如何使用该插件
Runtime Speech Recognizer 插件旨在从传入的音频数据中识别词语。它使用了略微修改版的 whisper.cpp 来与引擎协同工作。要使用该插件,请按照以下步骤操作:
编辑器端
- 根据此处的描述,为您的项目选择合适的语言模型。
运行时端
- 创建一个 Speech Recognizer 并设置必要的参数(CreateSpeechRecognizer,参数说明请参见此处)。
- 绑定到所需的委托(OnRecognitionFinished、OnRecognizedTextSegment 和 OnRecognitionError)。
- 开始语音识别(StartSpeechRecognition)。
- 处理音频数据并等待来自委托的结果(ProcessAudioData)。
- 在需要时(例如,在 OnRecognitionFinished 广播之后)停止语音识别器。
该插件支持传入 32 位交错 PCM 格式的浮点音频。虽然它与 Runtime Audio Importer 配合良好,但并不直接依赖它。
识别参数
该插件支持流式和非流式音频数据识别。要为您的特定用例调整识别参数,请调用 SetStreamingDefaults 或 SetNonStreamingDefaults。此外,您还可以灵活地手动设置各个参数,例如线程数、步长、是否将传入语言翻译为英语,以及是否使用过去的转录。有关可用参数的完整列表,请参阅识别参数列表。
提高性能
有关如何优化插件性能的技巧,请参阅如何提高性能部分。
语音活动检测 (VAD)
在处理音频输入时,尤其是在流式场景中,建议使用语音活动检测(VAD)在音频段到达识别器之前过滤掉空白或仅含噪声的音频段。可以在可捕获声波端使用 Runtime Audio Importer 插件启用此过滤功能,这有助于防止语言模型产生幻觉——即在噪声中尝试寻找模式并生成错误的转录。
为了获得最佳的语音识别效果,我们推荐使用 Silero VAD 提供程序,它具有卓越的噪声容限和更准确的语音检测能力。Silero VAD 作为 Runtime Audio Importer 插件的一个扩展提供。有关 VAD 配置的详细说明,请参阅语音活动检测文档。
以下示例中的可复制节点出于兼容性考虑使用了默认的 VAD 提供程序。为提高识别准确率,您可以通过以下步骤轻松切换至 Silero VAD:
- 按照 Silero VAD 扩展章节 所述安装 Silero VAD 扩展
- 在使用 Toggle VAD 节点启用 VAD 后,添加一个 Set VAD Provider 节点并从下拉菜单中选择 "Silero"
在插件附带的演示项目中,VAD 默认处于启用状态。您可以在 演示项目 中找到有关演示实现的更多信息。
示例
插件包含一个优秀的项目演示,位于 Content -> Demo 文件夹中,您可将其用作实现的参考。
这些示例说明了如何将 Runtime Speech Recognizer 插件与流式和非流式音频输入结合使用,并以 Runtime Audio Importer 获取音频数据为例。请注意,要访问示例中展示的相同音频导入功能集(例如可捕获声波和 ImportAudioFromFile),需要单独下载 RuntimeAudioImporter。这些示例仅用于说明核心概念,不包含错误处理。
流式音频输入示例
注意: 在 UE 5.3 及其他版本中,复制Blueprint后可能会遇到节点丢失的情况。这可能是由于不同引擎版本间节点序列化的差异所致。请务必在您的实现中验证所有节点是否正确连接。
1. 基础流式识别
此示例演示了使用可捕获声波从麦克风捕获音频数据流并将其传递给语音识别器的基本设置。它录制约 5 秒的语音然后处理识别,适用于快速测试和简单实现。 可复制节点.
此设置的主要特点:
- 固定的 5 秒录制时长
- 简单的一次性识别
- 最低限度的设置要求
- 非常适合测试和原型制作
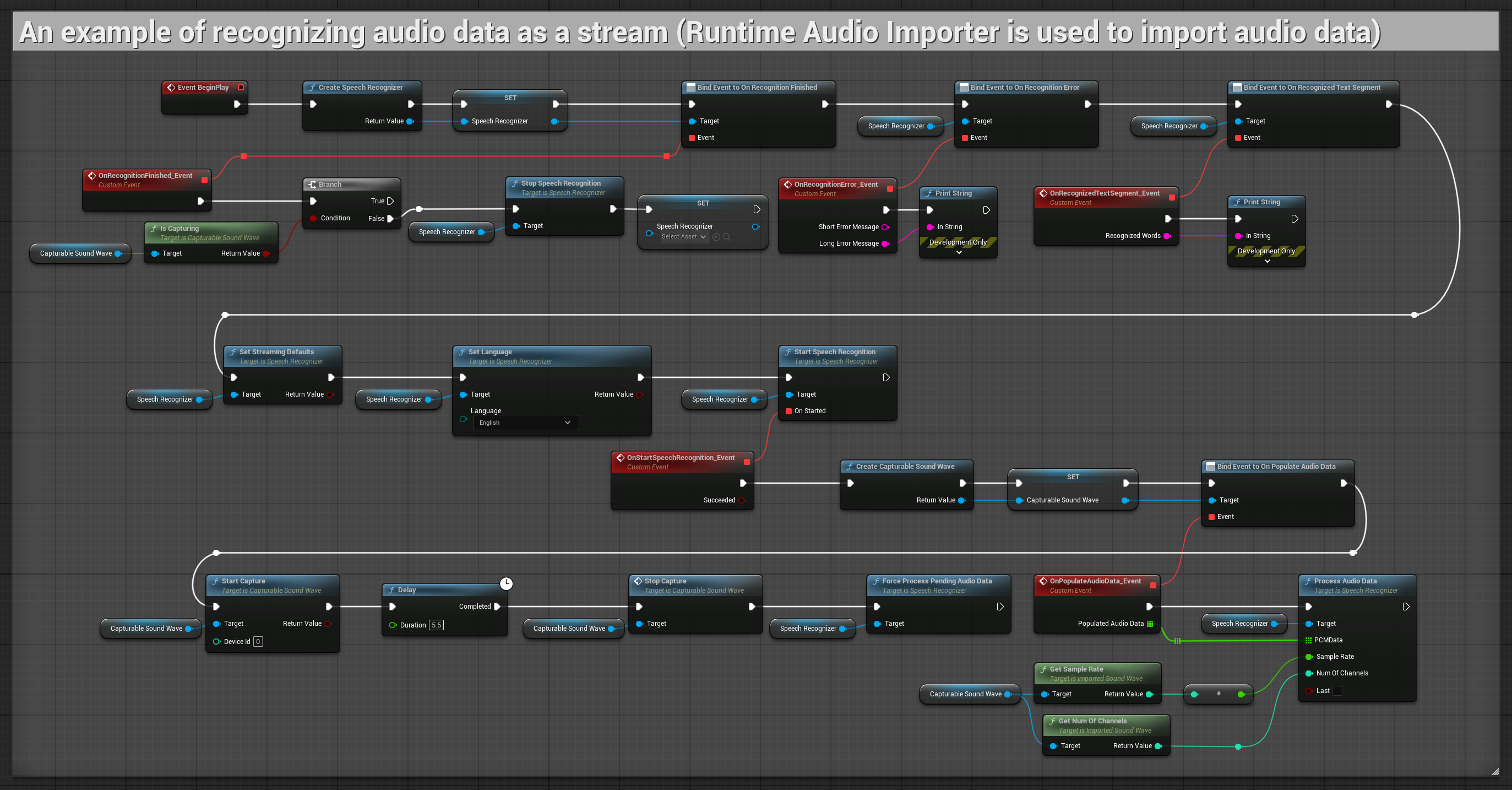
2. 受控流式识别
此示例通过添加对手动控制识别过程的功能,扩展了基础流式设置。它允许您根据需要随时启动和停止识别,适用于需要精确控制识别时机的场景。可复制节点.
此设置的主要特点:
- 手动开始/停止控制
- 持续识别能力
- 灵活的录制时长
- 适用于交互式应用
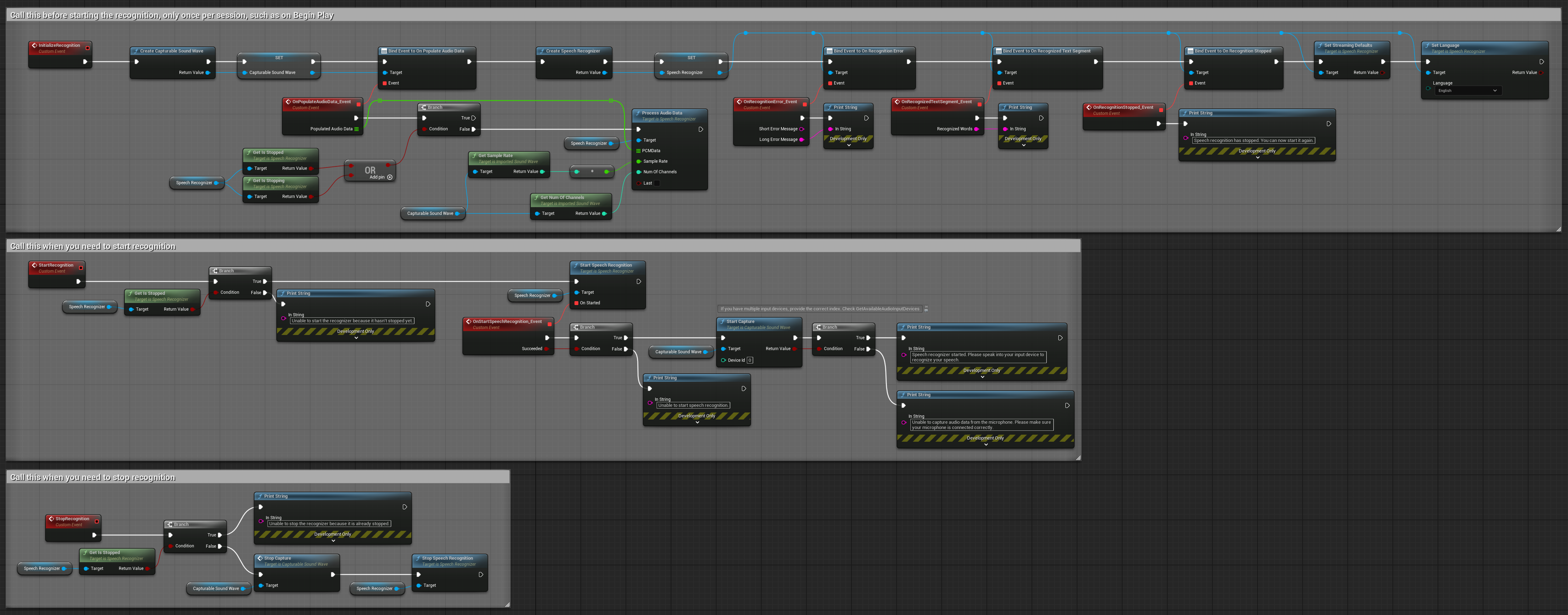
3. 语音激活命令识别
此示例针对命令识别场景进行了优化。它结合了流式识别与语音活动检测(VAD),以便在用户停止说话时自动处理语音。识别器仅在检测到静音时才开始处理累积的语音,这使其成为基于命令界面的理想选择。可复制的节点。
此设置的关键特性:
- 手动开始/停止控制
- 启用语音活动检测(VAD)以检测语音片段
- 检测到静音时自动触发识别
- 适用于短命令识别
- 仅识别实际语音,减少处理开销
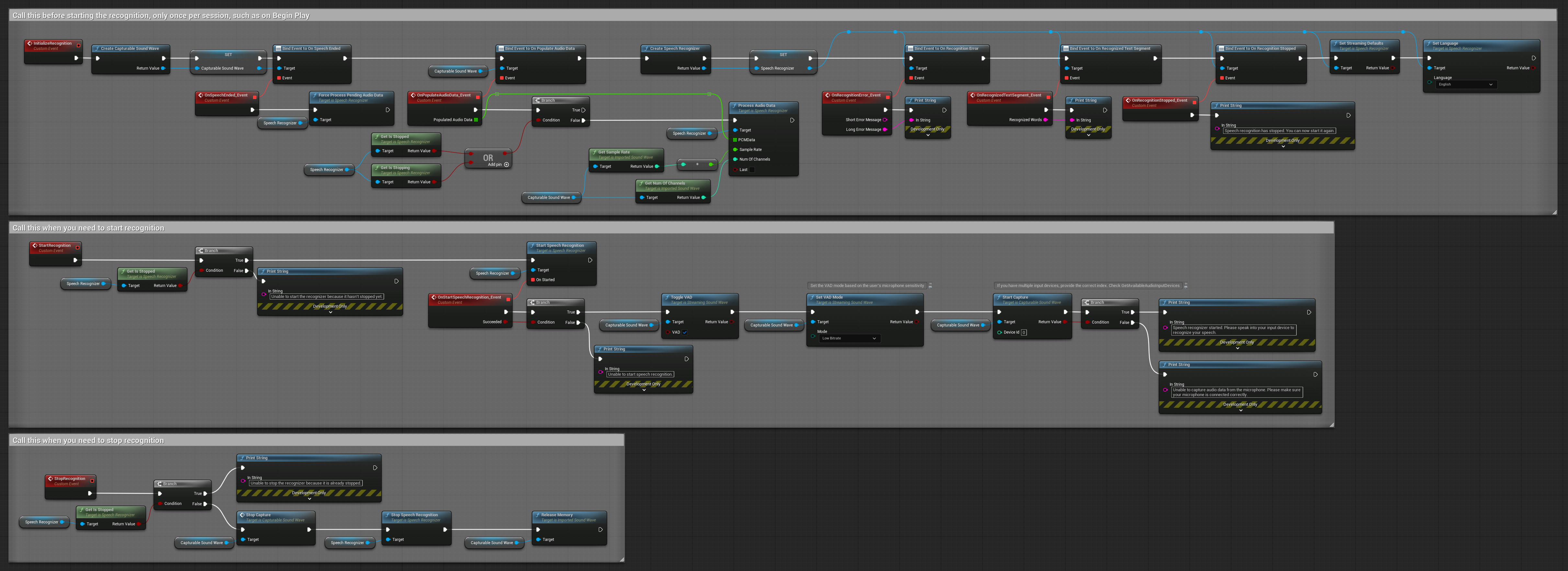
4. 自动初始化语音识别与最终缓冲区处理
此示例是语音激活识别方法的另一种变体,具有不同的生命周期处理方式。它会在初始化期间自动启动识别器,并在反初始化期间停止识别器。一个关键特性是,它在停止识别器之前会处理最后累积的音频缓冲区,确保在用户想要结束识别过程时不会丢失任何语音数据。此设置对于需要捕获完整用户话语(即使在说话中途停止)的应用特别有用。可复制的节点。
此设置的关键特性:
- 初始化时自动启动识别器
- 反初始化时自动停止识别器
- 在完全停止前处理最终音频缓冲区
- 使用语音活动检测(VAD)进行高效识别
- 确保停止时不会丢失语音数据
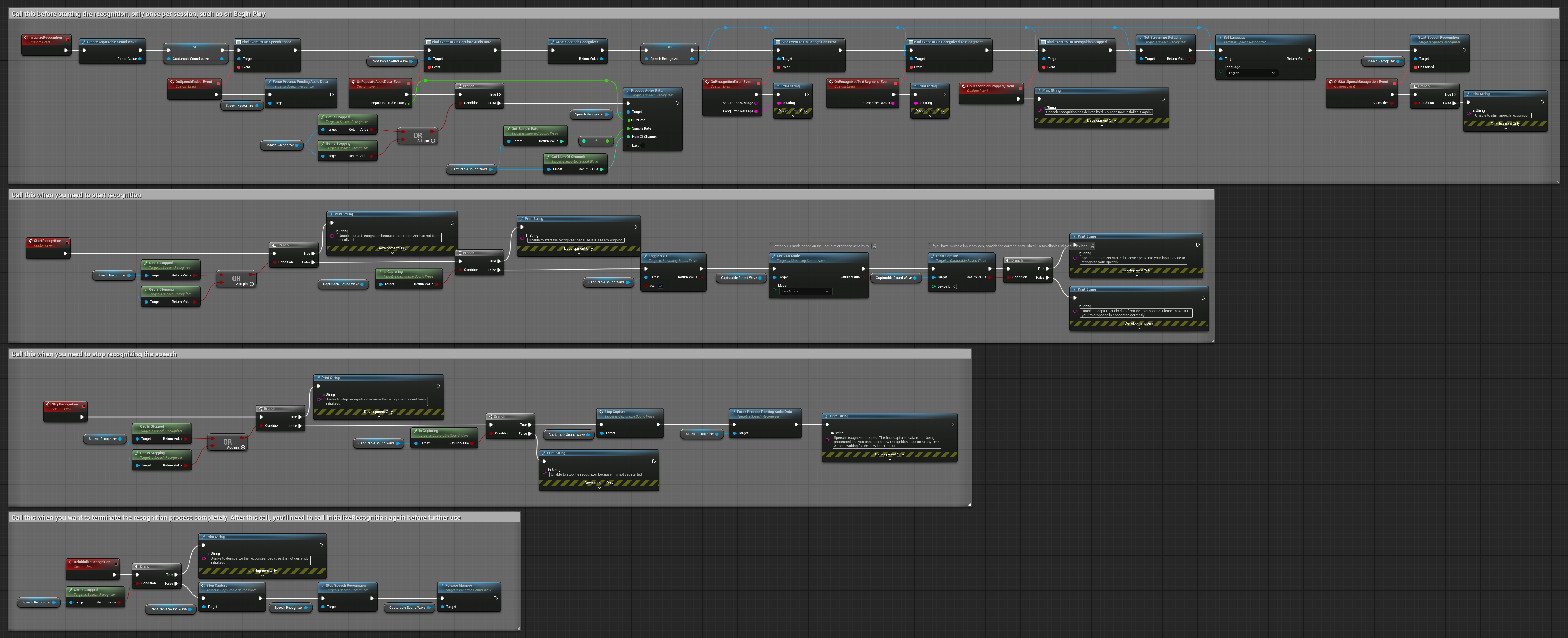
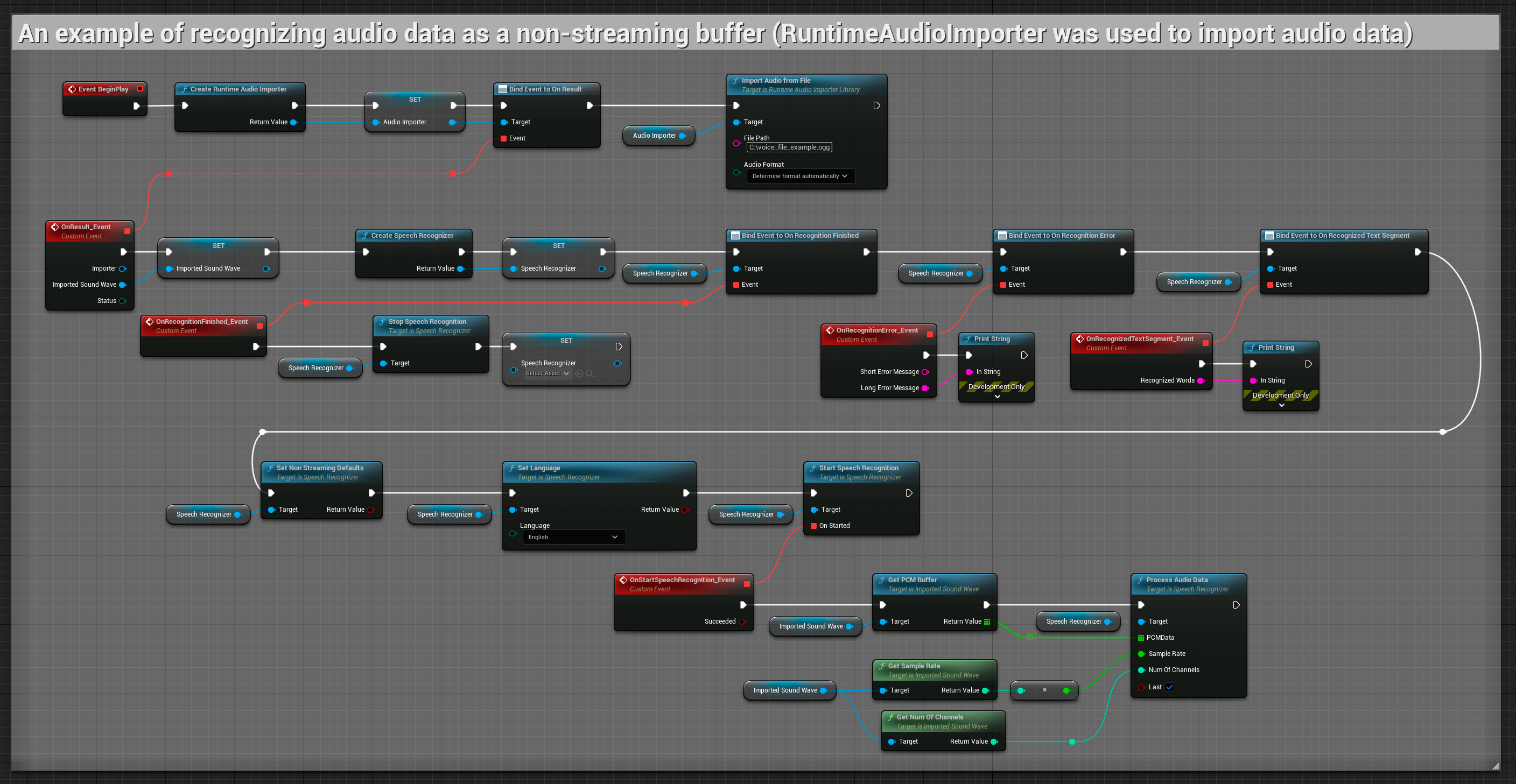
非流式音频输入
此示例将音频数据导入到导入的声音波形中,并在导入完整音频数据后一次性进行识别。可复制的节点。