推理参数
LLM推理参数结构控制模型的加载和文本生成方式。您可以在加载模型时传入这些参数。本页面将逐一说明每个参数及其作用。
参数参考
| 参数 | Type | 默认 | 范围 | 描述 |
|---|---|---|---|---|
| 最大令牌数 | int32 | 512 | 1–8192 | 单次响应中生成的最大令牌数 |
| 温度 | 浮点数 | 0.7 | 0.0–2.0 | 控制随机性。0.0 = 确定性输出。数值越高,输出越具创造性。 |
| Top P | 浮点数 | 0.9 | 0.0–1.0 | 核采样。仅考虑累积概率超过此值的令牌。 |
| Top K | int32 | 40 | 0–200 | 将选择限制为概率最高的前K个词元。0 = 禁用 |
| 重复惩罚 | 浮点数 | 1.1 | 0.0–3.0 | 对输出中已出现的标记进行惩罚。1.0 = 无惩罚 |
| GPU 层数 | int32 | -1 | -1–200 | 模型层数卸载到GPU。-1 = 自动。0 = 仅CPU。 |
| 上下文大小 | int32 | 2048 | 128–131072 | 最大上下文窗口(以Token计)。数值越大,内存占用越高。 |
| 系统提示 | FString | “你是一个有用的助手。” | — | 塑造模型行为的系统指令 |
| 种子 | int32 | -1 | -1+ | 用于可重复输出的随机种子。-1 = 随机 |
| 线程数 | int32 | 0 | 0–128 | 生成所用的CPU线程数。0 = 自动 |
用法
- 蓝图
- C++
推理参数在加载节点和异步节点上显示为结构体引脚。断开结构体以设置各个值。
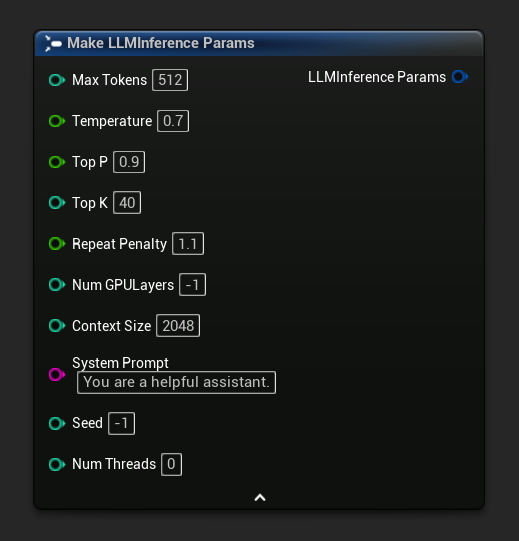
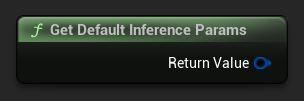
要获取一组默认参数作为起点,请使用 Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
平台推荐
移动端/VR(安卓、iOS、Meta Quest)
- 上下文大小:1024–2048
- GPU 层数:0(仅限 CPU),除非设备已确认支持 GPU 计算
- 最大令牌数:低于 256 以实现响应式交互
- 线程数:2–4,具体取决于设备
桌面端(Windows、Mac、Linux)
- 上下文大小:大多数对话为 2048–8192
- GPU 层数:-1(自动)以在可用时利用 GPU 加速
- 线程数:0(自动)
- 最大令牌数:512–2048 用于较长回复
长时间对话
如果你的应用需要维持长时间对话(如NPC对话、持久助手、角色扮演),建议将上下文大小与自动摘要功能配合使用,而非单纯增大Context Size。将Context Size保持在2048–4096的适中范围并启用自动摘要,可稳定控制延迟和内存占用,而更大的上下文窗口会导致每次生成速度逐渐变慢。详见自动上下文摘要。