示範專案
為了幫助您快速上手 Runtime MetaHuman Lip Sync,我們提供了兩個可直接使用的示範專案。兩者皆以 Unreal Engine 5.6+ 建置,僅使用藍圖,並可跨平台執行於 Windows、Mac、Linux、iOS、Android 以及基於 Android 的平台(包括 Meta Quest)。
可用示範專案
- AI 對話 NPC / 互動式虛擬角色
- 基本嘴型同步示範
一個 完整的 AI 對話虛擬角色工作流程,結合語音辨識、AI 聊天機器人(LLM)、文字轉語音以及音訊播放與即時嘴型同步——全部在同一個專案中執行。適用於多種使用情境,包括 遊戲、互動式資訊站、虛擬製作、博物館裝置、數位助理 以及 訓練模擬。
流程概述
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
影片
快速預覽 (~30 秒)
一個簡短的示範展示。
完整逐步解說
一個詳細的逐步解說,涵蓋設定、配置以及完整的對話流程。
下載
必要與選用插件
示範專案是模組化的 - 您只需要您想使用的提供者所需的插件。
| 插件 | 用途 | 必要? |
|---|---|---|
| Runtime MetaHuman Lip Sync | 嘴型同步動畫 | ✅ 總是 |
| Runtime Audio Importer | 音訊擷取與處理 | ✅ 總是 |
| Runtime Speech Recognizer | 離線語音辨識 (whisper.cpp) | ✅ 總是 |
| Runtime AI Chatbot Integrator | 外部 LLM (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) 和/或 外部 TTS (OpenAI, ElevenLabs) | 🔶 選用 |
| Runtime Local LLM | 透過 llama.cpp 進行本地 LLM 推論 (Llama, Mistral, Gemma 等 GGUF 模型) | 🔶 選用 |
| Runtime Text To Speech | 透過 Piper 和 Kokoro 進行本地 TTS | 🔶 選用 |
雖然上述每個插件都是個別選用的,但示範需要至少一個 LLM 提供者和至少一個 TTS 提供者才能運作。您可以自由混合搭配 (例如,本地 LLM + ElevenLabs TTS,或 OpenAI LLM + 本地 TTS)。
模組化架構
在 Content 資料夾中,您會找到一個 Modules 資料夾,其中包含三個子資料夾:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
如果您沒有取得一個(或多個)可選外掛,只需刪除對應的資料夾。示範專案的基礎資產(遊戲實例、小工具等)並未直接參考這些模組,因此刪除它們不會導致資產參考錯誤。設定 UI 會自動隱藏任何缺少資料夾的提供者。
此模組化僅適用於 LLM 和 TTS 提供者。語音辨識(Runtime Speech Recognizer)和嘴型同步(Runtime MetaHuman Lip Sync)是基礎示範專案的一部分,且始終為必要。
首次啟動時,Unreal 可能會詢問是否要停用任何遺失的可選外掛 - 請點擊是。請確保您也已刪除了對應的 Content/Modules/ 資料夾(見上方說明)。
示範專案佈局
下方顯示的使用者介面完全使用 UMG(Unreal Motion Graphics)建置,其目的純粹是為了示範流程 - 語音辨識 → LLM → TTS → 嘴型同步。您可以自由地重新設計樣式或替換它,以符合您專案的視覺設計、控制方案或平台(VR/AR、行動裝置、遊戲主機、資訊站等)。如果某些小工具在您的使用案例中不需要,您也可以直接隱藏它們(例如,將其可見性設為 Collapsed 或 Hidden)。

| 區域 | 內容 |
|---|---|
| 中央 | MetaHuman 角色。 |
| 左側 | 四個設定按鈕(語音辨識、AI 聊天機器人、文字轉語音、動畫),詳細說明如下。 |
| 中央底部 | 一個開始錄製按鈕。點擊它以開始語音對話:您的麥克風會被擷取、轉錄、發送給 LLM,回應會透過 TTS 合成,並伴隨嘴型同步播放,全程無需手動操作。 |
| 右側中央 | 一個對話歷史記錄小工具,顯示您與 AI 之間完整的來回對話(包含使用者和助理訊息)。它還包含一個文字輸入欄位,讓您可以直接輸入訊息而無需使用語音辨識,這對於測試、無障礙存取或麥克風不可用時非常有用。 |
您可以在同一個會話中自由混合兩種輸入模式 - 有些訊息用說的,有些用打的。
設定按鈕
左側的四個設定按鈕會為流程的每個部分開啟專用面板:
1. 設定語音辨識
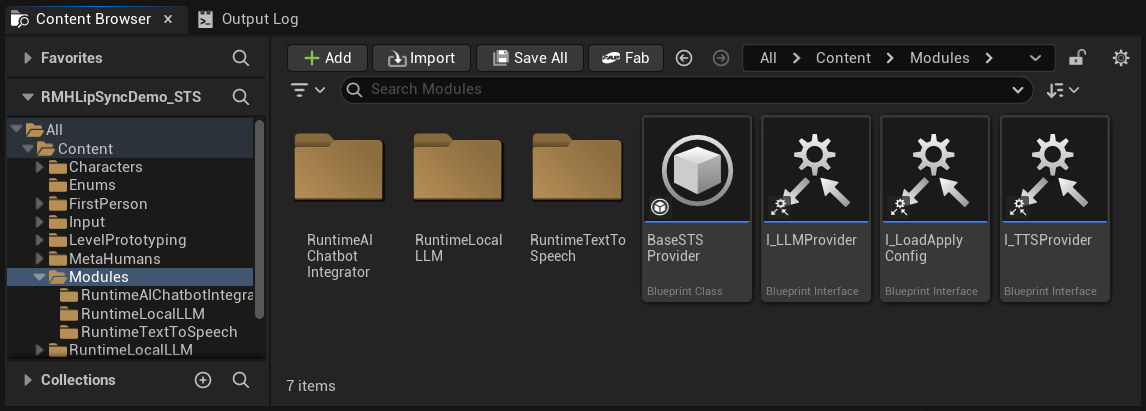
設定如何擷取和轉錄使用者的語音:
- 選擇語言
- 調整語音辨識參數(Whisper 模型設定)
- 設定 AEC(聲學迴聲消除)
- 設定 VAD(語音活動偵測)
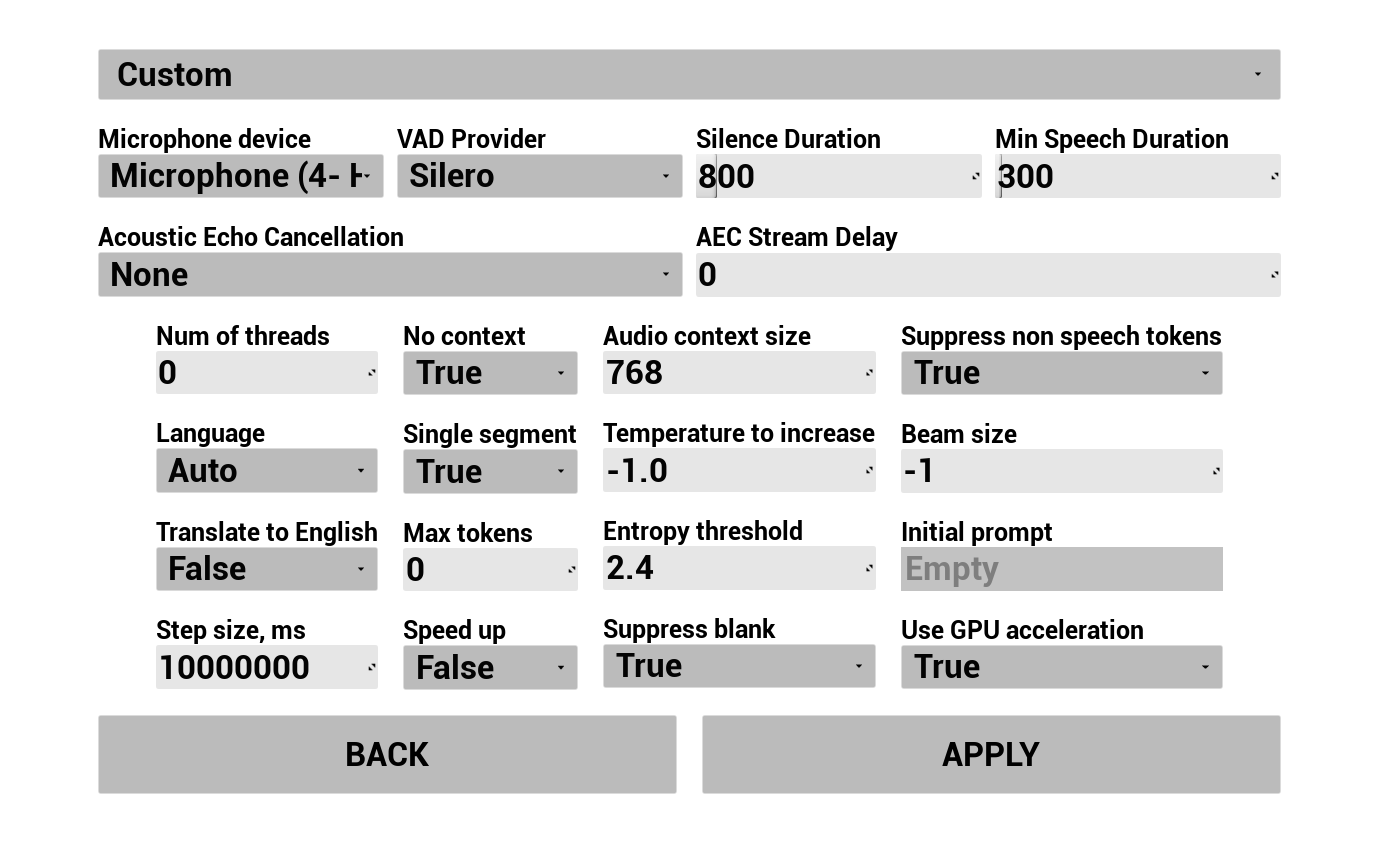
2. 設定 AI 聊天機器人
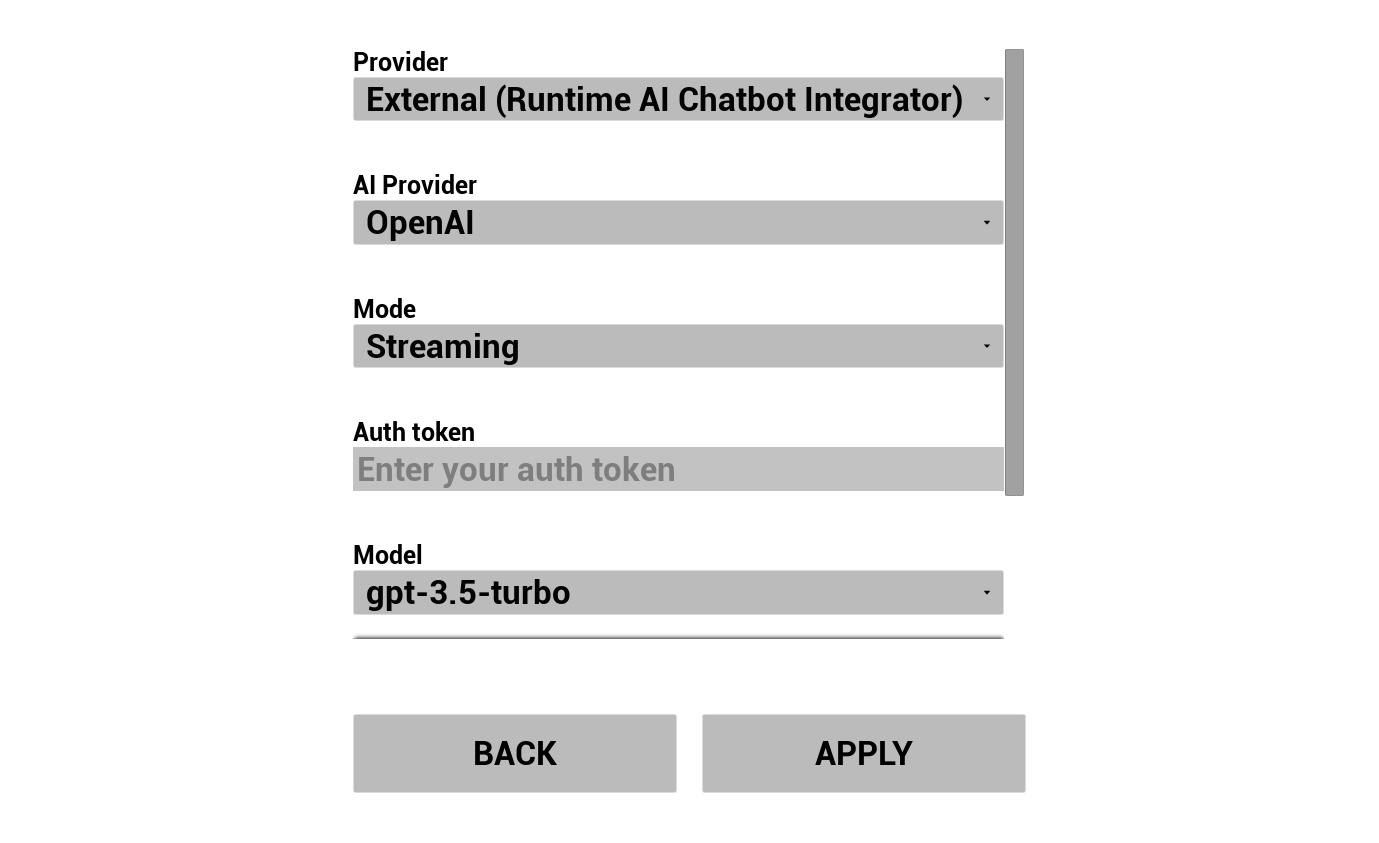
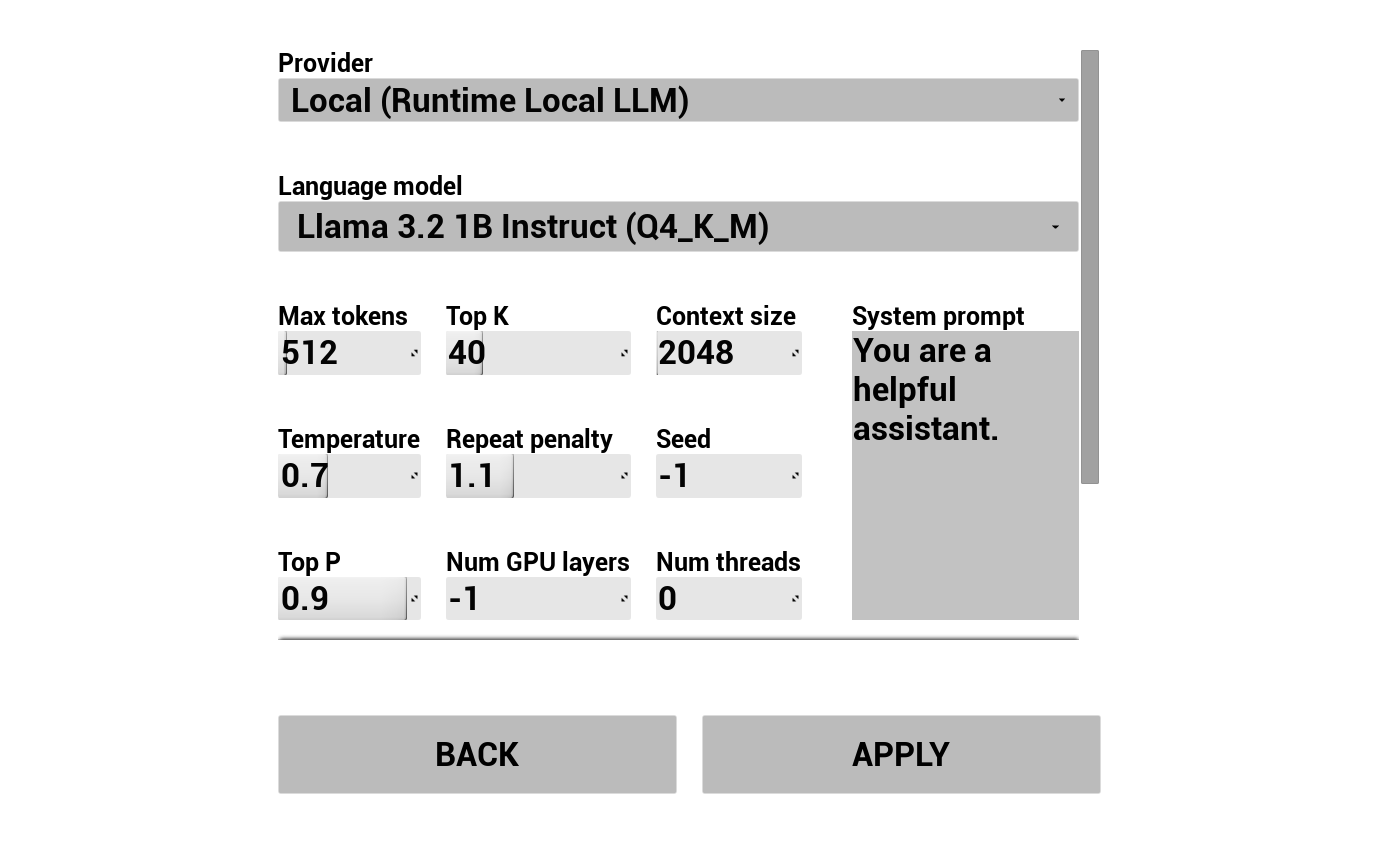
選擇您的 LLM 提供者並進行設定:
- 選擇提供者(Runtime AI Chatbot Integrator 或 Runtime Local LLM)
- 對於外部提供者:授權令牌、模型名稱等
- 對於本地 LLM:選擇一個 GGUF 模型,設定上下文大小和其他推論參數。您也可以直接從示範專案中在執行階段下載您自己的 GGUF 模型(例如透過 URL),並立即使用,無需重建專案。
提供者下拉選單只會顯示其外掛模組資料夾存在於 Content/Modules/ 中的提供者。
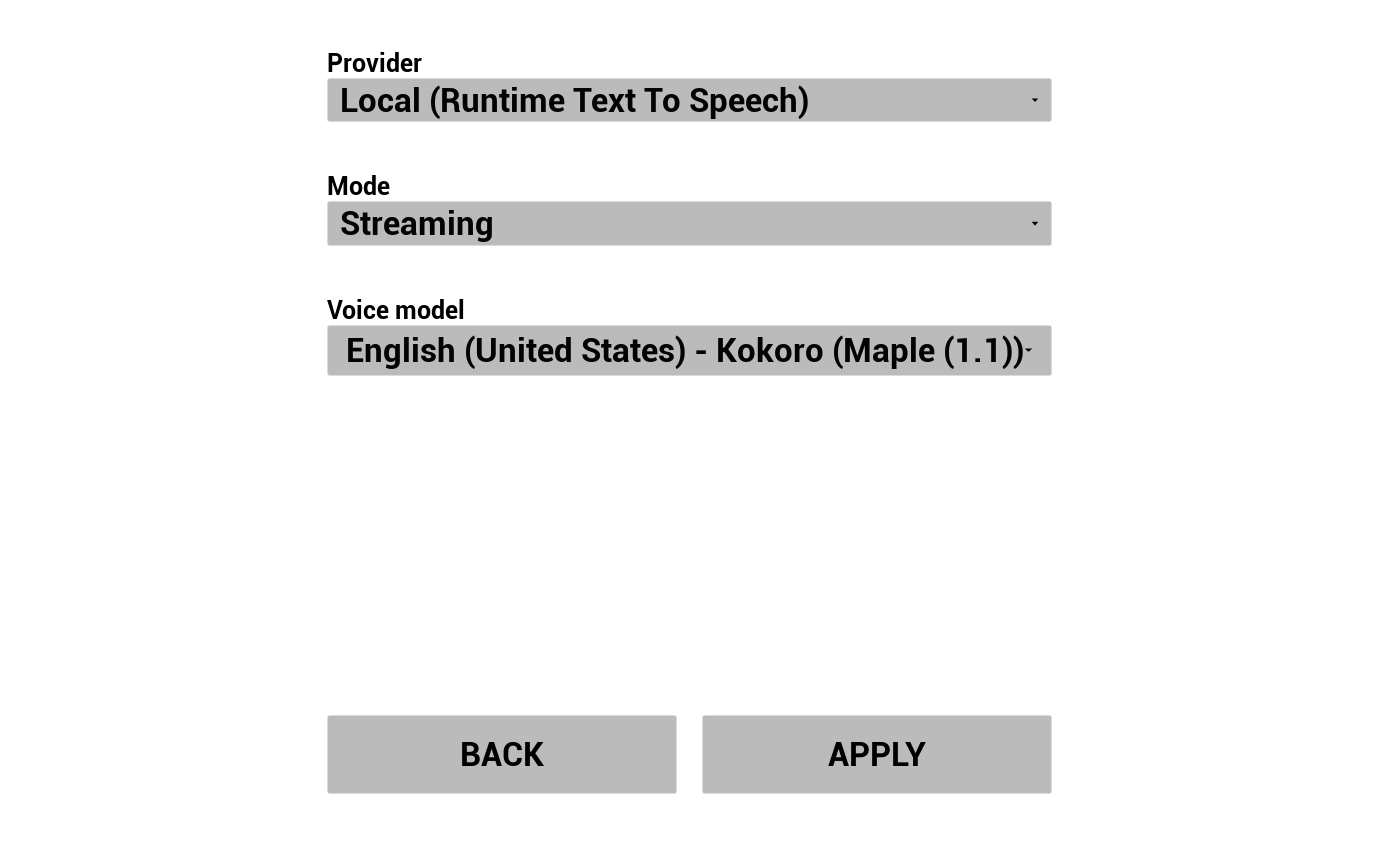
3. 設定文字轉語音
選擇您的 TTS 提供者並設定語音/模型:
- 選擇提供者(用於 OpenAI/ElevenLabs 的 Runtime AI Chatbot Integrator,或用於本地 Piper/Kokoro 的 Runtime Text To Speech)
- 選擇語音/模型
- 調整提供者特定的參數

4. 設定動畫
控制您的 AI 虛擬角色的視覺效果:
- 在 3 個預先下載的 MetaHuman 角色(Aera、Ada、Orlando)之間選擇
- 選擇嘴型同步模型(Standard 或 Realistic)
- 選擇嘴型同步模型類型 - Highly Optimized、Semi-Optimized 或 Original(請參閱模型類型)
- 調整處理區塊大小 - 控制嘴型同步推論的執行頻率(請參閱處理區塊大小)
- 選擇一個在對話期間於 MetaHuman 上播放的閒置動畫

在編輯器中預先設定示範專案
在使用原始碼版本時,您可以直接在編輯器中預先填入預設值,這樣每次執行時就不需要重新輸入數值:
| 項目 | 位置 |
|---|---|
| 一般設定(嘴型同步模型、閒置動畫、角色類別、語音辨識等) | Content/LipSyncSTSGameInstance |
| 外部 LLM / 外部 TTS 設定(Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| 本地 LLM 設定(Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| 本地 TTS 設定(Runtime Text To Speech) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
跨平台注意事項
示範專案使用的所有外掛都支援 Windows、Mac、Linux、iOS、Android 以及基於 Android 的平台(包括 Meta Quest),因此示範專案也能在所有這些平台上運作。這使其適用於部署在各種環境中 - 從遊戲和桌面資訊站到行動應用程式、獨立 VR 頭戴裝置以及片場虛擬製作設定。
對於效能較弱的裝置(行動裝置、獨立 VR),您可能需要:
- 使用 Standard 嘴型同步模型 而非 Realistic - 請參閱模型比較
- 切換到 Highly Optimized 模型類型
- 增加處理區塊大小以減少 CPU 負載
- 選擇較小的 LLM / TTS 模型
請參閱平台特定設定以了解 Android、iOS、Mac 和 Linux 上的額外設定步驟。
帶入您自己的角色
示範專案附帶三個範例 MetaHuman 角色(Aera、Ada、Orlando),但您可以匯入自己的 MetaHuman 並在示範專案中使用。
📺 影片教學: 將自訂 MetaHuman 角色加入示範專案
Runtime MetaHuman Lip Sync 外掛本身支援許多超越 MetaHuman 的其他角色系統(基於 ARKit 的角色、Daz Genesis 8/9、Reallusion CC3/CC4、Mixamo、ReadyPlayerMe 等 - 請參閱自訂角色設定指南)。無論您是在建構遊戲 NPC、虛擬主持人、資訊站服務員,還是用於虛擬製作的數位人類,此外掛都能適應您的角色流程。
一個更簡單的示範專案,純粹專注於嘴型同步功能本身,沒有完整的 AI 對話流程。如果您只想看到嘴型同步與各種音訊來源的實際運作情況,這個專案很適合。
精選影片
下載
包含內容
此示範專案展示了基本的嘴型同步工作流程:
- 麥克風輸入 - 從即時音訊進行即時嘴型同步
- 音訊檔案播放 - 從匯入的音訊檔案進行嘴型同步
- 文字轉語音 - 由合成的語音驅動的嘴型同步
必要與可選外掛
| 外掛 | 用途 | 必要? |
|---|---|---|
| Runtime MetaHuman Lip Sync | 嘴型同步動畫 | ✅ 必要 |
| Runtime Audio Importer | 音訊匯入與擷取 | ✅ 必要 |
| Runtime Text To Speech | 用於 TTS 示範場景的本地 TTS | 🔶 可選 |
| Runtime AI Chatbot Integrator | 外部 TTS 提供者(OpenAI、ElevenLabs) | 🔶 可選 |
標準嘴型同步模型的注意事項
如果您計劃在任何一個示範專案中使用 Standard 模型(而非 Realistic),您需要安裝 Standard Lip Sync Extension 外掛。請參閱標準模型擴充以了解安裝說明。
需要協助?
如果您在設定或執行示範專案時遇到任何問題,請隨時聯繫:
對於客製化開發需求(例如:為示範專案擴展您自己的邏輯、針對特定平台或角色管線進行調整),請聯絡 [email protected]。