Как использовать плагин
Плагин Runtime Text To Speech синтезирует текст в речь с использованием загружаемых голосовых моделей. Этими моделями управляют в настройках плагина внутри редактора, их загружают и упаковывают для использования во время выполнения. Следуйте приведенным ниже шагам, чтобы начать работу.
Сторона редактора
Загрузите подходящие голосовые модели для вашего проекта, как описано здесь. Вы можете загружать несколько голосовых моделей одновременно.
Сторона выполнения
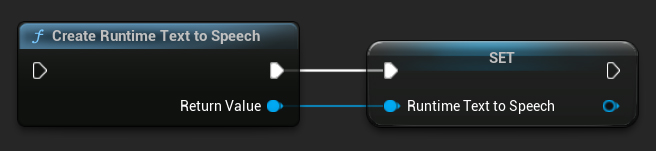
Создайте синтезатор с помощью функции CreateRuntimeTextToSpeech. Убедитесь, что вы сохраняете ссылку на него (например, как отдельную переменную в Blueprints или UPROPERTY в C++), чтобы предотвратить его сборку мусора.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Синтез речи
Плагин предлагает два режима синтеза речи из текста:
- Обычный синтез речи: Синтезирует весь текст и возвращает полное аудио по завершении
- Потоковый синтез речи: Предоставляет аудиофрагменты по мере их генерации, позволяя обрабатывать их в реальном времени
Каждый режим поддерживает два метода выбора голосовых моделей:
- По имени: Выбор голосовой модели по её имени (рекомендуется для UE 5.4+)
- По объекту: Выбор голосовой модели через прямую ссылку (рекомендуется для UE 5.3 и более ранних версий)
Обычный синтез речи
По имени
- Blueprint
- C++
Функция Text To Speech (By Name) более удобна в Blueprints начиная с UE 5.4. Она позволяет выбирать голосовые модели из выпадающего списка загруженных моделей. В версиях UE ниже 5.3 этот выпадающий список не отображается, поэтому если вы используете более старую версию, вам нужно будет вручную перебирать массив голосовых моделей, возвращаемый функцией GetDownloadedVoiceModels, чтобы выбрать нужную.
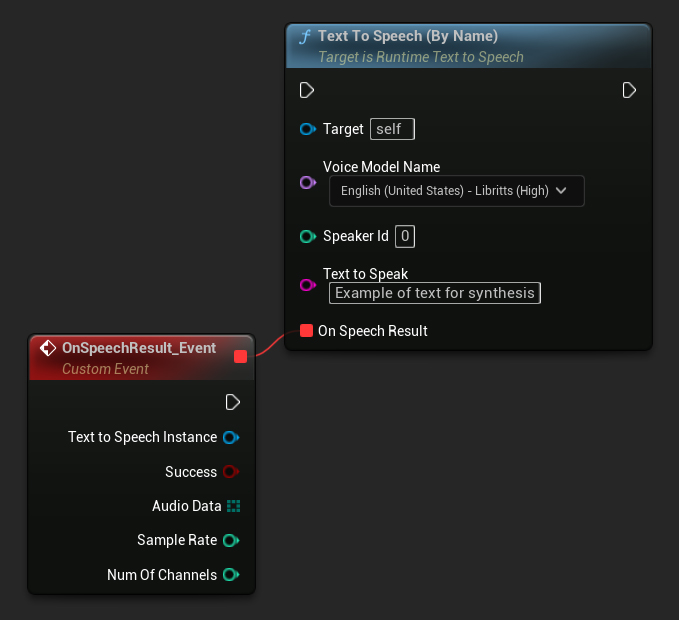
В C++ выбор голосовых моделей может быть немного сложнее из-за отсутствия выпадающего списка. Вы можете использовать функцию GetDownloadedVoiceModelNames для получения имён загруженных голосовых моделей и выбрать нужную. После этого вы можете вызвать функцию TextToSpeechByName для синтеза текста с использованием выбранного имени голосовой модели.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
По Объекту
- Blueprint
- C++
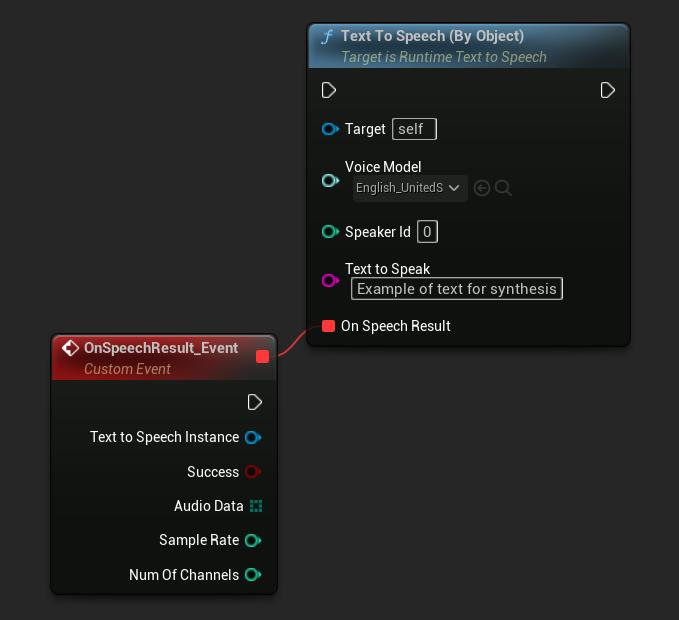
Функция Text To Speech (By Object) работает во всех версиях Unreal Engine, но представляет голосовые модели в виде выпадающего списка ссылок на ассеты, что менее интуитивно. Этот метод подходит для UE 5.3 и более ранних версий, или если ваш проект требует прямую ссылку на ассет голосовой модели по какой-либо причине.
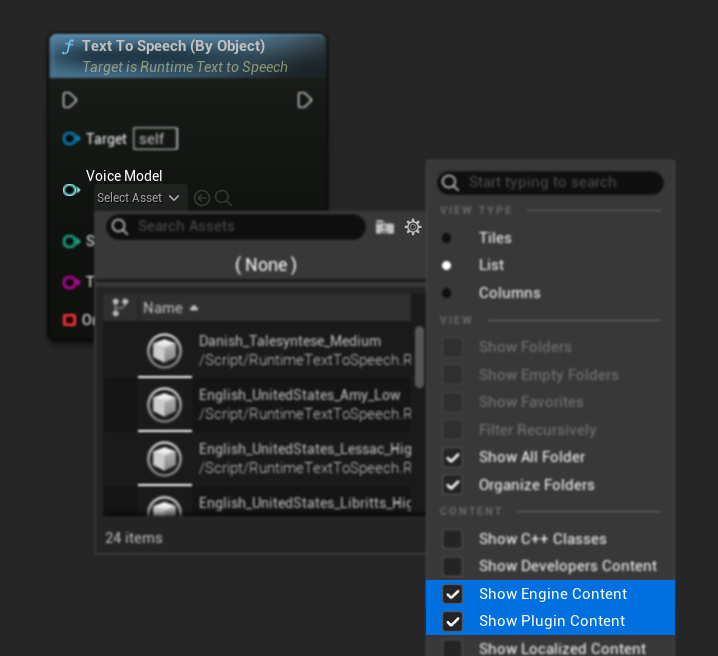
Если вы скачали модели, но не видите их, откройте выпадающий список Voice Model, нажмите на настройки (иконка шестеренки) и включите как Show Plugin Content, так и Show Engine Content, чтобы модели стали видны.
В C++ выбор голосовых моделей может быть немного сложнее из-за отсутствия выпадающего списка. Вы можете использовать функцию GetDownloadedVoiceModelNames для получения имен скачанных голосовых моделей и выбрать нужную. Затем вы можете вызвать функцию GetVoiceModelFromName, чтобы получить объект голосовой модели, и передать его в функцию TextToSpeechByObject для синтеза текста.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Потоковое преобразование текста в речь
Для длинных текстов или когда вы хотите обрабатывать аудиоданные в реальном времени по мере их генерации, вы можете использовать потоковые версии функций Text-to-Speech:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNameв C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjectв C++)
Эти функции предоставляют аудиоданные частями по мере их генерации, позволяя немедленно обрабатывать их без ожидания завершения всего синтеза. Это полезно для различных приложений, таких как воспроизведение аудио в реальном времени, живая визуализация или любые сценарии, где вам нужно обрабатывать речевые данные инкрементально.
Потоковое преобразование по имени
- Blueprint
- C++
Функция Streaming Text To Speech (By Name) работает аналогично обычной версии, но предоставляет аудио частями через делегат On Speech Chunk.
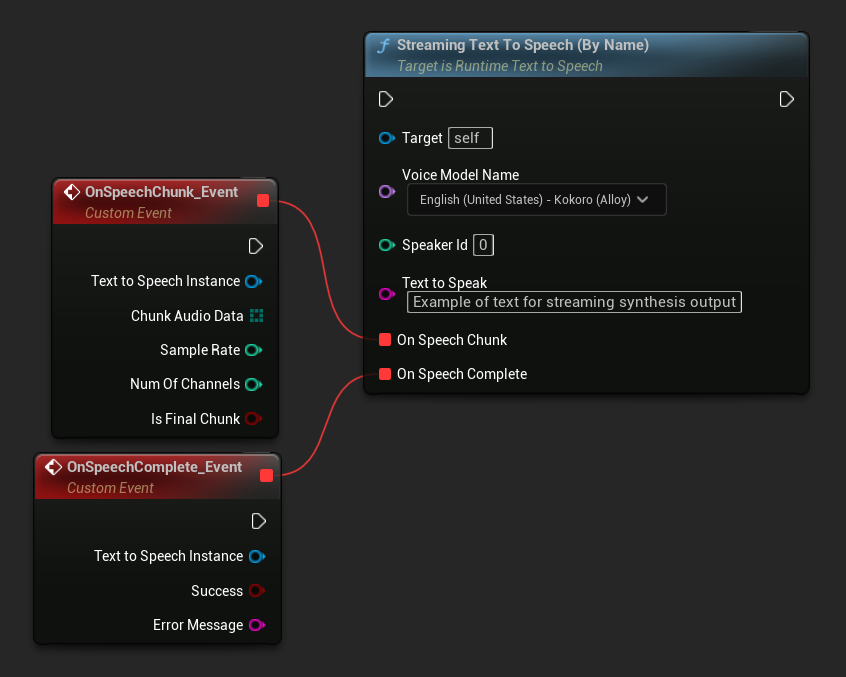
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Стриминг По Объекту
- Blueprint
- C++
Функция Streaming Text To Speech (By Object) предоставляет ту же стриминговую функциональность, но принимает ссылку на объект голосовой модели.
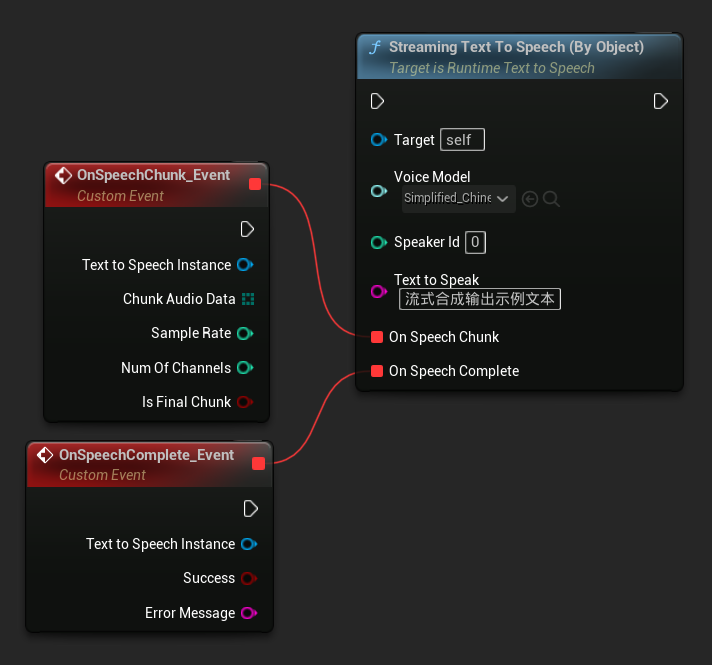
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Воспроизведение аудио
- Обычное воспроизведение
- Streaming Playback
Для обычного (не потокового) преобразования текста в речь, делегат On Speech Result предоставляет синтезированное аудио в формате PCM с данными в формате float (в виде массива байтов в Blueprints или TArray<uint8> в C++), вместе с Sample Rate (частотой дискретизации) и Num Of Channels (количеством каналов).
Для воспроизведения рекомендуется использовать плагин Runtime Audio Importer для преобразования сырых аудиоданных в воспроизводимую звуковую волну.
- Blueprint
- C++
Вот пример того, как могут выглядеть ноды Blueprint для синтеза текста и воспроизведения аудио (Копируемые ноды):
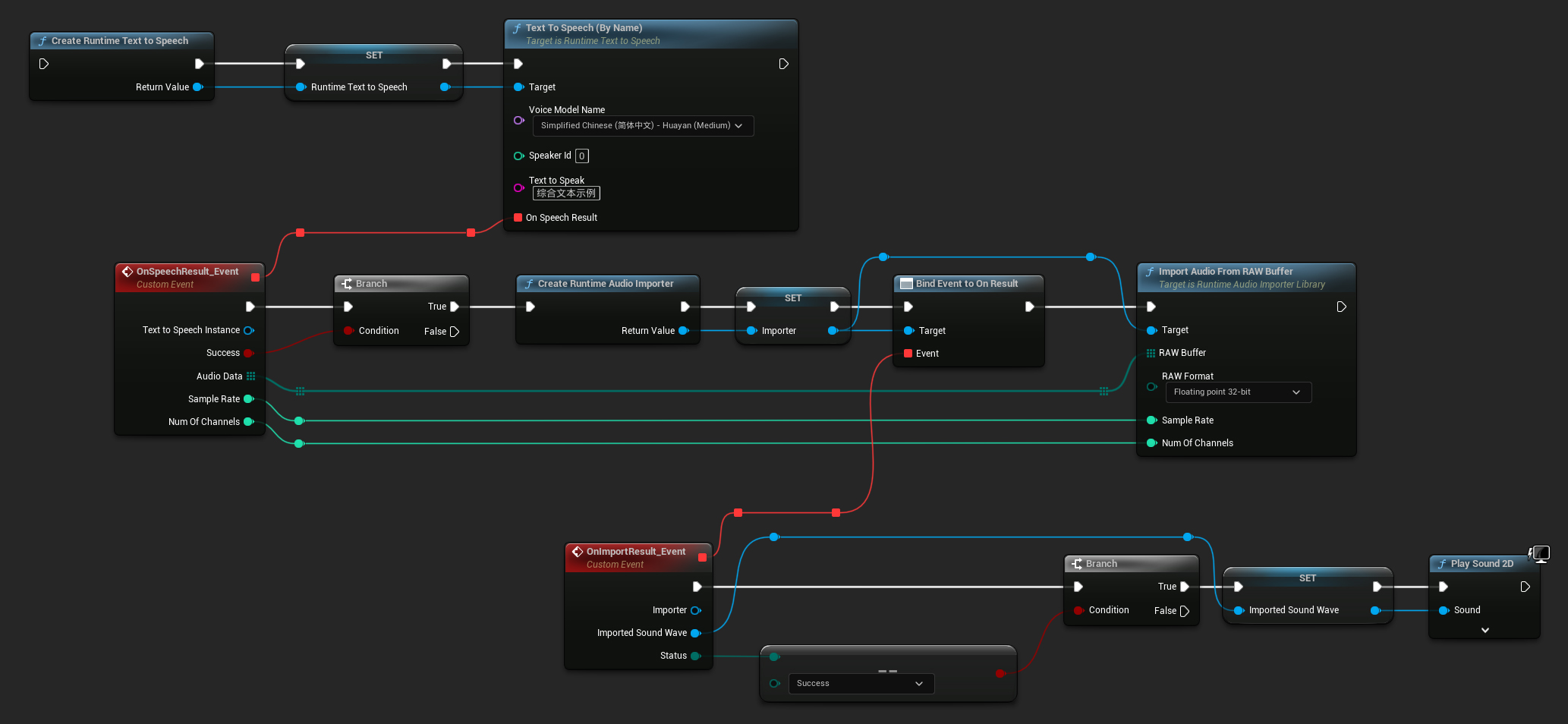
Вот пример того, как синтезировать текст и воспроизвести аудио в C++:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Для потокового преобразования текста в речь вы будете получать аудиоданные частями в формате PCM в формате float (в виде массива байтов в Blueprints или TArray<uint8> в C++), вместе с Sample Rate и Num Of Channels. Каждая часть может быть обработана немедленно по мере поступления.
Для воспроизведения в реальном времени рекомендуется использовать Streaming Sound Wave плагина Runtime Audio Importer, который специально разработан для потокового воспроизведения аудио или обработки в реальном времени.
- Blueprint
- C++
Вот пример того, как могут выглядеть ноды Blueprint для потокового преобразования текста в речь и воспроизведения аудио (Копируемые ноды):
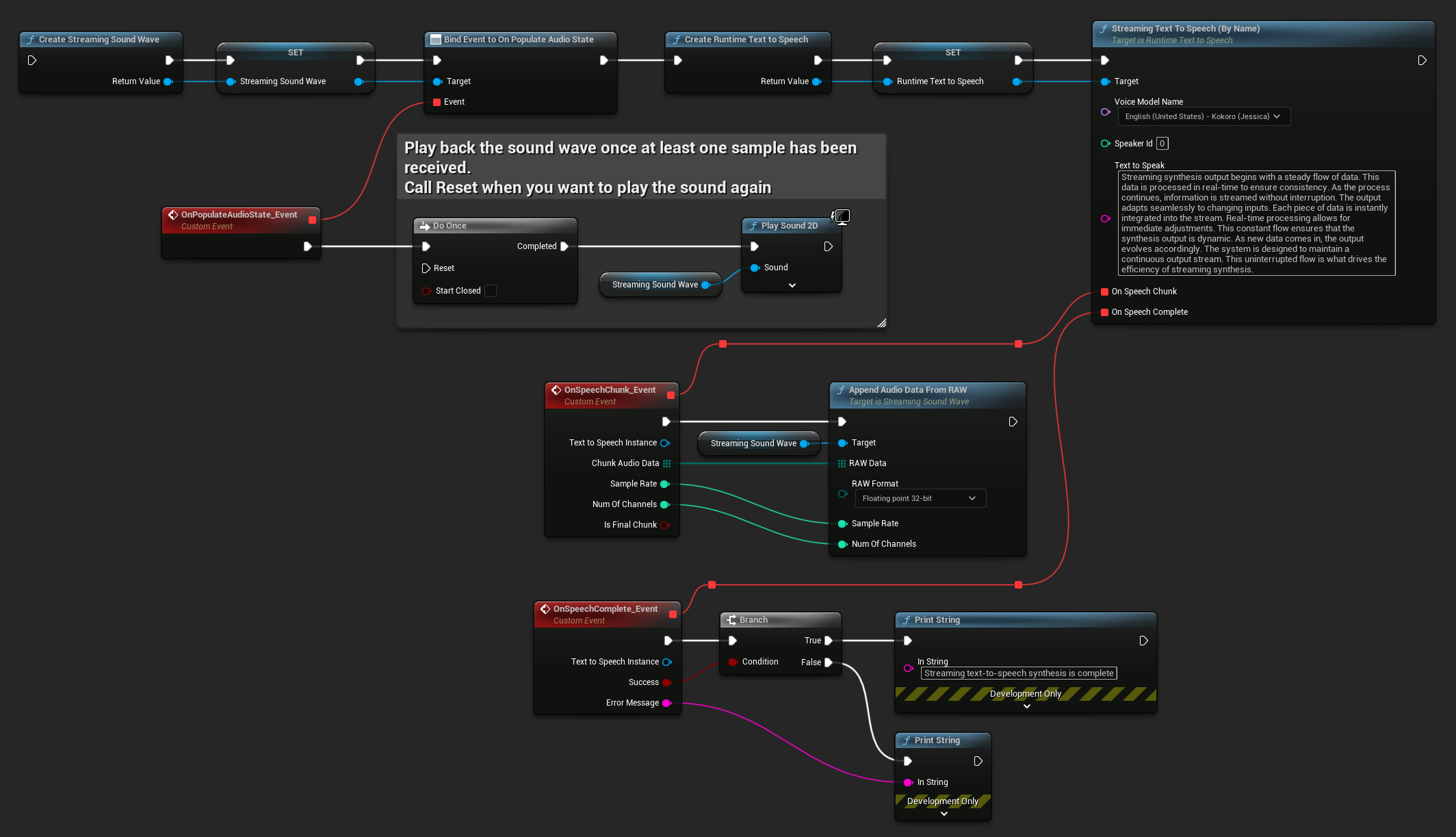
Вот пример реализации потокового преобразования текста в речь с воспроизведением в реальном времени на C++:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Отмена преобразования текста в речь
Вы можете отменить выполняющуюся операцию синтеза речи в любое время, вызвав функцию CancelSpeechSynthesis на вашем экземпляре синтезатора:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Когда синтез отменяется:
- Процесс синтеза остановится как можно скорее
- Все выполняемые обратные вызовы будут прерваны
- Делегат завершения будет вызван с
bSuccess = falseи сообщением об ошибке, указывающим, что синтез был отменен - Все ресурсы, выделенные для синтеза, будут корректно очищены
Это особенно полезно для длинных текстов или когда необходимо прервать воспроизведение, чтобы начать новый синтез.
Выбор диктора
Обе функции Text To Speech принимают необязательный параметр ID диктора, который полезен при работе с голосовыми моделями, поддерживающими нескольких дикторов. Вы можете использовать функции GetSpeakerCountFromVoiceModel или GetSpeakerCountFromModelName, чтобы проверить, поддерживает ли выбранная вами голосовая модель нескольких дикторов. Если доступно несколько дикторов, просто укажите желаемый ID диктора при вызове функций Text To Speech. Некоторые голосовые модели предлагают большое разнообразие - например, English LibriTTS включает более 900 различных дикторов на выбор.
Плагин Runtime Audio Importer также предоставляет дополнительные функции, такие как экспорт аудиоданных в файл, передача их в SoundCue, MetaSound и многое другое. Для получения дополнительной информации ознакомьтесь с документацией Runtime Audio Importer.