音訊處理指南
本指南說明如何設定不同的音訊輸入方法,將音訊資料提供給您的嘴型同步生成器。在繼續之前,請確保您已完成設定指南。
音訊輸入處理
您需要設定一種處理音訊輸入的方法。根據您的音訊來源,有幾種方式可以做到這一點。
- 麥克風(即時)
- 麥克風(播放)
- 文字轉語音(本地)
- 文字轉語音(外部 API)
- 從音訊檔案/緩衝區
- 串流音訊緩衝區
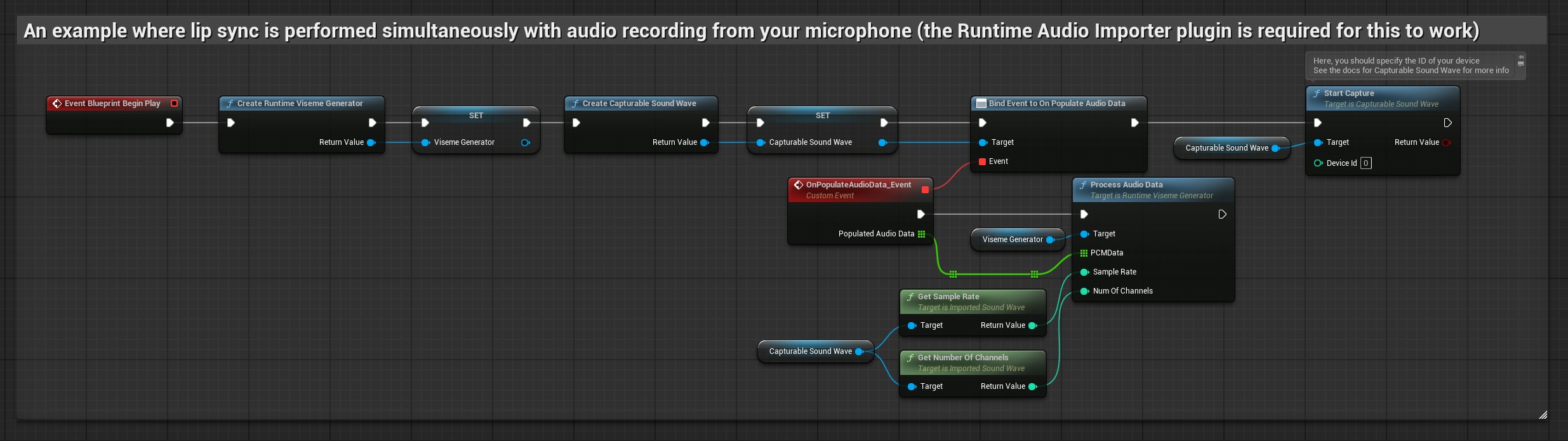
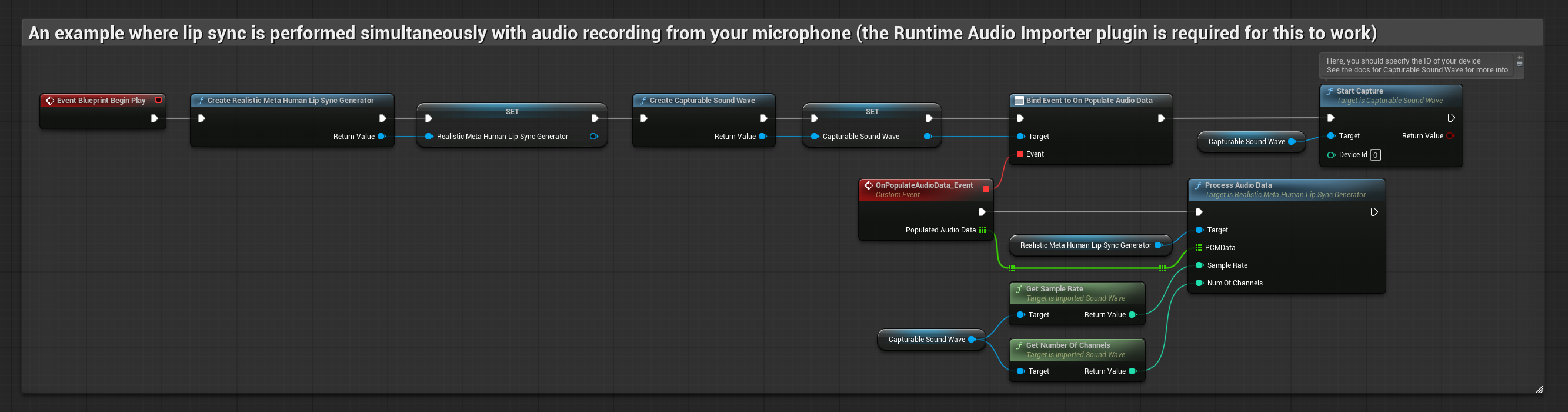
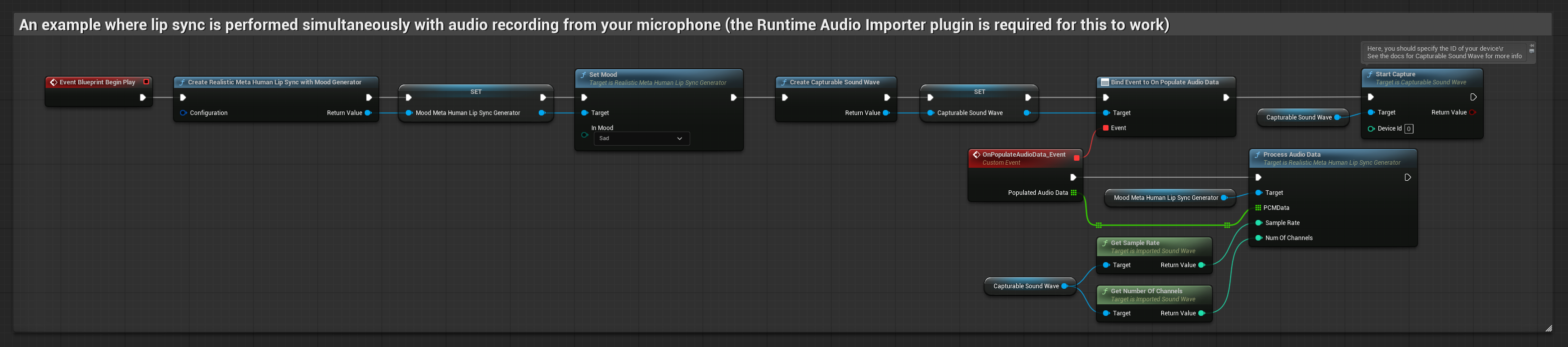
此方法在對著麥克風說話時即時執行嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime Audio Importer 建立一個 Capturable Sound Wave
- 對於使用 Pixel Streaming 的 Linux,請改用 Pixel Streaming Capturable Sound Wave
- 在開始捕捉音訊之前,綁定到
OnPopulateAudioData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData - 開始從麥克風捕捉音訊
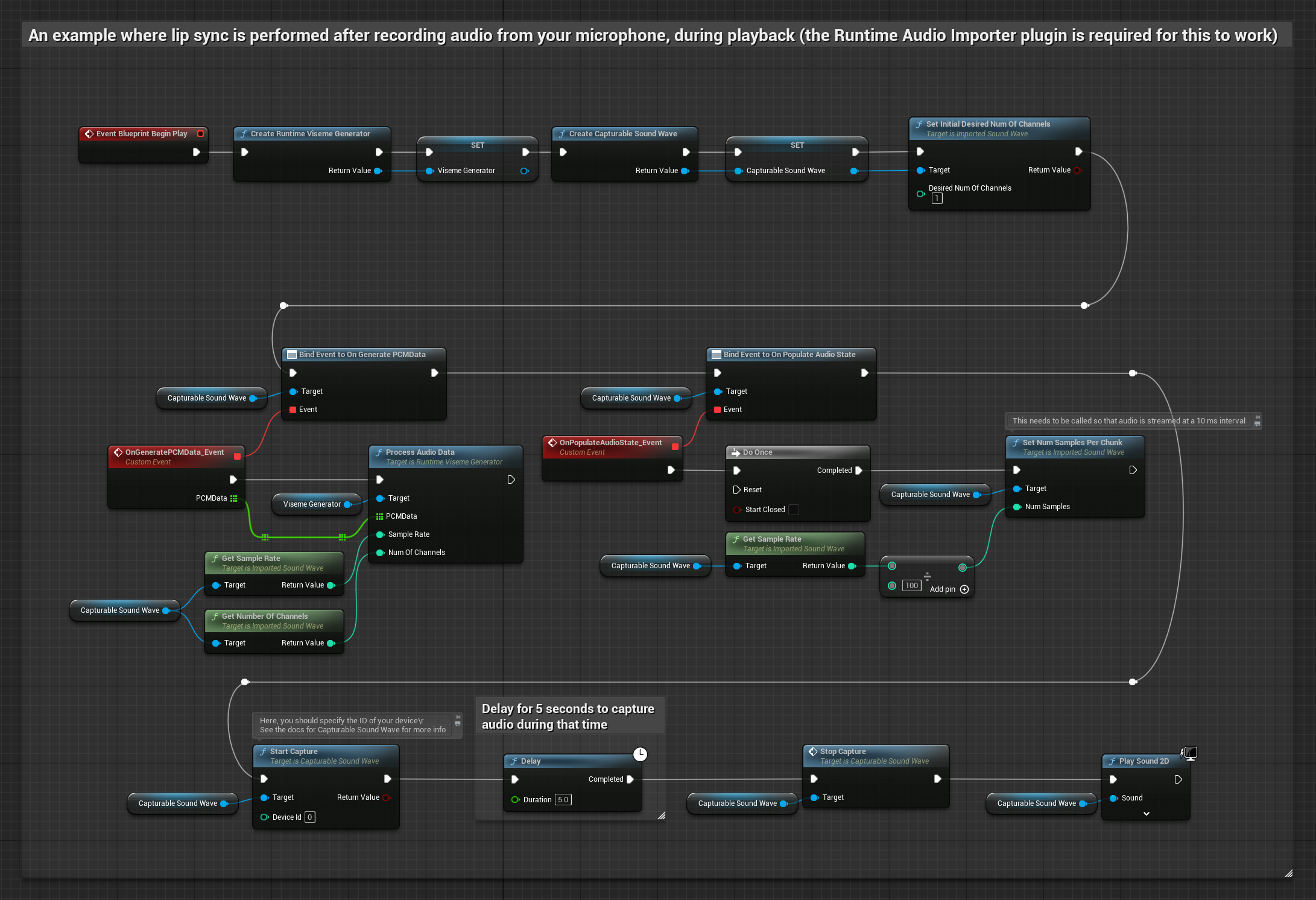
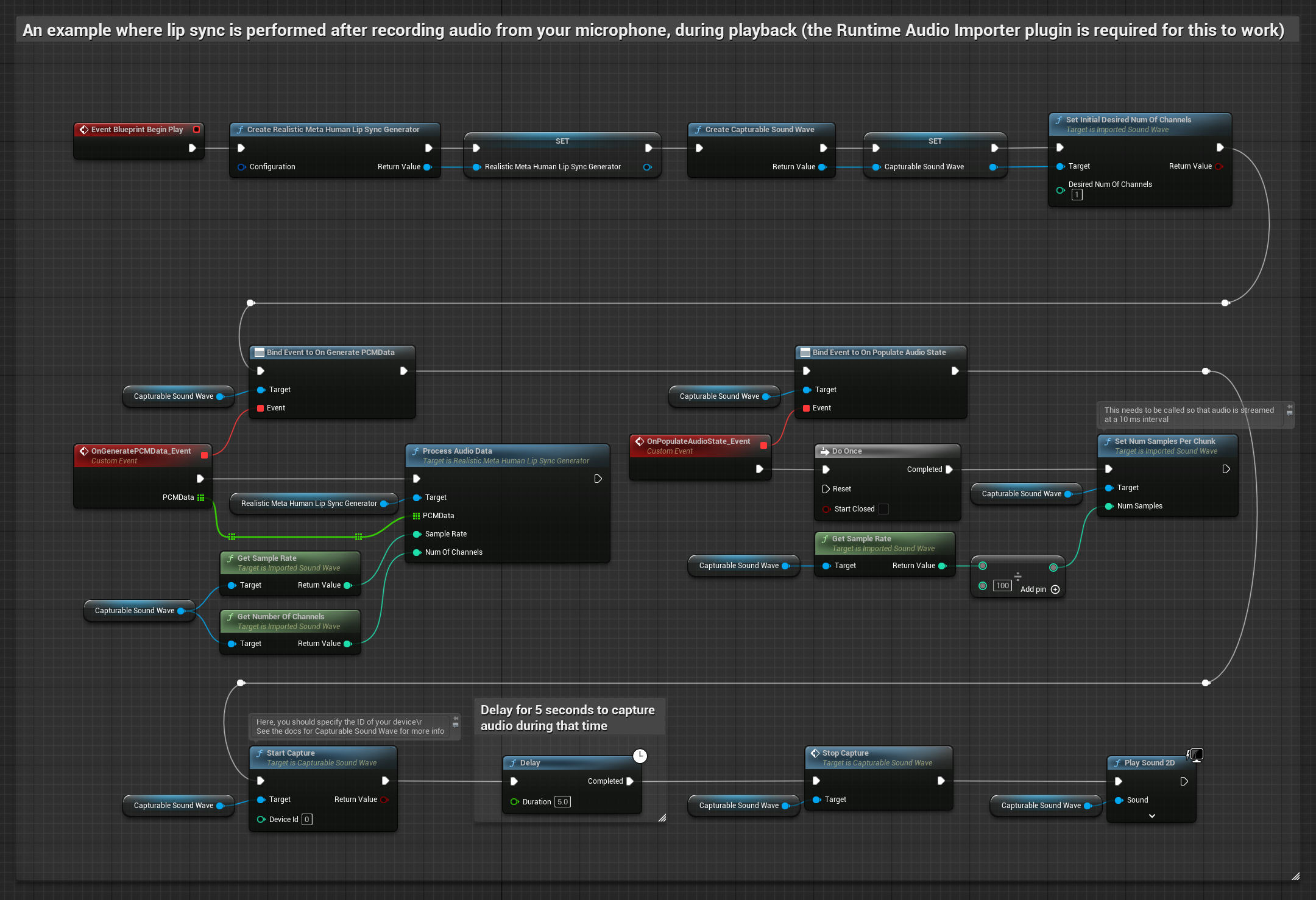
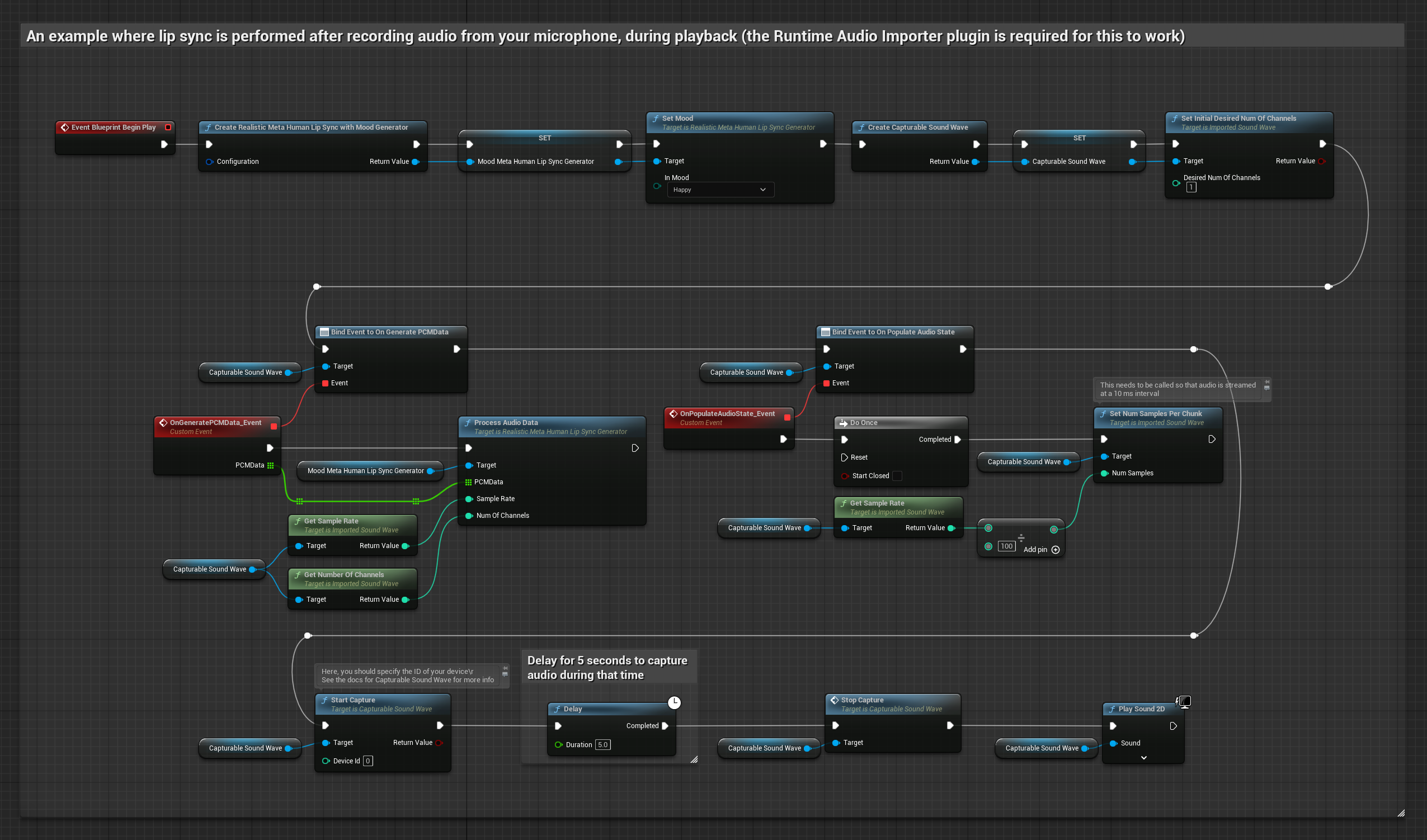
此方法從麥克風捕捉音訊,然後在播放時進行嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime Audio Importer 建立一個 Capturable Sound Wave
- 對於使用 Pixel Streaming 的 Linux,請改用 Pixel Streaming Capturable Sound Wave
- 開始從麥克風捕捉音訊
- 在播放可捕捉音波之前,綁定到其
OnGeneratePCMData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData
- 一般
- 串流
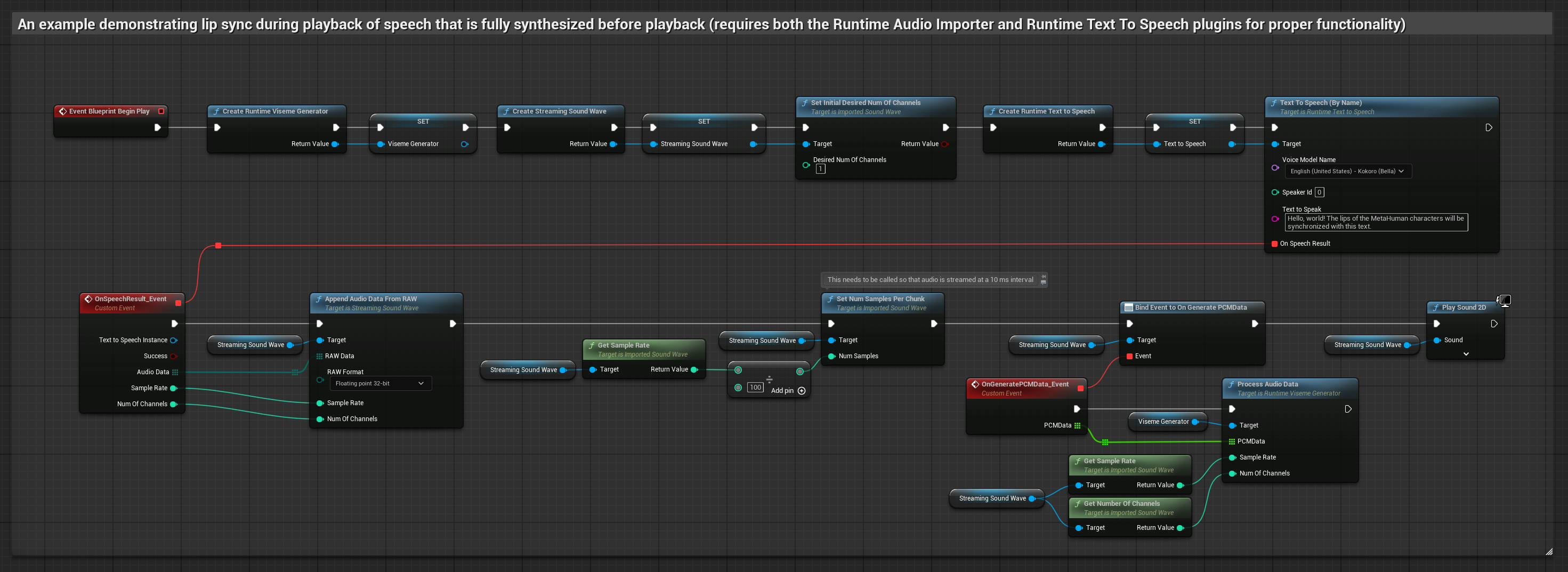
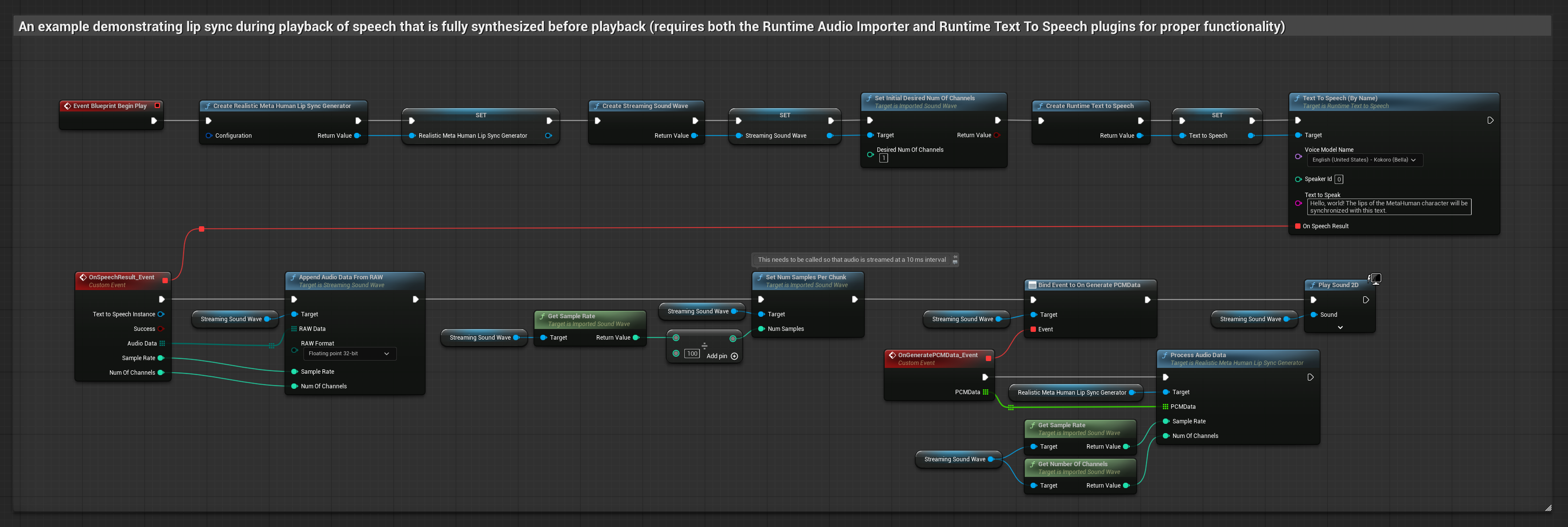
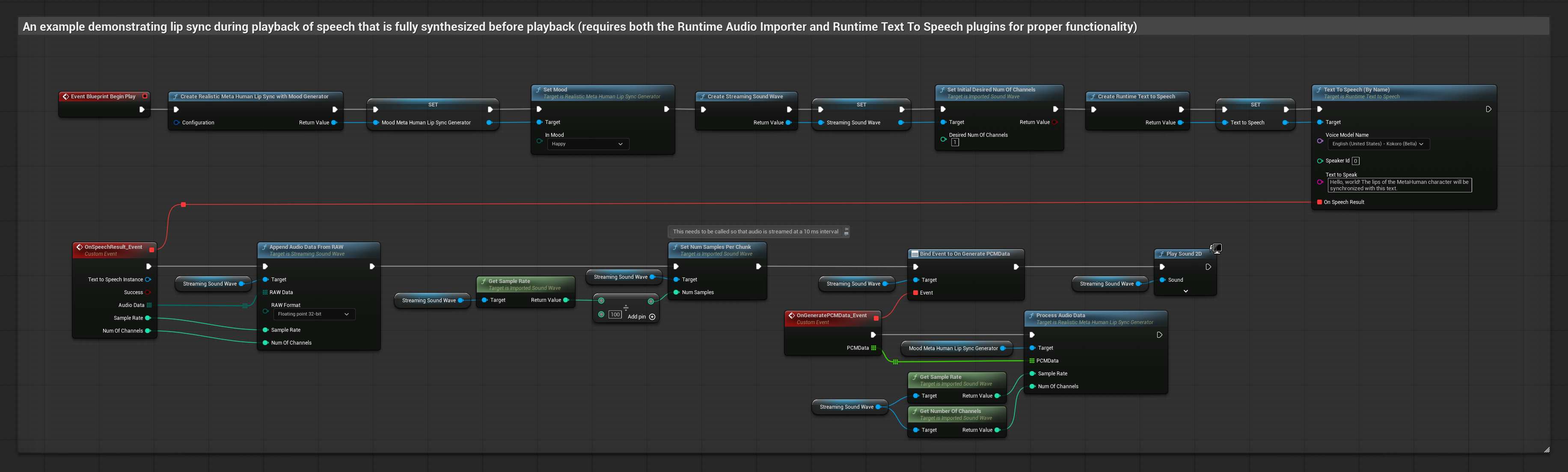
此方法使用本地 TTS 從文字合成語音並執行嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime Text To Speech 從文字生成語音
- 使用 Runtime Audio Importer 匯入合成的音訊
- 在播放匯入的音波之前,綁定到其
OnGeneratePCMData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData
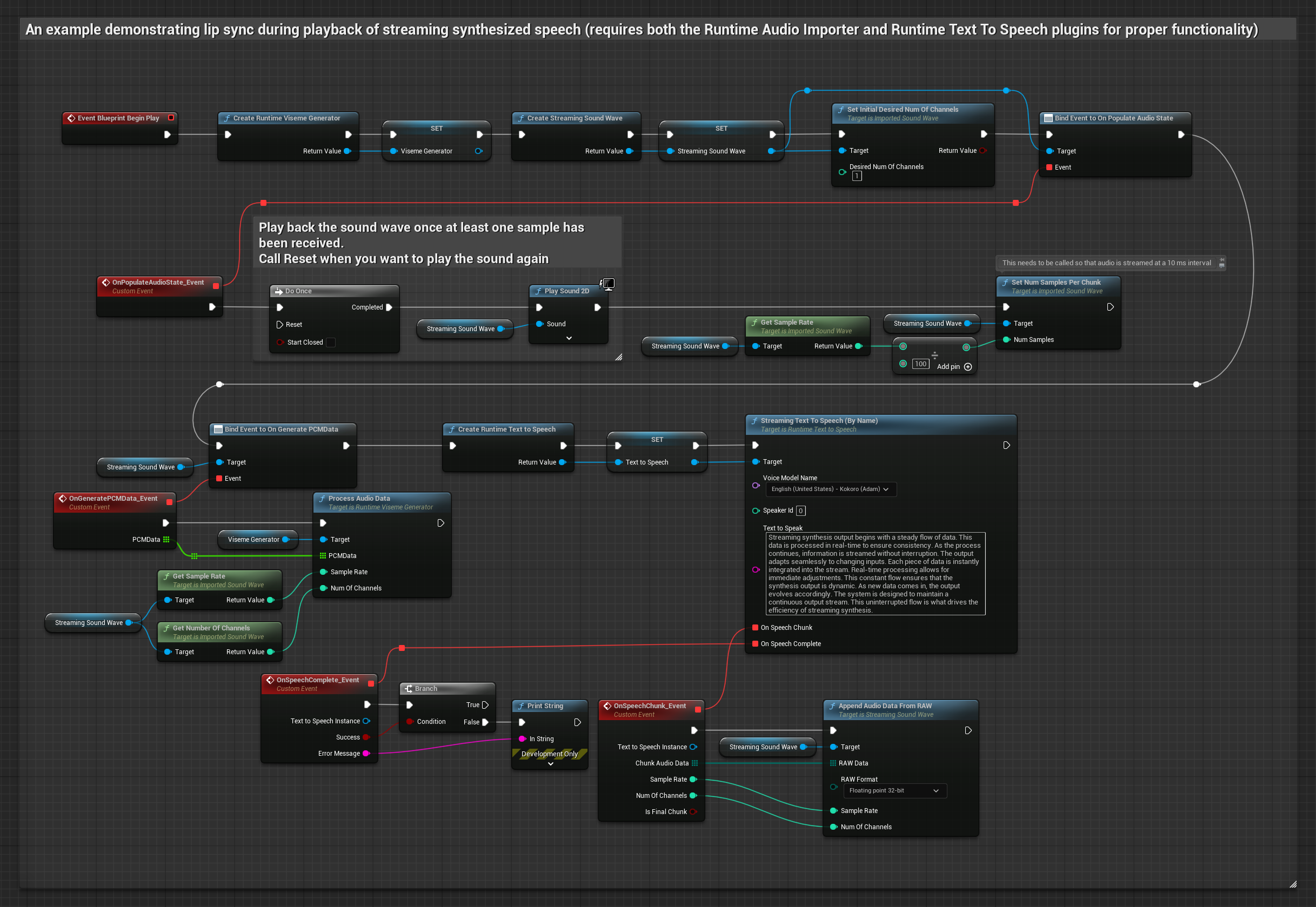
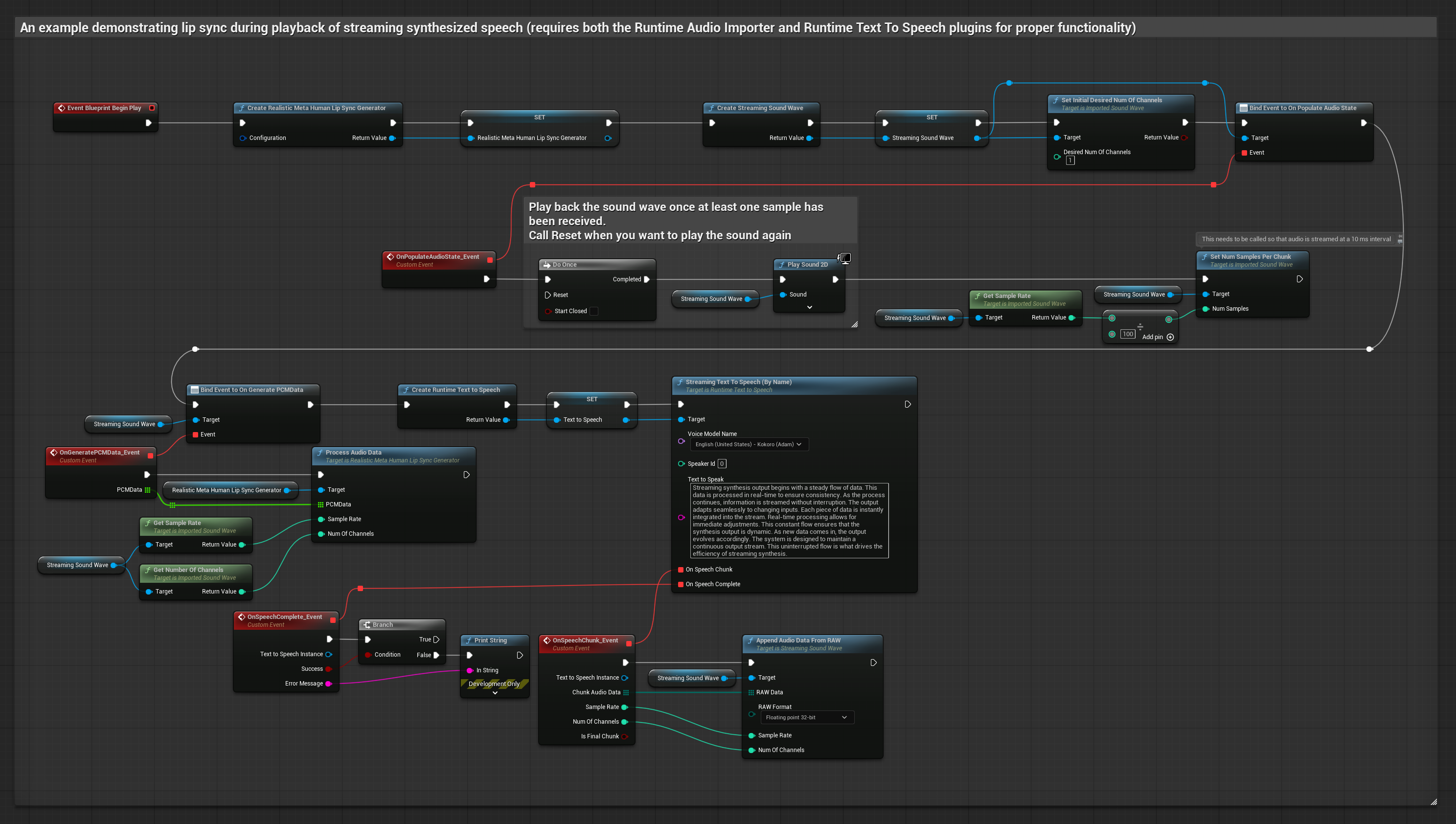
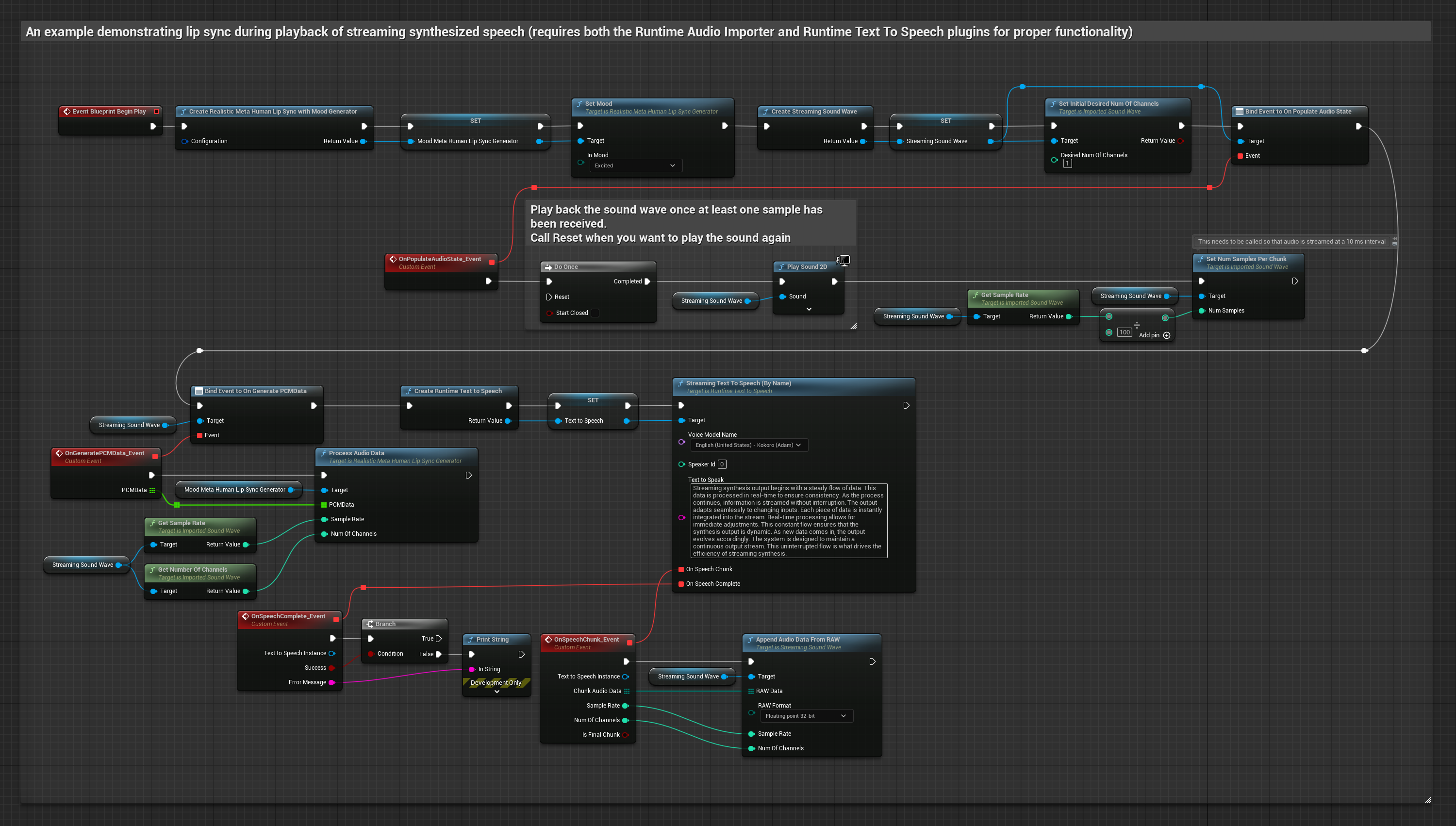
此方法使用串流文字轉語音合成與即時嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime Text To Speech 從文字生成串流語音
- 使用 Runtime Audio Importer 匯入合成的音訊
- 在播放串流音波之前,綁定到其
OnGeneratePCMData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData
- 一般
- 串流
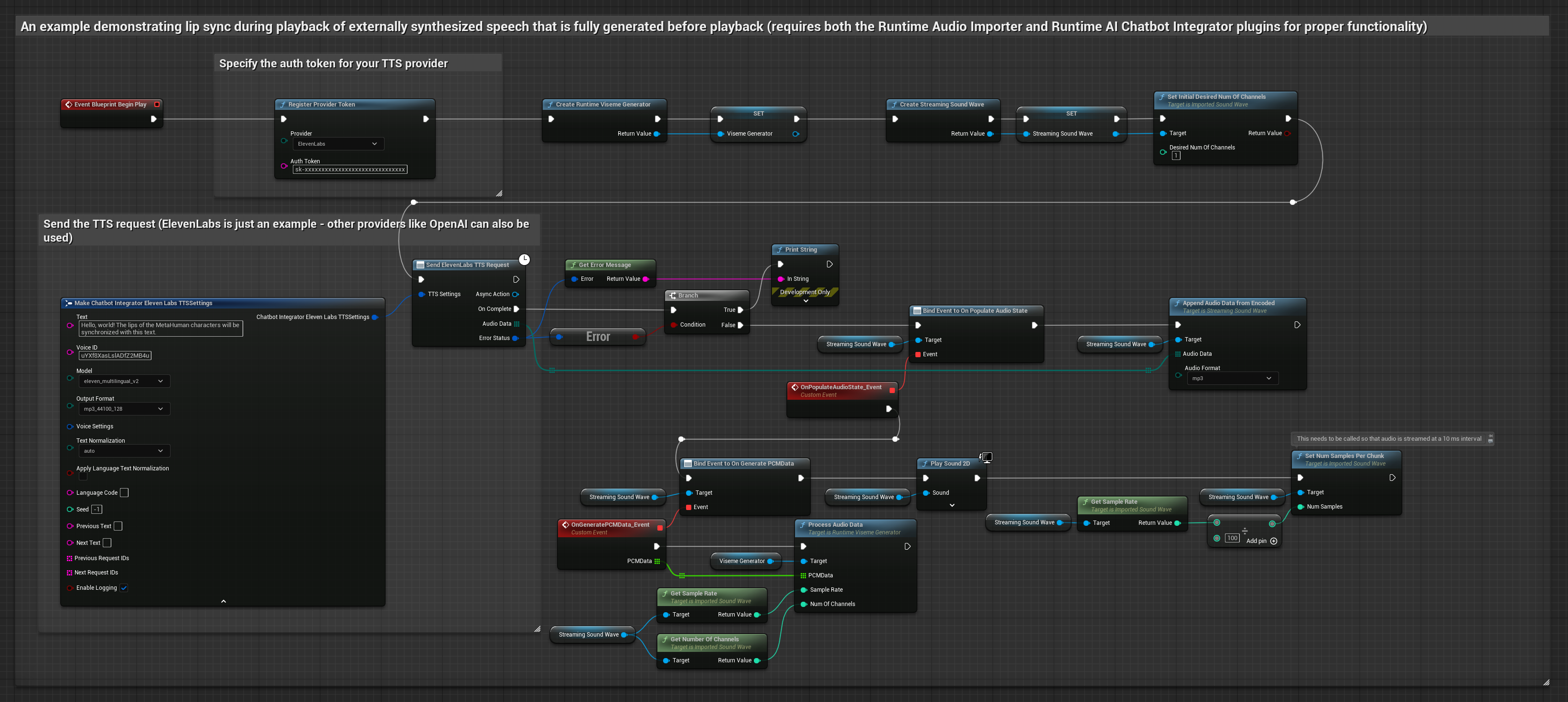
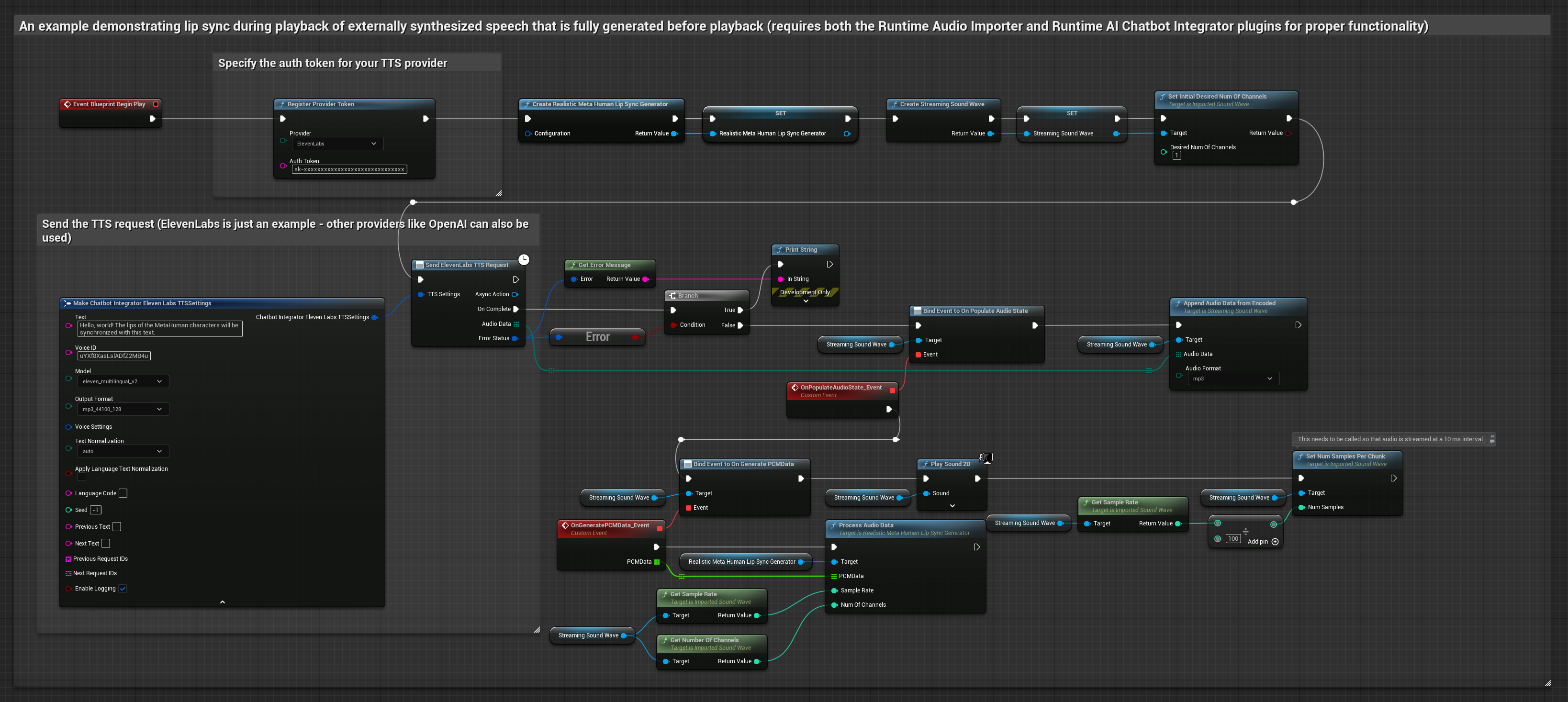
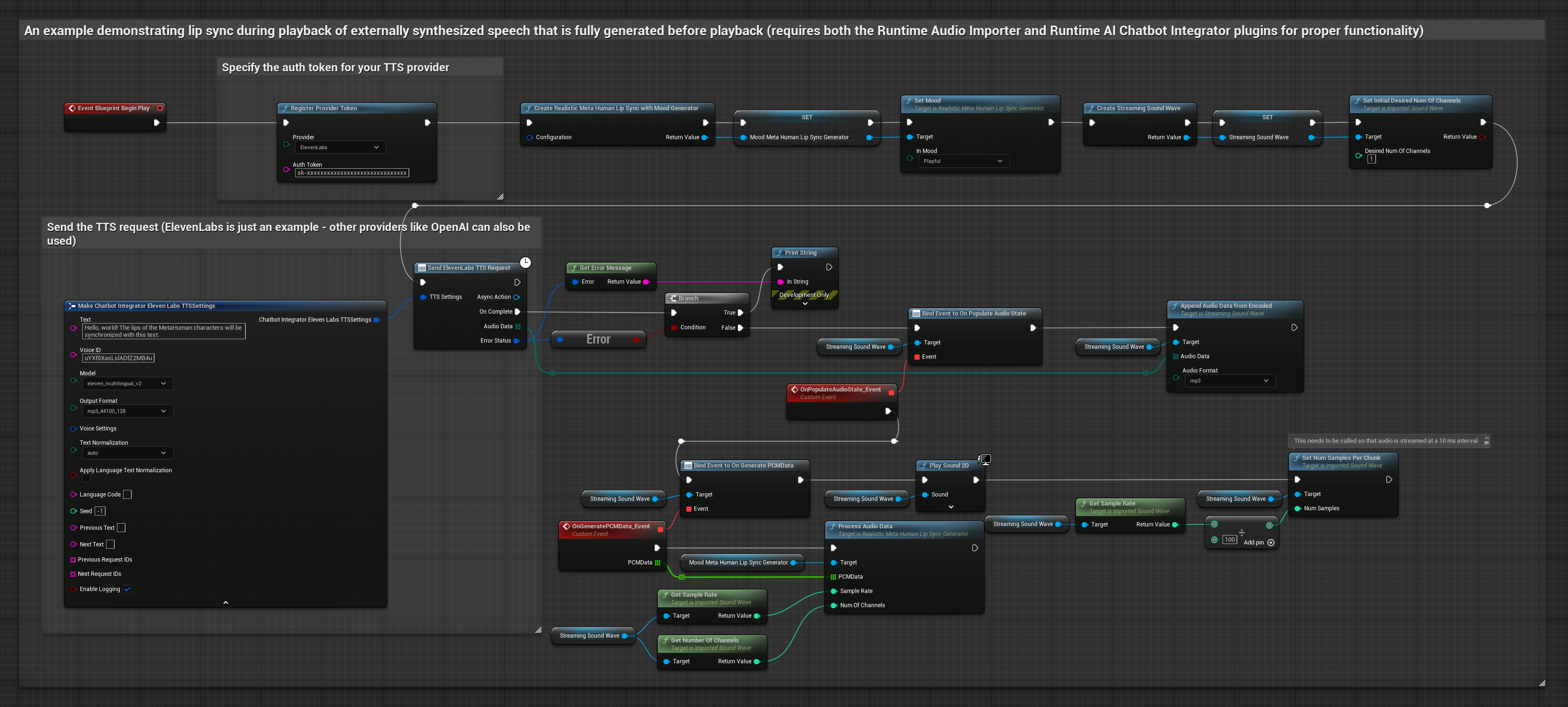
此方法使用 Runtime AI Chatbot Integrator 外掛程式從 AI 服務(OpenAI 或 ElevenLabs)生成合成語音並執行嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime AI Chatbot Integrator 使用外部 API(OpenAI、ElevenLabs 等)從文字生成語音
- 使用 Runtime Audio Importer 匯入合成的音訊資料
- 在播放匯入的音波之前,綁定到其
OnGeneratePCMData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData
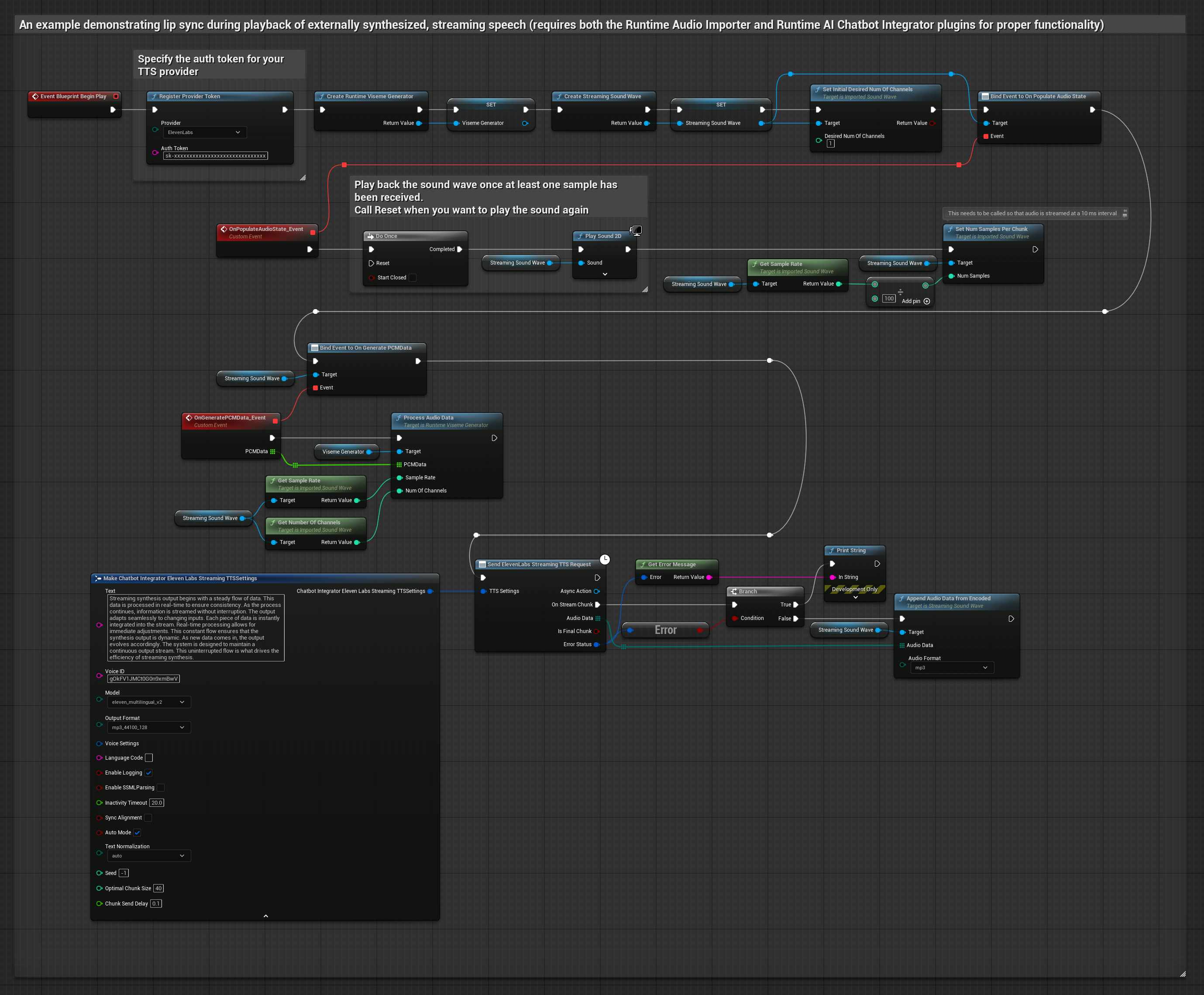
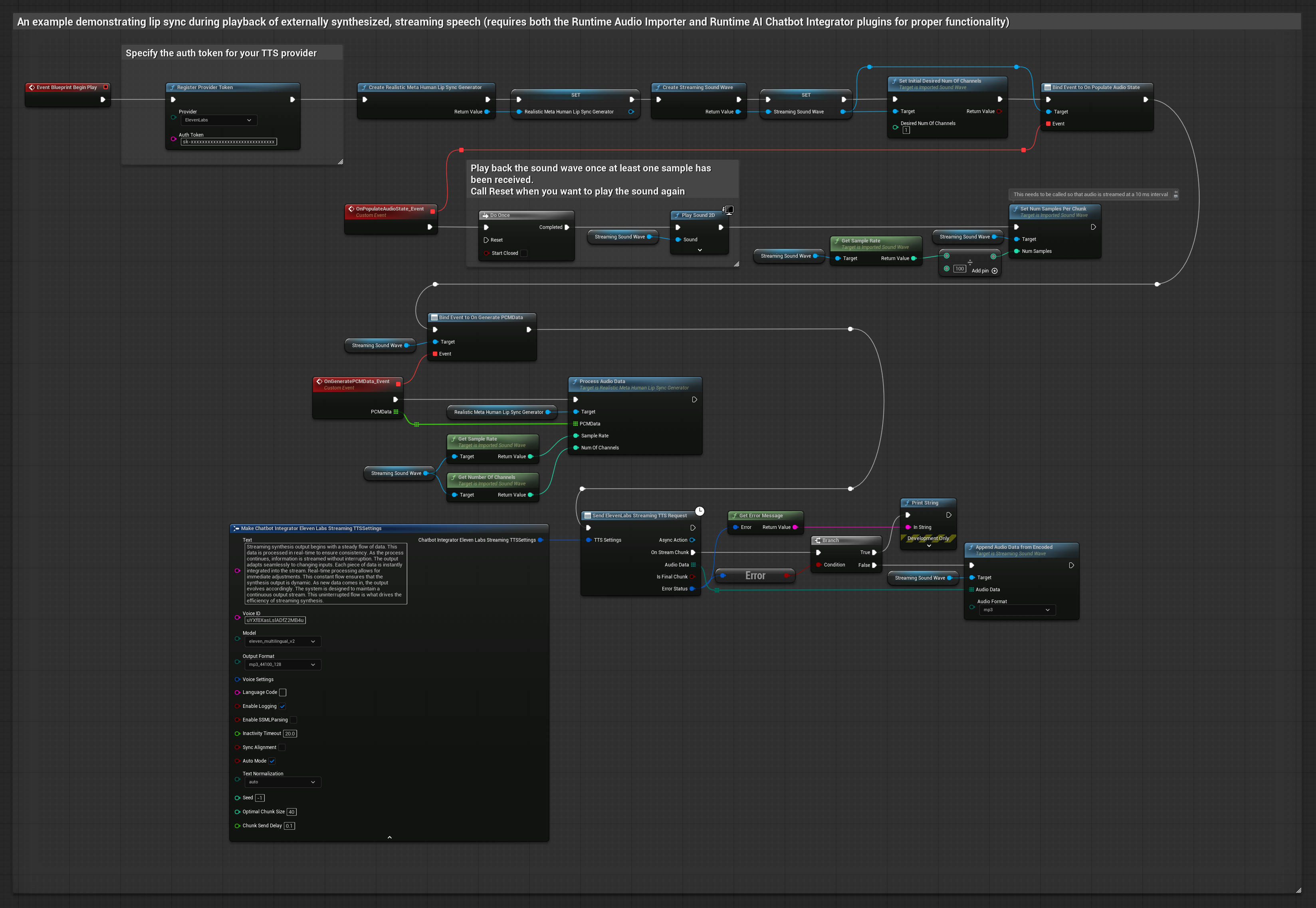
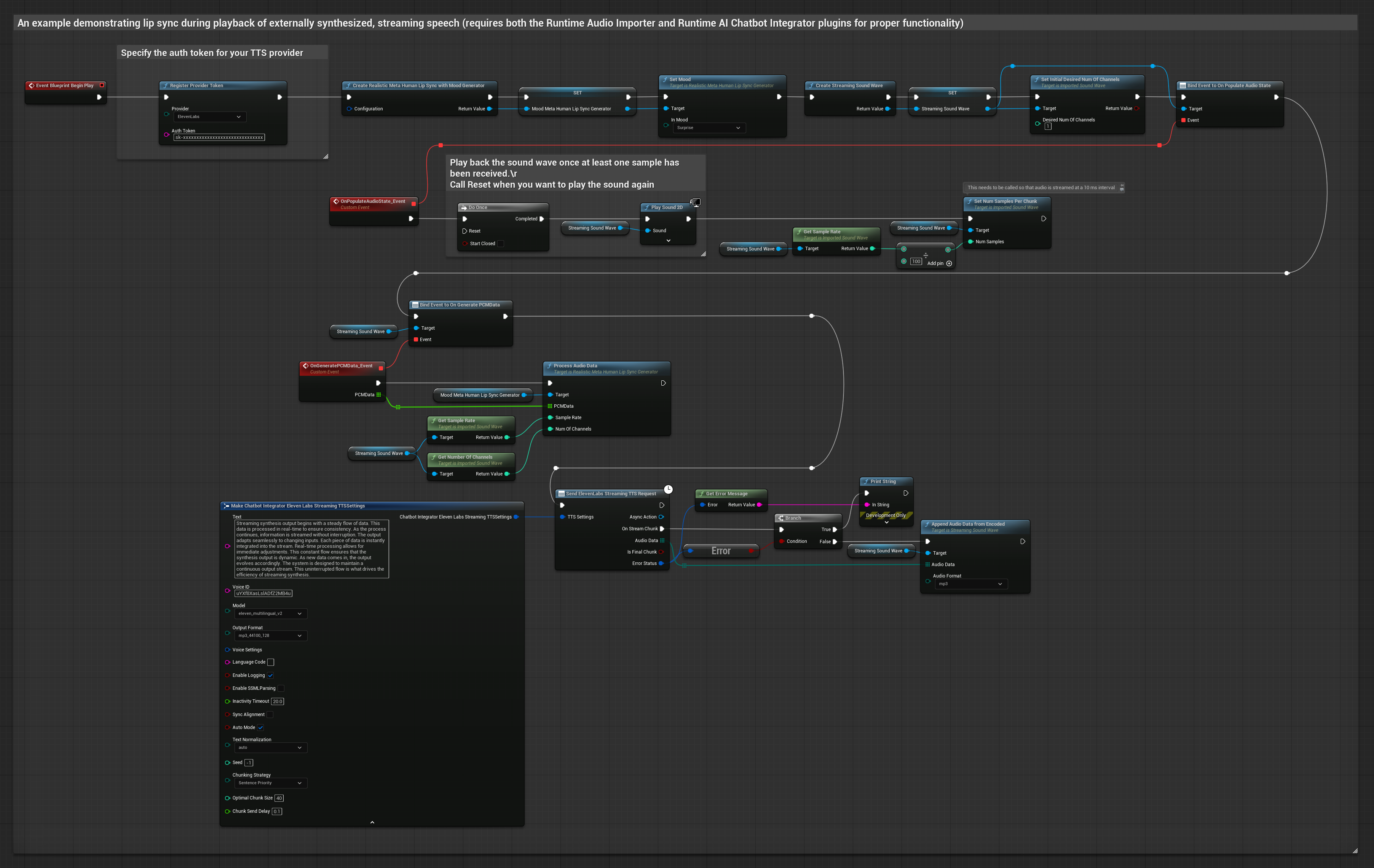
此方法使用 Runtime AI Chatbot Integrator 外掛程式從 AI 服務(OpenAI 或 ElevenLabs)生成合成串流語音並執行嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime AI Chatbot Integrator 連接到串流 TTS API(如 ElevenLabs Streaming API)
- 使用 Runtime Audio Importer 匯入合成的音訊資料
- 在播放串流音波之前,綁定到其
OnGeneratePCMData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData
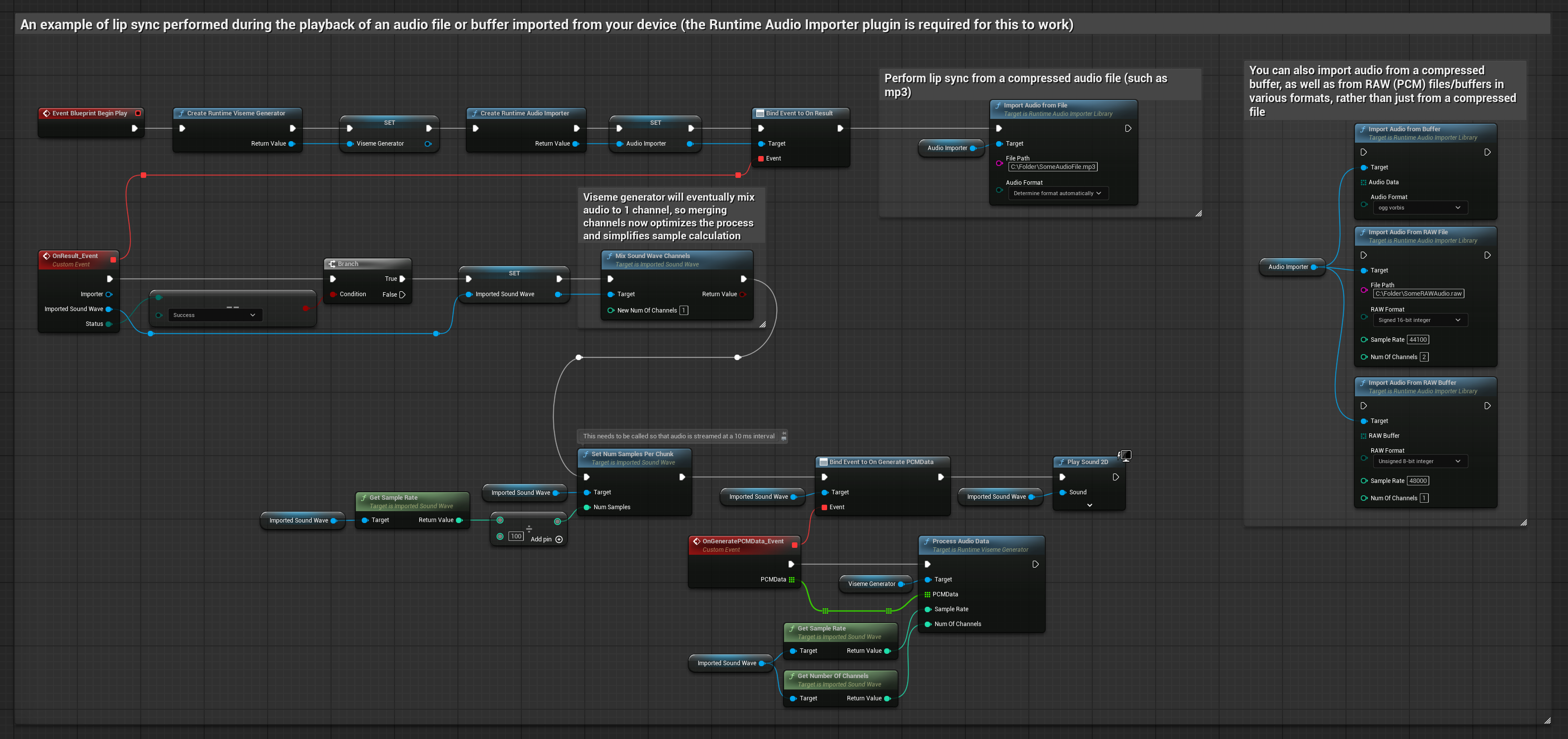
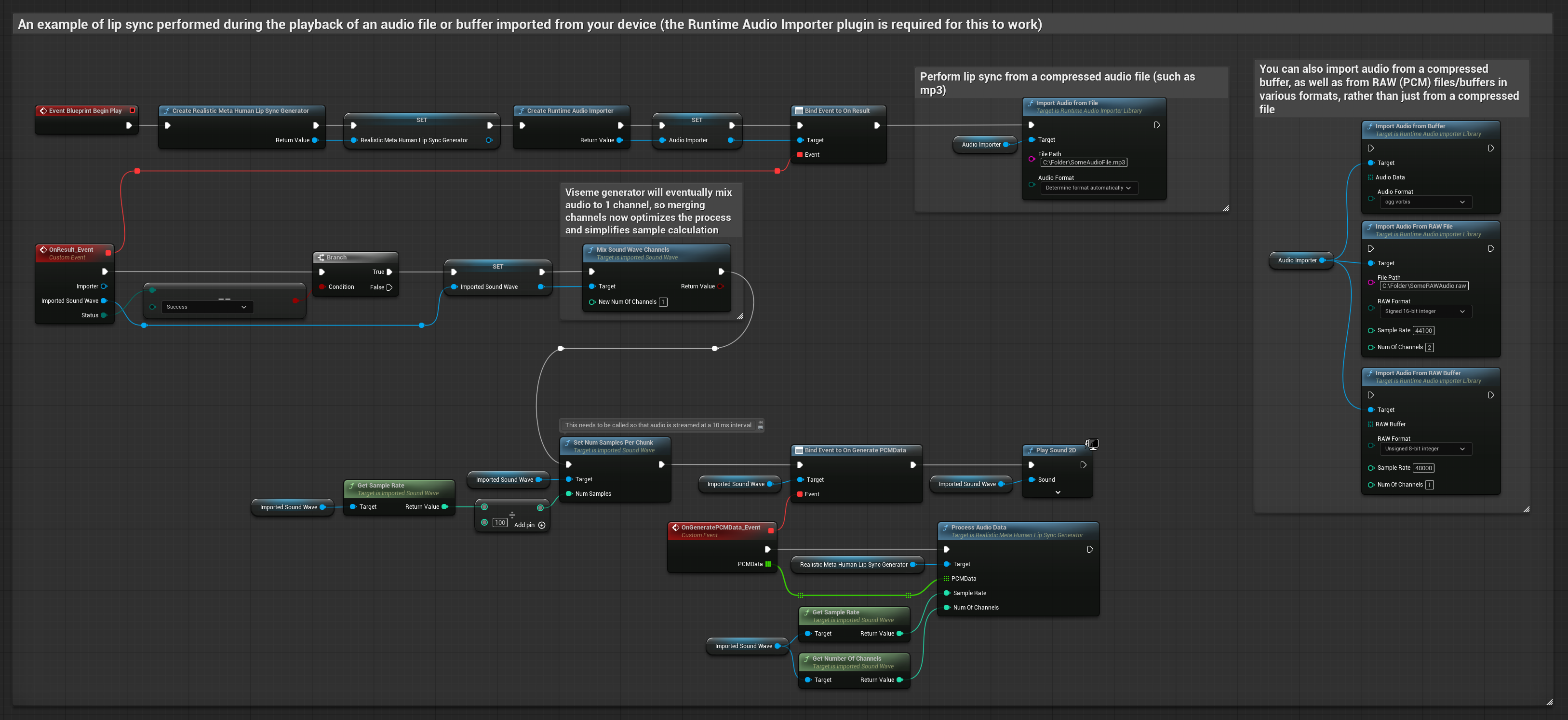
此方法使用預先錄製的音訊檔案或音訊緩衝區進行嘴型同步:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 使用 Runtime Audio Importer 從磁碟或記憶體匯入一個音訊檔案
- 在播放匯入的音波之前,綁定到其
OnGeneratePCMData委派 - 在綁定的函數中,從您的 Runtime Viseme Generator 呼叫
ProcessAudioData - 播放匯入的音波並觀察嘴型同步動畫
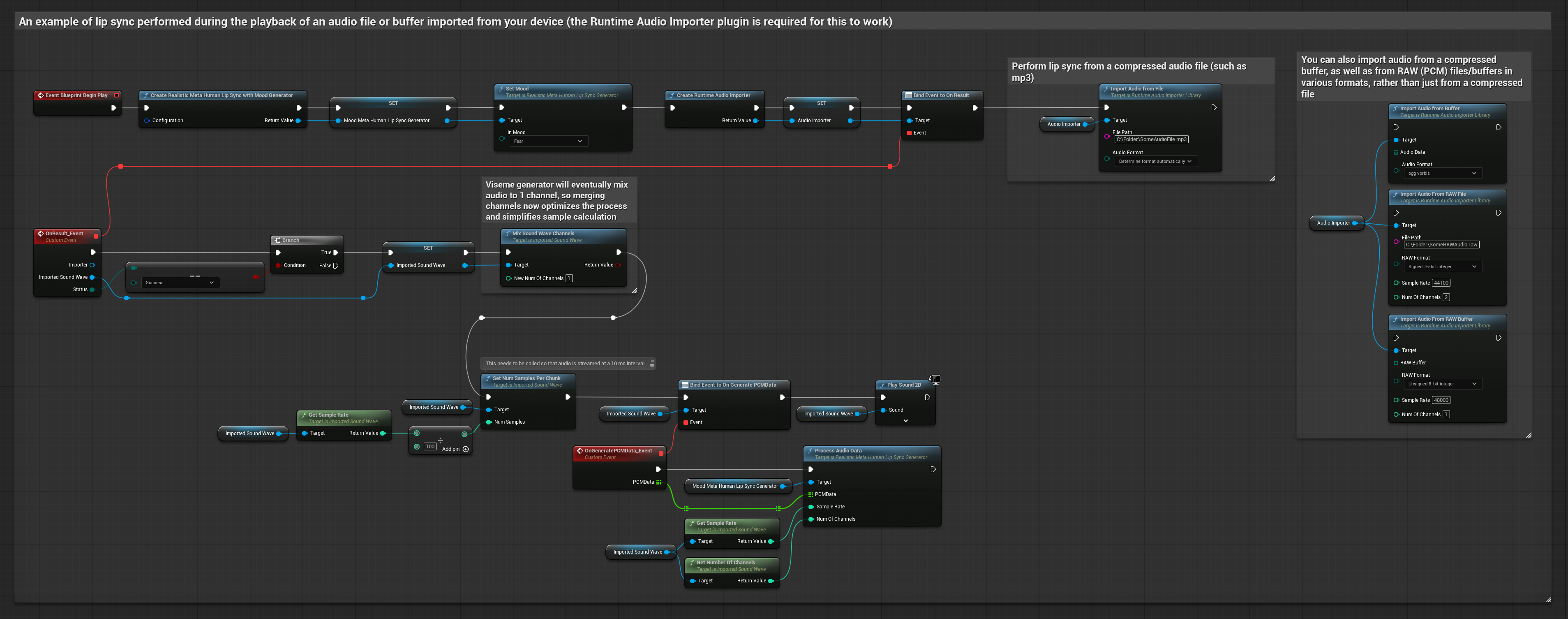
對於來自緩衝區的串流音訊資料,您需要:
- 標準模型
- 逼真模型
- 情緒啟用逼真模型
- 從您的串流來源取得 float PCM 格式的音訊資料(一個浮點樣本的陣列)(或使用 Runtime Audio Importer 以支援更多格式)
- 取樣率和聲道數
- 當音訊區塊可用時,使用這些參數從您的 Runtime Viseme Generator 呼叫
ProcessAudioData
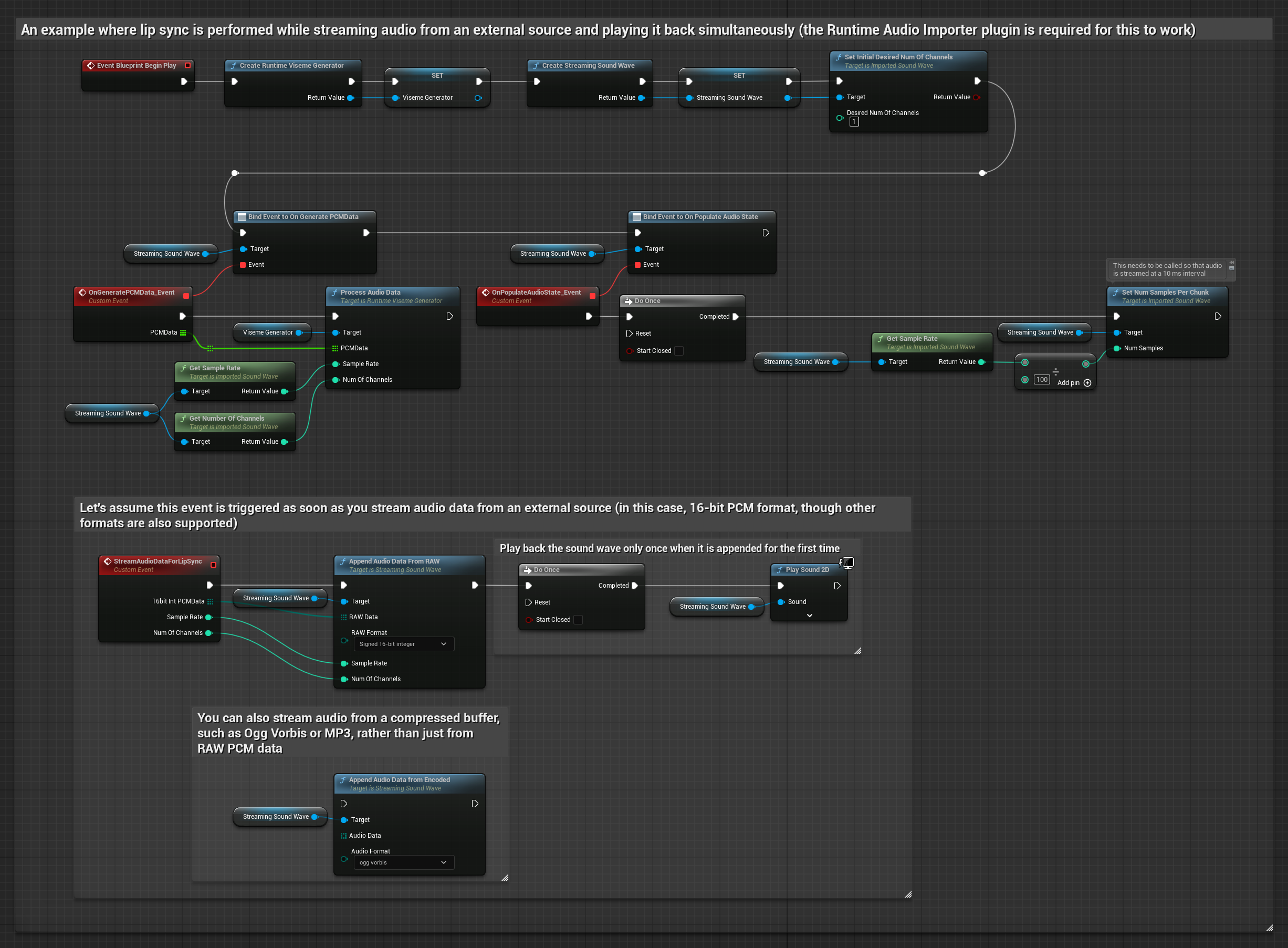
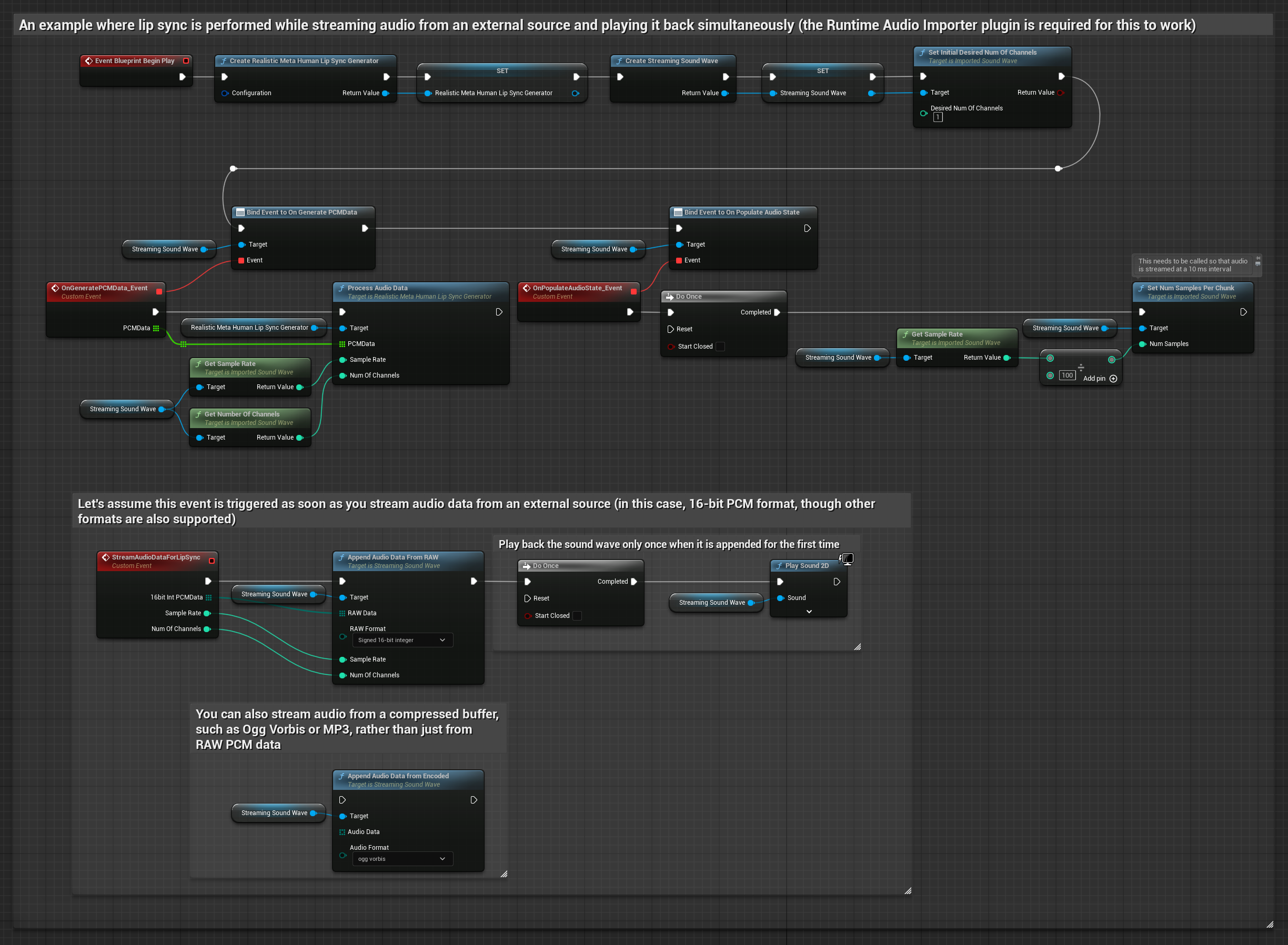
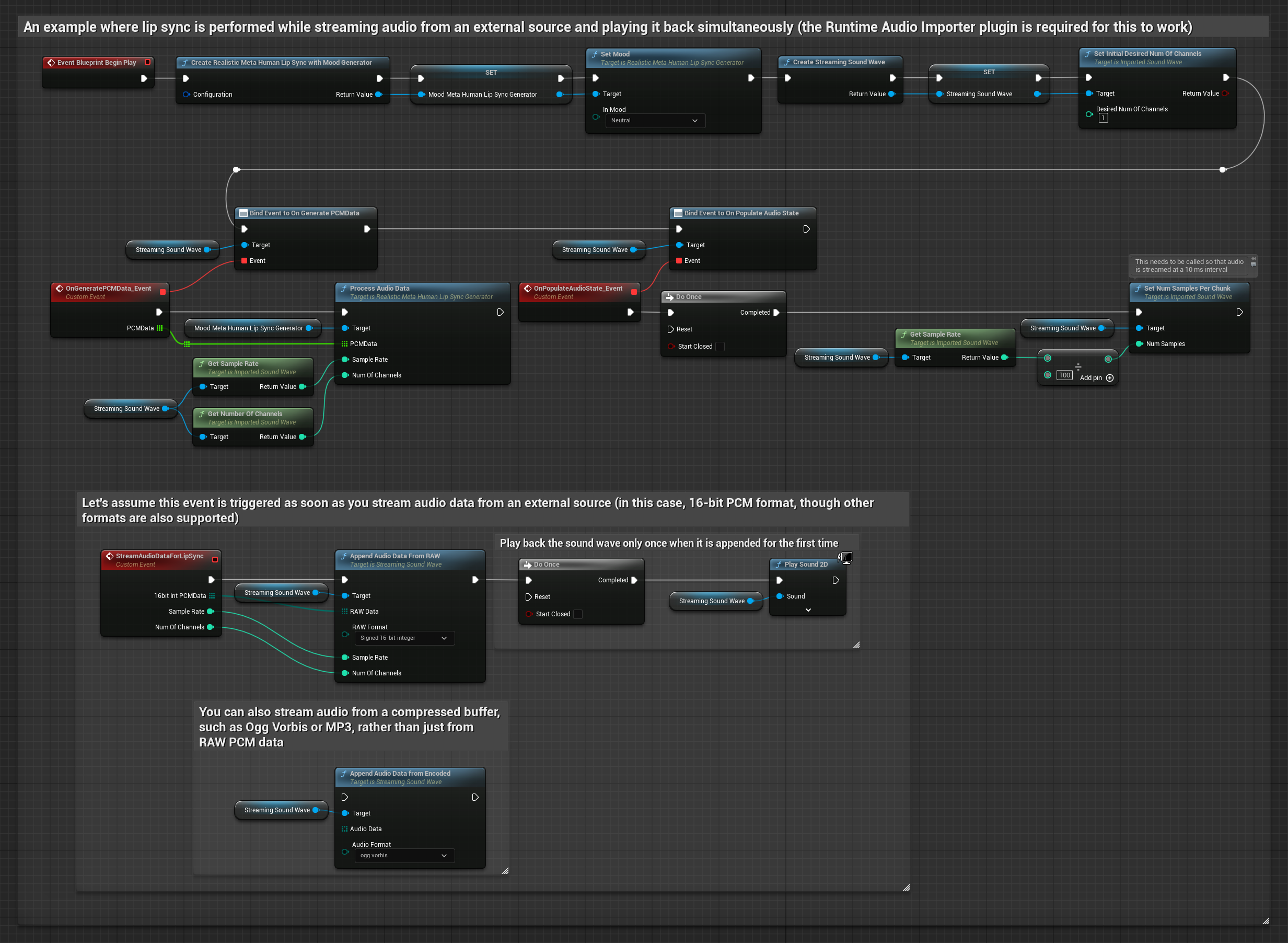
注意: 使用串流音訊來源時,請確保適當管理音訊播放時序,以避免播放失真。有關更多資訊,請參閱串流音波文件。
處理效能提示
-
區塊大小:增加
ProcessingChunkSize配置選項(例如增加到 320、480 或 640 個樣本)可以顯著改善延遲,同時對品質或響應性的影響最小。 -
模型類型:使用逼真模型時,切換到高度最佳化模型類型(預設選取)可以改善效能。請注意,原始模型可能產生略好的品質,特別是在處理有雜訊的音訊時。
-
緩衝區管理:情緒啟用模型以 320 個樣本的幀(16kHz 下為 20ms)處理音訊。確保您的音訊輸入時序與此對齊以獲得最佳效能。
-
生成器重建:為確保逼真模型的可靠運作,每次在非活動期後要饋送新的音訊資料時,請重建生成器。請參閱疑難排解中的生成器重建以了解說明。
後續步驟
一旦您設定好音訊處理,您可能想要: