如何使用此插件
本指南涵蓋完整的執行時期 API:建立 LLM 實例、載入模型、發送訊息、在執行時期下載模型、管理狀態以及實用函式。
建立一個 LLM 實例
首先建立一個 Runtime Local LLM 物件。請保留對它的參考(例如在 Blueprint 中作為變數,或在 C++ 中作為 UPROPERTY),以避免過早被垃圾回收。
- 藍圖
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
載入模型
您必須先載入模型才能發送訊息。此插件根據您的工作流程提供多種載入方式。
按名稱載入
如果您透過編輯器設定面板管理模型,請使用 Load Model (By Name)。
- 藍圖
- C++
- UE 5.3 及更早版本
- UE 5.4+
在 UE 5.3 及更早版本中,下拉選單不會顯示,因此您需要手動擷取可用的模型。使用 Get All Downloaded Model Metadata,取得索引 0 的元素(或您需要的任何模型),將其傳遞給 Get Model File Name 以擷取名稱字串,然後將該名稱傳遞給 Load Model (By Name)。
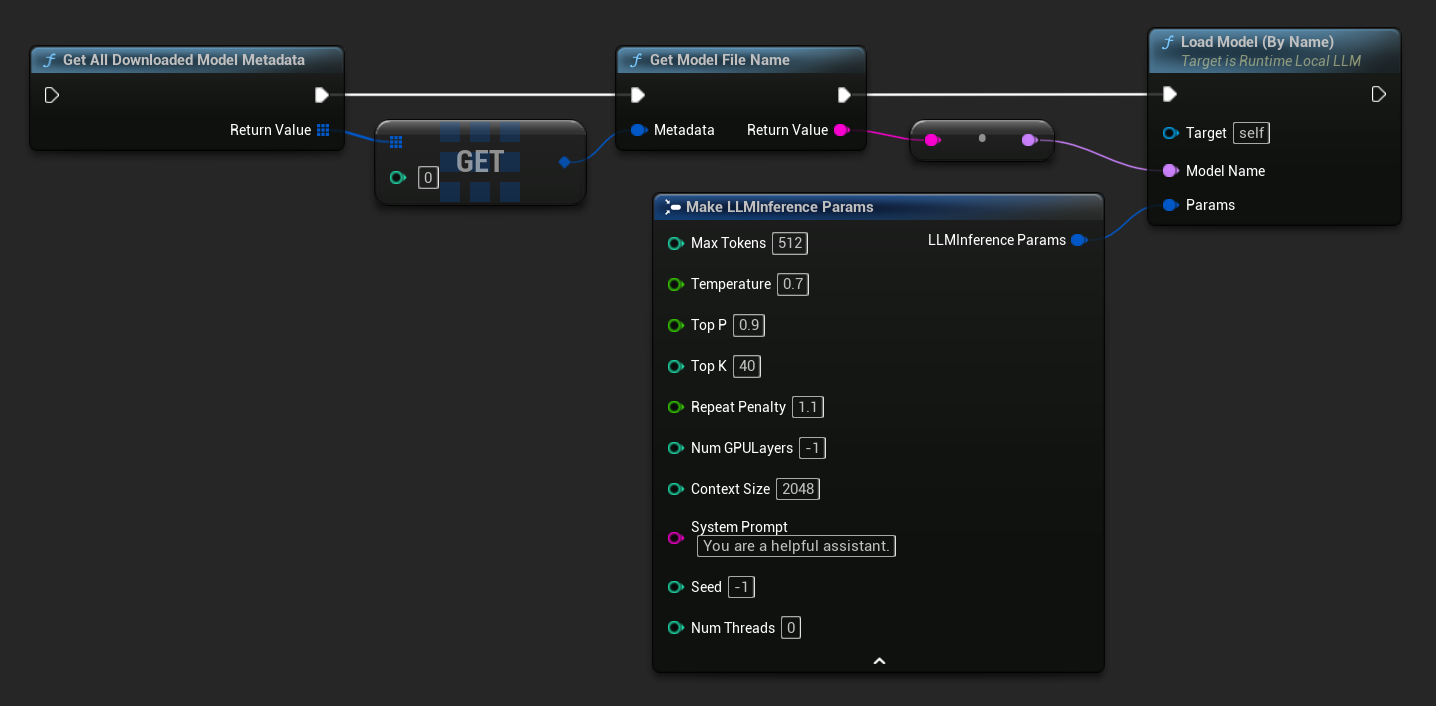
在 UE 5.4 及更新版本中,Load Model (By Name) 會顯示磁碟上所有模型的選單——只需選取您要載入的模型即可。
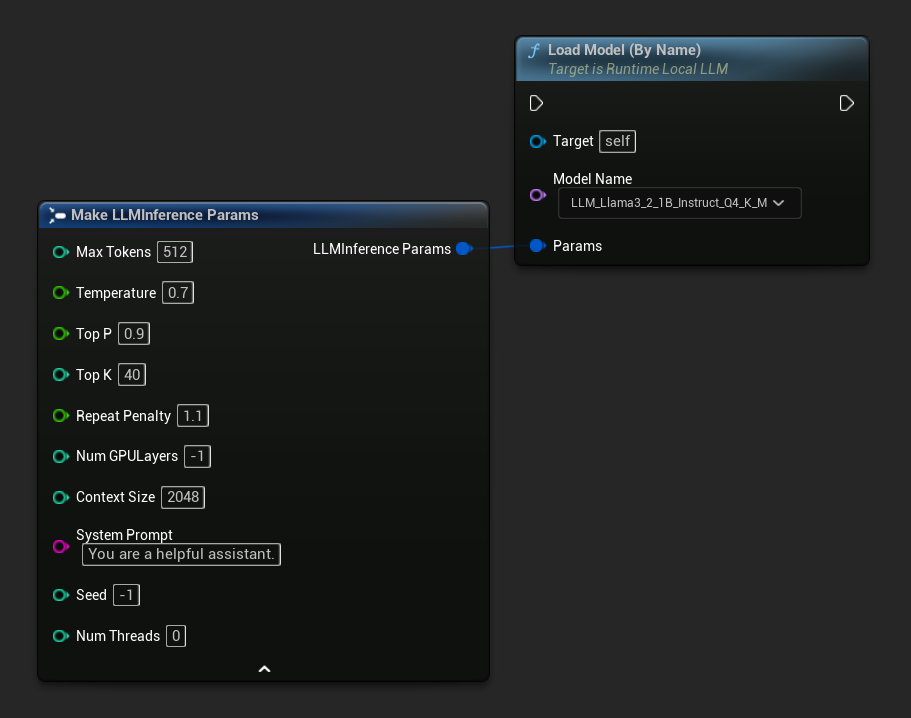
在 C++ 中,使用 GetAllDownloadedModelMetadata 來取得可用的模型,並使用 GetModelFileName 來獲取名稱,以傳遞給 LoadModelByName。
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
從檔案路徑載入
直接從 .gguf 檔案的絕對檔案路徑載入模型:
- 藍圖
- C++
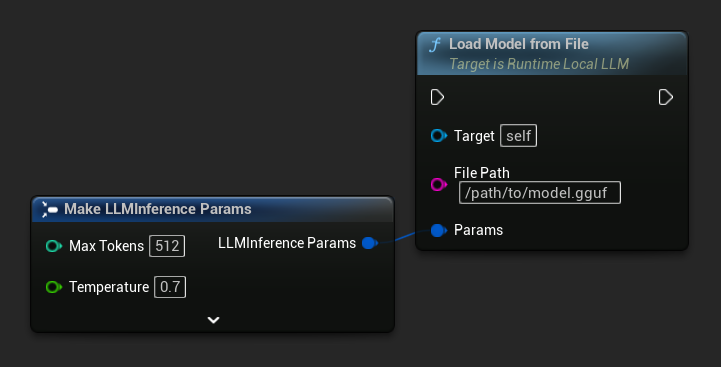
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
從 URL 載入(下載並載入)
從網址下載模型(若尚未存在於磁碟上)並自動載入。若檔案已存在於本機,則跳過下載步驟。
- 藍圖
- C++
最簡單的變體僅需一個 URL——元數據會從檔案名稱中推導出來:
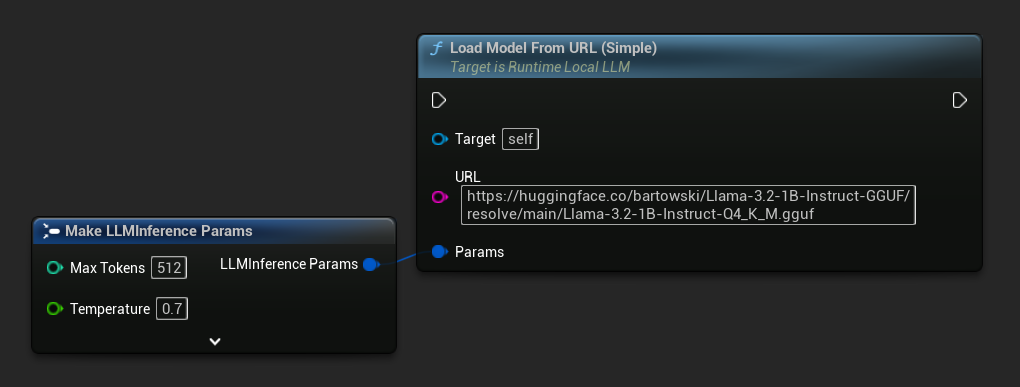
您也可以使用 Load Model From URL 搭配完整的模型元數據,以獲取更豐富的模型資訊:
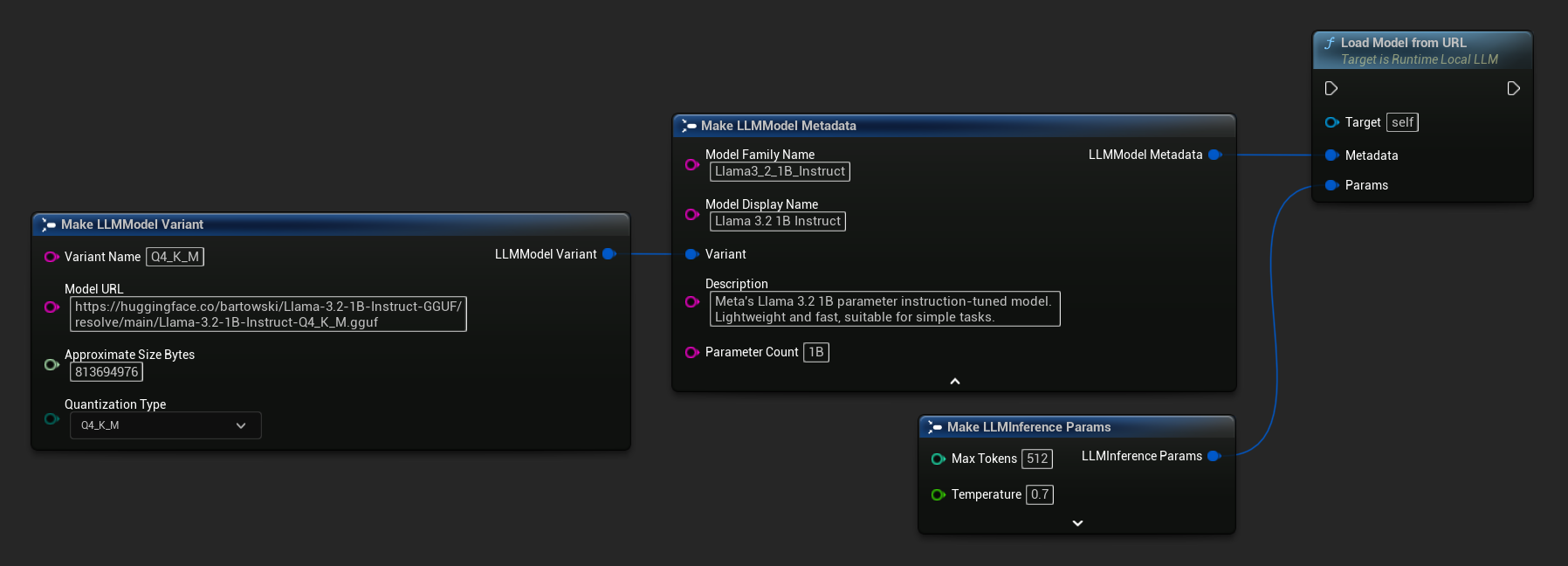
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
非同步載入(藍圖)
為了透過輸出引腳處理載入完成與錯誤,而非手動綁定委派,提供了兩個非同步節點。
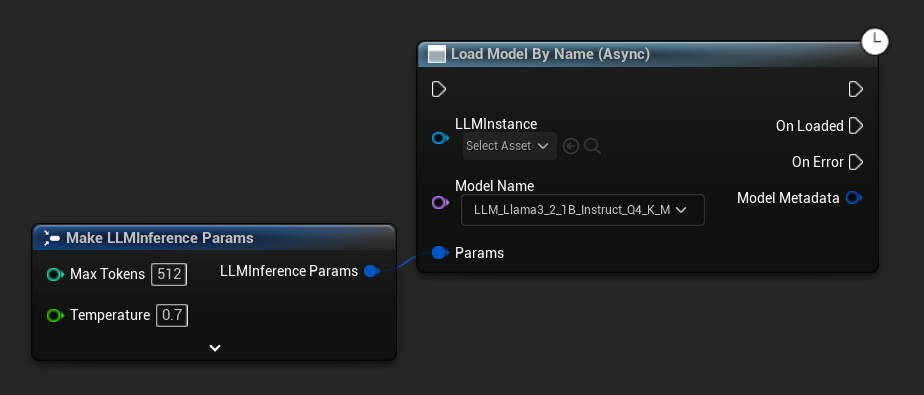
Load Model By Name (Async) 與 Load Model (By Name) 功能相同——在 UE 5.4+ 中,它會顯示磁碟上所有模型的下拉選單。
- UE 5.4+
- UE 5.3 及更早版本
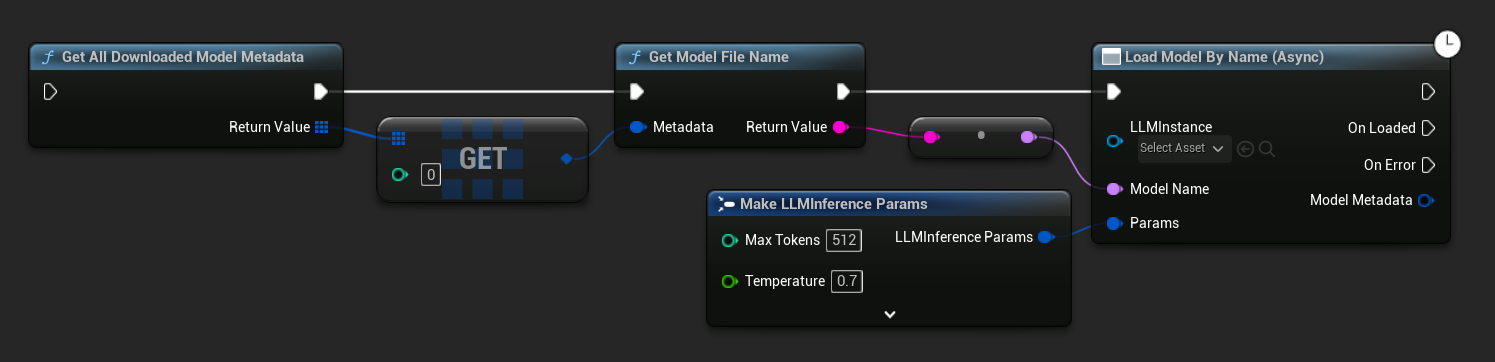
在 UE 5.3 及更早版本中,下拉選單不會顯示。請使用 Get All Downloaded Model Metadata,取得索引 0(或您需要的模型)的元素,將其傳遞給 Get Model File Name,再將結果傳遞給 Load Model By Name (Async)。
Load Model From File (Async) 改為接受絕對檔案路徑:
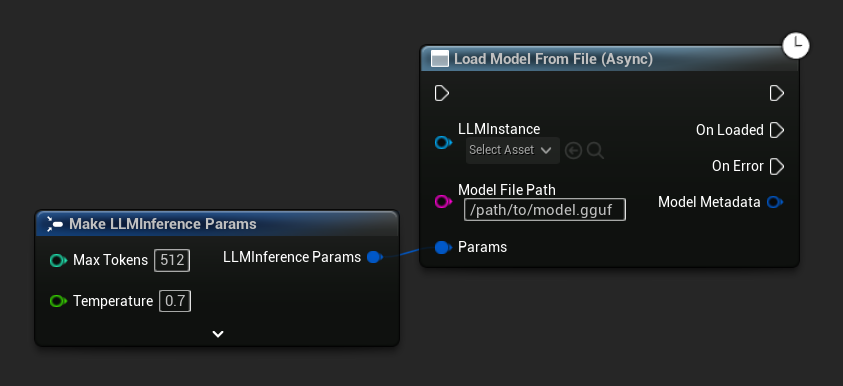
綁定事件
綁定至 LLM 實例的委派以接收回呼。所有回呼皆在遊戲執行緒上觸發。
- 藍圖
- C++
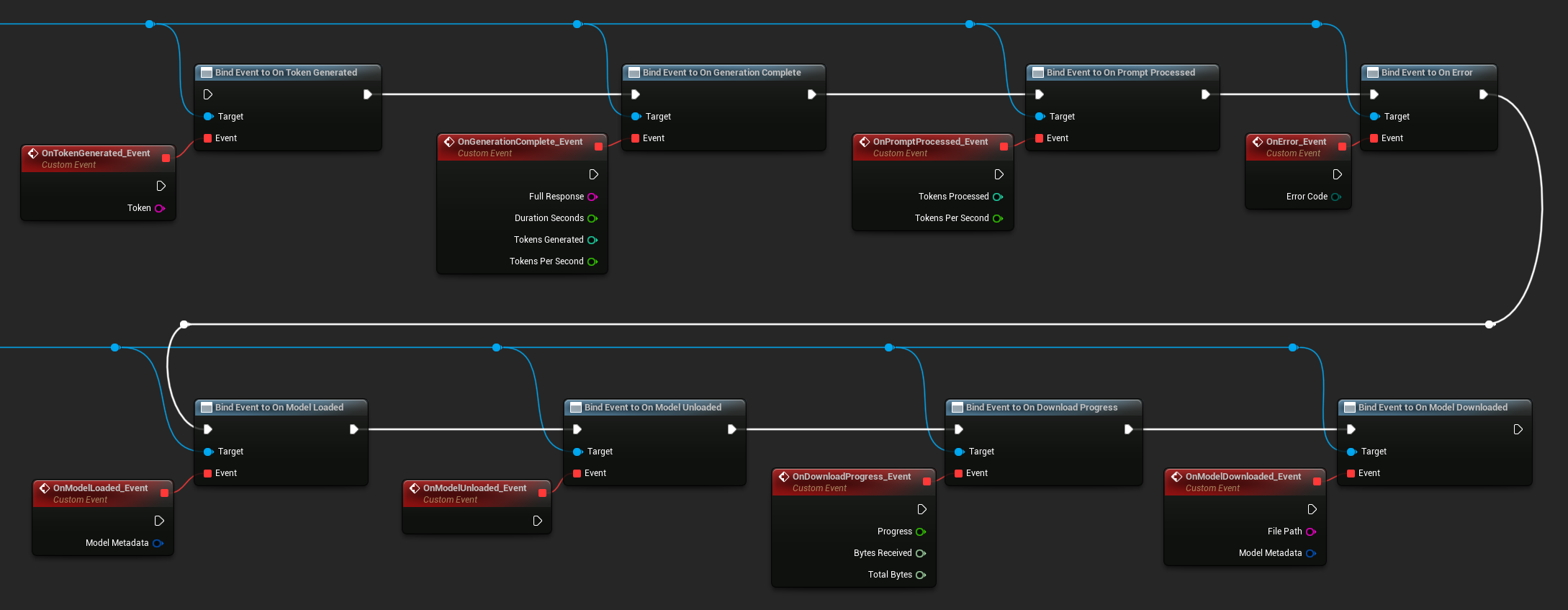
可用的委派:
- 生成 Token 時:在每個輸出 Token 產生時觸發
- 生成完成時:在完整回應準備就緒時觸發,包含持續時間、Token 數量及每秒 Token 數
- 提示處理完成時:在輸入提示處理完畢後、開始生成前觸發
- 發生錯誤時:在任何操作過程中發生錯誤時觸發
- 模型載入完成時:在模型完成載入時觸發
- 模型卸載完成時:在模型卸載時觸發
- 下載進度更新時:在模型下載過程中定期觸發(進度比例、已接收位元組、總位元組數)
- 模型下載完成時:在僅下載操作完成時觸發
- 對話儲存完成時:在對話已寫入 JSON 檔案時觸發
- 對話載入完成時:在對話已從檔案或記憶體快照載入時觸發
- 歷史記錄摘要完成時:在自動摘要壓縮較舊訊息時觸發(回報訊息數量、節省的 Token 數及摘要內容)
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda(
[](const FString& FullResponse, float DurationSeconds, int32 TokensGenerated, float TokensPerSecond)
{
});
LLM->OnPromptProcessedNative.AddLambda([](int32 TokensProcessed, float TokensPerSecond)
{
});
LLM->OnErrorNative.AddLambda([](ELLMErrorCode ErrorCode)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnModelUnloadedNative.AddLambda([]()
{
});
LLM->OnDownloadProgressNative.AddLambda([](float Progress, int64 BytesReceived, int64 TotalBytes)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& FilePath, const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnConversationSavedNative.AddLambda([](const FString& FilePath)
{
});
LLM->OnConversationLoadedNative.AddLambda([](const FLLMConversationSnapshot& Snapshot)
{
});
LLM->OnHistorySummarizedNative.AddLambda([](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
});
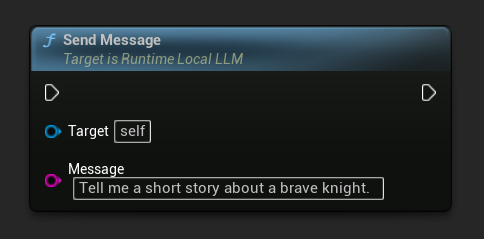
發送訊息
模型載入後,傳送使用者訊息以產生回應:
- 藍圖
- C++
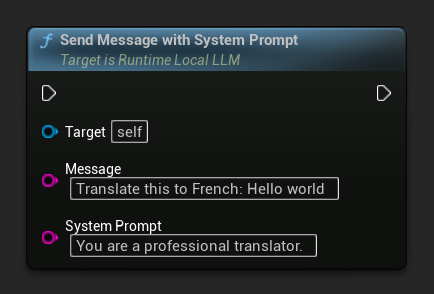
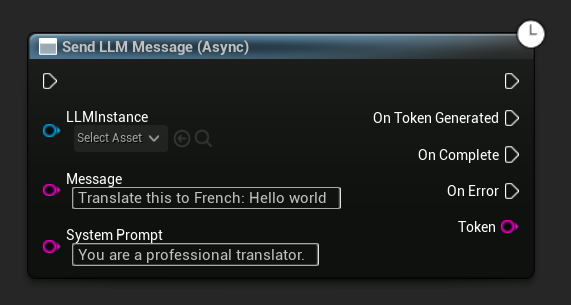
若要為特定訊息覆寫系統提示,請使用 Send Message With System Prompt:
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
當生成進行時,Token 會透過 OnTokenGenerated 串流傳遞。當生成完成時,OnGenerationComplete 會觸發,並提供完整回應、持續時間、Token 數量以及每秒 Token 數。
非同步發送訊息(藍圖)
Send LLM Message (Async) 節點提供專用的輸出引腳,分別用於處理 Token、完成狀態及錯誤訊息。
在執行階段下載模型
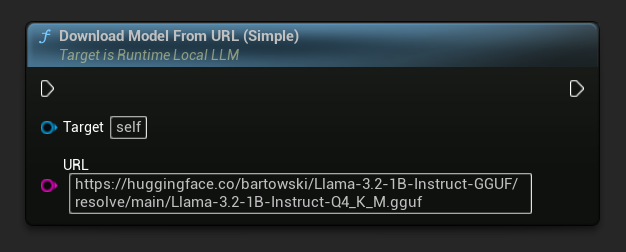
除了上述的下載並載入流程外,您也可以將模型下載至磁碟而不載入。這對於在載入畫面或設定選單中預先快取模型非常實用。
- 藍圖
- C++
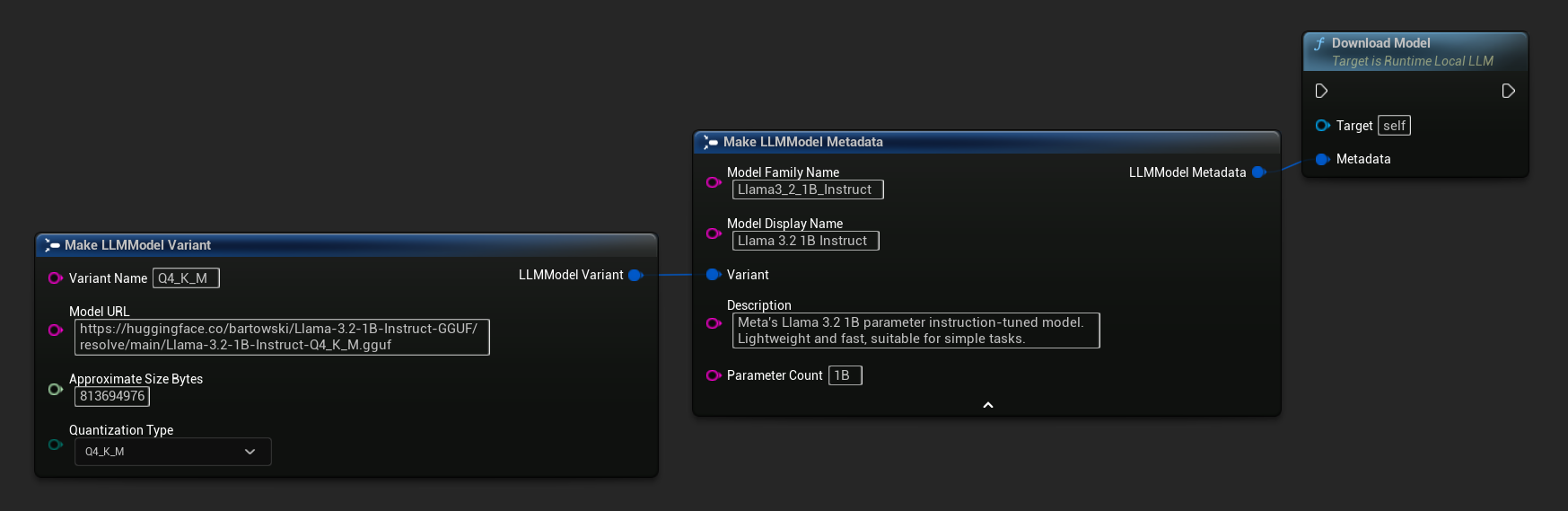
僅提供 URL 的變體也可使用。
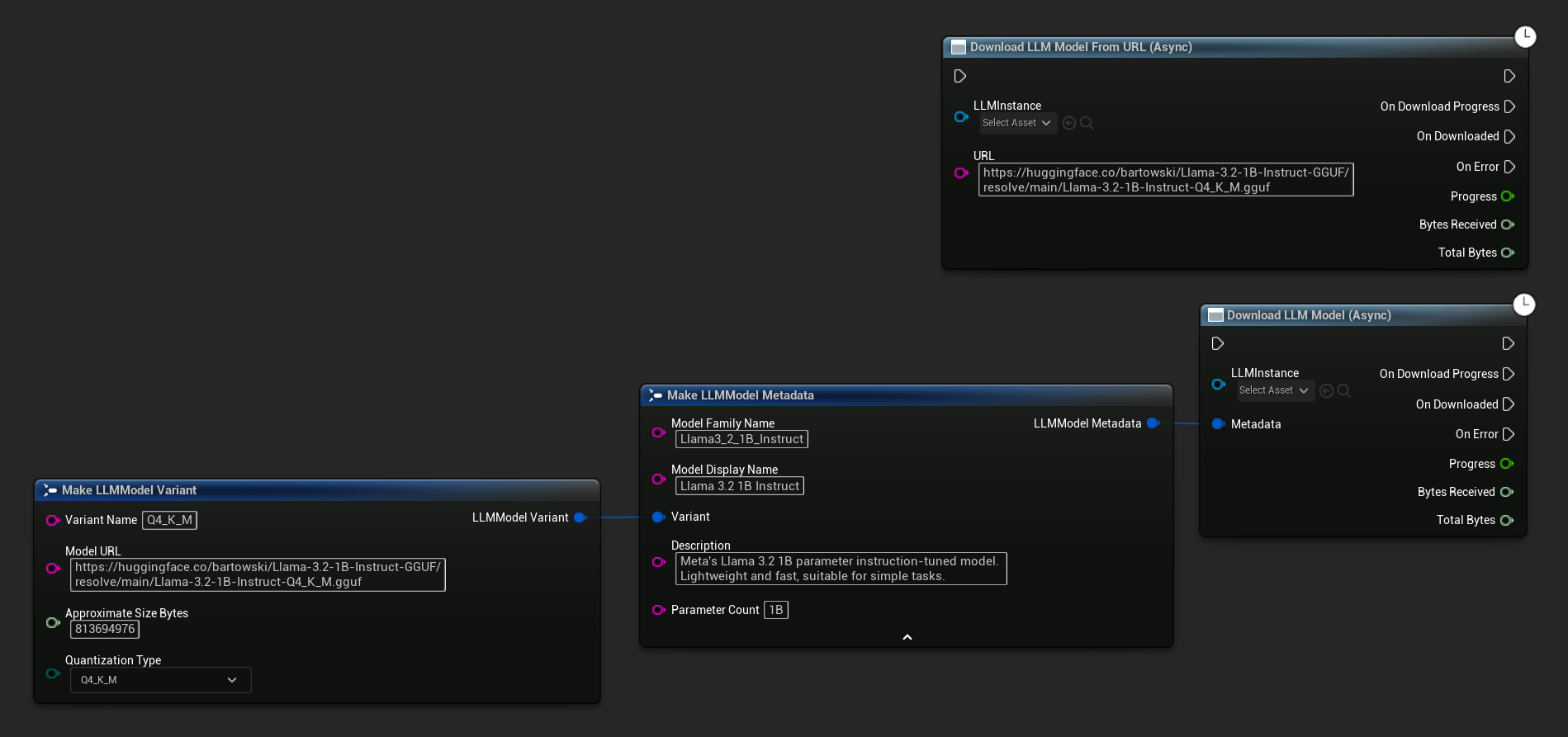
下載 LLM 模型(非同步) 和 從 URL 下載 LLM 模型(非同步) 節點提供了用於進度、完成和錯誤的輸出引腳:
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
OnDownloadProgress 委派會回報下載過程中的進度。當檔案儲存至磁碟時,會觸發 OnModelDownloaded。
若要取消正在進行中的下載:
- 藍圖
- C++
LLM->CancelDownload();
外掛程式會自動防止重複下載——如果同一個模型的下載已在進行中,後續的呼叫將會被忽略。
停止生成
若要中斷正在進行的生成:
- 藍圖
- C++
LLM->StopGeneration();
重置對話上下文
清除對話歷史以開始新對話:
- 藍圖
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
儲存與載入對話
外掛程式可將對話歷史記錄以 JSON 格式持久化儲存至磁碟,或保留在記憶體中作為快照。預設情況下,系統提示詞不會被儲存,因此相同的對話歷史可載入至不同的大型語言模型實例中,並搭配不同的系統規則。這在多 NPC 場景中相當實用,每個角色擁有各自的記憶,但系統指令可以共用或有所差異。
儲存至檔案
將當前對話儲存為磁碟上的 JSON 檔案:
- 藍圖
- C++
包含系統提示詞參數控制系統訊息(若存在)是否寫入檔案。預設值為 false,以確保在不同 NPC 之間的可攜性。
對話已儲存 會在檔案寫入時觸發。
// Excludes system prompt by default
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"));
// Include the system prompt in the file
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"), /*bIncludeSystemPrompt=*/ true);
從檔案載入
從 JSON 檔案載入對話記錄:
- 藍圖
- C++
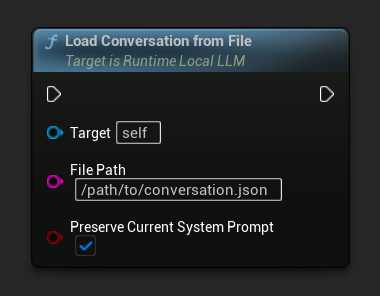
保留當前系統提示 參數(預設為 true)可在載入已儲存的對話歷史時,保持當前系統提示不變。這是 NPC 記憶交換的建議設定。
On Conversation Loaded 在載入快照時觸發。
// Keep current system prompt, swap in the saved history
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"));
// Replace the system prompt with whatever's in the file
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"), /*bPreserveCurrentSystemPrompt=*/ false);
記憶體內快照(多 NPC 工作流程)
為了在遊戲過程中快速切換 NPC,請將當前對話快照儲存於記憶體中,而非寫入磁碟。此模式是管理多個 NPC 共享單一已載入模型的建議做法:
- 藍圖
- C++
典型的多人 NPC 模式會在 NPC 管理器或遊戲狀態中使用一個 名稱 → LLM 對話快照 的映射表:
- 切換離開 NPC 時:呼叫
Save Conversation To Memory,然後在On Conversation Loaded(此事件也會在快照傳送時觸發)中,將快照以 NPC 名稱為鍵值儲存到你的地圖中。 - 切換到另一個 NPC 時:從你的地圖中讀取快照,並在啟用
Preserve Current System Prompt的情況下呼叫Load Conversation From Memory。

由於系統提示在切換過程中會保持載入狀態,每個 NPC 的「個性」可以編碼在個別 NPC 的系統提示中(在切換後呼叫一次 Send Message With System Prompt 來更新),或是在所有 NPC 之間共享。
// Maintain per-NPC snapshots
UPROPERTY()
TMap<FName, FLLMConversationSnapshot> NPCMemories;
// Save the currently active NPC's memory before switching
LLM->OnConversationLoadedNative.AddLambda([this](const FLLMConversationSnapshot& Snapshot)
{
NPCMemories.Add(CurrentNPC, Snapshot);
});
LLM->SaveConversationToMemory();
// Activate another NPC's memory
if (const FLLMConversationSnapshot* Found = NPCMemories.Find(NextNPC))
{
LLM->LoadConversationFromMemory(*Found, /*bPreserveCurrentSystemPrompt=*/ true);
CurrentNPC = NextNPC;
}
快照與模型無關——它們儲存的是訊息,而非 KV 快取狀態。同一份快照可以載入到不同的模型中(儘管對話風格可能會有所變化)。快照上的 OriginModelFamilyName 欄位可讓您檢查是哪個模型產生了該快照,以便在需要時強制相容性。
自動上下文摘要
長時間的對話最終會超出模型的上下文視窗,這通常會導致歷史記錄被截斷或引發錯誤。該插件的自動摘要功能會監控上下文使用情況,當超過設定的閾值時,會在生成下一次回應前將較舊的訊息摘要成一條「記憶」訊息。這使得在無限長的對話中,Token 成本與延遲能保持穩定。
摘要由同一個已載入的模型執行,因此無需第二個模型或 API 呼叫。
啟用自動摘要
- 藍圖
- C++
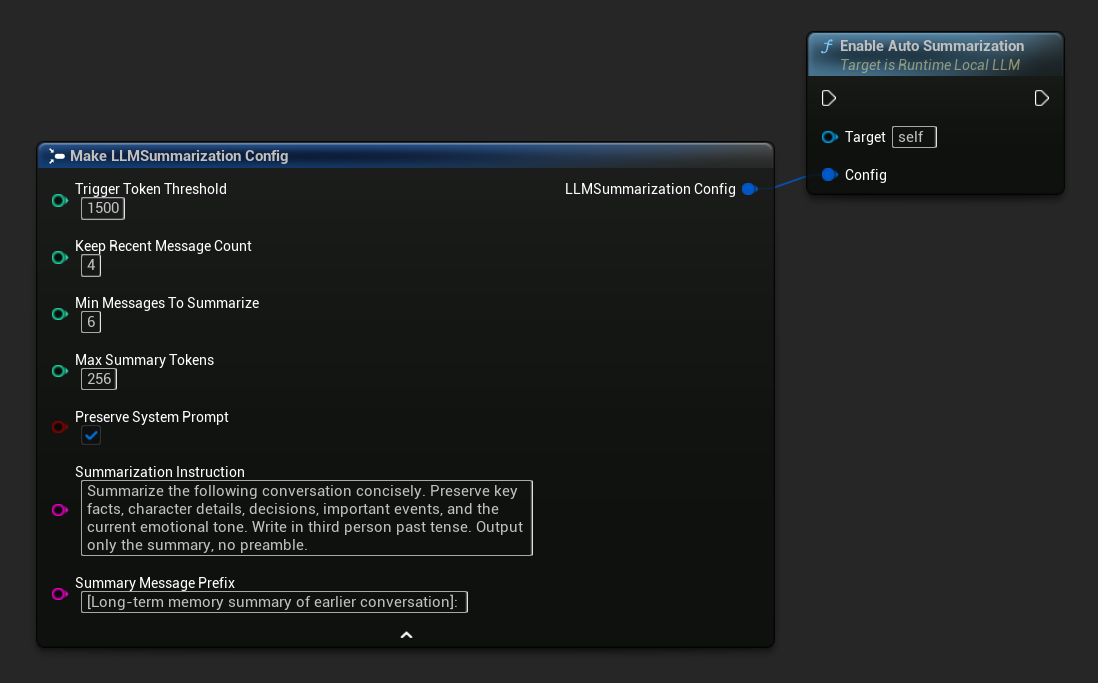
使用 Get Default Summarization Config 取得合理的起始預設值,再根據需要進行調整:
FLLMSummarizationConfig Config = URuntimeLocalLLM::GetDefaultSummarizationConfig();
Config.TriggerTokenThreshold = 1500;
Config.KeepRecentMessageCount = 4;
Config.MinMessagesToSummarize = 6;
LLM->EnableAutoSummarization(Config);
啟用後,摘要功能會在每次需要時自動於 SendMessage 呼叫前執行,無需額外操作。
預設情況下,自動摘要會在處理新訊息前執行,因為它需要重建上下文,而這無法在生成回覆的同時安全進行。如果您希望改為在回覆完成後執行(當玩家正在閱讀和輸入時),請停用自動摘要並手動驅動:繫結至 On Generation Complete,檢查 Get Used Context Length 是否超過閾值,若超過則呼叫 Summarize Now。由於 Summarize Now 會排入相同的背景工作佇列,它將在回覆完成後、下一個訊息處理前立即執行。
設定參考
| 參數 | Type | 預設 | 描述 |
|---|---|---|---|
| 觸發令牌閾值 | int32 | 1500 | 當使用的上下文 Token 超過此值時,將執行摘要功能。請根據您的「上下文大小」設定此值,一般建議設定在 60-75% 左右。 |
| 保留最近訊息數量 | int32 | 4 | 最新的 N 則訊息永遠不會被摘要,以保持即時對話的連貫性。 |
| 最少訊息數以進行摘要 | int32 | 6 | 若符合條件的較舊訊息少於此數量,則跳過摘要(避免無意義的微小摘要) |
| 最大摘要令牌數 | int32 | 256 | 生成的摘要最大長度(以 token 為單位) |
| 保留系統提示詞 | bool | true | 始終保持系統訊息(索引 0)完整不變。 |
| 摘要說明 | FString | (see default) | 傳送給模型以產生摘要的指令 |
| 摘要訊息前綴 | FString | 「[先前對話的長期記憶摘要]」: | 當生成的摘要作為助理角色的記憶訊息插入對話時,會預先附加的內容。 |
手動觸發與監聽摘要
您可以隨時手動觸發摘要,不受閾值限制:
- 藍圖
- C++
綁定至 On History Summarized,以便在摘要處理完成時收到通知。此事件會回報已移除的訊息數量、節省的 Token 數量,以及生成的摘要文字,有助於在聊天 UI 中顯示微妙的提示。
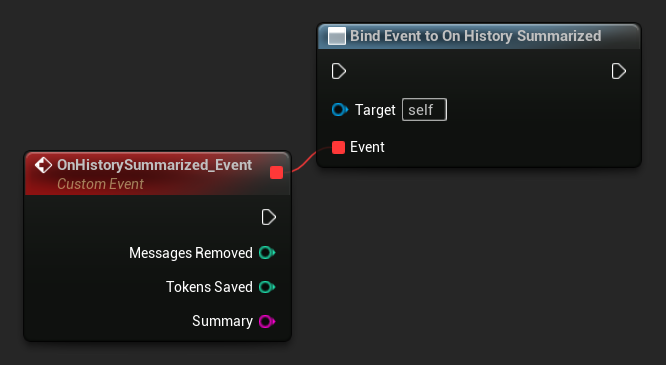
LLM->SummarizeNow();
LLM->OnHistorySummarizedNative.AddLambda(
[](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
UE_LOG(LogTemp, Log, TEXT("Summarized %d messages, saved %d tokens"), MessagesRemoved, TokensSaved);
});
查詢已使用的上下文長度
使用 Get Used Context Length 來檢查模型上下文視窗中目前佔用了多少個 Token。此數值與內建自動摘要觸發器比對 Trigger Token Threshold 時所檢查的值相同。
- 藍圖
- C++
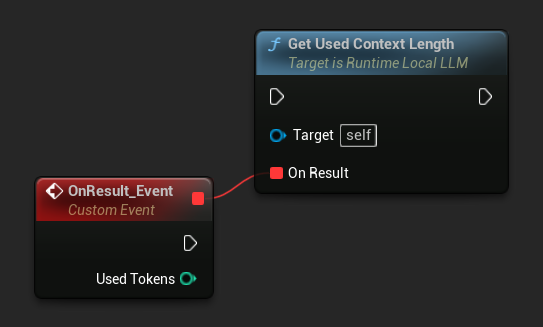
LLM->GetUsedContextLengthNative([](int32 UsedTokens)
{
UE_LOG(LogTemp, Log, TEXT("Used context: %d tokens"), UsedTokens);
});
停用自動摘要功能
- 藍圖
- C++
LLM->DisableAutoSummarization();
停用並不會撤銷已套用至對話的摘要。
摘要處理會在背景執行緒上執行一段時間(模型正在生成摘要)。在此內部生成過程中,Token 串流回呼會被抑制,因此不會顯示在您的聊天 UI 中。On History Summarized 會在拼接完成後觸發。
卸載模型
當模型不再需要時,可釋放的免費資源:
- 藍圖
- C++
LLM->UnloadModel();
查詢狀態
檢查 LLM 實例的當前狀態:
- 藍圖
- C++
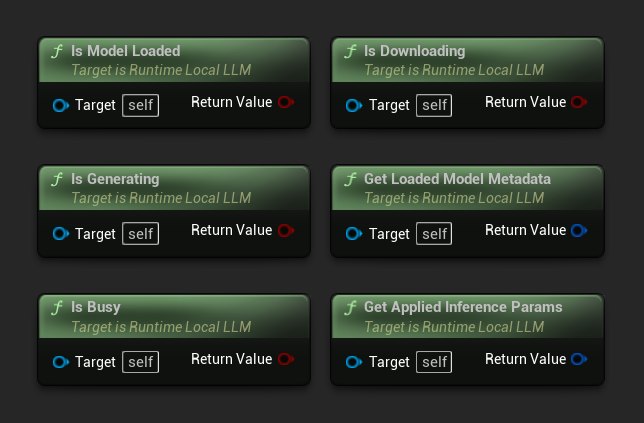
- 模型已載入:若模型已準備好進行推論,則為 True
- 正在生成中:若生成作業正在進行,則為 True
- 忙碌中:若有任何操作(載入、生成、下載)正在進行,則為 True
- 正在下載中:若模型下載正在進行,則為 True
- 取得已載入模型的中繼資料:回傳目前模型的中繼資料
- 取得已套用的推論參數:回傳載入時所套用的參數
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
模型庫功能
提供一組靜態工具函數,用於管理磁碟上的模型檔案。這些函數對於建立模型選擇介面或在執行時檢查模型可用性非常實用。
取得已下載模型名稱/元數據
- 藍圖
- C++
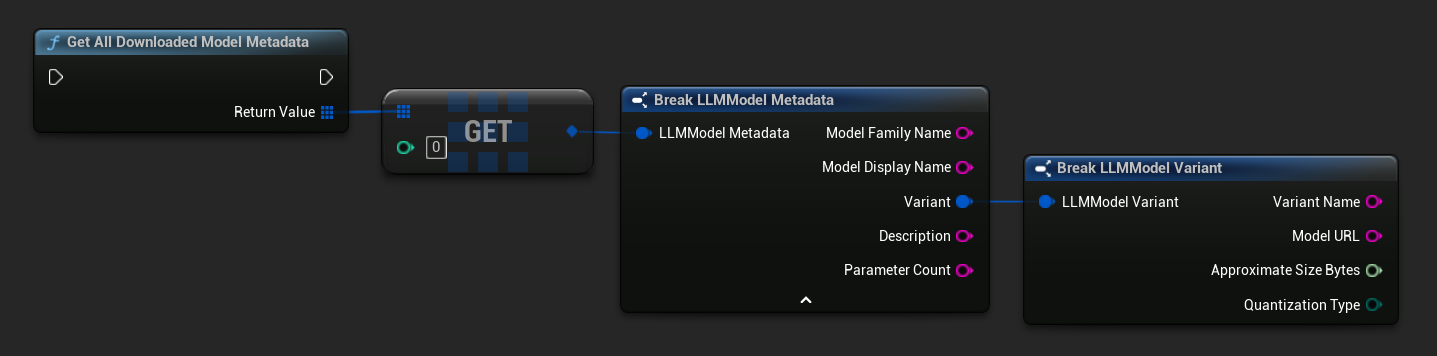
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
檢查模型是否在磁碟上
- 藍圖
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
取得模型檔案路徑
- 藍圖
- C++
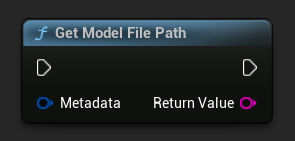
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
刪除模型檔案
- 藍圖
- C++
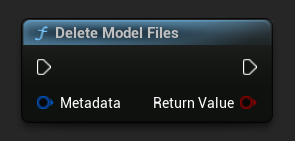
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
取得預先定義與可用的模型
- 藍圖
- C++
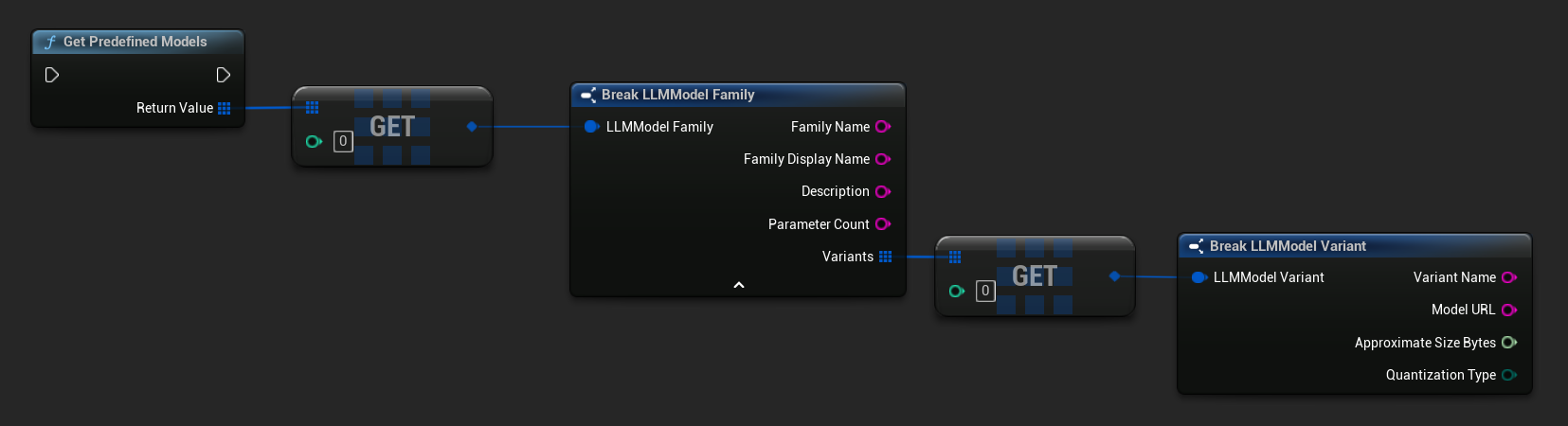
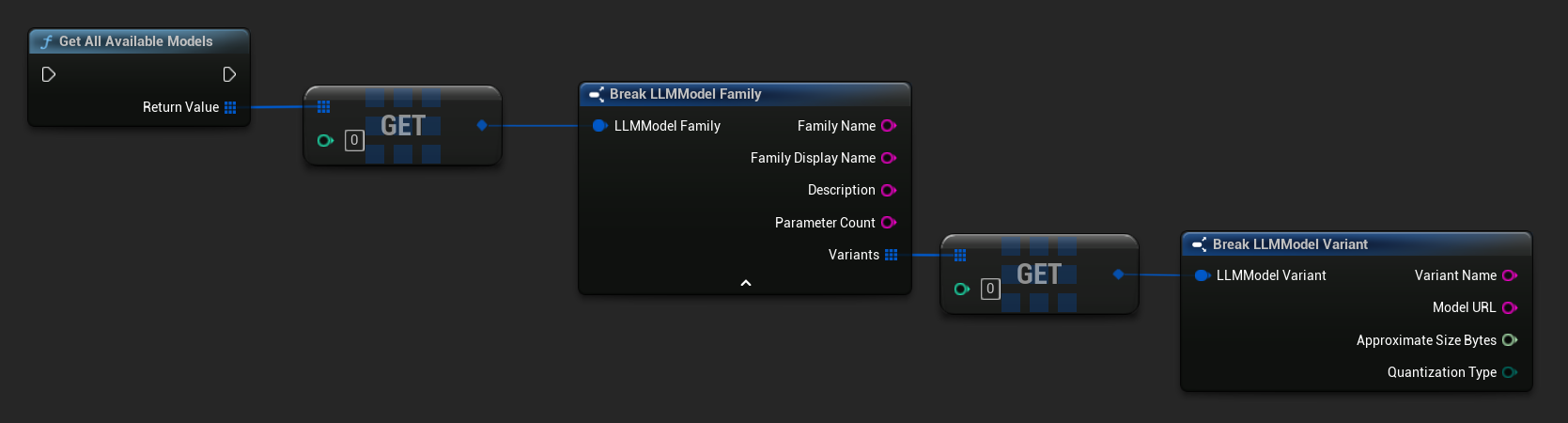
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
從 URL 建立中繼資料
從原始 URL 建構模型元資料(欄位從檔案名稱推導得出):
- 藍圖
- C++
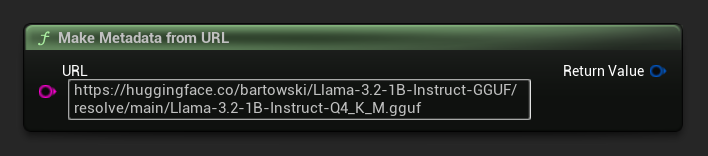
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
實用功能
提供了一組輔助函式,用於格式化與錯誤顯示。
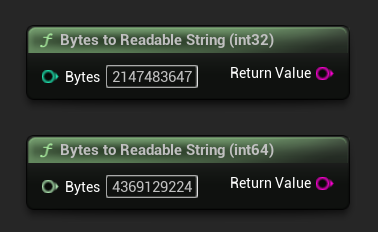
位元組轉可讀字串
將位元組數轉換為人類可讀的字串(例如「4.07 GB」)。適用於在 UI 中顯示模型大小。
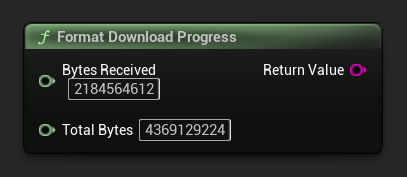
格式下載進度
格式化下載進度字串,例如「1.23 GB / 4.07 GB (30.2%)」。若總大小未知,則僅回傳已接收的量。
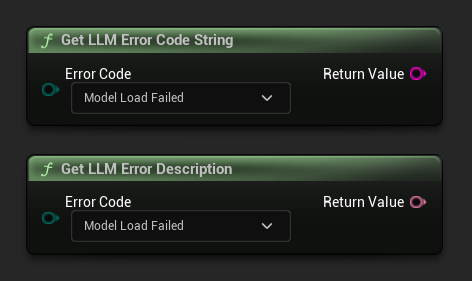
取得錯誤描述 / 錯誤代碼字串
Get LLM Error Description 會回傳錯誤代碼的人類可讀文字說明。Get LLM Error Code String 則會以字串形式回傳列舉值名稱(適用於記錄用途)。
錯誤代碼參考
| Code | 價值 | 描述 |
|---|---|---|
| 未知 | 0 | 未指定的錯誤 |
| 模型載入失敗 | 10 | GGUF 檔案載入失敗(檔案損毀、格式不相容等) |
| ContextCreateFailed | 11 | 無法建立推論上下文 |
| 模型未載入 | 20 | 嘗試進行推論時,未載入任何模型。 |
| ChatTemplateFailed | 21 | 模型的聊天模板無法套用。 |
| TokenizationFailed | 22 | 無法對輸入文字進行分詞。 |
| ContextOverflow | 23 | 提示詞加上上下文已超過設定的上下文大小。 |
| 提示解碼失敗 | 24 | 提示令牌解碼失敗。 |
| ContextTooFullToGenerate | 25 | 剩餘的上下文空間不足以產生輸出。 |
| GenerationDecodeFailed | 30 | 生成過程中,一個令牌解碼失敗。 |
| GenerationTruncated | 31 | 生成已停止,因為已達到最大 token 限制。 |
| LLMInstanceNull | 40 | LLM 實例為空或無效 |
| ModelNotFoundOnDisk | 41 | 模型檔案不存在於預期路徑。 |
| ModelURLEmpty | 42 | 下載請求使用了空的 URL。 |
| 模型下載已取消 | 43 | 下載已取消。 |
| 模型下載無資料 | 44 | 下載已完成,但回應內容為空。 |
| 模型下載儲存失敗 | 45 | 下載已完成,但檔案無法儲存至磁碟。 |