Список параметров распознавания
Эти параметры можно установить только когда распознаватель не работает.
Это не исчерпывающий список параметров, доступных в Whisper. Здесь представлены только самые важные. При необходимости этот список будет обновлен.
Установить параметры распознавания
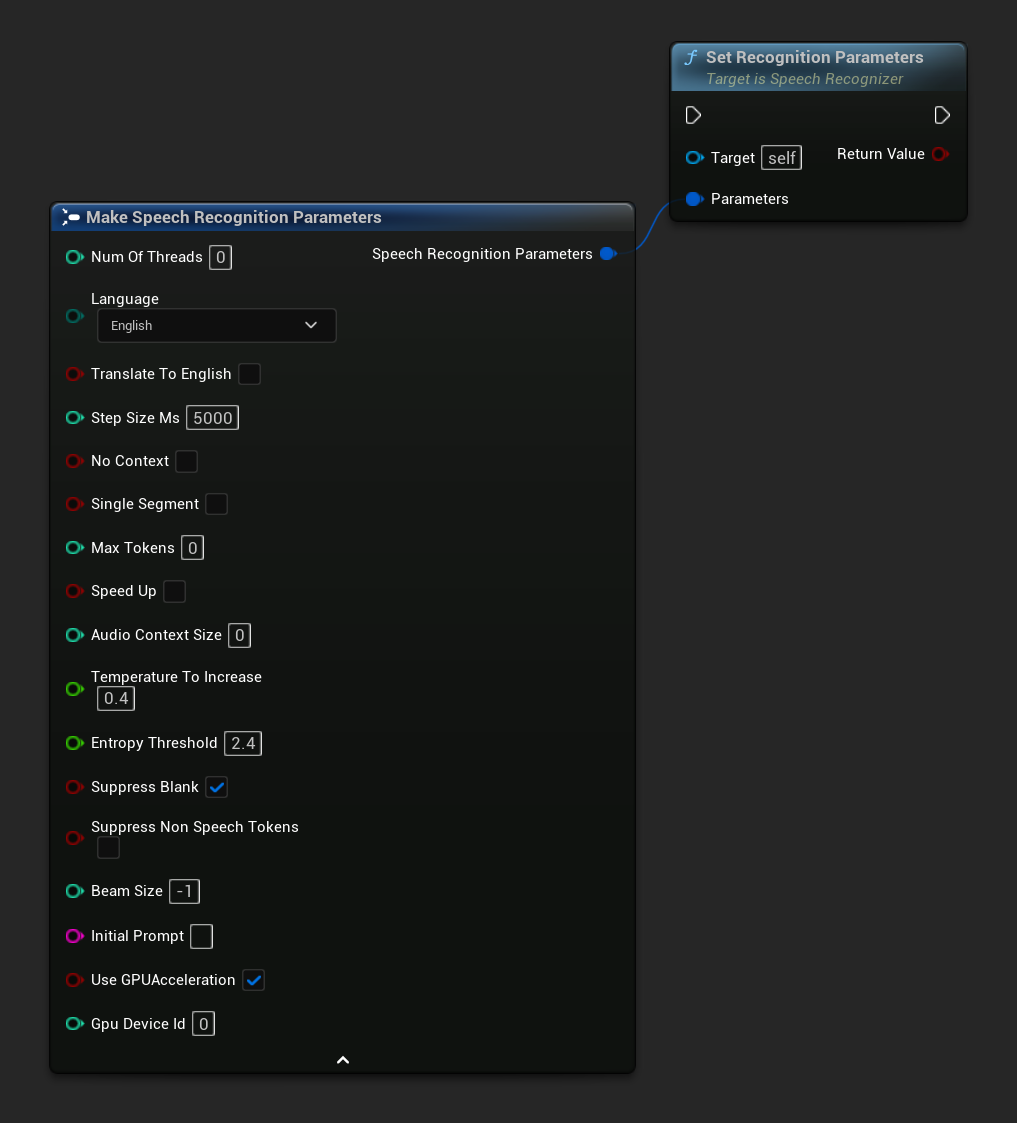
Устанавливает параметры для распознавания речи. Если вы хотите изменить только определенные параметры, рассмотрите использование отдельных функций-сеттеров.
Установить параметры по умолчанию для потокового режима
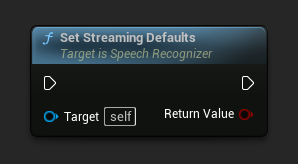
Устанавливает параметры по умолчанию, подходящие для потокового распознавания речи.
Эта функция перезаписывает все ранее примененные параметры. Убедитесь, что вызываете её перед установкой ваших пользовательских параметров, если вам нужно использовать настройки потокового режима по умолчанию в качестве базовой конфигурации.
Установить параметры по умолчанию для не-потокового режима
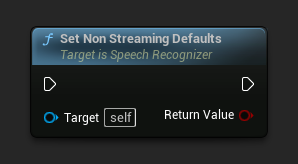
Устанавливает параметры по умолчанию, подходящие для не-потокового распознавания речи.
Эта функция перезаписывает все ранее примененные параметры. Убедитесь, что вызываете её перед установкой ваших пользовательских параметров, если вам нужно использовать настройки не-потокового режима по умолчанию в качестве базовой конфигурации.
Установить количество потоков
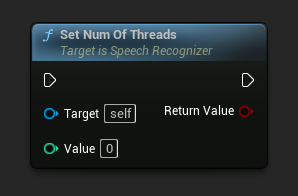
Устанавливает количество потоков для использования в распознавании речи. Установите это значение в 0, чтобы использовать количество ядер процессора.
Установить язык
Устанавливает язык для использования в распознавании речи. Должен поддерживаться выбранной языковой моделью в настройках редактора.
Установка языка в Auto снизит точность и производительность распознавания.
Получить обнаруженный язык
Получает обнаруженный язык из последнего распознавания. Возвращает язык в виде значения перечисления.
Примечание: Эта функция работает только после выполнения распознавания. Она возвращает Auto, если определение языка не удалось или не выполнялось. Это особенно полезно при использовании автоматического определения языка для идентификации того, какой язык был фактически распознан.
Получить код языка
Преобразует значение перечисления языка в его строковый код (например, En -> "en", Fr -> "fr", De -> "de").
Получить полное название языка
Преобразует значение перечисления языка в его полное название (например, En -> "English", Fr -> "French", De -> "German").
Установить перевод на английский
![]()
Устанавливает, следует ли переводить распознанные слова на английский язык. Если true, языковая модель должна быть многоязычной.
Установить размер шага
Устанавливает размер шага в миллисекундах. Определяет, как часто отправлять аудиоданные для распознавания. Значение по умолчанию — 5000 мс (5 секунд).
Установить отсутствие контекста
Устанавливает, использовать ли прошлую транскрипцию (если есть) в качестве начального промпта для декодера.
Установить одиночный сегмент
Устанавливает, принудительно ли выводить одиночный сегмент (полезно для потокового режима).
Установить максимальное количество токенов
Устанавливает максимальное количество токенов на текстовый сегмент. Используйте 0 для отсутствия ограничения.
Установить ускорение
Устанавливает, ускорять ли распознавание в 2 раза с использованием Phase Vocoder. Установите как false, чтобы улучшить качество вывода.
Установить размер аудиоконтекста
Устанавливает размер аудиоконтекста. Установите как 0, чтобы улучшить качество вывода.
Установить температуру для увеличения
Устанавливает температуру для увеличения при откате, когда декодирование не соответствует ни одному из пороговых значений ниже.
Установить порог энтропии
Устанавливает порог энтропии. Если коэффициент сжатия выше этого значения, считать декодирование неудачным. Аналогично "compression_ratio_threshold" от OpenAI
Установить подавление пробелов
![]()
Устанавливает, подавлять ли появление пробелов в выводе.
Установить подавление неречевых токенов
Устанавливает, подавлять ли появление неречевых токенов в выводе.
Установить размер луча
Установите количество лучей в поиске по лучу. Применимо только когда температура равна нулю.
Установить начальный промпт
Устанавливает начальный промпт для первого окна. Это можно использовать для предоставления контекста для распознавания, чтобы повысить вероятность правильного предсказания слов, например, пользовательские словари или имена собственные.
Для получения более подробной информации о стратегиях эффективного промптинга см. Руководство по промптингу Whisper.
Установить ускорение на GPU
Устанавливает, использовать ли ускорение на GPU для распознавания речи (в настоящее время применимо только на Windows).
Установить ID устройства GPU
Устанавливает ID устройства GPU для использования в распознавании речи. Значение по умолчанию — 0. Это полезно для систем с несколькими GPU, чтобы указать, какой GPU должен использоваться для процесса распознавания. Если указанный ID устройства GPU недействителен, вместо него будет использован первый доступный индекс устройства GPU.