Cách sử dụng plugin
Plugin Runtime Text To Speech tổng hợp văn bản thành giọng nói bằng cách sử dụng các mô hình giọng nói có thể tải xuống. Các mô hình này được quản lý trong cài đặt plugin trong trình chỉnh sửa, tải xuống và đóng gói để sử dụng trong thời gian chạy. Thực hiện theo các bước dưới đây để bắt đầu.
Phía Editor
Tải xuống các mô hình giọng nói phù hợp cho dự án của bạn như được mô tả tại đây. Bạn có thể tải xuống nhiều mô hình giọng nói cùng một lúc.
Phía Runtime
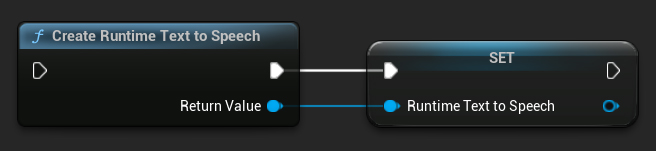
Tạo bộ tổng hợp bằng cách sử dụng hàm CreateRuntimeTextToSpeech. Đảm bảo bạn duy trì một tham chiếu đến nó (ví dụ: như một biến riêng biệt trong Blueprints hoặc UPROPERTY trong C++) để ngăn nó bị thu gom rác.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Tổng hợp Giọng nói
Plugin cung cấp hai chế độ tổng hợp giọng nói từ văn bản:
- Tổng hợp Giọng nói Thông thường: Tổng hợp toàn bộ văn bản và trả về âm thanh hoàn chỉnh khi kết thúc
- Tổng hợp Giọng nói Truyền phát: Cung cấp các đoạn âm thanh khi chúng được tạo ra, cho phép xử lý theo thời gian thực
Mỗi chế độ hỗ trợ hai phương pháp để chọn mô hình giọng nói:
- Theo Tên: Chọn mô hình giọng nói theo tên của nó (khuyến nghị cho UE 5.4+)
- Theo Đối tượng: Chọn mô hình giọng nói bằng tham chiếu trực tiếp (khuyến nghị cho UE 5.3 và các phiên bản cũ hơn)
Tổng hợp Giọng nói Thông thường
Theo Tên
- Blueprint
- C++
Hàm Text To Speech (By Name) thuận tiện hơn trong Blueprints bắt đầu từ UE 5.4. Nó cho phép bạn chọn mô hình giọng nói từ danh sách thả xuống của các mô hình đã tải xuống. Trong các phiên bản UE dưới 5.3, danh sách thả xuống này không xuất hiện, vì vậy nếu bạn đang sử dụng phiên bản cũ hơn, bạn sẽ cần phải tự lặp qua mảng các mô hình giọng nói được trả về bởi GetDownloadedVoiceModels để chọn mô hình bạn cần.
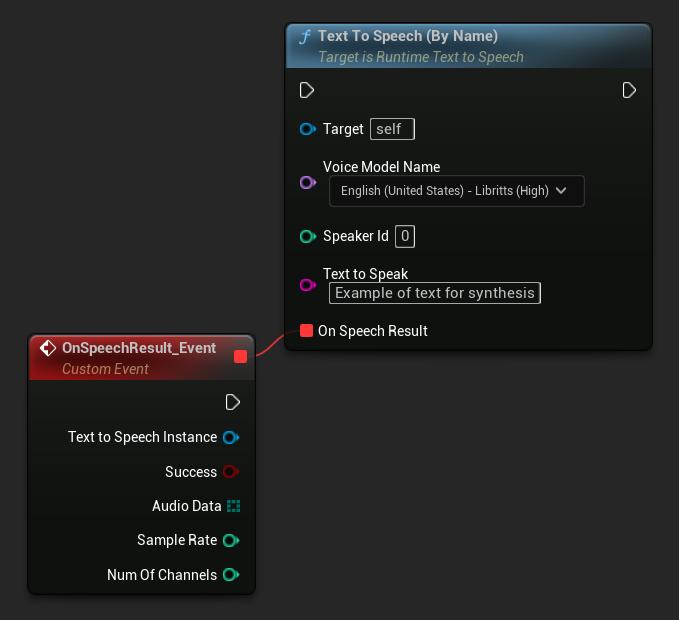
Trong C++, việc lựa chọn mô hình giọng nói có thể phức tạp hơn một chút do thiếu danh sách thả xuống. Bạn có thể sử dụng hàm GetDownloadedVoiceModelNames để lấy tên của các mô hình giọng nói đã tải xuống và chọn mô hình bạn cần. Sau đó, bạn có thể gọi hàm TextToSpeechByName để tổng hợp văn bản bằng cách sử dụng tên mô hình giọng nói đã chọn.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Theo Đối tượng
- Blueprint
- C++
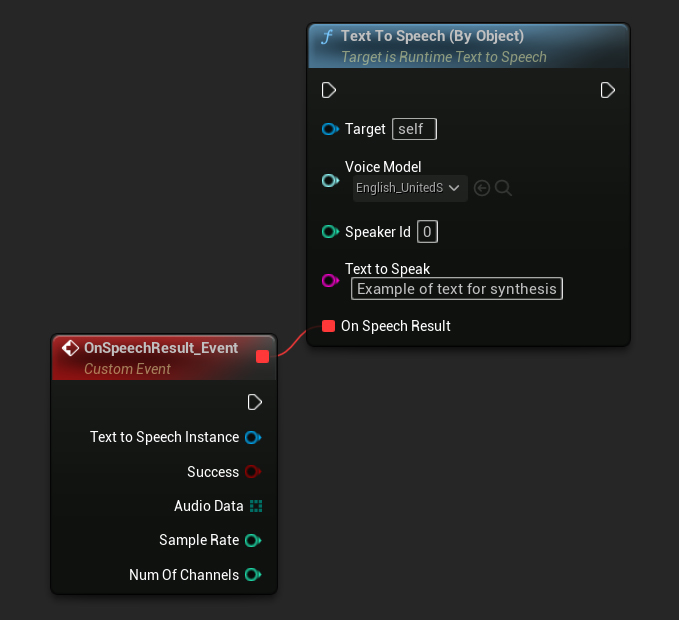
Hàm Text To Speech (By Object) hoạt động trên tất cả các phiên bản của Unreal Engine nhưng hiển thị các mô hình giọng nói dưới dạng danh sách thả xuống các tham chiếu tài sản, điều này kém trực quan hơn. Phương pháp này phù hợp cho UE 5.3 trở về trước, hoặc nếu dự án của bạn yêu cầu một tham chiếu trực tiếp đến một tài sản mô hình giọng nói vì bất kỳ lý do nào.
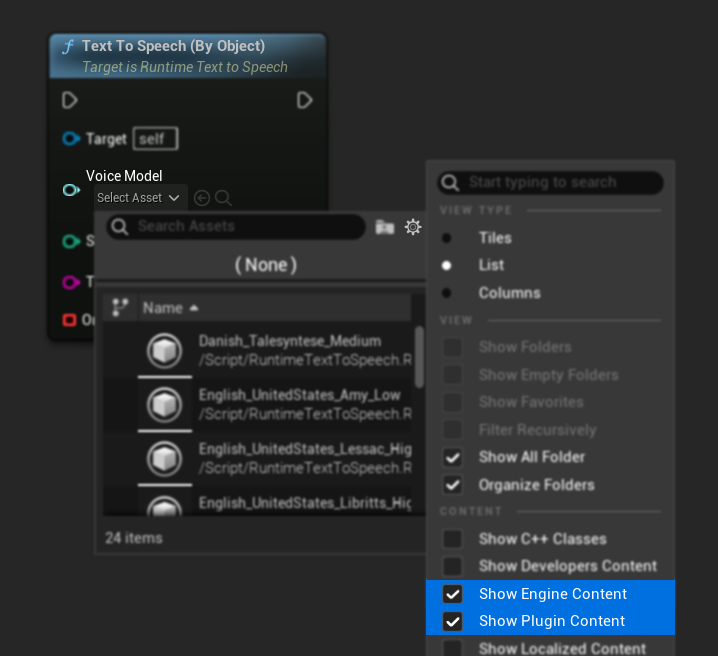
Nếu bạn đã tải xuống các mô hình nhưng không thấy chúng, hãy mở menu thả xuống Voice Model, nhấp vào biểu tượng cài đặt (hình bánh răng), và bật cả Show Plugin Content và Show Engine Content để hiển thị các mô hình.
Trong C++, việc lựa chọn các mô hình giọng nói có thể phức tạp hơn một chút do thiếu danh sách thả xuống. Bạn có thể sử dụng hàm GetDownloadedVoiceModelNames để lấy tên của các mô hình giọng nói đã tải xuống và chọn mô hình bạn cần. Sau đó, bạn có thể gọi hàm GetVoiceModelFromName để lấy đối tượng mô hình giọng nói và truyền nó vào hàm TextToSpeechByObject để tổng hợp văn bản.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Phát giọng nói từ văn bản theo luồng (Streaming Text-to-Speech)
Đối với các văn bản dài hơn hoặc khi bạn muốn xử lý dữ liệu âm thanh theo thời gian thực khi nó đang được tạo ra, bạn có thể sử dụng các phiên bản phát luồng của các hàm Text-to-Speech:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNametrong C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjecttrong C++)
Các hàm này cung cấp dữ liệu âm thanh theo từng khối (chunk) khi chúng được tạo ra, cho phép xử lý ngay lập tức mà không cần đợi toàn bộ quá trình tổng hợp hoàn tất. Điều này hữu ích cho nhiều ứng dụng khác nhau như phát lại âm thanh thời gian thực, trực quan hóa trực tiếp, hoặc bất kỳ tình huống nào bạn cần xử lý dữ liệu giọng nói một cách gia tăng.
Phát luồng theo tên (Streaming By Name)
- Blueprint
- C++
Hàm Streaming Text To Speech (By Name) hoạt động tương tự như phiên bản thông thường nhưng cung cấp dữ liệu âm thanh theo từng khối thông qua delegate On Speech Chunk.
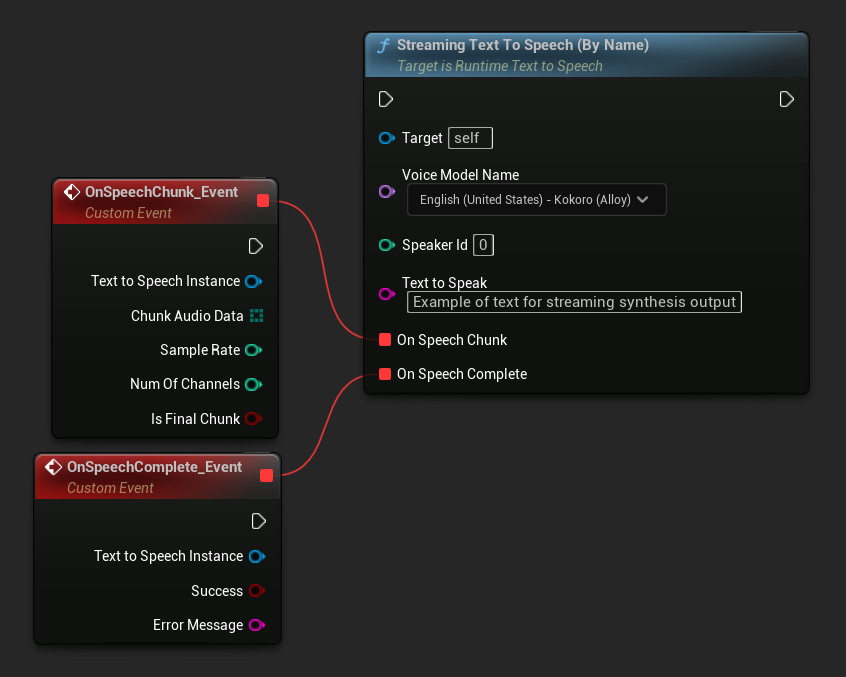
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Streaming Theo Đối Tượng
- Blueprint
- C++
Hàm Streaming Text To Speech (By Object) cung cấp cùng chức năng streaming nhưng nhận tham chiếu đối tượng mô hình giọng nói.
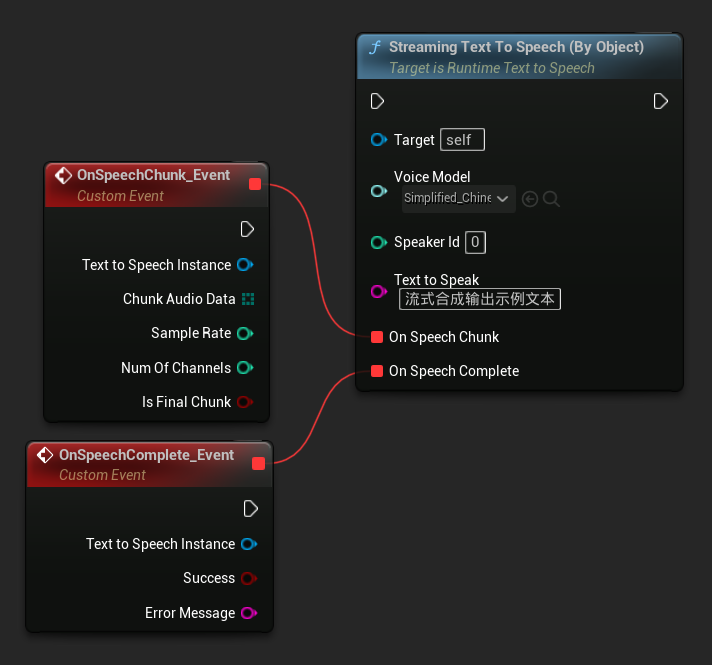
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Phát lại Âm thanh
- Phát lại Thông thường
- Phát lại trực tuyến
Đối với tính năng chuyển văn bản thành giọng nói thông thường (không phát trực tuyến), delegate On Speech Result cung cấp âm thanh đã tổng hợp dưới dạng dữ liệu PCM ở định dạng float (dưới dạng mảng byte trong Blueprint hoặc TArray<uint8> trong C++), cùng với Sample Rate và Num Of Channels.
Để phát lại, bạn nên sử dụng plugin Runtime Audio Importer để chuyển đổi dữ liệu âm thanh thô thành sóng âm thanh có thể phát được.
- Blueprint
- C++
Dưới đây là ví dụ về cách các node Blueprint để tổng hợp văn bản và phát âm thanh có thể trông như thế nào (Các node có thể sao chép):
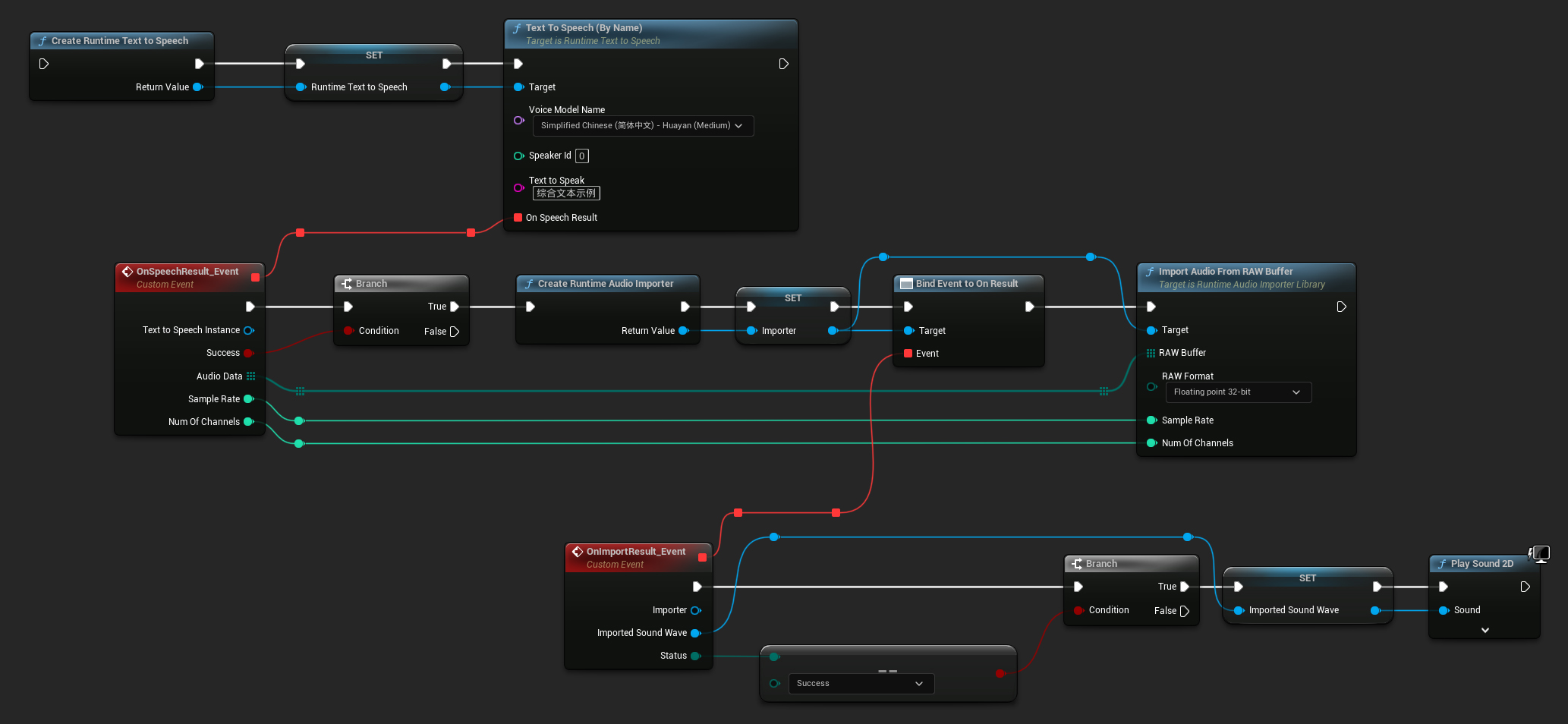
Dưới đây là ví dụ về cách tổng hợp văn bản và phát âm thanh trong C++:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Đối với tính năng chuyển văn bản thành giọng nói trực tuyến, bạn sẽ nhận được dữ liệu âm thanh theo từng khối dưới dạng dữ liệu PCM ở định dạng float (dưới dạng mảng byte trong Blueprints hoặc TArray<uint8> trong C++), cùng với Tần số mẫu và Số kênh. Mỗi khối có thể được xử lý ngay lập tức khi có sẵn.
Để phát lại theo thời gian thực, bạn nên sử dụng plugin Runtime Audio Importer Streaming Sound Wave, được thiết kế đặc biệt cho việc phát lại âm thanh trực tuyến hoặc xử lý thời gian thực.
- Blueprint
- C++
Dưới đây là ví dụ về cách các nút Blueprint cho tính năng chuyển văn bản thành giọng nói trực tuyến và phát âm thanh có thể trông như thế nào (Các nút có thể sao chép):
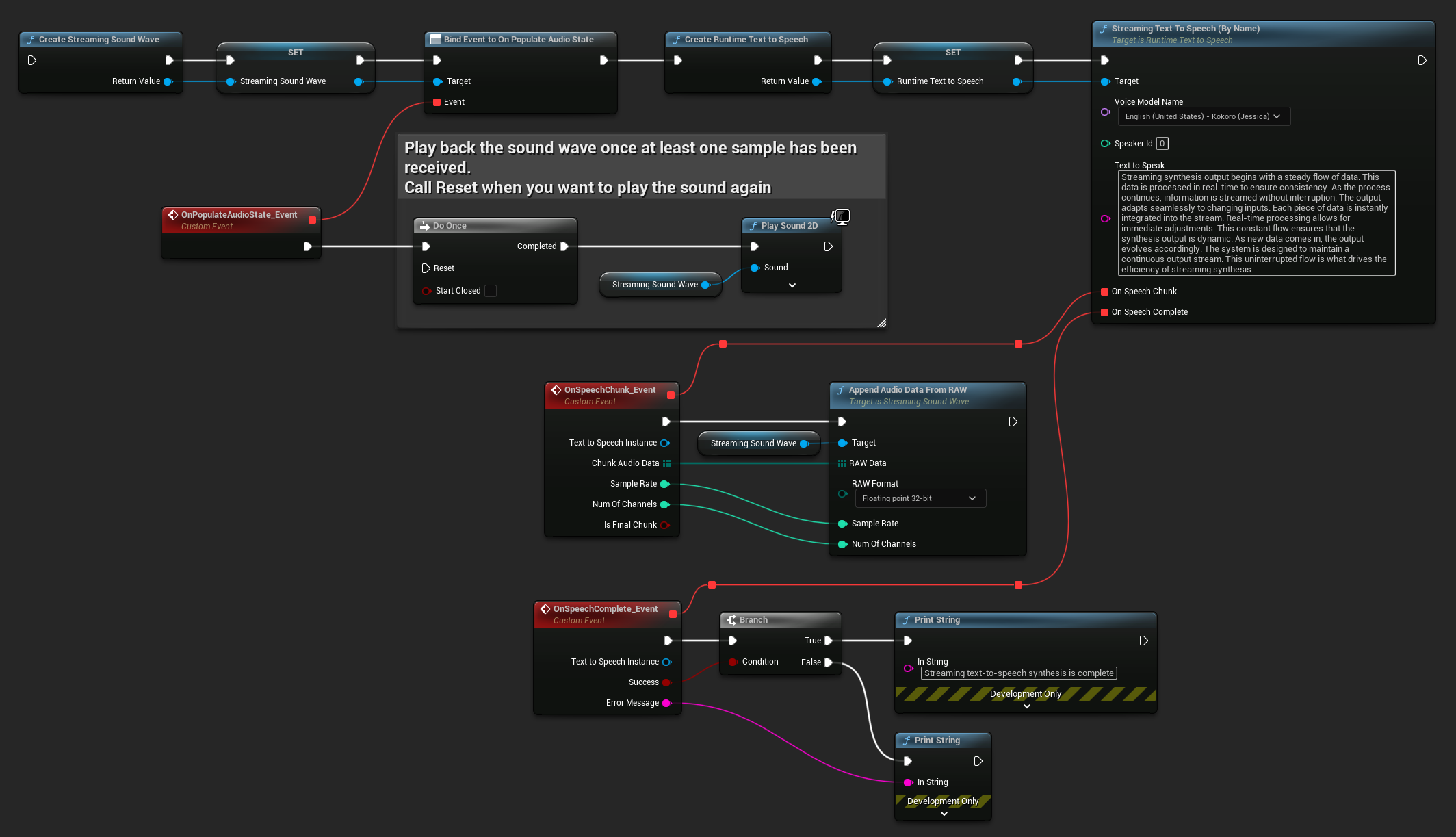
Dưới đây là ví dụ về cách triển khai tính năng chuyển văn bản thành giọng nói trực tuyến với phát lại thời gian thực trong C++:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Hủy Tổng Hợp Văn Bản Thành Giọng Nói
Bạn có thể hủy một thao tác tổng hợp văn bản thành giọng nói đang diễn ra bất kỳ lúc nào bằng cách gọi hàm CancelSpeechSynthesis trên phiên bản bộ tổng hợp của bạn:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Khi một quá trình tổng hợp bị hủy bỏ:
- Quá trình tổng hợp sẽ dừng lại nhanh nhất có thể
- Mọi callback đang diễn ra sẽ bị chấm dứt
- Delegate hoàn thành sẽ được gọi với
bSuccess = falsevà một thông báo lỗi cho biết quá trình tổng hợp đã bị hủy - Mọi tài nguyên được cấp phát cho quá trình tổng hợp sẽ được dọn dẹp đúng cách
Điều này đặc biệt hữu ích cho các văn bản dài hoặc khi bạn cần ngắt phát lại để bắt đầu một quá trình tổng hợp mới.
Lựa Chọn Diễn Giả
Cả hai hàm Text To Speech đều chấp nhận một tham số ID diễn giả tùy chọn, điều này hữu ích khi làm việc với các mô hình giọng nói hỗ trợ nhiều diễn giả. Bạn có thể sử dụng các hàm GetSpeakerCountFromVoiceModel hoặc GetSpeakerCountFromModelName để kiểm tra xem mô hình giọng nói bạn chọn có hỗ trợ nhiều diễn giả hay không. Nếu có nhiều diễn giả khả dụng, chỉ cần chỉ định ID diễn giả mong muốn khi gọi các hàm Text To Speech. Một số mô hình giọng nói cung cấp sự đa dạng phong phú - ví dụ, English LibriTTS bao gồm hơn 900 diễn giả khác nhau để bạn lựa chọn.
Plugin Runtime Audio Importer cũng cung cấp các tính năng bổ sung như xuất dữ liệu âm thanh ra tệp, chuyển nó đến SoundCue, MetaSound, và hơn thế nữa. Để biết thêm chi tiết, hãy xem tài liệu Runtime Audio Importer.