翻译提供商
AI Localization Automator 支持五种不同的 AI 提供商,每种都有其独特的优势和配置选项。请根据项目的需求、预算和质量要求选择最合适的提供商。
Ollama (本地 AI)
最适合:注重隐私的项目、离线翻译、无限使用
Ollama 在您的本地机器上运行 AI 模型,提供完全的隐私和控制,无需 API 成本或互联网连接。
热门模型
- translategemma:12b (基于 Gemma 3 的专用翻译模型)
- llama3.2 (推荐通用模型)
- mistral (高效替代方案)
- codellama (具备代码意识的翻译)
- 以及更多社区模型
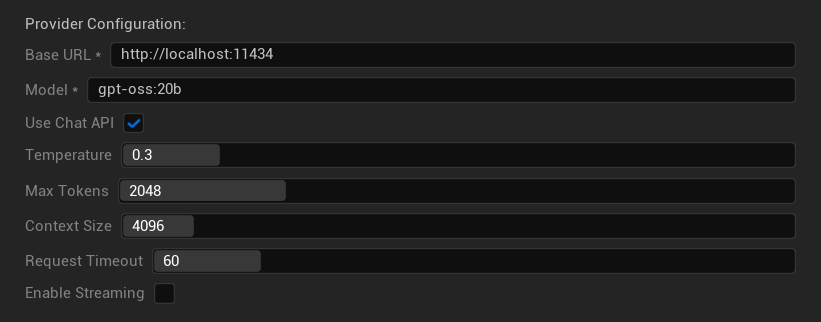
配置选项
- 基础 URL:本地 Ollama 服务器 (默认:
http://localhost:11434) - 模型:本地已安装模型的名称 (必需)
- 使用聊天 API:启用以获得更好的对话处理能力
- 温度:0.0-2.0 (推荐 0.3)
- 最大令牌数:1-8,192 个令牌
- 上下文大小:512-32,768 个令牌
- 请求超时:10-300 秒 (本地模型可能较慢)
- 启用流式传输:用于实时响应处理
优势
- ✅ 完全隐私 (数据不会离开您的机器)
- ✅ 无 API 成本或使用限制
- ✅ 可离线工作
- ✅ 完全控制模型参数
- ✅ 种类繁多的社区模型
- ✅ 无供应商锁定
注意事项
- 💻 需要本地设置和足够的硬件能力
- ⚡ 通常比云提供商慢
- 🔧 需要更多技术设置
- 📊 翻译质量因模型而异 (有些可能超过云提供商)
- 💾 模型需要大量存储空间
设置 Ollama
- 安装 Ollama:从 ollama.ai 下载并安装到您的系统
- 下载模型:使用
ollama pull translategemma:12b下载您选择的模型 - 启动服务器:Ollama 会自动运行,或使用
ollama serve启动 - 配置插件:在插件设置中设置基础 URL 和模型名称
- 测试连接:应用配置时,插件将验证连接性
OpenAI
最适合:最高的整体翻译质量、广泛的模型选择
OpenAI 通过其 Chat Completions API 提供行业领先的语言模型,包括最新的 GPT 模型、推理模型和具备网络搜索功能的模型。
可用模型
GPT-5 系列 (旗舰模型)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
GPT-4.1 系列 (高性能)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
GPT-4o 系列 (多模态)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O 系列 (推理模型 — 不支持温度/top_p 参数)
- o1, o1-pro, o3, o3-mini, o4-mini
网络搜索模型 (不支持温度/top_p 参数)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
旧版 / 预览版
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
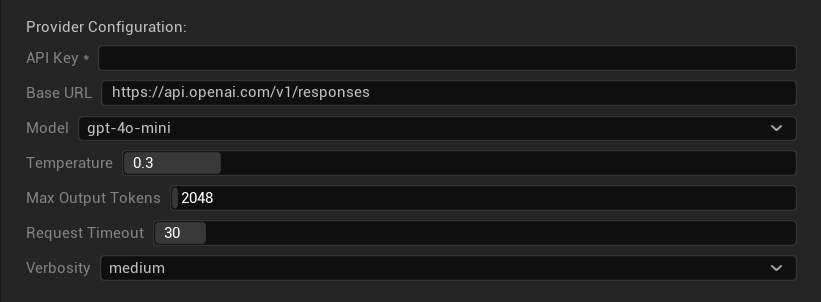
配置选项
- API 密钥:您的 OpenAI API 密钥 (必需)
- 基础 URL:API 端点 (默认:
https://api.openai.com/v1/chat/completions) - 模型:从上述可用模型中选择
- 使用温度:切换温度参数的开/关 (对于 o 系列推理和网络搜索模型会自动忽略)
- 温度:0.0–2.0 (推荐 0.3 以获得一致的翻译)
- Top P:0.0–1.0 核心采样参数 (对于 o 系列推理和网络搜索模型会被忽略)
- 最大完成令牌数:1–128,000 个令牌 (包括输出和推理令牌)
- 请求超时:5–300 秒
优势
- ✅ 持续高质量的翻译
- ✅ 出色的上下文理解能力
- ✅ 强大的格式保留能力
- ✅ 广泛的语言支持
- ✅ 可靠的 API 正常运行时间
注意事项
- 💰 每次请求成本较高
- 🌐 需要互联网连接
- ⏱️ 基于套餐的使用限制
Anthropic Claude
最适合:细微差别的翻译、创意内容、注重安全性的应用
Claude 模型擅长理解上下文和细微差别,使其成为叙事性强的游戏和复杂本地化场景的理想选择。
可用模型
Claude 4.6 系列 (最新)
- claude-opus-4-6, claude-sonnet-4-6
Claude 4.5 系列
- claude-haiku-4-5 (快速高效)
- claude-sonnet-4-5, claude-opus-4-5
Claude 4.x 系列
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Claude 3.x 系列 (旧版)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
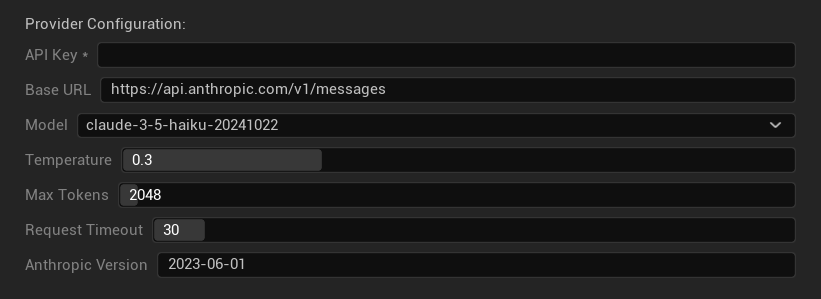
配置选项
- API 密钥:您的 Anthropic API 密钥 (必需)
- 基础 URL:Claude API 端点
- 模型:从 Claude 模型系列中选择
- 温度:0.0–1.0 (推荐 0.3)
- Top K:Top-K 采样参数 (0 = 未设置)
- 最大令牌数:1–64,000 个令牌
- 请求超时:5–300 秒
- Anthropic 版本:API 版本标头
优势
- ✅ 卓越的上下文感知能力
- ✅ 非常适合创意/叙事内容
- ✅ 强大的安全功能
- ✅ 详细的推理能力 (3.7+ 模型支持扩展思考)
- ✅ 出色的指令遵循能力
注意事项
- 💰 高级定价模式
- 🌐 需要互联网连接
- 📏 令牌限制因模型而异
DeepSeek
最适合:经济高效的翻译、高吞吐量、注重预算的项目
DeepSeek 以远低于其他提供商的成本提供有竞争力的翻译质量,使其成为大规模本地化项目的理想选择。
可用模型
- deepseek-chat (通用,推荐)
- deepseek-reasoner (增强的推理能力)
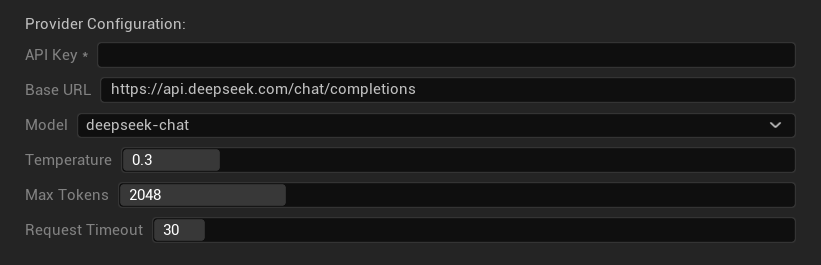
配置选项
- API 密钥:您的 DeepSeek API 密钥 (必需)
- 基础 URL:DeepSeek API 端点
- 模型:在聊天和推理器模型之间选择
- 温度:0.0-2.0 (推荐 0.3)
- 最大令牌数:1-8,192 个令牌
- 请求超时:5-300 秒
优势
- ✅ 非常经济高效
- ✅ 良好的翻译质量
- ✅ 快速的响应时间
- ✅ 配置简单
- ✅ 高频率限制
注意事项
- 📏 令牌限制较低
- 🆕 较新的提供商 (记录较少)
- 🌐 需要互联网连接
Google Gemini
最适合:多语言项目、经济高效的翻译、Google 生态系统集成
Gemini 模型提供强大的多语言能力、有竞争力的定价以及独特的功能,如用于增强推理的思考模式。
可用模型
Gemini 3.x 系列 (预览版)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Gemini 2.5 系列 (支持思考)
- gemini-2.5-pro (支持思考的旗舰版)
- gemini-2.5-flash (快速,支持思考)
- gemini-2.5-flash-lite (轻量级变体)
Gemini 2.0 系列
- gemini-2.0-flash, gemini-2.0-flash-lite
最新别名
- gemini-flash-latest, gemini-flash-lite-latest
配置选项
- API 密钥:您的 Google AI API 密钥 (必需)
- 基础 URL:Gemini API 端点
- 模型:从 Gemini 模型系列中选择
- 温度:0.0–2.0 (推荐 0.3)
- 最大输出令牌数:1–8,192 个令牌
- 请求超时:5–300 秒
- 启用思考:为 2.5+ 模型激活增强推理
- 思考预算:控制思考令牌分配 (0 = 无思考)
优势
- ✅ 强大的多语言支持
- ✅ 有竞争力的定价
- ✅ 高级推理 (思考模式)
- ✅ Google 生态系统集成
- ✅ 定期模型更新,可预览访问最新模型
注意事项
- 🧠 思考模式会增加令牌使用量
- 📏 令牌限制因模型而异
- 🌐 需要互联网连接
选择正确的提供商
| 提供商 | 最适合 | 质量 | 成本 | 设置 | 隐私 |
|---|---|---|---|---|---|
| Ollama | 隐私/离线 | 可变* | 免费 | 高级 | 本地 |
| OpenAI | 最高质量 | ⭐⭐⭐⭐⭐ | 💰💰💰 | 简单 | 云端 |
| Claude | 创意内容 | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | 简单 | 云端 |
| DeepSeek | 预算项目 | ⭐⭐⭐⭐ | 💰 | 简单 | 云端 |
| Gemini | 多语言 | ⭐⭐⭐⭐ | 💰 | 简单 | 云端 |
*Ollama 的质量因使用的本地模型而有显著差异 - 一些现代本地模型可以匹配甚至超过云提供商。
提供商配置技巧
对于所有云提供商:
- 安全存储 API 密钥,不要将其提交到版本控制
- 从保守的温度设置 (0.3) 开始,以获得一致的翻译
- 监控您的 API 使用情况和成本
- 在进行大规模翻译运行之前,先用小批量进行测试
对于 Ollama:
- 确保有足够的 RAM (推荐 8GB+ 用于较大模型)
- 使用 SSD 存储以获得更好的模型加载性能
- 考虑使用 GPU 加速以获得更快的推理速度
- 在依赖其进行生产翻译之前,先在本地进行测试