Ses İşleme Kılavuzu
Bu kılavuz, dudak senkronizasyonu oluşturucularınıza ses verisi beslemek için farklı ses giriş yöntemlerinin nasıl kurulacağını kapsar. Devam etmeden önce Kurulum Kılavuzu'nu tamamladığınızdan emin olun.
Ses Giriş İşleme
Ses girişini işlemek için bir yöntem ayarlamanız gerekiyor. Ses kaynağınıza bağlı olarak bunu yapmanın birkaç yolu vardır.
- Mikrofon (Gerçek Zamanlı)
- Mikrofon (Oynatma)
- Metin Sesten Sese (Yerel)
- Metin-Konuşma (Harici API'ler)
- Ses Dosyasından/Tamponundan
- Akış Ses Tamponu
Bu yaklaşım, mikrofona konuşurken gerçek zamanlı olarak dudak senkronizasyonu gerçekleştirir:
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Runtime Audio Importer kullanarak bir Yakalanabilir Ses Dalgası oluşturun
- Linux ve Pixel Streaming için, Pixel Streaming Capturable Sound Wave kullanın
- Ses yakalamaya başlamadan önce,
OnPopulateAudioDatatemsilcisine bağlanın - Bağlı fonksiyonda, Runtime Viseme Generator'ünüzden
ProcessAudioData'yı çağırın - Mikrofondan ses yakalamayı başlatın
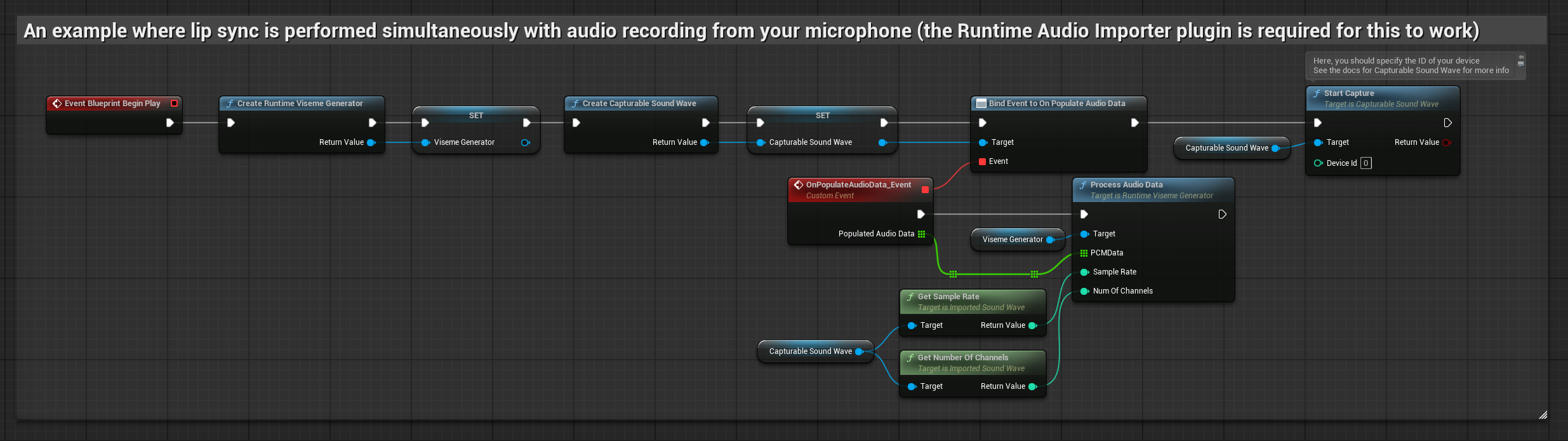
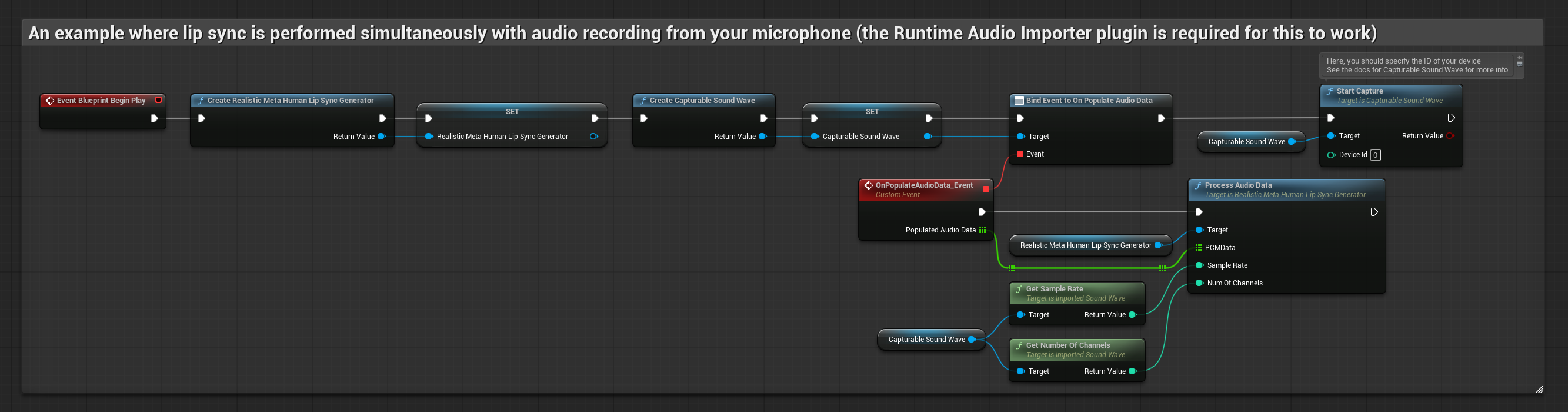
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleriyle birlikte gelir.

Bu yaklaşım, bir mikrofondan ses yakalar ve ardından dudak senkronizasyonu ile geri oynatır:
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Runtime Audio Importer kullanarak bir Yakalanabilir Ses Dalgası oluşturun
- Linux ve Pixel Streaming için, Pixel Streaming Capturable Sound Wave kullanın
- Mikrofondan ses yakalamayı başlat
- Yakalanabilir ses dalgasını oynatmadan önce,
OnGeneratePCMDatatemsilcisine bağlan - Bağlı fonksiyonda, Runtime Viseme Generator'ünüzden
ProcessAudioData'yı çağırın
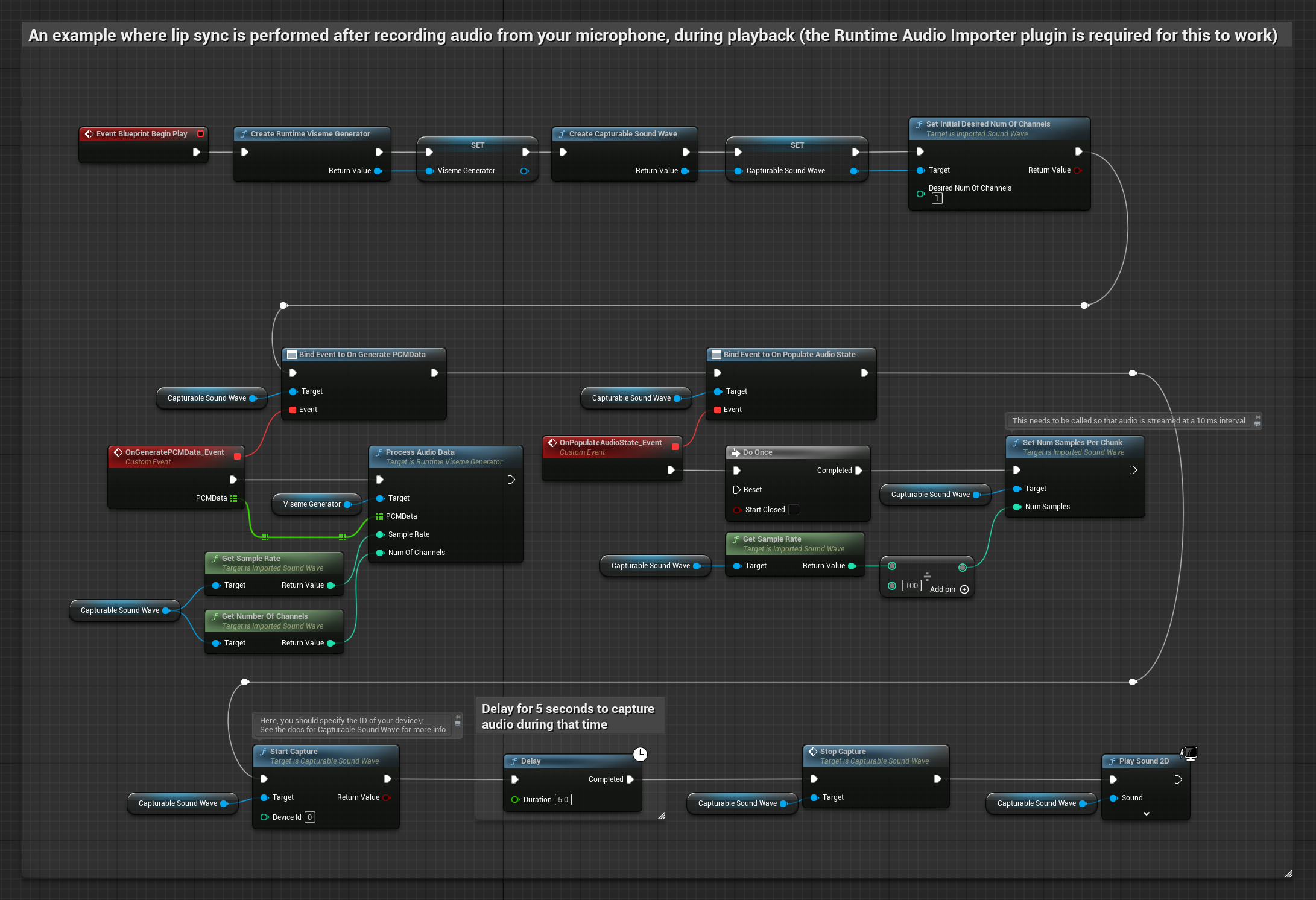
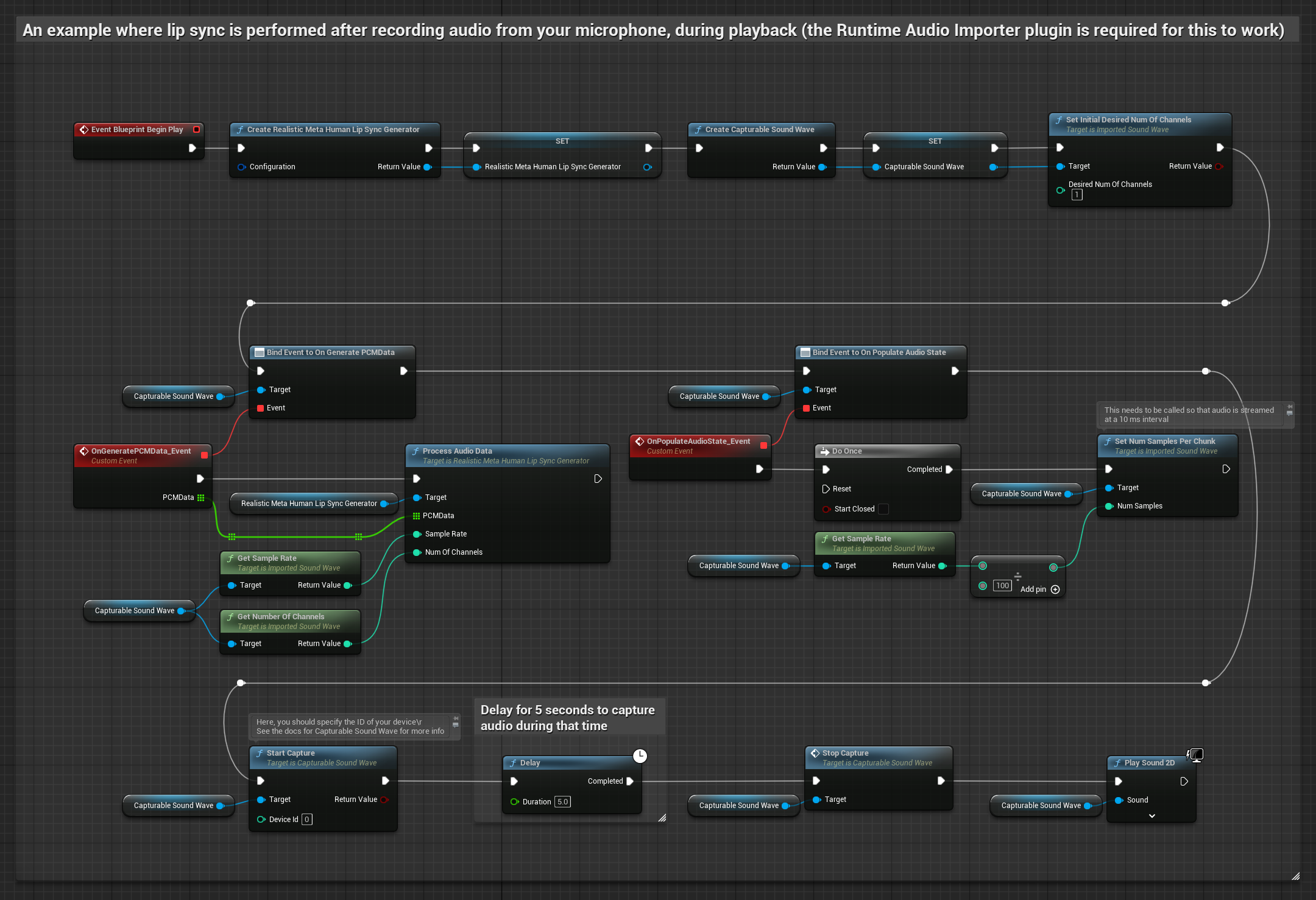
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleriyle birlikte gelir.

- Normal
- Akış
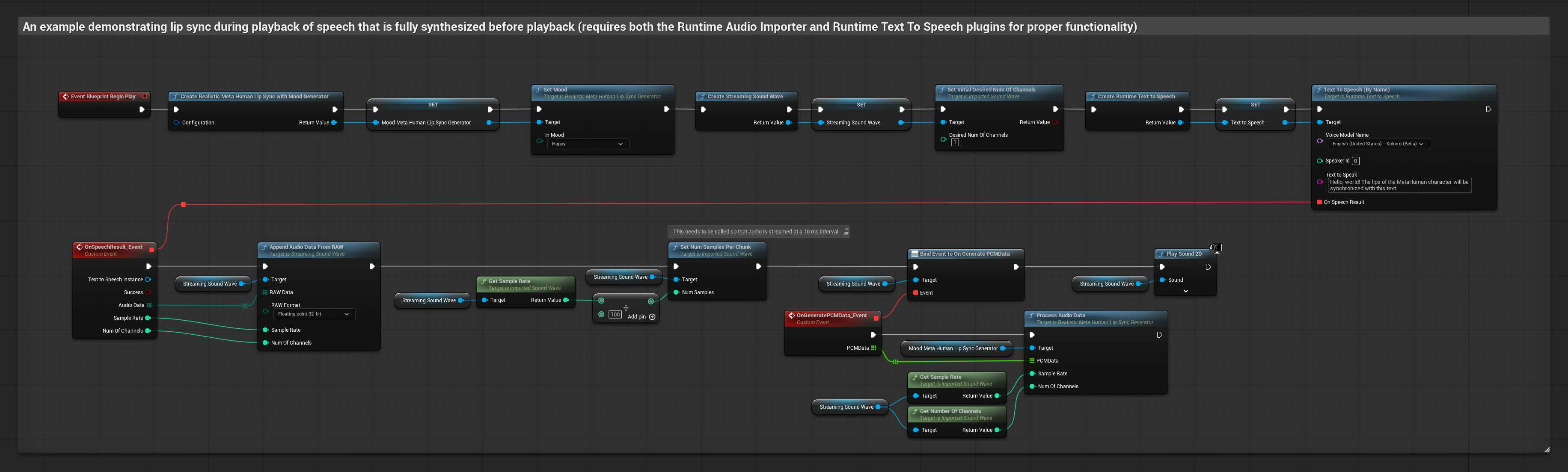
Bu yaklaşım, yerel TTS kullanarak metinden konuşma sentezler ve dudak senkronizasyonu gerçekleştirir.
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Metinlerden konuşma oluşturmak için Runtime Text To Speech kullanın
- Sentezlenen sesi içe aktarmak için Runtime Audio Importer kullanın
- İçe aktarılan ses dalgasını oynatmadan önce,
OnGeneratePCMDatatemsilcisine bağlanın - Bağlı fonksiyonda, Runtime Viseme Generator'ünüzden
ProcessAudioDatafonksiyonunu çağırın
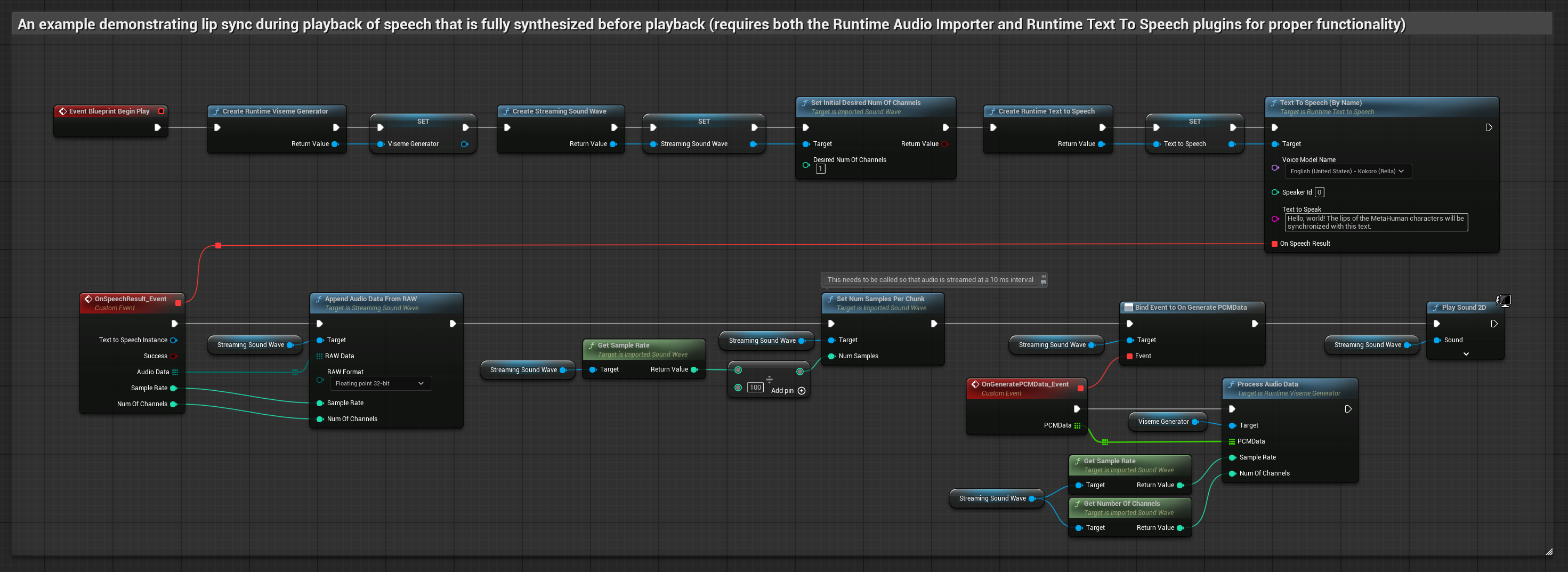
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
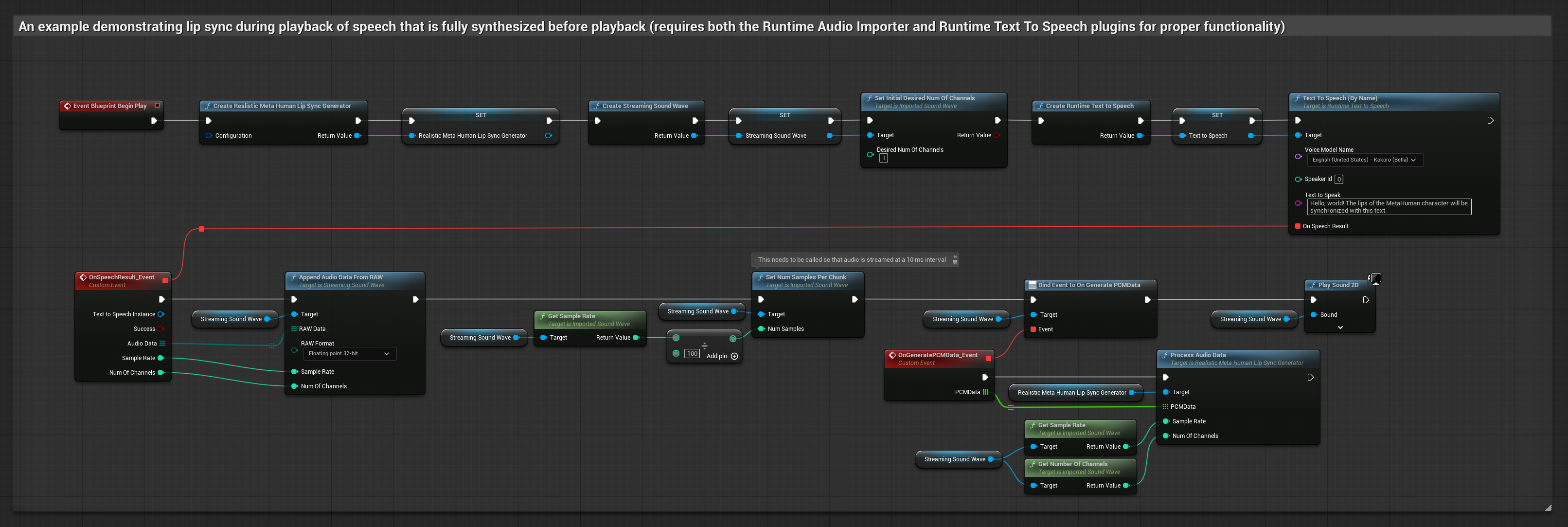
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleriyle birlikte gelir.
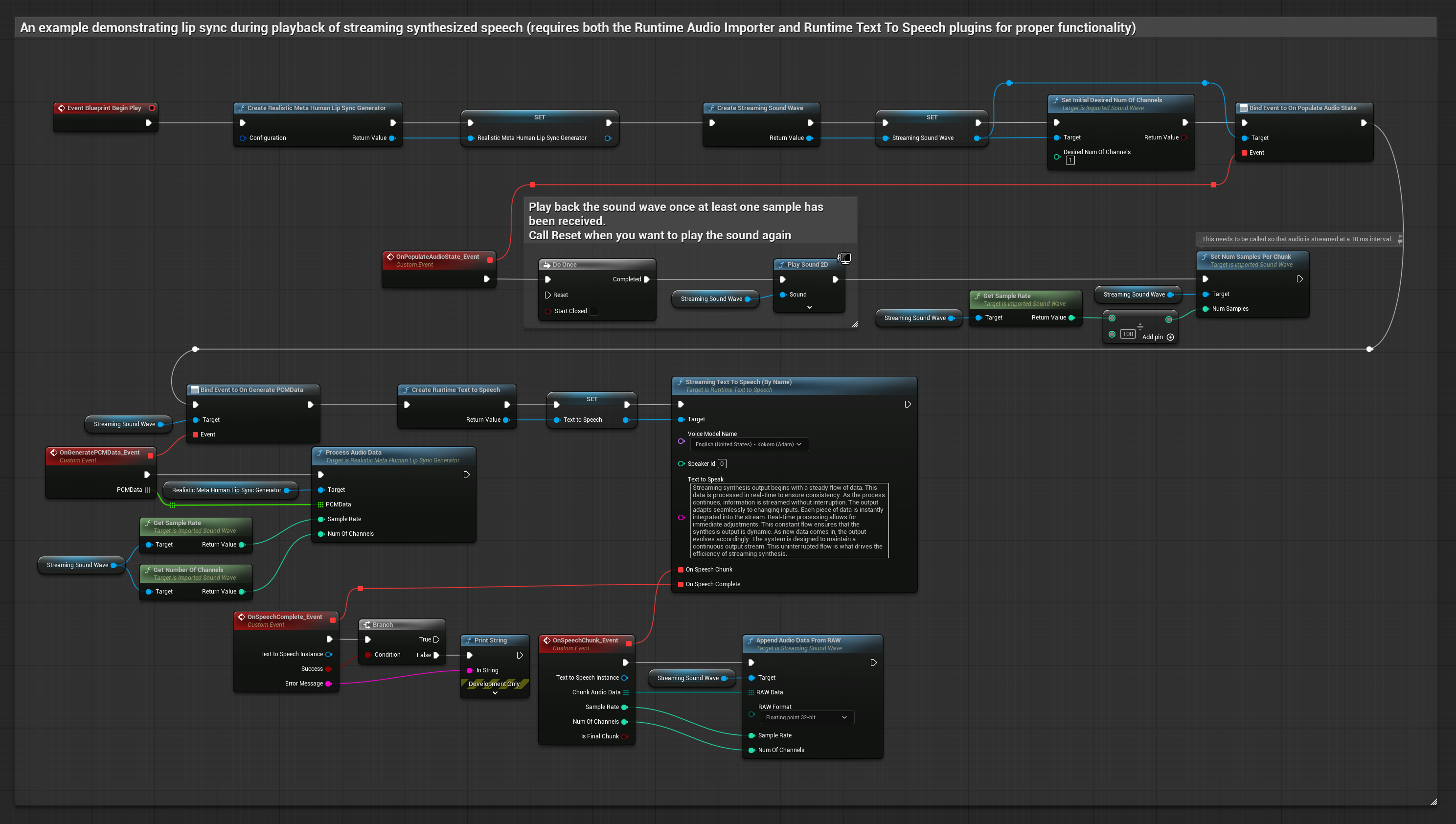
Bu yaklaşım, gerçek zamanlı dudak senkronizasyonu ile akışlı metin-konuşma sentezini kullanır.
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Metinlerden akışlı konuşma oluşturmak için Runtime Text To Speech kullanın
- Sentezlenen sesi içe aktarmak için Runtime Audio Importer kullanın
- Akışlı ses dalgasını oynatmadan önce,
OnGeneratePCMDatatemsilcisine bağlanın - Bağlı fonksiyonda, Runtime Viseme Generator'ınızdan
ProcessAudioDataçağrısı yapın
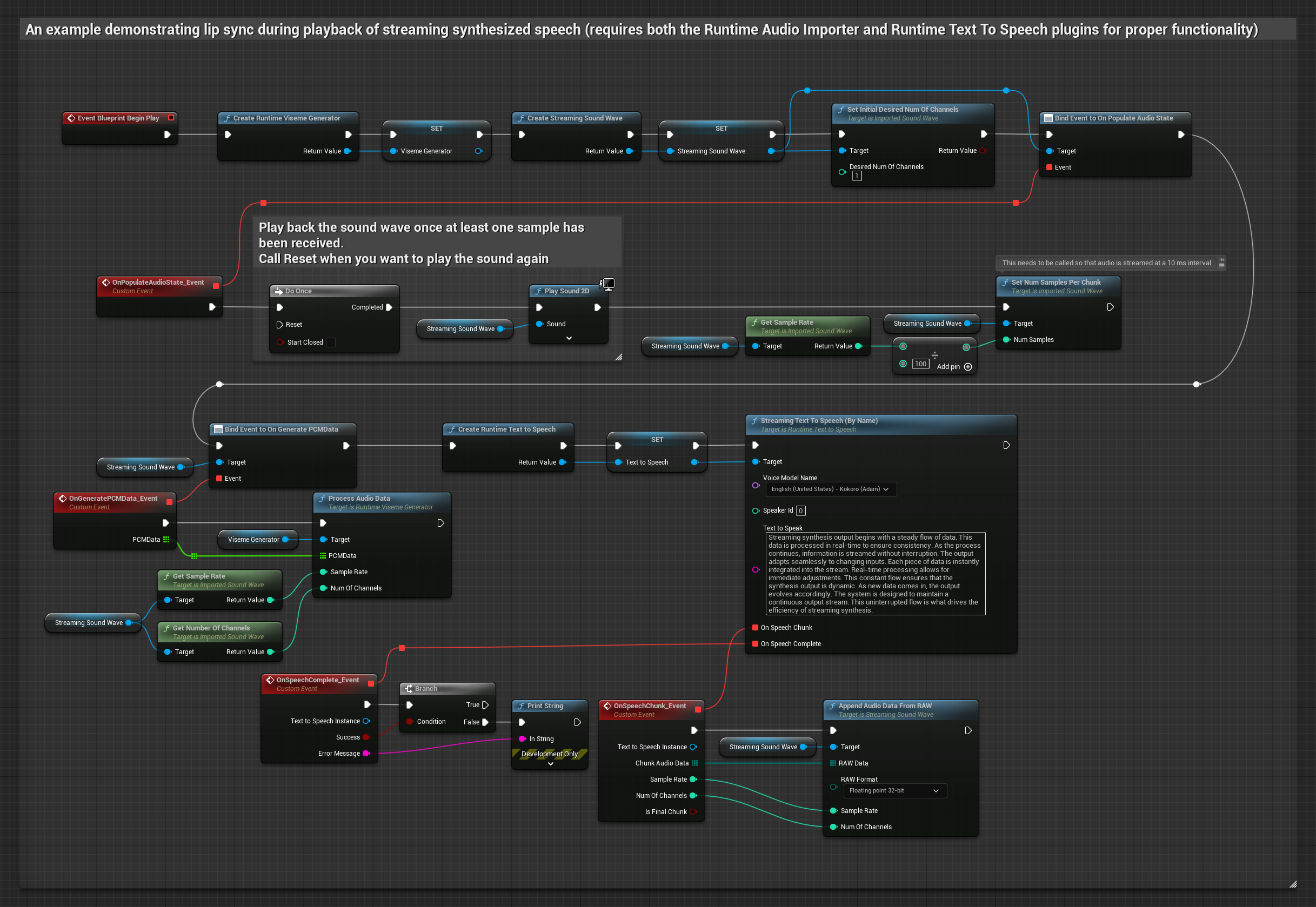
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleri ile birlikte çalışır.
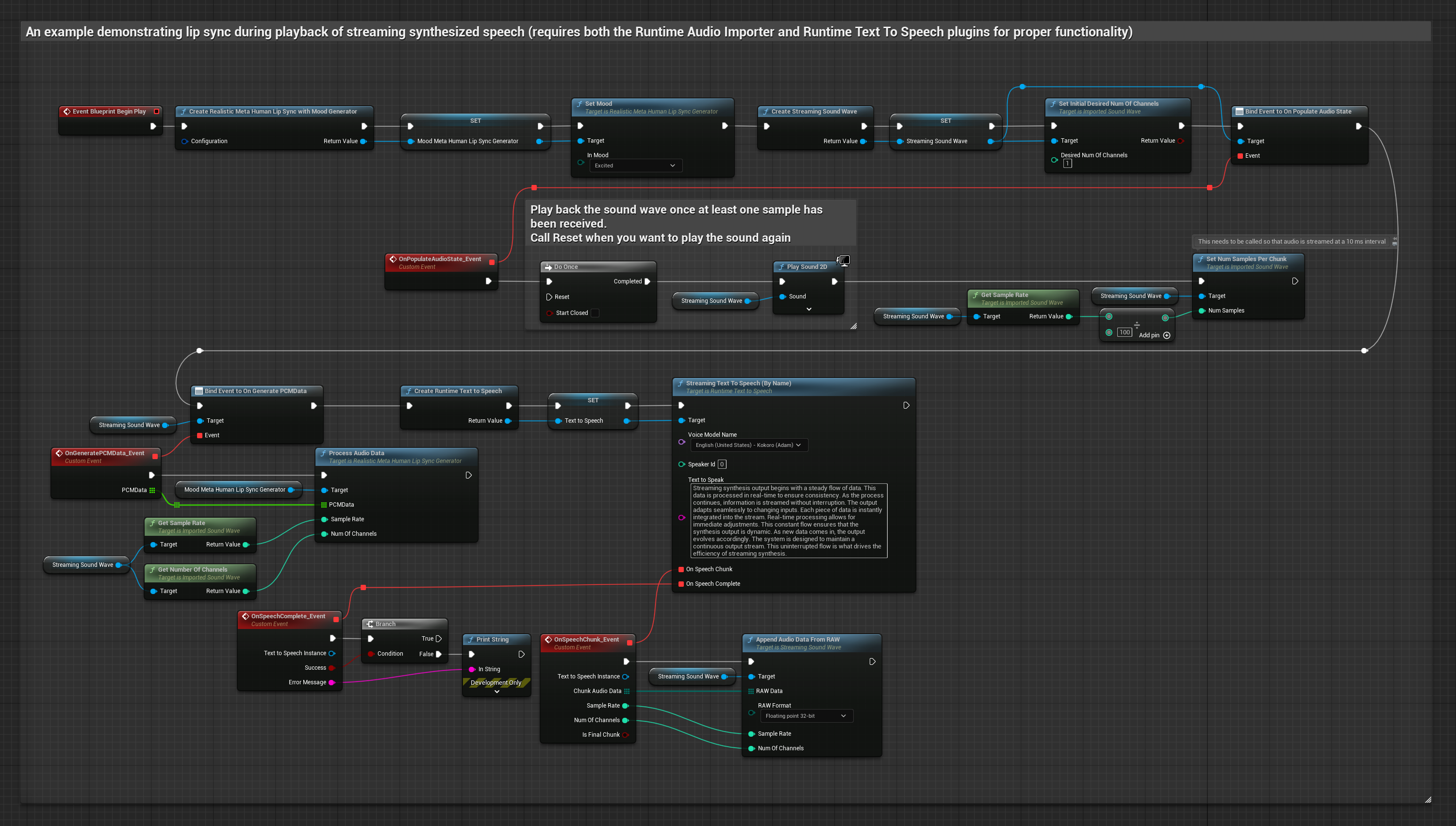
- Normal
- Akış
Bu yaklaşım, yapay zeka hizmetlerinden (OpenAI veya ElevenLabs) sentezlenmiş konuşma üretmek ve dudak senkronizasyonu gerçekleştirmek için Runtime AI Chatbot Integrator eklentisini kullanır.
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Harici API'ler (OpenAI, ElevenLabs vb.) kullanarak metinden konuşma oluşturmak için Runtime AI Chatbot Integrator kullanın
- Sentezlenen ses verilerini içe aktarmak için Runtime Audio Importer kullanın
- İçe aktarılan ses dalgasını oynatmadan önce,
OnGeneratePCMDatadelegate'ine bağlanın - Bağlı fonksiyonda, Runtime Viseme Generator'ünüzden
ProcessAudioData'yı çağırın
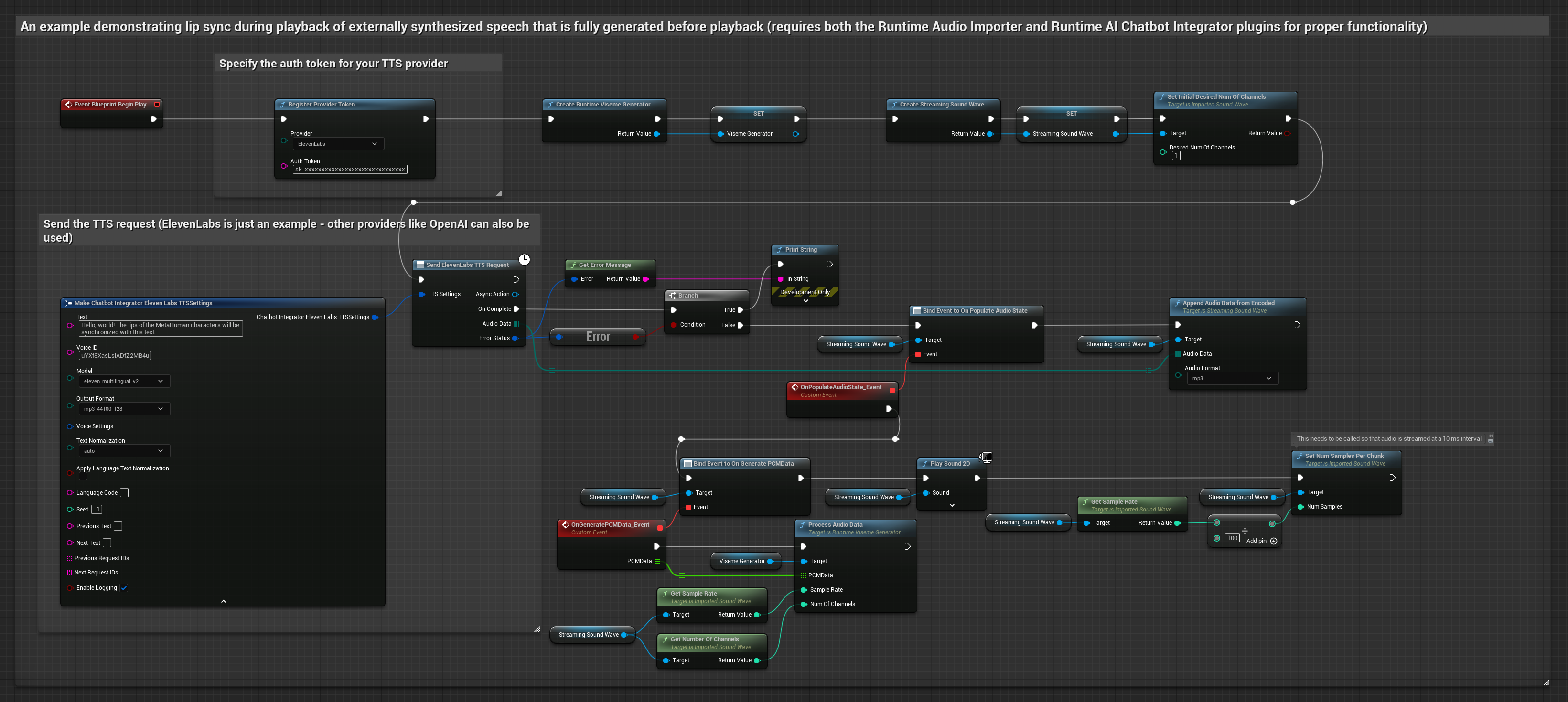
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
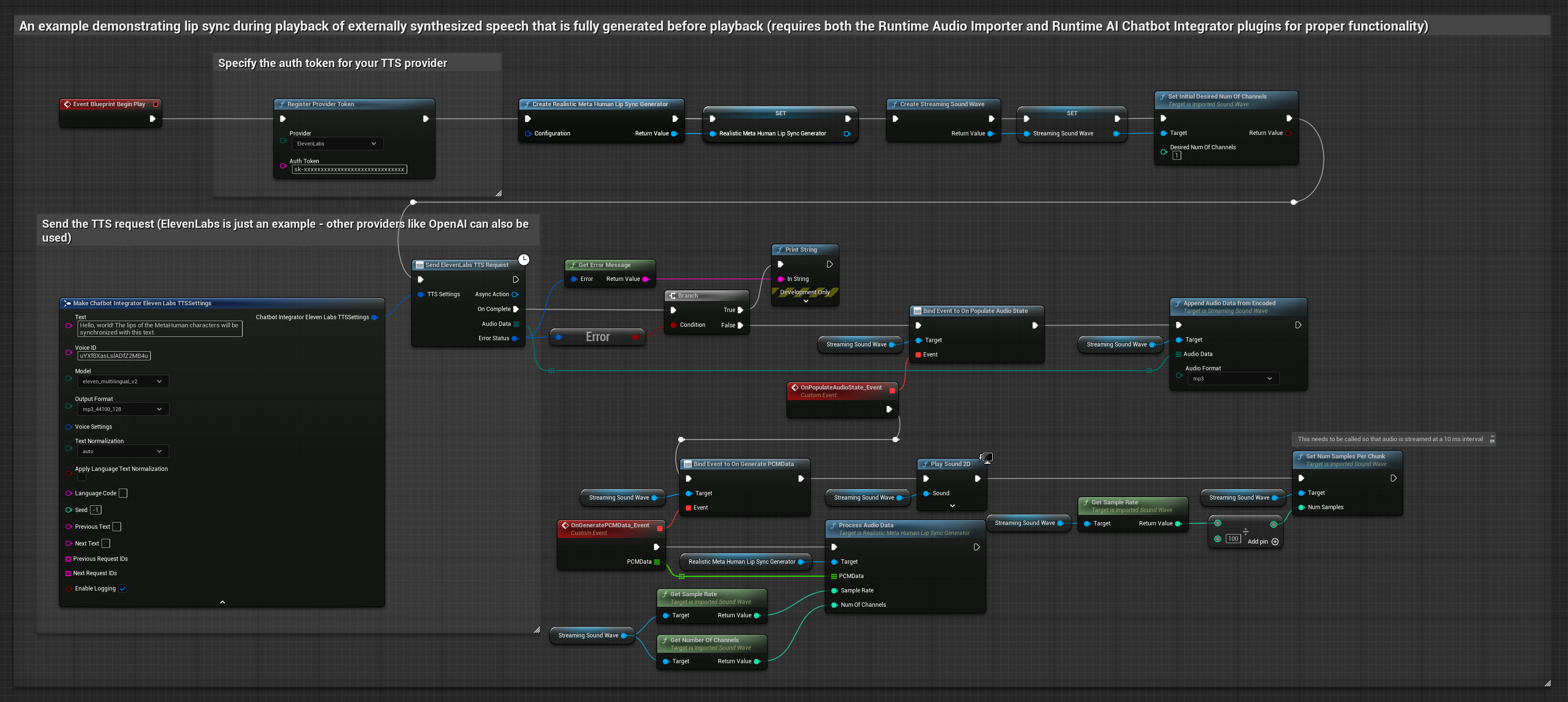
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleri ile birlikte çalışır.
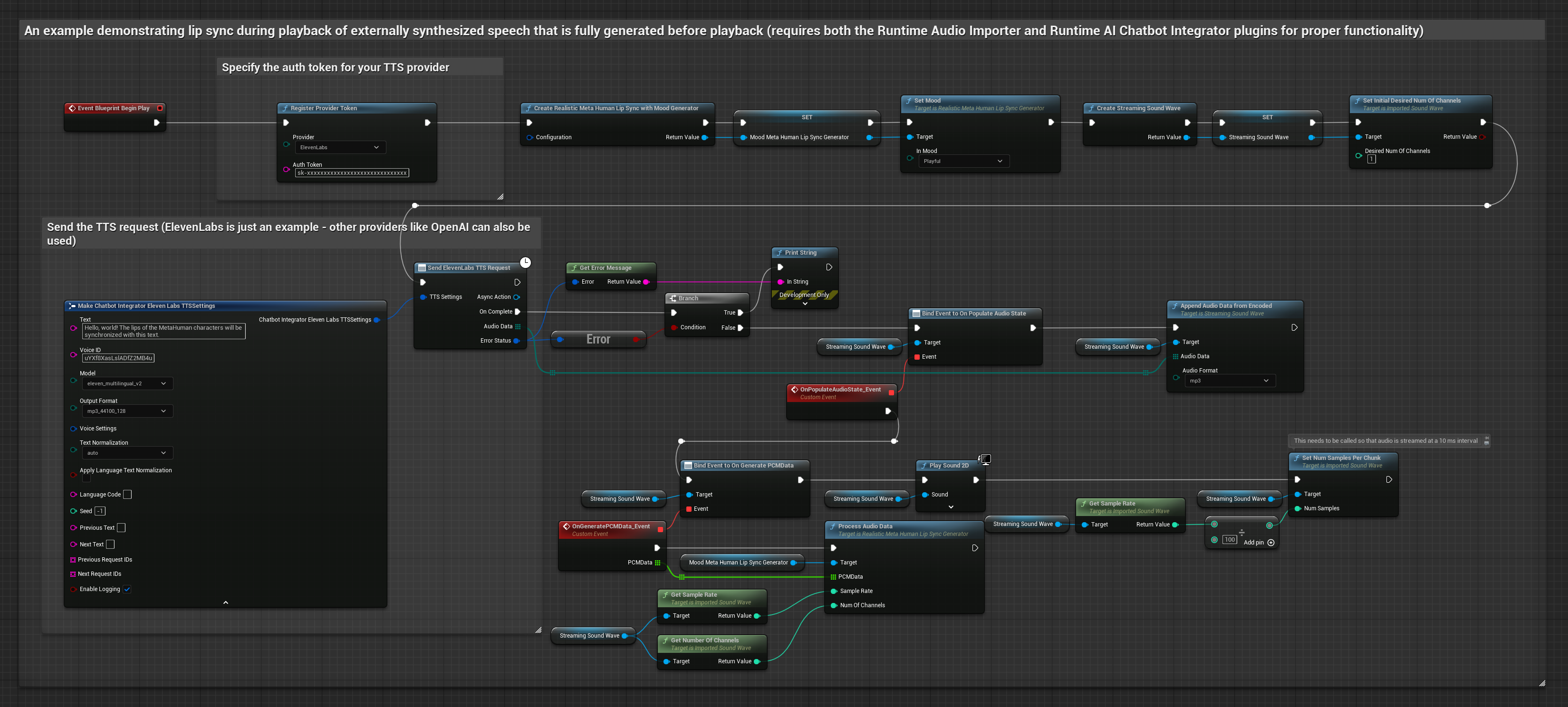
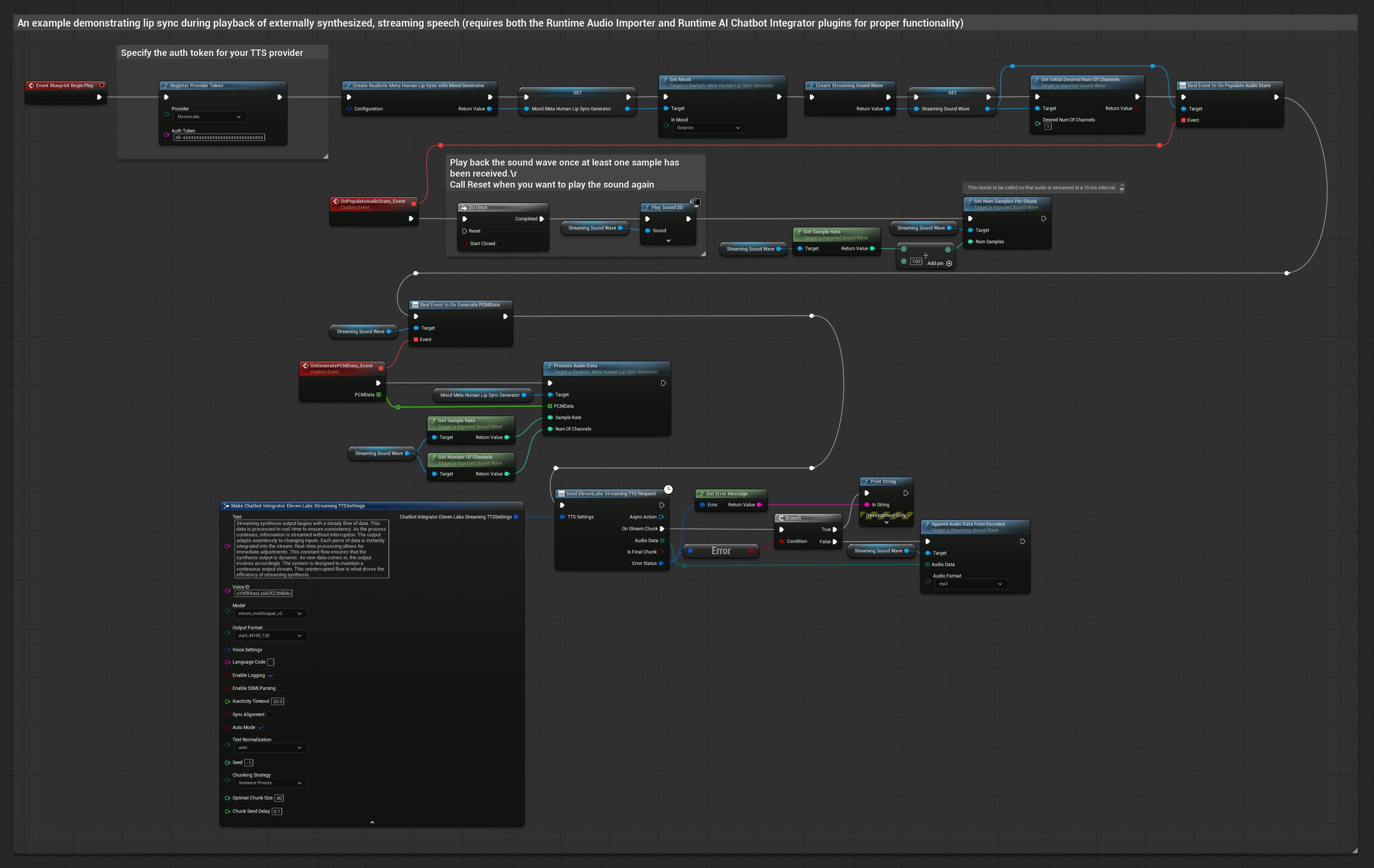
Bu yaklaşım, yapay zeka hizmetlerinden (OpenAI veya ElevenLabs) sentezlenmiş akışlı konuşma üretmek ve dudak senkronizasyonu gerçekleştirmek için Runtime AI Chatbot Integrator eklentisini kullanır.
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Runtime AI Chatbot Integrator kullanarak akışlı TTS API'lerine (ElevenLabs Streaming API gibi) bağlanın
- Sentezlenmiş ses verilerini içe aktarmak için Runtime Audio Importer kullanın
- Akışlı ses dalgasını oynatmadan önce,
OnGeneratePCMDatatemsilcisine bağlanın - Bağlı fonksiyonda, Runtime Viseme Generator'ünüzden
ProcessAudioDatafonksiyonunu çağırın
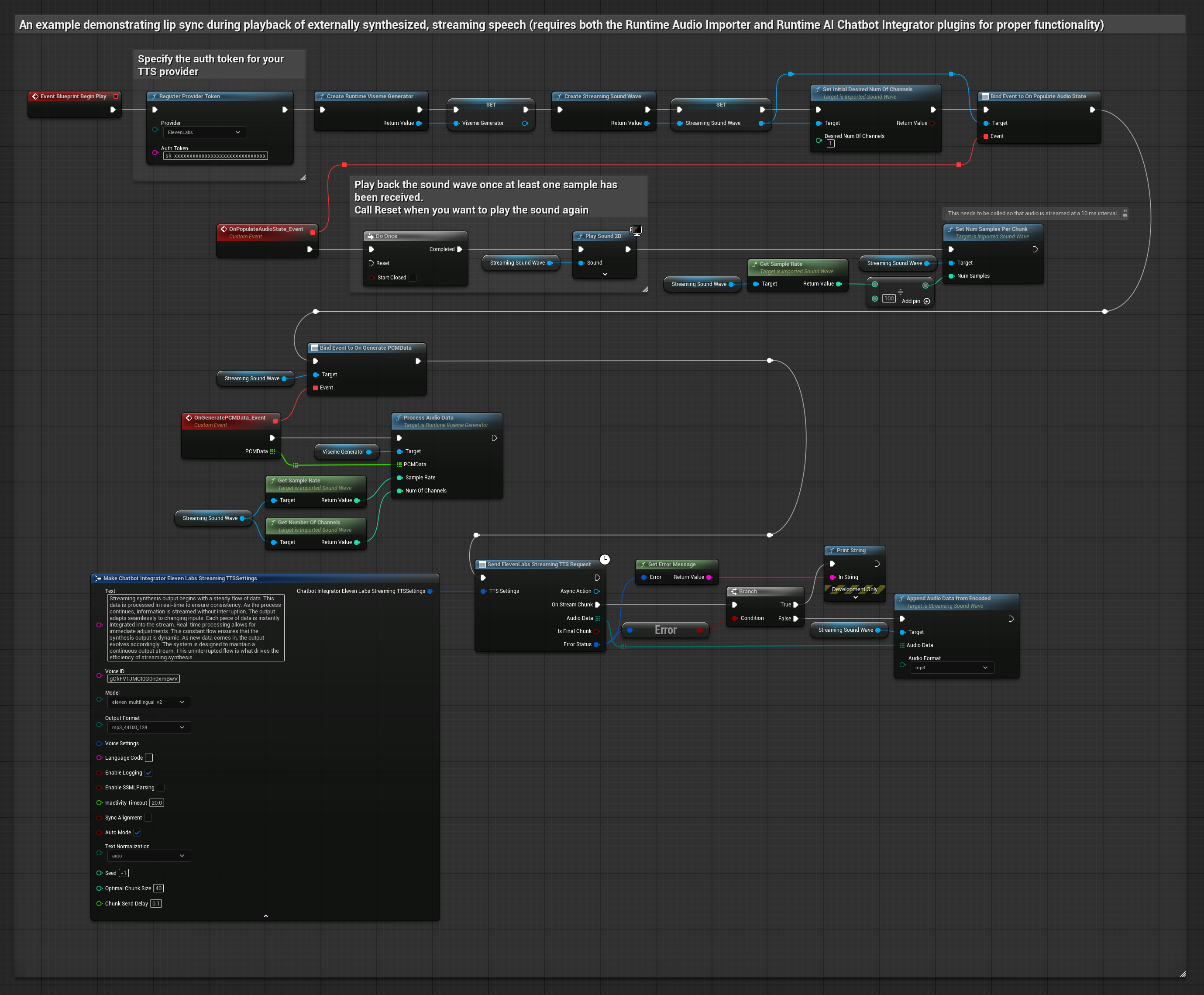
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
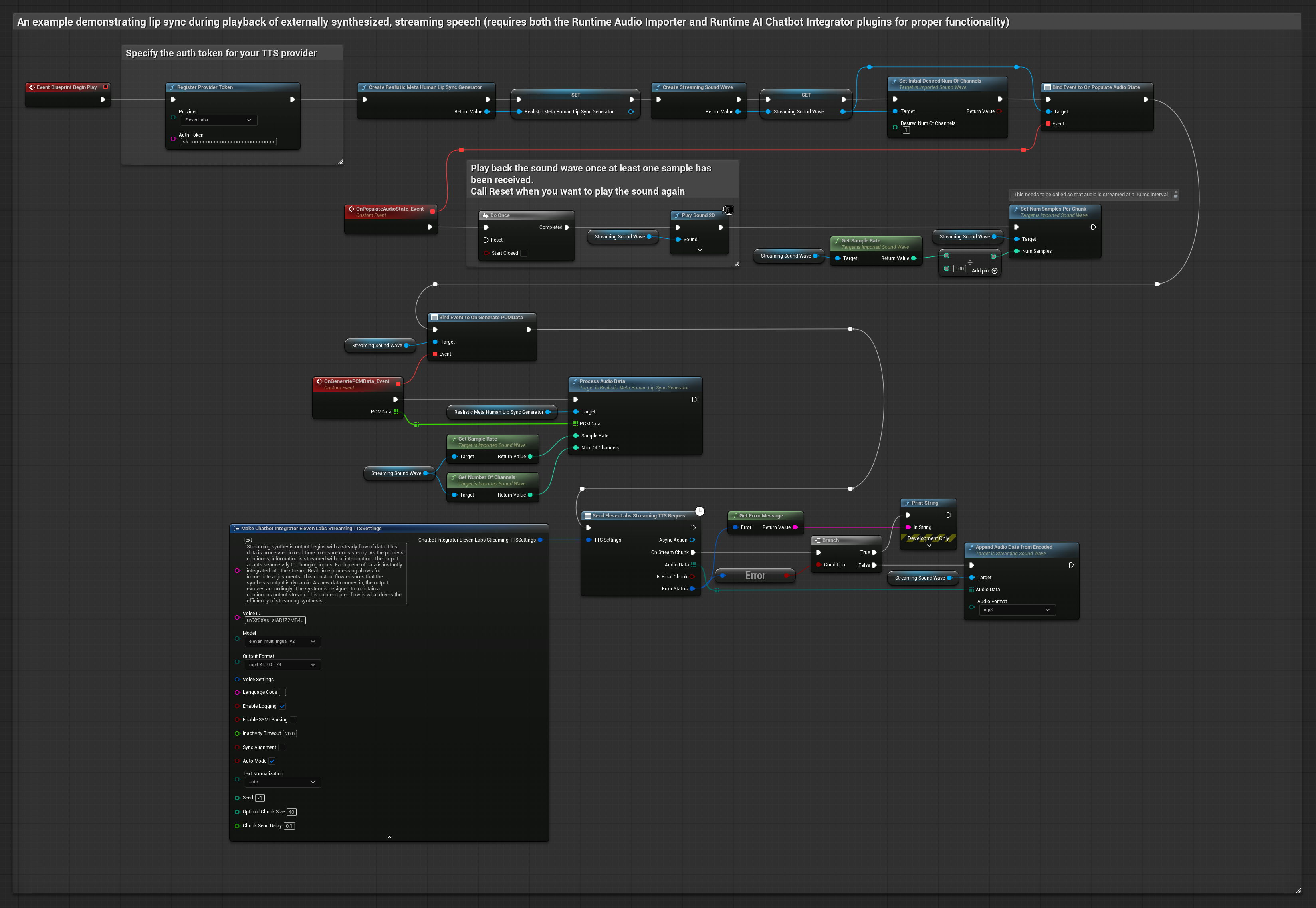
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleriyle birlikte gelir.
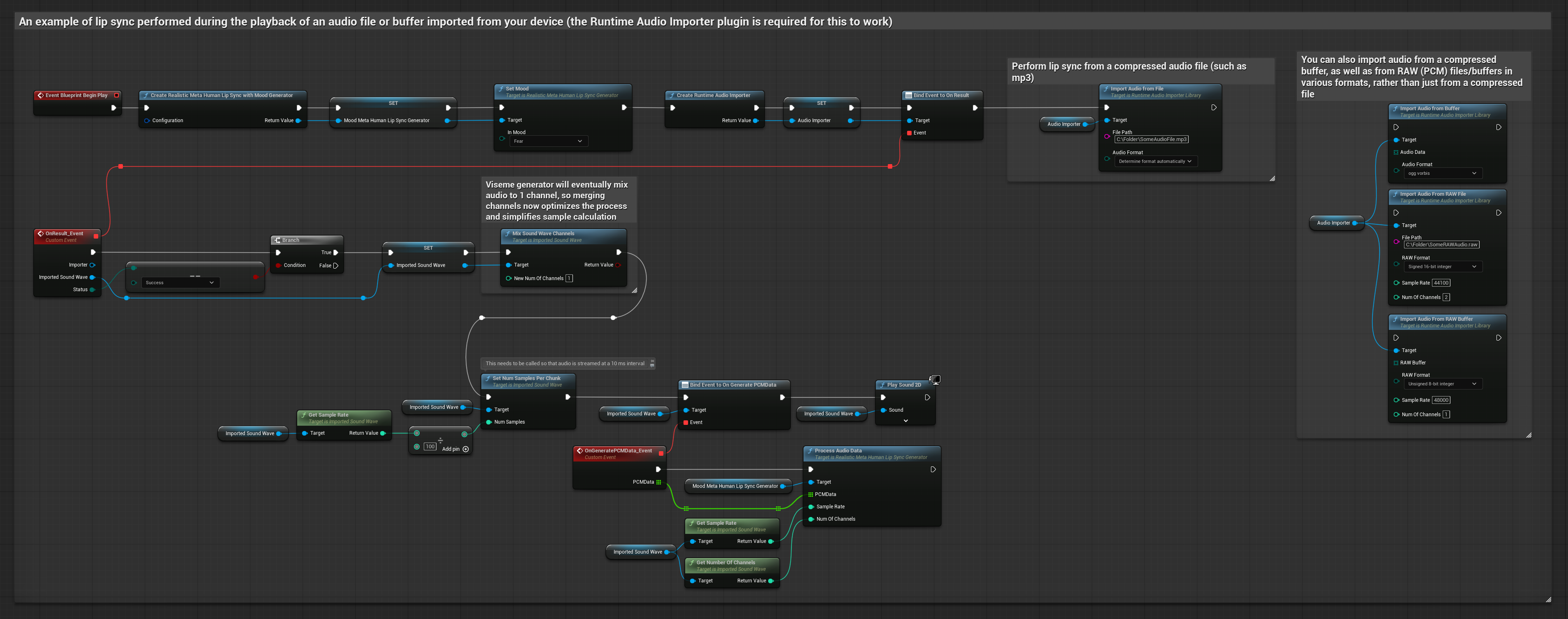
Bu yaklaşım, dudak senkronizasyonu için önceden kaydedilmiş ses dosyalarını veya ses tamponlarını kullanır:
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkinleştirilmiş Gerçekçi Model
- Diskten veya bellekten bir ses dosyasını içe aktarmak için Runtime Audio Importer kullanın
- İçe aktarılan ses dalgasını oynatmadan önce, onun
OnGeneratePCMDatatemsilcisine bağlanın - Bağlı fonksiyonda, Runtime Viseme Generator'ünüzden
ProcessAudioDatafonksiyonunu çağırın - İçe aktarılan ses dalgasını oynatın ve dudak senkronizasyonu animasyonunu gözlemleyin
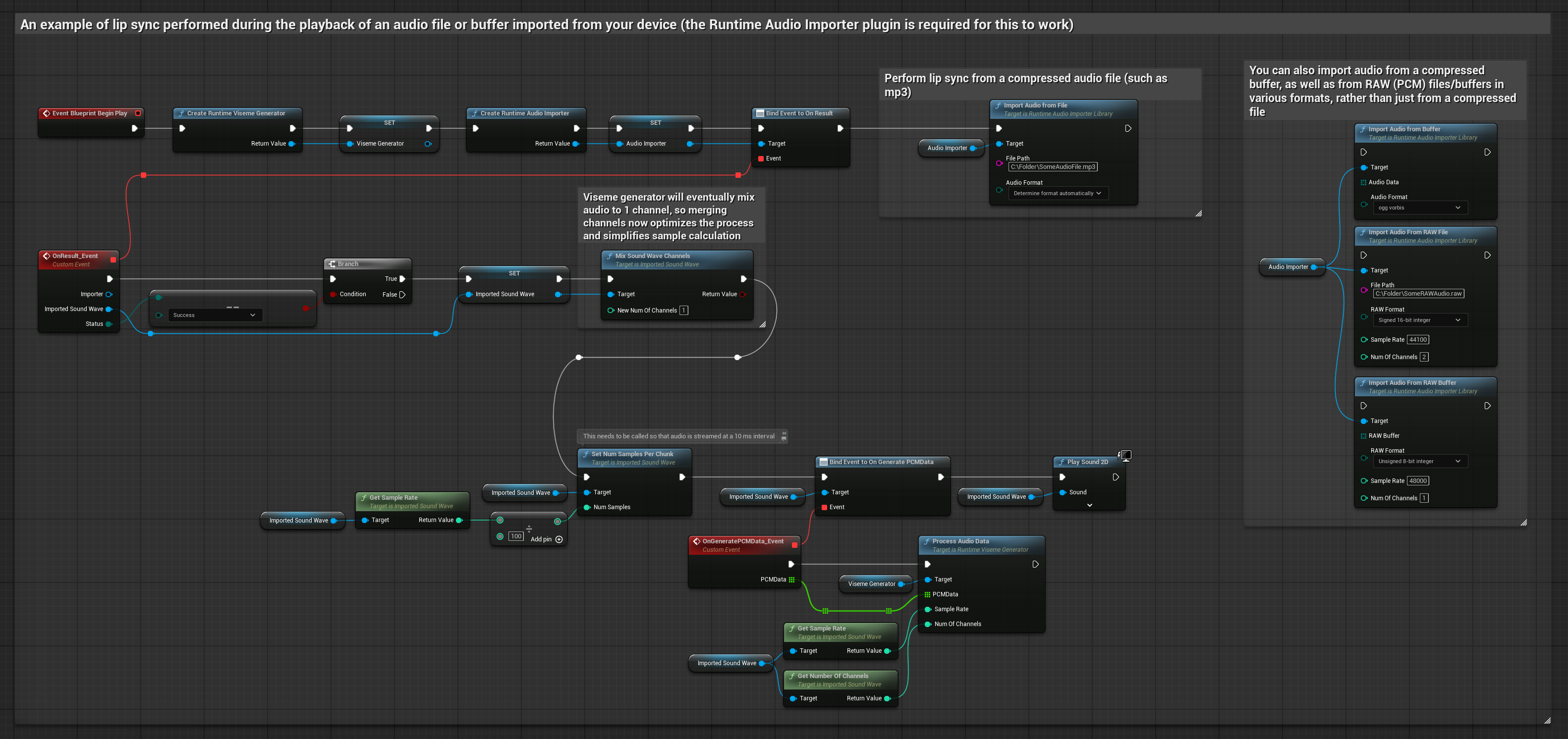
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
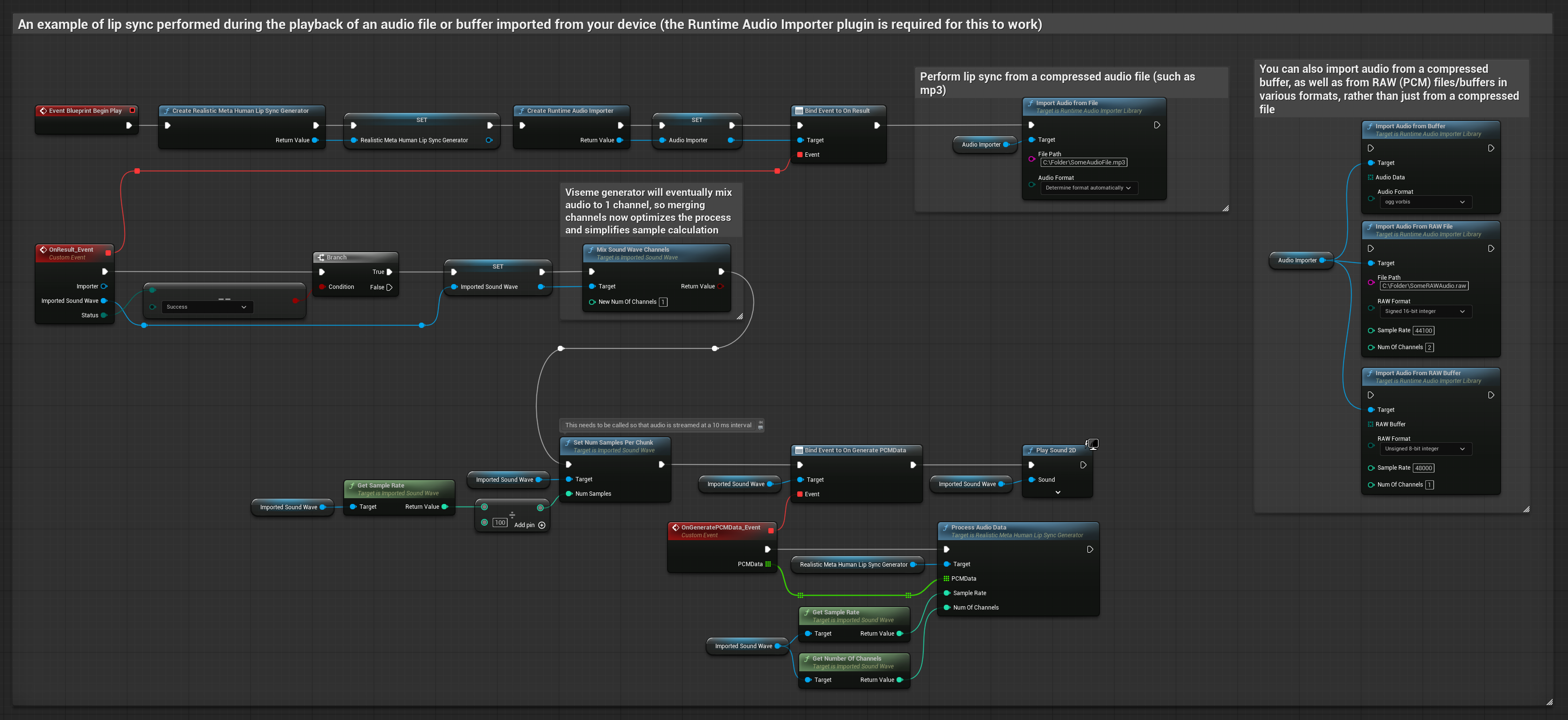
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleri ile birlikte çalışır.
Bir tampondan akan ses verisi akışı için ihtiyacınız olan:
- Standart Model
- Gerçekçi Model
- Ruh Hali Etkin Gerçekçi Model
- Ses verileri float PCM formatında (kayan noktalı örneklerden oluşan bir dizi) akış kaynağınızdan elde edilebilir (veya daha fazla formatı desteklemek için Runtime Audio Importer kullanın)
- Örnekleme hızı ve kanal sayısı
- Ses parçaları kullanılabilir hale geldikçe, Runtime Viseme Generator'ınızdan
ProcessAudioData'yı bu parametrelerle çağırın
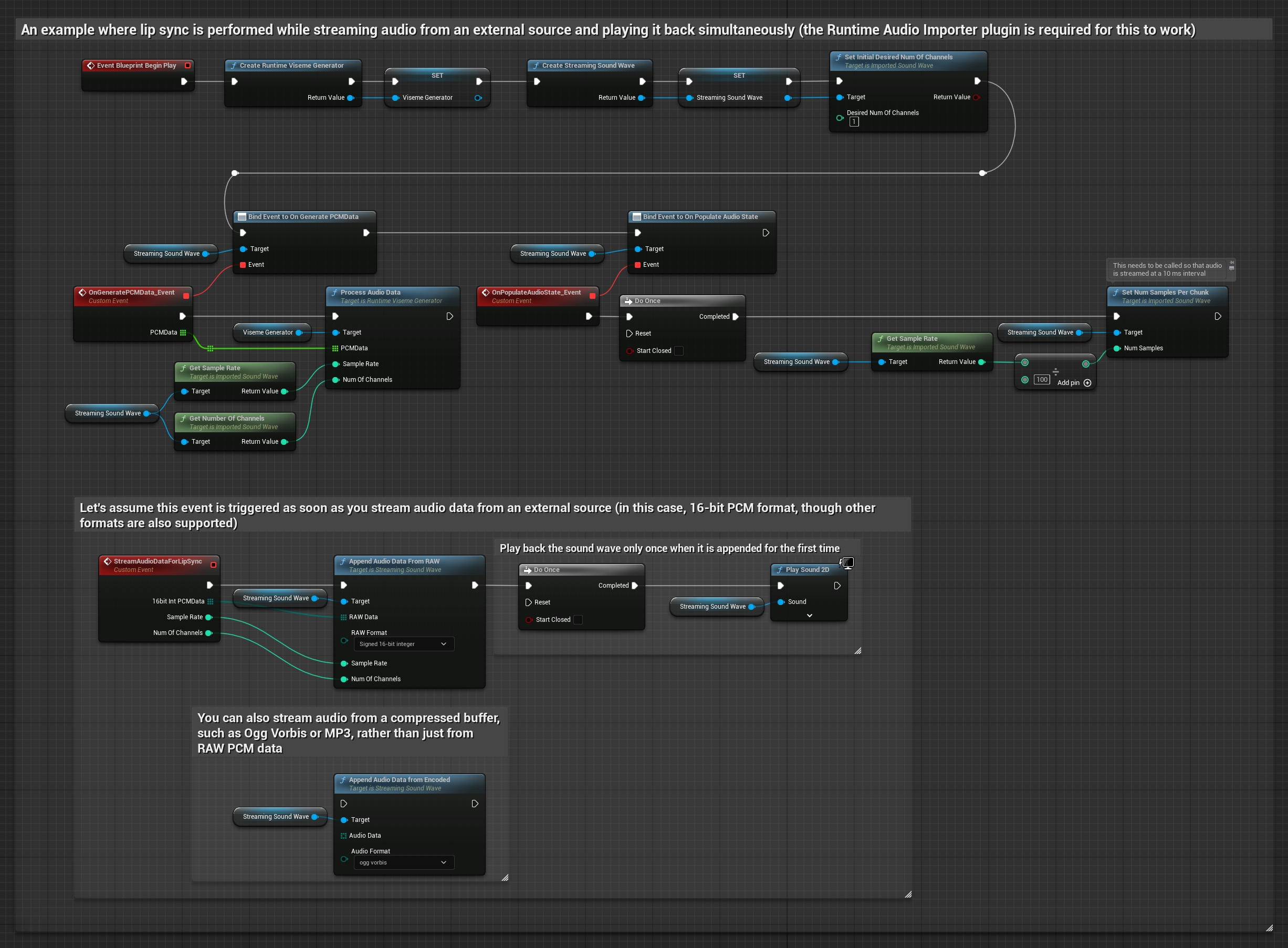
Gerçekçi Model, Standart Model ile aynı ses işleme iş akışını kullanır, ancak VisemeGenerator yerine RealisticLipSyncGenerator değişkenini kullanır.
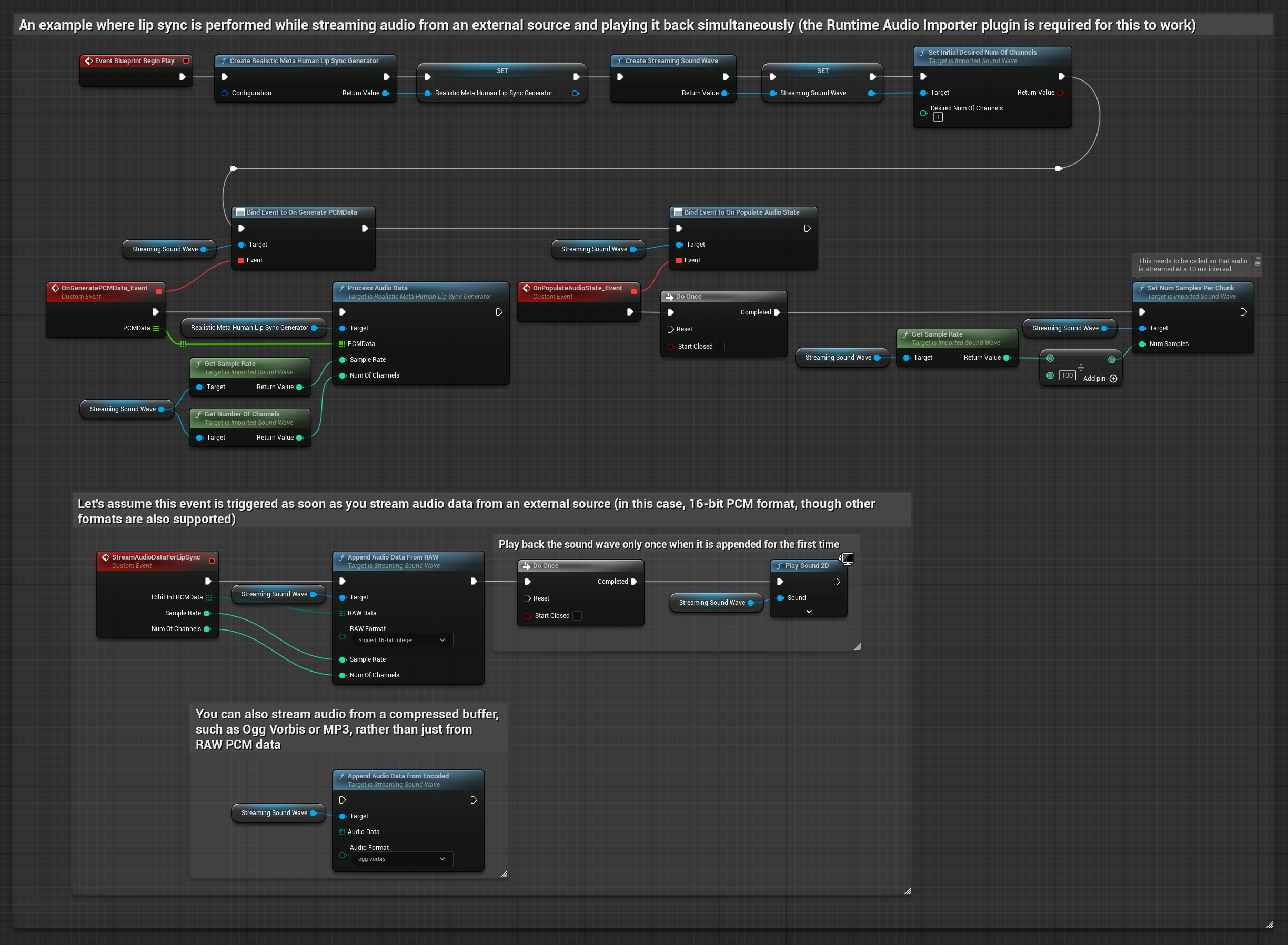
Ruh Hali Etkin Model, aynı ses işleme iş akışını kullanır ancak MoodMetaHumanLipSyncGenerator değişkeni ve ek ruh hali yapılandırma yetenekleriyle birlikte gelir.
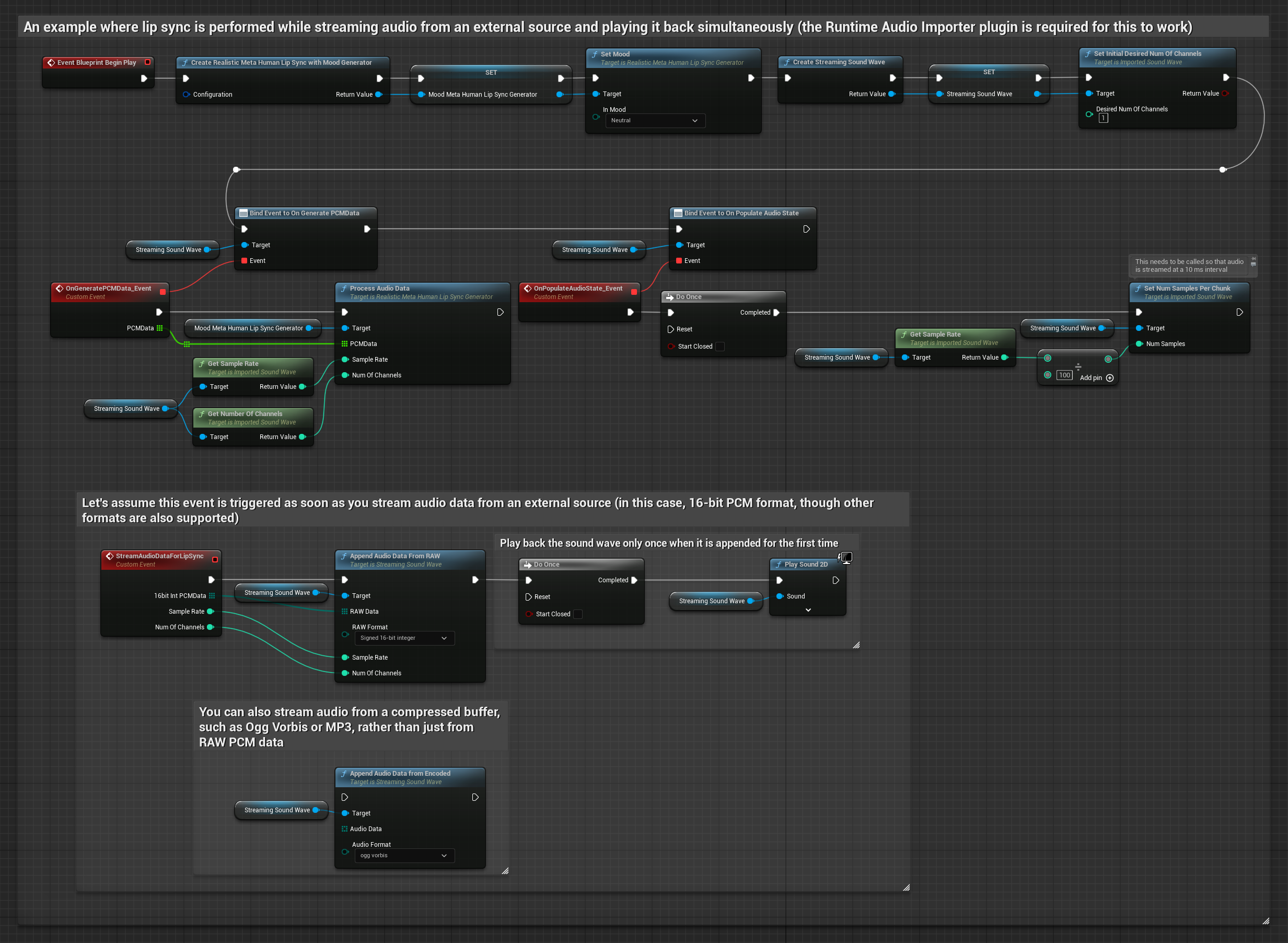
Not: Akışlı ses kaynakları kullanırken, bozuk oynatmayı önlemek için ses oynatma zamanlamasını uygun şekilde yönettiğinizden emin olun. Daha fazla bilgi için Akışlı Ses Dalgası dokümantasyonuna bakın.
İşlem Performansı İpuçları
-
Chunk Boyutu:
ProcessingChunkSizeyapılandırma seçeneğini (örneğin 320, 480 veya 640 örneğe) artırmak, kalite veya yanıt verme hızı üzerinde minimum etkiyle gecikmeyi belirgin şekilde iyileştirebilir. -
Model Türü: Gerçekçi modeller kullanırken, Yüksek Düzeyde Optimize Edilmiş model türüne (varsayılan olarak seçili) geçmek performansı artırabilir. Orijinal modelin, özellikle gürültülü seslerde, biraz daha iyi kalite sağlayabileceğini unutmayın.
-
Tampon Yönetimi: Ruh hali destekli model, sesi 320 örneklik çerçeveler halinde işler (16kHz'de 20ms). Optimum performans için ses giriş zamanlamanızın bununla uyumlu olduğundan emin olun.
-
Generator Yeniden Oluşturma: Gerçekçi modellerle güvenilir çalışma için, bir süre hareketsiz kaldıktan sonra yeni ses verisi beslemek istediğinizde generator'ü her seferinde yeniden oluşturun. Açıklama için Sorun Giderme bölümündeki Generator Yeniden Oluşturma bölümüne bakın.
Sonraki Adımlar
Ses işleme kurulumunu tamamladıktan sonra şunları yapmak isteyebilirsiniz:
- Dudak senkronizasyonu davranışınızı ince ayarlamak için Yapılandırma seçenekleri hakkında bilgi edinin
- Gelişmiş ifade gücü için kahkaha animasyonu ekleyin
- Yapılandırma kılavuzunda açıklanan katmanlama tekniklerini kullanarak dudak senkronizasyonunu mevcut yüz animasyonlarıyla birleştirin