Eklentiyi nasıl kullanırsınız
Runtime Text To Speech eklentisi, indirilebilir ses modellerini kullanarak metni sese dönüştürür. Bu modeller, editör içindeki eklenti ayarlarında yönetilir, indirilir ve runtime kullanımı için paketlenir. Başlamak için aşağıdaki adımları izleyin.
Editör tarafı
Projeniz için uygun ses modellerini burada açıklandığı gibi indirin. Aynı anda birden fazla ses modeli indirebilirsiniz.
Runtime tarafı
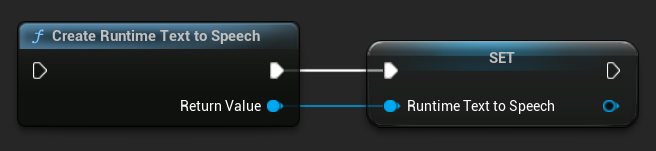
Sentezleyiciyi CreateRuntimeTextToSpeech fonksiyonunu kullanarak oluşturun. Çöp toplama (garbage collection) tarafından silinmesini önlemek için ona bir referans tuttuğunuzdan emin olun (örneğin Blueprints'te ayrı bir değişken olarak veya C++'ta UPROPERTY ile).
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Konuşma Sentezleme
Eklenti, iki metinden-konuşmaya sentezleme modu sunar:
- Düzenli Metinden-Konuşmaya: Tüm metni sentezler ve tamamlandığında sesi döndürür
- Akışlı Metinden-Konuşmaya: Ses parçalarını oluşturuldukça sağlar, gerçek zamanlı işleme imkanı tanır
Her mod, ses modellerini seçmek için iki yöntem destekler:
- İsimle: Bir ses modelini ismiyle seçin (UE 5.4+ için önerilir)
- Nesneyle: Bir ses modelini doğrudan referansla seçin (UE 5.3 ve öncesi için önerilir)
Düzenli Metinden-Konuşmaya
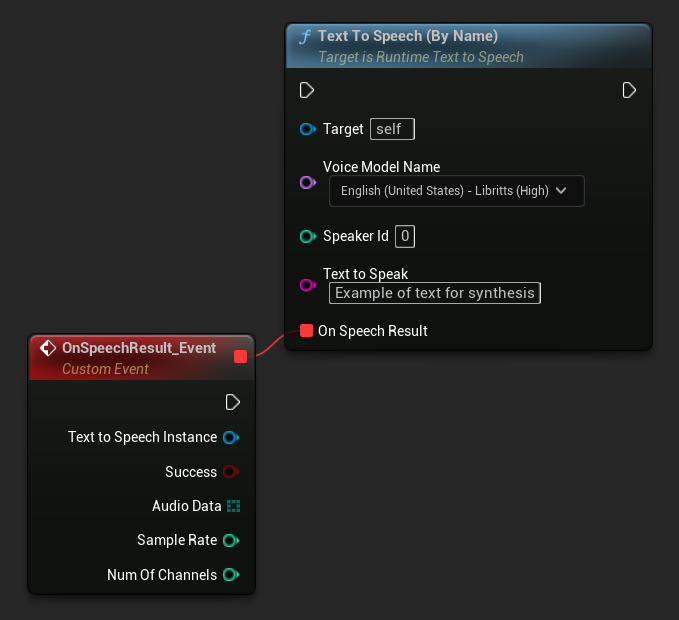
İsimle
- Blueprint
- C++
Text To Speech (By Name) fonksiyonu, UE 5.4'ten itibaren Blueprint'lerde daha kullanışlıdır. İndirilen modellerin bir açılır listesinden ses modelleri seçmenize olanak tanır. UE 5.3 ve altı sürümlerde, bu açılır liste görünmez, bu nedenle daha eski bir sürüm kullanıyorsanız, ihtiyacınız olanı seçmek için GetDownloadedVoiceModels tarafından döndürülen ses modelleri dizisini manuel olarak döngüye almanız gerekir.
C++'da, ses modellerinin seçimi açılır liste eksikliği nedeniyle biraz daha karmaşık olabilir. İndirilen ses modellerinin isimlerini almak için GetDownloadedVoiceModelNames fonksiyonunu kullanabilir ve ihtiyacınız olanı seçebilirsiniz. Ardından, seçilen ses modeli ismini kullanarak metin sentezlemek için TextToSpeechByName fonksiyonunu çağırabilirsiniz.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
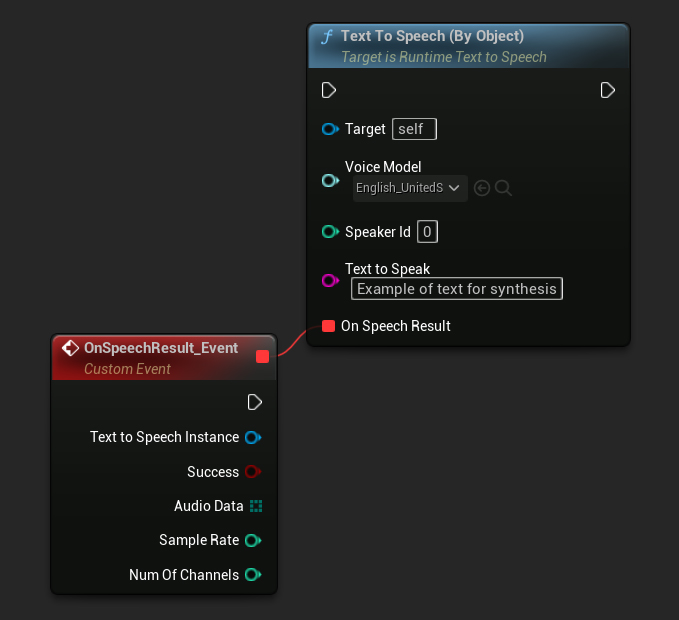
Nesne İle
- Blueprint
- C++
Text To Speech (By Object) fonksiyonu Unreal Engine'in tüm sürümlerinde çalışır ancak ses modellerini bir varlık referansları açılır listesi olarak sunar, bu daha az sezgiseldir. Bu yöntem UE 5.3 ve önceki sürümler için uygundur veya projeniz herhangi bir nedenle doğrudan bir ses modeli varlığına referans gerektiriyorsa.
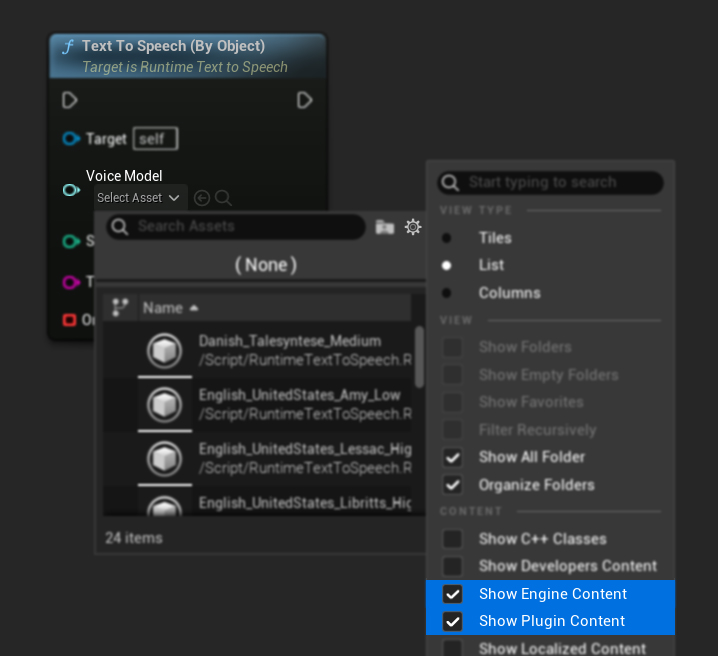
Modelleri indirdiyseniz ancak göremiyorsanız, Voice Model açılır listesini açın, ayarlar (dişli çark simgesi) seçeneğine tıklayın ve hem Show Plugin Content hem de Show Engine Content seçeneklerini etkinleştirerek modelleri görünür hale getirin.
C++'da, ses modellerinin seçimi bir açılır liste olmaması nedeniyle biraz daha karmaşık olabilir. İndirilen ses modellerinin isimlerini almak için GetDownloadedVoiceModelNames fonksiyonunu kullanabilir ve ihtiyacınız olanı seçebilirsiniz. Ardından, ses modeli nesnesini almak için GetVoiceModelFromName fonksiyonunu çağırabilir ve metni sentezlemek için TextToSpeechByObject fonksiyonuna iletebilirsiniz.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Akışlı Metinden Sese
Daha uzun metinler için veya ses verilerini oluşturulduğu gibi gerçek zamanlı olarak işlemek istediğinizde, Metinden Sese fonksiyonlarının akışlı sürümlerini kullanabilirsiniz:
Streaming Text To Speech (By Name)(C++'daStreamingTextToSpeechByName)Streaming Text To Speech (By Object)(C++'daStreamingTextToSpeechByObject)
Bu fonksiyonlar, ses verilerini oluşturuldukları gibi parçalar halinde sağlar, böylece tüm sentezin tamamlanmasını beklemeden hemen işleme olanağı tanır. Bu, gerçek zamanlı ses oynatma, canlı görselleştirme veya konuşma verilerini artımlı olarak işlemeniz gereken herhangi bir senaryo gibi çeşitli uygulamalar için kullanışlıdır.
İsimle Akış
- Blueprint
- C++
Streaming Text To Speech (By Name) fonksiyonu, normal sürümle benzer şekilde çalışır ancak sesi On Speech Chunk temsilcisi aracılığıyla parçalar halinde sağlar.
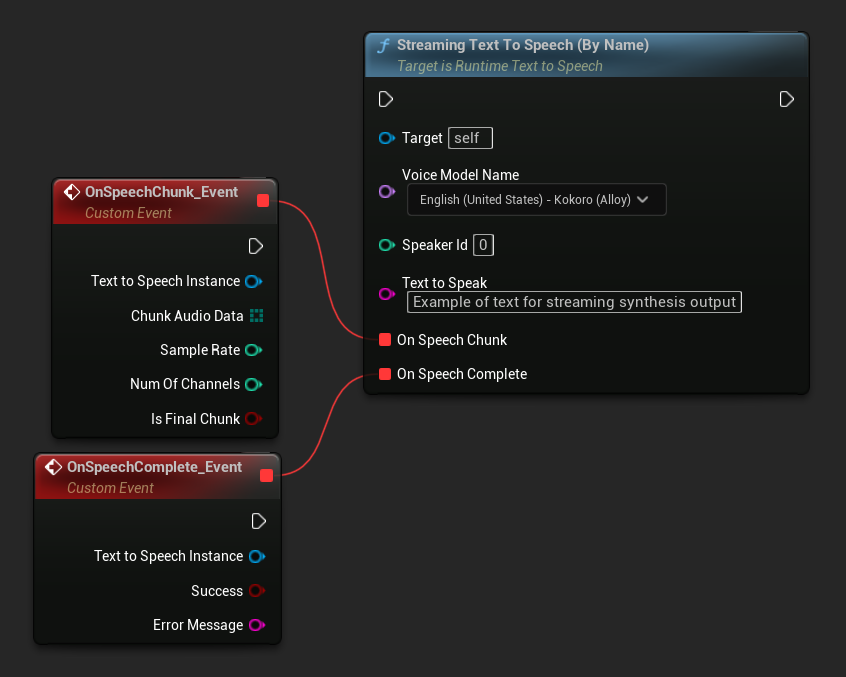
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Nesneye Göre Akış
- Blueprint
- C++
Streaming Text To Speech (By Object) işlevi aynı akış işlevselliğini sağlar ancak bir ses modeli nesne referansı alır.
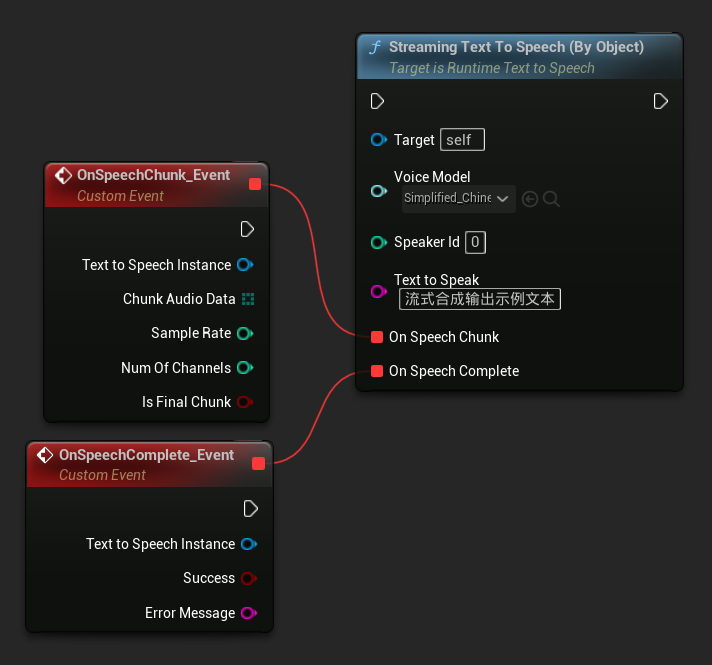
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Ses Oynatma
- Regular Playback
- Streaming Playback
Düzenli (akışsız) metinden sese için, On Speech Result temsilcisi, sentezlenmiş sesi PCM verisi olarak float formatında (Blueprint'lerde bir byte dizisi veya C++'da TArray<uint8> olarak), Sample Rate ve Num Of Channels ile birlikte sağlar.
Oynatma için, ham ses verisini oynatılabilir bir ses dalgasına dönüştürmek üzere Runtime Audio Importer eklentisini kullanmanız önerilir.
- Blueprint
- C++
Metni sentezleme ve sesi oynatma için Blueprint düğümlerinin nasıl görünebileceğine dair bir örnek (Kopyalanabilir düğümler):
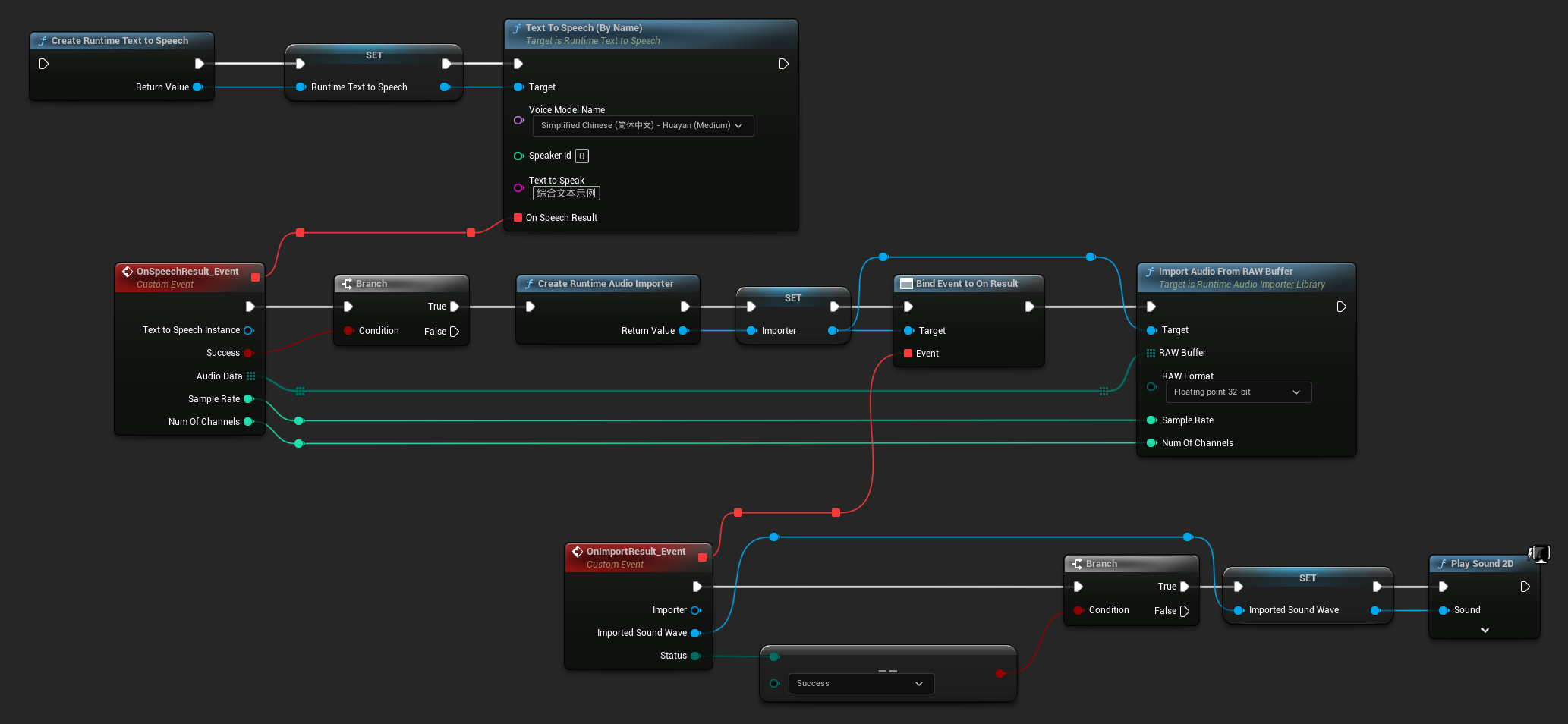
C++'da metni sentezleme ve sesi oynatma örneği:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Akışlı metin okuma için, PCM verilerini float formatında (Blueprint'lerde bir byte dizisi veya C++'da TArray<uint8> olarak), Örnekleme Oranı ve Kanal Sayısı ile birlikte parçalar halinde alacaksınız. Her parça, kullanılabilir olduğunda hemen işlenebilir.
Gerçek zamanlı oynatma için, özellikle akışlı ses oynatma veya gerçek zamanlı işleme için tasarlanmış Runtime Audio Importer eklentisinin Streaming Sound Wave kullanılması önerilir.
- Blueprint
- C++
İşte akışlı metin okuma ve sesi oynatma için Blueprint düğümlerinin nasıl görünebileceğine dair bir örnek (Kopyalanabilir düğümler):
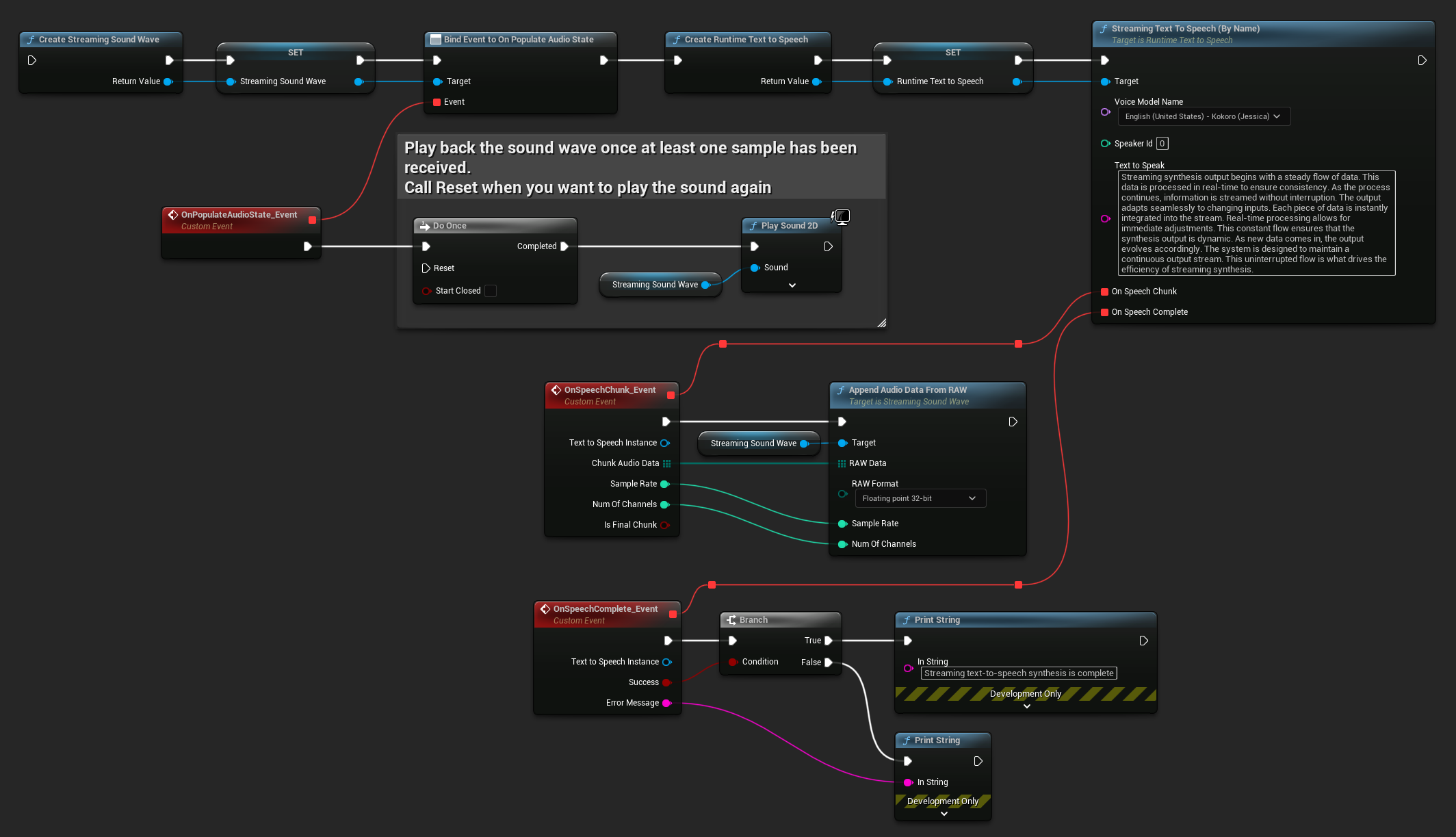
İşte C++'da gerçek zamanlı oynatma ile akışlı metin okumanın nasıl uygulanacağına dair bir örnek:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Metin Okumayı İptal Etme
Devam eden bir metin okuma sentezleme işlemini, sentezleyici örneğinizdeki CancelSpeechSynthesis fonksiyonunu çağırarak istediğiniz zaman iptal edebilirsiniz:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Bir sentez iptal edildiğinde:
- Sentez işlemi mümkün olan en kısa sürede durdurulacaktır
- Devam eden tüm geri çağrılar sonlandırılacaktır
- Tamamlama temsilcisi,
bSuccess = falseve sentezin iptal edildiğini belirten bir hata mesajı ile çağrılacaktır - Sentez için ayrılan tüm kaynaklar uygun şekilde temizlenecektir
Bu, özellikle uzun metinler için veya yeni bir sentez başlatmak için oynatmayı kesmek gerektiğinde oldukça kullanışlıdır.
Konuşmacı Seçimi
Her iki Metinden Sese dönüştürme işlevi, isteğe bağlı bir konuşmacı ID parametresi kabul eder; bu, birden fazla konuşmacıyı destekleyen ses modelleriyle çalışırken kullanışlıdır. Seçtiğiniz ses modelinin birden fazla konuşmacıyı destekleyip desteklemediğini kontrol etmek için GetSpeakerCountFromVoiceModel veya GetSpeakerCountFromModelName işlevlerini kullanabilirsiniz. Birden fazla konuşmacı mevcutsa, Metinden Sese dönüştürme işlevlerini çağırırken istediğiniz konuşmacı ID'sini belirtmeniz yeterlidir. Bazı ses modelleri kapsamlı çeşitlilik sunar - örneğin, English LibriTTS seçilebilecek 900'den fazla farklı konuşmacı içerir.
Runtime Audio Importer eklentisi ayrıca ses verilerini bir dosyaya aktarma, SoundCue, MetaSound ve daha fazlasına iletme gibi ek özellikler sağlar. Daha fazla ayrıntı için Runtime Audio Importer belgelerine göz atın.