Nhà cung cấp dịch thuật
AI Localization Automator hỗ trợ năm nhà cung cấp AI khác nhau, mỗi nhà cung cấp có những điểm mạnh và tùy chọn cấu hình riêng biệt. Hãy chọn nhà cung cấp phù hợp nhất với nhu cầu, ngân sách và yêu cầu chất lượng của dự án bạn.
Ollama (AI Cục bộ)
Phù hợp nhất cho: Dự án nhạy cảm về quyền riêng tư, dịch thuật ngoại tuyến, sử dụng không giới hạn
Ollama chạy các mô hình AI cục bộ trên máy của bạn, cung cấp quyền riêng tư hoàn toàn và kiểm soát mà không có chi phí API hoặc yêu cầu kết nối internet.
Các mô hình phổ biến
- translategemma:12b (Mô hình dịch thuật chuyên dụng dựa trên Gemma 3)
- llama3.2 (Đa năng được khuyến nghị)
- mistral (Phương án thay thế hiệu quả)
- codellama (Dịch thuật có nhận thức về mã nguồn)
- Và nhiều mô hình cộng đồng khác
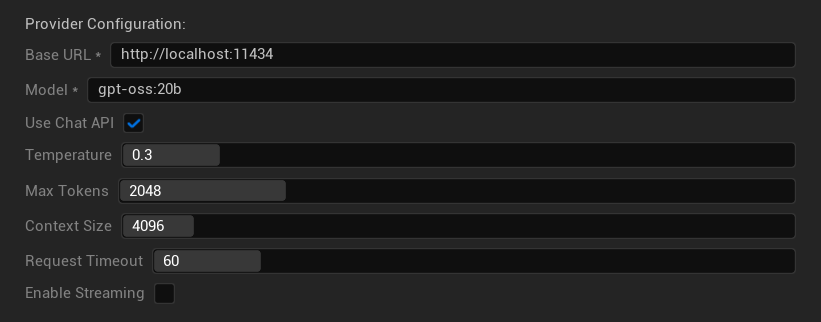
Tùy chọn Cấu hình
- Base URL: Máy chủ Ollama cục bộ (mặc định:
http://localhost:11434) - Model: Tên của mô hình được cài đặt cục bộ (bắt buộc)
- Use Chat API: Bật để xử lý hội thoại tốt hơn
- Temperature: 0.0-2.0 (khuyến nghị 0.3)
- Max Tokens: 1-8,192 token
- Context Size: 512-32,768 token
- Request Timeout: 10-300 giây (mô hình cục bộ có thể chậm hơn)
- Enable Streaming: Để xử lý phản hồi theo thời gian thực
Điểm mạnh
- ✅ Quyền riêng tư tuyệt đối (không có dữ liệu nào rời khỏi máy của bạn)
- ✅ Không có chi phí API hoặc giới hạn sử dụng
- ✅ Hoạt động ngoại tuyến
- ✅ Kiểm soát hoàn toàn các tham số mô hình
- ✅ Nhiều loại mô hình cộng đồng đa dạng
- ✅ Không bị khóa nhà cung cấp
Các lưu ý
- 💻 Yêu cầu cài đặt cục bộ và phần cứng đủ mạnh
- ⚡ Thường chậm hơn các nhà cung cấp đám mây
- 🔧 Yêu cầu cài đặt kỹ thuật hơn
- 📊 Chất lượng dịch thuật thay đổi đáng kể tùy theo mô hình (một số có thể vượt trội hơn các nhà cung cấp đám mây)
- 💾 Yêu cầu dung lượng lưu trữ lớn cho các mô hình
Thiết lập Ollama
- Cài đặt Ollama: Tải xuống từ ollama.ai và cài đặt trên hệ thống của bạn
- Tải mô hình: Sử dụng
ollama pull translategemma:12bđể tải mô hình bạn đã chọn - Khởi động máy chủ: Ollama chạy tự động hoặc khởi động bằng
ollama serve - Cấu hình plugin: Đặt URL cơ sở và tên mô hình trong cài đặt plugin
- Kiểm tra kết nối: Plugin sẽ xác minh kết nối khi bạn áp dụng cấu hình
OpenAI
Phù hợp nhất cho: Chất lượng dịch thuật tổng thể cao nhất, lựa chọn mô hình phong phú
OpenAI cung cấp các mô hình ngôn ngữ hàng đầu trong ngành thông qua Chat Completions API, bao gồm các mô hình GPT mới nhất, các mô hình suy luận và các mô hình hỗ trợ tìm kiếm web.
Các Mô hình Có sẵn
GPT-5 Family (Các mẫu chủ lực)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
- gpt-5.5, gpt-5.6-sol, gpt-5.6-luna
Dòng GPT-4.1 (Hiệu suất cao)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
Dòng GPT-4o (Đa phương thức)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O-Series (Mô hình suy luận — temperature/top_p không được hỗ trợ)
- o1, o1-pro, o3, o3-mini, o4-mini
Mô hình Tìm kiếm Web (Temperature/top_p không được hỗ trợ)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
Phiên bản cũ / Xem trước
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
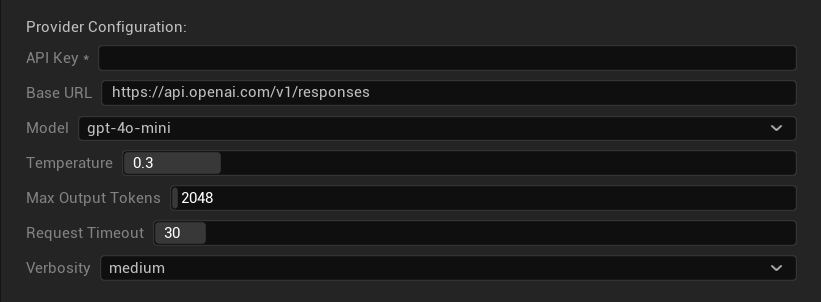
Các tùy chọn cấu hình
- API Key: Khóa API OpenAI của bạn (bắt buộc)
- Base URL: Điểm cuối API (mặc định:
https://api.openai.com/v1/chat/completions) - Model: Chọn từ các mô hình có sẵn được liệt kê ở trên
- Use Temperature: Bật/tắt tham số temperature (tự động bỏ qua đối với các mô hình suy luận dòng o và tìm kiếm web)
- Temperature: 0.0–2.0 (khuyến nghị 0.3 để nhất quán bản dịch)
- Top P: 0.0–1.0 tham số lấy mẫu hạt nhân (bỏ qua đối với các mô hình suy luận dòng o và tìm kiếm web)
- Max Completion Tokens: 1–128.000 token (bao gồm cả token đầu ra và token suy luận)
- Request Timeout: 5–300 giây
Điểm mạnh
- ✅ Bản dịch chất lượng cao nhất quán
- ✅ Hiểu ngữ cảnh xuất sắc
- ✅ Giữ nguyên định dạng tốt
- ✅ Hỗ trợ nhiều ngôn ngữ
- ✅ Thời gian hoạt động API đáng tin cậy
Những điều cần cân nhắc
- 💰 Chi phí cao hơn cho mỗi yêu cầu
- 🌐 Yêu cầu kết nối internet
- ⏱️ Giới hạn sử dụng dựa trên cấp độ
Anthropic Claude
Phù hợp nhất cho: Bản dịch tinh tế, nội dung sáng tạo, ứng dụng tập trung vào an toàn
Các mô hình Claude vượt trội trong việc hiểu ngữ cảnh và sắc thái, khiến chúng trở nên lý tưởng cho các game nặng về cốt truyện và các kịch bản bản địa hóa phức tạp.
Mô hình có sẵn
Claude 5 Family
- claude-opus-5, claude-sonnet-5, claude-fable-5
Claude 4.8 Dòng
- claude-opus-4-8
Dòng Claude 4.7
- claude-opus-4-7
Dòng Claude 4.6
- claude-opus-4-6, claude-sonnet-4-6
Dòng Claude 4.5
- claude-haiku-4-5 (Nhanh chóng và hiệu quả)
- claude-sonnet-4-5, claude-opus-4-5
Dòng Claude 4.x
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Dòng Claude 3.x (Cũ)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
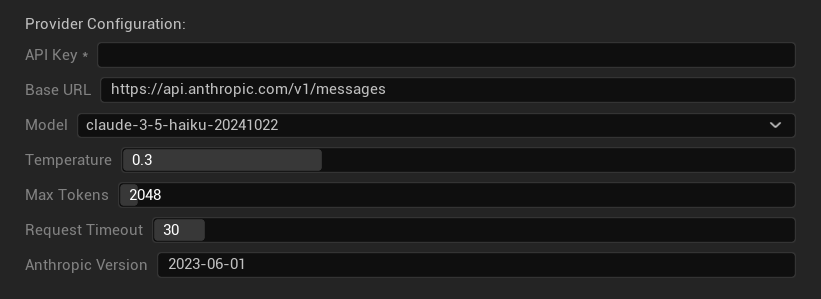
Tùy chọn cấu hình
- Khóa API: Khóa API Anthropic của bạn (bắt buộc)
- URL cơ sở: Điểm cuối API Claude
- Mô hình: Chọn từ dòng mô hình Claude
- Nhiệt độ: 0.0–1.0 (khuyến nghị 0.3)
- Top K: Tham số lấy mẫu Top-K (0 = không đặt)
- Số token tối đa: 1–64.000 token
- Thời gian chờ yêu cầu: 5–300 giây
- Phiên bản Anthropic: Tiêu đề phiên bản API
Điểm mạnh
- ✅ Nhận biết ngữ cảnh xuất sắc
- ✅ Tuyệt vời cho nội dung sáng tạo/kể chuyện
- ✅ Tính năng an toàn mạnh mẽ
- ✅ Khả năng suy luận chi tiết (suy nghĩ mở rộng trên các mô hình 3.7+)
- ✅ Tuân theo hướng dẫn xuất sắc
Các lưu ý
- 💰 Mô hình giá cao cấp
- 🌐 Yêu cầu kết nối Internet
- 📏 Giới hạn token thay đổi theo mô hình
DeepSeek
Phù hợp nhất cho: Dịch thuật tiết kiệm chi phí, thông lượng cao, các dự án có ngân sách hạn chế.
DeepSeek cung cấp chất lượng dịch thuật cạnh tranh với chi phí chỉ bằng một phần nhỏ so với các nhà cung cấp khác, khiến nó trở nên lý tưởng cho các dự án bản địa hóa quy mô lớn.
Các Mô Hình Có Sẵn
- deepseek-v4-pro
- deepseek-v4-flash
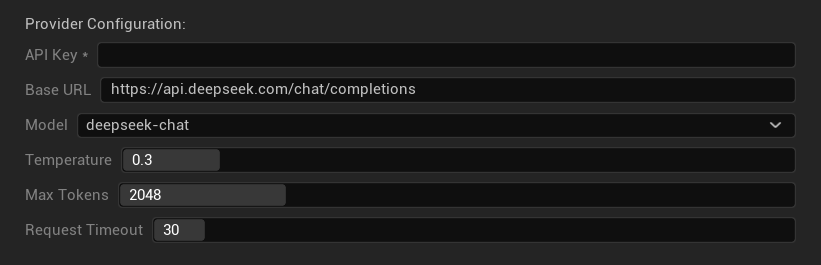
Tùy Chọn Cấu Hình
- API Key: Khóa API DeepSeek của bạn (bắt buộc)
- Base URL: Điểm cuối API DeepSeek
- Mô hình: Chọn giữa mô hình chat và reasoner
- Nhiệt độ: 0.0-2.0 (0.3 được khuyến nghị)
- Số token tối đa: 1-8,192 token
- Thời gian chờ yêu cầu: 5-300 giây
Điểm mạnh
- ✅ Rất tiết kiệm chi phí
- ✅ Chất lượng dịch thuật tốt
- ✅ Thời gian phản hồi nhanh
- ✅ Cấu hình đơn giản
- ✅ Hạn mức yêu cầu cao
Lưu ý
- 📏 Giới hạn token thấp hơn
- 🆕 Nhà cung cấp mới hơn (ít thành tích hơn)
- 🌐 Yêu cầu kết nối internet
Google Gemini
Phù hợp nhất cho: Dự án đa ngôn ngữ, dịch thuật tiết kiệm chi phí, tích hợp hệ sinh thái Google
Các mô hình Gemini cung cấp khả năng đa ngôn ngữ mạnh mẽ với giá cạnh tranh và các tính năng độc đáo như chế độ suy nghĩ để tăng cường khả năng suy luận.
Các mô hình có sẵn
Gemini 3.x Family (Preview)
- gemini-3.1-pro, gemini-3.1-flash-light, gemini-3.5-flash, gemini-3.6-flash
Gemini 2.5 Family (có hỗ trợ suy luận)
- gemini-2.5-pro (Chủ lực với suy luận)
- gemini-2.5-flash (Nhanh, với hỗ trợ suy luận)
- gemini-2.5-flash-lite (Biến thể nhẹ)
Gemini 2.0 Family
- gemini-2.0-flash, gemini-2.0-flash-lite
Bí danh mới nhất
- gemini-flash-latest, gemini-flash-lite-latest
Tùy chọn cấu hình
- Khóa API: Khóa API Google AI của bạn (bắt buộc)
- URL cơ sở: Điểm cuối API Gemini
- Mô hình: Chọn từ dòng mô hình Gemini
- Nhiệt độ: 0.0–2.0 (khuyến nghị 0.3)
- Số token đầu ra tối đa: 1–8.192 token
- Thời gian chờ yêu cầu: 5–300 giây
- Bật Suy nghĩ: Kích hoạt suy luận nâng cao cho các mô hình 2.5+
- Ngân sách Suy nghĩ: Kiểm soát phân bổ token suy nghĩ (0 = không suy nghĩ)
Điểm mạnh
- ✅ Hỗ trợ đa ngôn ngữ mạnh mẽ
- ✅ Giá cạnh tranh
- ✅ Suy luận nâng cao (chế độ suy nghĩ)
- ✅ Tích hợp hệ sinh thái Google
- ✅ Cập nhật mô hình thường xuyên với quyền truy cập xem trước các mô hình mới nhất
Cân nhắc
- 🧠 Chế độ suy luận làm tăng mức sử dụng token
- 📏 Giới hạn token biến đổi theo mô hình
- 🌐 Yêu cầu kết nối Internet
Chọn Nhà Cung Cấp Phù Hợp
| Nhà cung cấp | Tốt nhất cho | Chất lượng | Cost | Thiết lập | Quyền riêng tư |
|---|---|---|---|---|---|
| Ollama | Quyền riêng tư/Không kết nối | Biến* | Free | Nâng cao | Cục bộ |
| OpenAI | Chất lượng cao nhất | ⭐⭐⭐⭐⭐ | 💰💰💰 | Easy | đám mây |
| Claude | Nội dung sáng tạo | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Easy | đám mây |
| DeepSeek | Dự án ngân sách | ⭐⭐⭐⭐ | 💰 | Easy | Đám mây |
| Gemini | Đa ngôn ngữ | 4 sao | 💰 | Easy | Đám mây |
*Chất lượng của Ollama thay đổi đáng kể dựa trên mô hình cục bộ được sử dụng - một số mô hình cục bộ hiện đại có thể sánh ngang hoặc vượt qua các nhà cung cấp đám mây.
Mẹo cấu hình nhà cung cấp
Dành cho tất cả các nhà cung cấp đám mây:
- Lưu trữ khóa API một cách an toàn và không commit chúng vào kiểm soát phiên bản
- Bắt đầu với cài đặt nhiệt độ thận trọng (0.3) để có bản dịch nhất quán
- Theo dõi mức sử dụng và chi phí API của bạn
- Kiểm thử với các lô nhỏ trước khi chạy dịch thuật lớn
Dành cho Ollama:
- Đảm bảo RAM đủ (8GB+ được khuyến nghị cho các mô hình lớn hơn)
- Sử dụng ổ SSD để cải thiện hiệu suất tải mô hình
- Cân nhắc tăng tốc GPU để suy luận nhanh hơn
- Kiểm tra cục bộ trước khi phụ thuộc vào nó cho các bản dịch trong sản xuất