音频处理指南
本指南介绍了如何设置不同的音频输入方法,将音频数据提供给唇形同步生成器。请确保在继续之前已完成设置指南。
音频输入处理
你需要设置一种处理音频输入的方法。根据你的音频源,有几种不同的实现方式。
- 麦克风(实时)
- 麦克风(播放)
- 文本转语音(本地)
- 文本转语音(外部API)
- 从音频文件/缓冲区
- 流式音频缓冲区
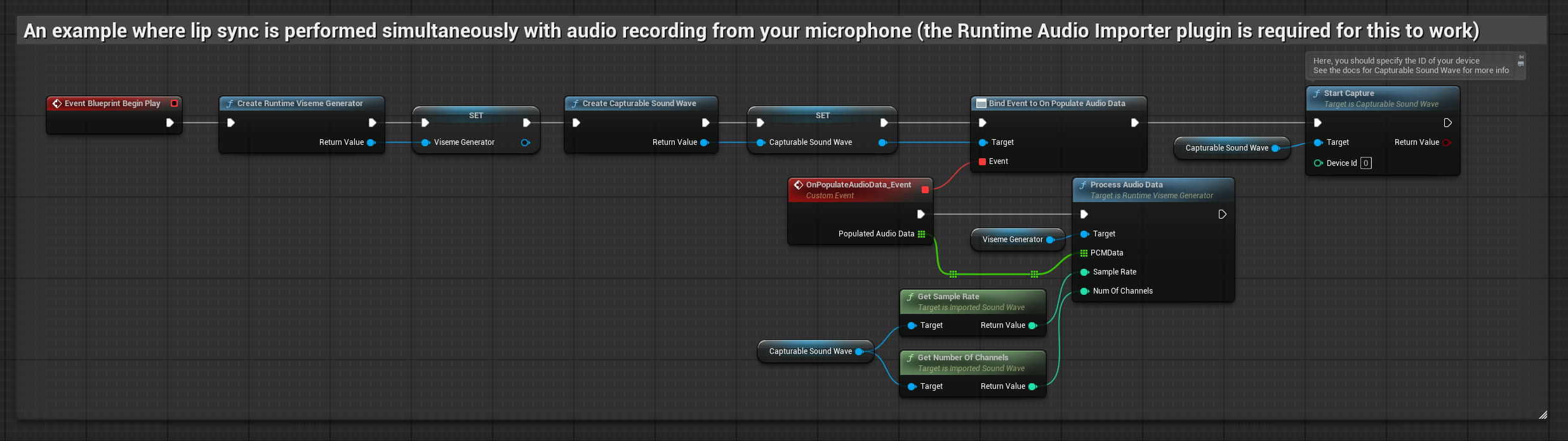
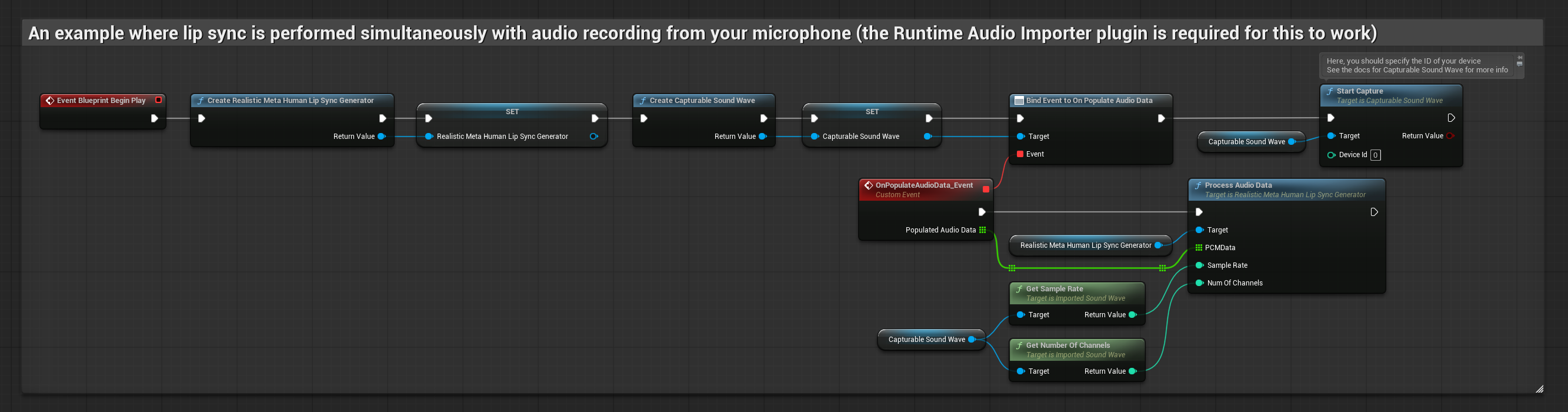
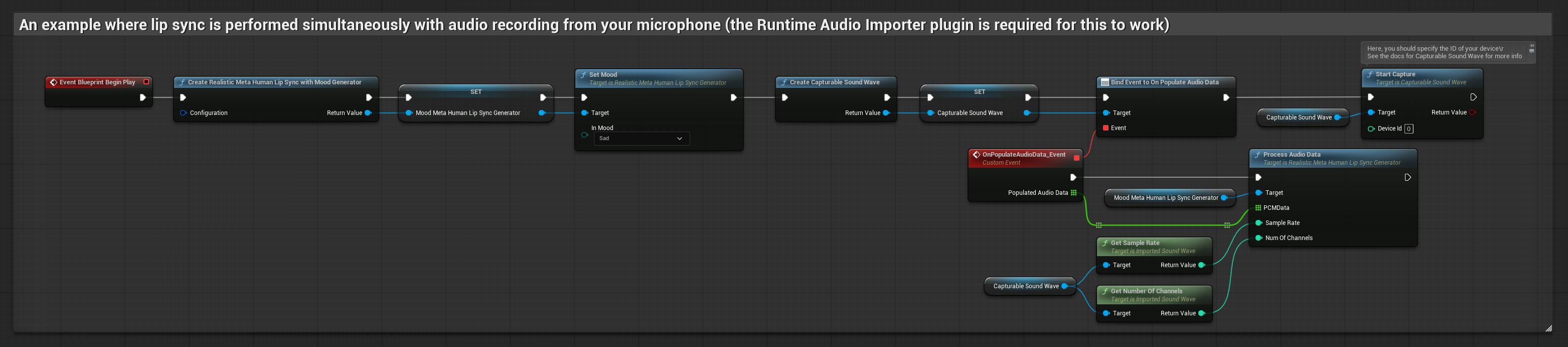
该方法可在对着麦克风说话时实时执行口型同步:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime Audio Importer 创建一个 可捕获声波
- 对于使用像素流媒体的 Linux 系统,请改用 像素流媒体可捕获声波
- 在开始捕获音频之前,绑定到
OnPopulateAudioData委托 - 在绑定的函数中,从你的运行时视位生成器调用
ProcessAudioData - 开始从麦克风捕获音频
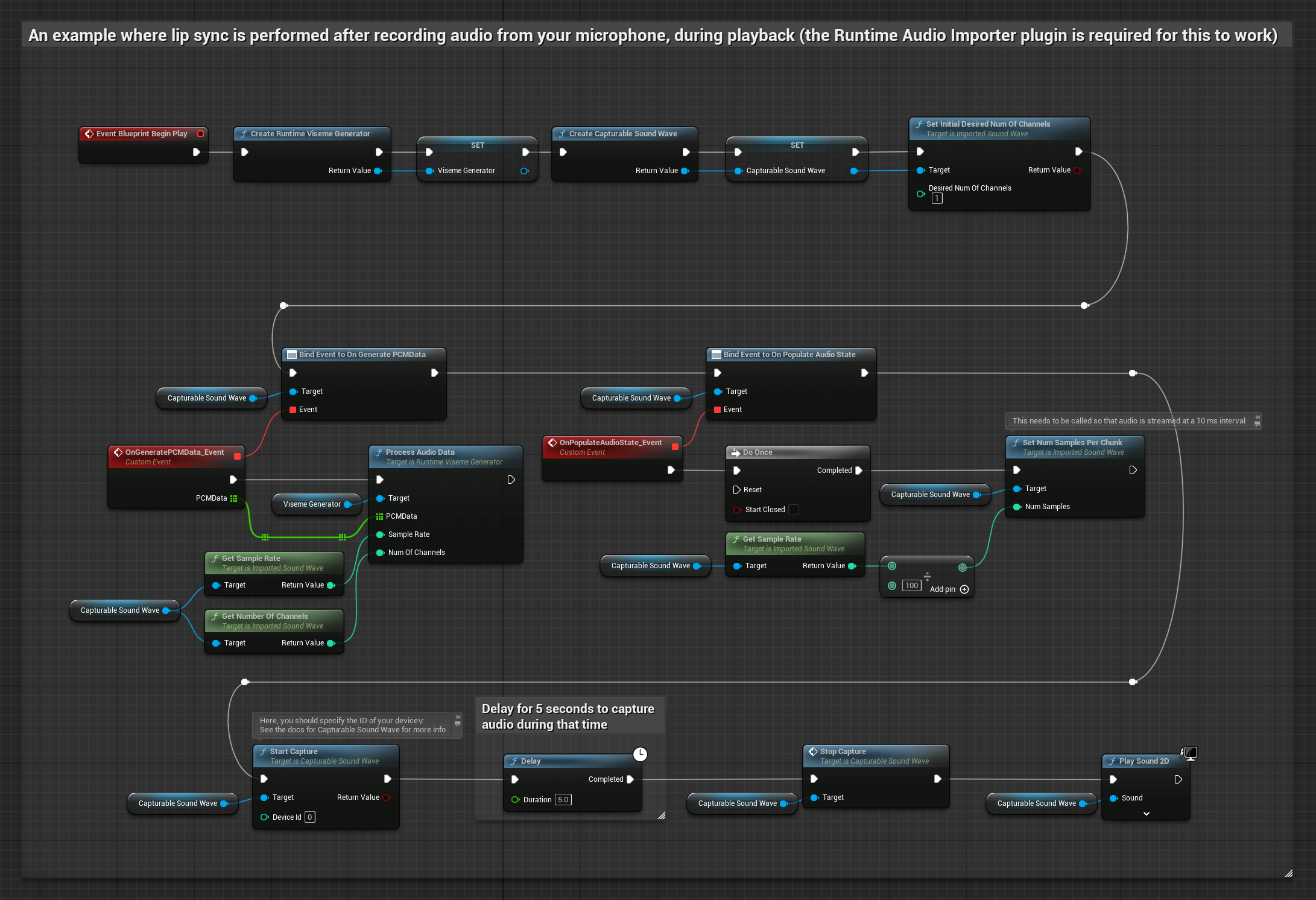
这种方法通过麦克风捕捉音频,然后配合口型同步进行回放:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime Audio Importer 创建一个 可捕获声波
- 对于使用像素流媒体的 Linux 系统,请改用 像素流媒体可捕获声波
- 从麦克风开始音频捕获
- 在播放可捕获音波之前,绑定到其
OnGeneratePCMData委托 - 在绑定的函数中,调用运行时视位生成器的
ProcessAudioData方法
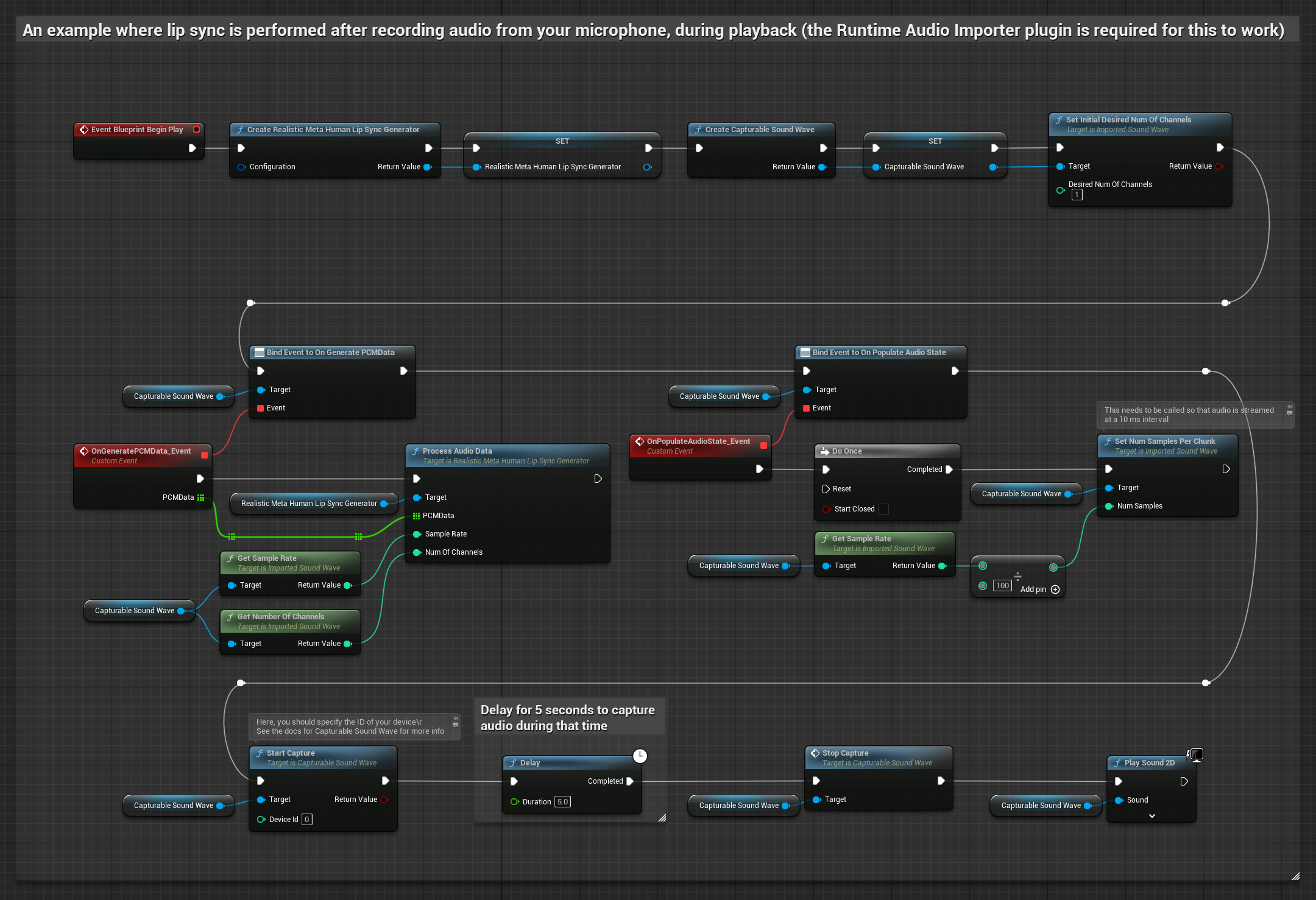
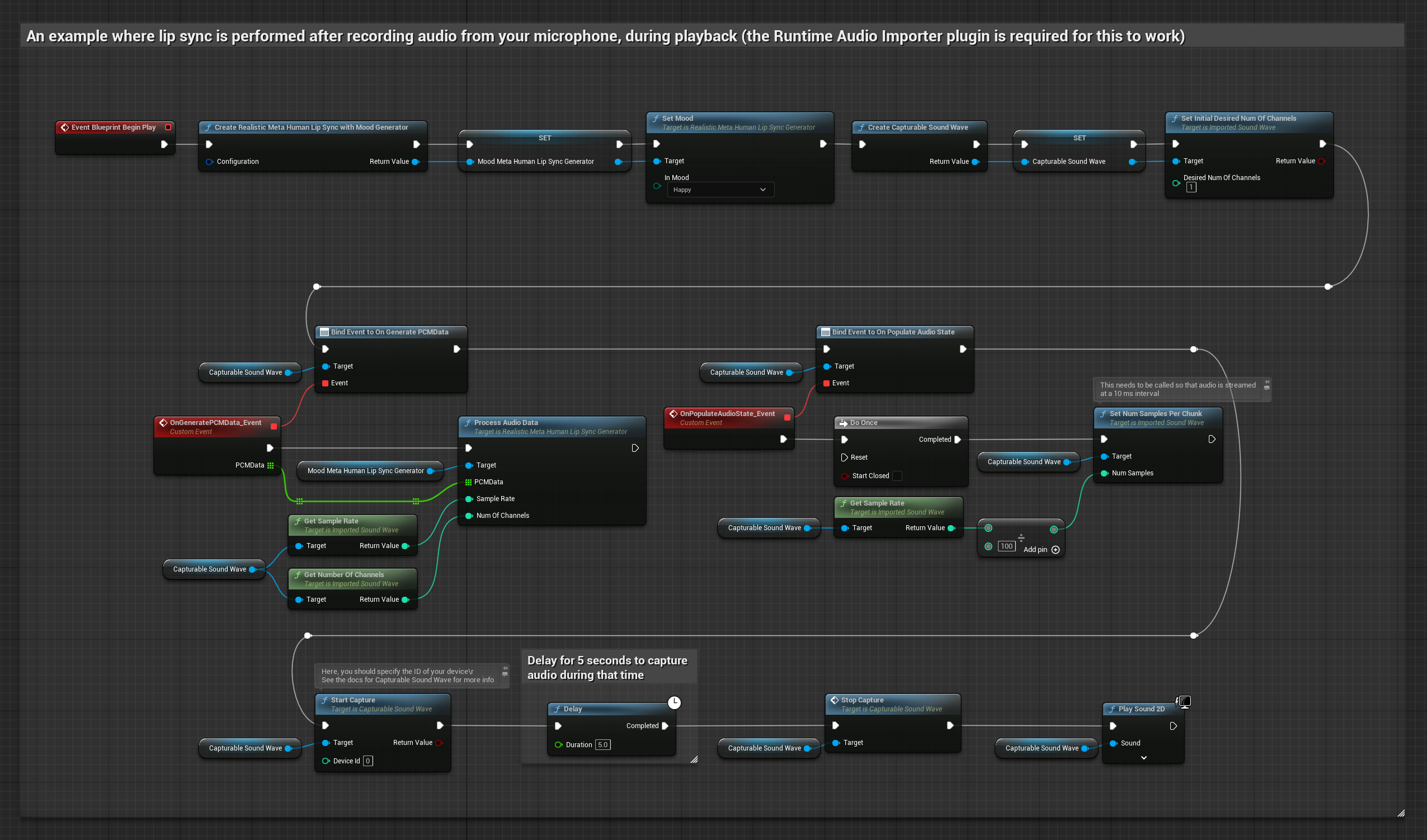
- 常规
- 流式传输
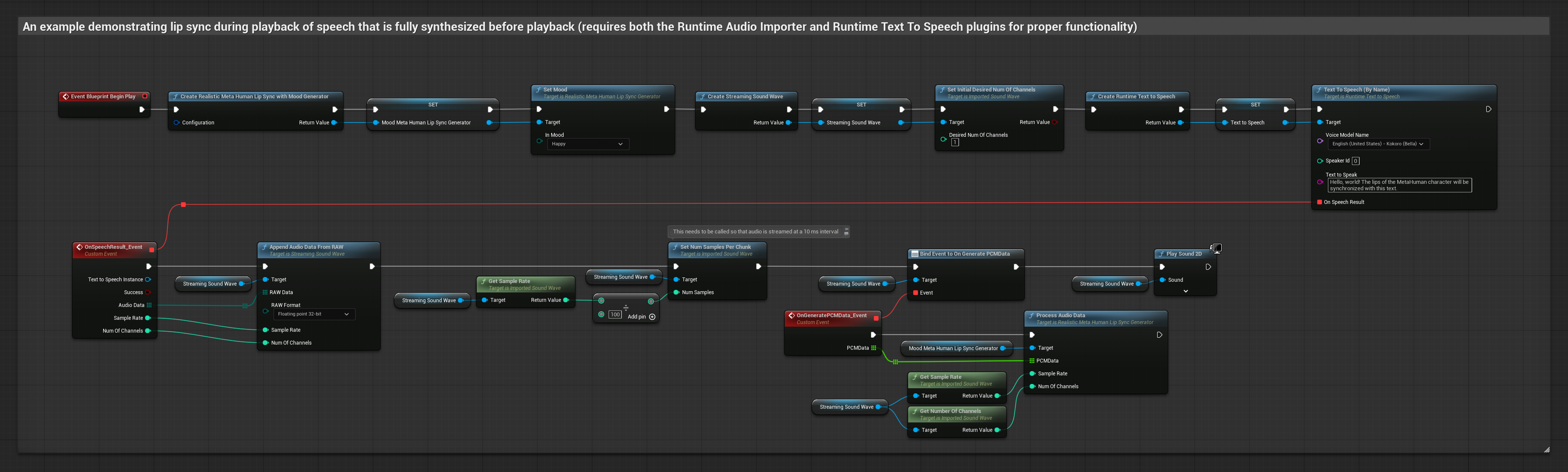
该方法利用本地TTS从文本合成语音,并执行口型同步:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime Text To Speech 从文本生成语音
- 使用 Runtime Audio Importer 导入合成的音频
- 在播放导入的声波之前,绑定到其
OnGeneratePCMData委托 - 在绑定的函数中,调用 Runtime Viseme Generator 的
ProcessAudioData方法
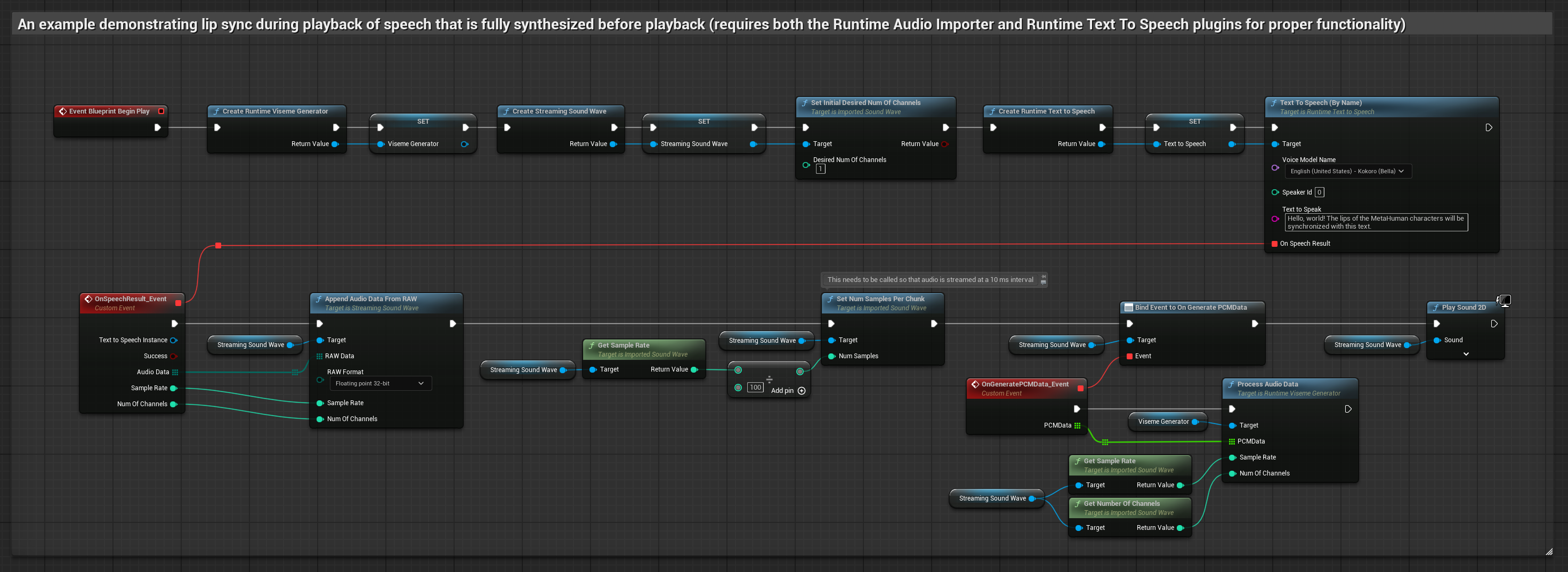
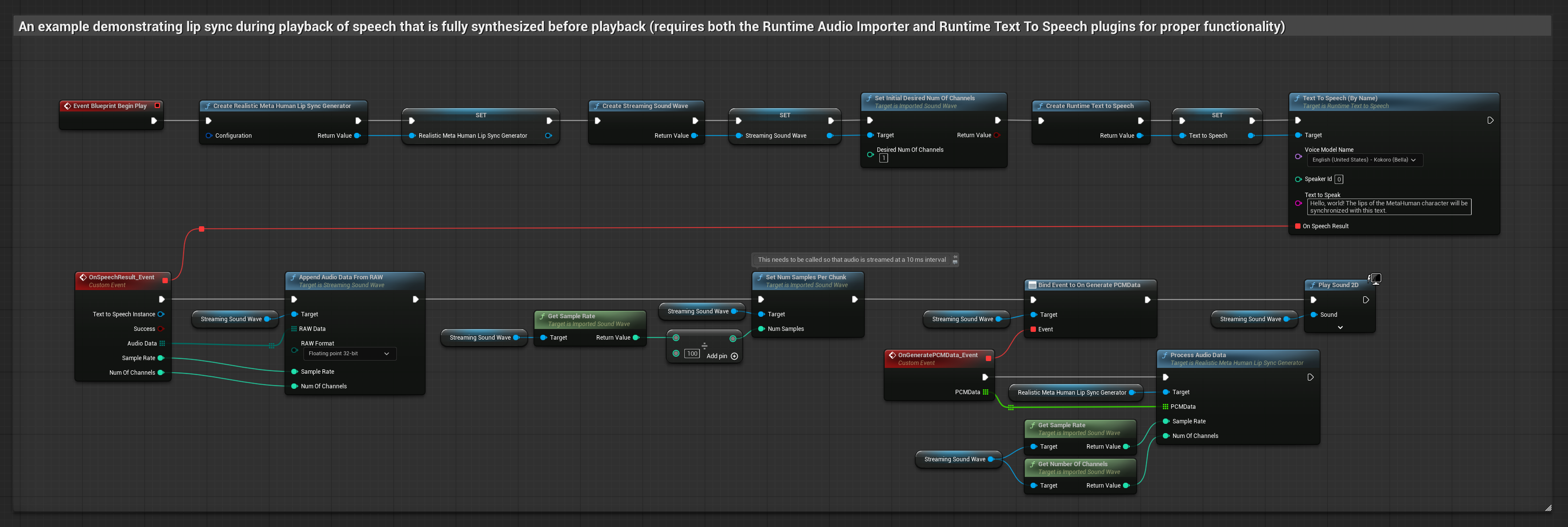
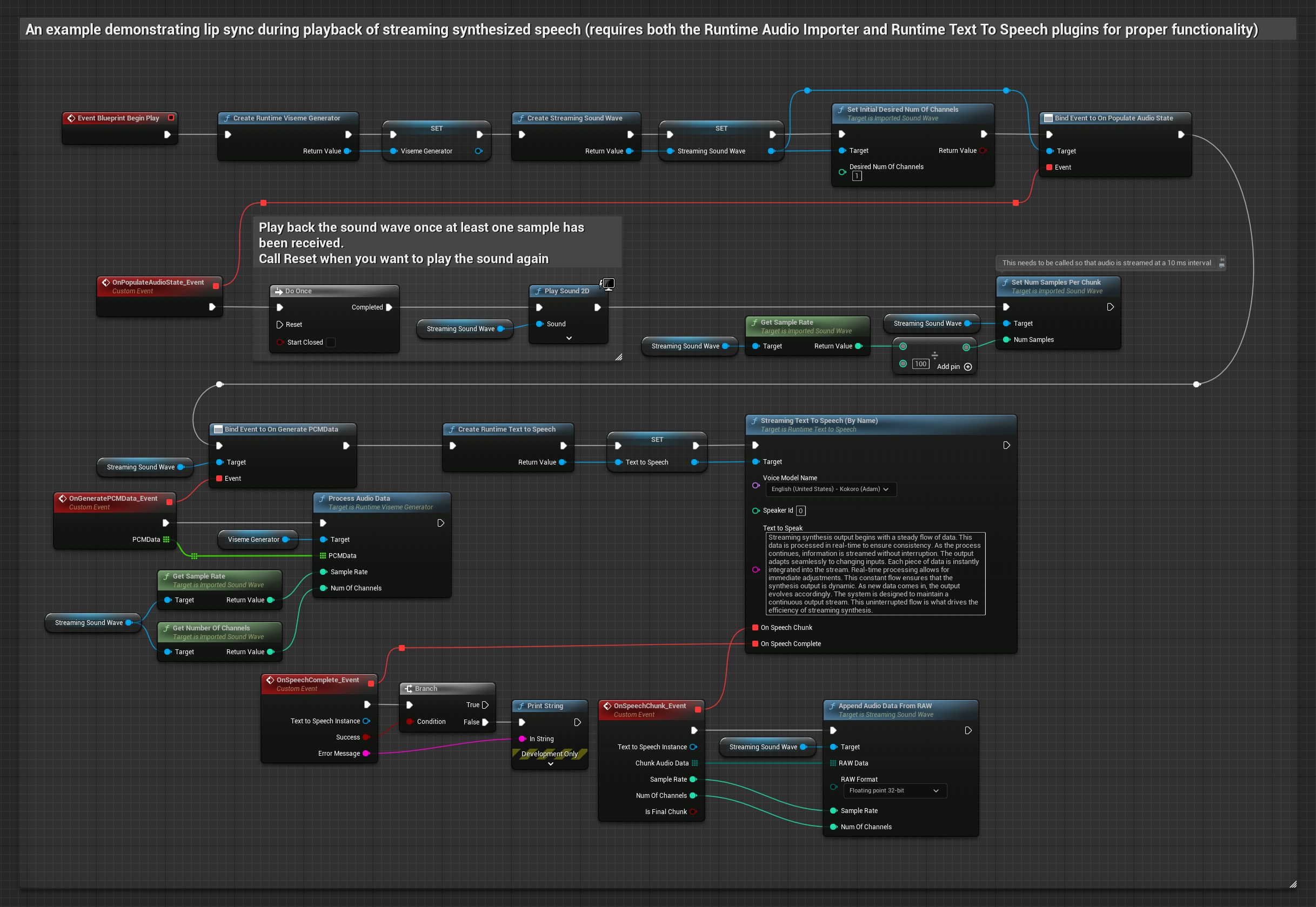
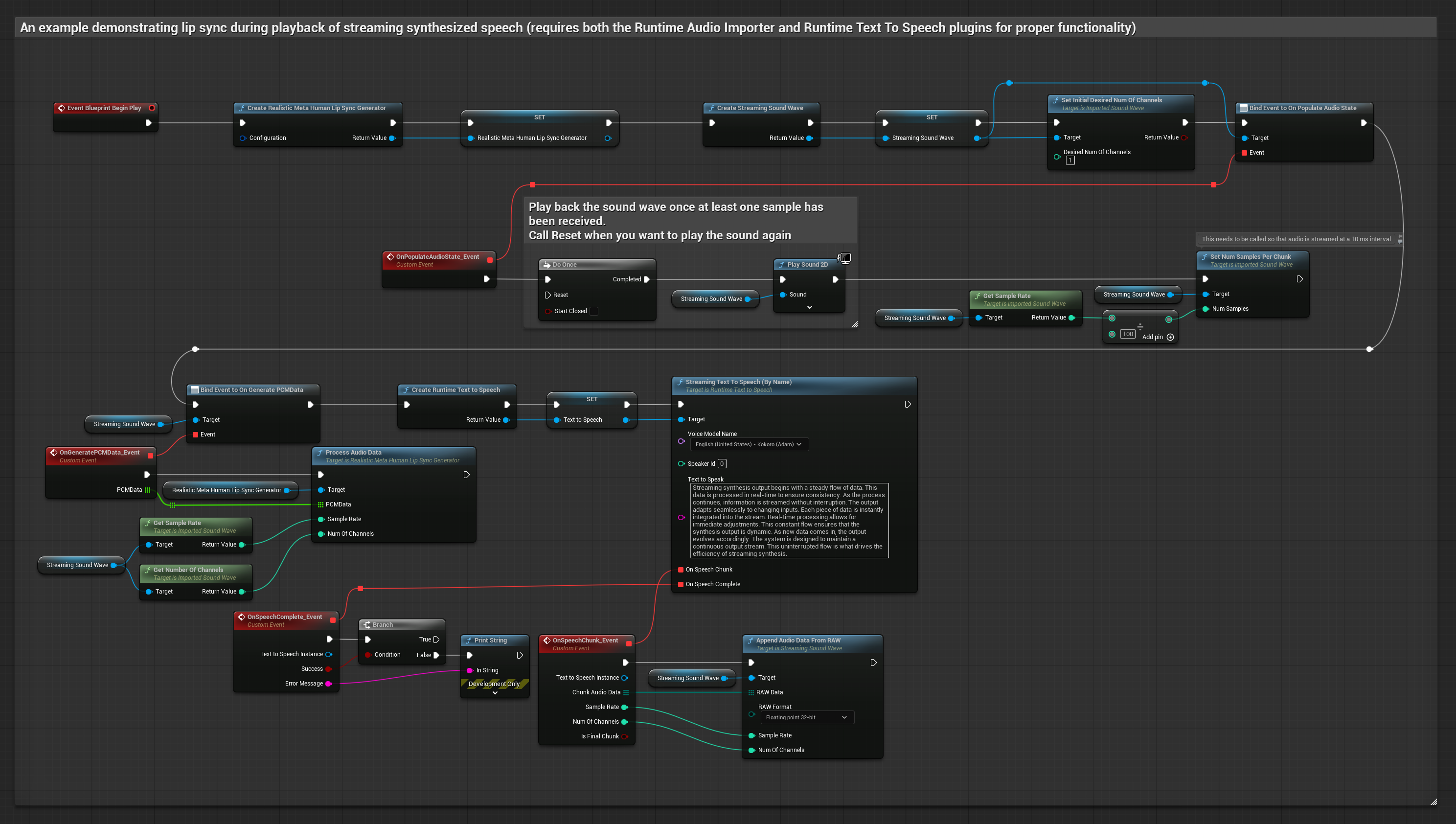
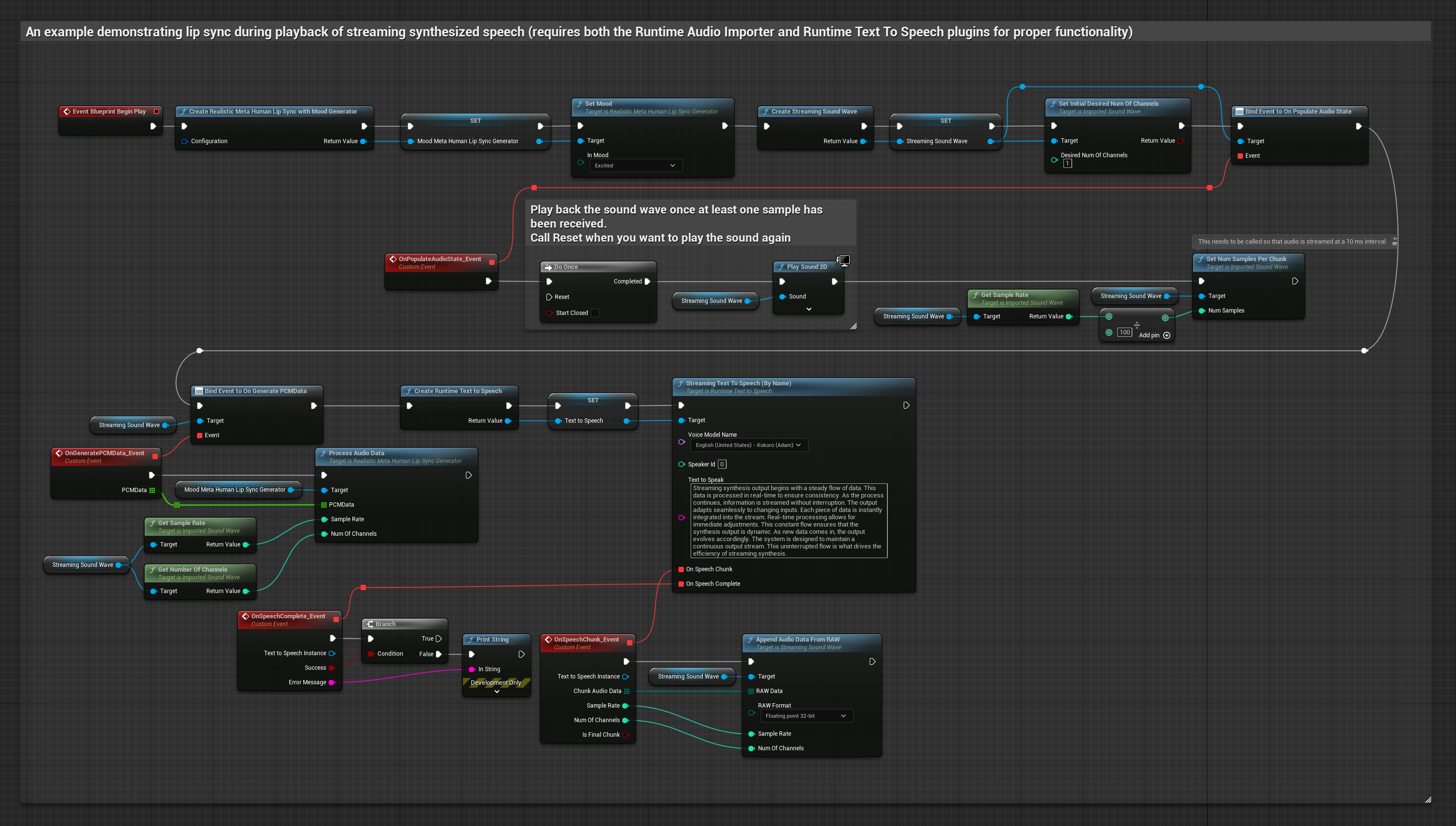
该方法采用流式文本转语音合成技术,并实时同步口型。
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime Text To Speech 从文本生成流式语音
- 使用 Runtime Audio Importer 导入合成的音频
- 在播放流式音频波形之前,绑定其
OnGeneratePCMData委托 - 在绑定的函数中,调用 Runtime Viseme Generator 的
ProcessAudioData方法
- 常规
- 流式传输
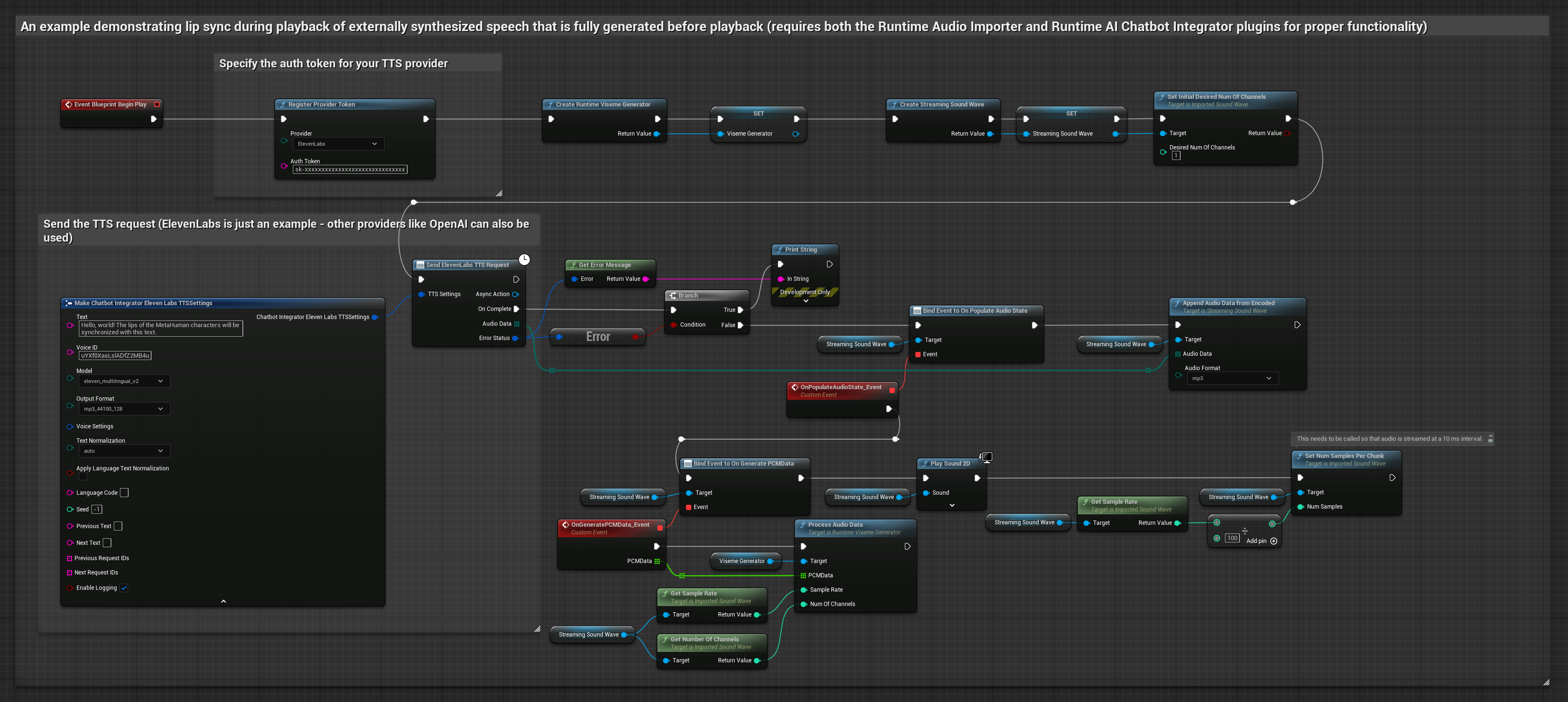
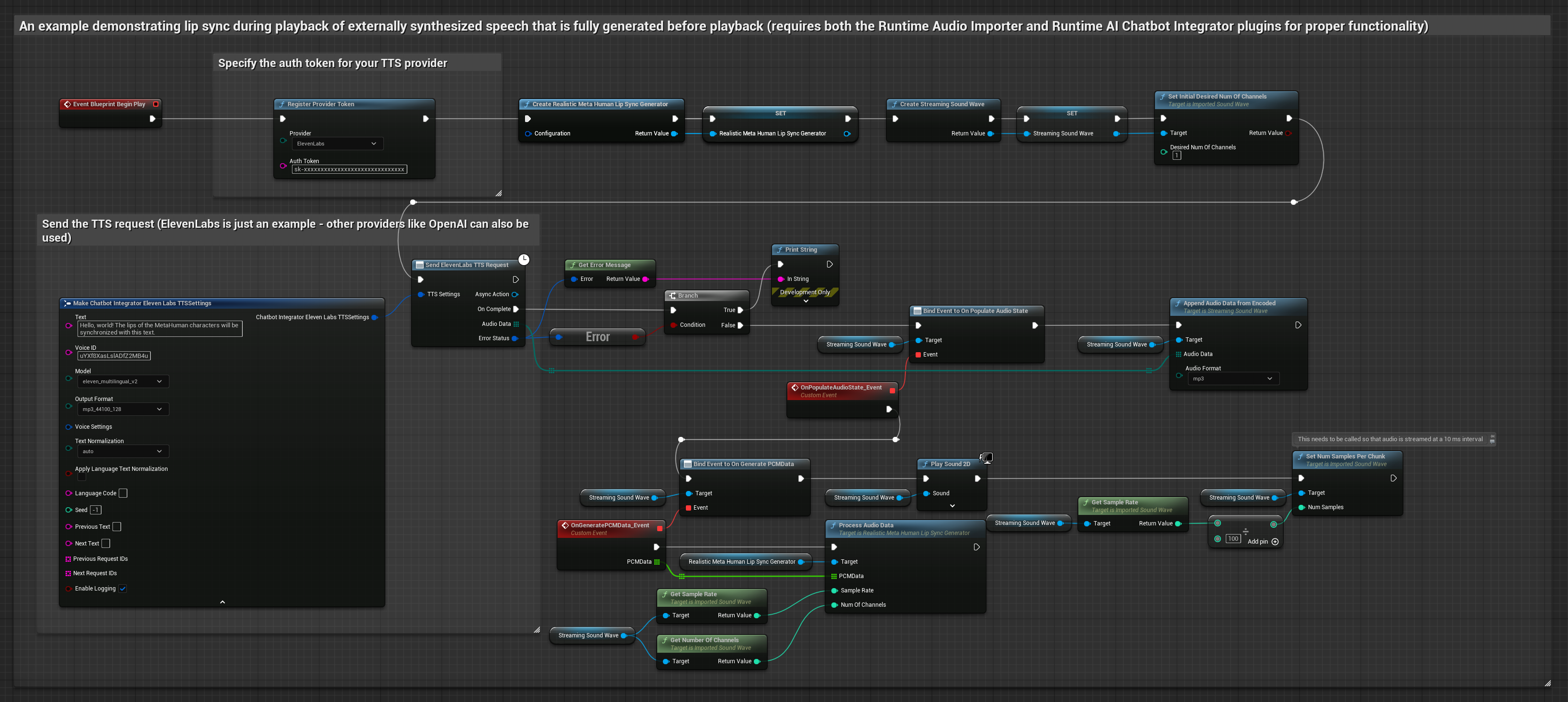
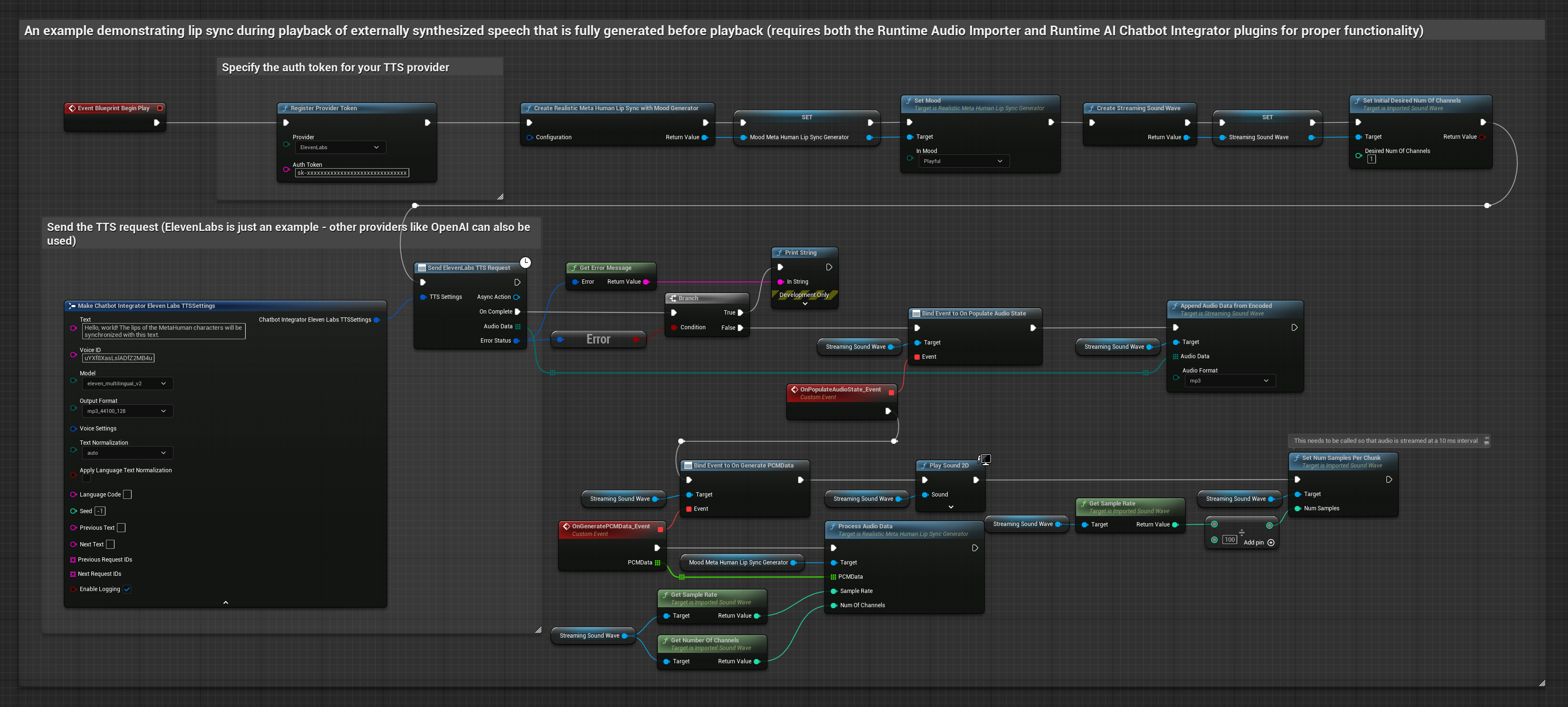
该方法使用运行时AI聊天机器人集成插件,从AI服务(OpenAI或ElevenLabs)生成合成语音并执行口型同步:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime AI Chatbot Integrator 通过外部 API(OpenAI、ElevenLabs 等)从文本生成语音
- 使用 Runtime Audio Importer 导入合成的音频数据
- 在播放导入的声波之前,绑定到其
OnGeneratePCMData委托 - 在绑定的函数中,调用 Runtime Viseme Generator 的
ProcessAudioData方法
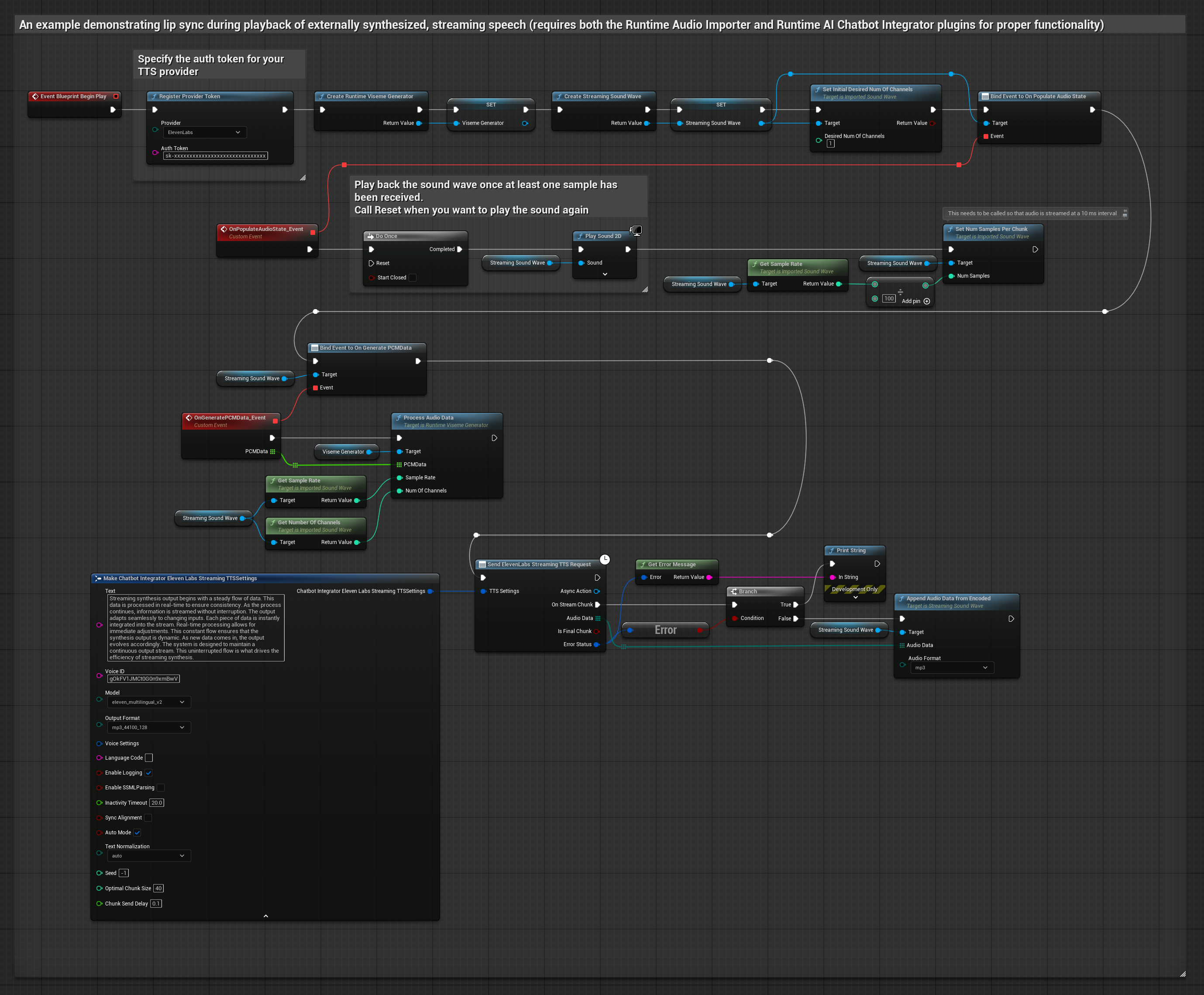
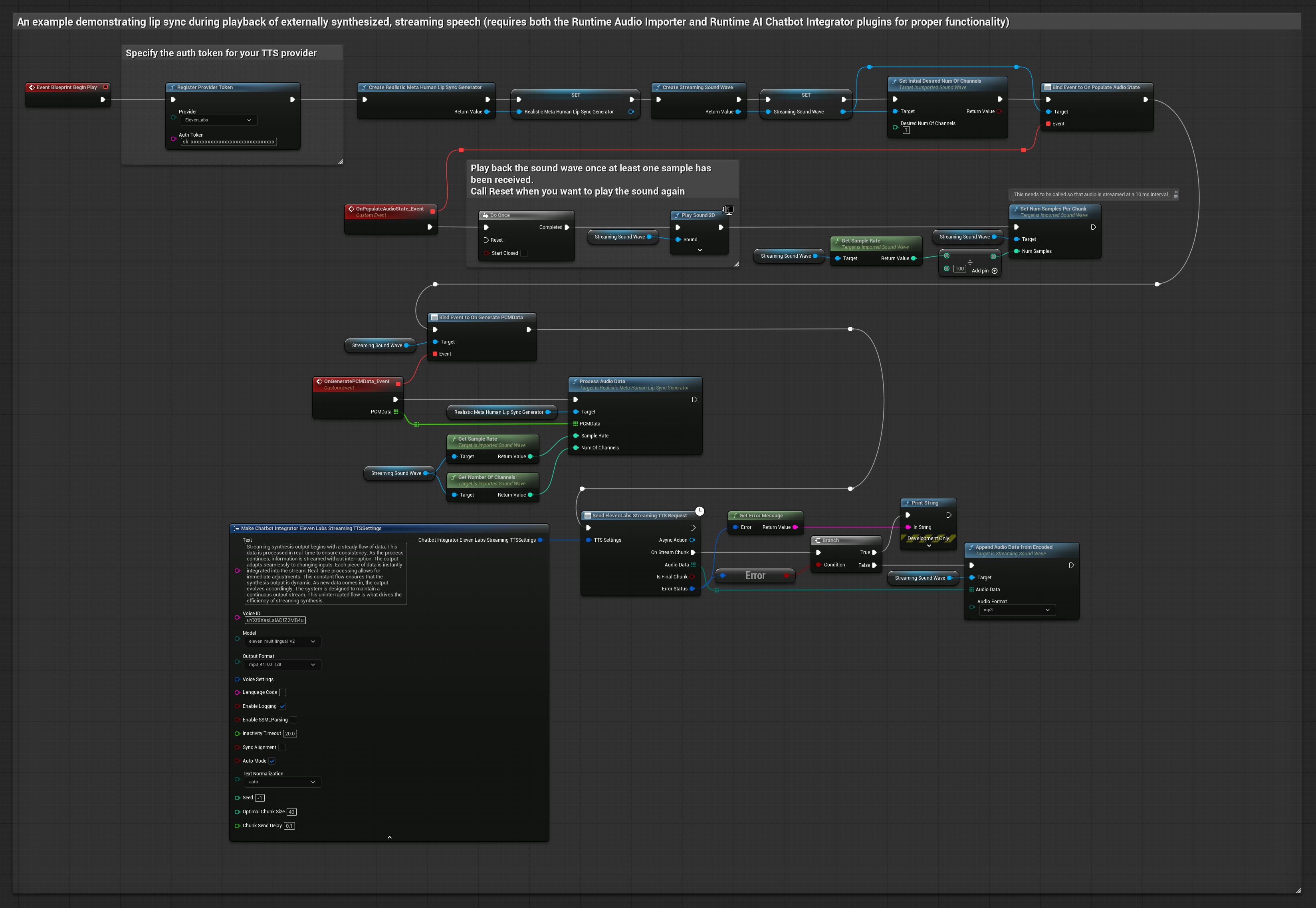
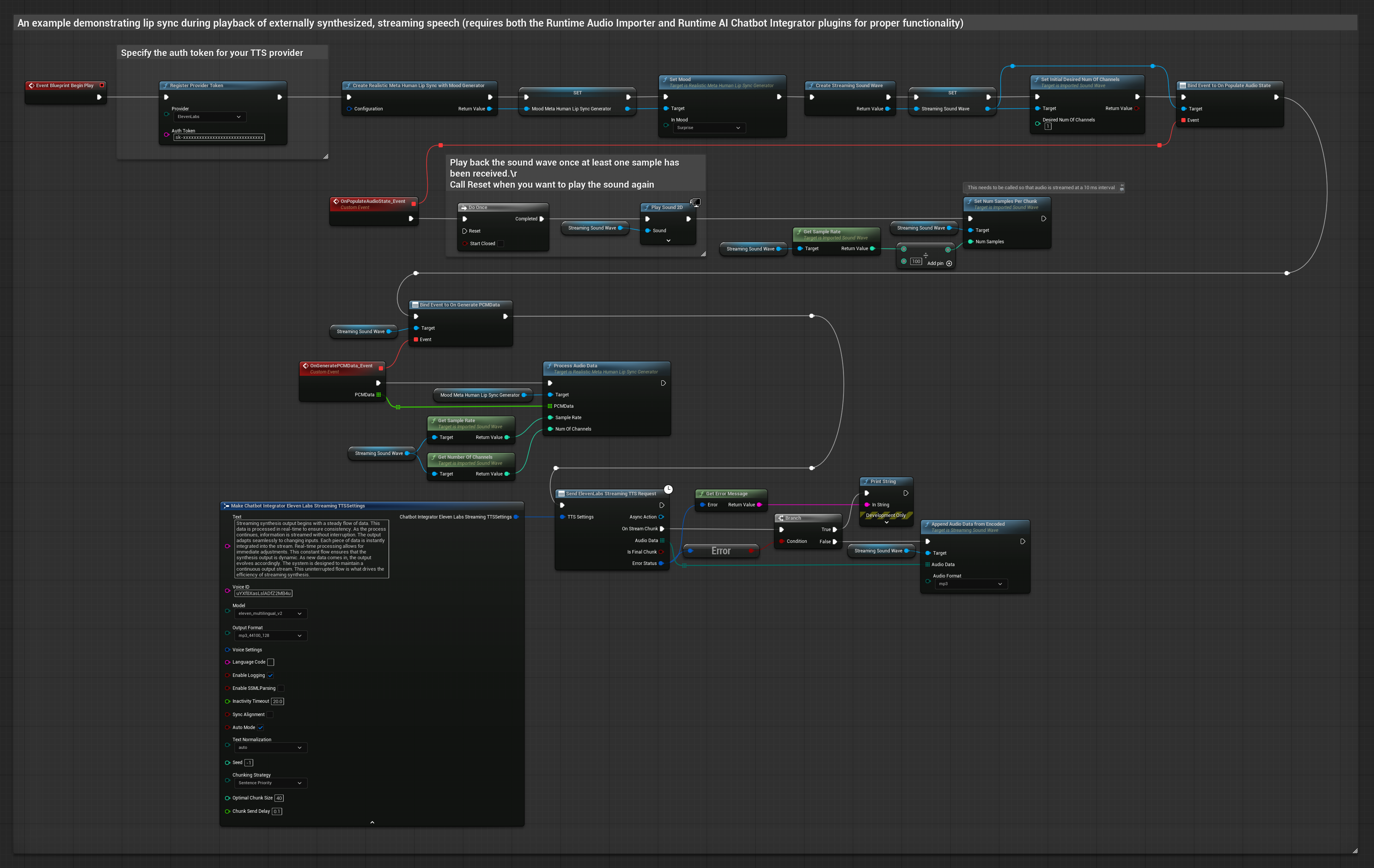
该方法利用运行时AI聊天机器人集成插件,从AI服务(OpenAI或ElevenLabs)生成合成流式语音,并执行口型同步:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime AI Chatbot Integrator 连接流式 TTS API(如 ElevenLabs 流式 API)
- 使用 Runtime Audio Importer 导入合成的音频数据
- 在播放流式音频波形前,绑定其
OnGeneratePCMData委托 - 在绑定的函数中,调用 Runtime Viseme Generator 的
ProcessAudioData方法
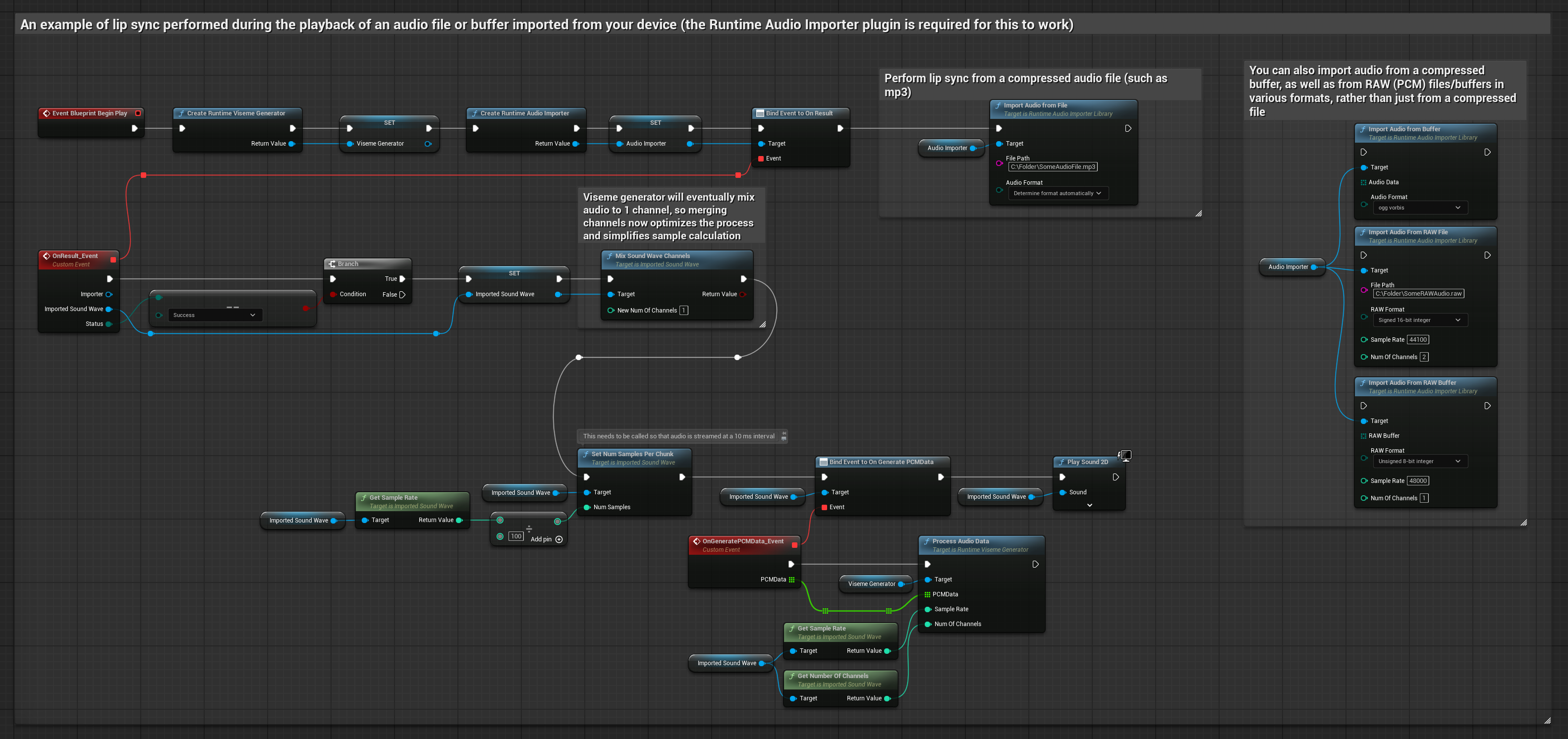
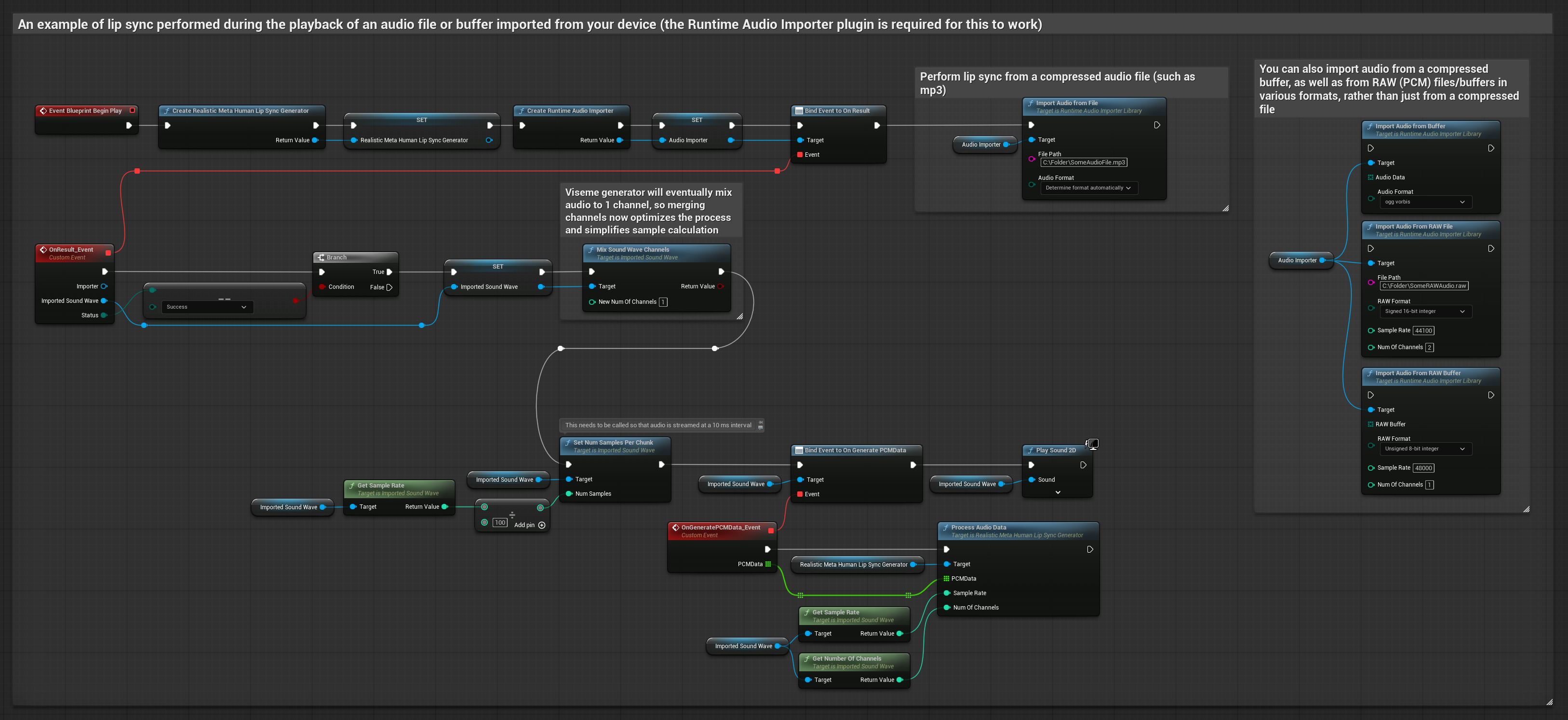
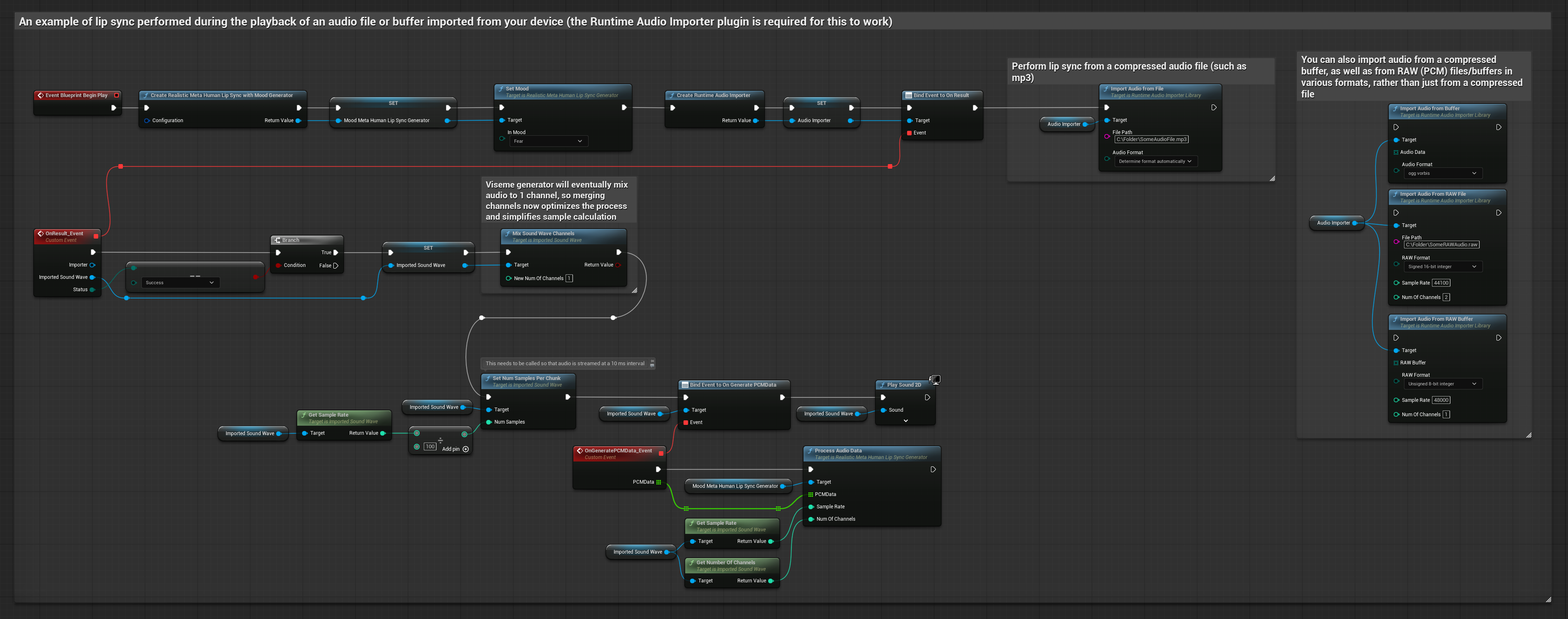
此方法使用预录制的音频文件或音频缓冲区来实现口型同步:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 使用 Runtime Audio Importer 从磁盘或内存中导入音频文件
- 在播放导入的声波之前,绑定其
OnGeneratePCMData委托 - 在绑定的函数中,调用运行时视位生成器的
ProcessAudioData方法 - 播放导入的声波并观察口型同步动画
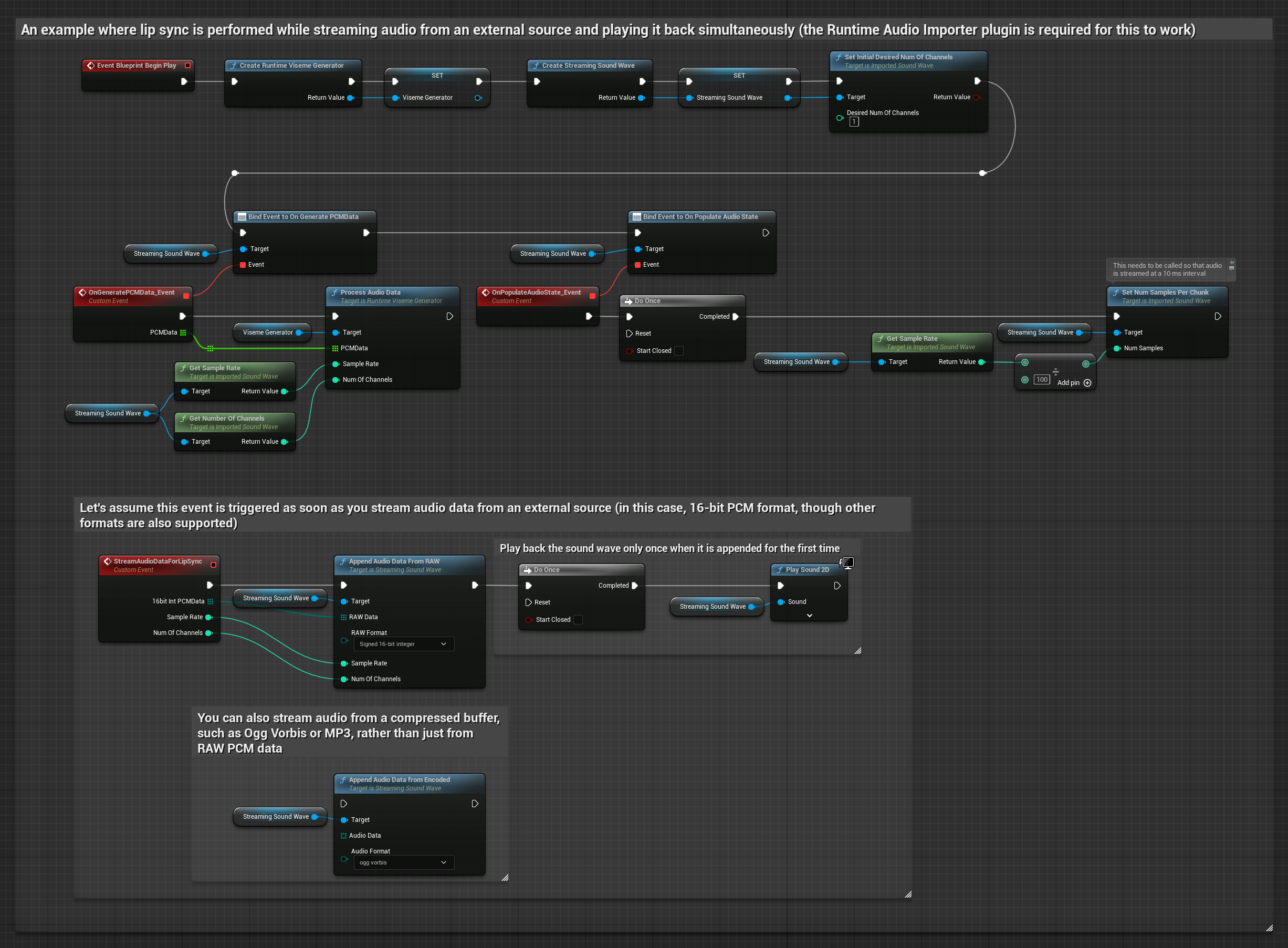
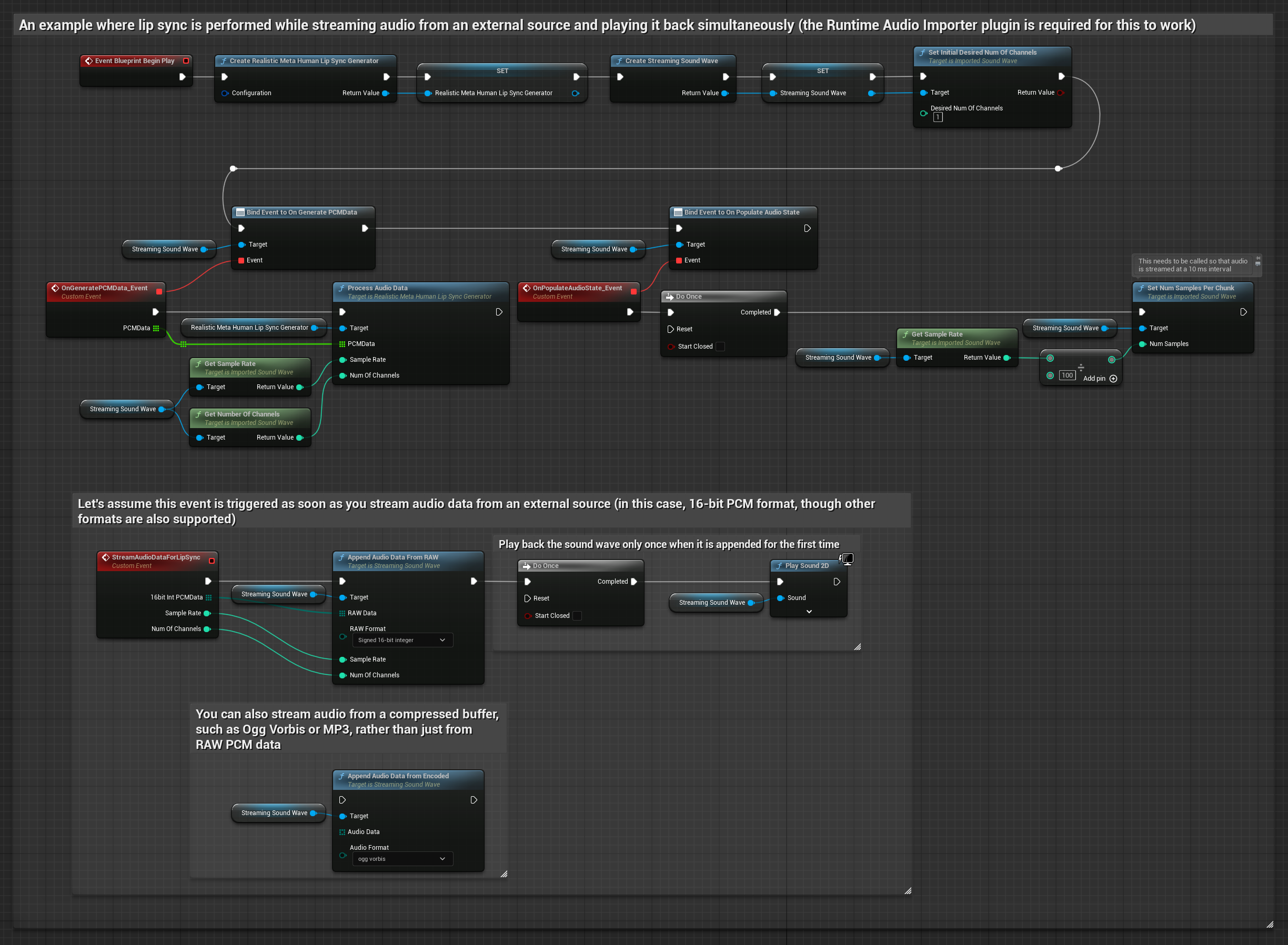
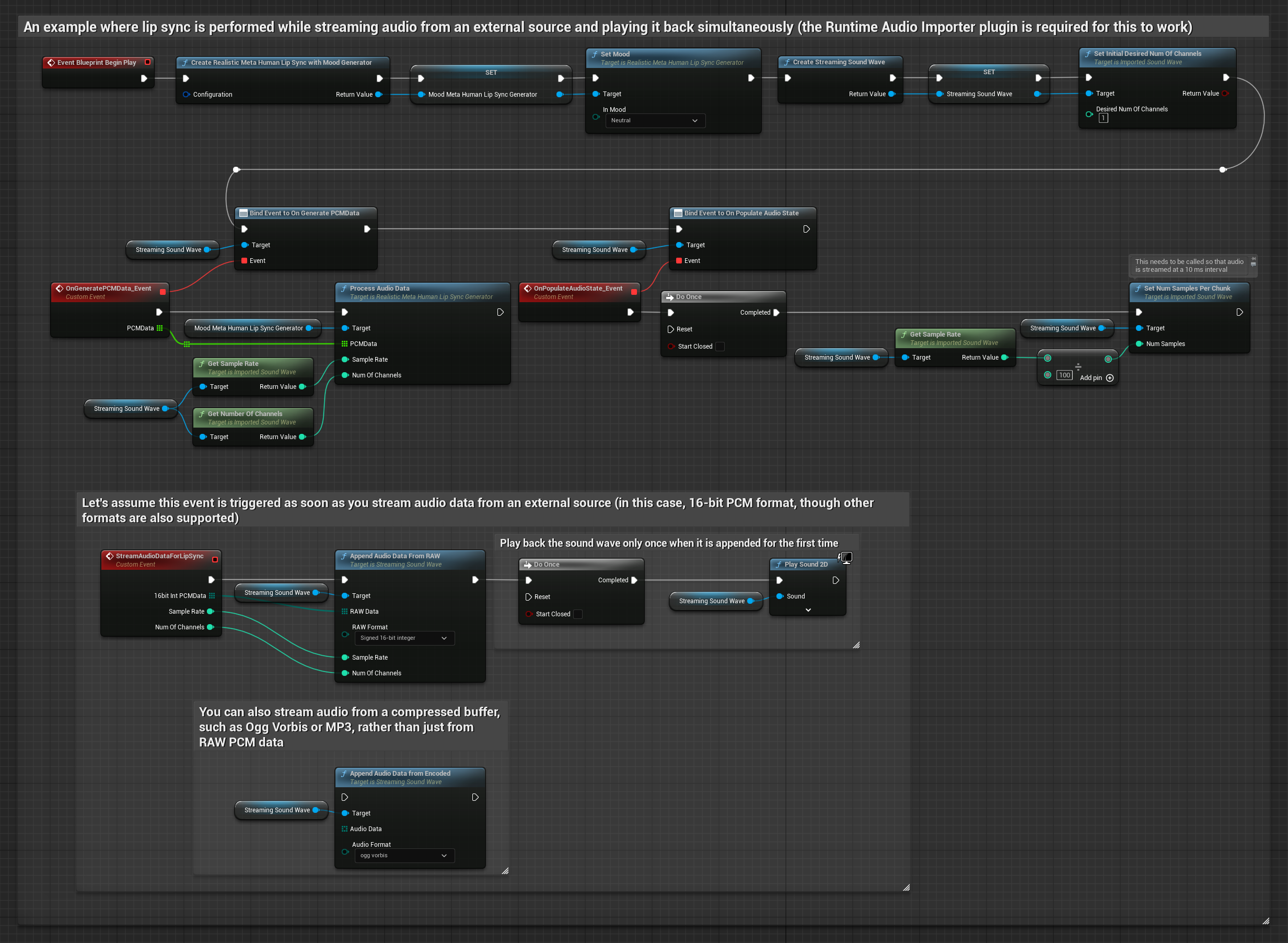
对于从缓冲区流式传输音频数据,您需要:
- 标准模型
- 写实模型
- 情绪驱动的逼真模型
- 来自流媒体源的浮点PCM格式音频数据(浮点样本数组)(或使用Runtime Audio Importer支持更多格式)
- 采样率和声道数
- 当音频块可用时,使用这些参数调用Runtime Viseme Generator中的
ProcessAudioData
注意: 使用流式音频源时,请确保合理管理音频播放时序,以避免播放失真。更多信息请参阅流式声波文档。
处理性能优化建议
-
块大小:增大
ProcessingChunkSize配置选项(例如设置为 320、480 或 640 个采样点)可显著改善延迟,同时对质量或响应速度影响极小。 -
模型类型:使用写实模型时,切换到高度优化模型类型(默认选中)可提升性能。请注意,原始模型在质量上可能略胜一筹,尤其是在处理嘈杂音频时。
-
缓冲区管理:支持情绪控制的模型以320采样点帧(16kHz采样率下对应20毫秒)处理音频。请确保您的音频输入时序与此对齐,以获得最佳性能。
-
生成器重建:为确保与真实感模型可靠运行,在长时间未使用后每次需要输入新音频数据时,请重建生成器。相关说明请参阅故障排除中的生成器重建。
下一步行动
一旦完成音频处理的设置,您可能希望: