Eklentiyi Nasıl Kullanılır
Runtime AI Chatbot Integrator iki ana işlevsellik sağlar: Metinden Metne sohbet ve Metinden Sese (TTS). Her iki özellik de benzer bir iş akışını takip eder:
- API sağlayıcı token'ınızı kaydedin
- Özelliğe özgü ayarları yapılandırın
- İstek gönderin ve yanıtları işleyin
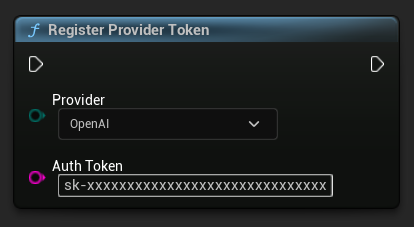
Sağlayıcı Token'ını Kaydet
Herhangi bir istek göndermeden önce, API sağlayıcı token'ınızı RegisterProviderToken işlevini kullanarak kaydedin.
Ollama yerel olarak çalışır ve bir API token'ı gerektirmez. Ollama için bu adımı atlayabilirsiniz.
- Blueprint
- C++
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
// Register other providers as needed
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::Anthropic,
TEXT("sk-ant-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::DeepSeek,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
etc
Metin-Metin Sohbet İşlevselliği
Eklenti, her sağlayıcı için iki sohbet isteği modunu destekler:
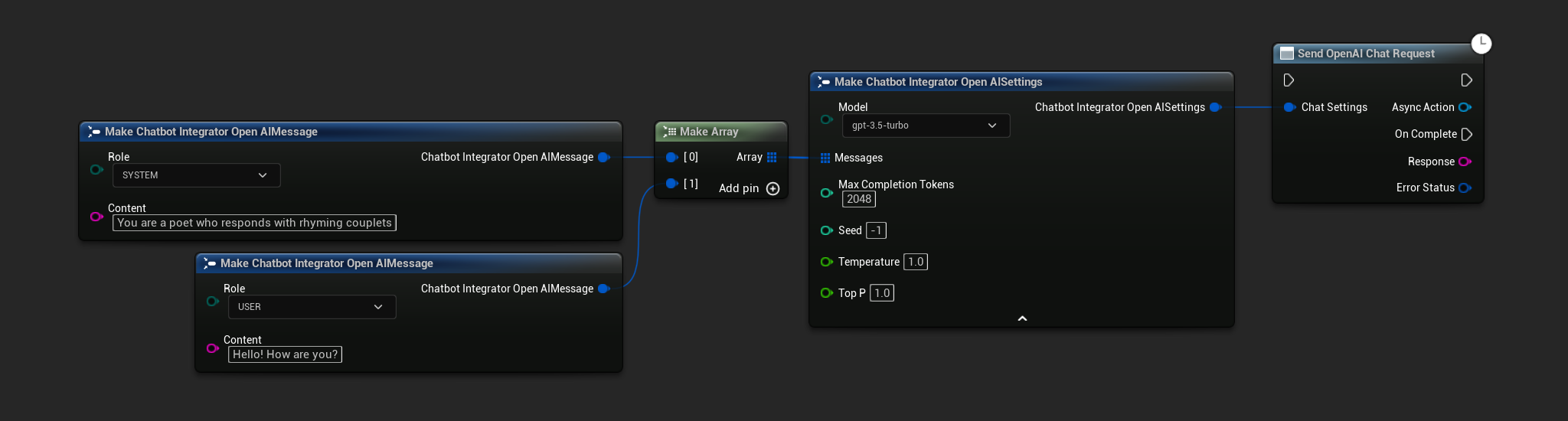
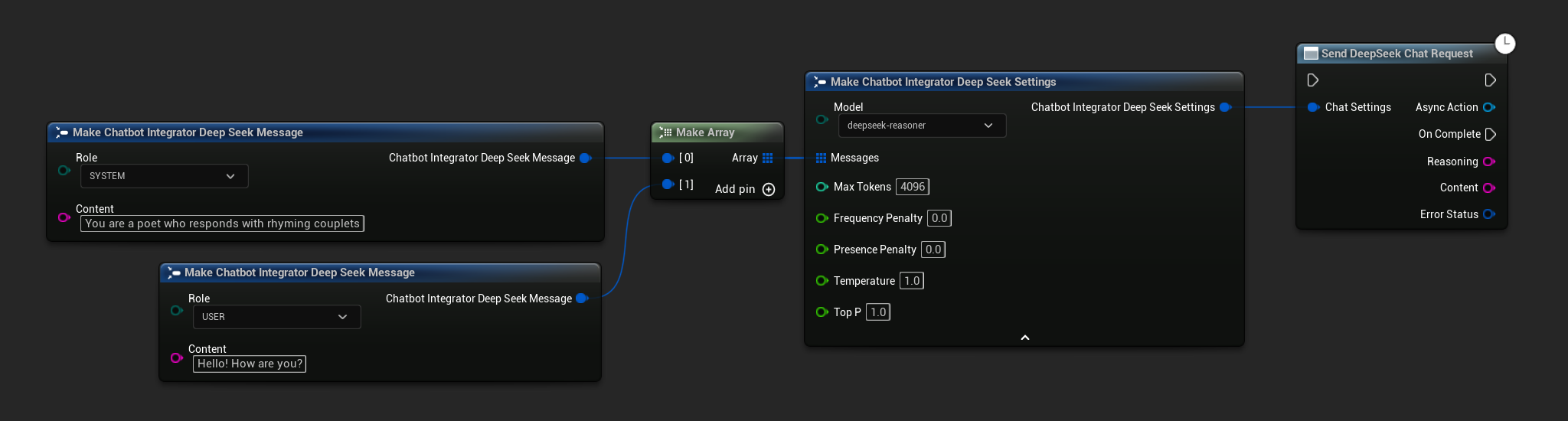
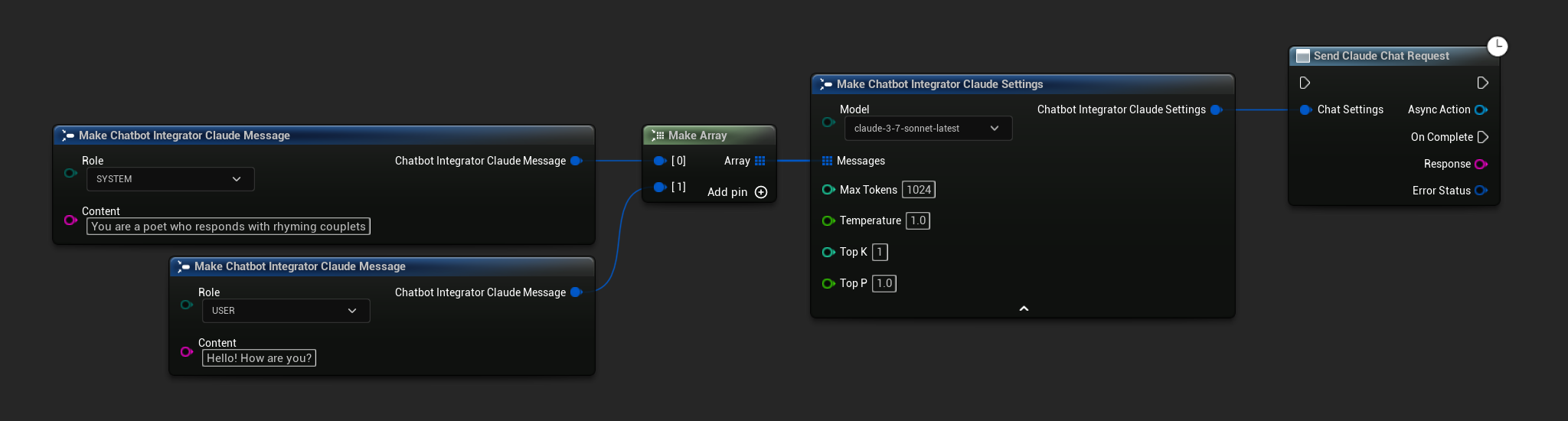
Akışsız Sohbet İstekleri
Tam yanıtı tek bir çağrıda alın.
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaude::SendChatRequestNative(
Settings,
FOnClaudeChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
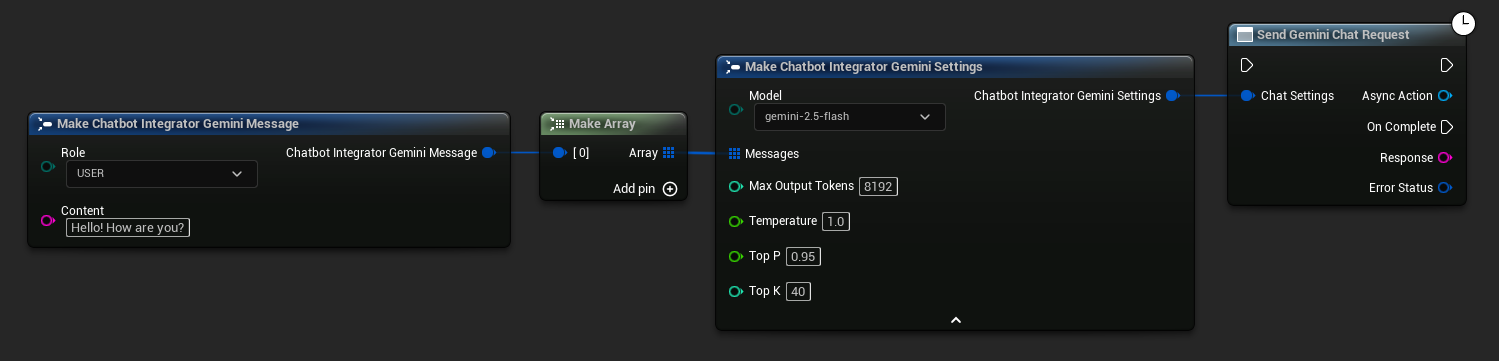
// Example of sending a non-streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGemini::SendChatRequestNative(
Settings,
FOnGeminiChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
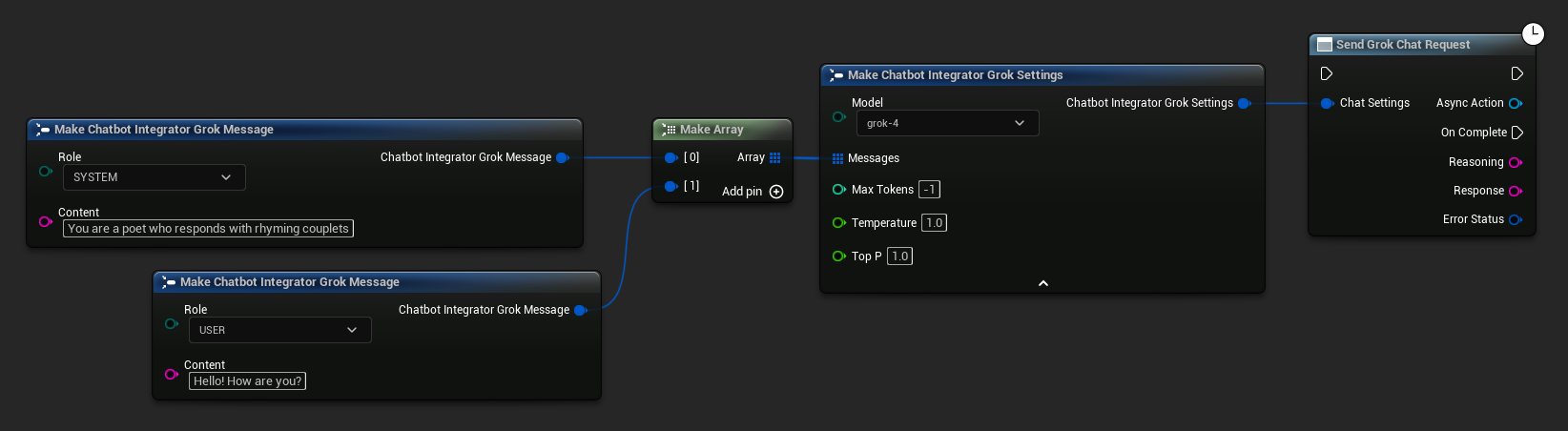
// Example of sending a non-streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrok::SendChatRequestNative(
Settings,
FOnGrokChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Response: %s, Error: %d: %s"),
*Reasoning, *Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
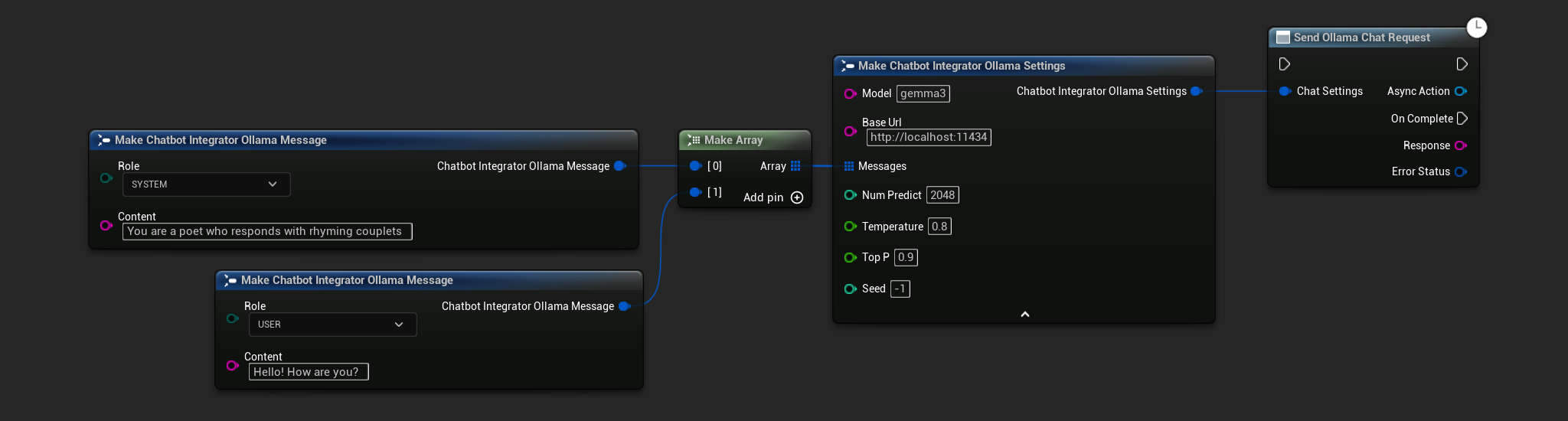
// Example of sending a non-streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllama::SendChatRequestNative(
Settings,
FOnOllamaChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
Akış Sohbet İstekleri
Daha dinamik bir etkileşim için yanıt parçalarını gerçek zamanlı olarak alın.
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
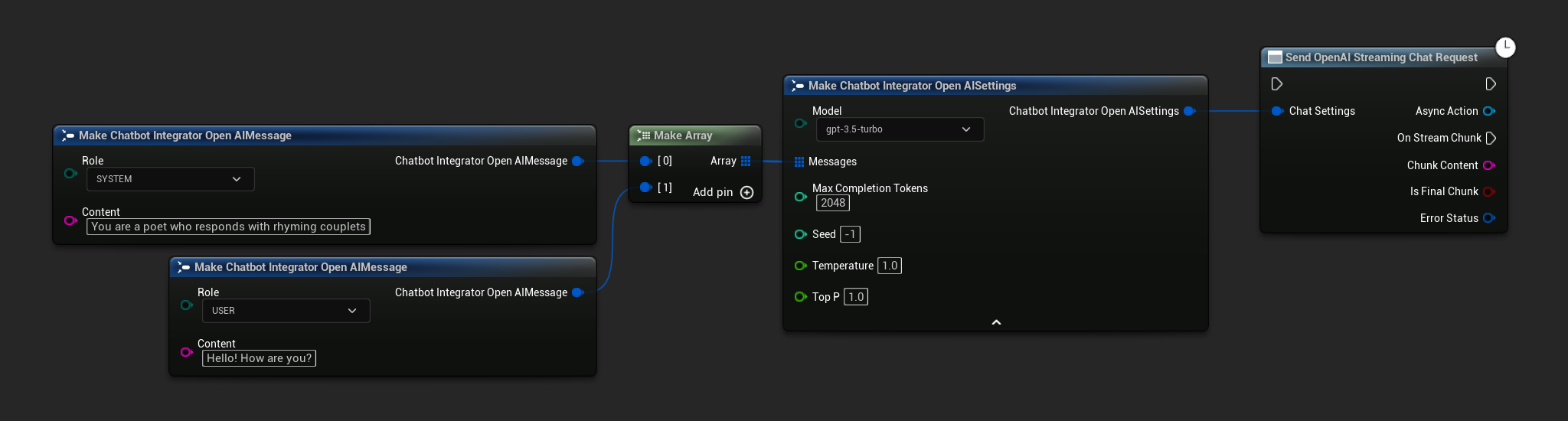
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAIStreamingSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
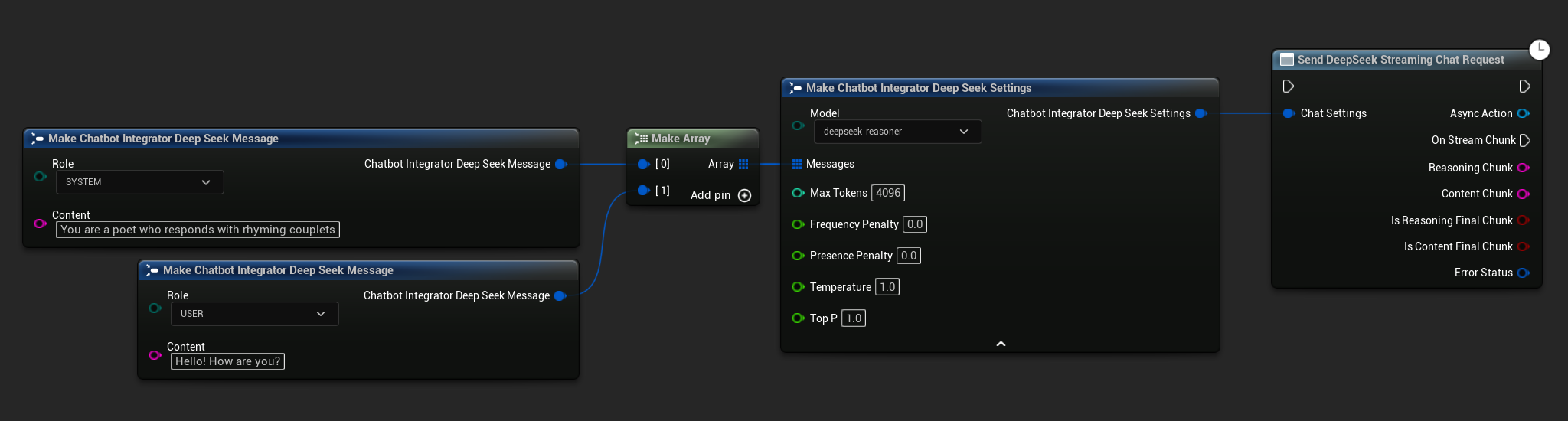
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
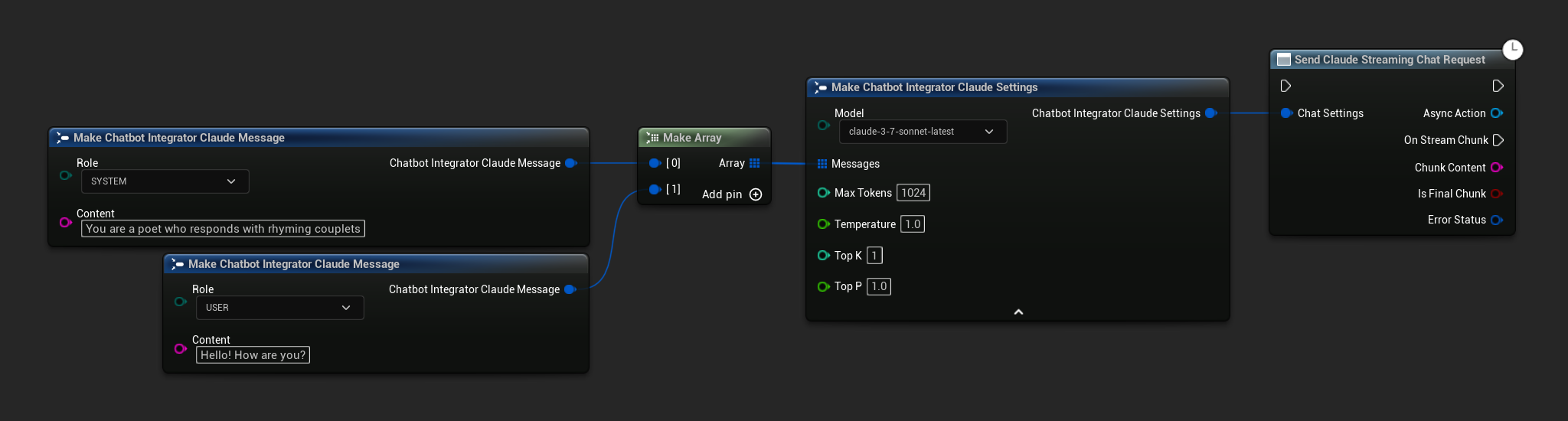
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
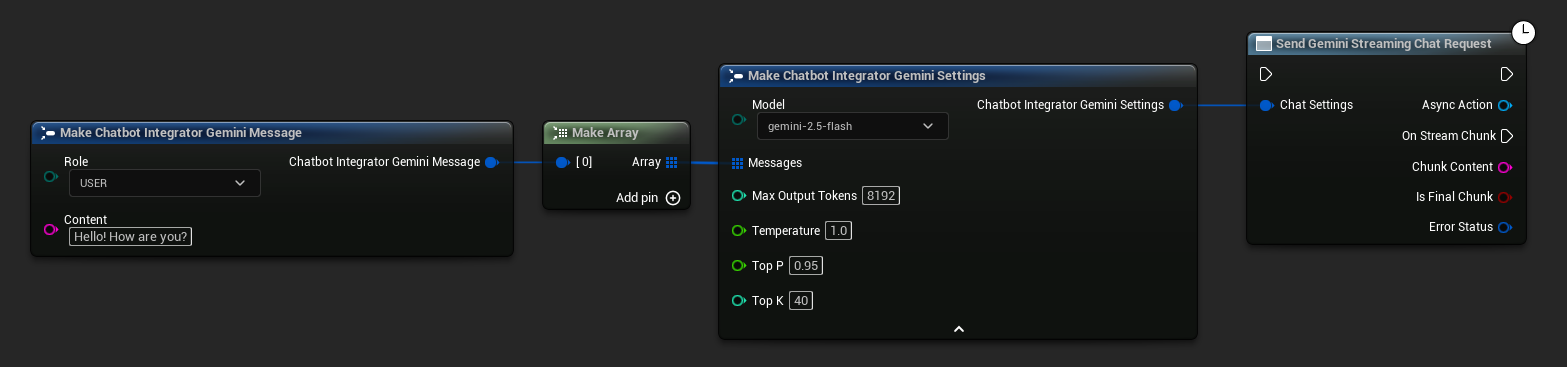
// Example of sending a streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGeminiStream::SendStreamingChatRequestNative(
Settings,
FOnGeminiChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
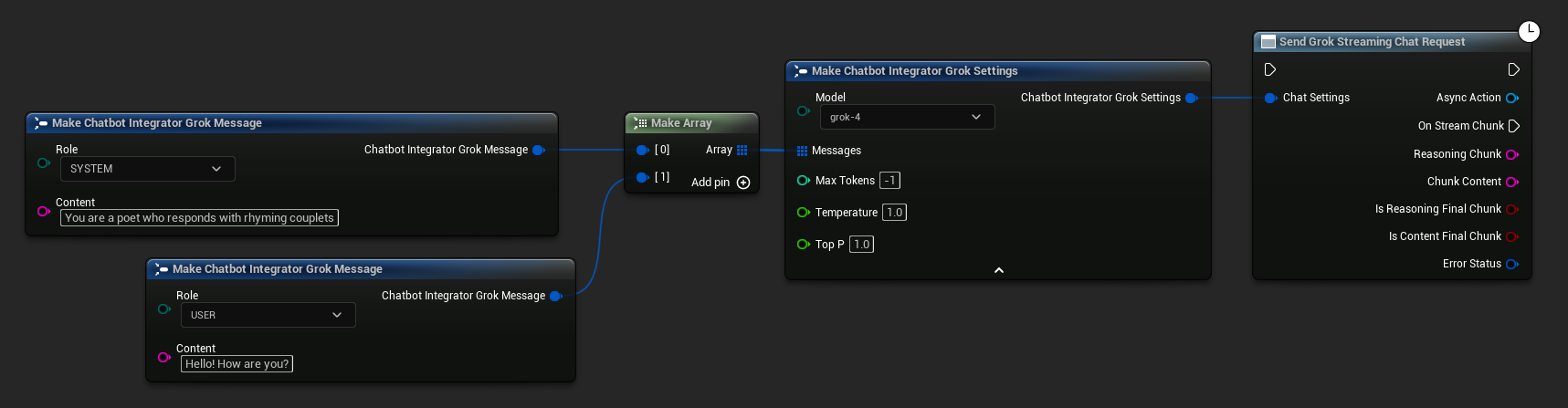
// Example of sending a streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrokStream::SendStreamingChatRequestNative(
Settings,
FOnGrokChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
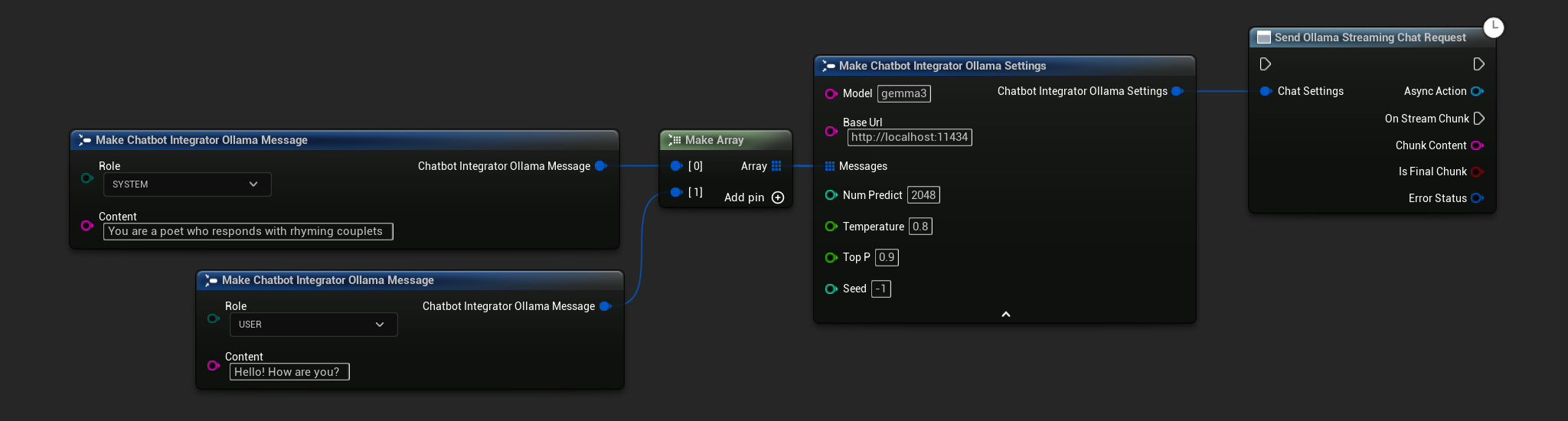
// Example of sending a streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllamaStream::SendStreamingChatRequestNative(
Settings,
FOnOllamaChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
Metinden Sese (TTS) İşlevselliği
Önde gelen TTS sağlayıcılarını kullanarak metni yüksek kaliteli konuşma sesine dönüştürün. Eklenti, projenizin ihtiyaçlarına göre işleyebileceğiniz ham ses verilerini (TArray<uint8>) döndürür.
Aşağıdaki örnekler, Runtime Audio Importer eklentisini kullanarak ses işleme ve oynatmayı gösterse de (bkz. ses içe aktarma belgeleri), Runtime AI Chatbot Integrator esnek olacak şekilde tasarlanmıştır. Eklenti yalnızca ham ses verilerini döndürür, böylece ses oynatma, dosyaya kaydetme, daha fazla ses işleme, diğer sistemlere iletme, özel görselleştirmeler ve daha fazlası gibi özel kullanım durumunuz için bu verileri nasıl işleyeceğiniz konusunda tam özgürlüğe sahip olursunuz.
Akışsız TTS İstekleri
Akışsız TTS istekleri, tüm metin işlendikten sonra tam ses verilerini tek bir yanıt olarak döndürür. Bu yaklaşım, tam sesin beklenmesinin sorun oluşturmadığı daha kısa metinler için uygundur.
- OpenAI TTS
- ElevenLabs TTS
- Google Cloud TTS
- Azure TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnOpenAITTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
}
)
);
- Blueprint
- C++
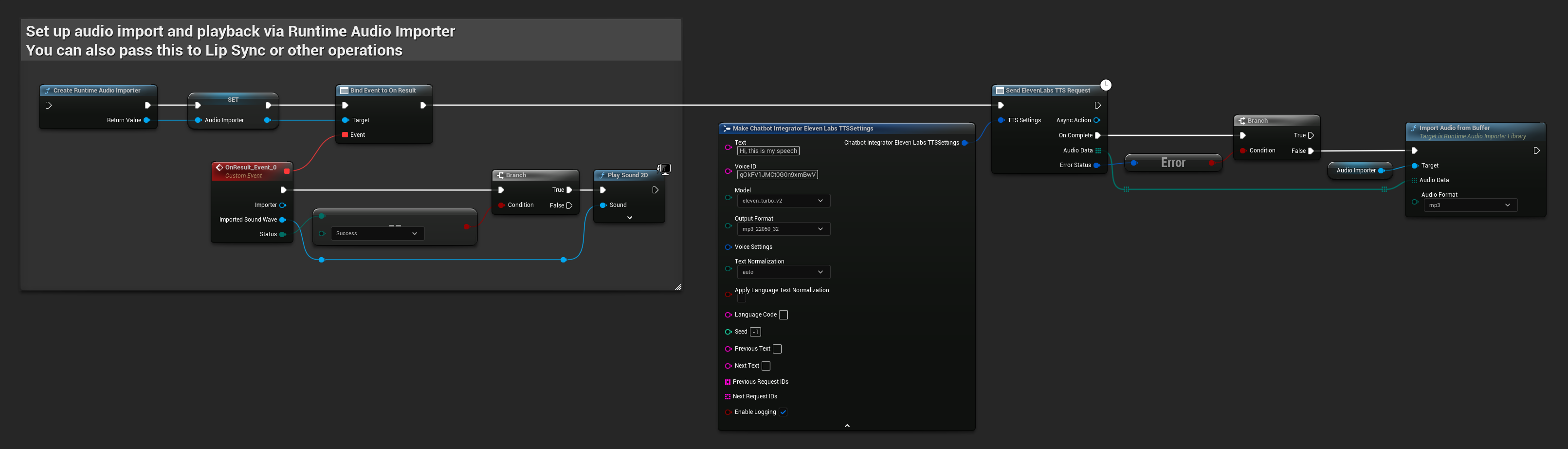
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process audio data as needed
}
}
)
);
- Blueprint
- C++
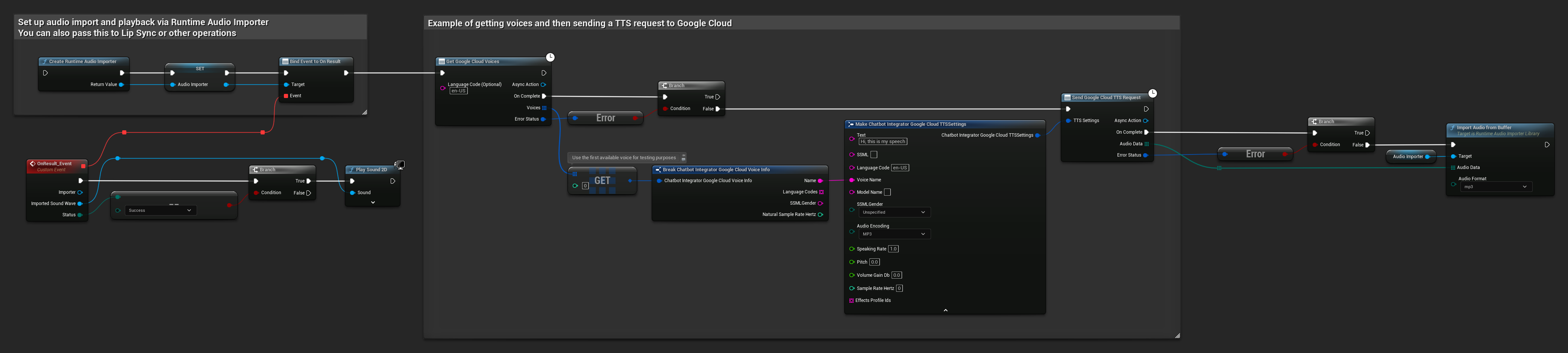
// Example of getting voices and then sending a TTS request to Google Cloud
// First, get available voices
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_GoogleCloudVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s"), *FirstVoice.Name);
// Now send TTS request with the selected voice
FChatbotIntegrator_GoogleCloudTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.LanguageCode = FirstVoice.LanguageCodes.Num() > 0 ? FirstVoice.LanguageCodes[0] : TEXT("en-US");
TTSSettings.VoiceName = FirstVoice.Name;
TTSSettings.AudioEncoding = EChatbotIntegrator_GoogleCloudAudioEncoding::MP3;
UAIChatbotIntegratorGoogleCloudTTS::SendTTSRequestNative(
TTSSettings,
FOnGoogleCloudTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
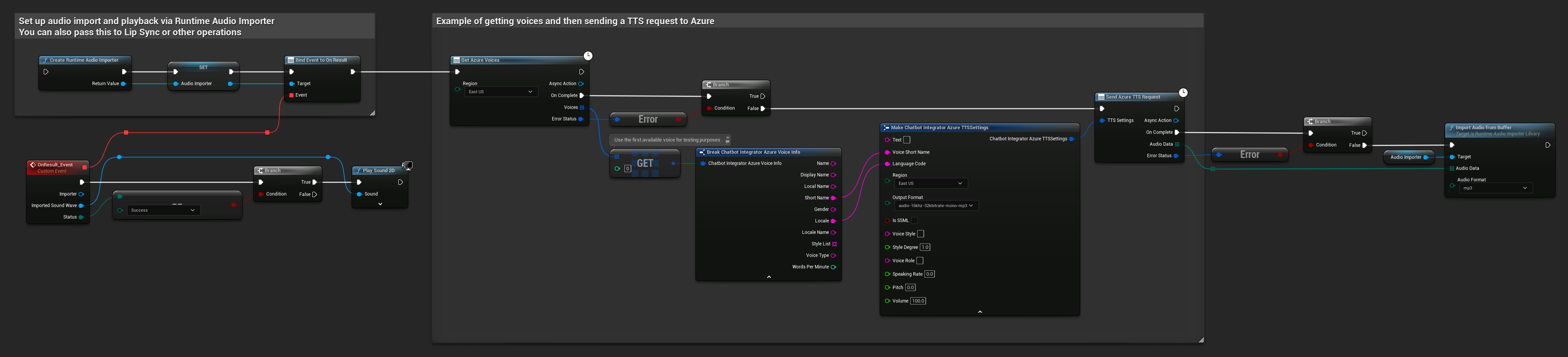
// Example of getting voices and then sending a TTS request to Azure
// First, get available voices
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_AzureVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s (%s)"), *FirstVoice.DisplayName, *FirstVoice.ShortName);
// Now send TTS request with the selected voice
FChatbotIntegrator_AzureTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceShortName = FirstVoice.ShortName;
TTSSettings.LanguageCode = FirstVoice.Locale;
TTSSettings.Region = EChatbotIntegrator_AzureRegion::EAST_US;
TTSSettings.OutputFormat = EChatbotIntegrator_AzureTTSFormat::AUDIO_16KHZ_32KBITRATE_MONO_MP3;
UAIChatbotIntegratorAzureTTS::SendTTSRequestNative(
TTSSettings,
FOnAzureTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
Streaming TTS İstekleri
Streaming TTS, ses parçalarını oluşturuldukları gibi teslim eder, böylece tüm sesin sentezlenmesini beklemek yerine verileri artımlı olarak işlemenize olanak tanır. Bu, uzun metinler için algılanan gecikmeyi önemli ölçüde azaltır ve gerçek zamanlı uygulamaları mümkün kılar. ElevenLabs Streaming TTS ayrıca dinamik metin oluşturma senaryoları için gelişmiş parçalı akış işlevlerini destekler.
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
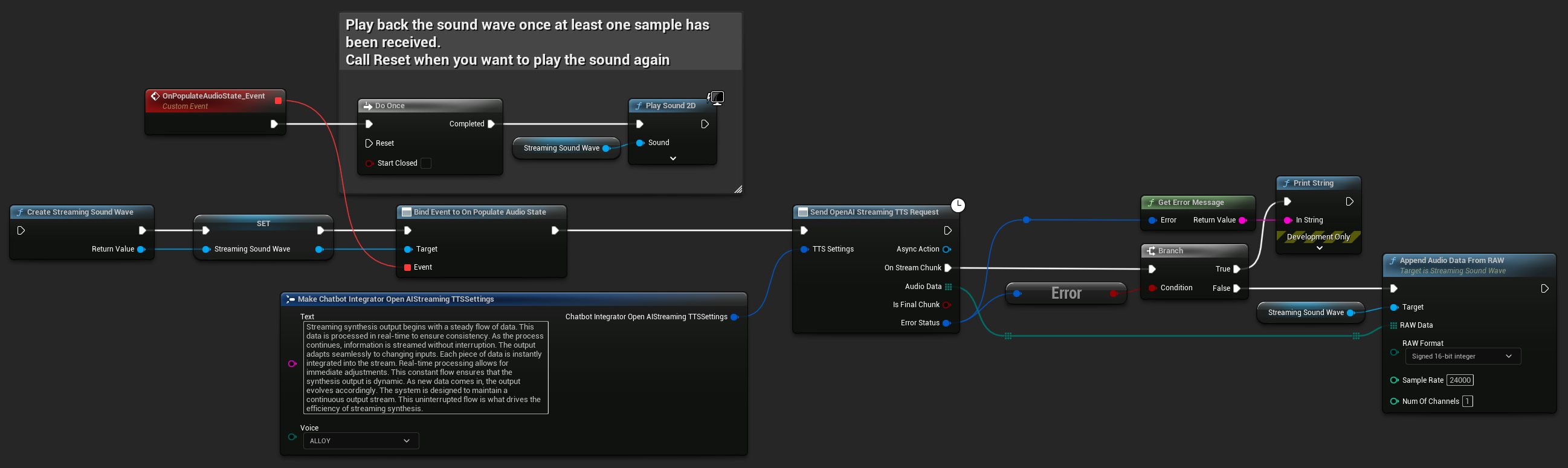
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
}));
}
ElevenLabs Streaming TTS, hem standart akış hem de gelişmiş parçalı akış modlarını destekler, bu da farklı kullanım durumları için esneklik sağlar.
Standart Akış Modu
Standart akış modu, önceden tanımlanmış metni işler ve ses parçalarını oluşturuldukça iletir.
- Blueprint
- C++
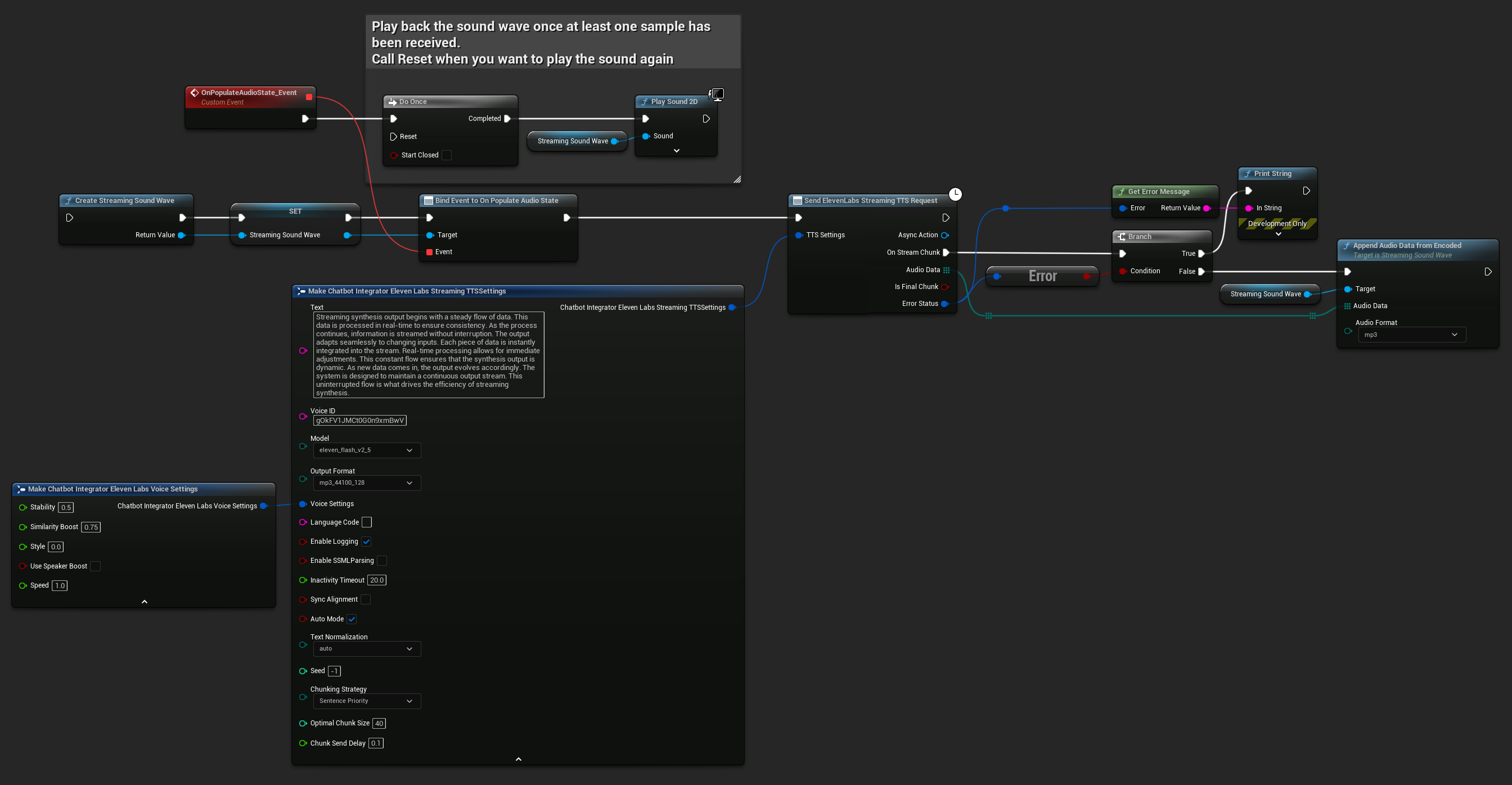
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = false; // Standard streaming mode
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
}));
}
Parçalı Akış Modu
Parçalı akış modu, sentez sırasında metni dinamik olarak eklemenize olanak tanır, bu da metnin artımlı olarak oluşturulduğu gerçek zamanlı uygulamalar için idealdir (örneğin, AI sohbet yanıtları oluşturuldukça sentezlenir). Bu modu etkinleştirmek için, TTS ayarlarınızda bEnableChunkedStreaming değerini true olarak ayarlayın.
- Blueprint
- C++
Başlangıç Kurulumu: TTS ayarlarınızda parçalı akış modunu etkinleştirerek ve ilk isteği oluşturarak parçalı akışı kurun. İstek fonksiyonu, parçalı akış oturumunu yönetmek için yöntemler sağlayan bir async eylem nesnesi döndürür:
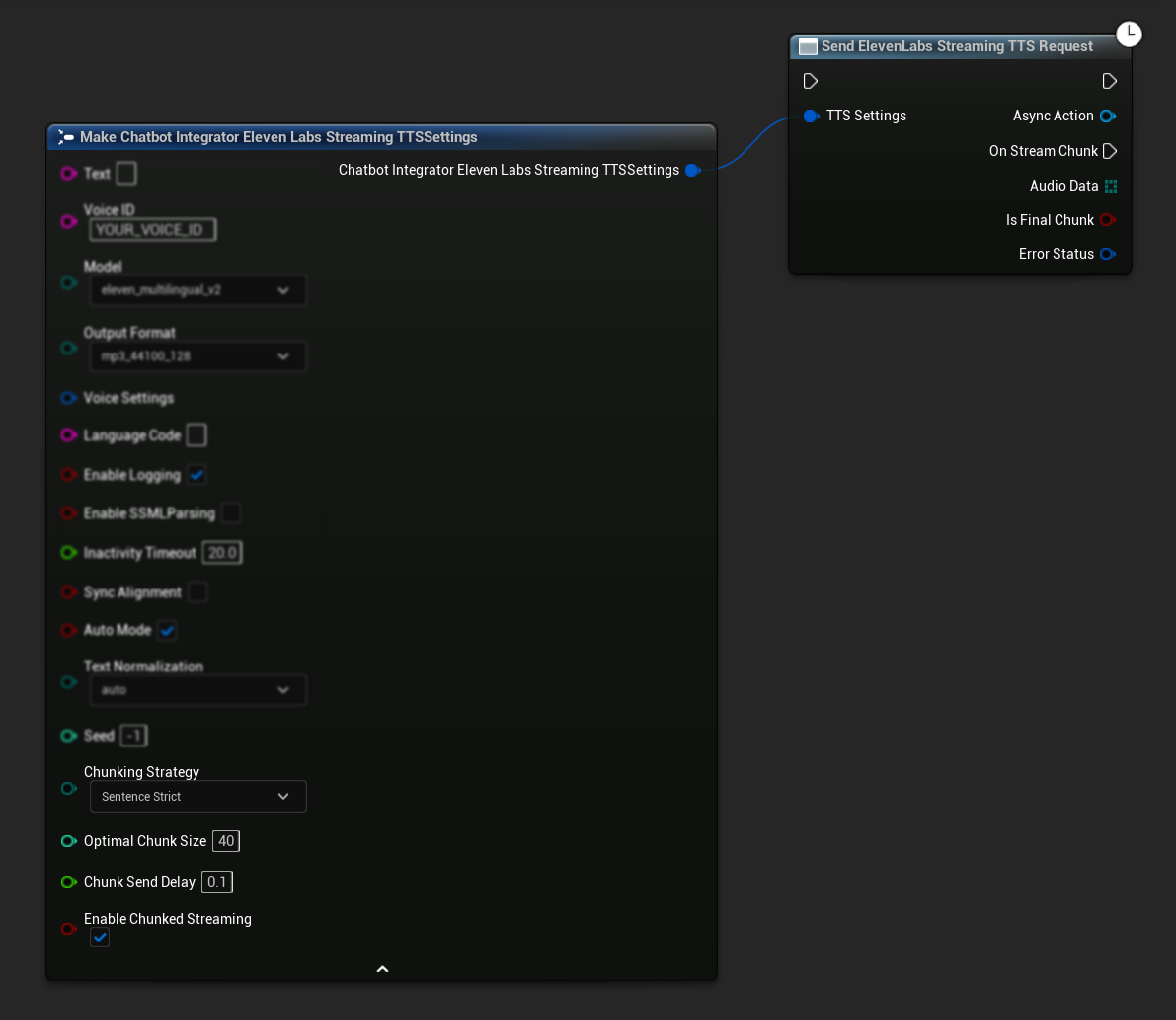
Sentez İçin Metin Ekle:
Aktif bir parçalı akış oturumu sırasında metni dinamik olarak eklemek için, döndürülen async eylem nesnesi üzerinde bu fonksiyonu kullanın. bContinuousMode parametresi, metnin nasıl işlendiğini kontrol eder:

bContinuousModetrueolduğunda: Metin, tam cümle sınırları algılanana kadar (noktalar, ünlem işaretleri, soru işaretleri) dahili olarak tamponlanır. Sistem, tamamlanmamış metni tamponda tutarken, sentez için tam cümleleri otomatik olarak çıkarır. Metnin parçalar veya kısmi kelimeler halinde geldiği ve cümle tamamlamanın belirsiz olduğu durumlarda bunu kullanın.bContinuousModefalseolduğunda: Metin, tamponlama veya cümle sınırı analizi olmadan hemen işlenir. Her çağrı, anlık parça işleme ve sentez ile sonuçlanır. Önceden oluşturulmuş tam cümlelere veya sınır tespiti gerektirmeyen ifadelere sahip olduğunuzda bunu kullanın.
Sürekli Tamponu Boşalt: Async eylem nesnesi üzerinde, herhangi bir cümle sınırı algılanmamış olsa bile, tamponlanmış sürekli metnin işlenmesini zorlar. Bir süre daha metin gelmeyeceğini bildiğinizde kullanışlıdır:
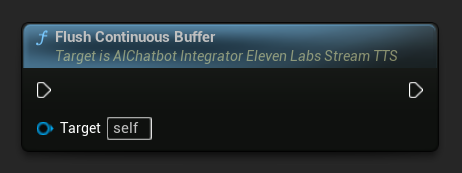
Sürekli Boşaltma Zaman Aşımını Ayarla: Async eylem nesnesi üzerinde, belirtilen zaman aşımı süresi içinde yeni metin gelmediğinde sürekli tamponun otomatik olarak boşaltılmasını yapılandırır:
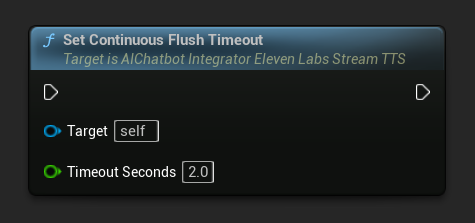
Otomatik boşaltmayı devre dışı bırakmak için 0 olarak ayarlayın. Gerçek zamanlı uygulamalar için önerilen değerler 1-3 saniyedir.
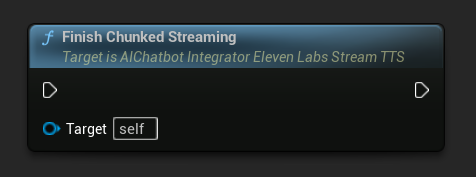
Parçalı Akışı Sonlandır: Async eylem nesnesi üzerindeki parçalı akış oturumunu kapatır ve mevcut sentezi nihai olarak işaretler. Metin eklemeyi bitirdiğinizde her zaman bunu çağırın:
UPROPERTY()
UAIChatbotIntegratorElevenLabsStreamTTS* ChunkedTTSRequest;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartChunkedStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT(""); // Start with empty text in chunked mode
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = true; // Enable chunked streaming mode
// Store the returned async action object to call chunked streaming functions on it
ChunkedTTSRequest = UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(
GetWorld(),
TTSSettings,
FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && AudioData.Num() > 0)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
if (IsFinalChunk)
{
UE_LOG(LogTemp, Log, TEXT("Chunked streaming session completed"));
ChunkedTTSRequest = nullptr;
}
})
);
// Now you can append text dynamically as it becomes available
// For example, from an AI chat response stream:
AppendTextToTTS(TEXT("Hello, this is the first part of the message. "));
}
UFUNCTION(BlueprintCallable)
void AppendTextToTTS(const FString& AdditionalText)
{
// Call AppendTextForSynthesis on the returned async action object
if (ChunkedTTSRequest)
{
// Use continuous mode (true) when text is being generated word-by-word
// and you want to wait for complete sentences before processing
bool bContinuousMode = true;
bool bSuccess = ChunkedTTSRequest->AppendTextForSynthesis(AdditionalText, bContinuousMode);
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Successfully appended text: %s"), *AdditionalText);
}
}
}
// Configure continuous text buffering with custom timeout
UFUNCTION(BlueprintCallable)
void SetupAdvancedChunkedStreaming()
{
// Call SetContinuousFlushTimeout on the async action object
if (ChunkedTTSRequest)
{
// Set automatic flush timeout to 1.5 seconds
// Text will be automatically processed if no new text arrives within this timeframe
ChunkedTTSRequest->SetContinuousFlushTimeout(1.5f);
}
}
// Example of handling real-time AI chat response synthesis
UFUNCTION(BlueprintCallable)
void HandleAIChatResponseForTTS(const FString& ChatChunk, bool IsStreamFinalChunk)
{
if (ChunkedTTSRequest)
{
if (!IsStreamFinalChunk)
{
// Append each chat chunk in continuous mode
// The system will automatically extract complete sentences for synthesis
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
}
else
{
// Add the final chunk
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
// Flush any remaining buffered text and finish the session
ChunkedTTSRequest->FlushContinuousBuffer();
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
}
// Example of immediate chunk processing (bypassing sentence boundary detection)
UFUNCTION(BlueprintCallable)
void AppendImmediateText(const FString& Text)
{
// Call AppendTextForSynthesis with continuous mode = false on the async action object
if (ChunkedTTSRequest)
{
// Use continuous mode = false for immediate processing
// Useful when you have complete sentences or phrases ready
ChunkedTTSRequest->AppendTextForSynthesis(Text, false);
}
}
UFUNCTION(BlueprintCallable)
void FinishChunkedTTS()
{
// Call FlushContinuousBuffer and FinishChunkedStreaming on the async action object
if (ChunkedTTSRequest)
{
// Flush any remaining buffered text
ChunkedTTSRequest->FlushContinuousBuffer();
// Mark the session as finished
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
ElevenLabs Parçalı Akışın Temel Özellikleri:
- Sürekli Mod:
bContinuousModetrueolduğunda, metin tam cümle sınırları algılanana kadar tamponlanır, ardından sentez için işlenir - Anında Mod:
bContinuousModefalseolduğunda, metin ayrı parçalar halinde tamponlama olmadan anında işlenir - Otomatik Temizleme: Yapılandırılabilir zaman aşımı, belirtilen süre içinde yeni girdi gelmediğinde tamponlanmış metni işler
- Cümle Sınırı Algılama: Cümle sonlarını (., !, ?) algılar ve tamponlanmış metinden tam cümleleri çıkarır
- Gerçek Zamanlı Entegrasyon: İçeriğin zamanla parçalar halinde geldiği artımlı metin girişini destekler
- Esnek Metin Parçalama: Sentez işlemini optimize etmek için birden fazla strateji mevcuttur (Cümle Öncelikli, Cümle Katı, Boyuta Dayalı)
Mevcut Sesleri Alma
Bazı TTS sağlayıcıları, mevcut sesleri programlı olarak keşfetmek için ses listeleme API'leri sunar.
- Google Cloud Voices
- Azure Sesleri
- Blueprint
- C++
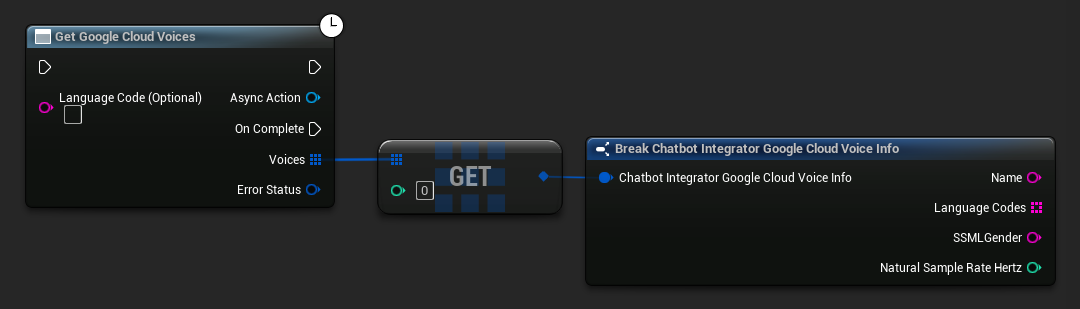
// Example of getting available voices from Google Cloud
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.Name, *Voice.SSMLGender);
}
}
}
)
);
- Blueprint
- C++
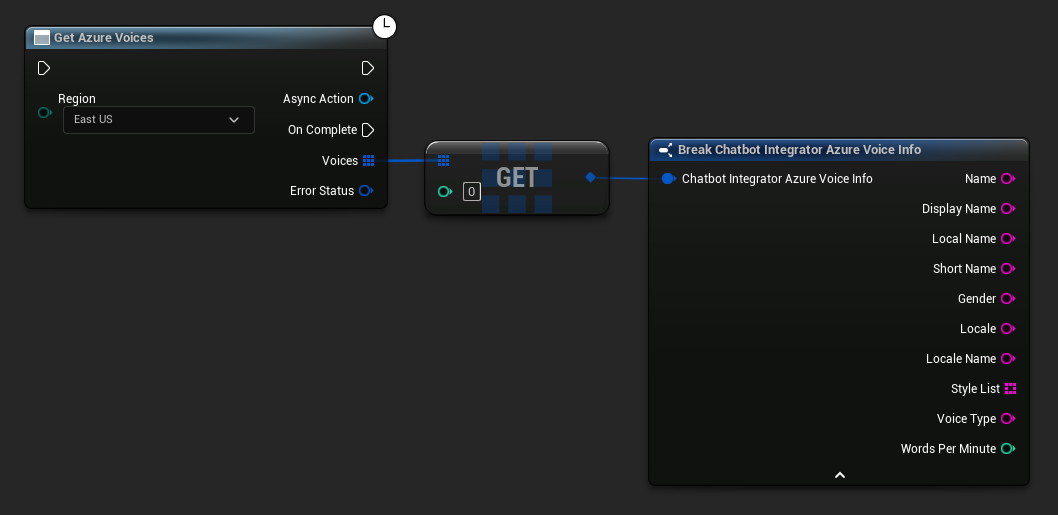
// Example of getting available voices from Azure
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.DisplayName, *Voice.Gender);
}
}
}
)
);
Ollama Modellerini Listeleme
Yerel Ollama örneğinizdeki tüm mevcut modelleri ListOllamaModels işlevini kullanarak sorgulayabilirsiniz. Bu, örneğin kullanıcı arayüzünüzdeki bir model seçiciyi dinamik olarak doldurmak için kullanışlı olabilir. GetModelNames yardımcı işlevi, kolaylık sağlamak için yalnızca sonuçtaki isim dizelerini çıkarır.
- Blueprint
- C++
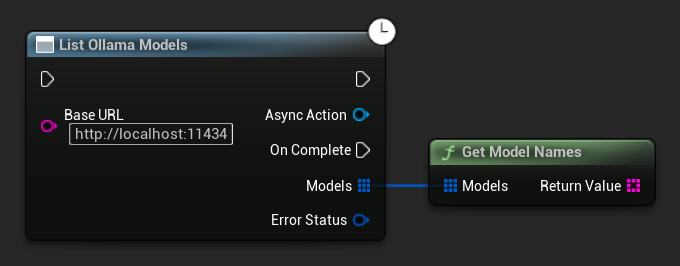
// Example of listing locally available Ollama models
UAIChatbotIntegratorOllamaModelList::ListModelsNative(
TEXT("http://localhost:11434"),
FOnOllamaListModelsResponseNative::CreateWeakLambda(
this,
[this](const TArray<FOllamaModelInfo>& Models, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const FOllamaModelInfo& Model : Models)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s | Family: %s | Parameters: %s | Quantization: %s | Size: %lld bytes"),
*Model.Name, *Model.Family, *Model.ParameterSize, *Model.QuantizationLevel, Model.Size);
}
// Convenience helper to get just the name strings, e.g. for a UI dropdown
TArray<FString> ModelNames = UAIChatbotIntegratorOllamaModelList::GetModelNames(Models);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to list Ollama models: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
Hata İşleme
Herhangi bir istek gönderirken, geri çağrınızda ErrorStatus'u kontrol ederek potansiyel hataları işlemek çok önemlidir. ErrorStatus, istek sırasında oluşabilecek herhangi bir sorun hakkında bilgi sağlar.
- Blueprint
- C++
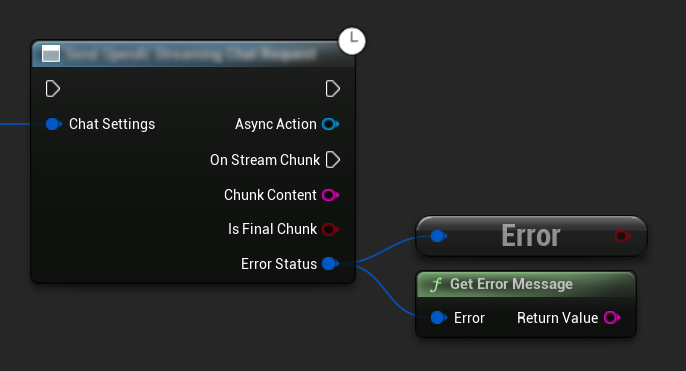
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
İstekleri İptal Etme
Eklenti, hem metinden-metne hem de TTS isteklerini devam ederken iptal etmenize olanak tanır. Bu, uzun süren bir isteği kesmek veya konuşma akışını dinamik olarak değiştirmek istediğinizde kullanışlı olabilir.
- Blueprint
- C++
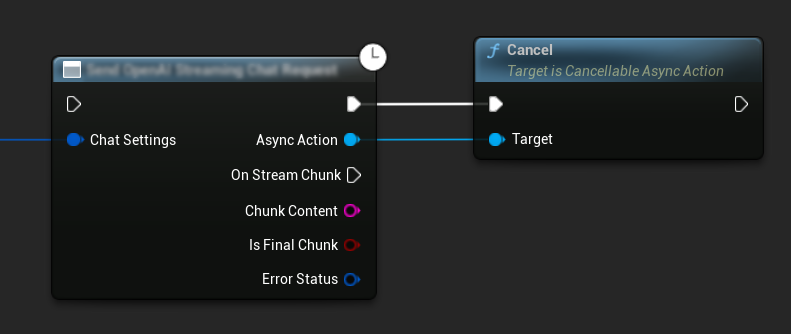
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
En İyi Uygulamalar
- Geri çağırma işlevinizde
ErrorStatus'u kontrol ederek potansiyel hataları her zaman ele alın - Her sağlayıcı için API hız sınırlarını ve maliyetlerini göz önünde bulundurun
- Uzun formlu veya etkileşimli konuşmalar için akış modunu kullanın
- Kaynakları verimli yönetmek için artık gerekli olmayan istekleri iptal etmeyi düşünün
- Algılanan gecikmeyi azaltmak için daha uzun metinler için akışlı TTS kullanın
- Ses işleme için Runtime Audio Importer eklentisi kullanışlı bir çözüm sunar, ancak proje ihtiyaçlarınıza göre özel işleme uygulayabilirsiniz
- Akıl yürütme modellerini (DeepSeek Reasoner, Grok) kullanırken, hem akıl yürütme hem de içerik çıktılarını uygun şekilde ele alın
- TTS özelliklerini uygulamadan önce, ses listeleme API'larını kullanarak mevcut sesleri keşfedin
- ElevenLabs parçalı akış için: Metin artımlı olarak oluşturulduğunda (AI yanıtları gibi) sürekli modu, önceden oluşturulmuş metin parçaları için anında modu kullanın
- Sürekli mod için, duyarlılık ile doğal konuşma akışı arasında denge kurmak için uygun temizleme zaman aşımlarını yapılandırın
- Uygulamanızın gerçek zamanlı gereksinimlerine göre optimal parça boyutlarını ve gönderme gecikmelerini seçin
- Ollama için: Model adlarını sabit kodlamak yerine, mevcut modelleri dinamik olarak keşfetmek için
ListOllamaModelskullanın
Sorun Giderme
- Her sağlayıcı için API kimlik bilgilerinizin doğru olduğunu doğrulayın
- İnternet bağlantınızı kontrol edin
- TTS özellikleriyle çalışırken kullandığınız ses işleme kütüphanelerinin (Runtime Audio Importer gibi) düzgün kurulduğundan emin olun
- TTS yanıt verilerini işlerken doğru ses formatını kullandığınızı doğrulayın
- Akışlı TTS için, ses parçalarını doğru şekilde işlediğinizden emin olun
- Akıl yürütme modelleri için, hem akıl yürütme hem de içerik çıktılarını işlediğinizden emin olun
- Model kullanılabilirliği ve yetenekleri için sağlayıcıya özgü belgeleri kontrol edin
- ElevenLabs parçalı akış için: Oturumu düzgün şekilde kapatmak için işiniz bittiğinde
FinishChunkedStreaming'i çağırdığınızdan emin olun - Sürekli mod sorunları için: Metninizde cümle sınırlarının doğru algılandığını kontrol edin
- Gerçek zamanlı uygulamalar için: Gecikme gereksinimlerinize göre parça gönderme gecikmelerini ve temizleme zaman aşımlarını ayarlayın
- Ollama için: İstek göndermeden önce Ollama sunucusunun çalıştığından ve yapılandırılan
BaseUrladresinden erişilebilir olduğundan emin olun