Hướng dẫn Xử lý Âm thanh
Hướng dẫn này trình bày cách thiết lập các phương pháp nhập âm thanh khác nhau để cung cấp dữ liệu âm thanh cho bộ tạo khớp môi của bạn. Hãy đảm bảo bạn đã hoàn thành Hướng dẫn Thiết lập trước khi tiếp tục.
Xử lý Đầu vào Âm thanh
Bạn cần thiết lập một phương pháp để xử lý đầu vào âm thanh. Có một số cách để thực hiện điều này tùy thuộc vào nguồn âm thanh của bạn.
- Microphone (Thời gian thực)
- Microphone (Phát lại)
- Chuyển văn bản thành giọng nói (Cục bộ)
- Chuyển văn bản thành giọng nói (API bên ngoài)
- Từ Tệp Âm thanh/Bộ đệm Âm thanh
- Bộ đệm Âm thanh Truyền phát
Phương pháp này thực hiện đồng bộ môi theo thời gian thực khi đang nói vào micro.
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Tạo một Capturable Sound Wave bằng Runtime Audio Importer
- Đối với Linux với Pixel Streaming, hãy sử dụng Pixel Streaming Capturable Sound Wave để thay thế.
- Trước khi bắt đầu ghi âm, hãy gắn kết với delegate
OnPopulateAudioData - Trong hàm đã gắn kết, hãy gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn - Bắt đầu ghi âm từ microphone
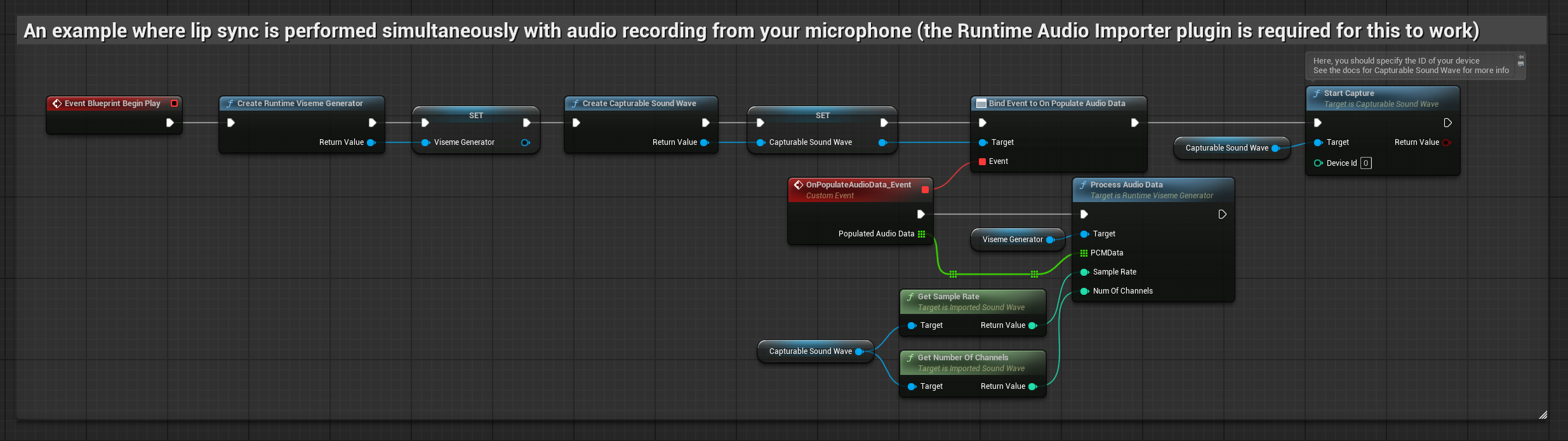
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
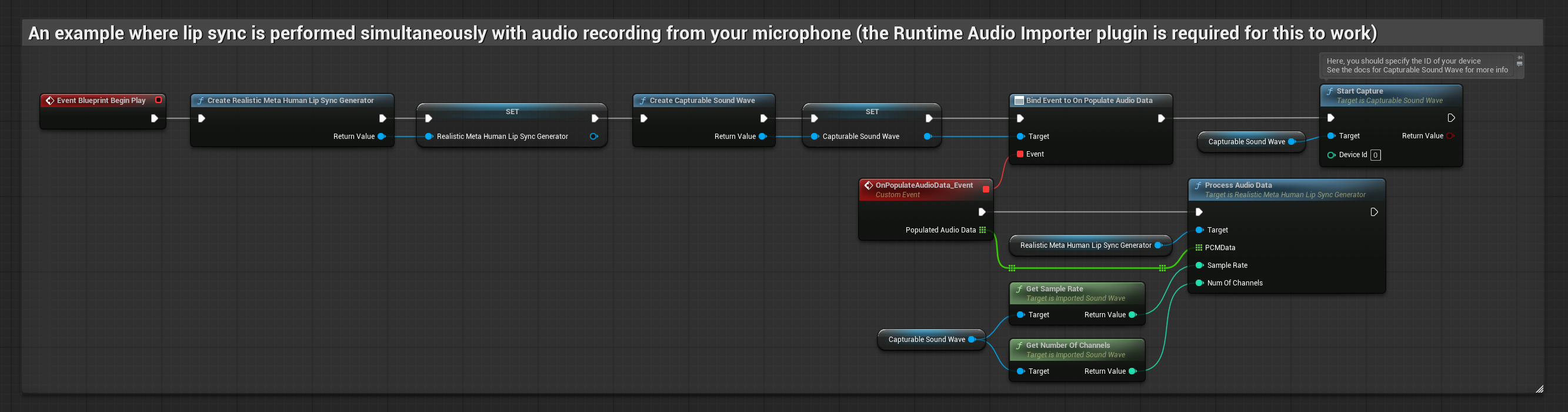
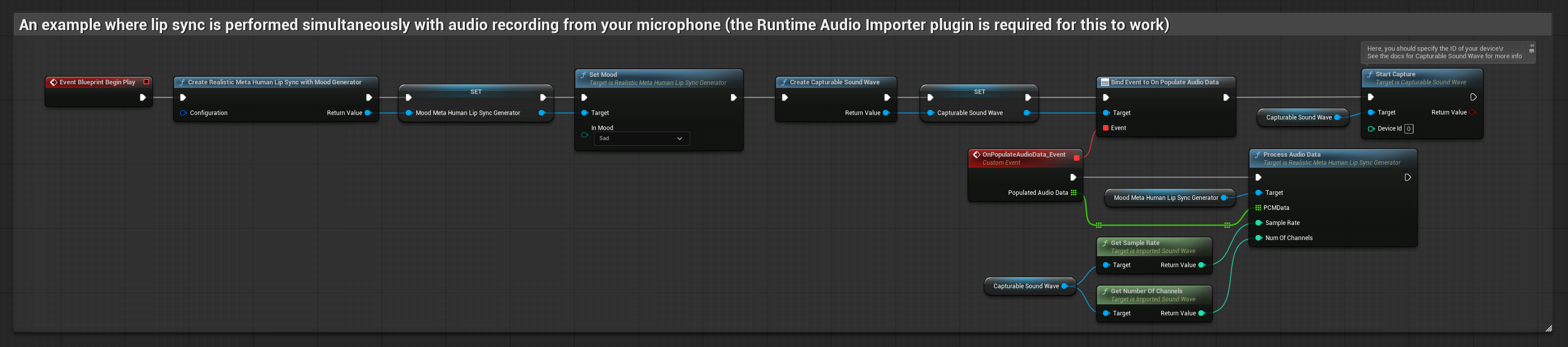
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
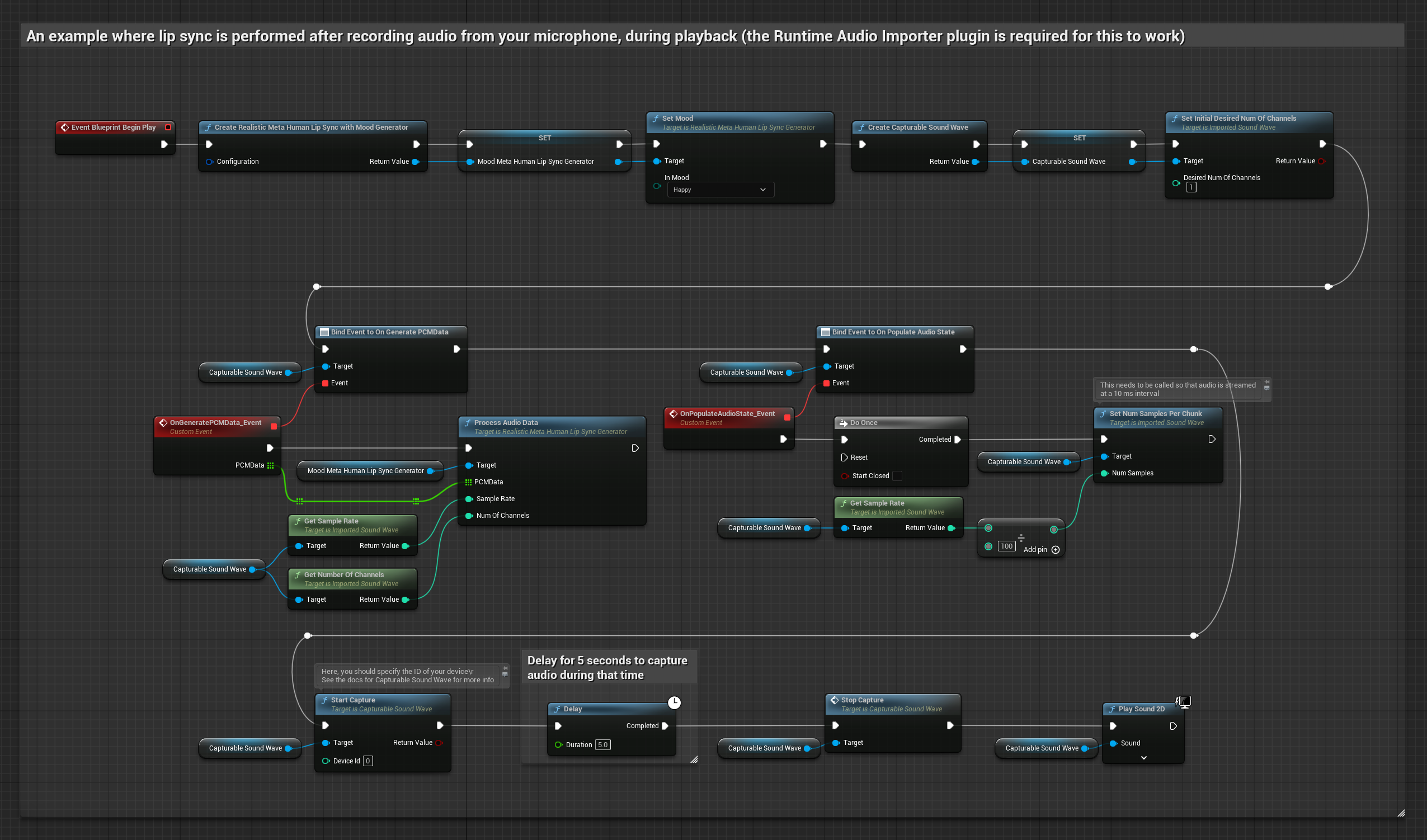
Phương pháp này thu âm từ micro, sau đó phát lại với đồng bộ môi:
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Tạo một Capturable Sound Wave bằng Runtime Audio Importer
- Đối với Linux với Pixel Streaming, hãy sử dụng Pixel Streaming Capturable Sound Wave để thay thế.
- Bắt đầu thu âm từ microphone
- Trước khi phát lại sóng âm thanh có thể thu được, hãy liên kết với delegate
OnGeneratePCMDatacủa nó - Trong hàm đã liên kết, hãy gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn
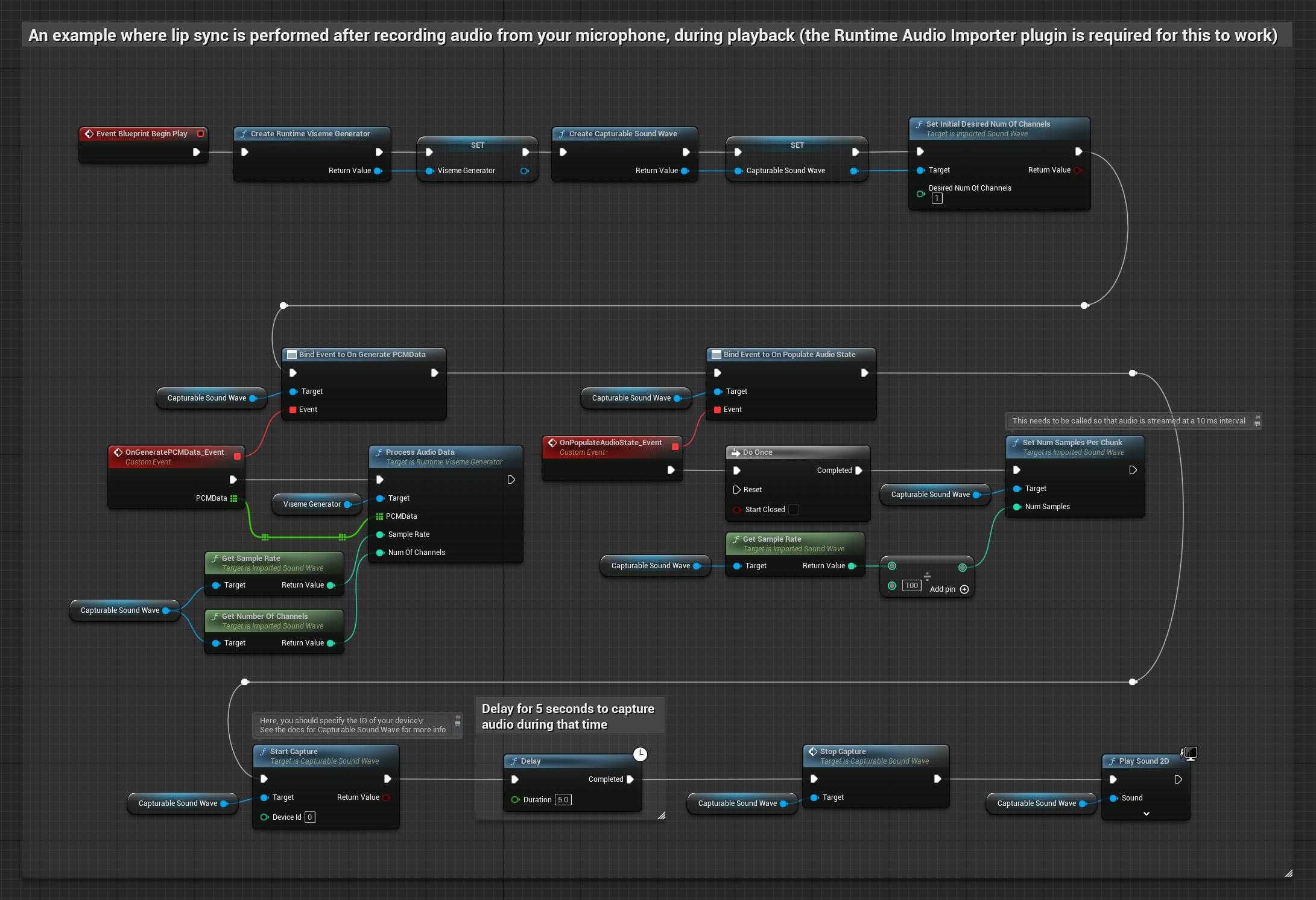
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
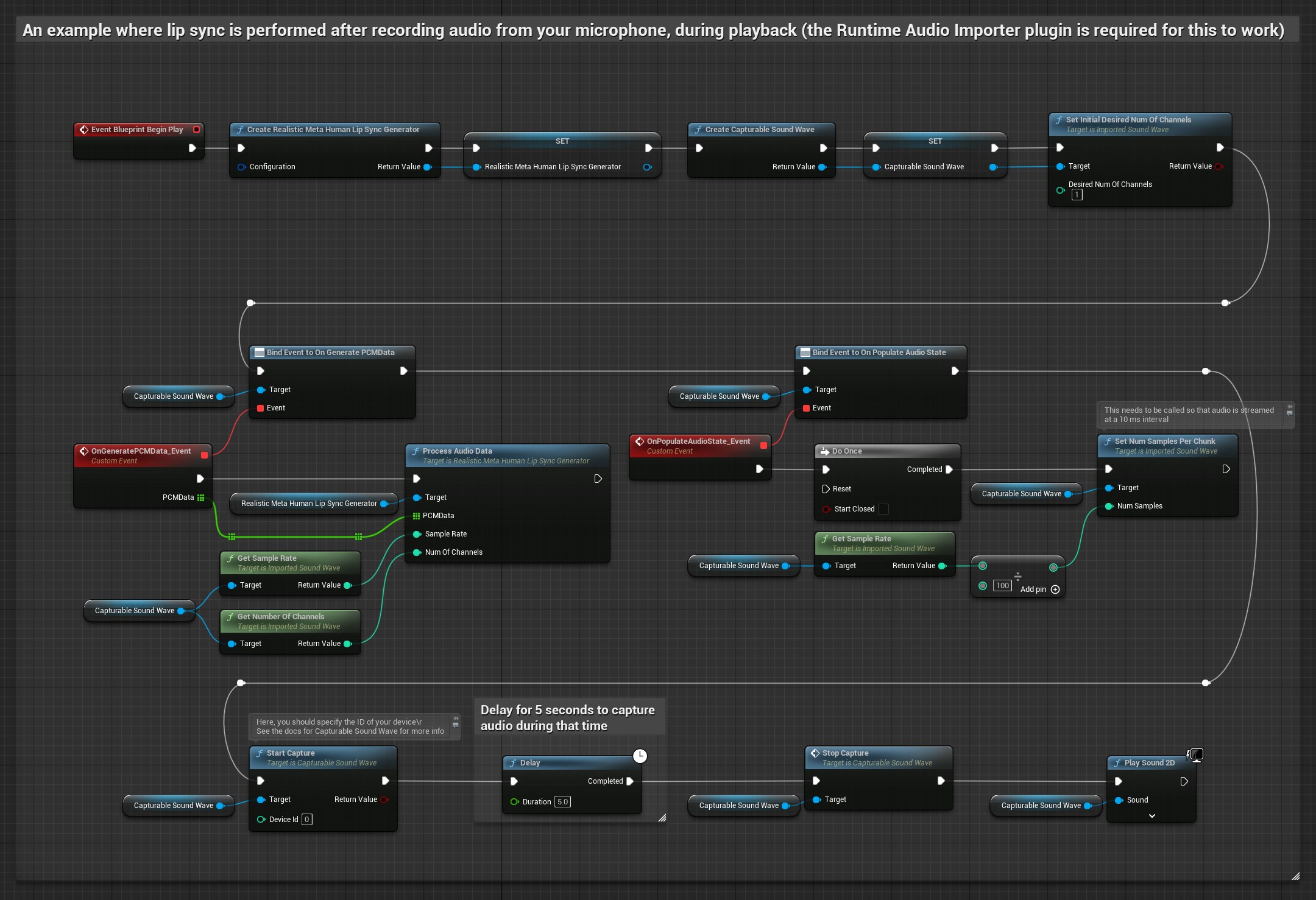
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
- Thường xuyên
- Phát trực tiếp
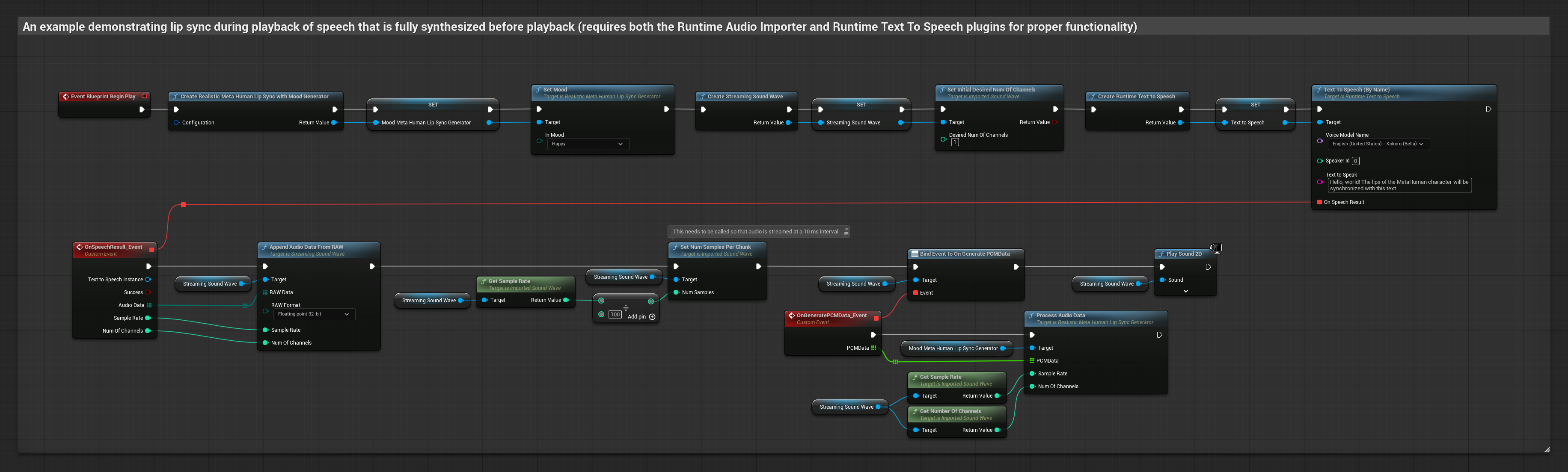
Phương pháp này tổng hợp giọng nói từ văn bản bằng TTS cục bộ và thực hiện đồng bộ môi.
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Sử dụng Runtime Text To Speech để tạo giọng nói từ văn bản
- Sử dụng Runtime Audio Importer để nhập âm thanh đã tổng hợp
- Trước khi phát sóng âm đã nhập, hãy liên kết với delegate
OnGeneratePCMDatacủa nó - Trong hàm đã liên kết, hãy gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn
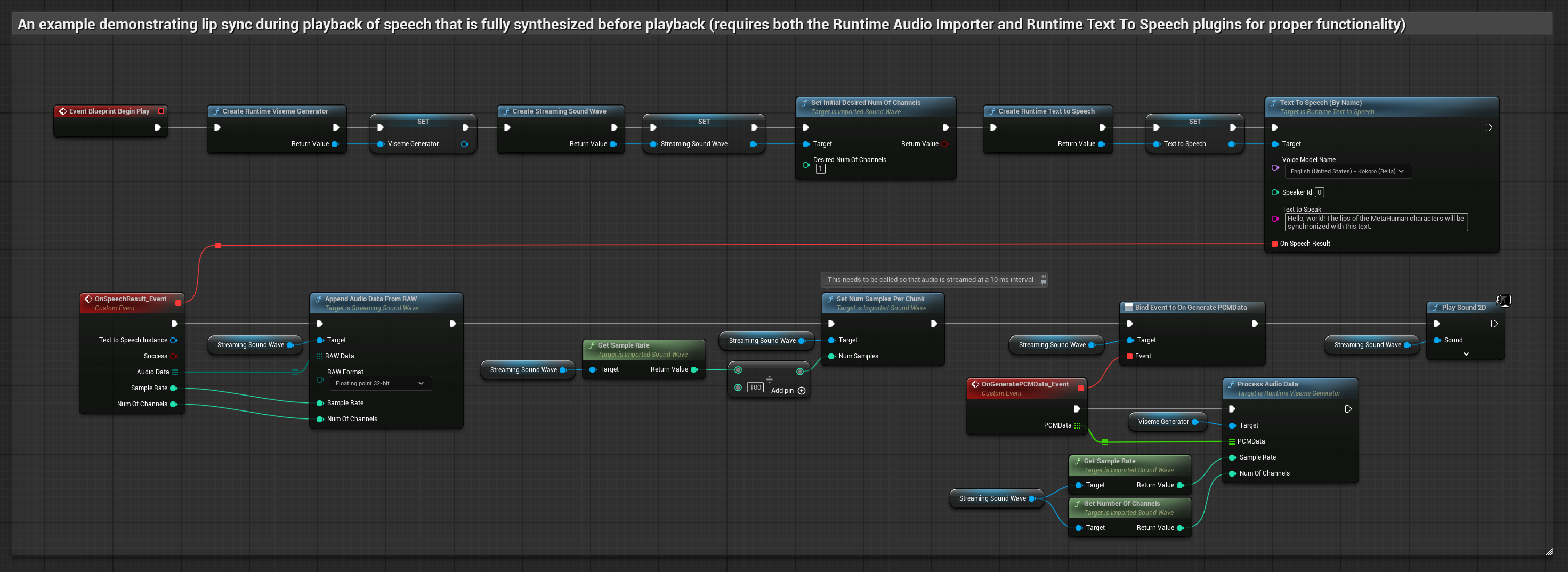
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
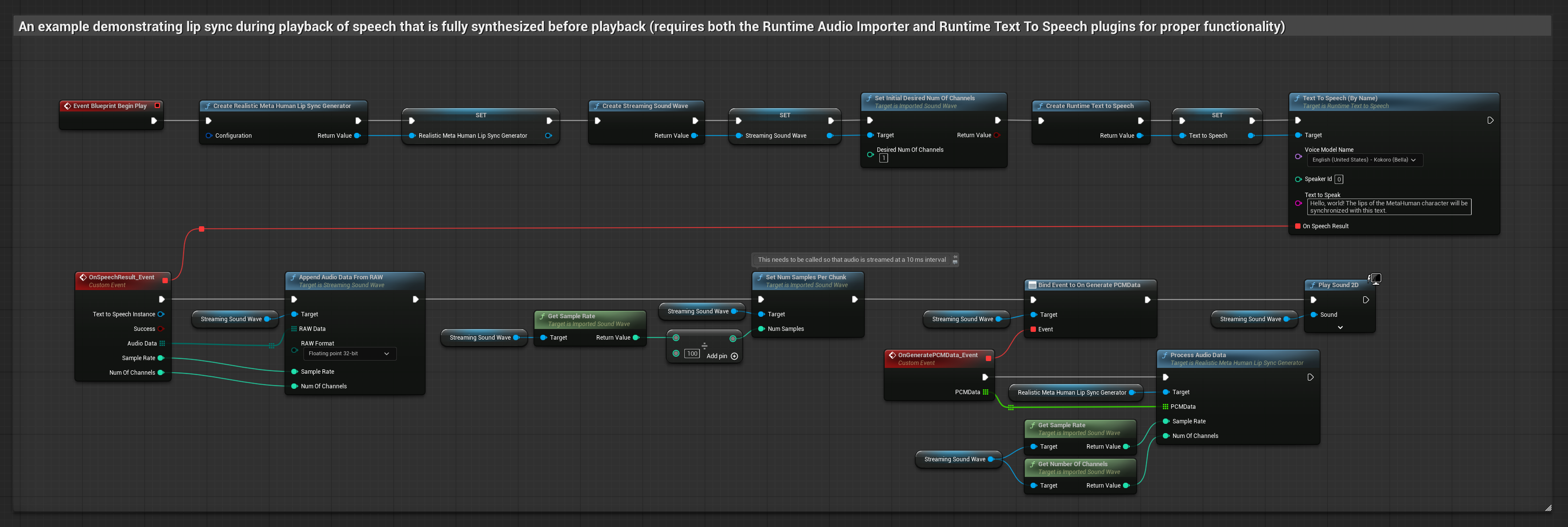
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
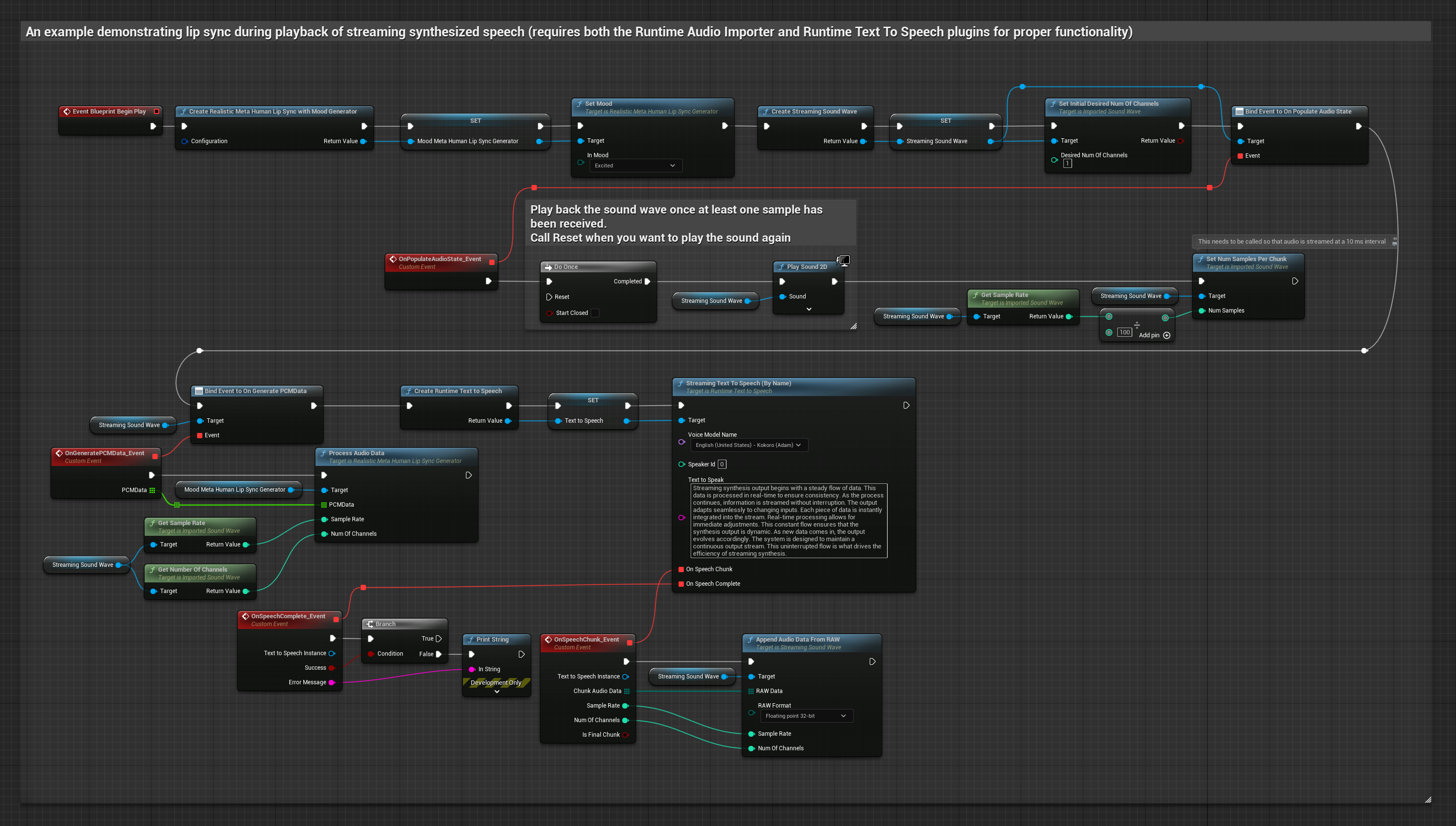
Phương pháp này sử dụng tổng hợp giọng nói từ văn bản dạng phát trực tuyến với đồng bộ hóa môi theo thời gian thực.
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Sử dụng Runtime Text To Speech để tạo giọng nói phát trực tuyến từ văn bản
- Sử dụng Runtime Audio Importer để nhập âm thanh đã tổng hợp
- Trước khi phát sóng âm thanh phát trực tuyến, hãy liên kết với ủy quyền
OnGeneratePCMDatacủa nó - Trong hàm đã liên kết, gọi
ProcessAudioDatatừ Trình tạo Viseme Runtime của bạn
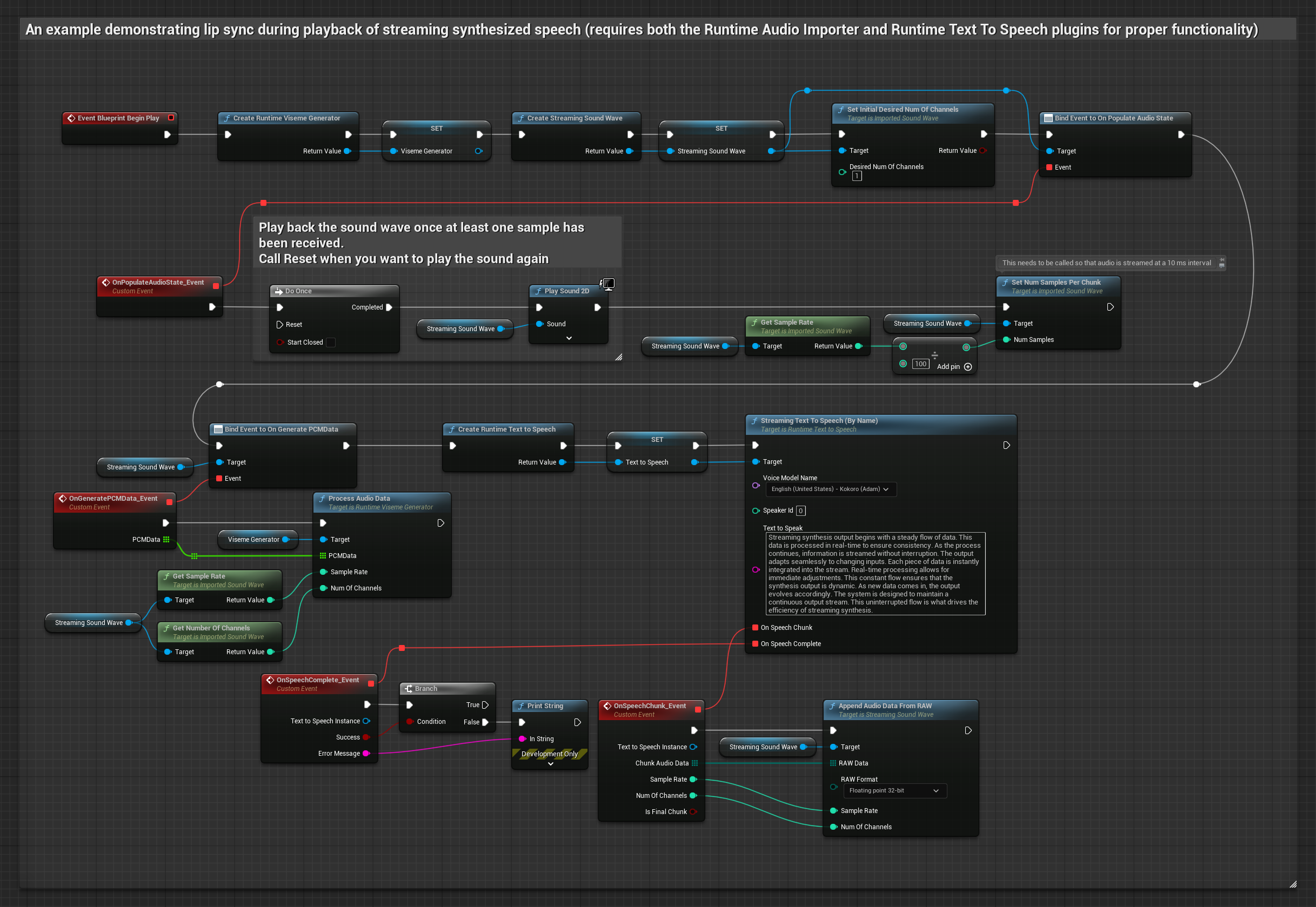
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
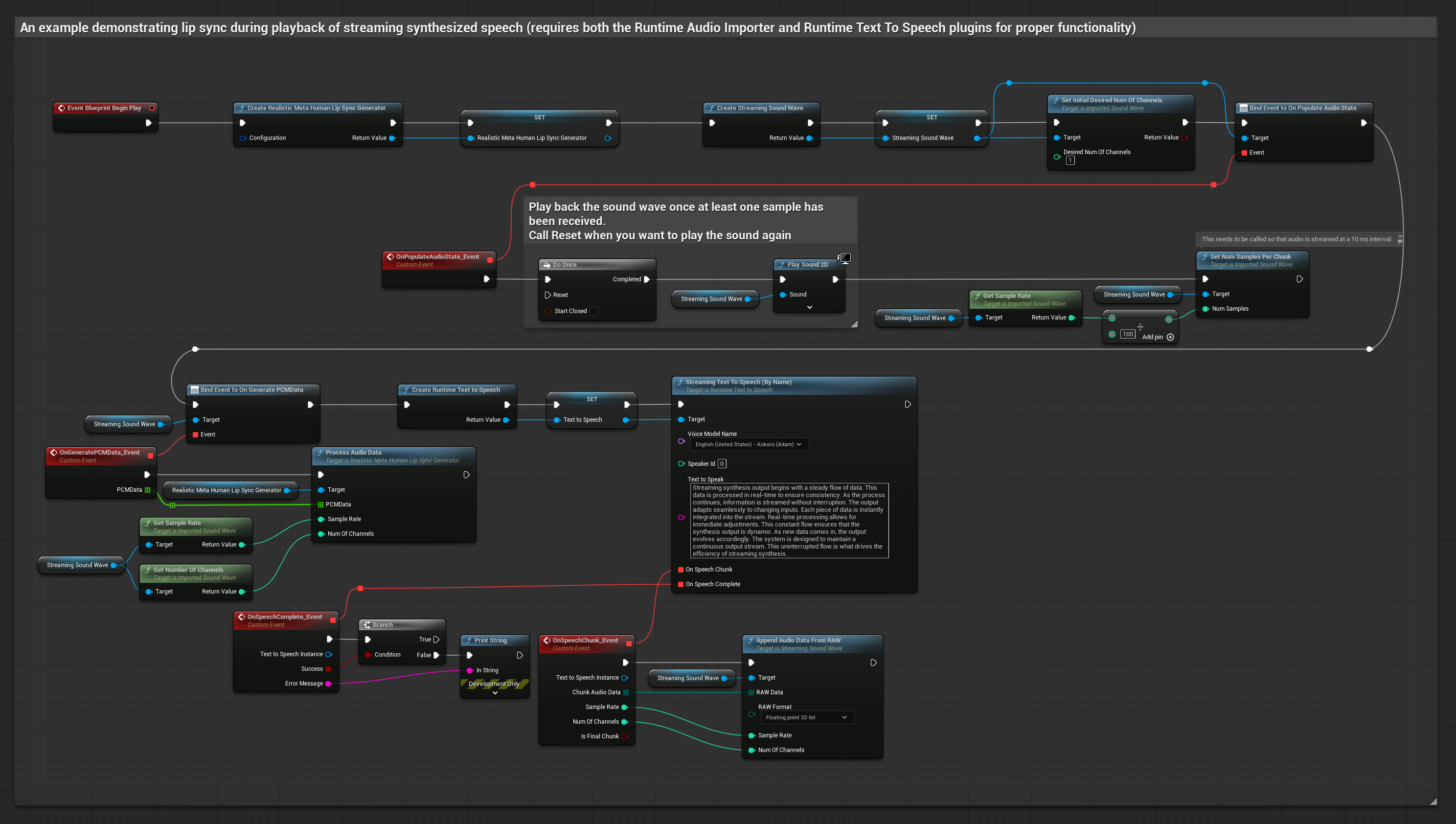
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
- Thường xuyên
- Phát trực tiếp
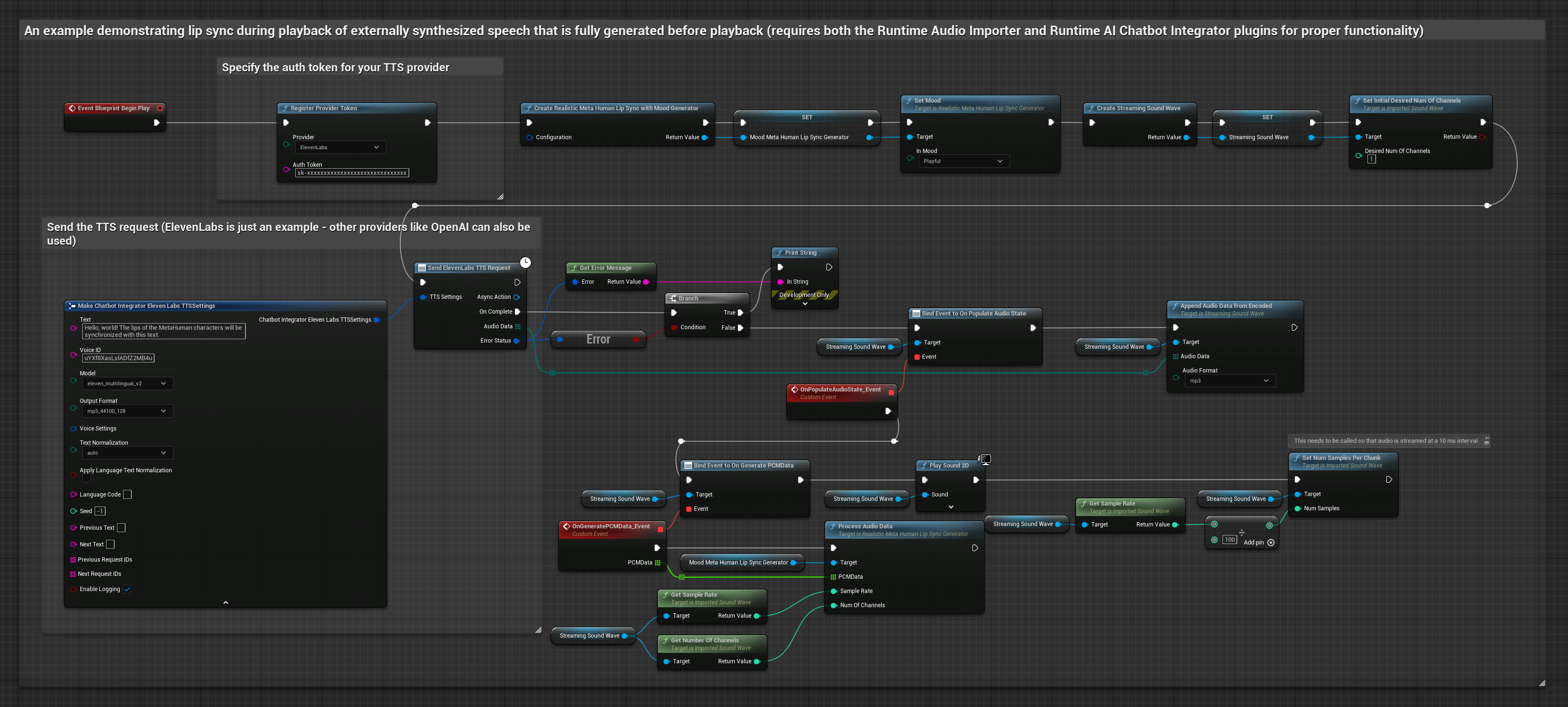
Phương pháp này sử dụng plugin Runtime AI Chatbot Integrator để tạo giọng nói tổng hợp từ các dịch vụ AI (OpenAI hoặc ElevenLabs) và thực hiện đồng bộ khẩu hình miệng (lip sync).
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Sử dụng Runtime AI Chatbot Integrator để tạo giọng nói từ văn bản bằng các API bên ngoài (OpenAI, ElevenLabs, v.v.)
- Sử dụng Runtime Audio Importer để nhập dữ liệu âm thanh đã tổng hợp
- Trước khi phát lại sóng âm đã nhập, hãy liên kết với delegate
OnGeneratePCMDatacủa nó - Trong hàm đã liên kết, hãy gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn
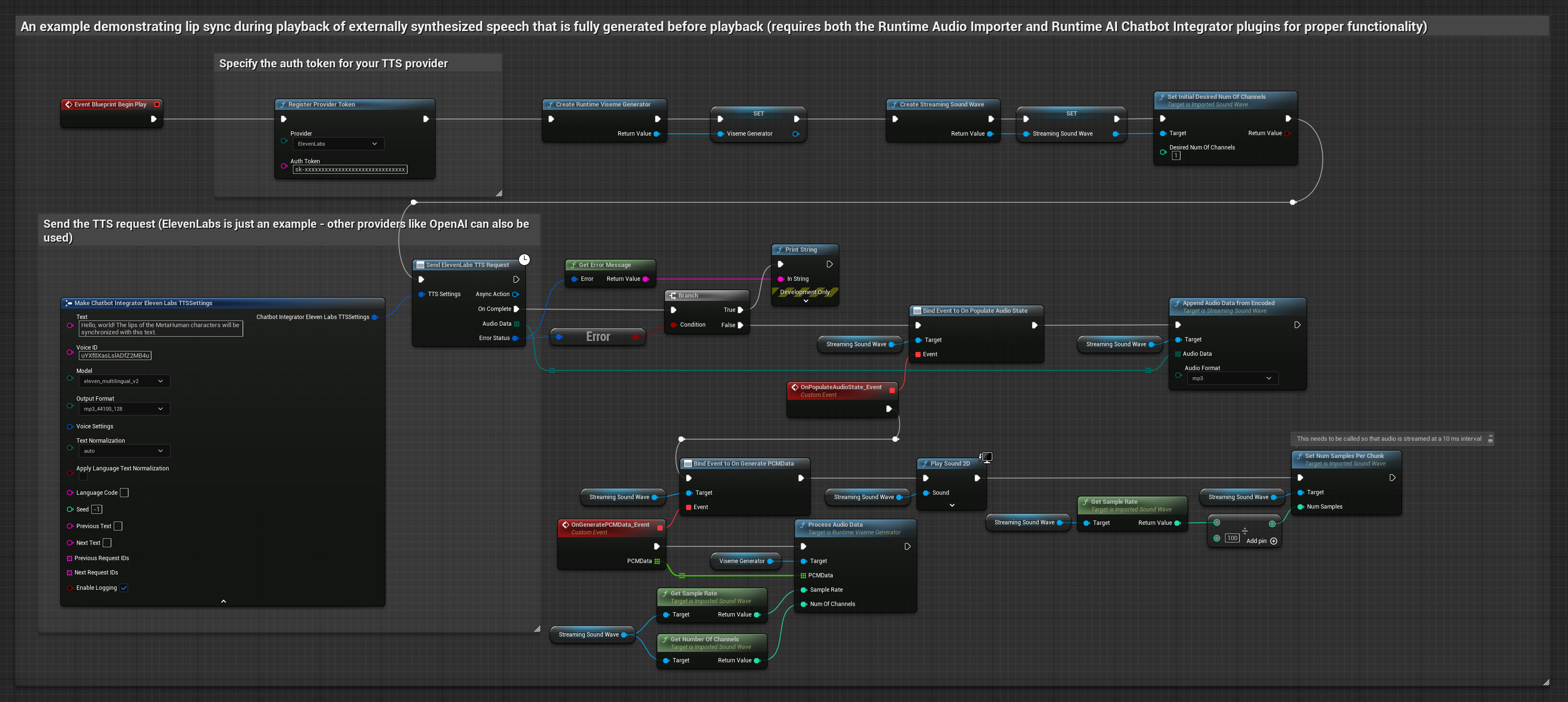
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
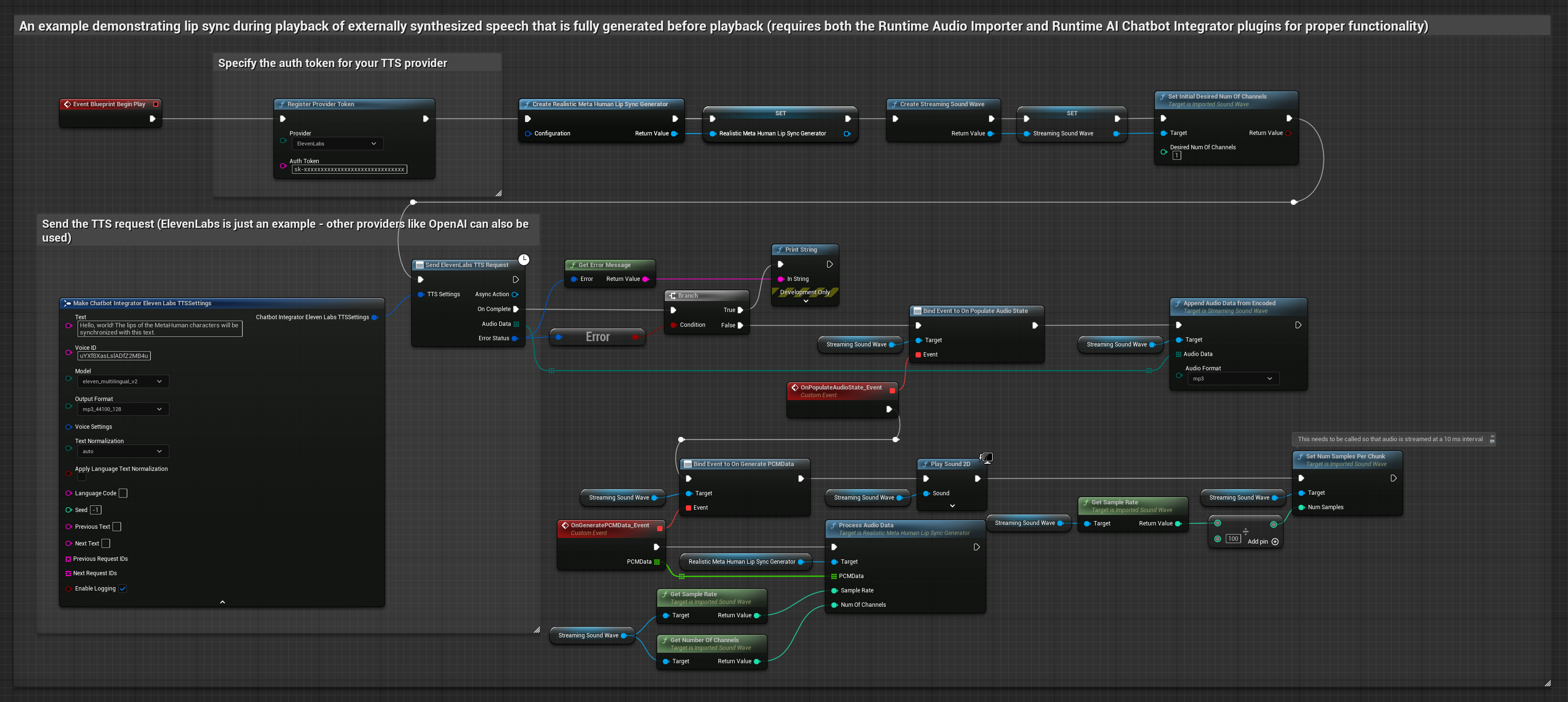
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
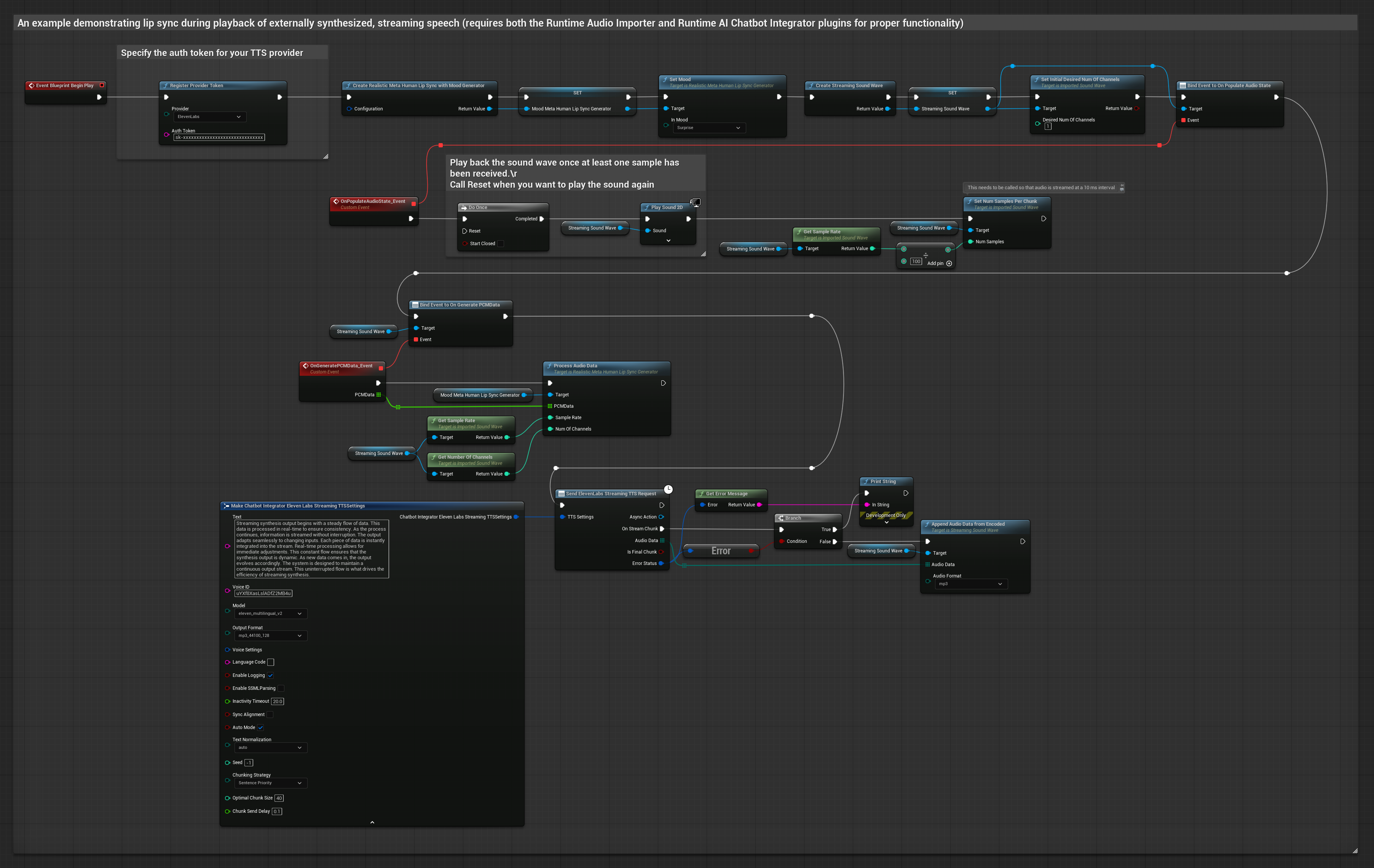
Phương pháp này sử dụng plugin Runtime AI Chatbot Integrator để tạo giọng nói tổng hợp phát trực tuyến từ các dịch vụ AI (OpenAI hoặc ElevenLabs) và thực hiện đồng bộ khẩu hình miệng (lip sync).
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Sử dụng Runtime AI Chatbot Integrator để kết nối với các API TTS phát trực tuyến (như ElevenLabs Streaming API)
- Sử dụng Runtime Audio Importer để nhập dữ liệu âm thanh đã tổng hợp
- Trước khi phát sóng âm thanh phát trực tuyến, hãy liên kết với delegate
OnGeneratePCMDatacủa nó - Trong hàm đã liên kết, hãy gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn
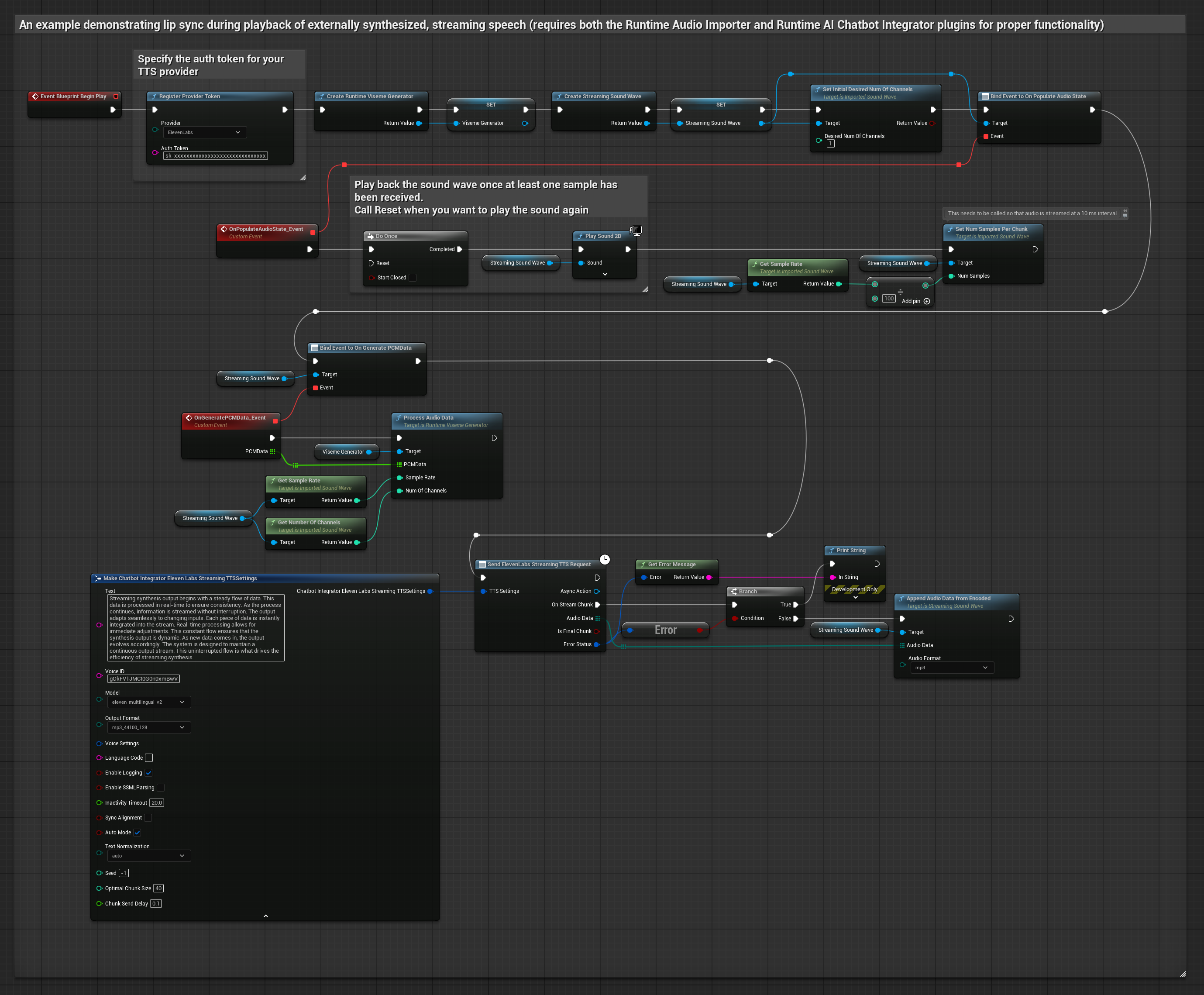
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
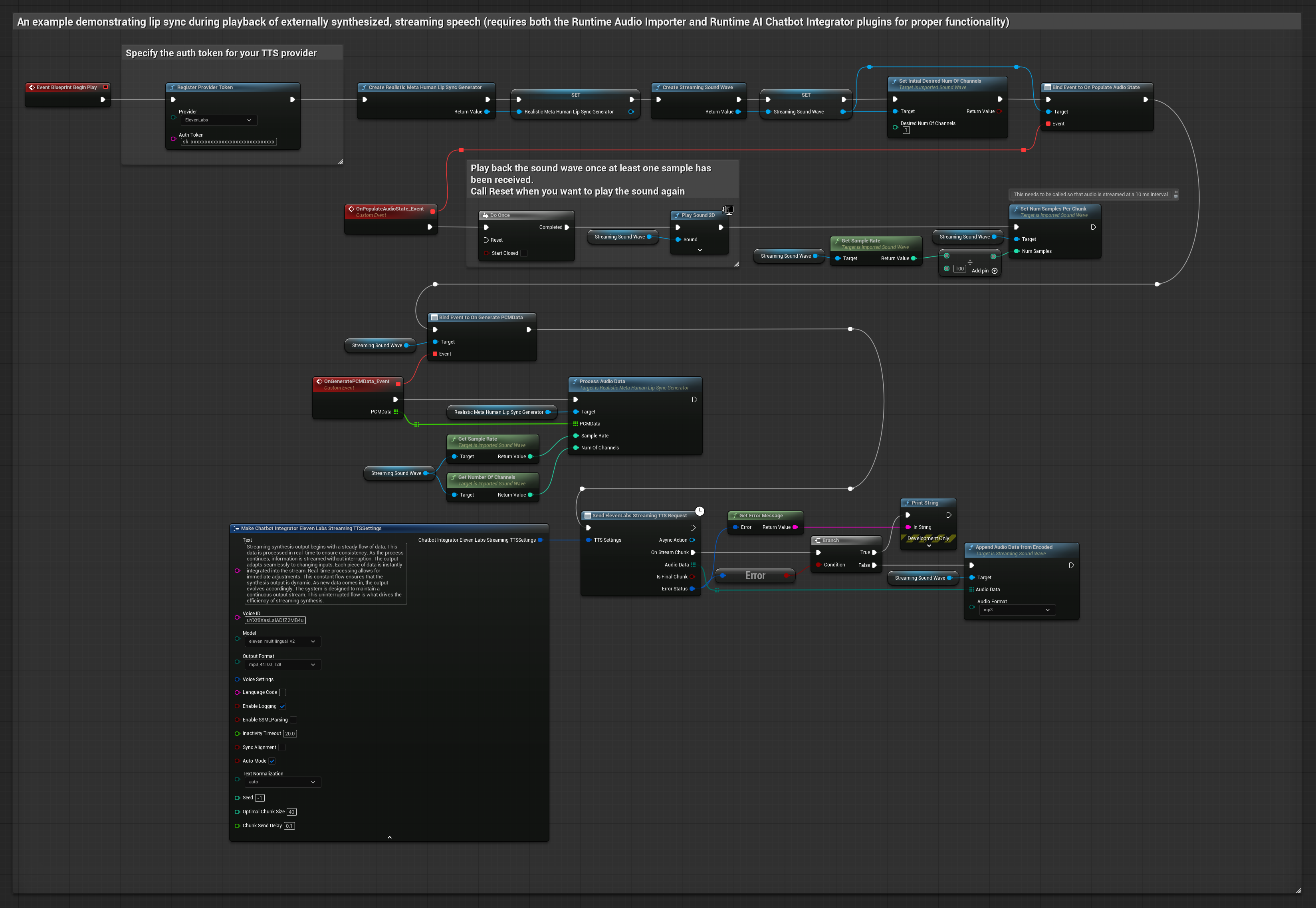
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
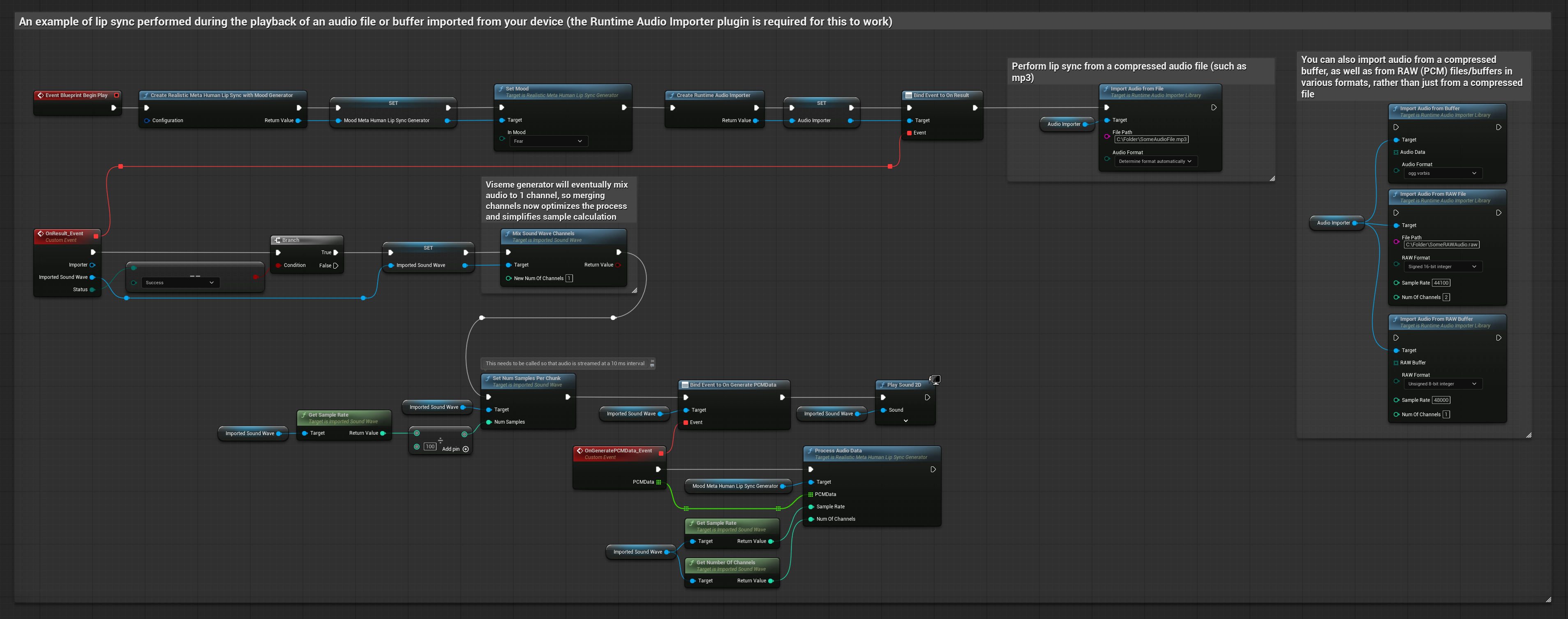
Phương pháp này sử dụng các tệp âm thanh đã ghi sẵn hoặc bộ đệm âm thanh để đồng bộ hóa môi.
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Sử dụng Runtime Audio Importer để nhập một tệp âm thanh từ đĩa hoặc bộ nhớ
- Trước khi phát lại sóng âm thanh đã nhập, hãy liên kết với delegate
OnGeneratePCMDatacủa nó - Trong hàm đã liên kết, gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn - Phát sóng âm thanh đã nhập và quan sát hoạt ảnh đồng bộ môi
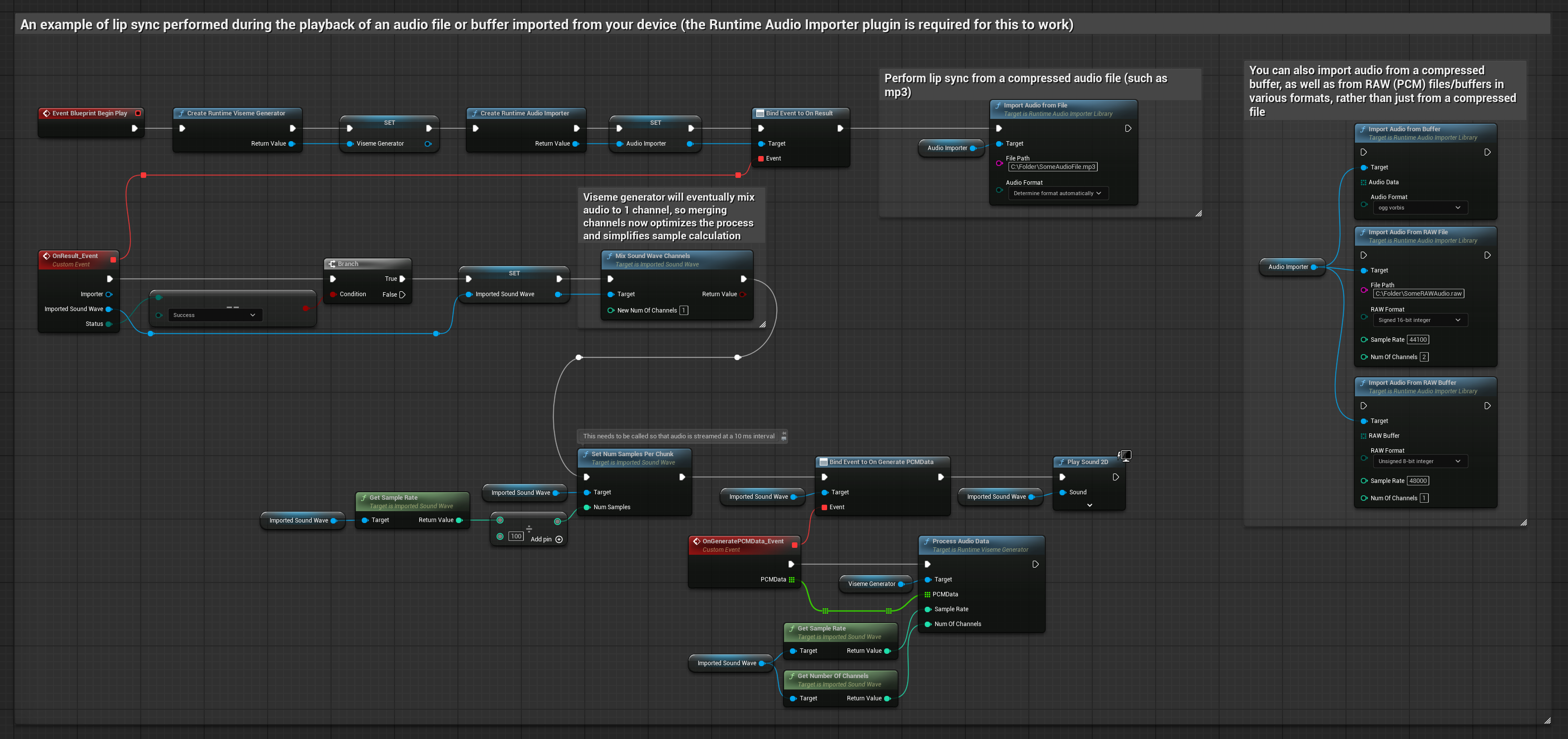
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
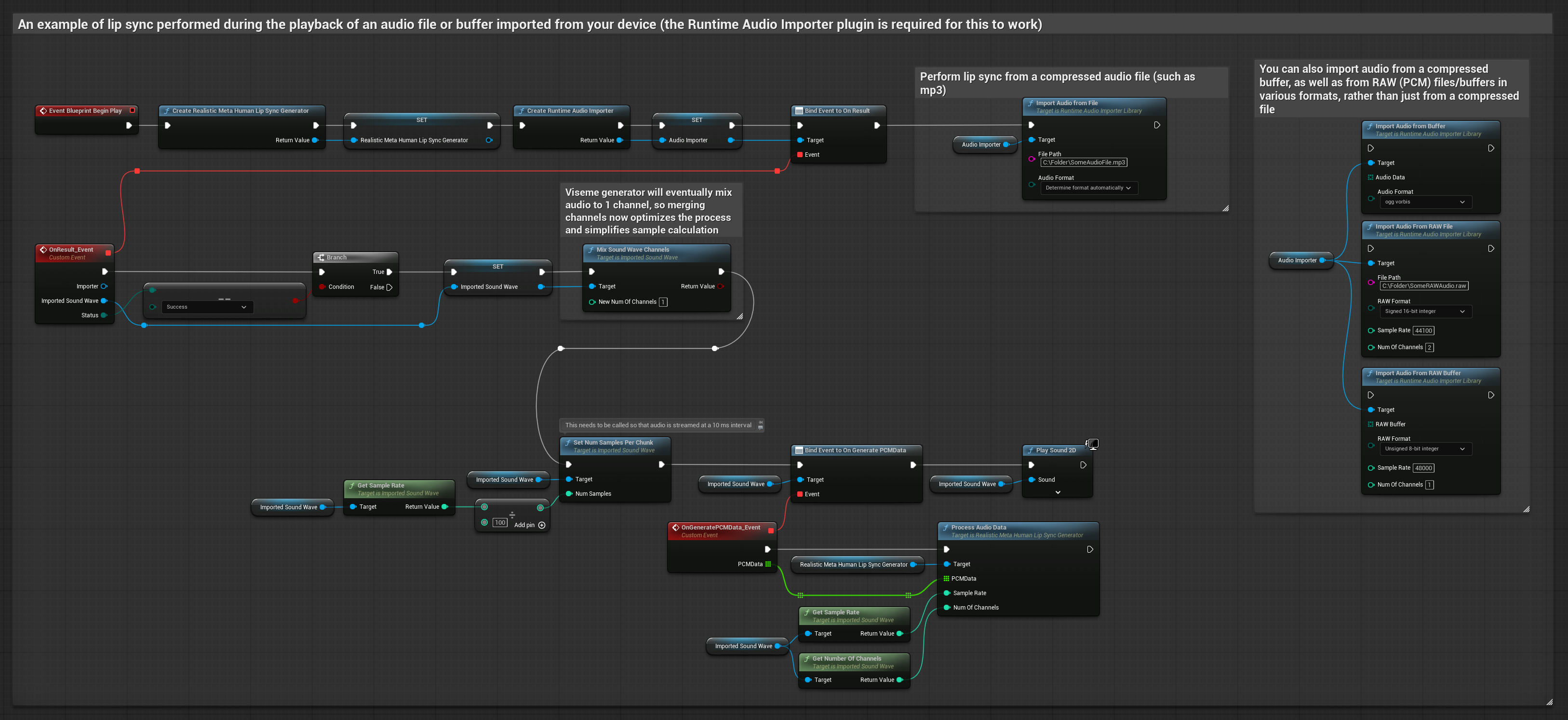
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
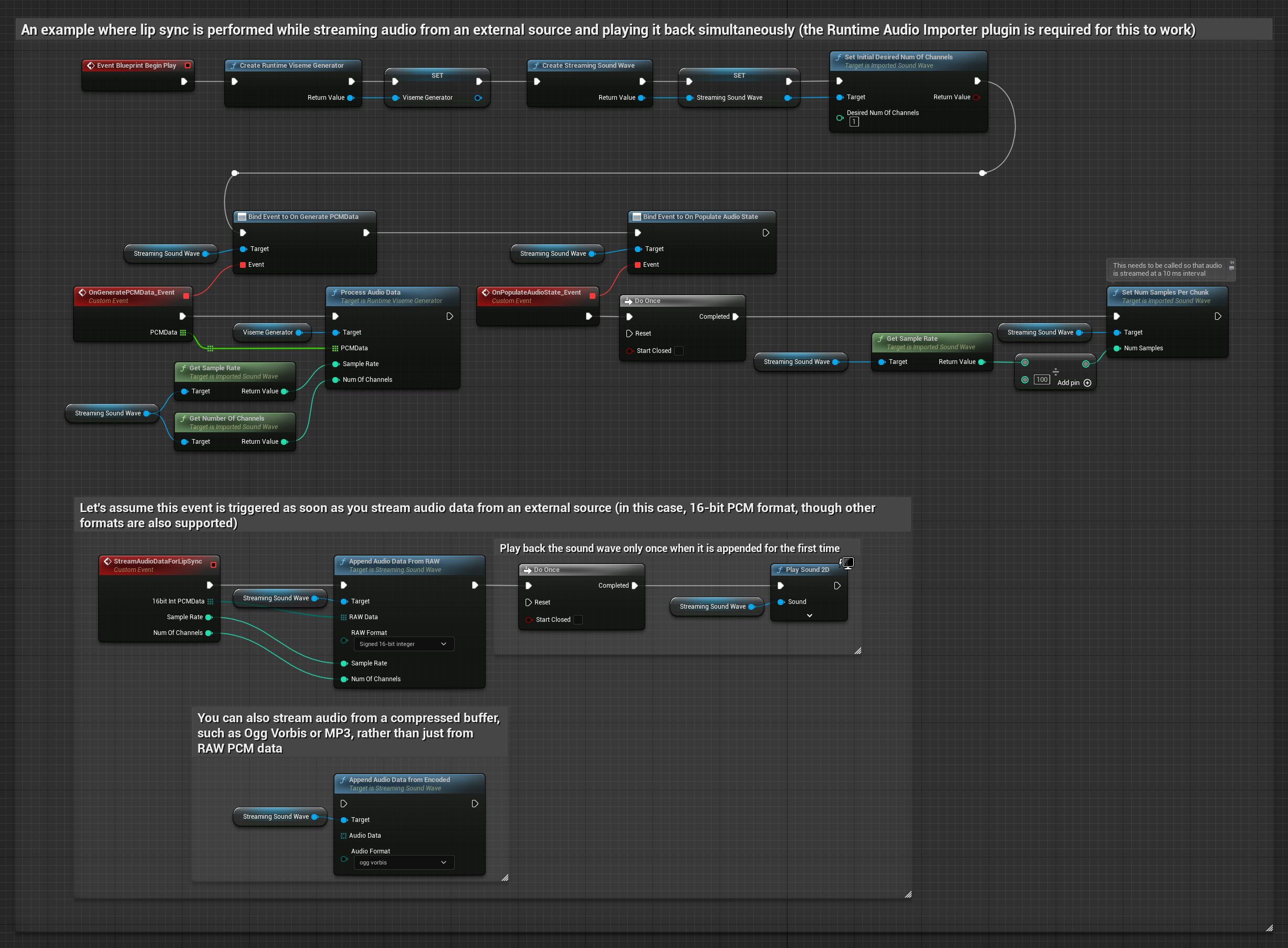
Để phát trực tiếp dữ liệu âm thanh từ bộ đệm, bạn cần:
- Mô hình Chuẩn
- Mô hình Chân thực
- Mô hình Hiện thực Hỗ trợ Cảm xúc
- Dữ liệu âm thanh ở định dạng PCM float (một mảng các mẫu dấu phẩy động) có sẵn từ nguồn phát trực tuyến của bạn (hoặc sử dụng Runtime Audio Importer để hỗ trợ nhiều định dạng hơn)
- Tốc độ lấy mẫu và số lượng kênh
- Gọi
ProcessAudioDatatừ Runtime Viseme Generator của bạn với các tham số này khi các khối âm thanh có sẵn
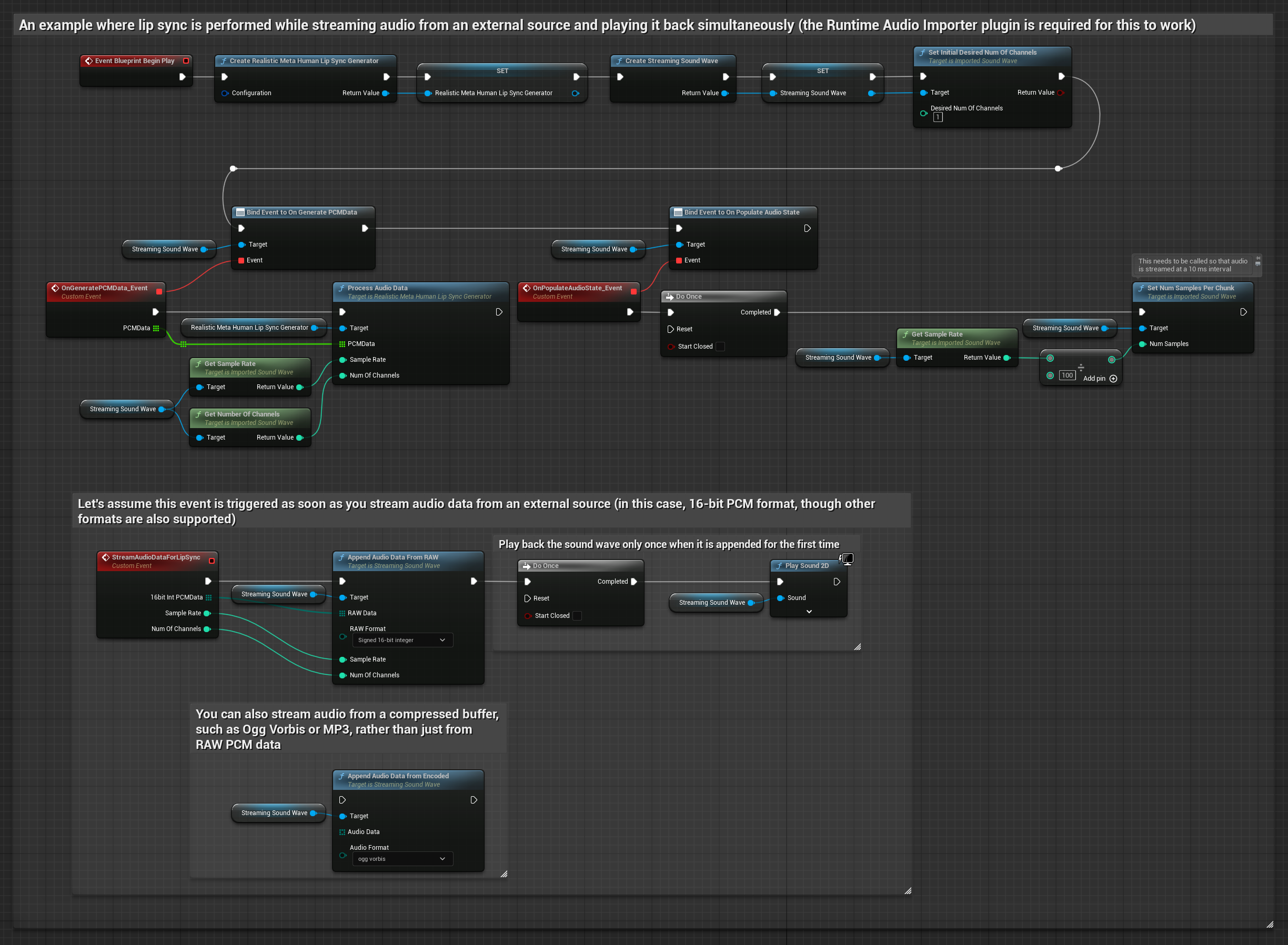
Mô hình Realistic sử dụng quy trình xử lý âm thanh tương tự như Mô hình Standard, nhưng với biến RealisticLipSyncGenerator thay vì VisemeGenerator.
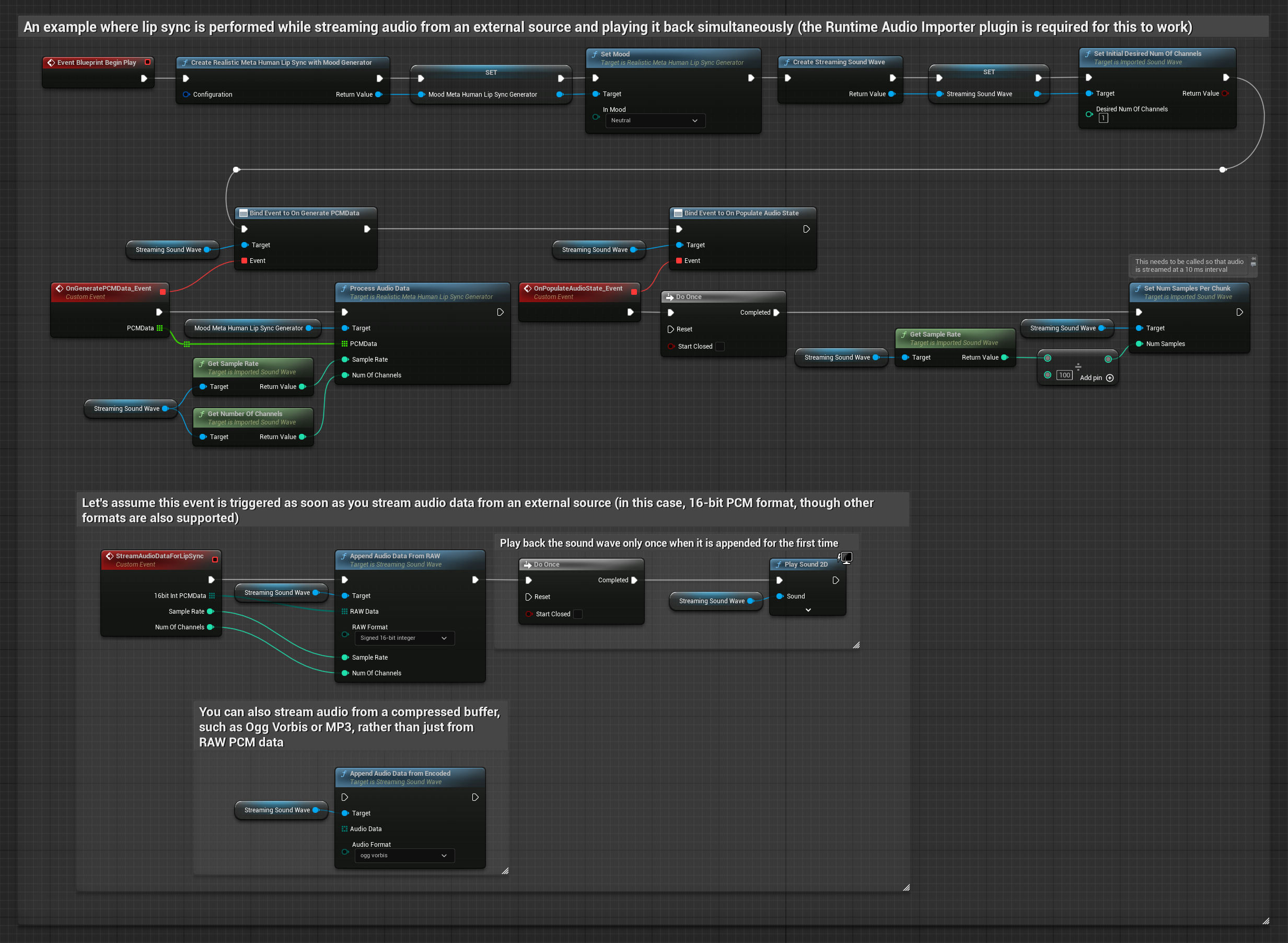
Mô hình hỗ trợ tâm trạng sử dụng quy trình xử lý âm thanh tương tự, nhưng với biến MoodMetaHumanLipSyncGenerator và các khả năng cấu hình tâm trạng bổ sung.
Lưu ý: Khi sử dụng các nguồn âm thanh phát trực tuyến, hãy đảm bảo quản lý thời gian phát âm thanh một cách phù hợp để tránh phát lại bị méo tiếng. Xem tài liệu Streaming Sound Wave để biết thêm thông tin.
Mẹo Hiệu Suất Xử Lý
-
Kích thước khối: Tăng tùy chọn cấu hình
ProcessingChunkSizetại đây (ví dụ lên 320, 480 hoặc 640 mẫu) có thể cải thiện đáng kể độ trễ mà ít ảnh hưởng đến chất lượng hoặc khả năng phản hồi. -
Loại mô hình: Khi sử dụng các mô hình Realistic, chuyển sang loại mô hình Highly Optimized (được chọn theo mặc định) có thể cải thiện hiệu suất. Lưu ý rằng mô hình gốc có thể cho chất lượng tốt hơn một chút, đặc biệt là với âm thanh có nhiễu.
-
Quản lý bộ đệm: Mô hình hỗ trợ tâm trạng xử lý âm thanh theo các khung 320 mẫu (20ms ở tần số 16kHz). Đảm bảo thời gian đầu vào âm thanh của bạn khớp với điều này để đạt hiệu suất tối ưu.
-
Tái tạo Generator: Để hoạt động ổn định với các mô hình Realistic, hãy tái tạo generator mỗi khi bạn muốn đưa dữ liệu âm thanh mới sau một khoảng thời gian không hoạt động. Xem Tái tạo Generator trong phần Khắc phục sự cố để biết giải thích.
Các bước tiếp theo
Sau khi thiết lập xử lý âm thanh, bạn có thể muốn:
- Tìm hiểu về Các tùy chọn cấu hình để tinh chỉnh hành vi đồng bộ môi của bạn
- Thêm hoạt ảnh cười để tăng cường biểu cảm
- Kết hợp đồng bộ môi với các hoạt ảnh khuôn mặt hiện có bằng kỹ thuật phân lớp được mô tả trong hướng dẫn Cấu hình