插件配置
模型配置
为确保使用真实感与情绪感知真实感模型时的稳定运行,应在每次新音频播放前重新创建生成器,而非在长时间静默中重复使用同一生成器。详见故障排除中的生成器重新创建。
标准模型配置
创建运行时视位生成器节点使用默认设置,适用于大多数场景。配置通过动画蓝图混合节点属性进行处理。
关于动画蓝图配置选项,请参阅下方的口型同步配置章节。
写实模型配置
创建逼真 MetaHuman 口型同步生成器节点接受一个可选的配置参数,允许您自定义生成器的行为:
模型类型
模型类型设置决定了使用哪个版本的写实模型:
| 模型类型 | 性能 | 视觉质量 | 噪声处理 | 推荐使用场景 |
|---|---|---|---|---|
| 高度优化(默认) | 最高性能,最低CPU占用 | 高质量 | 在背景噪音或非语音声音下,可能会显示出明显的嘴部动作。 | 干净的音频环境、对性能要求较高的场景 |
| 半优化 | 性能良好,CPU占用适中 | 高质量 | 对嘈杂音频的稳定性更佳 | 平衡性能与质量,混合音频条件 |
| 原文 | 适用于现代CPU的实时使用 | 最高质量 | 在背景噪音和非人声环境下最为稳定 | 高质量制作、嘈杂音频环境、需要最高精度时 |
性能设置
内部操作线程数: 控制用于模型内部处理操作的线程数量。
- 0(默认/自动):使用自动检测(通常为可用CPU核心数的1/4,最多4个)
- 1-16:手动指定线程数。在多核系统上,较高的数值可能提升性能,但会占用更多CPU资源。
算子间线程数: 控制用于并行执行不同模型操作的线程数量。
- 0(默认/自动):使用自动检测(通常为可用CPU核心数的1/8,最大值为2)
- 1-8:手动指定线程数。通常为实时处理保持较低数值。
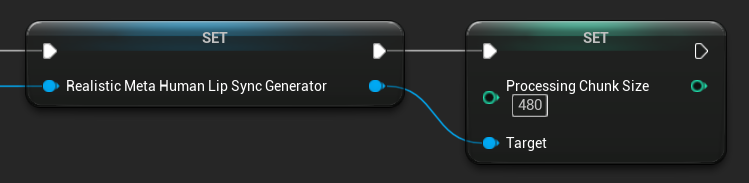
处理块大小
处理块大小决定了每次推理步骤中处理的样本数量。默认值为 160 个样本(16kHz 音频的 10 毫秒)。
- 较小的值提供更频繁的更新,但会增加CPU使用率
- 较大的值可降低CPU负载,但可能降低口型同步的响应速度
- 建议使用160的倍数以获得最佳对齐效果
情绪驱动模型配置
创建逼真的MetaHuman口型同步与情绪生成器节点提供了超越基础逼真模型的额外配置选项:
基本配置
前瞻毫秒数: 用于提升口型同步精度的前瞻时间(毫秒)。
- 默认值:80毫秒
- 范围:20毫秒至200毫秒(必须能被20整除)
- 数值越高,同步效果越好,但延迟也会增加
输出类型: 控制生成哪些面部控制。
- 全脸:全部81个面部控制(眉毛、眼睛、鼻子、嘴巴、下巴、舌头)
- 仅嘴巴:仅与嘴巴、下巴和舌头相关的控制
性能设置: 使用与常规逼真模型相同的内部操作线程和外部操作线程设置。
情绪设置
可用情绪:
- 中性, 快乐, 悲伤, 厌恶, 愤怒, 惊讶, 恐惧
- 自信, 兴奋, 无聊, 俏皮, 困惑
情绪强度: 控制情绪对动画的影响程度(0.0 至 1.0)
运行时情绪控制
您可以在运行时使用以下函数调整情绪设置:
- 设置情绪:更改当前情绪类型
- 设置情绪强度:调整情绪对动画的影响程度(0.0 至 1.0)
- 设置预读毫秒数:修改同步的预读时间
- 设置输出类型:在全脸控制和仅嘴部控制之间切换

情绪选择指南
根据您的内容选择合适的情感:
| Mood | 最适合 | 典型强度范围 |
|---|---|---|
| 中性 | 通用对话、旁白、默认状态 | 0.5 - 1.0 |
| 快乐 | 积极向上的内容、愉快的对话、庆祝活动 | 0.6 - 1.0 |
| 悲伤 | 忧郁的内容、情感场景、阴郁时刻 | 0.5 - 0.9 |
| 厌恶 | 负面反应、令人反感的内容、拒绝 | 0.4 - 0.8 |
| 愤怒 | 激烈对话、对抗场景、挫败感 | 0.6 - 1.0 |
| 惊讶 | 意外事件、真相揭露、震惊反应 | 0.7 - 1.0 |
| 恐惧 | 威胁情境、焦虑情绪、紧张对话 | 0.5 - 0.9 |
| 自信 | 专业演示、领导对话、坚定表达 | 0.7 - 1.0 |
| 兴奋 | 充满活力的内容、公告、热情洋溢的对话 | 0.8 - 1.0 |
| 无聊 | 内容单调,对话乏味,言语疲惫。 | 0.3 - 0.7 |
| 俏皮 | 日常闲聊、幽默风趣、轻松互动 | 0.6 - 0.9 |
| 困惑 | 充满疑问的对话、不确定感、困惑 | 0.4 - 0.8 |
动画蓝图配置
唇形同步配置
- 标准模型
- 逼真模型
混合运行时元人类唇形同步节点在其属性面板中具有配置选项:
| 属性 | 默认 | 描述 |
|---|---|---|
| 插值速度 | 25 | 控制唇部动作在不同视位之间过渡的速度。数值越高,过渡越快、越突兀。 |
| 重置时间 | 0.2 | 唇形同步重置前的持续时间(秒)。此设置有助于防止音频停止后唇形同步继续运行。 |
大笑动画
您还可以添加笑声动画,使其能够动态响应音频中检测到的笑声。
- 添加
混合运行时 MetaHuman 笑声节点 - 将你的
RuntimeVisemeGenerator变量连接到Viseme Generator引脚 - 如果你已经在使用口型同步:
- 将
混合运行时 MetaHuman 口型同步节点的输出连接到混合运行时 MetaHuman 笑声节点的源姿势输入。 - 将
混合运行时 MetaHuman 笑声节点的输出连接到输出姿势的结果引脚。
- 将
- 如果仅使用笑声而不进行口型同步:
- 将您的源姿势直接连接到
混合运行时元人类笑声节点的源姿势输入 - 将输出连接到
结果引脚
- 将您的源姿势直接连接到
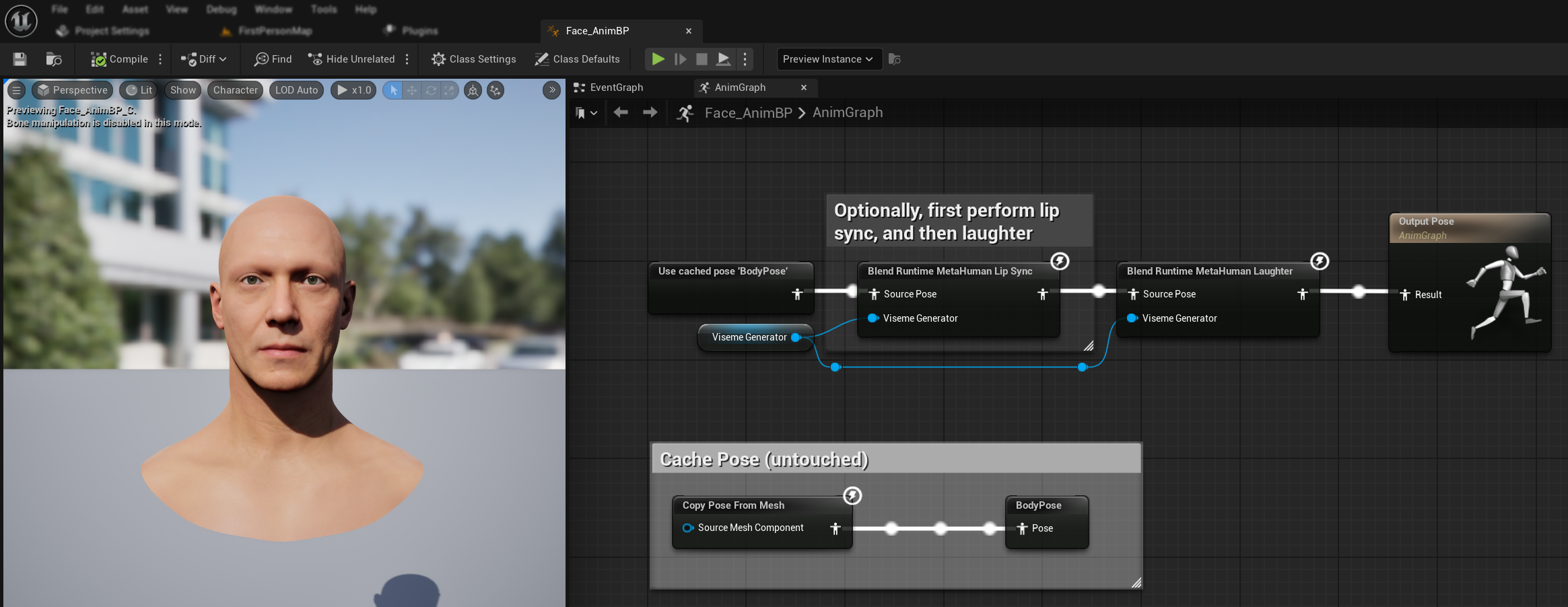
当音频中检测到笑声时,您的角色将动态地做出相应的动画表现:
笑声配置
混合运行时元人类笑声节点拥有其自身的配置选项:
| 属性 | 默认 | 描述 |
|---|---|---|
| 插值速度 | 25 | 控制唇部动作在笑声动画之间过渡的速度。数值越高,过渡越快越突兀。 |
| 重置时间 | 0.2 | 笑声重置的持续时间(秒)。此设置可防止音频停止后笑声继续播放。 |
| 最大笑声权重 | 0.7 | 缩放大笑动画的最大强度(0.0 - 1.0)。 |
注意: 笑声检测目前仅适用于标准模型。
Blend Realistic MetaHuman Lip Sync(混合逼真 MetaHuman 口型同步)节点在其属性面板中具有配置选项:
| 属性 | 默认 | 描述 |
|---|---|---|
| 插值速度 | 30 | 控制说话时面部表情过渡的速度。数值越高,过渡越快越突然。 |
| 空闲插值速度 | 15 | 控制面部表情恢复到空闲/中性状态的速度。数值越低,表情回归静止姿态的过程就越平滑、越渐进。 |
| 重置时间 | 0.2 | 唇形同步在多少秒后重置为闲置状态。用于防止音频停止后表情继续持续。 |
| 保持空闲状态 | false | 启用后,在空闲期间保持最后的情感状态,而非重置为中性。 |
| 保留眼部表情 | true | 控制是否在空闲状态下保留眼部相关的面部控制。仅在启用“保留空闲状态”时生效。 |
| 保留眉毛表情 | true | 控制空闲状态下是否保留眉毛相关的面部控制。仅在启用“保留空闲状态”时生效。 |
| 保持嘴部形状 | false | 控制是否在空闲状态下保留嘴部形状控制(不包括舌头和下巴等与语音相关的动作)。仅在启用“保留空闲状态”时生效。 |
空闲状态保持
保持空闲状态功能解决了写实模型处理静默时段的方式。与标准模型使用离散视位并在静默时始终归零不同,写实模型的神经网络可能会维持与MetaHuman默认休息姿势不同的微妙面部定位。
何时启用:
- 在语音片段之间保持情感表达
- 保留角色个性特征
- 确保电影序列中的视觉连贯性
区域控制选项:
- 眼部表情:保留眯眼、睁眼及眼睑位置
- 眉毛表情:维持眉毛与前额位置
- 嘴部形状:保持整体嘴部弧度,同时允许说话动作(舌头、下颌)复位
与现有动画结合
要在不覆盖现有身体动画和自定义面部动画的情况下应用口型同步和笑声:
此设置适用于面部动画蓝图,因为口型同步不属于身体动画蓝图的一部分。对于自定义身体动画(例如躯干、手臂及其他身体动作),只需通过序列播放器将动画序列直接连接到身体动画蓝图的输出姿势即可。此处无需额外设置。
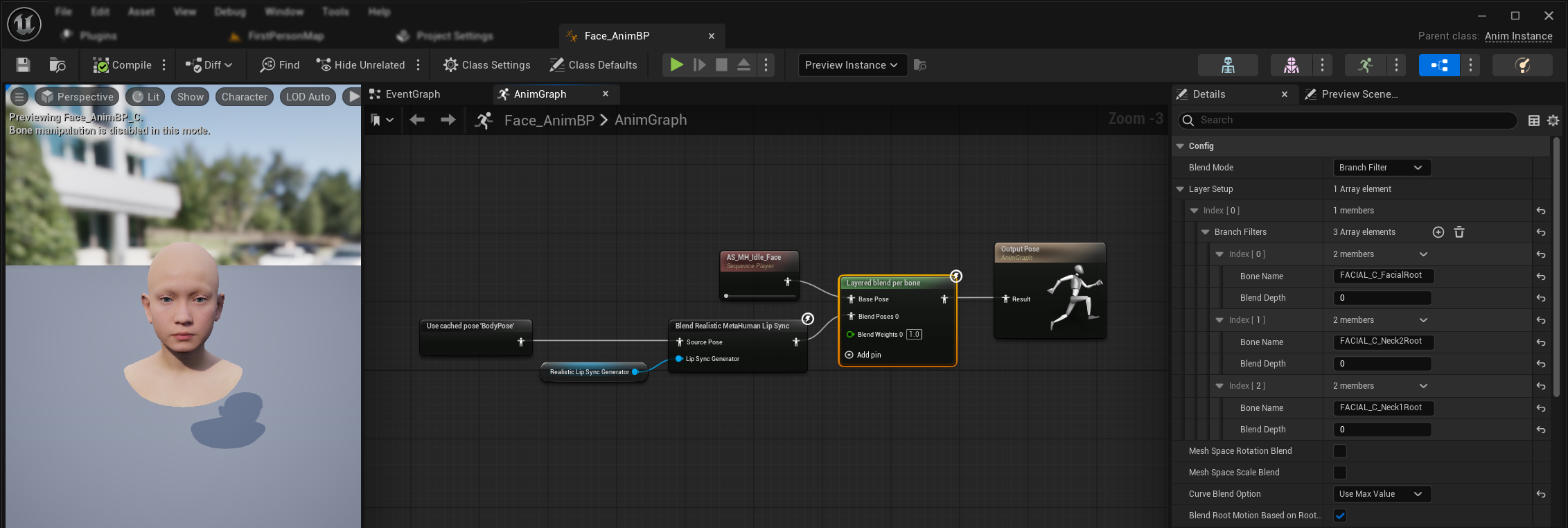
- 在你的身体动画和最终输出之间添加一个
按骨骼分层混合节点。确保使用附加父级设置为真。 - 配置图层设置:
- 向
Layer Setup数组添加 1 个元素 - 向该层的
Branch Filters添加 3 个元素,其Bone Name分别为:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- 向
- 自定义面部动画的重要提示: 在
曲线混合选项中,选择 "使用最大值"。这允许自定义面部动画(表情、情绪等)正确叠加在唇形同步之上。 - 建立连接:
- 您的自定义动画(通常是一个带有所需动画序列资源的
序列播放器)→基础姿势输入 - 面部动画输出(来自口型同步和/或笑声节点)→
混合姿势0输入 - 分层混合节点 → 最终
结果姿势
- 您的自定义动画(通常是一个带有所需动画序列资源的
形态目标集选择
- 标准模型
- 逼真模型
标准模型使用姿态资产,这些资产通过自定义姿态资产设置天然支持任何形态目标命名规范。无需额外配置。
混合逼真MetaHuman唇形同步节点包含一个形态目标集属性,用于确定面部动画所使用的形态目标命名规范:
| 形态目标集 | 描述 | 使用案例 |
|---|---|---|
| MetaHuman(默认) | 标准 MetaHuman 形态目标名称(例如 CTRL_expressions_jawOpen) | MetaHuman 角色 |
| ARKit | 与 Apple ARKit 兼容的名称(例如 JawOpen、MouthSmileLeft) | 基于ARKit的角色 |
微调唇形同步行为
缩放特定口型同步曲线
您可以使用修改曲线节点来减弱(或增强)唇形同步产生的单个面部动作。当某个曲线对您的音频内容或角色来说显得过于夸张时,这一功能尤为实用。
设置:
- 在您的口型同步混合节点之后,添加一个
修改曲线节点 - 右键点击该节点,选择添加曲线引脚,然后输入您想要缩放的曲线名称
- 将该节点的应用模式属性设置为缩放
- 设置值参数:低于1.0的值会减弱运动幅度,高于1.0的值会增强运动幅度(例如,0.8表示减少20%)
常用缩放曲线:
| 曲线名称 | 目的 | 适用于 | 典型调整 |
|---|---|---|---|
CTRL_expressions_tongueOut | 在某些音素发音时,舌头向前伸出。 | 标准模型 | 0.8 以减少突出 |
CTRL_expressions_jawOpen | 下颌张开范围 | 逼真模型 | 0.9 以减少下颌运动 |
你可以向同一个 Modify Curve 节点添加多个曲线引脚,以同时缩放多条曲线。
情绪特定微调
对于支持情绪控制的模型,您可以微调特定的情感表达:
眉毛控制:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- 眉毛内侧提升CTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- 眉毛外侧提升CTRL_expressions_browDownL/CTRL_expressions_browDownR- 眉毛降低
眼部表情控制:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- 眼睛眯起CTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- 脸颊抬起
模型对比与选择
选择模型
在决定为项目使用哪种口型同步模型时,请考虑以下因素:
| 考量 | 标准模型 | 写实模型 | 情绪驱动的逼真模型 |
|---|---|---|---|
| 角色兼容性 | MetaHumans 及所有自定义角色类型 | MetaHumans(以及 ARKit)角色 | MetaHumans(以及 ARKit)角色 |
| 视觉质量 | 良好的口型同步与高效性能 | 通过更自然的嘴部动作增强真实感 | 通过情感表达增强真实感 |
| 性能 | 针对所有平台(包括移动端/VR)进行了优化 | 更高的资源需求 | 更高的资源需求 |
| 功能特性 | 14个视位,笑声检测 | 81个面部控制,3个优化级别 | 81个面部控制、12种情绪、可配置输出 |
| 平台支持 | Windows、Android、Quest | Windows、Mac、iOS、Linux、Android、Quest | Windows、Mac、iOS、Linux、Android、Quest |
| 使用案例 | 通用应用、游戏、VR/AR、移动端 | 电影级体验,近距离互动 | 情感叙事与高级角色互动 |
引擎版本兼容性
如果您使用的是 Unreal Engine 5.2,由于 UE 重采样库中存在一个错误,真实感模型可能无法正常工作。对于需要可靠唇形同步功能的 UE 5.2 用户,请改用 标准模型。
此问题仅与 UE 5.2 相关,不影响其他引擎版本。
性能优化建议
- 对于大多数项目而言,标准模型在质量与性能之间提供了出色的平衡
- 当您需要为MetaHuman角色实现最高视觉保真度时,请使用逼真模型
- 当情感表达控制对您的应用至关重要时,请使用情绪驱动逼真模型
- 在选择模型时,请考虑目标平台的性能能力
- 测试不同的优化级别,为您的特定用例找到最佳平衡点
故障排除
常见问题
为写实模型重新创建生成器: 为确保与写实模型可靠且一致地运行,建议在长时间未使用后,每次要输入新音频数据时重新创建生成器。这是由于ONNX运行时行为所致——在静默期后重复使用生成器可能导致口型同步停止工作。
例如,您可以在每次播放开始时重新创建口型同步生成器,比如每当调用 Play Sound 2D 或使用其他方法启动声波播放和口型同步时:
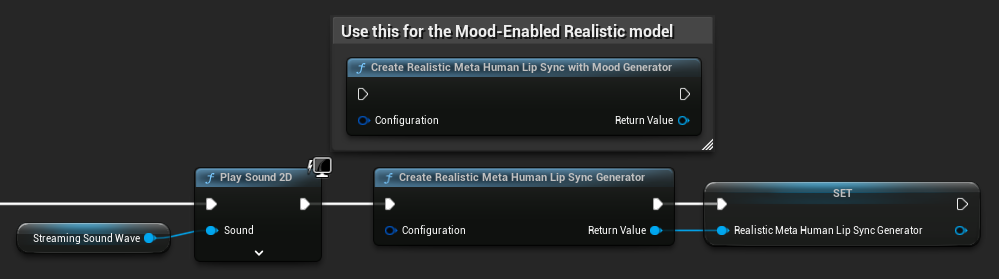
运行时文本转语音集成的插件位置:
当同时使用运行时元人类唇形同步与运行时文本转语音(两个插件均依赖ONNX运行时)时,若插件安装在引擎的Marketplace文件夹中,打包构建时可能会遇到问题。解决方法如下:
- 在你的UE安装目录下的
\Engine\Plugins\Marketplace文件夹中找到这两个插件(例如:C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - 将
RuntimeMetaHumanLipSync和RuntimeTextToSpeech这两个文件夹移动到项目的Plugins文件夹中 - 如果你的项目没有
Plugins文件夹,请在.uproject文件所在的目录下创建一个 - 重启虚幻编辑器
此修复解决了当从引擎的Marketplace目录加载多个基于ONNX Runtime的插件时可能出现的兼容性问题。
打包配置(Windows):
如果在 Windows 打包后的项目中唇形同步无法正常工作,请确保使用发布构建配置而非开发配置。开发配置可能会导致打包构建中逼真模型 ONNX 运行时出现问题。
要修复此问题:
- 在你的项目设置 → 打包中,将构建配置设置为 Shipping
- 重新打包你的项目
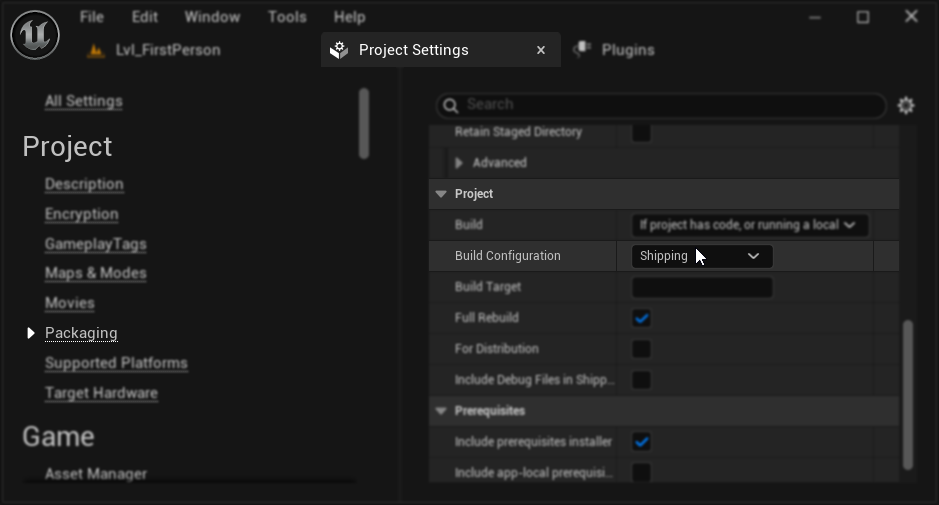
在某些纯蓝图项目中,即使选择了"Shipping"配置,虚幻引擎仍可能以"Development"配置进行构建。若出现此情况,请通过添加至少一个C++类(可为空类)将项目转换为C++项目。操作方法:在UE编辑器菜单中依次选择工具 → 新建C++类,创建一个空类。这将强制项目在"Shipping"配置下正确构建。您的项目功能上仍可保持纯蓝图实现,添加C++类仅用于确保正确的构建配置。
口型同步响应下降:
若在使用流式音频波形或可捕获音频波形时,口型同步随时间推移响应变慢,可能是由内存累积所致。默认情况下,每次追加新音频时都会重新分配内存。为避免此问题,请定期调用 ReleaseMemory 函数释放累积内存,例如每隔约30秒执行一次。
性能优化:
- 根据您的性能需求,为逼真模型调整处理块大小
- 根据目标硬件使用合适的线程数
- 当不需要完整面部动画时,可考虑对支持情绪控制的模型使用仅嘴部输出类型