推論參數
LLM 推論參數結構控制模型載入與文字生成的方式。您可在載入模型時傳入這些參數。本頁面將說明每個參數及其作用。
參數參考
| 參數 | Type | 預設 | 範圍 | 描述 |
|---|---|---|---|---|
| 最大令牌數 | int32 | 512 | 1–8192 | 單一回應中可生成的最大 Token 數量 |
| 溫度 | float | 0.7 | 0.0–2.0 | 控制隨機性。0.0 = 確定性。數值越高,輸出越具創造力。 |
| Top P | float | 0.9 | 0.0–1.0 | 核取樣。僅考慮累積機率超過此值的標記。 |
| Top K | int32 | 40 | 0–200 | 將選擇範圍限制在機率最高的前 K 個標記。0 = 停用 |
| 重複懲罰 | float | 1.1 | 0.0–3.0 | 懲罰已在輸出中出現的標記。1.0 = 無懲罰 |
| GPU 層數 | int32 | -1 | -1 至 200 | 模型層級卸載至 GPU。-1 = 自動。0 = 僅限 CPU。 |
| 上下文大小 | int32 | 2048 | 128–131072 | 最大上下文視窗(以 token 為單位)。數值越大,使用的記憶體越多。 |
| 系統提示 | FString | 「你是一位有用的助手。」 | — | 塑造模型行為的系統指令 |
| 種子 | int32 | -1 | -1 | 隨機種子,用於產生可重現的輸出。-1 = 隨機。 |
| 執行緒數量 | int32 | 0 | 0–128 | 生成用的 CPU 執行緒數。0 = 自動 |
用法
- 藍圖
- C++
推論參數在載入和非同步節點上以結構體引腳的形式出現。將結構體拆開以設定個別數值:
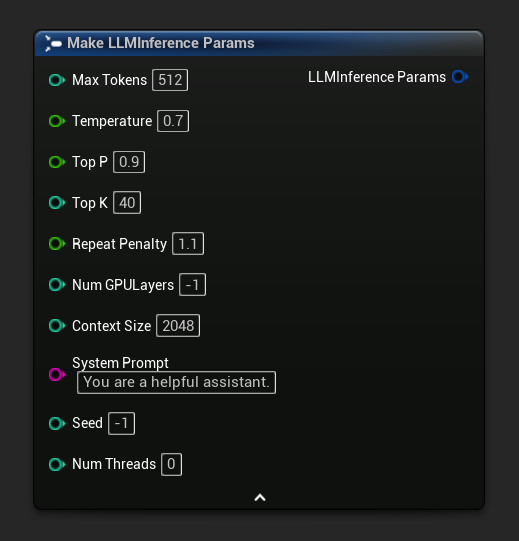
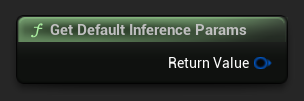
若要取得一組預設參數作為起點,請使用 Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
平台建議
行動裝置 / VR(Android、iOS、Meta Quest)
- 上下文大小:1024–2048
- GPU 層數:0(僅限 CPU),除非裝置已確認支援 GPU 運算
- 最大 Token 數:低於 256 以確保互動反應迅速
- 執行緒數:2–4,視裝置而定
桌面(Windows、Mac、Linux)
- 上下文大小:大多數對話為 2048–8192
- GPU 層數:-1(自動)以在可用時利用 GPU 加速
- 執行緒數:0(自動)
- 最大 Token 數:512–2048 以獲得較長回應
長時間對話
若您的應用程式需在長時間對話中維持上下文(如NPC對話、持續性助手、角色扮演),建議將上下文大小與自動摘要功能搭配使用,而非單純增加Context Size。啟用自動摘要後,設定適中的Context Size(2048–4096)即可穩定控制延遲與記憶體使用量;反之,過大的上下文視窗會導致每次生成速度逐漸變慢。詳情請參閱自動上下文摘要。