Danh sách tham số nhận dạng
Các tham số này chỉ có thể được thiết lập khi bộ nhận dạng không đang chạy.
Đây không phải là danh sách đầy đủ các tham số có sẵn trong Whisper. Chỉ những tham số quan trọng nhất mới được hiển thị ở đây. Nếu cần, danh sách này sẽ được cập nhật.
Thiết lập tham số nhận dạng
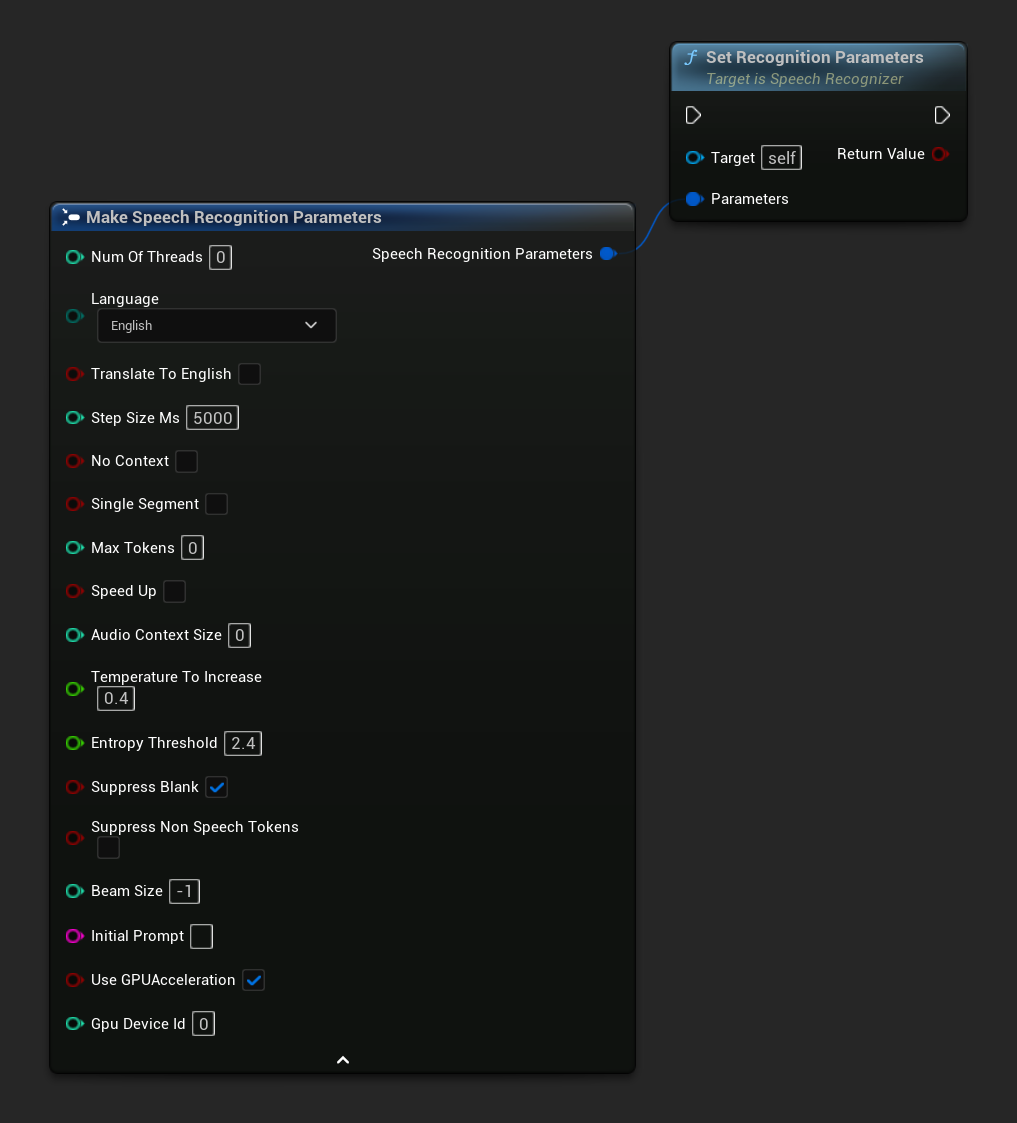
Thiết lập các tham số cho nhận dạng giọng nói. Nếu bạn chỉ muốn thay đổi các tham số cụ thể, hãy cân nhắc sử dụng các hàm thiết lập riêng lẻ.
Thiết lập mặc định cho streaming
Thiết lập các tham số mặc định phù hợp cho nhận dạng giọng nói dạng streaming.
Hàm này ghi đè tất cả các tham số đã được áp dụng trước đó. Hãy đảm bảo gọi hàm này trước khi thiết lập các tham số tùy chỉnh của bạn nếu bạn cần sử dụng các giá trị mặc định streaming làm cấu hình cơ sở.
Thiết lập mặc định không streaming
Thiết lập các tham số mặc định phù hợp cho nhận dạng giọng nói không streaming.
Hàm này ghi đè tất cả các tham số đã được áp dụng trước đó. Hãy đảm bảo gọi hàm này trước khi thiết lập các tham số tùy chỉnh của bạn nếu bạn cần sử dụng các giá trị mặc định không streaming làm cấu hình cơ sở.
Thiết lập số luồng
Thiết lập số luồng để sử dụng cho nhận dạng giọng nói. Đặt giá trị này thành 0 để sử dụng số lõi.
Thiết lập ngôn ngữ
Thiết lập ngôn ngữ để sử dụng cho nhận dạng giọng nói. Phải được hỗ trợ bởi mô hình ngôn ngữ đã chọn trong cài đặt Editor.
Việc đặt ngôn ngữ thành Tự động sẽ làm giảm độ chính xác và hiệu suất nhận dạng.
Lấy ngôn ngữ đã phát hiện
Lấy ngôn ngữ đã được phát hiện từ lần nhận dạng cuối cùng. Trả về ngôn ngữ dưới dạng giá trị enum.
Lưu ý: Hàm này chỉ hoạt động sau khi nhận dạng đã được thực hiện. Nó trả về Tự động nếu việc phát hiện ngôn ngữ thất bại hoặc không được thực hiện. Điều này đặc biệt hữu ích khi sử dụng tính năng phát hiện ngôn ngữ Tự động để xác định ngôn ngữ nào thực sự đã được nhận dạng.
Lấy mã ngôn ngữ
Chuyển đổi giá trị enum ngôn ngữ thành chuỗi mã ngôn ngữ của nó (ví dụ: En -> "en", Fr -> "fr", De -> "de").
Lấy tên đầy đủ của ngôn ngữ
Chuyển đổi giá trị enum ngôn ngữ thành tên ngôn ngữ đầy đủ của nó (ví dụ: En -> "Tiếng Anh", Fr -> "Tiếng Pháp", De -> "Tiếng Đức").
Thiết lập dịch sang tiếng Anh
![]()
Thiết lập có dịch các từ đã nhận dạng sang tiếng Anh hay không. Nếu true, mô hình ngôn ngữ phải là đa ngôn ngữ.
Thiết lập kích thước bước
Thiết lập kích thước bước tính bằng mili giây. Xác định tần suất gửi dữ liệu âm thanh để nhận dạng. Giá trị mặc định là 5000 ms (5 giây).
Thiết lập không ngữ cảnh
Thiết lập có sử dụng bản phiên âm trước đó (nếu có) làm lời nhắc ban đầu cho bộ giải mã hay không.
Thiết lập phân đoạn đơn
Thiết lập có buộc đầu ra là phân đoạn đơn hay không (hữu ích cho streaming).
Thiết lập số token tối đa
Thiết lập số lượng token tối đa trên mỗi phân đoạn văn bản. Sử dụng 0 để không giới hạn.
Thiết lập tăng tốc
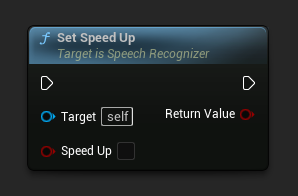
Thiết lập có tăng tốc nhận dạng lên 2 lần bằng Phase Vocoder hay không. Đặt thành false để cải thiện chất lượng đầu ra.
Thiết lập kích thước ngữ cảnh âm thanh
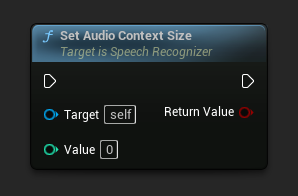
Thiết lập kích thước của ngữ cảnh âm thanh. Đặt thành 0 để cải thiện chất lượng đầu ra.
Thiết lập nhiệt độ để tăng
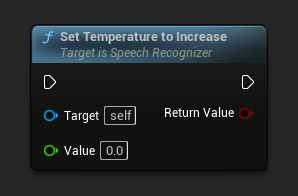
Thiết lập nhiệt độ để tăng khi dự phòng khi giải mã không đáp ứng được một trong các ngưỡng dưới đây.
Thiết lập ngưỡng entropy
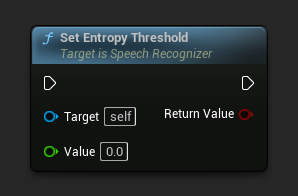
Thiết lập ngưỡng entropy. Nếu tỷ lệ nén cao hơn giá trị này, hãy coi việc giải mã là thất bại. Tương tự như "compression_ratio_threshold" của OpenAI.
Thiết lập triệt tiêu khoảng trắng
![]()
Thiết lập có triệt tiêu các khoảng trắng xuất hiện trong đầu ra hay không.
Thiết lập triệt tiêu token không phải giọng nói
Thiết lập có triệt tiêu các token không phải giọng nói xuất hiện trong đầu ra hay không.
Thiết lập kích thước chùm tia
Thiết lập số lượng chùm tia trong tìm kiếm chùm tia. Chỉ áp dụng khi nhiệt độ bằng không.
Thiết lập lời nhắc ban đầu
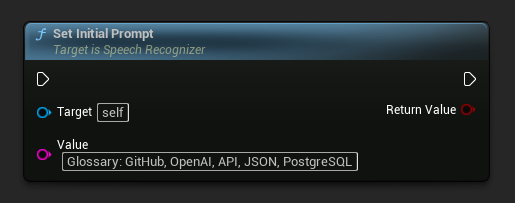
Thiết lập lời nhắc ban đầu cho cửa sổ đầu tiên. Điều này có thể được sử dụng để cung cấp ngữ cảnh cho việc nhận dạng nhằm dự đoán các từ chính xác hơn, ví dụ: từ vựng tùy chỉnh hoặc danh từ riêng.
Để biết thêm chi tiết về các chiến lược tạo lời nhắc hiệu quả, hãy xem Hướng dẫn tạo lời nhắc Whisper.
Thiết lập tăng tốc GPU
Thiết lập có sử dụng tăng tốc GPU cho nhận dạng giọng nói hay không (chỉ áp dụng trên Windows tại thời điểm hiện tại).
Thiết lập ID thiết bị GPU
Thiết lập ID thiết bị GPU để sử dụng cho nhận dạng giọng nói. Giá trị mặc định là 0. Điều này hữu ích cho các hệ thống có nhiều GPU để chỉ định GPU nào sẽ được sử dụng cho quá trình nhận dạng. Nếu ID thiết bị GPU được chỉ định không hợp lệ, chỉ mục thiết bị GPU khả dụng đầu tiên sẽ được sử dụng thay thế.