翻譯提供者
AI Localization Automator 支援五種不同的 AI 供應商,每種都有其獨特優勢與配置選項。請根據您專案的需求、預算和品質要求,選擇最適合的供應商。
Ollama (本機AI)
最適合: 隱私敏感項目、離線翻譯、無限制使用
Ollama 在您的本機上執行 AI 模型,提供完全的隱私和控制,無需 API 費用或網際網路需求。
熱門模型
- translategemma:12b(基於Gemma 3的專門翻譯模型)
- llama3.2(推薦的通用模型)
- mistral(高效的替代方案)
- codellama(感知程式碼的翻譯)
- 以及更多社群模型
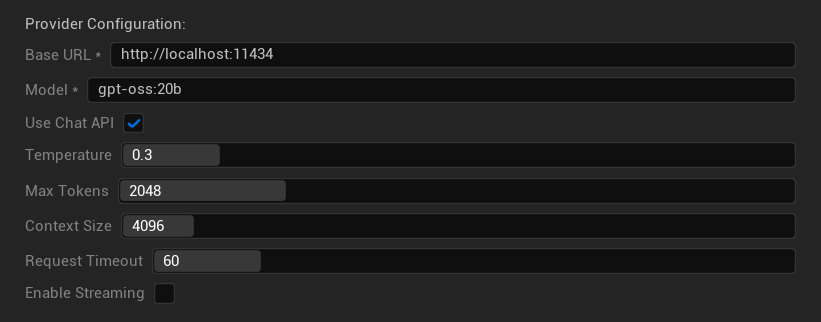
配置選項
- Base URL:本地 Ollama 伺服器(預設:
http://localhost:11434) - 模型:已安裝的本地模型名稱(必填)
- 啟用聊天 API:啟用以獲得更好的對話處理能力
- 溫度:0.0-2.0(建議 0.3)
- 最大令牌數:1-8,192 個令牌
- 上下文大小:512-32,768 個令牌
- 請求超時:10-300 秒(本地模型可能較慢)
- 啟用串流:用於即時回應處理
優勢
- ✅ 完全隱私(無資料離開您的機器)
- ✅ 無 API 費用或使用限制
- ✅ 可離線運作
- ✅ 完全控制模型參數
- ✅ 多種多樣的社群模型
- ✅ 無供應商鎖定
注意事項
- 💻 需要本地設定與高效能硬體
- ⚡ 通常比雲端服務商慢
- 🔧 需要更多技術設定
- 📊 翻譯品質因模型而異(部分可超越雲端服務商)
- 💾 模型需要大量儲存空間
設定 Ollama
- 安裝 Ollama:從 ollama.ai 下載並安裝到您的系統
- 下載模型:使用
ollama pull translategemma:12b下載您選擇的模型 - 啟動伺服器:Ollama 會自動執行,或使用
ollama serve啟動 - 設定外掛程式:在外掛程式設定中設定基礎 URL 和模型名稱
- 測試連線:當您套用設定時,外掛程式會驗證連線
OpenAI
最適合:最高的整體翻譯品質,廣泛的模型選擇
OpenAI 透過其 Chat Completions API 提供業界領先的語言模型,包括最新的 GPT 模型、推理模型,以及啟用網路搜尋的模型。
可用模型
GPT-5 系列(旗艦模型)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
- gpt-5.5, gpt-5.6-sol, gpt-5.6-luna
GPT-4.1 Family (高效能)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
GPT-4o Family(多模態)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O-Series(推理模型 — temperature/top_p 不支援)
- o1, o1-pro, o3, o3-mini, o4-mini
網路搜尋模型(不支援 Temperature/top_p)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
舊版 / 預覽
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
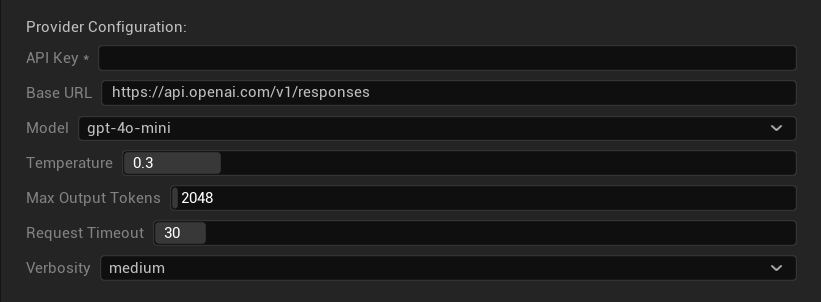
配置選項
- API 金鑰:您的 OpenAI API 金鑰(必填)
- 基本 URL:API 端點(預設:
https://api.openai.com/v1/chat/completions) - 模型:從上方列出的可用模型中選擇
- 使用溫度:開啟/關閉溫度參數(對於 o 系列推理模型與網路搜尋模型會自動忽略)
- 溫度:0.0–2.0(建議翻譯一致性使用 0.3)
- Top P:0.0–1.0 核取樣參數(對於 o 系列推理模型與網路搜尋模型會忽略)
- 最大完成 Token 數:1–128,000 個 Token(包含輸出與推理 Token)
- 請求超時:5–300 秒
優勢
- ✅ 一致的高品質翻譯
- ✅ 出色的上下文理解
- ✅ 強大的格式保留
- ✅ 廣泛的語言支援
- ✅ 可靠的API正常運行時間
注意事項
- 💰 每次請求成本較高
- 🌐 需要網際網路連線
- ⏱️ 根據等級的使用限制
Anthropic Claude
最適合:細膩的翻譯、創意內容、注重安全的應用
Claude 模型擅長理解上下文和細微差別,使其非常適合敘事型遊戲和複雜的在地化場景。
可用模型
Claude 5 系列
- claude-opus-5, claude-sonnet-5, claude-fable-5
Claude 4.8 系列
- claude-opus-4-8
Claude 4.7 Family
- claude-opus-4-7
Claude 4.6 Family
- claude-opus-4-6, claude-sonnet-4-6
Claude 4.5 Family
- claude-haiku-4-5(快速且高效)
- claude-sonnet-4-5、claude-opus-4-5
Claude 4.x 系列
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Claude 3.x 系列(舊版)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
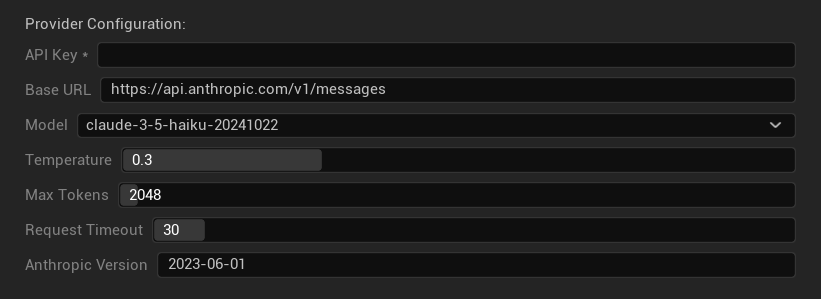
配置選項
- API 金鑰:您的 Anthropic API 金鑰(必填)
- 基礎 URL:Claude API 端點
- 模型:從 Claude 模型系列中選取
- 溫度:0.0–1.0(建議 0.3)
- Top K:Top-K 取樣參數(0 = 未設定)
- 最大權杖數:1–64,000 個權杖
- 請求超時:5–300 秒
- Anthropic 版本:API 版本標頭
優勢
- ✅ 卓越的上下文感知能力
- ✅ 非常適合創意/敘事內容
- ✅ 強大的安全功能
- ✅ 詳細的推理能力(3.7+ 模型上的擴展思考)
- ✅ 優秀的指令遵循能力
考量事項
- 💰 高級定價模式
- 🌐 需要網路連接
- 📏 Token 限制因模型而異
DeepSeek
最適合:具成本效益的翻譯、高吞吐量、預算有限的專案
DeepSeek 以極低的成本提供具有競爭力的翻譯品質,使其成為大規模本地化專案的理想選擇。
可用模型
- deepseek-v4-pro
- deepseek-v4-flash
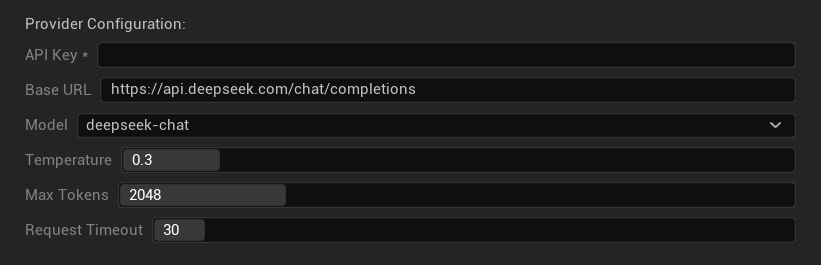
配置選項
- API金鑰:您的DeepSeek API金鑰(必填)
- 基礎URL:DeepSeek API端點
- 模型:在聊天模型與推理模型之間選擇
- 溫度:0.0-2.0(建議0.3)
- 最大Token數:1-8,192個Token
- 請求逾時:5-300秒
優勢
- ✅ 極具成本效益
- ✅ 翻譯品質優良
- ✅ 回應速度快
- ✅ 配置簡單
- ✅ 高速率限制
注意事項
- 📏 較低的Token限制
- 🆕 較新的提供者(較少的過往記錄)
- 🌐 需要網路連線
Google Gemini
適合: 多語言專案、成本效益高的翻譯、Google 生態系統整合
Gemini 模型提供強大的多語言能力,搭配有競爭力的價格,以及獨特的功能,例如思考模式以增強推理能力。
可用模型
Gemini 3.x Family (預覽)
- gemini-3.1-pro, gemini-3.1-flash-light, gemini-3.5-flash, gemini-3.6-flash
Gemini 2.5 Family(支援思考)
- gemini-2.5-pro(旗艦級,具備思考能力)
- gemini-2.5-flash(快速,支援思考功能)
- gemini-2.5-flash-lite(輕量級變體)
Gemini 2.0 系列
- gemini-2.0-flash, gemini-2.0-flash-lite
最新別名
- gemini-flash-latest, gemini-flash-lite-latest
配置選項
- API 金鑰: 您的 Google AI API 金鑰(必填)
- 基礎 URL: Gemini API 端點
- 模型: 從 Gemini 模型系列中選擇
- 溫度: 0.0–2.0(建議 0.3)
- 最大輸出 Token 數: 1–8,192 個 Token
- 請求超時: 5–300 秒
- 啟用思考: 為 2.5+ 模型啟用增強推理
- 思考預算: 控制思考 token 分配(0 = 無思考)
優勢
- ✅ 強大的多語言支援
- ✅ 具競爭力的價格
- ✅ 進階推理(思考模式)
- ✅ Google生態系統整合
- ✅ 定期模型更新,並可搶先體驗最新模型
注意事項
- 🧠 思考模式會增加代幣使用量
- 📏 可變代幣限制依模型而異
- 🌐 需要網際網路連線
選擇合適的提供者
| 提供者 | 最適合 | 品質 | Cost | 設定 | 隱私 |
|---|---|---|---|---|---|
| Ollama | 隱私/離線 | 變數* | Free | 進階 | 本地 |
| OpenAI | 最高品質 | ⭐⭐⭐⭐⭐ | 💰💰💰 | Easy | 雲端 |
| 克勞德 | 創意內容 | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Easy | 雲端 |
| DeepSeek | 預算專案 | 四星 | 💰 | Easy | 雲端 |
| Gemini | 多語言 | ⭐⭐⭐⭐ | 💰 | Easy | 雲端 |
*Ollama 的品質會因所使用的本地模型而有顯著差異——一些現代本地模型可以匹配甚至超越雲端提供商。
提供者配置提示
適用於所有雲端服務供應商:
- 安全儲存 API 金鑰,不要將其提交至版本控制
- 從保守的溫度設定(0.3)開始,以獲得一致的翻譯結果
- 監控你的 API 使用量與成本
- 在大規模翻譯前先以小批量測試
對於 Ollama:
- 確保足夠的記憶體(建議8GB以上,用於較大型號)
- 使用SSD儲存以獲得更好的模型加載效能
- 考慮使用GPU加速以獲得更快的推論速度
- 在依賴它進行生產翻譯之前,先在本地測試