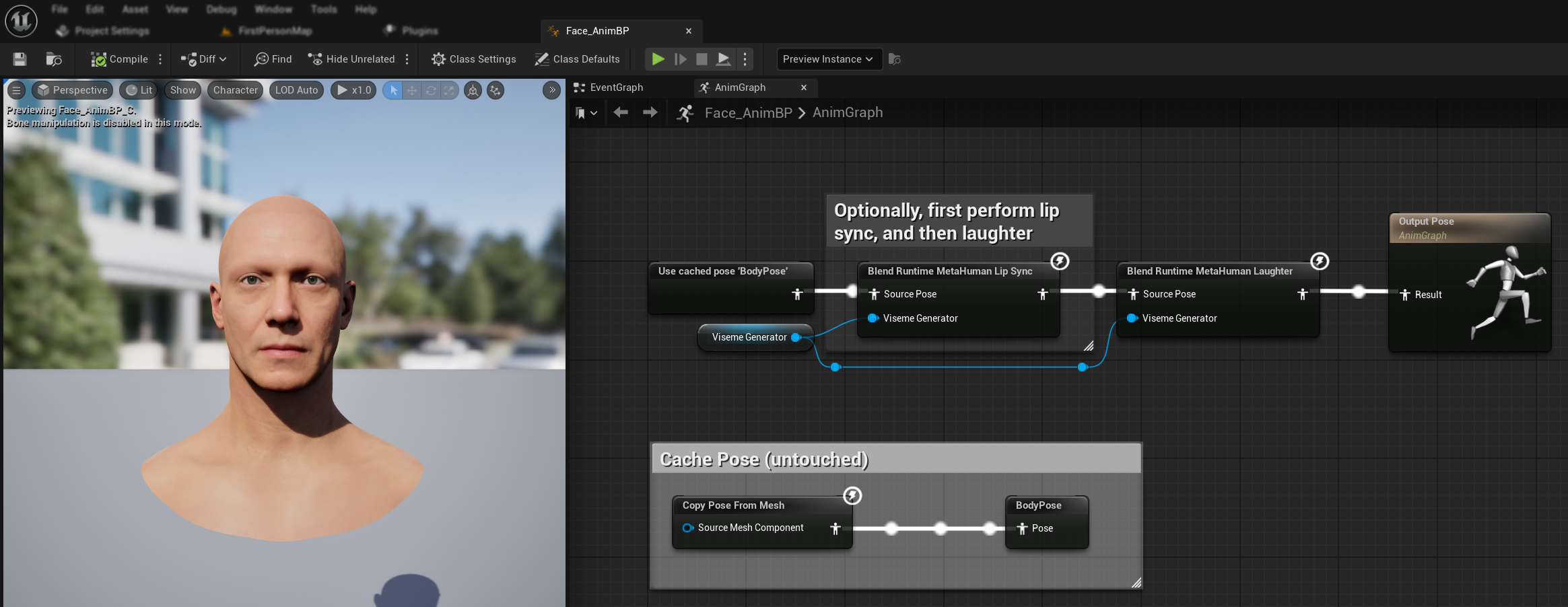
- Добавьте узел
Blend Runtime MetaHuman Laughter - Подключите вашу переменную
RuntimeVisemeGeneratorк пинуViseme Generator - Если вы уже используете синхронизацию губ:
- Подключите выход узла
Blend Runtime MetaHuman Lip Syncк входуSource PoseузлаBlend Runtime MetaHuman Laughter - Подключите выход узла
Blend Runtime MetaHuman Laughterк пинуResultвходаOutput Pose
- Подключите выход узла
- Если используется только смех без синхронизации губ:
- Подключите исходную позу напрямую к входу
Source PoseузлаBlend Runtime MetaHuman Laughter - Подключите выход к пину
Result
- Подключите исходную позу напрямую к входу
Когда в аудио обнаруживается смех, ваш персонаж будет динамически анимироваться соответствующим образом:
Конфигурация смеха
Узел Blend Runtime MetaHuman Laughter имеет собственные параметры конфигурации:
| Свойство | По умолчанию | Описание |
|---|---|---|
| Скорость интерполяции | 25 | Управляет скоростью перехода движений губ между анимациями смеха. Более высокие значения приводят к более быстрым и резким переходам. |
| Сброс времени | 0.2 | Продолжительность в секундах, после которой смех сбрасывается. Это полезно для предотвращения продолжения смеха после остановки аудио. |
| Максимальный вес смеха | 0.7 | Масштабирует максимальную интенсивность анимации смеха (0.0 - 1.0). |
Примечание: Обнаружение смеха в настоящее время доступно только в Стандартной модели.
Узел Blend Realistic MetaHuman Lip Sync имеет параметры конфигурации на панели свойств:
| Свойство | По умолчанию | Описание |
|---|---|---|
| Скорость интерполяции | 30 | Управляет скоростью перехода мимики во время активной речи. Более высокие значения приводят к более быстрым и резким переходам. |
| Скорость интерполяции в состоянии покоя | 15 | Управляет скоростью возврата выражений лица в нейтральное/спокойное состояние. Меньшие значения обеспечивают более плавный и постепенный возврат к исходной позе. |
| Сброс времени | 0.2 | Продолжительность в секундах, после которой синхронизация губ сбрасывается в состояние покоя. Полезно для предотвращения продолжения выражений после остановки аудио. |
| Сохранить состояние бездействия | ложь | Когда включено, сохраняет последнее эмоциональное состояние в периоды бездействия вместо сброса на нейтральное. |
| Сохранить выражения глаз | true | Определяет, сохраняются ли лицевые контроллеры, связанные с глазами, в состоянии покоя. Действует только при включенном параметре «Сохранять состояние покоя». |
| Сохранить выражения бровей | true | Определяет, сохраняются ли элементы управления мимикой, связанные с бровями, в состоянии покоя. Действует только при включенной опции «Сохранять состояние покоя». |
| Сохранить форму рта | ложь | Определяет, сохраняются ли элементы управления формой рта (за исключением речевых движений, таких как язык и челюсть) в состоянии покоя. Действует только при включенном параметре «Сохранять состояние покоя». |
Сохранение состояния бездействия
Функция Preserve Idle State решает вопрос обработки периодов тишины моделью Realistic. В отличие от стандартной модели, которая использует дискретные виземы и последовательно возвращается к нулевым значениям во время тишины, нейронная сеть модели Realistic может сохранять едва заметное положение лица, отличающееся от стандартной позы покоя MetaHuman.
Когда включать:
- Поддержание эмоциональных выражений между речевыми сегментами
- Сохранение черт характера персонажа
- Обеспечение визуальной непрерывности в кинематографических последовательностях
Региональные параметры управления:
- Выражения глаз: Сохраняет прищуривание, расширение и положение век
- Выражения бровей: Сохраняет положение бровей и лба
- Форма рта: Сохраняет общий изгиб рта, позволяя речевым движениям (язык, челюсть) сбрасываться
Комбинирование с существующими анимациями
Чтобы применить синхронизацию губ и смех вместе с существующей анимацией тела и пользовательской анимацией лица, не переопределяя их:
Эта настройка применяется к анимационному блюпринту лица, поскольку синхронизация губ не является частью анимационного блюпринта тела. Для пользовательских анимаций тела (например, торса, рук и других движений тела) просто подключите вашу анимационную последовательность (через Sequence Player) напрямую к выходной позе в анимационном блюпринте тела. Никаких дополнительных настроек там не требуется.
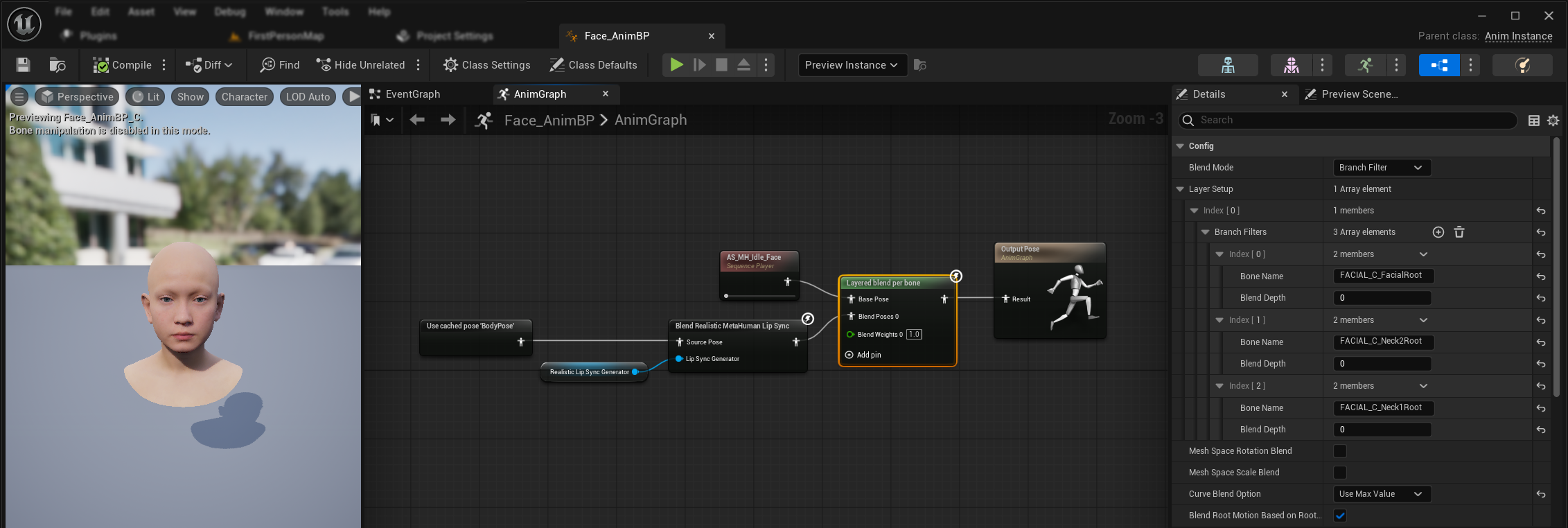
- Добавьте узел
Layered blend per boneмежду анимациями тела и финальным выходом. Убедитесь, чтоUse Attached Parentустановлено в true. - Настройте конфигурацию слоёв:
- Добавьте 1 элемент в массив
Layer Setup - Добавьте 3 элемента в
Branch Filtersдля слоя со следующимиBone Name:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Добавьте 1 элемент в массив
- Важно для пользовательских анимаций лица: В
Curve Blend Optionвыберите "Use Max Value". Это позволяет корректно накладывать пользовательские анимации лица (выражения, эмоции и т.д.) поверх синхронизации губ. - Установите соединения:
- Ваша пользовательская анимация (обычно
Sequence Playerс нужным анимационным ассетом последовательности) → входBase Pose - Вывод лицевой анимации (от узлов синхронизации губ и/или смеха) → вход
Blend Poses 0 - Узел слоистого смешивания → итоговая поза
Result
- Ваша пользовательская анимация (обычно
Выбор набора морф-целей
- Стандартная модель
- Реалистичные модели
Стандартная модель использует ассеты поз, которые по своей сути поддерживают любые соглашения об именовании морф-таргетов благодаря настройке пользовательского ассета поз. Никакой дополнительной конфигурации не требуется.
Узел Blend Realistic MetaHuman Lip Sync включает свойство Morph Target Set, которое определяет, какое соглашение об именовании морф-целей использовать для анимации лица:
| Набор целей морфинга | Описание | Варианты использования |
|---|---|---|
| MetaHuman (По умолчанию) | Стандартные имена целей морфинга MetaHuman (например, CTRL_expressions_jawOpen) | Персонажи MetaHuman |
| ARKit | Имена, совместимые с Apple ARKit (например, JawOpen, MouthSmileLeft) | Персонажи на основе ARKit |
Тонкая настройка поведения синхронизации губ
Масштабирование конкретных кривых синхронизации губ
Вы можете ослабить (или усилить) отдельные движения лица, создаваемые синхронизацией губ, с помощью узла Modify Curve. Это полезно, когда конкретная кривая выглядит слишком выраженной для вашего аудиоконтента или персонажа.
Настройка:
- После вашего узла смешивания липсинка добавьте узел
Modify Curve - Щёлкните правой кнопкой мыши по узлу и выберите Add Curve Pin, затем введите имя кривой, которую хотите масштабировать
- Установите свойство Apply Mode узла в значение Scale
- Установите параметр Value: значения ниже 1.0 ослабляют движение, значения выше 1.0 усиливают его (например, 0.8 = уменьшение на 20%)
Обычно масштабируемые кривые:
| Имя кривой | Цель | Применяется к | Типичная настройка |
|---|---|---|---|
CTRL_expressions_tongueOut | Выдвижение языка вперед при произнесении определенных фонем | Стандартная модель | 0.8 для уменьшения выступания |
CTRL_expressions_jawOpen | Диапазон открытия челюсти | Реалистичные модели | 0.9 для уменьшения движения челюсти |
Вы можете добавить несколько кривых-пинов к одному и тому же узлу Modify Curve, чтобы масштабировать сразу несколько кривых.
Тонкая настройка под конкретное настроение
Для моделей с поддержкой настроения можно тонко настраивать конкретные эмоциональные выражения:
Управление бровями:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR— подъем внутренней части бровиCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR— подъем внешней части бровиCTRL_expressions_browDownL/CTRL_expressions_browDownR— опускание брови
Управление выражением глаз:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Прищуривание глазCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Поднятие щек
Сравнение и выбор моделей
Выбор между моделями
При выборе модели синхронизации губ для вашего проекта учитывайте следующие факторы:
| Соображение | Стандартная модель | Реалистичная модель | Модель с реалистичной передачей настроения |
|---|---|---|---|
| Совместимость персонажей | Металюди и все типы пользовательских персонажей | Металюди (и персонажи ARKit) | Металюди (и персонажи ARKit) |
| Визуальное качество | Хорошая синхронизация губ с эффективной производительностью | Повышенная реалистичность за счет более естественных движений рта | Улучшенная реалистичность с эмоциональными выражениями |
| Производительность | Оптимизировано для всех платформ, включая мобильные устройства/VR. | Более высокие требования к ресурсам | Более высокие требования к ресурсам |
| Возможности | 14 висем, обнаружение смеха | 81 лицевых контроллеров, 3 уровня оптимизации | 81 лицевых контролов, 12 настроений, настраиваемый вывод |
| Поддержка платформ | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Варианты использования | Общие приложения, игры, VR/AR, мобильные устройства | Кинематографичные сцены, взаимодействия крупным планом | Эмоциональное повествование, продвинутое взаимодействие персонажей |
Совместимость версий движка
Если вы используете Unreal Engine 5.2, реалистичные модели могут работать некорректно из-за ошибки в библиотеке ресемплинга UE. Пользователям UE 5.2, которым требуется надежная функция синхронизации губ, рекомендуется использовать стандартную модель.
Эта проблема характерна для UE 5.2 и не затрагивает другие версии движка.
Рекомендации по производительности
- Для большинства проектов Стандартная модель обеспечивает отличный баланс качества и производительности
- Используйте Реалистичную модель, когда вам нужна максимальная визуальная точность для персонажей MetaHuman
- Используйте Реалистичную модель с поддержкой настроения, когда контроль эмоциональной выразительности важен для вашего приложения
- Учитывайте производительность целевой платформы при выборе между моделями
- Тестируйте различные уровни оптимизации, чтобы найти наилучший баланс для вашего конкретного случая использования
Устранение неполадок
Распространенные проблемы
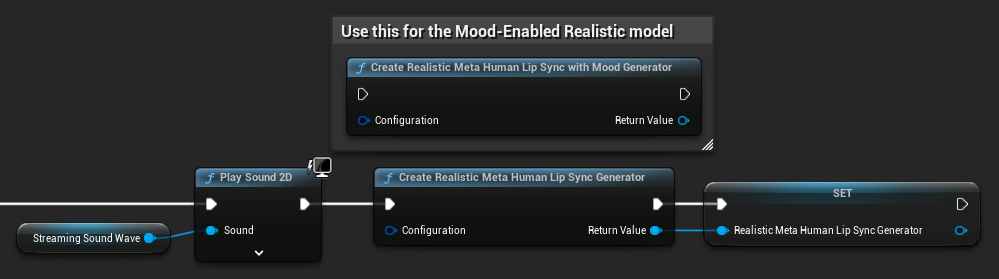
Воссоздание генератора для реалистичных моделей: Для надежной и стабильной работы с реалистичными моделями рекомендуется воссоздавать генератор каждый раз, когда вы хотите подать новые аудиоданные после периода бездействия. Это связано с поведением среды выполнения ONNX, которое может привести к остановке синхронизации губ при повторном использовании генераторов после периодов тишины.
Например, вы можете пересоздавать генератор синхронизации губ при каждом запуске воспроизведения, например, всякий раз, когда вы вызываете Play Sound 2D или используете любой другой метод для запуска воспроизведения звуковой волны и синхронизации губ:
Расположение плагина для интеграции Runtime Text To Speech: При совместном использовании Runtime MetaHuman Lip Sync и Runtime Text To Speech (оба плагина используют ONNX Runtime) в собранных сборках могут возникать проблемы, если плагины установлены в папку Marketplace движка. Чтобы это исправить:
- Найдите оба плагина в папке установки UE по пути
\Engine\Plugins\Marketplace(например,C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Переместите обе папки
RuntimeMetaHumanLipSyncиRuntimeTextToSpeechв папкуPluginsвашего проекта - Если в вашем проекте нет папки
Plugins, создайте её в той же директории, где находится файл.uproject - Перезапустите редактор Unreal
Это решает проблемы совместимости, которые могут возникать при загрузке нескольких плагинов на основе ONNX Runtime из каталога Marketplace движка.
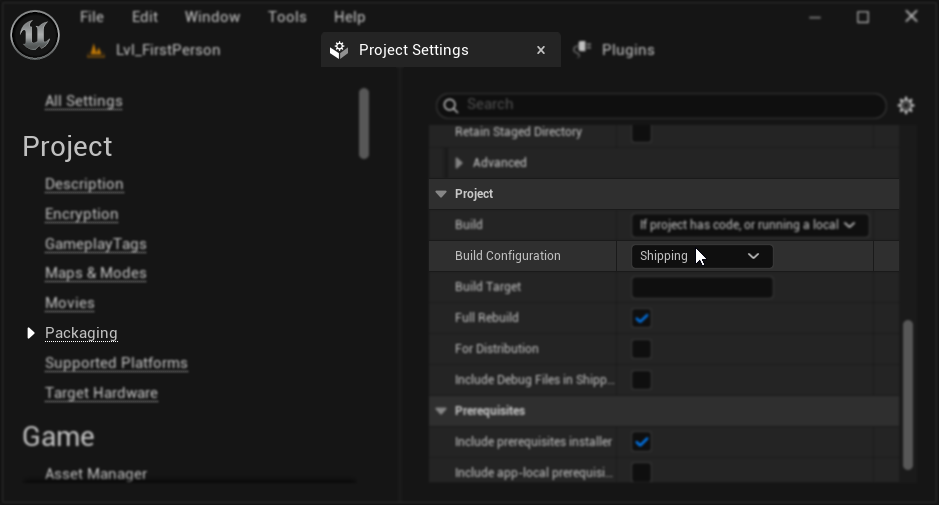
Конфигурация упаковки (Windows): Если синхронизация губ не работает должным образом в вашем упакованном проекте на Windows, убедитесь, что вы используете конфигурацию сборки Shipping вместо Development. Конфигурация Development может вызывать проблемы с ONNX-средой выполнения реалистичных моделей в упакованных сборках.
Чтобы исправить это:
- В настройках вашего проекта → Упаковка установите конфигурацию сборки на Shipping
- Перепакуйте ваш проект
В некоторых проектах, использующих только Blueprint, Unreal Engine может по-прежнему выполнять сборку в конфигурации Development, даже если выбрана конфигурация Shipping. Если это происходит, преобразуйте ваш проект в проект C++, добавив хотя бы один класс C++ (он может быть пустым). Для этого перейдите в Tools → New C++ Class в меню редактора UE и создайте пустой класс. Это заставит проект правильно собираться в конфигурации Shipping. Ваш проект может оставаться функционально основанным только на Blueprint — класс C++ нужен лишь для корректной конфигурации сборки.
Ухудшение отзывчивости синхронизации губ: Если вы замечаете, что синхронизация губ со временем становится менее отзывчивой при использовании Streaming Sound Wave или Capturable Sound Wave, это может быть вызвано накоплением памяти. По умолчанию память перераспределяется каждый раз при добавлении нового аудио. Чтобы предотвратить эту проблему, периодически вызывайте функцию ReleaseMemory для освобождения накопленной памяти, например, каждые 30 секунд.
Оптимизация производительности:
- Настройте размер обрабатываемого фрагмента для реалистичных моделей в соответствии с вашими требованиями к производительности
- Используйте подходящее количество потоков для вашего целевого оборудования
- Рассмотрите возможность использования типа вывода «Только рот» для моделей с поддержкой настроения, когда полная анимация лица не требуется