Plugin Configuration
Model Configuration
For reliable operation with the Realistic and Mood-Enabled Realistic models, recreate the generator before each new audio playback rather than reusing one across long silences. See Generator Recreation in Troubleshooting for details.
Standard Model Configuration
The Create Runtime Viseme Generator node uses default settings that work well for most scenarios. Configuration is handled through the Animation Blueprint blending node properties.
For Animation Blueprint configuration options, see the Lip Sync Configuration section below.
Realistic Model Configuration
The Create Realistic MetaHuman Lip Sync Generator node accepts an optional Configuration parameter that allows you to customize the generator's behavior:
Model Type
The Model Type setting determines which version of the realistic model to use:
| Model Type | Performance | Visual Quality | Noise Handling | Recommended Use Cases |
|---|---|---|---|---|
| Highly Optimized (Default) | Highest performance, lowest CPU usage | Good quality | May show noticeable mouth movements with background noise or non-voice sounds | Clean audio environments, performance-critical scenarios |
| Semi-Optimized | Good performance, moderate CPU usage | High quality | Better stability with noisy audio | Balanced performance and quality, mixed audio conditions |
| Original | Suitable for real-time use on modern CPUs | Highest quality | Most stable with background noise and non-voice sounds | High-quality productions, noisy audio environments, when maximum accuracy is needed |
Performance Settings
Intra Op Threads: Controls the number of threads used for internal model processing operations.
- 0 (Default/Automatic): Uses automatic detection (typically 1/4 of available CPU cores, maximum 4)
- 1-16: Manually specify thread count. Higher values may improve performance on multi-core systems but use more CPU
Inter Op Threads: Controls the number of threads used for parallel execution of different model operations.
- 0 (Default/Automatic): Uses automatic detection (typically 1/8 of available CPU cores, maximum 2)
- 1-8: Manually specify thread count. Usually kept low for real-time processing
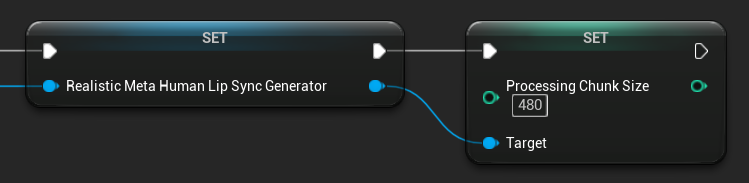
Processing Chunk Size
The Processing Chunk Size determines how many samples are processed in each inference step. The default value is 160 samples (10ms of audio at 16kHz):
- Smaller values provide more frequent updates but increase CPU usage
- Larger values reduce CPU load but may decrease lip sync responsiveness
- Recommended to use multiples of 160 for optimal alignment
Mood-Enabled Model Configuration
The Create Realistic MetaHuman Lip Sync With Mood Generator node provides additional configuration options beyond the basic realistic model:
Basic Configuration
Lookahead Ms: Lookahead timing in milliseconds for improved lip sync accuracy.
- Default: 80ms
- Range: 20ms to 200ms (must be divisible by 20)
- Higher values provide better synchronization but increase latency
Output Type: Controls which facial controls are generated.
- Full Face: All 81 facial controls (eyebrows, eyes, nose, mouth, jaw, tongue)
- Mouth Only: Only mouth, jaw, and tongue-related controls
Performance Settings: Uses the same Intra Op Threads and Inter Op Threads settings as the regular realistic model.
Mood Settings
Available Moods:
- Neutral, Happy, Sad, Disgust, Anger, Surprise, Fear
- Confident, Excited, Bored, Playful, Confused
Mood Intensity: Controls how strongly the mood affects the animation (0.0 to 1.0)
Runtime Mood Control
You can adjust mood settings during runtime using the following functions:
- Set Mood: Change the current mood type
- Set Mood Intensity: Adjust how strongly the mood affects the animation (0.0 to 1.0)
- Set Lookahead Ms: Modify the lookahead timing for synchronization
- Set Output Type: Switch between Full Face and Mouth Only controls

Mood Selection Guide
Choose appropriate moods based on your content:
| Mood | Best For | Typical Intensity Range |
|---|---|---|
| Neutral | General conversation, narration, default state | 0.5 - 1.0 |
| Happy | Positive content, cheerful dialogue, celebrations | 0.6 - 1.0 |
| Sad | Melancholic content, emotional scenes, somber moments | 0.5 - 0.9 |
| Disgust | Negative reactions, distasteful content, rejection | 0.4 - 0.8 |
| Anger | Aggressive dialogue, confrontational scenes, frustration | 0.6 - 1.0 |
| Surprise | Unexpected events, revelations, shock reactions | 0.7 - 1.0 |
| Fear | Threatening situations, anxiety, nervous dialogue | 0.5 - 0.9 |
| Confident | Professional presentations, leadership dialogue, assertive speech | 0.7 - 1.0 |
| Excited | Energetic content, announcements, enthusiastic dialogue | 0.8 - 1.0 |
| Bored | Monotonous content, disinterested dialogue, tired speech | 0.3 - 0.7 |
| Playful | Casual conversation, humor, light-hearted interactions | 0.6 - 0.9 |
| Confused | Question-heavy dialogue, uncertainty, bewilderment | 0.4 - 0.8 |
Animation Blueprint Configuration
Lip Sync Configuration
- Standard Model
- Realistic Models
The Blend Runtime MetaHuman Lip Sync node has configuration options in its properties panel:
| Property | Default | Description |
|---|---|---|
| Interpolation Speed | 25 | Controls how quickly the lip movements transition between visemes. Higher values result in faster, more abrupt transitions. |
| Reset Time | 0.2 | The duration in seconds after which the lip sync is reset. This is useful to prevent the lip sync from continuing after the audio has stopped. |
Laughter Animation
You can also add laughter animations that will dynamically respond to laughter detected in the audio:
- Add the
Blend Runtime MetaHuman Laughternode - Connect your
RuntimeVisemeGeneratorvariable to theViseme Generatorpin - If you're already using lip sync:
- Connect the output from the
Blend Runtime MetaHuman Lip Syncnode to theSource Poseof theBlend Runtime MetaHuman Laughternode - Connect the output of the
Blend Runtime MetaHuman Laughternode to theResultpin of theOutput Pose
- Connect the output from the
- If using only laughter without lip sync:
- Connect your source pose directly to the
Source Poseof theBlend Runtime MetaHuman Laughternode - Connect the output to the
Resultpin
- Connect your source pose directly to the
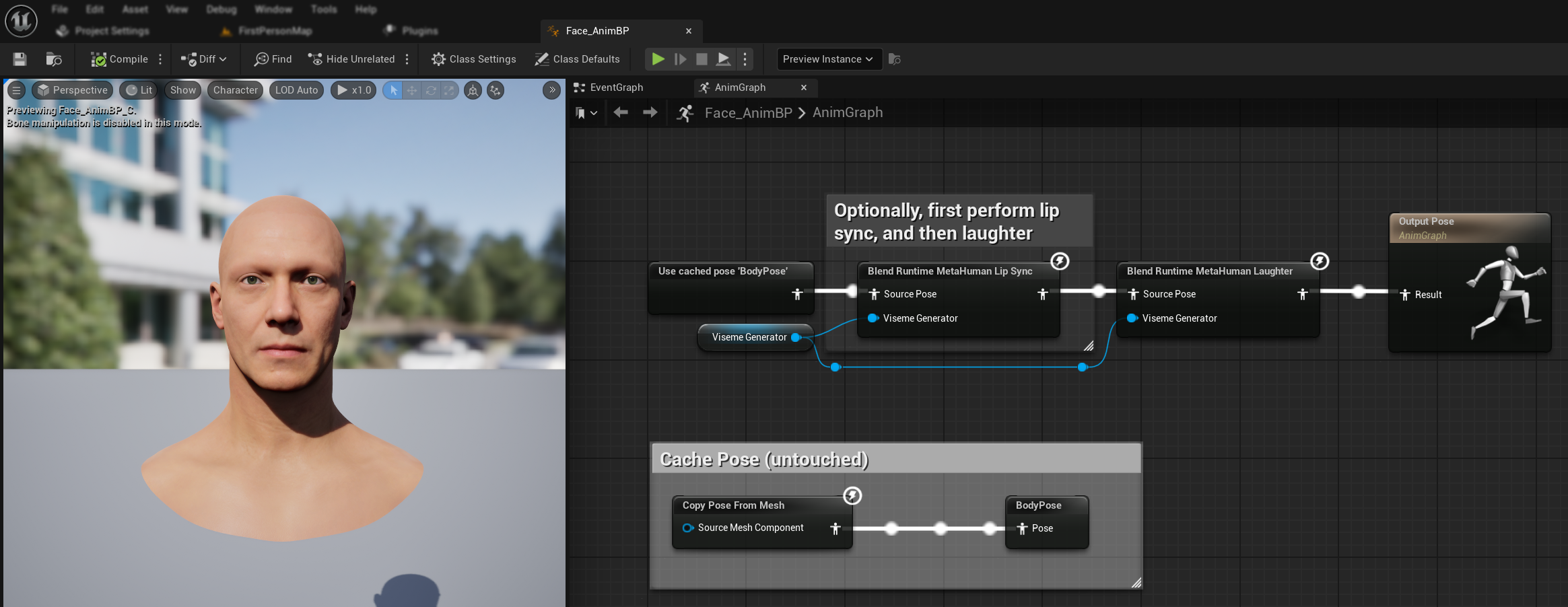
When laughter is detected in the audio, your character will dynamically animate accordingly:
Laughter Configuration
The Blend Runtime MetaHuman Laughter node has its own configuration options:
| Property | Default | Description |
|---|---|---|
| Interpolation Speed | 25 | Controls how quickly the lip movements transition between laughter animations. Higher values result in faster, more abrupt transitions. |
| Reset Time | 0.2 | The duration in seconds after which the laughter is reset. This is useful to prevent the laughter from continuing after the audio has stopped. |
| Max Laughter Weight | 0.7 | Scales the maximum intensity of the laughter animation (0.0 - 1.0). |
Note: Laughter detection is currently available only with the Standard Model.
The Blend Realistic MetaHuman Lip Sync node has configuration options in its properties panel:
| Property | Default | Description |
|---|---|---|
| Interpolation Speed | 30 | Controls how quickly facial expressions transition during active speech. Higher values result in faster, more abrupt transitions. |
| Idle Interpolation Speed | 15 | Controls how quickly facial expressions transition back to idle/neutral state. Lower values create smoother, more gradual returns to rest pose. |
| Reset Time | 0.2 | Duration in seconds after which lip sync resets to idle state. Useful to prevent expressions from continuing after audio stops. |
| Preserve Idle State | false | When enabled, preserves the last emotional state during idle periods instead of resetting to neutral. |
| Preserve Eye Expressions | true | Controls whether eye-related facial controls are preserved during idle state. Only effective when Preserve Idle State is enabled. |
| Preserve Brow Expressions | true | Controls whether eyebrow-related facial controls are preserved during idle state. Only effective when Preserve Idle State is enabled. |
| Preserve Mouth Shape | false | Controls whether mouth shape controls (excluding speech-specific movements like tongue and jaw) are preserved during idle state. Only effective when Preserve Idle State is enabled. |
Idle State Preservation
The Preserve Idle State feature addresses how the Realistic model handles silence periods. Unlike the Standard model which uses discrete visemes and consistently returns to zero values during silence, the Realistic model's neural network may maintain subtle facial positioning that differs from the MetaHuman's default rest pose.
When to Enable:
- Maintaining emotional expressions between speech segments
- Preserving character personality traits
- Ensuring visual continuity in cinematic sequences
Regional Control Options:
- Eye Expressions: Preserves eye squinting, widening, and eyelid positioning
- Brow Expressions: Maintains eyebrow and forehead positioning
- Mouth Shape: Keeps general mouth curvature while allowing speech movements (tongue, jaw) to reset
Combining with Existing Animations
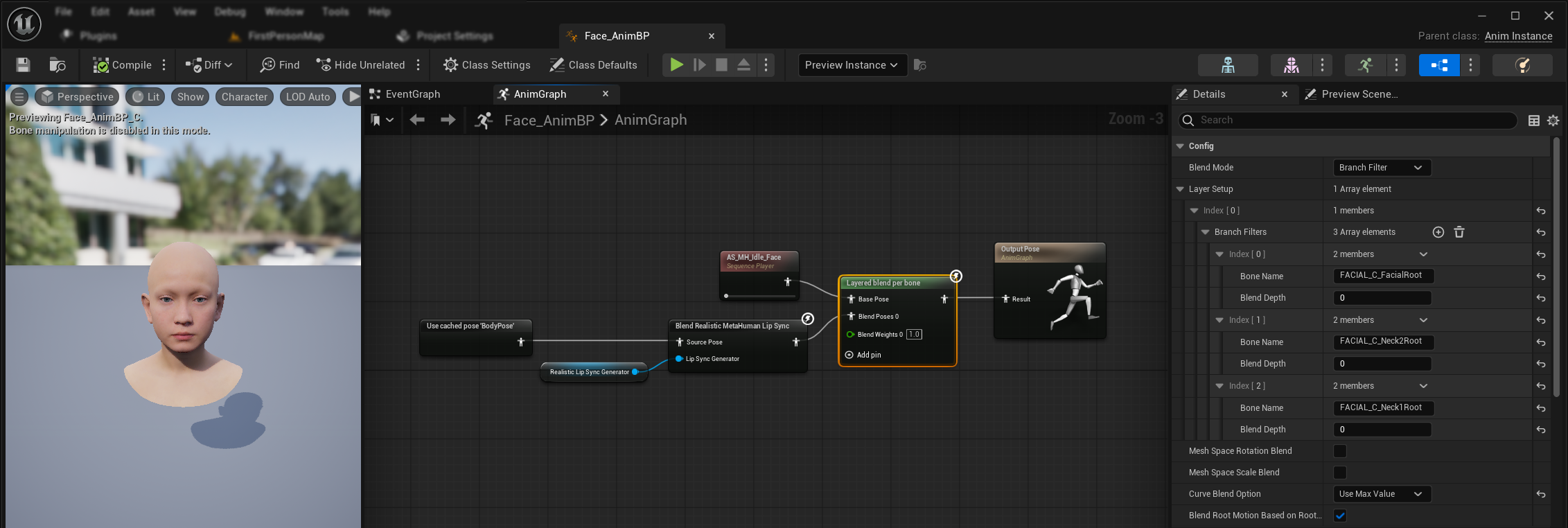
To apply lip sync and laughter alongside existing body animations and custom facial animations without overriding them:
This setup applies to the face Animation Blueprint, since lip sync is not part of the body Animation Blueprint. For custom body animations (e.g. torso, arms, and other body movement), simply connect your animation sequence (via a Sequence Player) directly to the output pose in the body Animation Blueprint. No additional setup is needed there.
- Add a
Layered blend per bonenode between your body animations and the final output. Make sureUse Attached Parentis true. - Configure the layer setup:
- Add 1 item to the
Layer Setuparray - Add 3 items to the
Branch Filtersfor the layer, with the followingBone Names:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Add 1 item to the
- Important for custom facial animations: In the
Curve Blend Option, select "Use Max Value". This allows custom facial animations (expressions, emotions, etc.) to be properly layered on top of the lip sync. - Make the connections:
- Your custom animation (typically a
Sequence Playerwith the desired animation sequence asset) →Base Poseinput - Facial animation output (from lip sync and/or laughter nodes) →
Blend Poses 0input - Layered blend node → Final
Resultpose
- Your custom animation (typically a
Morph Target Set Selection
- Standard Model
- Realistic Models
The Standard Model uses pose assets which inherently support any morph target naming convention through the custom pose asset setup. No additional configuration is needed.
The Blend Realistic MetaHuman Lip Sync node includes a Morph Target Set property that determines which morph target naming convention to use for facial animation:
| Morph Target Set | Description | Use Cases |
|---|---|---|
| MetaHuman (Default) | Standard MetaHuman morph target names (e.g., CTRL_expressions_jawOpen) | MetaHuman characters |
| ARKit | Apple ARKit-compatible names (e.g., JawOpen, MouthSmileLeft) | ARKit-based characters |
Fine-Tuning Lip Sync Behavior
Scaling Specific Lip Sync Curves
You can dampen (or amplify) individual facial movements produced by lip sync using a Modify Curve node. This is useful when a particular curve looks too pronounced for your audio content or character.
Setup:
- After your lip sync blend node, add a
Modify Curvenode - Right-click the node and select Add Curve Pin, then enter the curve name you want to scale
- Set the node's Apply Mode property to Scale
- Set the Value parameter: values below 1.0 dampen the movement, values above 1.0 amplify it (e.g., 0.8 = 20% reduction)
Commonly scaled curves:
| Curve Name | Purpose | Applies To | Typical Adjustment |
|---|---|---|---|
CTRL_expressions_tongueOut | Forward tongue protrusion during certain phonemes | Standard model | 0.8 to reduce protrusion |
CTRL_expressions_jawOpen | Jaw opening range | Realistic models | 0.9 to reduce jaw movement |
You can add multiple curve pins to the same Modify Curve node to scale several curves at once.
Mood-Specific Fine-Tuning
For mood-enabled models, you can fine-tune specific emotional expressions:
Eyebrow Control:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- Inner eyebrow raiseCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- Outer eyebrow raiseCTRL_expressions_browDownL/CTRL_expressions_browDownR- Eyebrow lowering
Eye Expression Control:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Eye squintingCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Cheek raising
Model Comparison and Selection
Choosing Between Models
When deciding which lip sync model to use for your project, consider these factors:
| Consideration | Standard Model | Realistic Model | Mood-Enabled Realistic Model |
|---|---|---|---|
| Character Compatibility | MetaHumans and all custom character types | MetaHumans (and ARKit) characters | MetaHumans (and ARKit) characters |
| Visual Quality | Good lip sync with efficient performance | Enhanced realism with more natural mouth movements | Enhanced realism with emotional expressions |
| Performance | Optimized for all platforms including mobile/VR | Higher resource requirements | Higher resource requirements |
| Features | 14 visemes, laughter detection | 81 facial controls, 3 optimization levels | 81 facial controls, 12 moods, configurable output |
| Platform Support | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Use Cases | General applications, games, VR/AR, mobile | Cinematic experiences, close-up interactions | Emotional storytelling, advanced character interaction |
Engine Version Compatibility
If you're using Unreal Engine 5.2, the Realistic Models may not work correctly due to a bug in UE's resampling library. For UE 5.2 users who need reliable lip sync functionality, please use the Standard Model instead.
This issue is specific to UE 5.2 and does not affect other engine versions.
Performance Recommendations
- For most projects, the Standard Model provides an excellent balance of quality and performance
- Use the Realistic Model when you need the highest visual fidelity for MetaHuman characters
- Use the Mood-Enabled Realistic Model when emotional expression control is important for your application
- Consider your target platform's performance capabilities when choosing between models
- Test different optimization levels to find the best balance for your specific use case
Troubleshooting
Common Issues
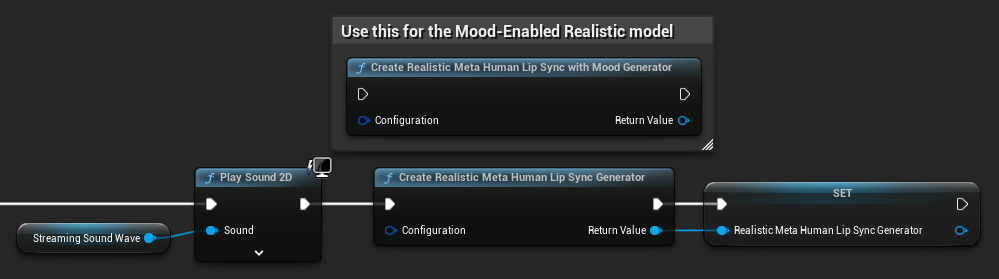
Generator Recreation for Realistic Models: For reliable and consistent operation with the Realistic Models, it's recommended to recreate the generator each time you want to feed new audio data after a period of inactivity. This is due to ONNX runtime behavior that can cause lip sync to stop working when reusing generators after periods of silence.
For example, you could recreate the lip sync generator on every playback start, such as whenever you call Play Sound 2D or use any other method to start sound wave playback and lip sync:
Plugin Location for Runtime Text To Speech Integration: When using Runtime MetaHuman Lip Sync together with Runtime Text To Speech (both plugins use ONNX Runtime), you may experience issues in packaged builds if the plugins are installed in the engine's Marketplace folder. To fix this:
- Locate both plugins in your UE installation folder under
\Engine\Plugins\Marketplace(e.g.,C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Move both the
RuntimeMetaHumanLipSyncandRuntimeTextToSpeechfolders to your project'sPluginsfolder - If your project doesn't have a
Pluginsfolder, create one in the same directory as your.uprojectfile - Restart the Unreal Editor
This addresses compatibility issues that can occur when multiple ONNX Runtime-based plugins are loaded from the engine's Marketplace directory.
Packaging Configuration (Windows): If lip sync is not working correctly in your packaged project on Windows, ensure you're using the Shipping build configuration instead of Development. The Development configuration can cause issues with the realistic models ONNX runtime in packaged builds.
To fix this:
- In your Project Settings → Packaging, set the Build Configuration to Shipping
- Repackage your project
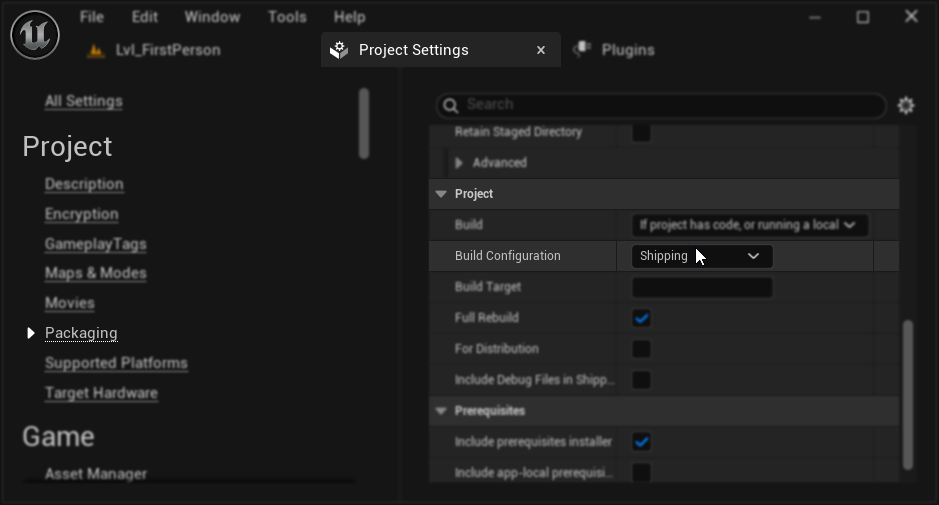
In some Blueprint-only projects, Unreal Engine may still build in Development configuration even when Shipping is selected. If this happens, convert your project to a C++ project by adding at least one C++ class (it can be empty). To do this, go to Tools → New C++ Class in the UE editor menu and create an empty class. This will force the project to build correctly in Shipping configuration. Your project can remain Blueprint-only in functionality, the C++ class is just needed for proper build configuration.
Degraded Lip Sync Responsiveness: If you experience that lip sync becomes less responsive over time when using Streaming Sound Wave or Capturable Sound Wave, this may be caused by memory accumulation. By default, memory is reallocated each time new audio is appended. To prevent this issue, call the ReleaseMemory function periodically to free up accumulated memory, such as every 30 seconds or so.
Performance Optimization:
- Adjust Processing Chunk Size for Realistic models based on your performance requirements
- Use appropriate thread counts for your target hardware
- Consider using Mouth Only output type for mood-enabled models when full facial animation isn't needed