How to use the plugin
The Runtime Text To Speech plugin synthesizes text into speech using downloadable voice models. These models are managed in the plugin settings within the editor, downloaded, and packaged for runtime use. Follow the steps below to get started.
Editor side
Download the appropriate voice models for your project as described here. You can download multiple voice models at the same time.
Runtime side
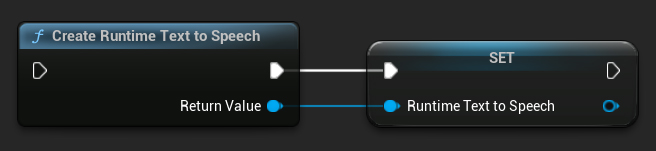
Create the synthesizer using the CreateRuntimeTextToSpeech function. Ensure you maintain a reference to it (e.g. as a separate variable in Blueprints or UPROPERTY in C++) to prevent it from being garbage collected.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Synthesizing Speech
The plugin offers two modes of text-to-speech synthesis:
- Regular Text-to-Speech: Synthesizes the entire text and returns the complete audio when finished
- Streaming Text-to-Speech: Provides audio chunks as they're generated, allowing for real-time processing
Each mode supports two methods for selecting voice models:
- By Name: Select a voice model by its name (recommended for UE 5.4+)
- By Object: Select a voice model by direct reference (recommended for UE 5.3 and earlier)
Regular Text-to-Speech
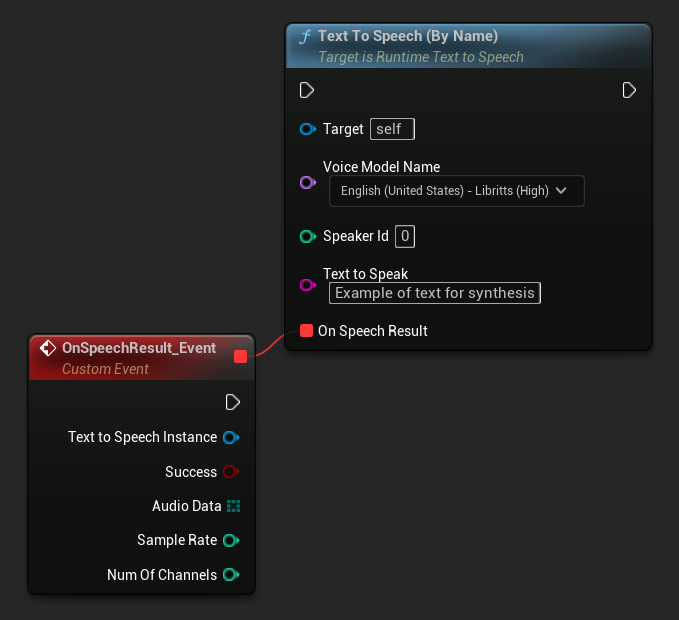
By Name
- Blueprint
- C++
The Text To Speech (By Name) function is more convenient in Blueprints starting from UE 5.4. It allows you to select voice models from a dropdown list of the downloaded models. In UE versions below 5.3, this dropdown doesn't appear, so if you're using an older version, you'll need to manually iterate over the array of voice models returned by GetDownloadedVoiceModels to select the one you need.
In C++, the selection of voice models can be slightly more complex due to the lack of a dropdown list. You can use the GetDownloadedVoiceModelNames function to retrieve the names of the downloaded voice models and select the one you need. Afterward, you can call the TextToSpeechByName function to synthesize text using the selected voice model name.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
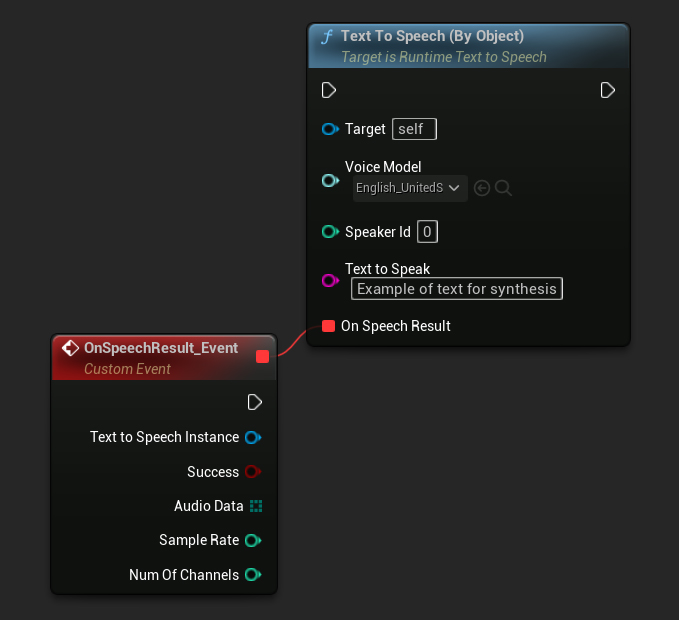
By Object
- Blueprint
- C++
The Text To Speech (By Object) function works across all versions of Unreal Engine but presents the voice models as a dropdown list of asset references, which is less intuitive. This method is suitable for UE 5.3 and earlier, or if your project requires a direct reference to a voice model asset for any reason.
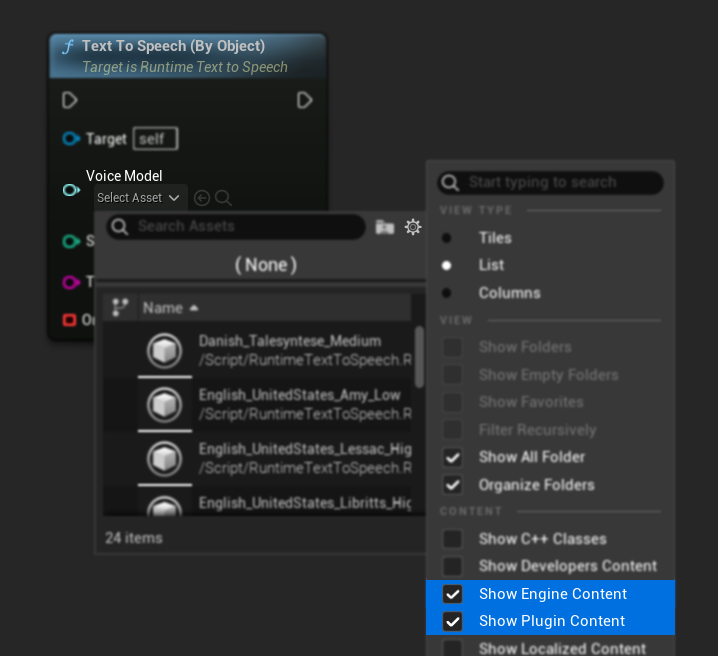
If you've downloaded the models but can't see them, open the Voice Model dropdown, click the settings (gear icon), and enable both Show Plugin Content and Show Engine Content to make the models visible.
In C++, the selection of voice models can be slightly more complex due to the lack of a dropdown list. You can use the GetDownloadedVoiceModelNames function to retrieve the names of the downloaded voice models and select the one you need. Then, you can call the GetVoiceModelFromName function to get the voice model object and pass it to the TextToSpeechByObject function to synthesize text.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Streaming Text-to-Speech
For longer texts or when you want to process audio data in real-time as it's being generated, you can use the streaming versions of the Text-to-Speech functions:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNamein C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjectin C++)
These functions provide audio data in chunks as they're generated, allowing for immediate processing without waiting for the entire synthesis to complete. This is useful for various applications like real-time audio playback, live visualization, or any scenario where you need to process speech data incrementally.
Streaming By Name
- Blueprint
- C++
The Streaming Text To Speech (By Name) function works similarly to the regular version but provides audio in chunks through the On Speech Chunk delegate.
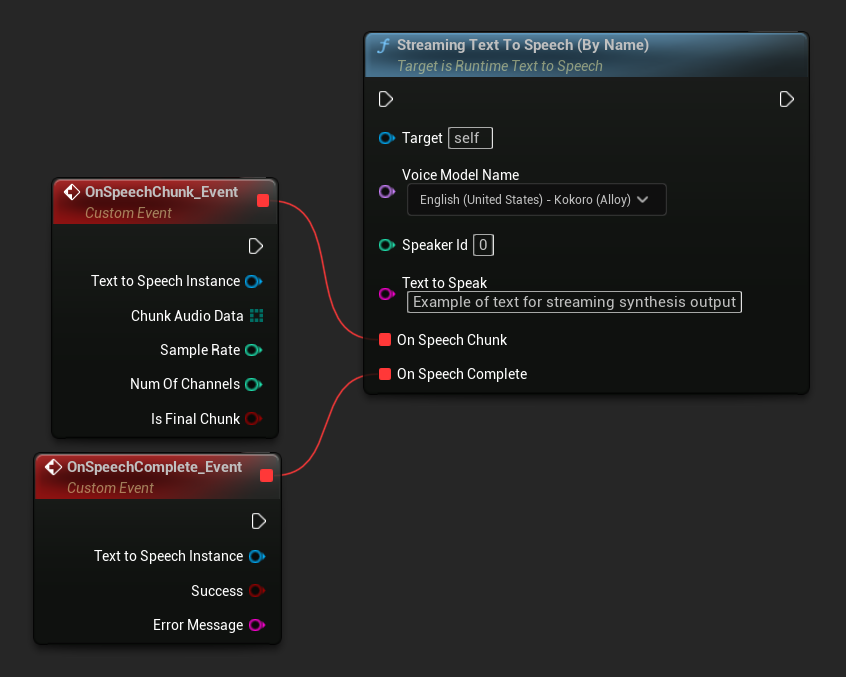
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Streaming By Object
- Blueprint
- C++
The Streaming Text To Speech (By Object) function provides the same streaming functionality but takes a voice model object reference.
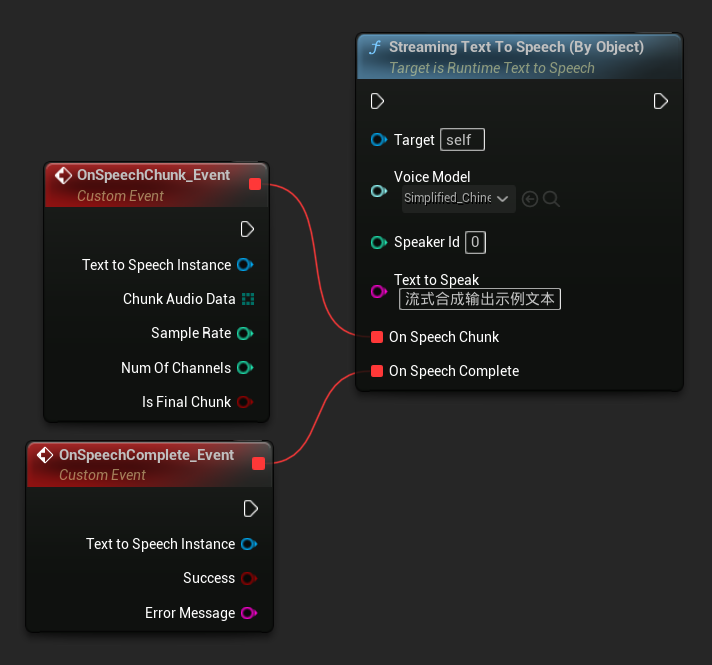
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Audio Playback
- Regular Playback
- Streaming Playback
For regular (non-streaming) text-to-speech, the On Speech Result delegate provides the synthesized audio as PCM data in float format (as a byte array in Blueprints or TArray<uint8> in C++), along with the Sample Rate and Num Of Channels.
For playback, it's recommended to use the Runtime Audio Importer plugin to convert raw audio data into a playable sound wave.
- Blueprint
- C++
Here's an example of how the Blueprint nodes for synthesizing text and playing the audio might look (Copyable nodes):
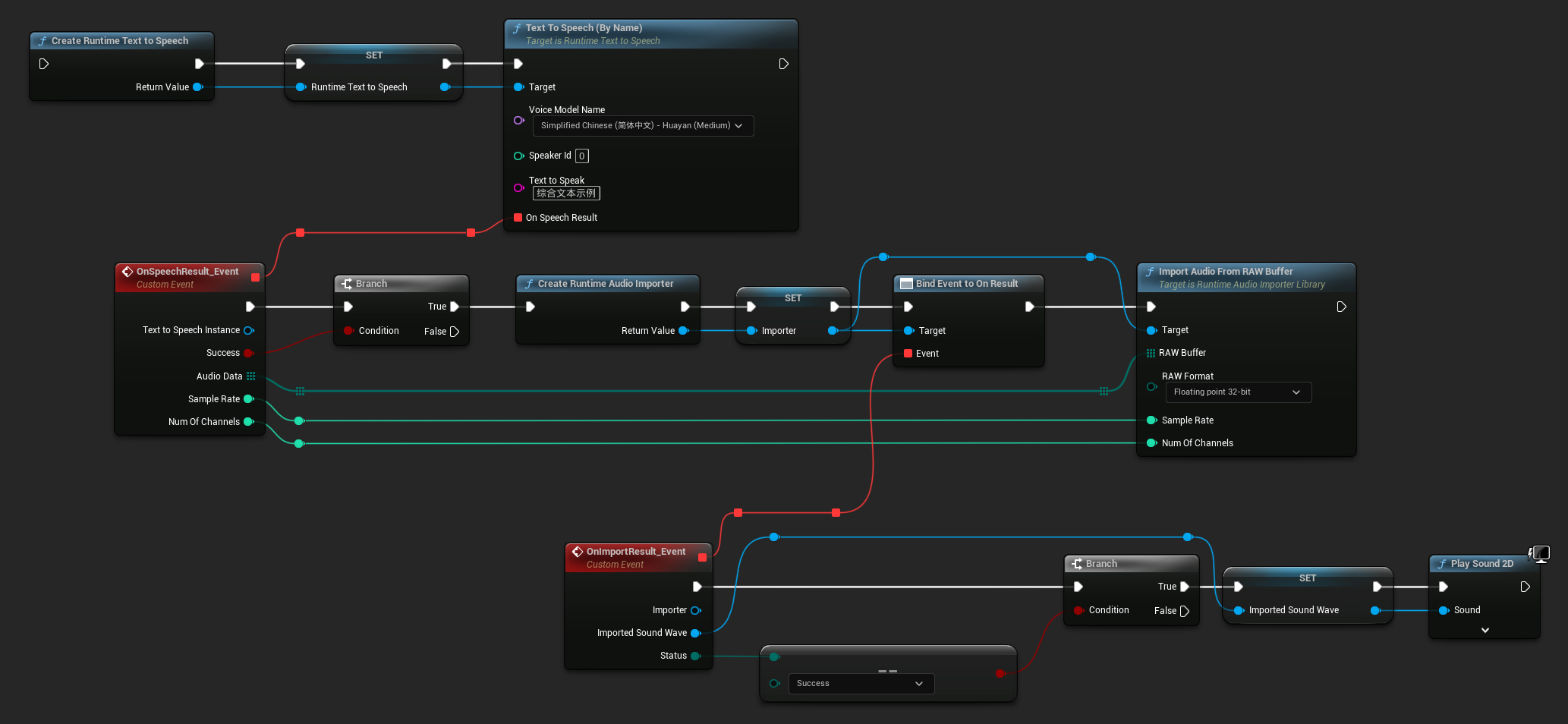
Here's an example of how to synthesize text and play the audio in C++:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
For streaming text-to-speech, you'll receive audio data in chunks as PCM data in float format (as a byte array in Blueprints or TArray<uint8> in C++), along with the Sample Rate and Num Of Channels. Each chunk can be processed immediately as it becomes available.
For real-time playback, it's recommended to use the Runtime Audio Importer plugin's Streaming Sound Wave, which is specifically designed for streaming audio playback or real-time processing.
- Blueprint
- C++
Here's an example of how the Blueprint nodes for streaming text-to-speech and playing the audio might look (Copyable nodes):
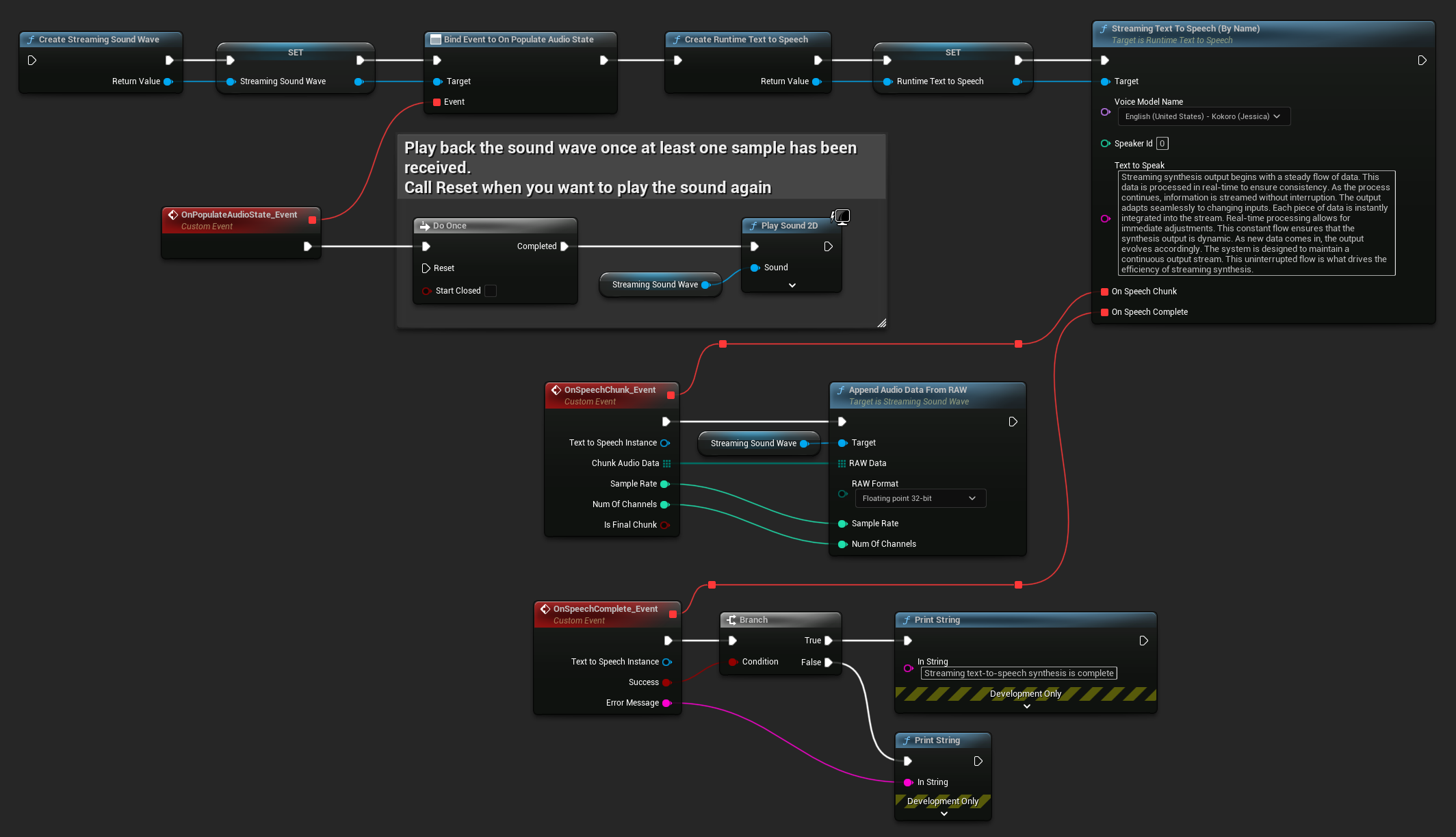
Here's an example of how to implement streaming text-to-speech with real-time playback in C++:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Cancelling Text-to-Speech
You can cancel an ongoing text-to-speech synthesis operation at any time by calling the CancelSpeechSynthesis function on your synthesizer instance:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
When a synthesis is cancelled:
- The synthesis process will stop as soon as possible
- Any ongoing callbacks will be terminated
- The completion delegate will be called with
bSuccess = falseand an error message indicating the synthesis was cancelled - Any resources allocated for the synthesis will be properly cleaned up
This is particularly useful for long texts or when you need to interrupt playback to start a new synthesis.
Speaker Selection
Both Text To Speech functions accept an optional speaker ID parameter, which is useful when working with voice models that support multiple speakers. You can use the GetSpeakerCountFromVoiceModel or GetSpeakerCountFromModelName functions to check if multiple speakers are supported by your chosen voice model. If multiple speakers are available, simply specify your desired speaker ID when calling the Text To Speech functions. Some voice models offer extensive variety - for example, English LibriTTS includes over 900 different speakers to choose from.
The Runtime Audio Importer plugin also provides additional features like exporting audio data to a file, passing it to SoundCue, MetaSound, and more. For further details, check out the Runtime Audio Importer documentation.