识别参数列表
这些参数只能在识别器未运行时设置。
这不是 Whisper 中所有可用参数的详尽列表。此处仅公开最重要的参数。如有必要,此列表将会更新。
设置识别参数
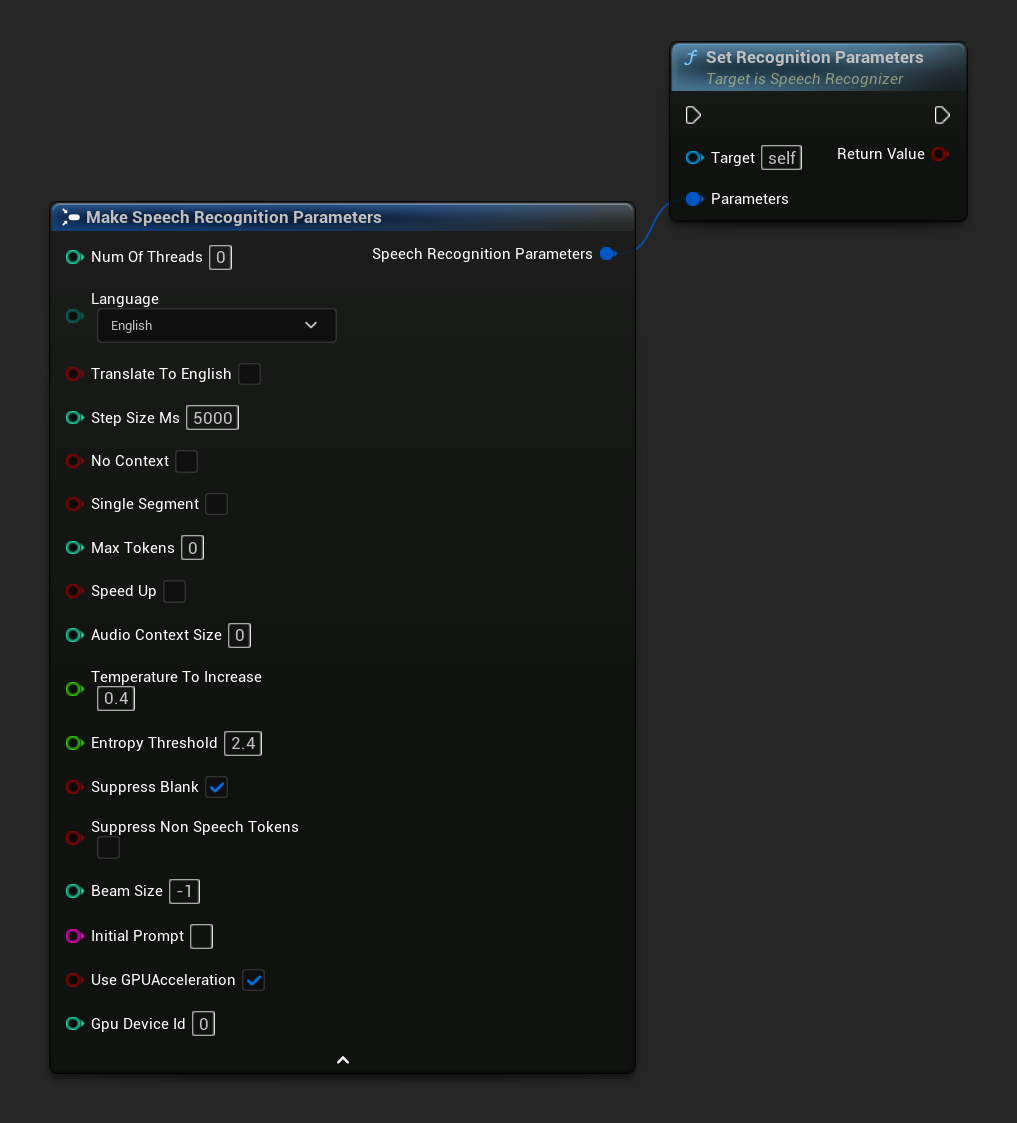
设置语音识别的参数。如果只想更改特定参数,请考虑使用单独的设置器函数。
设置流式默认值
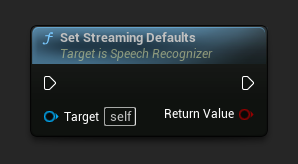
设置适用于流式语音识别的默认参数。
此函数会覆盖所有先前应用的参数。如果需要将流式默认值作为基础配置,请确保在设置自定义参数之前调用此函数。
设置非流式默认值
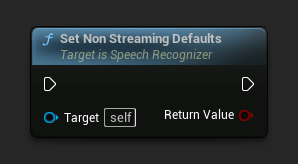
设置适用于非流式语音识别的默认参数。
此函数会覆盖所有先前应用的参数。如果需要将非流式默认值作为基础配置,请确保在设置自定义参数之前调用此函数。
设置线程数
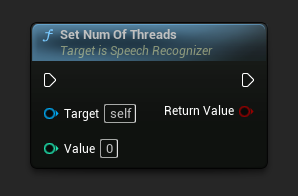
设置用于语音识别的线程数。将此值设置为 0 以使用核心数。
设置语言
设置用于语音识别的语言。必须受编辑器设置中所选语言模型支持。
将语言设置为 Auto 会降低识别准确性和性能。
获取检测到的语言
获取上次识别中检测到的语言。以枚举值形式返回语言。
注意: 此函数仅在执行识别后才有效。如果语言检测失败或未执行,则返回 Auto。这在需要识别实际识别出的语言时特别有用。
获取语言代码
将语言枚举值转换为其语言代码字符串(例如,En -> "en",Fr -> "fr",De -> "de")。
获取语言全称
将语言枚举值转换为其完整的语言名称(例如,En -> "English",Fr -> "French",De -> "German")。
设置翻译为英语
![]()
设置是否将识别出的单词翻译为英语。如果为 true,则语言模型必须是多语言的。
设置步长
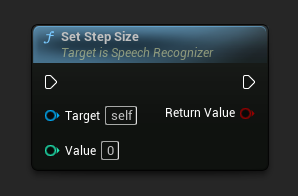
设置步长(以毫秒为单位)。决定发送音频数据进行识别的频率。默认值为 5000 毫秒(5 秒)。
设置无上下文
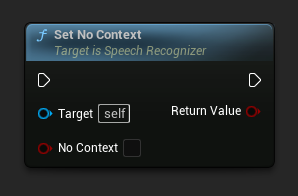
设置是否使用过去的转录(如果有)作为解码器的初始提示。
设置单一段落
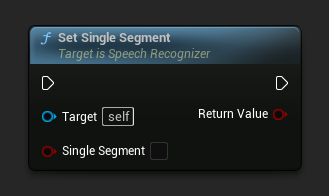
设置是否强制输出单一段落(对流式处理有用)。
设置最大令牌数
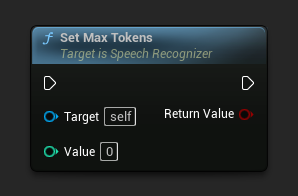
设置每个文本段落的最大令牌数。使用 0 表示无限制。
设置加速
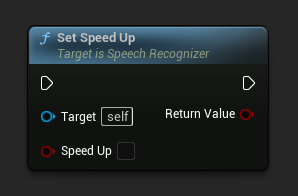
设置是否使用相位声码器将识别速度提高 2 倍。将其设置为 false 以提高输出质量。
设置音频上下文大小
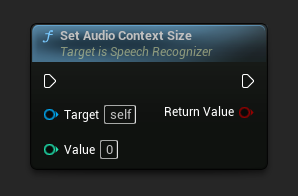
设置音频上下文的大小。将其设置为 0 以提高输出质量。
设置回退温度
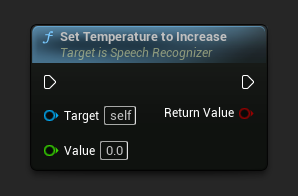
设置当解码未能满足以下任一阈值而回退时要增加的温度。
设置熵阈值
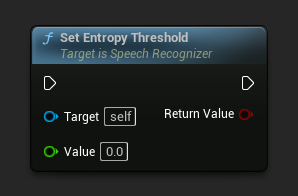
设置熵阈值。如果压缩比高于此值,则将解码视为失败。类似于 OpenAI 的 "compression_ratio_threshold"
设置抑制空白
![]()
设置是否抑制输出中出现的空白。
设置抑制非语音令牌
设置是否抑制输出中出现的非语音令牌。
设置束搜索大小
设置束搜索中的束数量。仅在温度为零时适用。
设置初始提示
设置第一个窗口的初始提示。这可用于为识别提供上下文,使其更有可能正确预测单词,例如自定义词汇表或专有名词。
有关有效提示策略的更多详细信息,请参阅 Whisper 提示指南。
设置 GPU 加速
设置是否使用 GPU 加速进行语音识别(目前仅适用于 Windows)。
设置 GPU 设备 ID
设置用于语音识别的 GPU 设备 ID。默认值为 0。这对于具有多个 GPU 的系统非常有用,可以指定哪个 GPU 应用于识别过程。如果指定的 GPU 设备 ID 无效,则将使用第一个可用的 GPU 设备索引。