Dự án Demo
Lưu ý: Runtime Audio Importer là yêu cầu bắt buộc cho demo này để lấy dữ liệu âm thanh làm ví dụ. Vui lòng tải plugin này trước khi sử dụng demo (Fab).
Trong thư mục Demo nằm trong thư mục Content của plugin, bạn sẽ tìm thấy các tài sản được tạo ra cho mục đích trình diễn.
Nếu bạn không thấy thư mục của plugin, vui lòng vào Content Browser của bạn, hiển thị Settings ở góc trên bên phải, và bật Show Engine Content cũng như Show Plugin Content. Dự án sẽ nằm trong thư mục Engine -> Plugins -> Runtime Speech Recognizer Content.
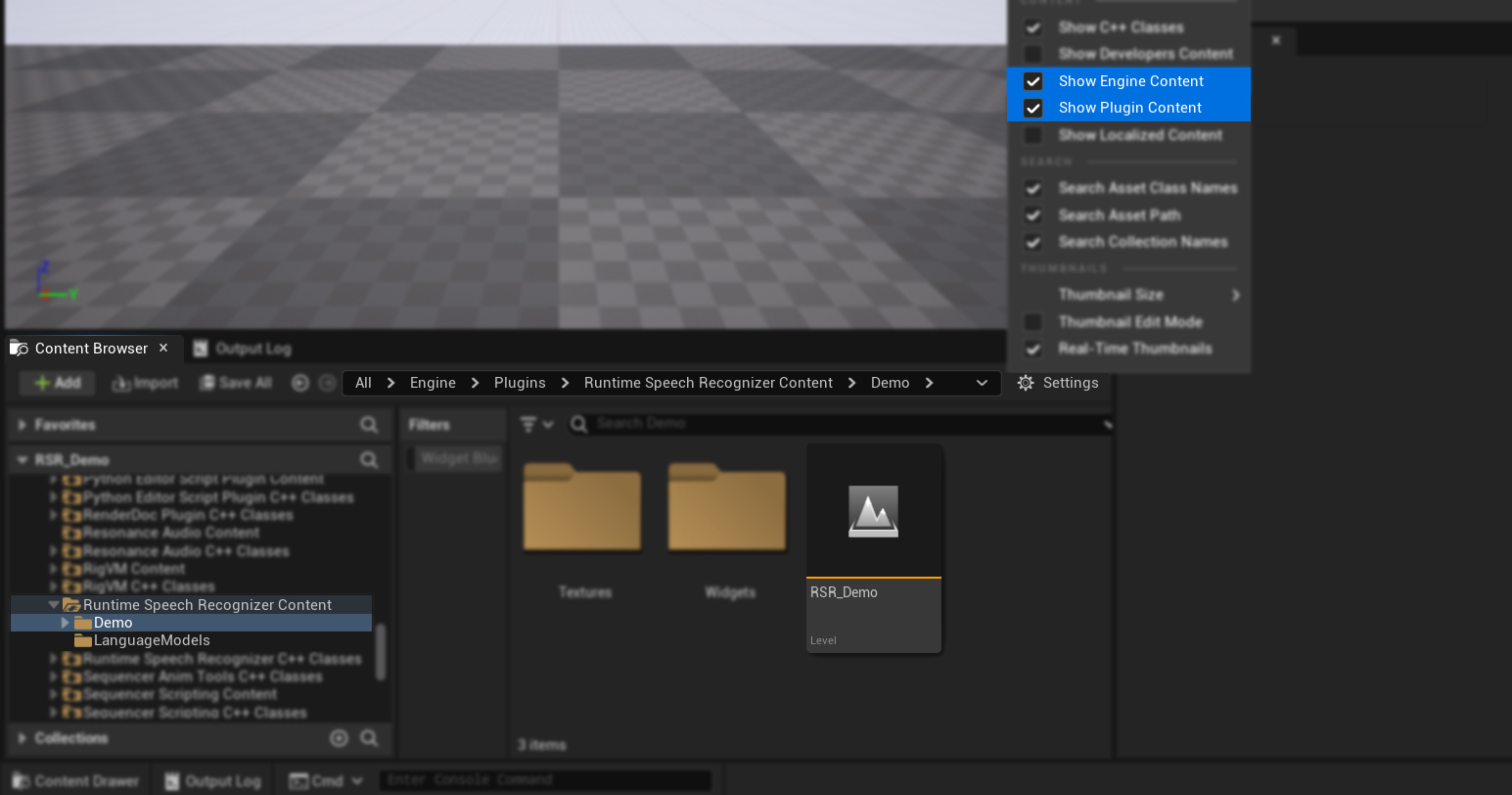
Các tài sản này có thể được sử dụng để kiểm tra và quan sát ví dụ về việc triển khai nhận dạng giọng nói. Dự án chứa hai ví dụ: một để nhận dạng giọng nói từ microphone và một để nhận dạng giọng nói từ tệp tin. Nó cũng hỗ trợ tùy chỉnh các thuộc tính nhận dạng thông qua menu cài đặt.
Dự án được triển khai hoàn toàn bằng Blueprints và widget UMG, giữ cho nó tối giản. Nó hỗ trợ UE 4.27 và các phiên bản mới hơn.
Để kiểm tra dự án, chỉ cần mở level RSR_Demo nằm trong thư mục Demo và chạy nó trong trình biên tập. Điều này sẽ thêm các widget liên quan đến nhận dạng giọng nói vào màn hình của bạn để bạn có thể tương tác. Bạn cũng có thể đóng gói dự án cho thiết bị mục tiêu của mình (để đặt level RSR_Demo làm mặc định trong dự án đã đóng gói, hãy chọn RSR_Demo làm Game Default Map trong cài đặt dự án).
Mô tả Ngắn về Dự án
Dự án bắt đầu với level RSR_Demo, level này thêm một widget W_RSR_MainMenu vào viewport, widget này đóng vai trò là menu chính và tạo bộ nhận dạng giọng nói chỉ một lần cho toàn bộ vòng đời của widget.

Nó cũng tạo nội bộ ba widget: W_RSR_SettingsMenu, W_RSR_FromMic, và W_RSR_FromFile, và truyền tham chiếu đối tượng bộ nhận dạng giọng nói cho chúng để hoạt động tiếp theo.
W_RSR_SettingsMenu được sử dụng để sửa đổi các thuộc tính nhận dạng như số lượng luồng được sử dụng, ngôn ngữ, kích thước bước, v.v.
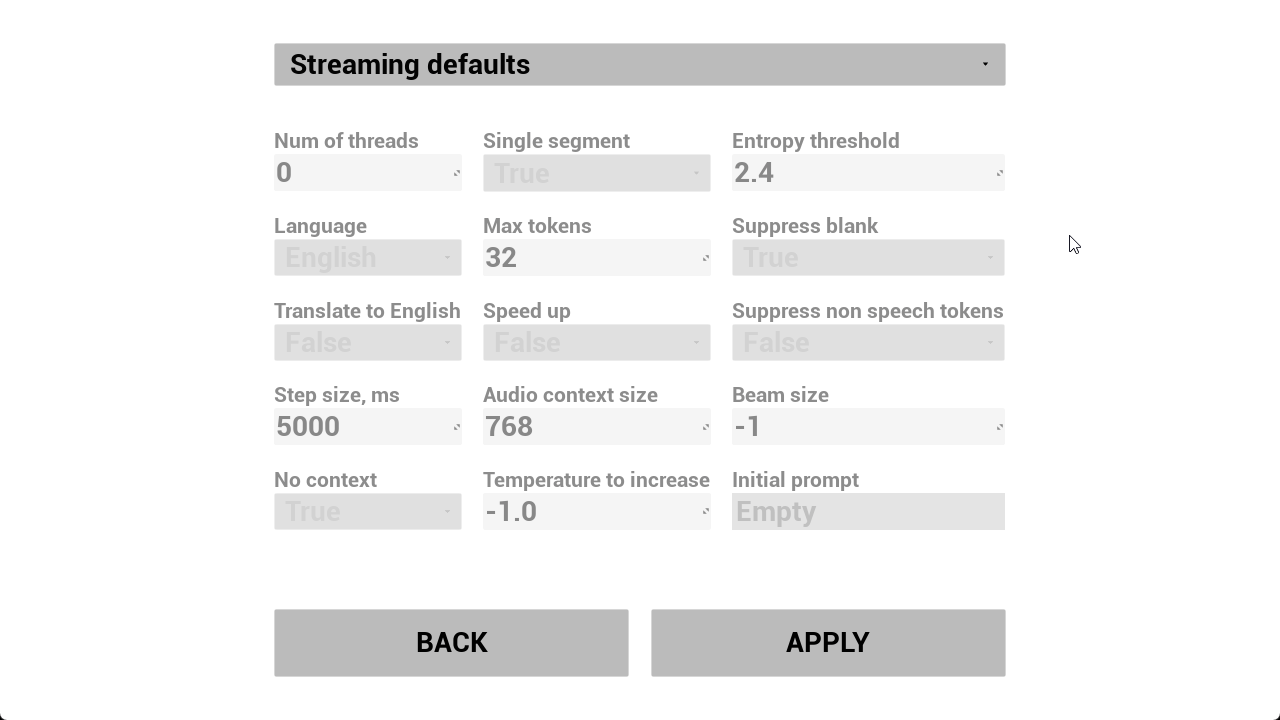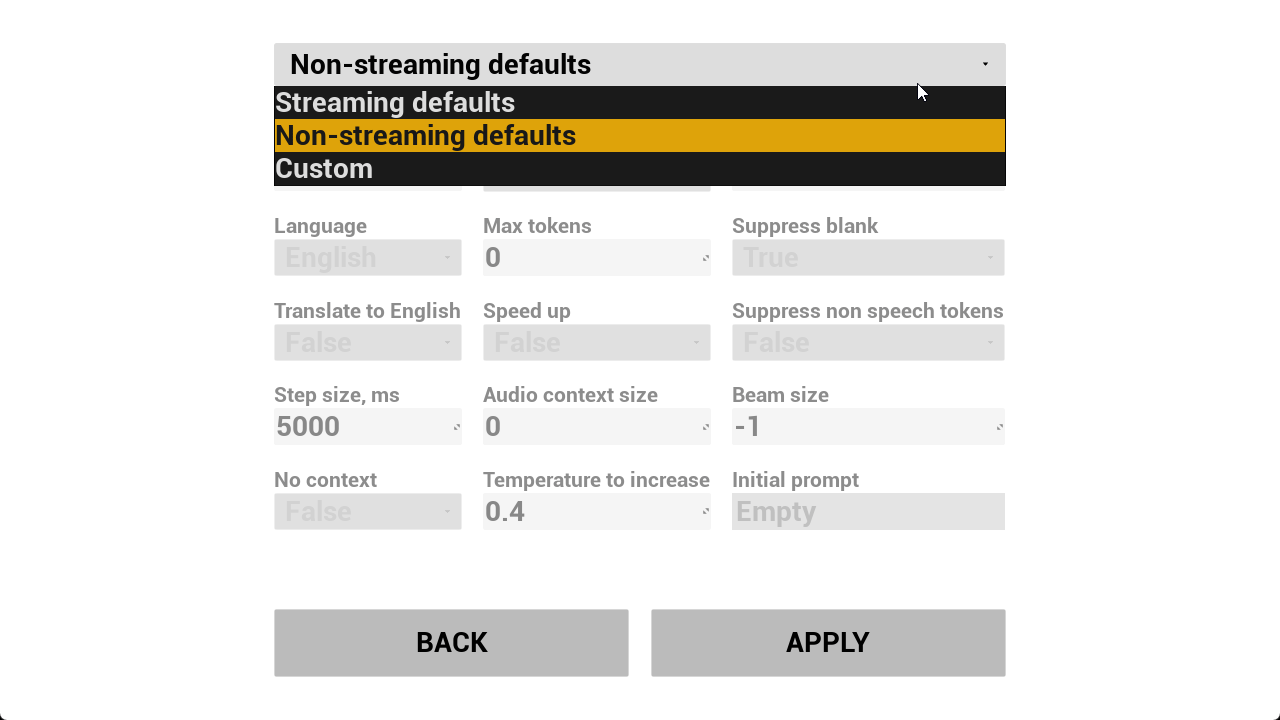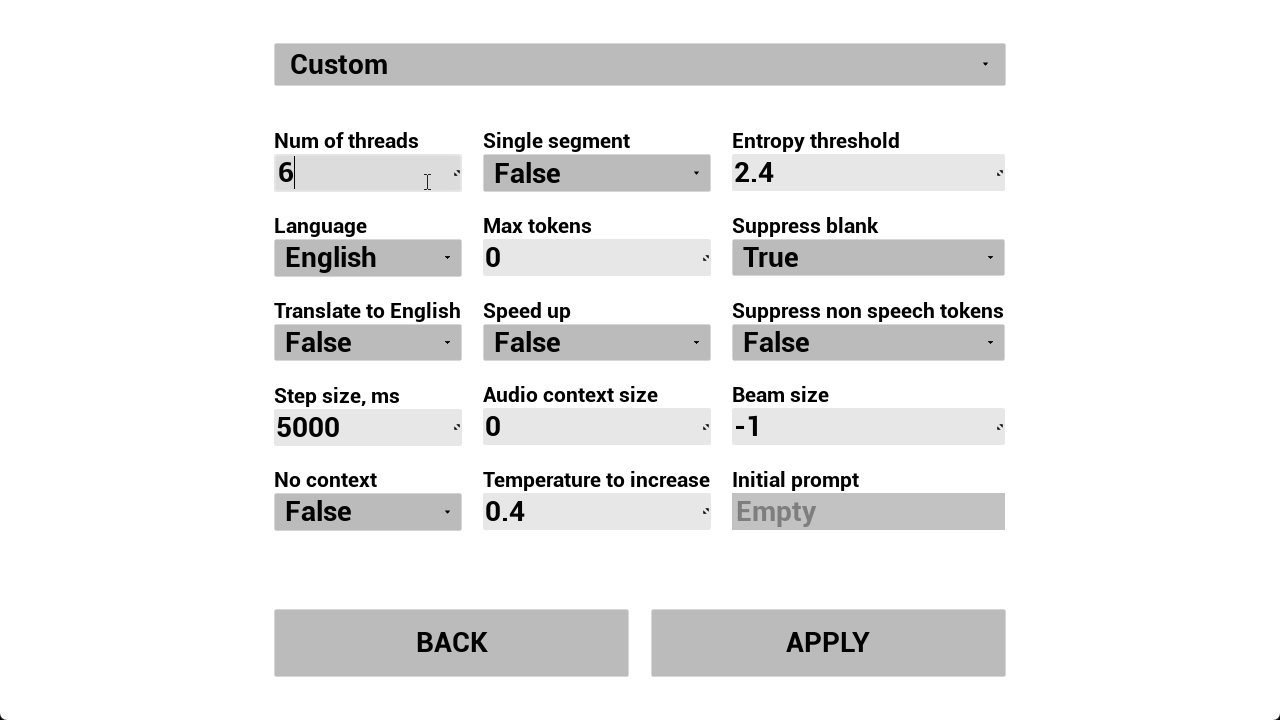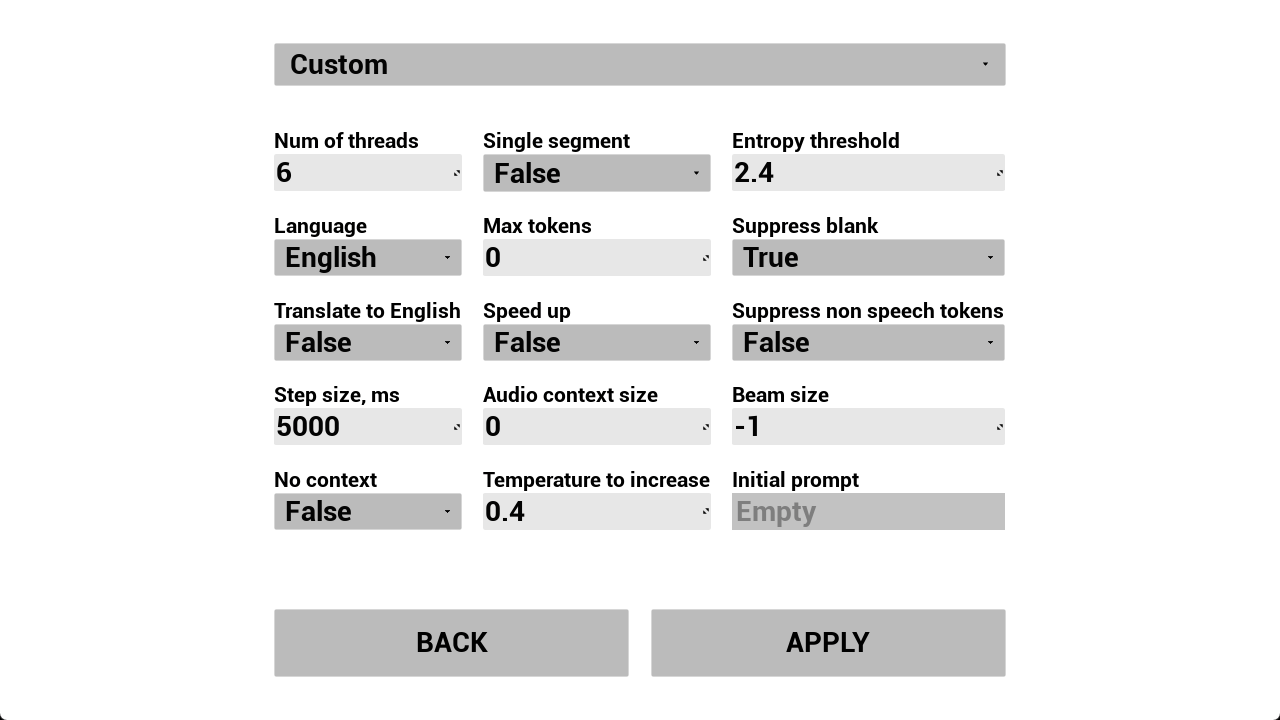
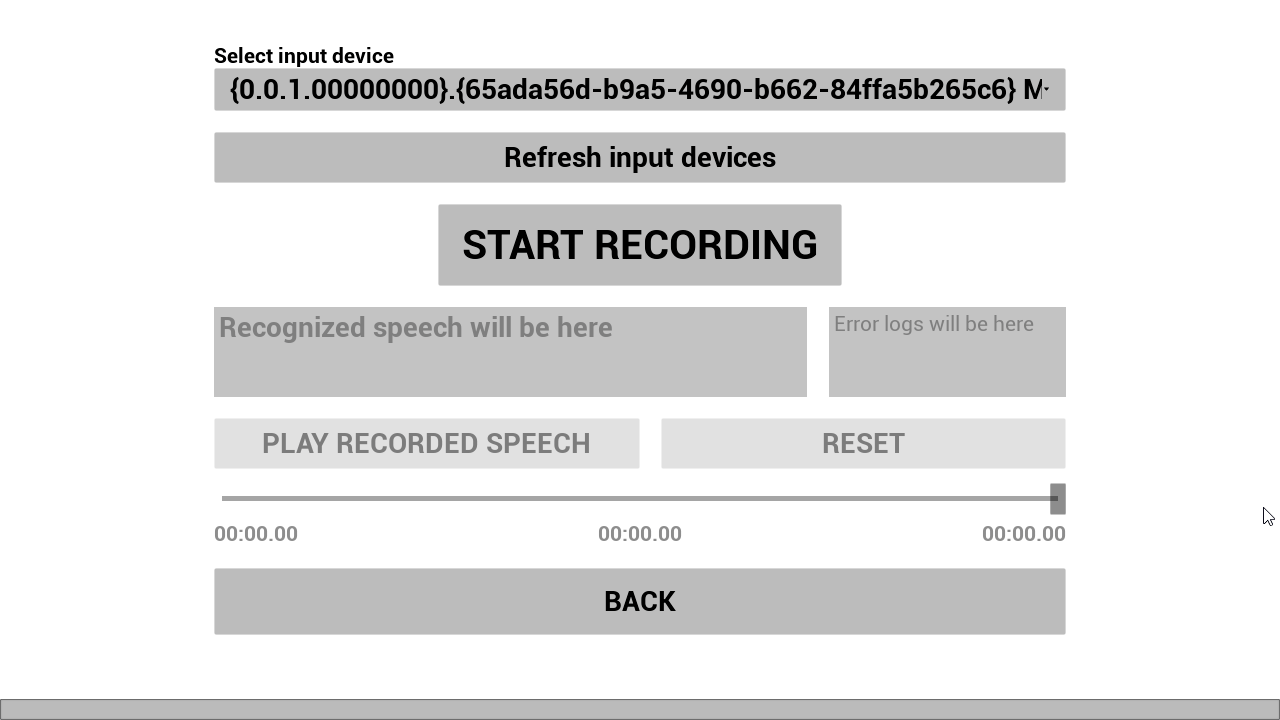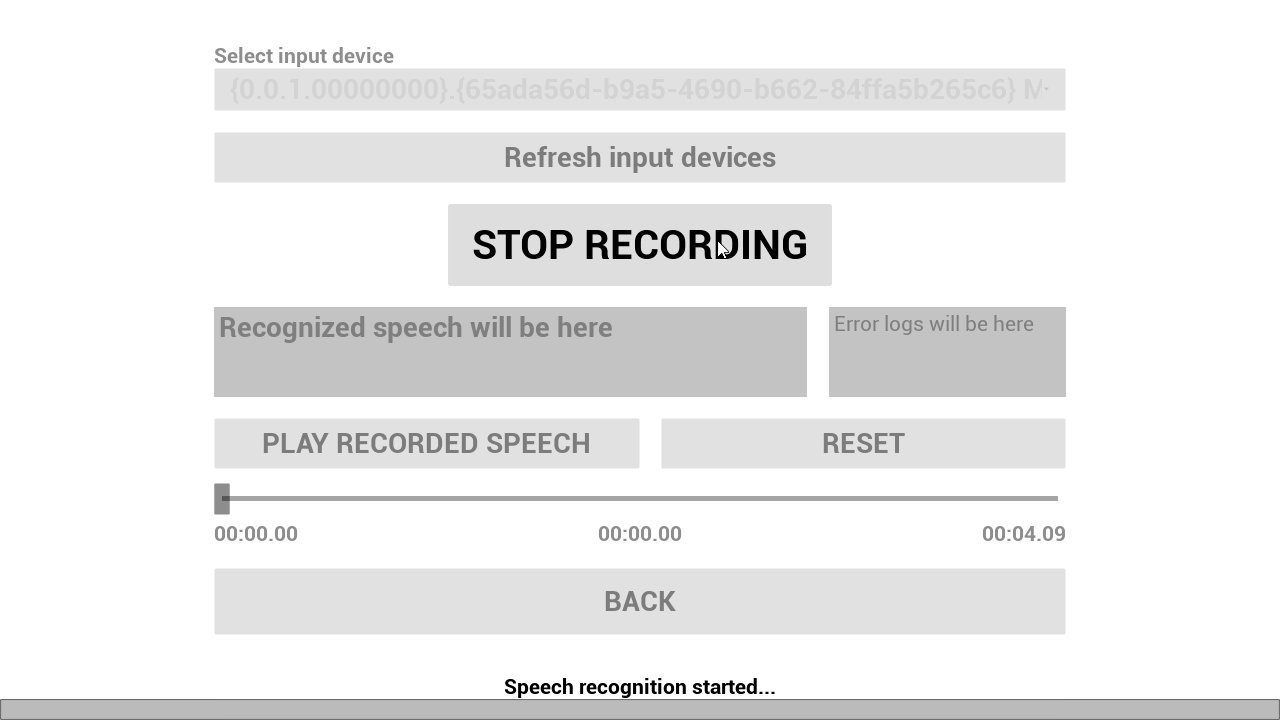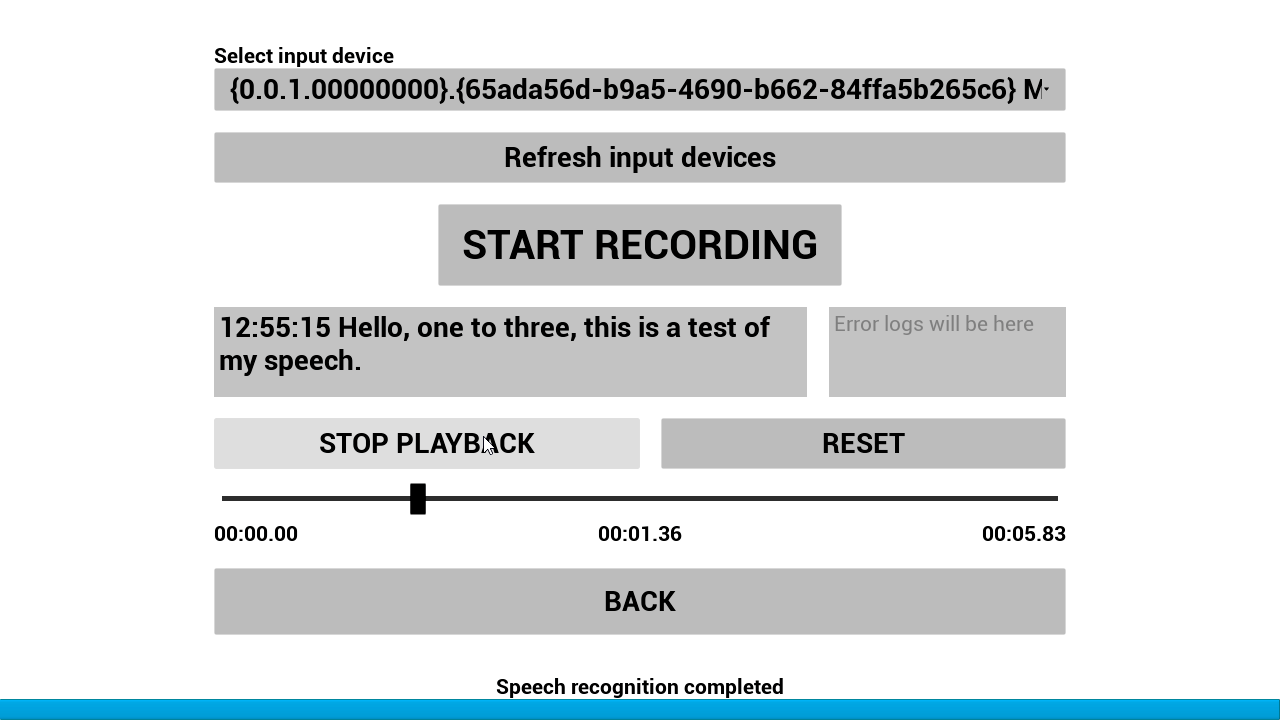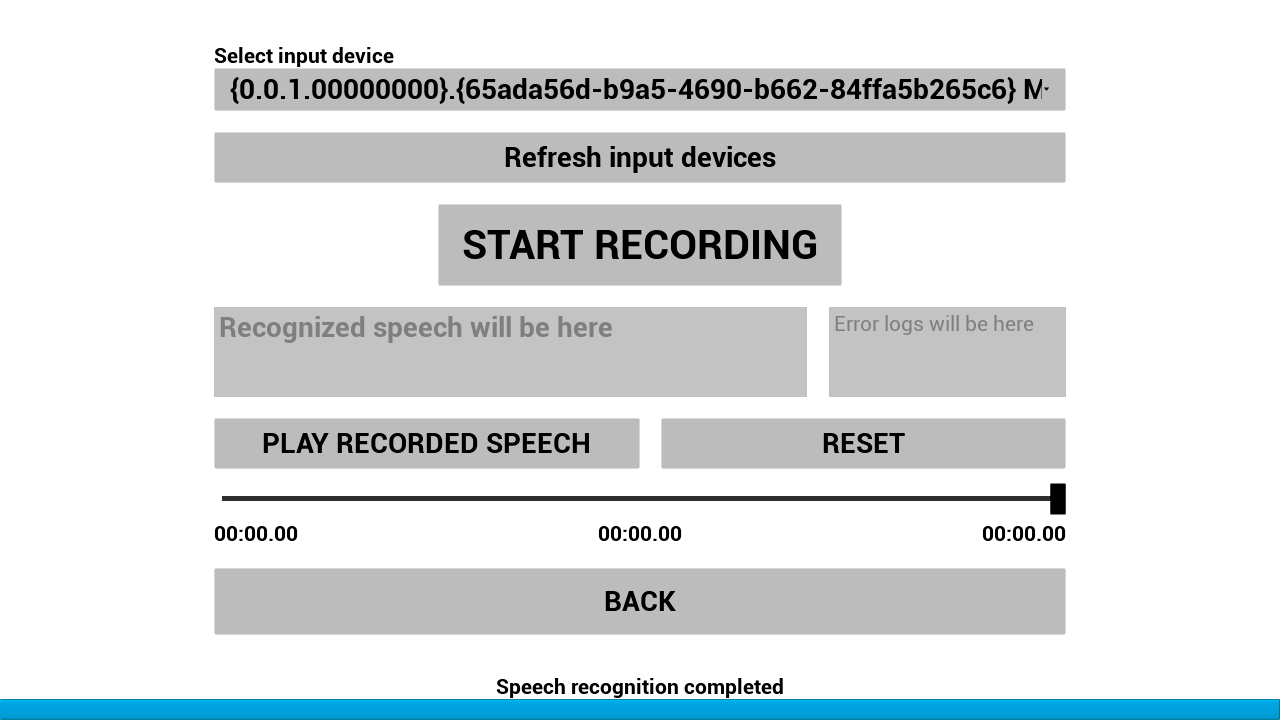
W_RSR_FromMic được sử dụng để nhận dạng giọng nói từ microphone. VAD được bật theo mặc định.
W_RSR_FromFile được sử dụng để nhận dạng giọng nói từ một tệp tin bằng cách sử dụng đường dẫn trực tiếp.