Tham số suy luận
Cấu trúc Tham số Suy luận LLM kiểm soát cách mô hình tải và sinh văn bản. Bạn truyền các tham số này khi tải một mô hình. Trang này mô tả từng tham số và tác dụng của nó.
Tham số Tham chiếu
| Tham số | Type | Mặc định | Phạm vi | Mô tả |
|---|---|---|---|---|
| Max Tokens | int32 | 512 | 1–8192 | Số lượng token tối đa có thể tạo ra trong một phản hồi duy nhất |
| Nhiệt độ | float | 0.7 | 0.0–2.0 | Kiểm soát tính ngẫu nhiên. 0.0 = đầu ra xác định. Giá trị càng cao = đầu ra càng sáng tạo. |
| Top P | float | 0.9 | 0.0–1.0 | Lấy mẫu hạt nhân. Chỉ những token có xác suất tích lũy vượt quá giá trị này mới được xem xét. |
| Top K | int32 | 40 | 0–200 | Giới hạn lựa chọn trong số K token có xác suất cao nhất. 0 = tắt. |
| Hình phạt Lặp lại | float | 1.1 | 0.0–3.0 | Phạt các token đã xuất hiện trong đầu ra. 1.0 = không phạt. |
| Số Lớp GPU | int32 | -1 | -1–200 | Các lớp mô hình để chuyển sang GPU. -1 = tự động. 0 = chỉ CPU. |
| Kích thước Ngữ cảnh | int32 | 2048 | 128–131072 | Kích thước cửa sổ ngữ cảnh tối đa (tính bằng token). Giá trị càng lớn càng tốn nhiều bộ nhớ. |
| System Prompt | FString | "Bạn là một trợ lý hữu ích." | — | Hướng dẫn hệ thống định hình hành vi của mô hình |
| Seed | int32 | -1 | -1+ | Hạt giống ngẫu nhiên cho đầu ra có thể tái tạo. -1 = ngẫu nhiên |
| Số Luồng | int32 | 0 | 0–128 | Số luồng CPU cho quá trình sinh. 0 = tự động. |
Cách sử dụng
- Blueprint
- C++
Các tham số suy luận xuất hiện dưới dạng một chân struct trên các node load và async. Hãy phá vỡ struct để thiết lập các giá trị riêng lẻ.
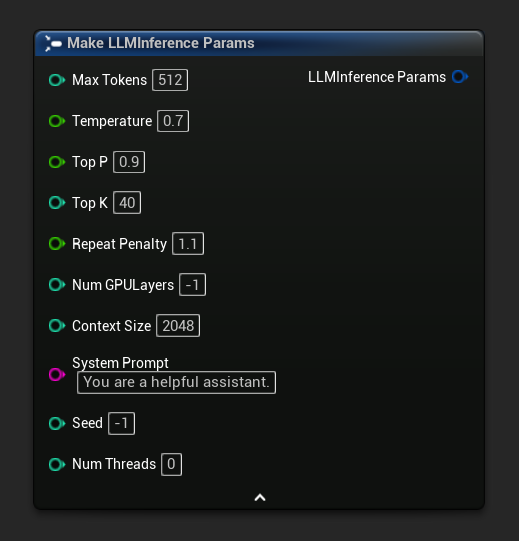
Để lấy một bộ tham số mặc định làm điểm khởi đầu, hãy sử dụng Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Đề xuất Nền tảng
Di động / VR (Android, iOS, Meta Quest)
- Kích thước ngữ cảnh: 1024–2048
- Số lớp GPU: 0 (chỉ CPU) trừ khi thiết bị đã xác nhận hỗ trợ tính toán GPU
- Token tối đa: Dưới 256 để tương tác phản hồi nhanh
- Số luồng: 2–4 tùy thuộc vào thiết bị
Máy tính để bàn (Windows, Mac, Linux)
- Kích thước Ngữ cảnh: 2048–8192 cho hầu hết các cuộc hội thoại
- Số Lớp GPU: -1 (tự động) để tận dụng tăng tốc GPU khi có sẵn
- Số Luồng: 0 (tự động)
- Token Tối đa: 512–2048 cho các phản hồi dài hơn
Các Cuộc Hội Thoại Kéo Dài
Nếu ứng dụng của bạn duy trì các cuộc hội thoại trong các phiên dài (đối thoại NPC, trợ lý liên tục, nhập vai), hãy cân nhắc kết hợp kích thước ngữ cảnh của bạn với tự động tóm tắt thay vì chỉ tăng Context Size. Một Context Size khiêm tốn từ 2048–4096 với tính năng tự động tóm tắt được bật sẽ giữ cho độ trễ và mức sử dụng bộ nhớ ổn định, trong khi các cửa sổ ngữ cảnh lớn hơn khiến mỗi lần sinh nội dung trở nên chậm dần. Xem Tự động tóm tắt ngữ cảnh.