Cách sử dụng plugin
Plugin Runtime Speech Recognizer được thiết kế để nhận dạng từ từ dữ liệu âm thanh đầu vào. Nó sử dụng phiên bản đã được sửa đổi nhẹ của whisper.cpp để hoạt động với engine. Để sử dụng plugin, hãy làm theo các bước sau:
Phía Editor
- Chọn các mô hình ngôn ngữ phù hợp cho dự án của bạn như được mô tả tại đây.
Phía Runtime
- Tạo một Speech Recognizer và thiết lập các tham số cần thiết (CreateSpeechRecognizer, xem tham số tại đây).
- Liên kết với các delegate cần thiết (OnRecognitionFinished, OnRecognizedTextSegment và OnRecognitionError).
- Bắt đầu nhận dạng giọng nói (StartSpeechRecognition).
- Xử lý dữ liệu âm thanh và chờ kết quả từ các delegate (ProcessAudioData).
- Dừng bộ nhận dạng giọng nói khi cần (ví dụ: sau khi broadcast OnRecognitionFinished).
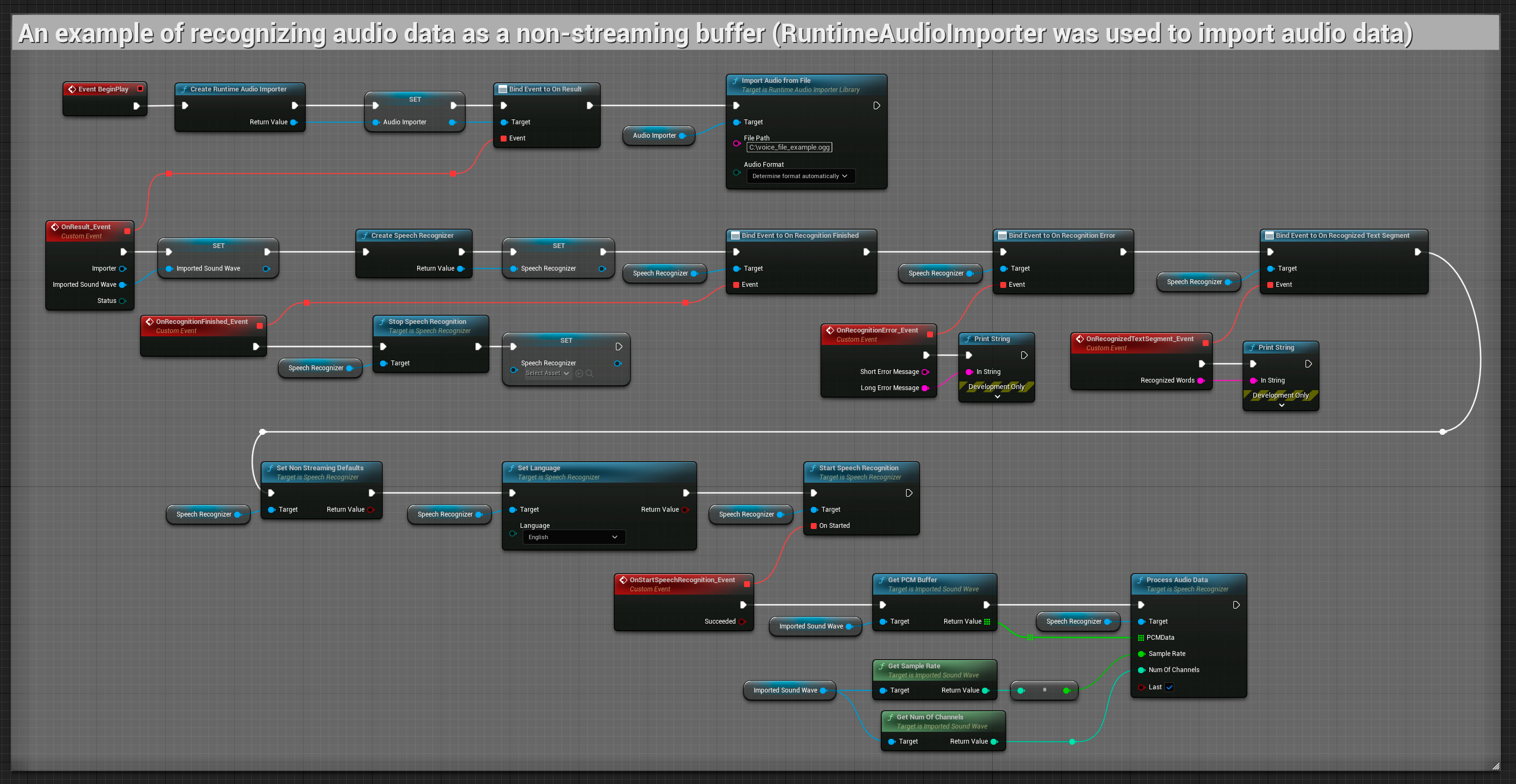
Plugin hỗ trợ âm thanh đầu vào ở định dạng floating point 32-bit interleaved PCM. Mặc dù nó hoạt động tốt với Runtime Audio Importer, nhưng nó không phụ thuộc trực tiếp vào plugin đó.
Tham số nhận dạng
Plugin hỗ trợ cả nhận dạng dữ liệu âm thanh dạng luồng (streaming) và không phải luồng (non-streaming). Để điều chỉnh các tham số nhận dạng cho trường hợp sử dụng cụ thể của bạn, hãy gọi SetStreamingDefaults hoặc SetNonStreamingDefaults. Ngoài ra, bạn có thể linh hoạt thiết lập thủ công các tham số riêng lẻ như số lượng luồng (threads), kích thước bước (step size), có dịch ngôn ngữ đầu vào sang tiếng Anh hay không, và có sử dụng bản phiên âm trước đó hay không. Tham khảo Danh sách tham số nhận dạng để biết danh sách đầy đủ các tham số có sẵn.
Cải thiện hiệu suất
Vui lòng tham khảo phần Cách cải thiện hiệu suất để biết các mẹo tối ưu hóa hiệu suất của plugin.
Phát hiện hoạt động giọng nói (VAD)
Khi xử lý đầu vào âm thanh, đặc biệt là trong các tình huống phát trực tuyến (streaming), bạn nên sử dụng Phát hiện hoạt động giọng nói (VAD) để lọc các đoạn âm thanh trống hoặc chỉ có tiếng ồn trước khi chúng đến bộ nhận dạng. Việc lọc này có thể được kích hoạt ở phía capturable sound wave bằng cách sử dụng plugin Runtime Audio Importer, giúp ngăn các mô hình ngôn ngữ bị ảo giác - cố gắng tìm kiếm các mẫu trong tiếng ồn và tạo ra các bản phiên âm không chính xác.
Để có kết quả nhận dạng giọng nói tối ưu, chúng tôi khuyên bạn nên sử dụng Silero VAD provider, cung cấp khả năng chống nhiễu vượt trội và phát hiện giọng nói chính xác hơn. Silero VAD có sẵn dưới dạng một phần mở rộng cho plugin Runtime Audio Importer. Để biết hướng dẫn chi tiết về cấu hình VAD, hãy tham khảo tài liệu Phát hiện hoạt động giọng nói.
Các node có thể sao chép trong các ví dụ bên dưới sử dụng VAD provider mặc định vì lý do tương thích. Để nâng cao độ chính xác của nhận dạng, bạn có thể dễ dàng chuyển sang Silero VAD bằng cách:
- Cài đặt phần mở rộng Silero VAD như được mô tả trong phần Silero VAD Extension
- Sau khi kích hoạt VAD bằng node Toggle VAD, thêm node Set VAD Provider và chọn "Silero" từ menu thả xuống
Trong dự án demo đi kèm với plugin, VAD được kích hoạt theo mặc định. Bạn có thể tìm thêm thông tin về cách triển khai demo tại Dự án Demo.
Ví dụ
Các ví dụ này minh họa cách sử dụng plugin Runtime Speech Recognizer với cả đầu vào âm thanh dạng luồng và không phải luồng, sử dụng Runtime Audio Importer để lấy dữ liệu âm thanh làm ví dụ. Xin lưu ý rằng cần phải tải riêng RuntimeAudioImporter để có quyền truy cập vào cùng một bộ tính năng nhập âm thanh được trình bày trong các ví dụ (ví dụ: capturable sound wave và ImportAudioFromFile). Các ví dụ này chỉ nhằm mục đích minh họa khái niệm cốt lõi và không bao gồm xử lý lỗi.
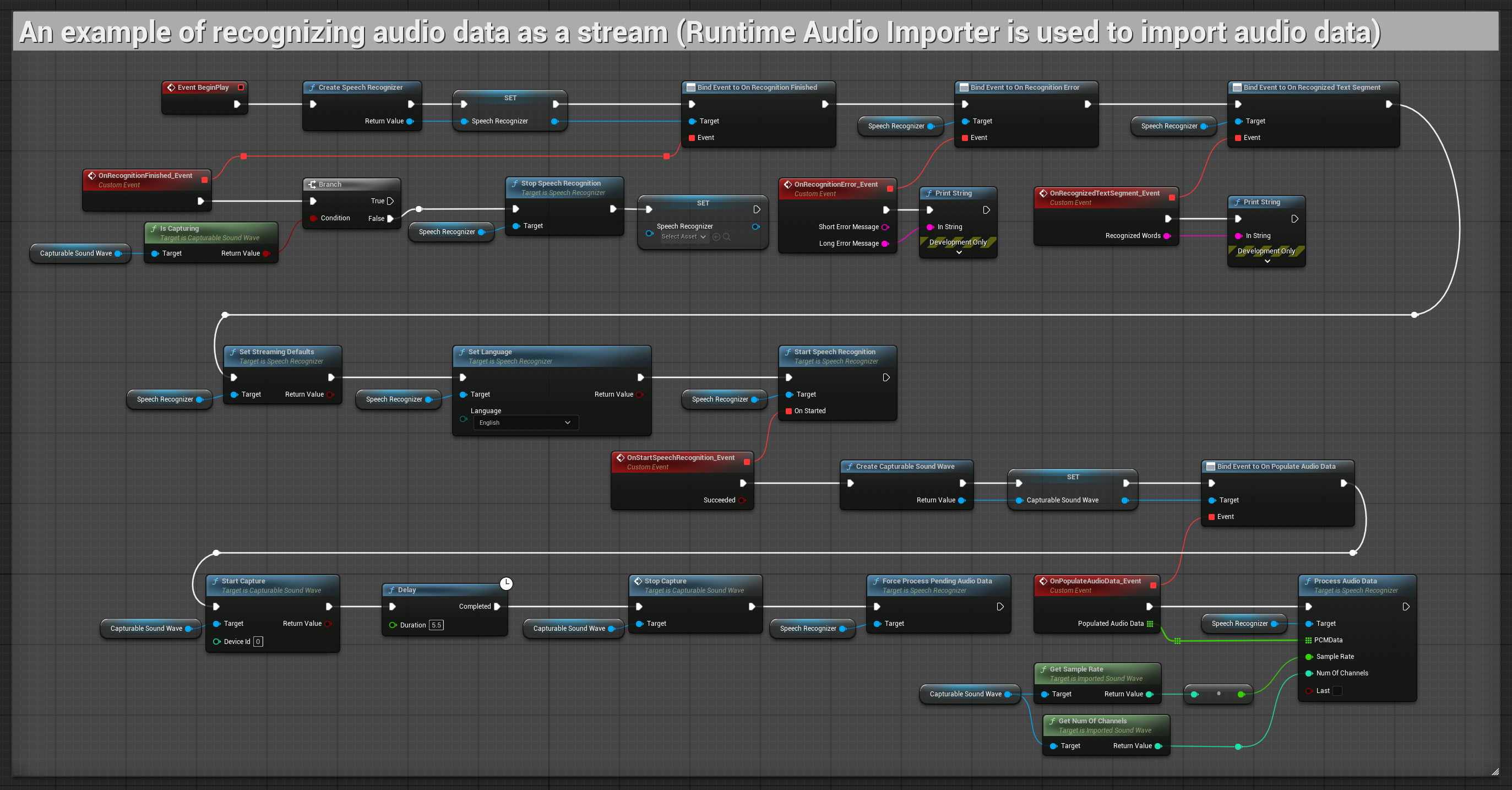
Ví dụ về đầu vào âm thanh dạng luồng (streaming)
Lưu ý: Trong UE 5.3 và các phiên bản khác, bạn có thể gặp phải các node bị thiếu sau khi sao chép Blueprint. Điều này có thể xảy ra do sự khác biệt trong quá trình tuần tự hóa node giữa các phiên bản engine. Luôn kiểm tra xem tất cả các node đã được kết nối đúng cách trong quá trình triển khai của bạn hay chưa.
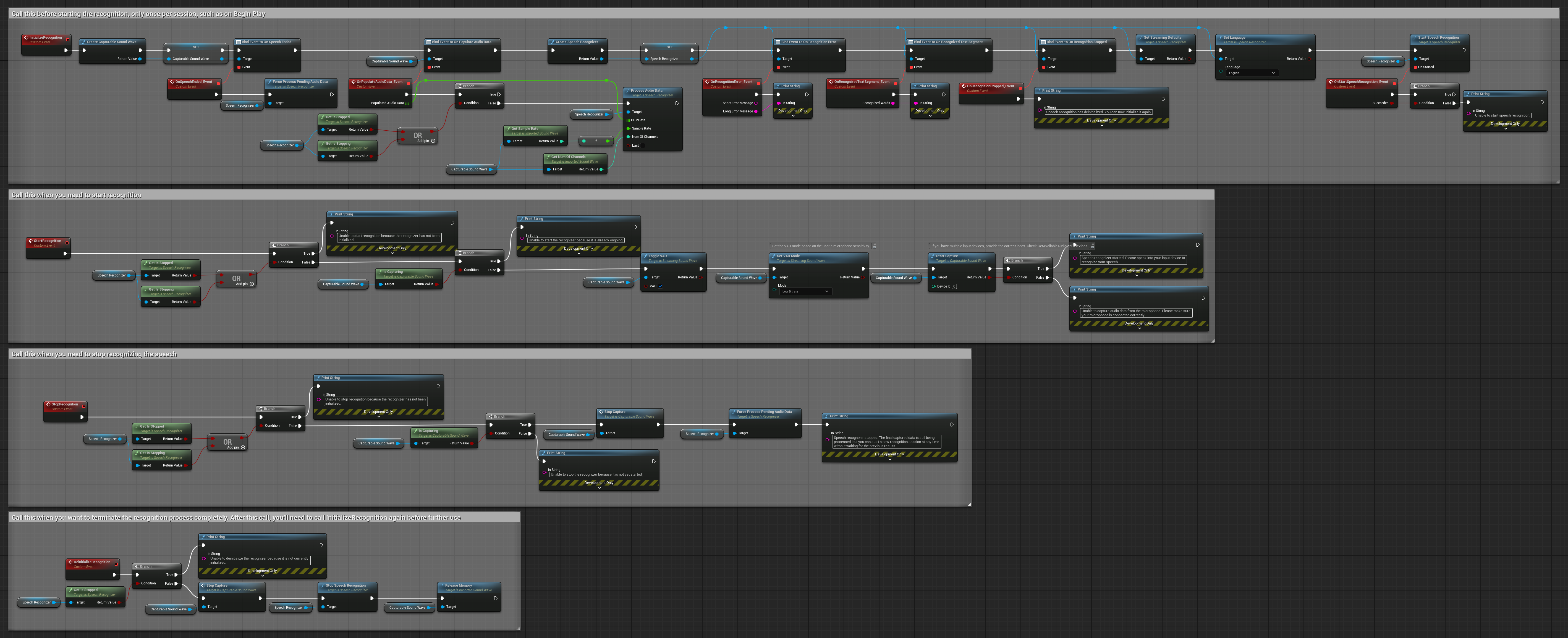
1. Nhận dạng luồng cơ bản
Ví dụ này minh họa thiết lập cơ bản để thu dữ liệu âm thanh từ micrô dưới dạng luồng bằng cách sử dụng Capturable sound wave và chuyển nó đến bộ nhận dạng giọng nói. Nó ghi lại giọng nói trong khoảng 5 giây và sau đó xử lý nhận dạng, phù hợp cho các thử nghiệm nhanh và triển khai đơn giản. Các node có thể sao chép.
Các tính năng chính của thiết lập này:
- Thời lượng ghi cố định 5 giây
- Nhận dạng một lần đơn giản
- Yêu cầu thiết lập tối thiểu
- Hoàn hảo cho thử nghiệm và tạo mẫu thử
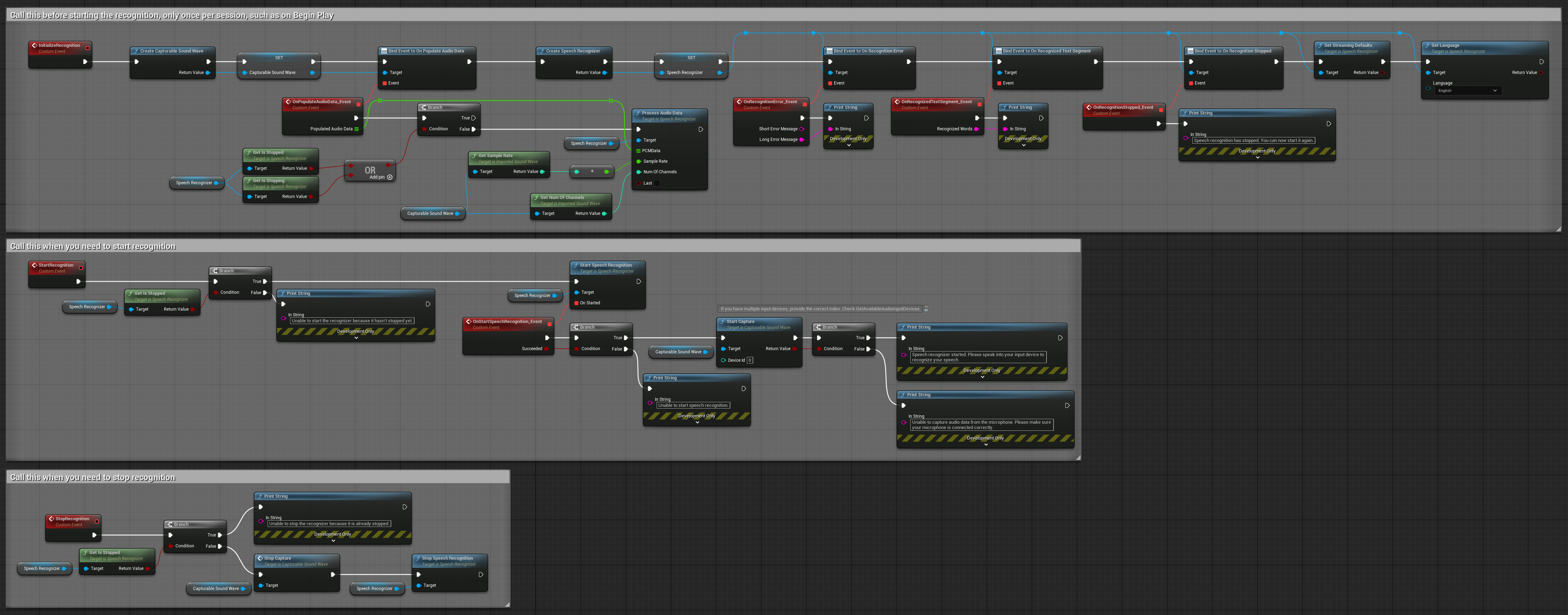
2. Nhận dạng luồng có kiểm soát
Ví dụ này mở rộng thiết lập luồng cơ bản bằng cách thêm khả năng kiểm soát thủ công quá trình nhận dạng. Nó cho phép bạn bắt đầu và dừng nhận dạng theo ý muốn, phù hợp cho các tình huống bạn cần kiểm soát chính xác thời điểm nhận dạng xảy ra. Các node có thể sao chép.
Các tính năng chính của thiết lập này:
- Kiểm soát bắt đầu/dừng thủ công
- Khả năng nhận dạng liên tục
- Thời lượng ghi linh hoạt
- Phù hợp cho các ứng dụng tương tác
3. Nhận dạng lệnh kích hoạt bằng giọng nói
Ví dụ này được tối ưu hóa cho các tình huống nhận dạng lệnh. Nó kết hợp nhận dạng luồng với Phát hiện hoạt động giọng nói (VAD) để tự động xử lý giọng nói khi người dùng ngừng nói. Bộ nhận dạng bắt đầu xử lý giọng nói tích lũy chỉ khi phát hiện thấy sự im lặng, lý tưởng cho các giao diện dựa trên lệnh. Các node có thể sao chép.
Các tính năng chính của thiết lập này:
- Kiểm soát bắt đầu/dừng thủ công
- Phát hiện hoạt động giọng nói (VAD) được kích hoạt để phát hiện các đoạn giọng nói
- Kích hoạt nhận dạng tự động khi phát hiện thấy sự im lặng
- Tối ưu cho nhận dạng lệnh ngắn
- Giảm chi phí xử lý bằng cách chỉ nhận dạng giọng nói thực tế
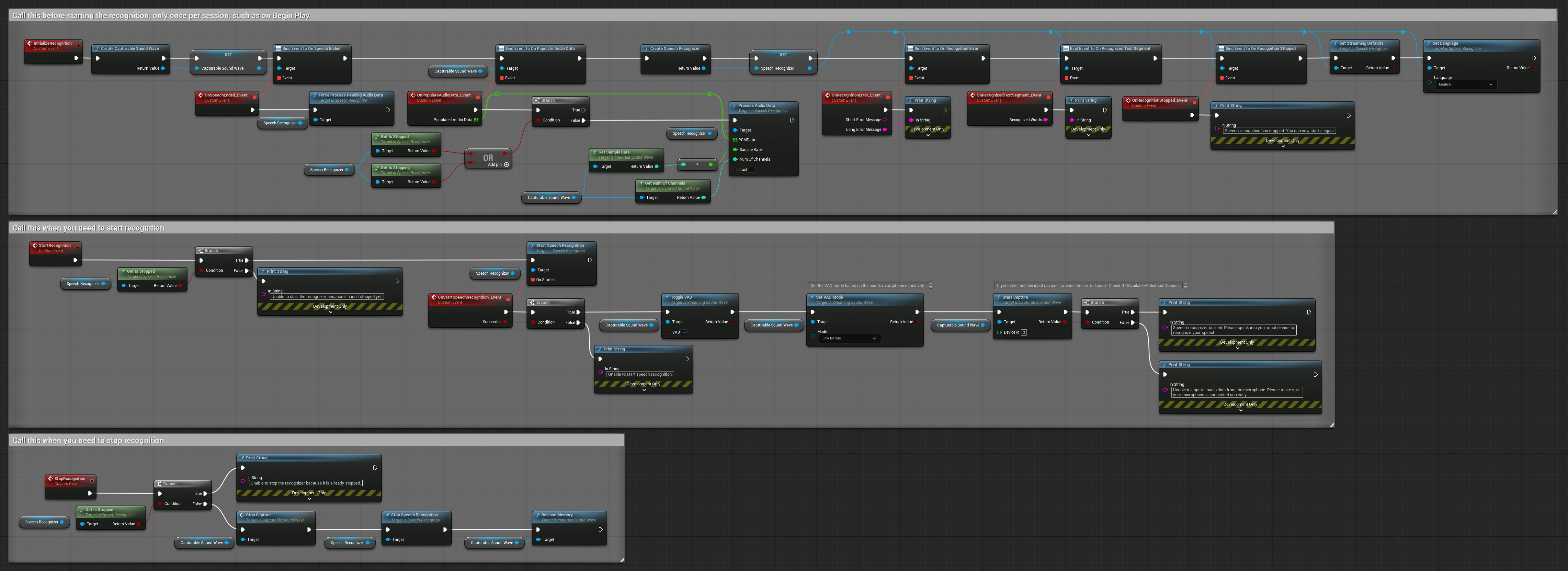
4. Nhận dạng giọng nói tự động khởi tạo với xử lý bộ đệm cuối cùng
Ví dụ này là một biến thể khác của phương pháp nhận dạng kích hoạt bằng giọng nói với cách xử lý vòng đời khác. Nó tự động khởi động bộ nhận dạng trong quá trình khởi tạo và dừng nó trong quá trình hủy khởi tạo. Một tính năng chính là nó xử lý bộ đệm âm thanh tích lũy cuối cùng trước khi dừng bộ nhận dạng, đảm bảo không có dữ liệu giọng nói nào bị mất khi người dùng muốn kết thúc quá trình nhận dạng. Thiết lập này đặc biệt hữu ích cho các ứng dụng nơi bạn cần ghi lại toàn bộ câu nói của người dùng ngay cả khi dừng giữa chừng. Các node có thể sao chép.
Các tính năng chính của thiết lập này:
- Tự động khởi động bộ nhận dạng khi khởi tạo
- Tự động dừng bộ nhận dạng khi hủy khởi tạo
- Xử lý bộ đệm âm thanh cuối cùng trước khi dừng hoàn toàn
- Sử dụng Phát hiện hoạt động giọng nói (VAD) để nhận dạng hiệu quả
- Đảm bảo không có dữ liệu giọng nói nào bị mất khi dừng
Đầu vào âm thanh không phải luồng (non-streaming)
Ví dụ này nhập dữ liệu âm thanh vào Imported sound wave và nhận dạng toàn bộ dữ liệu âm thanh sau khi nó đã được nhập. Các node có thể sao chép.